

AIは「行列」という数学のレンズを使い、データを変換して本質を理解します。ここでは、データを自在に操る基本文法から、その変換の「魂」を見抜く固有値、そして複雑な情報を要約する主成分分析(PCA)までの核心を探ります。
患者の状態(ベクトル)を、治療介入などのアクション(行列)によって変化させるプロセスです。行列の積というルールに従い、AIはデータを処理・変換します。
逆行列は変換を取り消す操作ですが、常には存在しません。行列式が0のとき、空間が潰れ情報が失われるため元に戻せなくなります。これはCT画像再構成の基本原理です。
複雑な変換の中でも向きを変えず、伸縮するだけの特別な方向(固有ベクトル)とその倍率(固有値)です。疾患の進行パターンやその勢いなど、システムの「本質」を暴きます。
AIが、まるでベテランの臨床医のように複雑な医療データから重要なパターンを見つけ出す—その裏側で何が起きているか、考えたことはありますか? 実は、AIは数学という非常に強力な「レンズ」を駆使しています。CTスキャンがX線のデータを再構成して鮮明な断面画像を作り出すように、AIもまた、生のデータを数学的に「変換」することで、その奥に隠された本質的な構造を浮かび上がらせているのです。この魔法のような「レンズ」の正体こそ、今回探検する「変換」の数学の世界です。
一見すると無秩序な数字の羅列にしか見えないデータも、行列(マトリックス)という道具を用いることで、その姿をガラリと変えることができます。データを回転させたり、引き伸ばしたり、あるいは特定の方向から光を当てて影を映すように、重要な特徴だけを抽出したり…。この「変換」という操作こそが、AIがデータを理解するための第一歩となります。
さあ、今回はAIの「目」そのものと言える、このパワフルな数学の世界へ一緒に足を踏み入れてみましょう。データを自在に操る行列の演算から始まり、その応用として、複雑な情報をシンプルに要約する主成分分析(PCA)に至るまで、医療現場の具体的なシナリオを思い浮かべながら、その仕組みと臨床的な価値を解き明かしていきます。
行列の演算:データを自在に動かす「文法」
AIの数学の世界、その主役であるベクトルと行列の関係から見ていきましょう。ここを正確に、そして直感的に理解することが、AIがデータをどう扱っているのかを掴むための最短ルートです。
ベクトル:患者の「状態」を座標で示す
まず、AIが「患者さん」を認識するためには、その複雑な情報をコンピュータが扱える形、つまり数字のリストに変換する必要があります。この、特定の順序で並べられた数字のリストがベクトルです。
例えば、一人の患者さんの基本的な情報(身長、体重、収縮期血圧)を、次のように縦に並べてみましょう。
\[ \text{患者Aの状態ベクトル} = \begin{pmatrix} 170 \\ 65 \\ 120 \end{pmatrix} \quad \leftarrow \text{身長(cm), 体重(kg), 血圧(mmHg)} \]
これは単なるデータの入れ物ではありません。地図上の点が緯度と経度の2つの数字で位置を示すように、このベクトルは「身長・体重・血圧」という3つの軸が張る3次元の健康空間における、患者Aさんの現在の位置(座標)を示している、と考えることができます。これが、データを「登場人物」や「モノ」、すなわち「名詞」と捉える考え方です。
行列:状態を変化させる「アクション」
次に、この患者さんの状態(位置)を変化させる「何か」が必要です。それが行列です。行列は、特定の操作、例えば「治療介入」や「1年間の自然経過」といった「アクション(動詞)」を数学的に表現したものです。
行列は、ベクトルに掛け合わされることで、ベクトルを別のベクトルに変換します。つまり、患者さんを健康空間内のある地点から別の地点へと移動させる、「移動指示書」のような役割を果たすのです。
行列の積:文法に従って「変換」を実行する
「名詞」であるベクトル(患者の状態)と、「動詞」である行列(アクション)が出会いました。これらを結びつけ、「誰が(何が)、どうした」という一つの完成した文、すなわち「変換」を完成させるルールが行列の積です。この計算ルールこそが、AIがデータを処理する上での基本文法となります。
具体的な例で、この文法をじっくりと見ていきましょう。
シナリオ1:シンプルな治療介入
ある治療が「体重を10%減少させ、血圧を5%上昇させる」独立した効果を持つとします。これを数式にすると、
- 新しい体重 = 0.9 × (現在の体重) + 0 × (現在の血圧)
- 新しい血圧 = 0 × (現在の体重) + 1.05 × (現在の血圧)
となりますね。この関係性をそのままの形で、数字を抜き出して箱に詰めたものが「行列」です。1行目が「新しい体重の作り方」、2行目が「新しい血圧の作り方」に対応します。
\[ \text{治療介入Aの行列} = \begin{pmatrix} 0.9 & 0 \\ 0 & 1.05 \end{pmatrix} \]
では、この行列を、患者さんの現在の状態ベクトル(体重65kg, 血圧120mmHg)に作用させてみましょう。計算は「行列の行」と「ベクトルの列」のペアで行います。
ステップ1:新しい体重(1行目)を計算する
行列の1行目 \((0.9, 0)\) を取り出し、ベクトル \((65, 120)\) の上に乗せて、対応する要素同士を掛け算し、足し合わせます。
\[ (0.9 \times 65) + (0 \times 120) = 58.5 \]
これが、新しいベクトルの1行目の値になります。
ステップ2:新しい血圧(2行目)を計算する
同様に、行列の2行目 \((0, 1.05)\) を取り出し、ベクトルと計算します。
\[ (0 \times 65) + (1.05 \times 120) = 126 \]
これが、新しいベクトルの2行目の値です。
結果の完成
この2つの結果を縦に並べれば、変換後の新しいベクトルが完成します。
\[ \begin{pmatrix} 0.9 & 0 \\ 0 & 1.05 \end{pmatrix} \begin{pmatrix} 65 \\ 120 \end{pmatrix} = \begin{pmatrix} 58.5 \\ 126 \end{pmatrix} \]
このように、行列の積は、元のベクトルの各要素を様々に組み合わせ、重み付けすることで、新しいベクトルを生成するプロセスなのです。
シナリオ2:少し複雑な治療介入(変数の相互作用)
行列の真価は、変数同士が互いに影響し合う、より複雑な状況を表現できる点にあります。
例えば、別の治療Bは「体重を10%減少させるが、副作用として減少した体重1kgあたり0.2mmHg血圧が上昇する」とします。これを数式にすると、
- 新しい体重 = 0.9 × (現在の体重) + 0 × (現在の血圧)
- 新しい血圧 = -0.02 × (現在の体重) + 1.0 × (現在の血圧)
*(体重が10kg減ると(-10kg)、血圧が-0.02×(-10)=+2mmHg上がる、という関係)*
この場合の「治療介入B」の行列は次のようになります。
\[ \text{治療介入Bの行列} = \begin{pmatrix} 0.9 & 0 \\ -0.02 & 1.0 \end{pmatrix} \]
先ほどと違い、行列の左下の成分に「-0.02」という数字が入りました。これは「現在の体重が、未来の血圧に影響を与える」という変数間の相互作用を示しています。これこそが、現実の複雑な生命現象をモデル化する上で行列が強力なツールである理由です。
ディープラーニングとの繋がり
一見シンプルなこの「行 × 列」の計算ですが、実はディープラーニングの根幹そのものです。ニューラルネットワークの各層(レイヤー)では、入力ベクトルに対して、その層が持つ「重み行列」を掛け合わせる、という変換が延々と繰り返されています。
「学習」とは、何百万人もの患者データを使って、「未来の状態(予測)」が「実際の状態(正解)」と一致するように、この膨大な数の行列に含まれる数字(重み)を、勾配降下法という手法で微調整していく作業なのです。この基本文法こそが、AIがデータを理解し、精緻な予測を行うための、全ての出発点と言えるでしょう。
逆行列と行列式:「元に戻す」魔法とその条件
科学や医療の世界では、しばしば「逆の問題」を解く必要に迫られます。私たちは「結果」を観測し、そこから「原因」を推測するのです。症状という「結果」から病気という「原因」を探る診断プロセスも、その一つと言えるでしょう。
データの世界でも同じです。行列を使ってデータを変換(操作)できることは学びましたが、多くの場合、私たちは変換された「結果」のデータを見て、「元の状態はどうだったのか?」を知りたくなります。この「原因を遡る」という極めて重要な操作を可能にするのが、逆行列です。
逆行列:完璧な「取り消しボタン」
変換\(A\)を完全に元に戻す操作、それが逆行列\(A^{-1}\)です。変換\(A\)を適用した直後に逆行列\(A^{-1}\)を適用すると、データは完全に元の状態に戻ります。
\[ A^{-1} (A \boldsymbol{x}) = \boldsymbol{x} \]
これは、ある操作とその「取り消し」操作を連続して行うと、結局「何も起こらなかった」のと同じになる、ということです。この「何も起こらない」という変換を表す特別な行列が単位行列 \(I\)(対角成分がすべて1で、他は0の行列)です。逆行列の厳密な定義は、「ある行列\(A\)とその逆行列\(A^{-1}\)を掛け合わせると、単位行列\(I\)になる」というものです。
\[ A^{-1}A = I \]
しかし、この強力な「取り消しボタン」には重大な制約があります。それは、すべての行列に逆行列が存在するわけではない、ということです。では、どんな時に「取り消しボタン」は機能しなくなるのでしょうか?その運命を握るのが行列式です。
行列式:変換が「情報を失うか」を判定する究極の指標
さて、前のセクションで、便利な「取り消しボタン」である逆行列が、いつでも使えるわけではない、という少し厄介な問題に直面しました。では、ある変換が「元に戻せる」のか、それとも「もう後戻りできない」のか。その運命を、変換を実行する前に知ることはできるのでしょうか?
できます。そのための究極の指標が行列式(Determinant)です。これは、行列から計算されるたった一つの数字ですが、その変換が持つ「性質」を見事に暴き出してくれます。
すべての変換は「地図のルール」を変えることから始まる
行列式の本質を掴むために、まず行列が空間に何をしているのか、そのからくりを覗いてみましょう。
私たちのデータが住んでいる2次元空間を、方眼紙が引かれた広大な地図だと考えてください。この地図には、「右に1進む」という基本的な動きと、「上に1進む」という基本的な動き、2つの「ものさし」がありますよね。この最も基本的な動きの単位こそが、基底ベクトル \( \boldsymbol{e_1} = \begin{pmatrix} 1 \\ 0 \end{pmatrix} \) と \( \boldsymbol{e_2} = \begin{pmatrix} 0 \\ 1 \end{pmatrix} \) です。これらは、いわば地図の東西南北のルールそのものです。
行列による変換の正体とは、実はこの地図のルール自体を書き換えることに他なりません。「今までの『右』は、これからはこちらの『新しい右』の方向を指すことにします」「『上』はこちらの『新しい上』です」と、基準となるものさし(基底ベクトル)の行き先を新たに定義するのです。
基準となる方眼紙のグリッドが歪めば、その上に描かれた地図全体も、当然同じように歪みます。
行列式とは? –– 「基準となる正方形」の面積変化率
ここで、行列式が登場します。行列式は、非常にシンプルな問いに答えてくれます。
「基準となっていた面積1の正方形グリッドは、変換後、どれくらいの面積の平行四辺形になりましたか?」
行列式の絶対値は、まさにこの面積の変化率(倍率)なのです。この「面積」がどうなるかが、情報が失われるかどうかを考える上で決定的に重要になります。
ケース1:行列式 ≠ 0 — 復元の「設計図」が描ける世界
行列式の値が0でない、ということは、基準の正方形が変換後に面積を持つ平行四辺形になったことを意味します。
- 何が起きているか?
形は歪んだかもしれませんが、「新しい右」と「新しい上」はそれぞれ異なる方向を指しており、依然として空間を2次元的に「張る」力を持っています。つまり、次元が潰れていないのです。 - なぜ元に戻せるのか?
面積が残っている、ということは、情報が失われていない証拠です。どの点がどこに移動したかの対応関係がきちんと残っているため、操作を逆にたどる「復元の設計図」(=逆行列)を描くことができます。
ケース2:行列式 = 0 — 情報が「次元のブラックホール」に吸い込まれる瞬間
問題は、行列式の値が0になる場合です。これは、単なる変形ではありません。次元の崩壊です。
- 何が起きているか?
行列式が0になる、ということは、変換後の平行四辺形の面積が0になったことを意味します。これは、「新しい右」と「新しい上」が、偶然にも同じ直線上を向いてしまった状態です。2つあったはずの基準の「ものさし」が、1つのものさしに重なってしまったのです。
その結果、2次元の「面」だった空間全体が、一本の「線」あるいは一つの「点」へと押しつぶされて(射影されて)しまいます。 - なぜ元に戻せないのか?
一度「線」に潰されてしまうと、その線上の点が、もともと2次元空間のどこにあったのか、という奥行きに関する情報が完全に失われます。例えるなら、3次元の物体を真横から撮影した2次元の写真から、元の3次元形状を完璧に復元できないのと同じです。これが「情報が不可逆的に失われた」状態であり、逆行列が存在しない理由です。
この劇的な情報の損失を、具体的な計算で見てみましょう。
\(A = \begin{pmatrix} 1 & 1 \\ 1 & 1 \end{pmatrix}\) という行列の行列式は \(1 \times 1 – 1 \times 1 = 0\) です。この変換を、異なる2点 \( \boldsymbol{u} = \begin{pmatrix} 1 \\ 3 \end{pmatrix} \) と \( \boldsymbol{v} = \begin{pmatrix} 2 \\ 2 \end{pmatrix} \) に適用すると、
\[ A\boldsymbol{u} = \begin{pmatrix} 4 \\ 4 \end{pmatrix} \quad \text{そして} \quad A\boldsymbol{v} = \begin{pmatrix} 4 \\ 4 \end{pmatrix} \]
全く異なる2つの点が、\(y=x\) 直線上の \( (4,4) \) というたった一つの点に合流してしまいました。観測結果が \( (4,4) \) であったとき、元が \( \boldsymbol{u} \) だったのか \( \boldsymbol{v} \) だったのか、もう誰にもわかりません。
なぜ「情報の消失」が医療AIで致命的なのか?
ここまでの話は、一見すると抽象的な数学の世界に思えるかもしれません。
しかし、この「行列式が0になる(=情報が失われる)」という現象は、医療AIにおいては単なる数値上の問題ではなく、患者を見誤る致命的な欠陥につながります。
AIが医療データを学習する際、患者ごとに異なる特徴——年齢、性別、血圧、血糖値、肝機能、遺伝情報、画像上の所見など——を「次元(情報の軸)」として扱います。
これらの軸は、患者を区別し、診断や治療方針を個別化するための“座標軸”のような役割を果たしています。
ところが、モデル内部で行列式が0になるということは、
これらの複数の軸のうちいくつかが同じ方向を向いて重なってしまう(=独立性を失う)ことを意味します。
その結果、AIは異なる患者を数学的に同一視してしまうのです。
たとえば、
- 血糖値が高いが筋肉量が多く健康なアスリート
- 同じ血糖値だがインスリン抵抗性を持つ糖尿病予備群
本来はまったく異なる2人のプロファイルが、AIの内部では同じ座標上の一点に潰れてしまうことがあります。
これは、2次元の「面」が1本の「線」に押しつぶされるのと同じで、
「違いを表す情報の次元」が消えてしまった状態です。
こうしてAIは、「違い」を感じ取る力を失い、
- 病態を正しく区別できない
- 個別化治療の根拠を見誤る
- 診断や予測に一貫した精度が出ない
といった重大な誤作動を引き起こします。
つまり、情報の消失とは、AIが患者の“個性”を見失うことなのです。
それは、逆行列を持たない行列と同じく、一度失われたら二度と取り戻せない不可逆の損失なのです。
現場で起こりうること:「多重共線性」という罠
この問題は、特に多重共線性(multicollinearity)として知られる統計的な罠と深く関連しています。
例えば、ある疾患の予後を予測するために、「バイオマーカーA」と「バイオマーカーB」の2つの検査値を使ったとします。しかし、もしこの2つのマーカーが極めて強く相関していて、Aが上がればBもほぼ同じように上がる、という関係にあったらどうでしょう。
この2つの変数は、実質的に同じ情報しか持っていません。片方があれば、もう片方は不要なくらいです。このような冗長なデータを使ってAIモデルを構築すると、モデル内部の変換行列は「次元が潰れた」状態に近づき、行列式は限りなく0に近づきます。
その結果、モデルは極めて不安定になります。ほんのわずかな測定誤差やノイズによって、「Aを重視すべきか、Bを重視すべきか」の判断が大きく揺らぎ、昨日と今日で全く異なる予測結果を出してしまう、といった信頼性のないAIになってしまうのです。これは、Steward (1987) の研究などでも指摘されているように、回帰分析の係数が不安定になる古典的な問題です。
このように、行列式は単なる数学的な計算ではありません。それは、AIモデルがデータの情報を健全に扱えているか、その信頼性を評価するための「バイタルサイン」のようなものなのです。行列式の値が0に近づくことは、モデルが情報の「心停止」を起こしかけている危険な兆候と言えるでしょう。
臨床応用:CT・MRI画像再構成の舞台裏
この考え方は、CTやMRIの画像再構成の原理そのものです。臨床で目にする鮮明な断層画像は、まさにこの逆行列の計算によって生み出されています。
プロセスを分解すると、次のようになります。
- 私たちが知りたいもの (\(\boldsymbol{x}\)): 患者さんの体内の各部位(ピクセル/ボクセル)のX線吸収率。これが、最終的に画像になる未知のベクトルです。
- 私たちが測定できるもの (\(\boldsymbol{b}\)): CT検出器が受け取ったX線の強度。これは既知の測定結果ベクトルです。
- 物理法則と装置の仕様 (\(A\)): どの角度からX線を照射すれば、体内のどのピクセルを通り、検出器のどこに届くか、という物理的・幾何学的関係。これは装置の仕様から決まる既知の巨大な行列です。
これらは、\(A\boldsymbol{x} = \boldsymbol{b}\) という一本の行列方程式で結ばれています。私たちの目的は、測定値 \(\boldsymbol{b}\) とシステム行列 \(A\) から、未知の画像 \(\boldsymbol{x}\) を復元することです。その解こそが、
\[ \boldsymbol{x} = A^{-1}\boldsymbol{b} \]
なのです。もし、スキャンの回転角度が不十分だったり、一部の検出器が故障していたりすると、行列 \(A\) に含まれる情報に重複や欠損が生じ、その行列式は0に近づきます。そうなると、安定した逆行列 \(A^{-1}\) を計算できず、結果としてアーチファクトの多い不鮮明な画像しか得られない、という事態に陥るのです。
このように逆行列と行列式は、AIや画像処理技術が「逆の問題」を解くための、根幹を支える極めて重要な概念なのです。
固有値と固有ベクトル:変換の「魂」を見つけ出す
行列がデータに作用すると、ほとんどのベクトルはその向きや大きさを変え、まるで嵐の中の木の葉のように流されていきます。しかし、どれほど複雑な変換の中にも、その嵐の中心にある「台風の目」のように、ほとんど動じない、あるいは向きを変えずにただ伸び縮みするだけの、特別なベクトルが存在します。
これこそが固有ベクトル (Eigenvector) であり、そのベクトルが変換によってどれだけ伸縮したかを示す倍率が固有値 (Eigenvalue) です。
一見すると抽象的なこの概念、実はAIが複雑なデータの中から「最も重要なパターン」や「システムの安定した状態」を見つけ出す上で、心臓部とも言える極めて重要な役割を果たします。例えるなら、無数の遺伝子データの中からがんの進行を最も強く特徴づけている変化のパターンを見つけ出したり、ある治療法が患者さんの体にどのような「主要な変化の軸」をもたらすのかを理解したりするための、強力な手がかりとなるのです。
アナロジー:変換という「嵐」の中の、揺るがぬ「羅針盤」
この固有ベクトルと固有値のイメージを掴むために、いくつかのアナロジーを考えてみましょう。
例えば、地球の自転を思い浮かべてください。これは地球という球体全体にかかる「回転」という変換です。この変換によって、東京やニューヨーク、ロンドンといった地表のほとんどの点は、円を描いてダイナミックに移動します。しかし、考えてみてください。その中でほとんど動かない点がありますよね。
そうです、北極点と南極点です。この2点を結ぶ「地軸」こそが、自転という回転変換における固有ベクトルなのです。この揺るがぬ軸があるからこそ、私たちは地球の複雑な回転運動を安定して記述できます。ちなみに、この場合の固有値は「1」です。これは、回転しても地球が伸び縮みしない、つまりベクトルの長さが変わらないことを意味しています。
もう一つ、川の流れを想像してみるのも良いかもしれません。川の中の水は、場所によって渦を巻いたり、ゆっくり流れたり、岸にぶつかって向きを変えたりと、実に複雑な動きをしています。しかし、川全体を大きく見渡せば、そこには最も勢いの強い「主流」とでも言うべき中心的な流れが存在するはずです。
その「主流」の方向こそが、この流れ(変換)における主要な固有ベクトルです。そのライン上にある水の粒子は、横にぶれることなく、ただその流れの方向に沿ってまっすぐ加速していきます。そして、その流れの「速さ」や「勢い」が固有値に相当します。固有値が大きければ大きいほど、その流れは速く、川全体の動きに与える影響力が強いことを示唆します。
このように固有ベクトルと固有値は、一見カオスに見える複雑な変換(流れ)の中に潜む、最もシンプルで本質的な「軸」や「方向性」、そしてその「重要度」を私たちに教えてくれる、強力な羅針盤のような存在なのです。
数式 \( A\boldsymbol{v} = \lambda\boldsymbol{v} \) の正体:変換の「DNA」を読み解く設計図
さて、この固有ベクトルと固有値の不思議な関係は、たった一本の、しかし非常に奥深い数式によって表現されます。線形代数の世界における、いわば「憲法」のような存在です。
\[ A\boldsymbol{v} = \lambda\boldsymbol{v} \]
一見するとシンプルですが、この式の左辺と右辺には、全く質の異なる世界が広がっています。この式の本当の意味を理解するために、登場人物を一人ずつ、じっくりと見ていきましょう。
\(A\):変換行列(システムそのもの)
これは、私たちのデータが置かれる世界の「ルール」や「物理法則」を定める行列です。患者さんの1ヶ月後の状態変化、ある治療介入が引き起こす作用、空間そのものを歪ませる力——そういった複雑な「動詞」の役割を果たします。中にはたくさんの数字が詰まっていて、ベクトルがこの中を通ると、各成分が複雑に混ぜ合わされ、通常は全く新しいベクトルに姿を変えます。
\(\boldsymbol{v}\):固有ベクトル(システムの「魂」)
この物語の特別な「主人公」です。無数にあるベクトルの中で唯一、行列 \(A\) という変換を受けても向きを変えない、特別なベクトルです。変換の嵐の中でも、その方向性だけは決してぶれない、システムの「魂」や「骨格」とも言える存在です。(ただし、ゼロベクトルは除きます。なぜなら、ゼロは何を掛けてもゼロのままで、向きという概念自体がなく、あまりに自明すぎて何の洞察も与えてくれないからです。)
\(\lambda\):固有値(魂の「運命」を示す倍率)
これは、固有ベクトル (\(\boldsymbol{v}\)) の「運命」を決める、ただの数値(スカラー)です。固有ベクトル (\(\boldsymbol{v}\)) が変換の軸としてどれだけ重要か、その影響力の大きさを示します。変換によって (\(\boldsymbol{v}\)) がどれだけ伸びるか(\(\lambda > 1\))、縮むか(\(0 < \lambda < 1\))、あるいは反転するか(\(\lambda < 0\))を示す、運命の「倍率」です。
この式の本当のすごさは、左辺と右辺を比較することで見えてきます。
左辺: \(A\boldsymbol{v}\) は、「複雑な行列計算の世界」を表しています。
ベクトル (\(\boldsymbol{v}\)) が、行列 \(A\) というブラックボックスのような変換器に投入され、その内部の複雑なレシピに従って、各要素が足されたり引かれたり、掛け合わされたりするプロセスです。出力がどうなるかは、一見すると予測がつきません。
右辺: \(\lambda\boldsymbol{v}\) は、「驚くほど単純なスカラー倍の世界」です。
元のベクトル (\(\boldsymbol{v}\)) の向きはそのままに、ただ長さだけを (\(\lambda\)) 倍に調整するという、小学校で習うようなシンプルな掛け算です。
そして、この全く異なる2つの計算世界を、「=(イコール)」 が結びつけているのです。
この式が私たちに告げているのは、こういうことです。
「行列 \(A\) が行う複雑で予測不能に見える変換も、その“魂”である固有ベクトル (\(\boldsymbol{v}\)) に対してだけは、その作用が『単純に長さを (\(\lambda\)) 倍にする』という、非常にシンプルなものに還元されるのだ」
これは、複雑なシステムの本質を見抜くための、まさに「魔法の杖」です。
例えば、ある疾患の進行モデル(行列 \(A\))があったとして、その固有ベクトル(特定の悪化パターン \(\boldsymbol{v}\))を見つけ出すことができれば、そのパターンが将来どれくらいの勢いで進行するのか(固有値 \(\lambda\))、複雑なシミュレーションをせずとも、一瞬で理解できるのです。(以下で、詳しく見てみます)
この式は、複雑な現象の裏に隠された、最もシンプルで本質的な「軸」とその「勢い」を暴き出すための、強力な設計図と言えるでしょう。
具体的な変換で見てみよう:空間の「骨格」を探す旅
言葉だけでは、なかなかイメージが湧きにくいかもしれませんね。ここで、とてもシンプルな行列を使って、固有ベクトルと固有値が実際にどのように現れるのか、その姿を一緒に見ていきましょう。
ここに、「y軸方向はそのままに、x軸(水平)方向だけを2倍に引き伸ばす」という、とても単純な変換を行う行列 A があるとします。
\[ A = \begin{pmatrix} 2 & 0 \\ 0 & 1 \end{pmatrix} \]
この行列 A という「変換装置」に、いくつかのベクトルを通してみると、それぞれがどんな運命をたどるのか、観察してみましょう。
ケース1:嵐に流される、ごく普通のベクトル
まず、ごく普通のベクトルとして、右上45度を指す \(\boldsymbol{u} = \begin{pmatrix} 1 \\ 1 \end{pmatrix}\) を考えてみます。
このベクトル u に行列 A を作用させてみましょう。計算は「行列の行」と「ベクトルの列」をペアにして行います。
\[ A\boldsymbol{u} = \begin{pmatrix} 2 & 0 \\ 0 & 1 \end{pmatrix} \begin{pmatrix} 1 \\ 1 \end{pmatrix} = \begin{pmatrix} 2 \\ 1 \end{pmatrix} \]
結果を見てください。元のベクトル \(\boldsymbol{u}\) は (1, 1) で真の右上を指していましたが、変換後は (2, 1) となり、x方向に伸びたことで、より水平に近い、なだらかな角度になりました。

このように、向きが変わってしまいました。これは、変換の嵐に流されるごく普通のベクトルであり、固有ベクトルではありません。
ケース2:変換の「軸」となる、特別なベクトルたち
では、次に特別なベクトルを試してみましょう。
特別なベクトル①:x軸そのもの
今度は、x軸の方向をまっすぐ向いたベクトル \(\boldsymbol{v_1} = \begin{pmatrix} 1 \\ 0 \end{pmatrix}\) です。
\[ A\boldsymbol{v_1} = \begin{pmatrix} 2 & 0 \\ 0 & 1 \end{pmatrix} \begin{pmatrix} 1 \\ 0 \end{pmatrix} = \begin{pmatrix} (2 \times 1) + (0 \times 0) \\ (0 \times 1) + (1 \times 0) \end{pmatrix} = \begin{pmatrix} 2 \\ 0 \end{pmatrix} \]
驚くべきことに、変換後のベクトルは \(\begin{pmatrix} 2 \\ 0 \end{pmatrix}\) となり、元のベクトル \(\begin{pmatrix} 1 \\ 0 \end{pmatrix}\) と全く同じ方向を向いています!
ただ、長さだけがちょうど2倍になりました。

これは、まさに \( A\boldsymbol{v_1} = 2\boldsymbol{v_1} \) という関係そのものです。このとき、私たちはこう結論づけます。
- 固有ベクトル: \(\boldsymbol{v_1} = \begin{pmatrix} 1 \\ 0 \end{pmatrix}\) (x軸の方向)
- 固有値: \(\lambda_1 = 2\) (その方向への伸縮率)
特別なベクトル②:y軸そのもの
もう一つ、y軸の方向をまっすぐ向いたベクトル \(\boldsymbol{v_2} = \begin{pmatrix} 0 \\ 1 \end{pmatrix}\) も試してみましょう。
\[ A\boldsymbol{v_2} = \begin{pmatrix} 2 & 0 \\ 0 & 1 \end{pmatrix} \begin{pmatrix} 0 \\ 1 \end{pmatrix} = \begin{pmatrix} (2 \times 0) + (0 \times 1) \\ (0 \times 0) + (1 \times 1) \end{pmatrix} = \begin{pmatrix} 0 \\ 1 \end{pmatrix} \]
こちらも、変換の前後で向きが全く変わりませんでした。そして、長さは1倍(つまり変化なし)です。これもまた、この変換のもう一つの「不動の軸」、固有ベクトルなのです。
- 固有ベクトル: \(\boldsymbol{v_2} = \begin{pmatrix} 0 \\ 1 \end{pmatrix}\) (y軸の方向)
- 固有値: \(\lambda_2 = 1\) (その方向への伸縮率)
このシンプルな例からわかるように、行列 A が行う「水平方向に2倍引き伸ばす」という変換の本質は、2つの固有ベクトル(x軸とy軸)と、それに対応する2つの固有値(2と1)によって、完全に説明できます。
固有ベクトルはこの変換の「骨格」や「DNA」のようなものであり、その骨格がそれぞれどのように伸縮するか(固有値)が分かれば、その変換が空間全体に何をするのか、その設計図を読み解くことができるのです。
医療における固有値・固有ベクトルの意味:病態の「本質」を読み解く
さて、この一見すると抽象的な数学の概念が、日々の臨床や医療研究の現場で、一体どのように役立つというのでしょうか? 実は、この固有値と固有ベクトルこそが、複雑な生命現象の裏に隠された「本質的なパターン」を読み解くための、非常に強力な鍵となります。生命現象を相互作用する要素からなる動的なシステムとして捉えるシステム生物学の考え方では、このような数学的アプローチが中心的な役割を果たします (Kitano, 2002)。
シナリオ:慢性疾患の進行を予測する
例えば、関節リウマチや慢性心不全のような、長期的な管理が必要な疾患の進行をモデル化するケースを考えてみましょう。
患者さんの現在の状態は、単一の指標では表現できません。「炎症の強さ(例:CRP値)」と「関節や心筋の組織ダメージ(例:画像所見スコア)」など、複数の指標が絡み合って決まります。ここでは、この2つの指標で患者さんの状態をベクトルとして表現してみましょう。
\[ \text{現在の患者の状態} = \begin{pmatrix} \text{炎症レベル} \\ \text{組織ダメージ} \end{pmatrix} \]
そして、過去の膨大な患者データを分析することで、現在の状態から「1ヶ月後の状態」を予測する行列 \(A\) を構築できたとします。これは、この疾患が持つ平均的な振る舞いを表す「状態遷移行列」と呼ばれるものです。このような状態遷移モデルは、慢性疾患の長期的な経過をシミュレーションするための標準的なアプローチとして確立されており、その構築と評価に関するベストプラクティスもISPOR-SMDMタスクフォースによって提言されています (Siebert et al., 2012)。
\[ \begin{pmatrix} \text{来月の炎症レベル} \\ \text{来月の組織ダメージ} \end{pmatrix} = \underbrace{ \begin{pmatrix} a & b \\ c & d \end{pmatrix} }_{A: \text{疾患の進行ルール}} \begin{pmatrix} \text{今月の炎症レベル} \\ \text{今月の組織ダメージ} \end{pmatrix} \]
もちろん、実際の生命現象はより複雑な非線形性を含みますが、この線形モデルはシステムの基本的な振る舞いを理解するための強力な第一歩となります。この行列 \(A\) の固有値と固有ベクトルを解析することで、この疾患が持つ「隠れた本質」が、驚くほどクリアに見えてくるのです。
固有ベクトルが暴く「疾患の進行パターン(モード)」
行列 \(A\) の固有ベクトルを計算すると、それはこの疾患がたどる可能性のある、いくつかの「主要な進行パターン(モード)」を指し示してくれます。これは、多数の変数の中からデータの変動を最もよく説明する「パターン」を抽出する考え方であり、主成分分析(PCA)などの多変量解析手法の根幹をなすものです (Ringnér, 2008)。
例えば、計算によって2つの主要な固有ベクトルが見つかったとしましょう。
固有ベクトル①: \(\boldsymbol{v_1} = \begin{pmatrix} 0.9 \\ 0.1 \end{pmatrix}\) ⟵ 「炎症主体・増悪モード」
このベクトルが示すのは、「炎症レベルが9割、組織ダメージが1割」という構成比のパターンです。つまり、組織ダメージよりも炎症が急激に悪化することを特徴とする、臨床症状が出やすい進行パターンだと解釈できます。
固有ベクトル②: \(\boldsymbol{v_2} = \begin{pmatrix} 0.2 \\ 0.8 \end{pmatrix}\) ⟵ 「ダメージ蓄積・潜行モード」
こちらは対照的に、「炎症レベルが2割、組織ダメージが8割」というパターンです。これは、臨床症状(炎症)は比較的穏やかでも、水面下で関節や心筋の不可逆的なダメージが静かに進行していく、見過ごされやすい危険なパターンを示唆しています。
固有値が示す「進行パターンの“勢い”」
では、これらの進行パターンは、それぞれどれくらいの「勢い」を持っているのでしょうか?その答えを教えてくれるのが、各固有ベクトルに対応する固有値です。力学系の理論では、固有値はシステムの安定性を決定づける重要な指標となります (Strogatz, 2015)。
固有値①: \(\lambda_1 = 1.3\) (\(\boldsymbol{v_1}\) に対応)
固有値の絶対値が1より大きい 1.3 であることは、この「炎症主体モード」が、1ヶ月ごとに1.3倍の勢いで指数関数的に悪化していくことを意味します。これは放置すれば急速に状態が悪化する、非常に危険な「増悪モード」(不安定な状態)です。
固有値②: \(\lambda_2 = 1.05\) (\(\boldsymbol{v_2}\) に対応)
こちらも固有値の絶対値は1より大きいですが、1.05 と比較 Küçük bir値です。これは「ダメージ蓄積モード」が、1ヶ月あたり1.05倍と、よりゆっくりではあるが、しかし着実に悪化していくことを示しています。
もし、ある治療法によって、この危険な固有値 \(\lambda_1\) の絶対値を 1.3 から 0.8 (1未満)に下げることができればどうでしょう?それは、その治療が「急速増悪モード」を時間とともに収束する「寛解モード」(安定な状態)へと転換させる力を持つことを数学的に意味するのです。
臨床応用:個別化医療への道筋
この固有値と固有ベクトルを用いた解析は、単なる机上の計算に留まりません。実際の患者さん一人ひとりの状態を、これらの「基本モード」の組み合わせとして表現し直すことで、個別化医療への道が拓けます。
では、具体的にどうやって、ある患者さんの状態を、例えば、「危険な増悪モードの成分が70%、潜行性のダメージモードの成分が30%」といった形に分解できるのでしょうか?
そのプロセスは、一言で言えば「座標変換」です。つまり、私たちが普段使っている「ものさし」を、病態の本質をより深く理解できる「特別なものさし」に持ち替える作業に他なりません。
患者の状態を「特別なものさし」で測り直す
まず、ある患者さんの状態が「炎症レベル: 10, 組織ダメージ: 3」だったとします。これは、私たちが普段使う座標軸(ものさし)で測った値です。
\[ \text{患者の状態ベクトル } \boldsymbol{p} = \begin{pmatrix} 10 \\ 3 \end{pmatrix} \]
一方、私たちは固有値分析によって、この疾患の本質を表す2つの「特別なものさし(固有ベクトル)」を手に入れました。
- \(\boldsymbol{v_1}\): 「炎症主体・増悪モード」の方向を指すものさし
- \(\boldsymbol{v_2}\): 「ダメージ蓄積・潜行モード」の方向を指すものさし
ここで行うのは、「患者ベクトル \(\boldsymbol{p}\) の位置を、この2つの“特別なものさし”で測り直したら、それぞれの目盛りはいくつになるか?」を計算することです。患者さんの状態を、これらの基本モードがどれくらい混ざり合ってできているのか、その構成比を明らかにするのです。
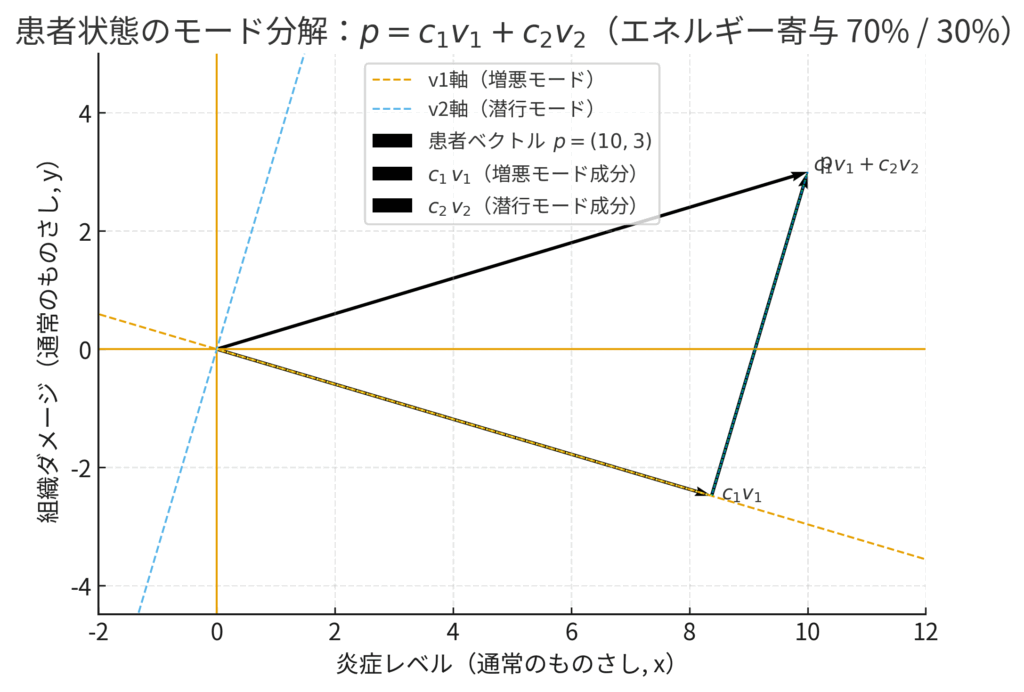
この新しい座標値、つまり各モードの「強さ」を表す係数 \(c_1\) と \(c_2\) を求める計算は、射影という考え方と内積という計算道具を使うことで実行できます。難しい数学に聞こえるかもしれませんが、やっていることは「ある方向の成分をどれだけ含んでいるかを抽出する」というシンプルな操作です。
この計算によって、私たちは患者さんの状態を「増悪モードの強さが \(c_1\)」「潜行モードの強さが \(c_2\)」という、臨床的により意味のある新しい指標で捉え直すことができるのです。
データに基づいた戦略立案へ
この分解がなぜこれほど強力かというと、元の「炎症レベル: 10」といった単一の指標よりも、「増悪モードの強さ: \(c_1\)、潜行モードの強さ: \(c_2\)」という新しい指標セットの方が、予後予測や治療方針の決定において、はるかに示唆に富んでいるからです。
例えば、先ほどの計算で、ある患者さんの状態が「危険な増悪モード \(\boldsymbol{v_1}\) の成分が非常に強く、潜行性のダメージモード \(\boldsymbol{v_2}\) の成分は弱い」と分解できたとしましょう。
この情報と、増悪モードに対応する固有値 \(\lambda_1\) が1を大きく超える危険な値(例: 1.3)であったことを組み合わせれば、「この方は今、急速に悪化するリスクが非常に高い。直ちにこの増悪モードを標的とする抗炎症作用の強い治療を開始すべきだ」という、データに基づいた戦略を立てることができます。
このように、固有値・固有ベクトルを調べることは、複雑な病態の中から「本当に注目すべき危険なパターン」や「治療介入によって抑制すべき主要な動き」を数学的に抽出し、患者さんの層別化や治療方針の決定を支援する、極めて強力なアプローチなのです。
そしてこの「座標変換によってデータの本質を捉える」という考え方こそが、次にお話しする、高次元データを要約するための最強のツールの一つ、主成分分析(PCA)の根幹をなしています。
Deep Dive! 特異値分解(SVD):あらゆる行列を分解する究極のツール
さて、固有値分解という、変換の「魂」を見つけ出す強力な道具を手にしました。しかし、この道具には一つ、重大な制約があります。それは、正方行列(入力と出力の次元数が同じ変換)に対してしか使えない、という点です。
臨床現場や研究で扱う現実のデータに目を向けてみましょう。例えば、「100人の患者さん(行)× 2万種類の遺伝子(列)」のデータや、「512×512ピクセルの画像データ(行)× 100枚のスライス(列)」など、そのほとんどは長方形行列です。
では、入力と出力の次元が異なる、このような長方形行列に対して、固有値分解のようにその変換の「本質的な軸」や「重要な要素」を見つけ出すことはできないのでしょうか?
この問いに対する答えこそが、線形代数における最も強力で美しい定理の一つ、特異値分解(Singular Value Decomposition, SVD)です。
SVDの正体:直交変換・伸縮・直交変換への分解
SVDが主張することは、驚くほど普遍的です。それは、
「どんな複雑な行列(線形変換)であっても、それは『直交変換(回転や反転)』→『伸縮』→『別の直交変換(回転や反転)』という、3つの非常にシンプルな基本操作の組み合わせに分解できる」
ということです。この普遍的な性質は、多くの標準的な教科書で詳細に解説されています (Trefethen and Bau, 1997)。数式で表現すると、任意の行列 \(A\) は、以下の3つの行列の積に分解できます。
\[ A = U\Sigma V^{\top} \]
この設計図の登場人物を見ていきましょう。
\(V^{\top}\) (最初の直交変換):
これは、入力データの世界(例:遺伝子の特徴空間)における「最適な座標軸」を見つけ出し、データをその軸に沿って整列させる直交変換です。この新しい座標軸のセットを右特異ベクトルと呼びます。
\(\Sigma\) (伸縮):
これは、新しい座標軸に沿って、データをどれだけ引き伸ばすか(あるいは押しつぶすか)を決める「伸縮」操作です。この行列は対角成分に特異値(\(\sigma_1, \sigma_2, \dots\))が降順(\(\sigma_1 \ge \sigma_2 \ge \dots \ge 0\))に並んでおり、それ以外の成分はすべて0です。この特異値こそが、各軸方向の「重要度」や「影響力の大きさ」を示します。
\(U\) (最後の直交変換):
伸縮されたデータを、今度は出力の世界(例:患者サンプルの空間)における「最適な座標軸」に配置し直す、もう一つの直交変換です。この出力空間の座標軸のセットを左特異ベクトルと呼びます。
この一連の操作は、入力データを最適な軸で捉え(\(V^{\top}\))、その軸の重要度に応じて情報を伸縮させ(\(\Sigma\))、結果を最適な形で表現する(\(U\))、という流れとして直感的に理解できます。
臨床応用:ノイズ除去からPCAとの関係まで
このSVDの威力は、理論上の美しさに留まりません。
低ランク近似とノイズ除去:
特異値は、その変換の「重要度」を反映していました。もし、小さな特異値がノイズに対応していると考えるなら、それらの値をゼロにしてしまうことで、データの本質的な構造を保ったまま、ノイズだけを綺麗に取り除くことができます。これは医用画像でも応用されており、とくに拡散MRIでは、ランダム行列理論に基づくMarchenko–Pastur PCA(MPPCA)により、ノイズ成分に対応する主成分をデータ駆動で識別・除去できることが示されています (Veraart et al., 2016)。その理論的基盤としては、高次元におけるサンプル固有値の挙動解析が広く参照されます (Nadakuditi and Edelman, 2008)。
主成分分析(PCA)との深いつながり:
そして、ここが最も重要な点です。次にお話しする主成分分析(PCA)は、実はSVDの応用そのものなのです。
データ行列の共分散行列に対して固有値分解を行うことは、元のデータ行列(から平均を引いたもの)に対してSVDを行うことと、数学的に等価であることが知られています (Wall et al., 2003; Jolliffe, 2002)。
上記のように、PCAが求める3つの主要な要素(軸、新座標、分散)は、SVDによって得られる行列(\(V, U\Sigma, \Sigma\))と直接対応します。
実際のデータ解析の現場では、巨大な共分散行列を計算する際の数値誤差や計算コストを避けるため、固有値分解ではなくSVDを用いてPCAを計算するのが一般的です。遺伝子発現データへのSVDの古典的応用としては、Alterら (2000) の研究が広く知られています。一方で、Golubら (1999) の研究は、DNAマイクロアレイによるがん分類の実証を行った代表的な研究として金字塔的な存在です(主手法はSOM・重み付き投票等)。
SVDは、固有値分解を一般の長方形行列へと拡張し、あらゆるデータ変換の根幹にある「直交変換・伸縮・直交変換」という普遍的な構造を暴き出す、まさに究極の分解ツールなのです。この強力な視点を持って、いよいよPCAの世界へ進んでいきましょう。
主成分分析(PCA):複雑なデータに「最高の視点」を与える
さて、いよいよこれまでの線形代数の知識——行列、固有値、そして特異値分解——が結集する、非常に強力な分析手法、主成分分析(Principal Component Analysis, PCA)の登場です。これは、AIやデータサイエンスの世界で「まず試してみるべき手法」の代表格であり、その考え方は多くの応用技術の基礎となっています。
PCAの目的は、一見すると非常にシンプルです。それは、「情報の損失を最小限に抑えながら、高次元のデータを低次元に要約すること」。つまり、複雑すぎるデータを、その本質を保ったまま、人間が理解できるシンプルな形に「翻訳」してくれる、魔法のような道具なのです。
直面する課題:情報の洪水と「次元の呪い」
まずは、なぜPCAが必要なのか、その背景にある臨床現場の切実な課題を考えてみましょう。
想像してみてください。あなたは、あるがん患者さんたち100人から、腫瘍組織の遺伝子発現量データを取得したとします。技術の進歩により、一度に2万種類もの遺伝子の活動レベルを測定できました。これはつまり、2万次元という、もはや人間の脳では想像すらできない超多次元空間に、患者さん一人ひとりがデータ点として浮かんでいる状態です。
このままでは、情報の洪水に溺れてしまいます。
「どの遺伝子の組み合わせが、このがんの悪性度を真に特徴づけているのか?」
「A群の患者とB群の患者を分ける、本質的な生物学的特徴は何か?」
2万もの変数を同時に見ながらこれらの問いに答えるのは、ほぼ不可能です。変数があまりに多いと、統計モデルはデータの本質的なパターンではなく、偶然のノイズにまで過剰に適合してしまい(過学習)、未知のデータに対する予測性能が著しく低下します。これが、データサイエンスの世界で恐れられる「次元の呪い」の一つの側面です (Bishop, 2006)。
PCAの核心的アイデア:「最高の視点」を探す
この情報の洪水の中から意味のあるパターンを救い出すために、PCAは非常に賢いアプローチを取ります。それは「データを最もよく見渡せる角度(視点)を探す」ことです。
例えるなら、あなたは夜空に浮かぶ、葉巻型に広がった無数の星々(データ点)の集まりを観察している天文学者だとします。
悪い視点: 葉巻型の星雲を「先端」から見つめると、星々はほぼ円形に重なって見え、その奥行きや細長い形状といった本質的な広がりが全く分かりません。これでは、得られる情報はごく僅かです。
最高の視点: 葉巻型の星雲を「真横」から眺めると、その細長い全体像がはっきりと捉えられ、星々がどの方向に最も広がっている(分散している)かが一目で理解できます。
PCAがやっていることは、まさにこの「最高の視点」を数学的に見つけ出す作業なのです。データ全体が最も大きくばらついている方向、つまり分散が最大となる方向を探し出し、それを新しい「ものさし(軸)」として定義します。なぜなら、データのばらつき(分散)こそが「情報」の源泉であり、分散が最も大きい方向は、データの個性の違いを最もよく表現している方向だからです。
PCAの舞台裏:固有ベクトルとの再会
では、どうやって「最高の視点」を見つけ出すのでしょうか?ここで、先ほど学んだ固有値と固有ベクトルが、再び主役として登場します。
PCAのアルゴリズムは、以下のステップで進められます。
データの前処理(中心化)
分析を始める前に、非常に重要な下準備があります。それは、各変数(遺伝子)の平均値が0になるように、すべてのデータを平行移動させる「中心化」です。これにより、データのばらつき具合を純粋に評価できるようになります。
共分散行列の計算
次に、データが持つ変数(遺伝子)同士の関係性をぎゅっと凝縮した「共分散行列」という正方行列を作成します。この行列の各要素は、「遺伝子Aの発現量が増えたとき、遺伝子Bの発現量も増えるか(正の共分散)、減るか(負の共分散)、あるいは無関係か(共分散が0に近い)」といった、変数間の関係性を示しています。
固有値分解(またはSVD)の実行
ここがクライマックスです。この共分散行列の固有値と固有ベクトルを計算します。(前章の「Deep Dive! 特異値分解(SVD):あらゆる行列を分解する究極のツール」で学んだように、実際には数値計算の安定性から、中心化したデータ行列に直接SVDを適用するのが一般的です。)
- 固有ベクトル: 計算された固有ベクトルの方向こそが、データの分散が最大になる方向、つまり「最高の視点」を指し示しています。
- 固有値: 対応する固有値は、その固有ベクトルの方向にデータがどれだけばらついているか、つまり「その視点の重要度(説明する情報量)」を表しています。
主成分の決定
固有値が最も大きい固有ベクトルを第1主成分(Principal Component 1, \(PC1\))と名付けます。これが、データ全体の情報を最もよく要約する「最強の軸」です。次に、\(PC1\)とは直交する(全く相関がない)方向の中で2番目に分散が大きい方向(2番目に大きい固有値を持つ固有ベクトル)を第2主成分(\(PC2\))とします。これを繰り返すことで、\(PC3\), \(PC4\), …と、互いに無相関な新しい「軸」のセットを見つけ出していきます。
重要なのは、これらの主成分が単一の遺伝子ではないということです。一つの主成分は、例えば「(0.1 × 遺伝子A) – (0.05 × 遺伝子B) + …」のように、元の全遺伝子の情報を重み付けして合成された、全く新しい人工的な指標(軸)なのです。この重み(係数)を見ることで、その主成分がどのような生物学的な意味を持つのかを解釈することができます。
臨床応用:2万次元のデータを2次元の「意味ある地図」へ
このPCAの威力は、実際の医療データ解析でいかんなく発揮されます。
先ほどの2万次元の遺伝子データも、PCAを使えば、その情報の大部分を保持したまま、第1主成分(\(PC1\))と第2主成分(\(PC2\))という、たった2つの軸で表現できるかもしれません。
そうなれば、全ての患者さんのデータを、見慣れた2次元の散布図にプロットして、「意味のある地図」として可視化できます。
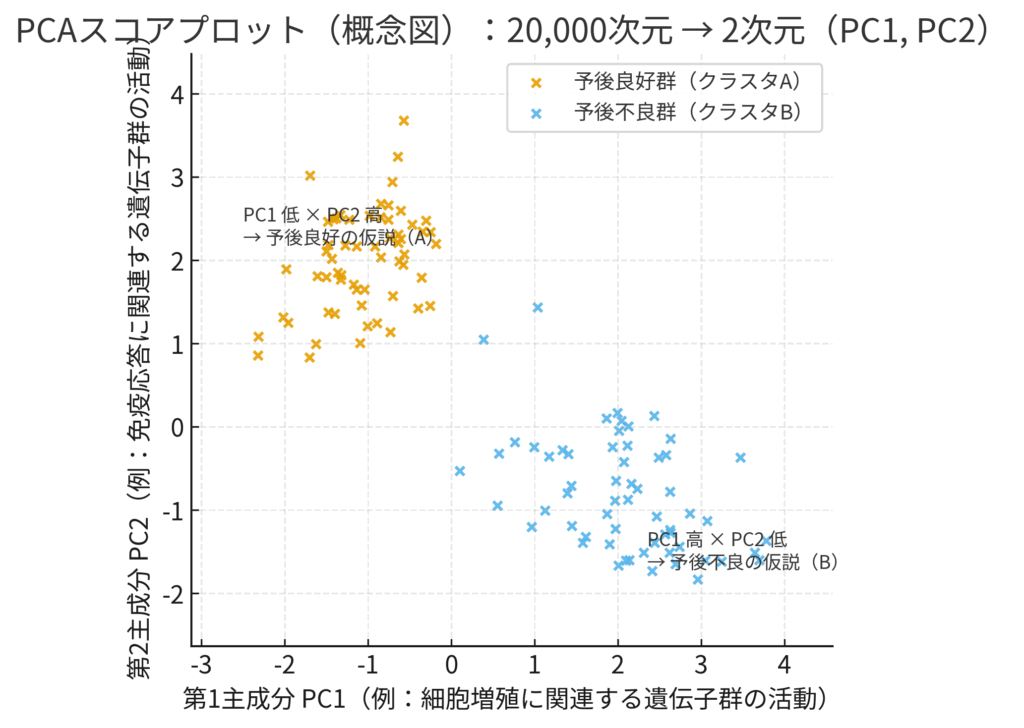
図:PCAによって2次元に次元削減された患者データの散布図(スコアプロット)の概念図。
すると、上図のように、それまでノイズの海に埋もれて見えなかった患者さんのクラスター(集団)が、くっきりと浮かび上がってくることがあります。さらに、各主成分軸の「重み」を詳しく調べることで、例えば「\(PC1\)は細胞増殖関連の遺伝子群のスコアを、\(PC2\)は免疫応答関連の遺伝子群のスコアを強く反映している」といった生物学的な解釈が可能になります。
この地図から、私たちは「細胞増殖が活発(\(PC1\)の値が大きい)で、かつ免疫応答が弱い(\(PC2\)の値が小さい)患者群(クラスタB)は、予後が悪い傾向にあるのではないか」といった、臨床的に極めて重要な仮説を発見できるのです。
このようにPCAは、人間が直感的に理解できない高次元空間に潜むデータの「本質的な構造」を暴き出し、可視化してくれる、強力な「望遠鏡」なのです。PCAは、ゲノム解析だけでなく、多岐にわたる臨床指標から疾患のサブタイプを発見したり、バイオマーカーを探索したりと、現代の医療AI研究において不可欠な基盤技術となっています (Jolliffe and Cadima, 2016)。
まとめ:変換の数学は、AIがデータを理解するための言語
今回は、AIが複雑な医療データをどのように「見て」「理解」しているのか、その根幹をなす「変換」の数学というパワフルな言語体系を一緒に旅してきました。最後に、今回の冒険で手に入れた知識を振り返ってみましょう。
旅の始まりは、データを操作するための基本的な「文法」である行列演算でした。ここから、一度行った操作を元に戻せるかを教えてくれる逆行列と、その可否を判定する行列式というルールを学びました。これは、変換における情報の可逆性を見極めるための重要な羅針盤でしたね。
そして、この言語の最も詩的で本質的な部分、固有値と固有ベクトルへと進みました。これらは、どんなに複雑な変換の中にも存在する、決してぶれることのない「不動の軸」や「システムの魂」を明らかにしてくれる概念でした。
最終的に、これらの文法と単語を総動員して、一つの長文、すなわち「データが語る物語」を読み解く応用技術、主成分分析(PCA)にたどり着きました。PCAは、情報の洪水を整理し、最も伝えたいメッセージ(主成分)だけを抽出してくれる、非常に雄弁な翻訳ツールでした。
これら一連の数学は、一見すると抽象的で、日々の臨床とは縁遠いものに感じられたかもしれません。しかし、これらこそが、AIが混沌とした医療データの中から秩序を見出し、人間が見落としてしまうような微細なパターンを捉え、診断の補助や治療法の最適化といった、臨床に直結する洞察(インサイト)を生み出すための、まさに「思考の言語」そのものなのです。
私たちは今回、AIがデータを「見る」ためのレンズを手に入れました。次回からは、AIがそのレンズを通して見たものから、どのように「学ぶ」のか、その驚くべきメカニズムを覗いていきましょう。
参考文献
- Alter, O., Brown, P.O. and Botstein, D. (2000). Singular value decomposition for genome-wide expression data processing and modeling. Proceedings of the National Academy of Sciences, 97(18), pp.10101–10106. https://doi.org/10.1073/pnas.97.18.10101
- Bishop, C.M. (2006). Pattern Recognition and Machine Learning. Springer. ISBN: 978-0387310732.
- Golub, T.R., Slonim, D.K., Tamayo, P., Huard, C., Gaasenbeek, M., Mesirov, J.P., Coller, H., Loh, M.L., Downing, J.R., Caligiuri, M.A., Bloomfield, C.D. and Lander, E.S. (1999). Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science, 286(5439), pp.531–537. https://doi.org/10.1126/science.286.5439.531
- Jolliffe, I.T. (2002). Principal Component Analysis. 2nd ed. Springer. https://doi.org/10.1007/b98835
- Jolliffe, I.T. and Cadima, J. (2016). Principal component analysis: a review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2065), p.20150202. https://doi.org/10.1098/rsta.2015.0202
- Kitano, H. (2002). Systems biology: a brief overview. Science, 295(5560), pp.1662–1664. https://doi.org/10.1126/science.1069492
- Nadakuditi, R.R. and Edelman, A. (2008). Sample eigenvalue based detection of high-dimensional signals in white noise using relatively few samples. IEEE Transactions on Signal Processing, 56(7), pp.2625–2638. https://doi.org/10.1109/TSP.2008.917356
- Ringnér, M. (2008). What is principal component analysis? — from a biologist’s point of view. Nature Biotechnology, 26(3), pp.303–304. https://doi.org/10.1038/nbt0308-303
- Siebert, U., Alagoz, O., Bayoumi, A.M., Jahn, B., Owens, D.K., Cohen, D.J. and Kuntz, K.M. (2012). State-transition modeling: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force–3. Value in Health, 15(6), pp.812–820. https://doi.org/10.1016/j.jval.2012.06.014
- Steward, G.W. (1987). Collinearity and cautions about interpretations of regression analysis. The American Statistician, 41(1), pp.1–4.
- Strogatz, S.H. (2015). Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering. 2nd ed. CRC Press. ISBN: 9780813349107.
- Sukkar, R., Katz, E., Zhang, Y., Raunig, D. and Wyman, B.T. (2012). Disease progression modeling using Hidden Markov Models. Annual International Conference of the IEEE Engineering in Medicine and Biology Society, 2012, pp.2845–2848. https://doi.org/10.1109/EMBC.2012.6346556
- Trefethen, L.N. and Bau, D., III. (1997). Numerical Linear Algebra. SIAM. https://doi.org/10.1137/1.9780898719574
- Veraart, J., Fieremans, E. and Novikov, D.S. (2016). Denoising of diffusion MRI using random matrix theory. Magnetic Resonance in Medicine, 76(5), pp.1582–1593. https://doi.org/10.1002/mrm.26059
- Wall, M.E., Rechtsteiner, A. and Rocha, L.M. (2003). Singular value decomposition and principal component analysis. In: Berrar, D.P., Dubitzky, W. and Granzow, M. (eds) A Practical Approach to Microarray Data Analysis. Springer, Boston, MA. pp.91–109. https://doi.org/10.1007/0-306-47815-3_5
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




