

従来のRNNは、長期的な情報の記憶が苦手でした。LSTMは「忘却・入力・出力」の3つのゲート機構と「セル状態」を導入し、どの情報を忘れ、何を追加し、何を出力するかを賢く制御することで、この問題を解決した画期的なモデルです。
従来のRNNは、時系列が長くなると過去の情報を忘れてしまう「長期依存性」の問題や、学習が不安定になる「勾配消失・爆発」の問題を抱えていました。
長期記憶用の「セル状態」と、忘却・入力・出力の3つのゲートを導入。これにより、どの情報を忘れ、何を追加し、何を出力するかを動的に制御し、長期記憶を可能にします。
電子カルテからの疾患予測、心電図や脳波などの生体信号解析、治療効果のモデリングなど、長期的な文脈が重要な医療データの解析で強力な性能を発揮します。
医療の世界でも、人工知能(AI)の力が大きな変化をもたらそうとしていますね。診断の精度を上げたり、一人ひとりに最適な治療法を見つけ出したり、新しい薬の開発を加速させたり…。まさに、これまで難しかった課題への新しい扉が開かれつつある、そんな期待感に満ちています。皆さんも、日々のニュースや論文でそういった可能性に触れる機会が増えているのではないでしょうか。
中でも、患者さんの日々のバイタルサインの変化や、治療経過に伴う検査値の動き、さらには連続的に記録される心電図や脳波といった「時間とともに変化するデータ」、いわゆる時系列データをどう読み解くかが、医療AIを次のステージに進めるための鍵と言えるでしょう。これらのデータには、病気の微細な兆候や治療効果の重要なヒントが、まるでパズルのピースのように隠されていることが多いですからね。それをうまく見つけ出すことができれば、より早期の介入や、より効果的な治療戦略に繋がるかもしれません。
このコースの前半、特に第15.2回から15.4回にかけては、こうした時系列データを扱うための基本的なAIモデルとして、再帰型ニューラルネットワーク(RNN)の仕組みを一緒に見てきました。過去の情報を記憶し、それを現在の判断材料にするというRNNのアイデアは、とても魅力的でしたよね。「前の情報が次の判断に影響する」という、私たちが自然に行っている思考プロセスに似ている点も、理解しやすかったかもしれません。しかし、実際に使ってみると、時系列が長くなればなるほど、例えば数週間前、数ヶ月前の重要な情報がだんだん薄れてしまったり、逆に直近の些細な情報に過度に引きずられてしまったりと、なかなか悩ましい課題も見えてきたのではないでしょうか。「うーん、もっとうまく過去の情報を扱えないものか…」と感じた方もいらっしゃるかもしれません。
そこで今回、第15.5回としてお届けするのが、RNNが抱えていたそうした「もどかしさ」を解消するために開発された、より進んだモデル、LSTM(Long Short-Term Memory:長短期記憶)です。私自身、最初にLSTMの「ゲート」という情報を選別する仕組みを知ったときは、「なるほど、こうやって情報を賢く取捨選択するのか!」と、そのアイデアの巧妙さにちょっと感動したものです。まるで、人間が重要な情報をメモに取り、不要になったら消し、必要な時に参照する、そんな作業をAIが自動で行ってくれるようなイメージでしょうか。
このセクションでは、まずLSTMがなぜ「長期」の情報を「短期」の記憶としてうまく保持できるのか、その理論的な背景を、数式も交えつつ、できるだけ直感的に理解できるようにお話しします。その後、実際にPythonのライブラリであるPyTorchを使って、皆さんの手でLSTMモデルを動かしながら実装する方法をステップバイステップで解説します。そして最後に、このLSTMが医療の現場でどんな風に役立つ可能性があるのか、具体的な応用例を通じてイメージを膨らませていきたいと思います。この記事を読み終える頃には、LSTMの基本的な考え方をしっかりと掴み、ご自身の研究テーマや日々の臨床の中で「もしかしたら、あのデータにLSTMを使ったら面白い結果が出るかも?」とアイデアが湧いてくる、そんな状態を目指しましょう。一緒に、LSTMの世界を探求していきましょう!
1. なぜLSTMが生まれたの? RNNが抱えていた、ちょっと悩ましい「記憶」の問題
さて、前回までの道のり(特に第15.2回から15.4回)で、私たちは時系列データ、つまり時間の流れとともに変化していくデータを扱うための強力な相棒として、再帰型ニューラルネットワーク(RNN)について学んできましたね。RNNは、まるで人間が過去の出来事を記憶し、それを今の行動に活かすように、過去の情報を「隠れ状態」という形で保持し、次の瞬間の予測に役立てようとする、とても直感的で賢い仕組みを持っていました。
例えば、患者さんの日々の血圧の推移をRNNに入力すれば、次の日の血圧を予測してくれるかもしれない。あるいは、心電図の波形を読み込ませれば、異常なパターンを見つけ出してくれるかもしれない…。そんな期待を抱かせてくれるモデルでしたよね。私自身、初めてRNNの概念に触れたとき、「これは時系列データ解析のゲームチェンジャーになるかもしれない!」とワクワクしたものです。
しかし、実際にRNNを使ってみると、特に扱う時系列が長くなればなるほど、いくつかの悩ましい問題点も見えてきました。まるで、たくさんのことを記憶しようとしても、昔のことはだんだん思い出せなくなったり、逆に最近の些細な出来事にばかり気を取られてしまったりする、私たちの記憶と少し似ているかもしれません。
具体的には、主に以下の2つの課題が、RNNがそのポテンシャルを最大限に発揮する上での壁となっていました。
課題1:遠い過去の記憶が薄れてしまう… 「長期依存性の問題」
考えてみてください。例えば、ある患者さんが数週間前に特定の薬を飲み始めたことが、今日の体調にじわじわと影響を与えている、というケースがあるとします。このような「遠い過去の出来事」と「現在の状態」の間の関連性、これを専門用語で「長期依存性(Long-term Dependencies)」と呼びます。
RNNは、理論上はこうした長期の依存関係も捉えられるはずなのですが、実際には少し苦手としていました。なぜかというと、RNNの内部では、過去の情報(隠れ状態)が次の時刻、また次の時刻…と伝播していく際に、毎回同じような計算処理(具体的には重み行列を掛けたり、活性化関数を通したり)を繰り返します。これが、まるで伝言ゲームのようになってしまうんです。
RNNの情報の流れ(イメージ): 時刻1: [情報A] → 処理 → [隠れ状態1] ↓ 時刻2: [情報B] + [隠れ状態1] → 処理 → [隠れ状態2] ↓ 時刻3: [情報C] + [隠れ状態2] → 処理 → [隠れ状態3] ↓ ... ... ↓ 時刻t: [情報X] + [隠れ状態t-1] → 処理 → [隠れ状態t] (←ここに時刻1の情報Aが残っているか?)
この図のように、時刻1の情報Aが時刻tまで影響を及ぼそうとすると、何度も「処理」というフィルターを通過しなければなりません。その過程で、情報が少しずつ薄まってしまったり、あるいは他の情報と混ざって変質してしまったりして、いざ遠い未来の時刻tでその情報を使おうとしても、「あれ?なんだっけ?」となってしまうことが多いのです。医療の現場では、数日前、数週間前の出来事が今日の状態を理解する鍵になることも少なくないですから、これは結構深刻な問題ですよね。
課題2:学習がうまく進まない… 「勾配消失・勾配爆発の問題」
もう一つの大きな壁が、ニューラルネットワークの学習方法である「誤差逆伝播法(Backpropagation Through Time, BPTT)」と深く関わっています。RNNの学習では、現在の予測の「間違い(誤差)」を、時間を遡って過去の各時点に伝え、それぞれの時点で「どうすればもっと良い予測ができたか」を学習していきます。この「間違い」を伝える指標が「勾配(gradient)」と呼ばれるものです。
ところが、この勾配を時間を遡って伝えていく過程で、おかしなことが起こりやすかったのです。
- 勾配消失 (Vanishing Gradient Problem): 時間を遡るにつれて、伝えるべき勾配の値がどんどん小さくなっていき、ついにはほぼゼロになってしまう現象です。勾配がゼロに近くなると、モデルは「どこを修正すれば良いか」が分からなくなり、実質的に学習がストップしてしまいます。特に、長期依存性を学習しようとすると、この勾配消失が顕著に現れやすかったのです。まるで、遠くにいる人に声を届けようとしても、途中で声が小さくなって届かなくなってしまうようなイメージですね。 勾配消失のイメージ (時間を遡る方向): 誤差 → [勾配(大)] → 処理の逆伝播 → [勾配(中)] → 処理の逆伝播 → [勾配(小)] → … → [勾配(ほぼ0)] (現在) (遠い過去)
- 勾配爆発 (Exploding Gradient Problem): 逆に、勾配が時間を遡るにつれて指数関数的に大きくなり、とんでもなく巨大な値になってしまう現象です。勾配が大きすぎると、モデルのパラメータがほんの少し更新されただけで、予測が大きく変動してしまい、学習が不安定になったり、発散してしまったりします。こちらは、小さな声がエコーでどんどん大きくなりすぎて、何を言っているか分からなくなるような状況でしょうか。勾配爆発のイメージ (時間を遡る方向): 誤差 → [勾配(小)] → 処理の逆伝播 → [勾配(中)] → 処理の逆伝播 → [勾配(大)] → … → [勾配(巨大すぎ!)] (現在) (遠い過去)
これらの「勾配消失」と「勾配爆発」は、特に系列が長くなればなるほどRNNを悩ませる、いわば持病のようなものでした。学習がうまく進まなければ、せっかくのRNNも宝の持ち腐れになってしまいますよね。
「うーん、これじゃあ、本当に知りたい長期的なパターンを見つけ出すのは難しいぞ…」研究者たちは頭を抱えました。過去の情報をうまく取捨選択し、必要な情報を必要な期間だけ保持し、そして学習も安定して行えるような、もっと賢いRNNが求められていたのです。
そして、こうしたRNNの限界を乗り越えるために、救世主のように登場したのが、本日の主役であるLSTM(Long Short-Term Memory)というわけです。LSTMは、これらの問題を解決するための巧妙な仕掛けを内部に持っています。そのおかげで、RNNよりもずっと上手に長期的な依存関係を学習できるようになったのです。まさに、AI研究者たちの知恵と工夫の結晶と言えるかもしれませんね。次のセクションでは、そのLSTMの秘密のメカニズムに迫っていきましょう!
2. LSTMの核心:情報を賢く取捨選択する「ゲート」という名の仕掛け人
この章では、このLSTMの心臓部である「ゲート」の仕組みを、数式も交えながら、できるだけ直感的に、そして医療の現場でのイメージも湧きやすいように、じっくりと解き明かしていきます。「数式はちょっと苦手で…」という方もいらっしゃるかもしれませんが、一つ一つの記号が何を意味し、どんな役割を果たしているのかを丁寧に見ていけば、きっとLSTMの賢さに「なるほど!」と納得していただけるはずです。さあ、一緒にLSTMの奥深い世界を探検しましょう!
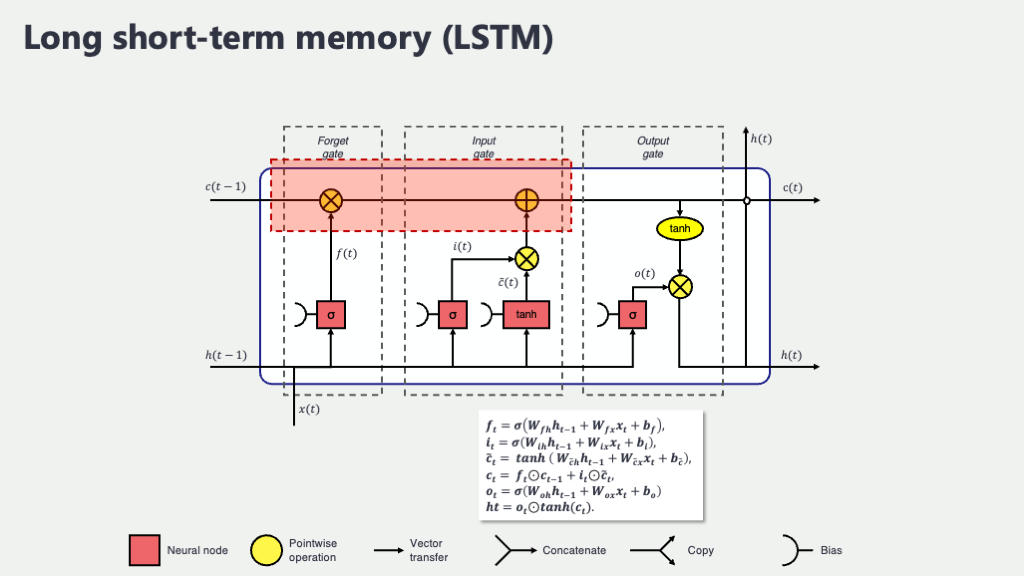
1. LSTMの舞台裏:セル状態と3つのゲート
LSTMユニット(LSTMセルとも呼ばれます。これがたくさん連なってLSTMネットワークを形成します)の内部には、情報を処理するための主要な構成要素があります。まずは、それらの役割を大まかに掴んでみましょう。
- セル状態 (Cell State, \(C_t\)): LSTMの最も重要な革新の一つが、この「セル状態」です。これは、情報を長期的に保持するための専用のラインで、LSTMユニットを貫くように存在します。まるで、情報がスムーズに流れるハイウェイのようなもので、このセル状態のおかげで、重要な情報が途中で薄まったり歪んだりすることなく、長い時間にわたって保持されやすくなっています。これが、LSTMが「長期記憶」を扱える大きな理由です。
- 隠れ状態 (Hidden State, \(h_t\)): これは、RNNにも存在したもので、ある時刻におけるLSTMユニットの「短期的な記憶」であり、同時にその時刻の「出力」としても機能します。セル状態が内部的な長期記憶だとすれば、隠れ状態は外部とのインターフェースや、短期的な作業メモリのような役割を担います。
- 3つのゲート (Gates): これらがLSTMの賢さの源泉です!以下の図の「忘却ゲート」「入力ゲート」「出力ゲート」という3種類のゲートがあり、それぞれがセル状態への情報の流れを精密にコントロールします。各ゲートは、現在の入力と前の隠れ状態に基づいて、「どの情報をどの程度通すか」を決定する、いわば情報の関所のようなものです。
下の図は、1つのLSTMユニット(時刻 \(t\) における処理)の内部で、これらの要素がどのように連携して情報を処理しているかを示した概念図です。矢印は情報の流れを、記号は計算処理を表しています。

この図を見ると、以下のように、中央を水平に走るラインがセル状態 \(C\) の流れを示しており、比較的直接的に情報が伝わっているのが分かりますね。そして、入力 \(x_t\) と前の隠れ状態 \(h_{t-1}\) が、3つのゲート(忘却、入力、出力)の計算に使われ、それらのゲートがセル状態の流れを制御したり、新しい隠れ状態 \(h_t\) を生成したりしている様子が見て取れると思います。なんだか、精密な流体制御システムみたいですね!
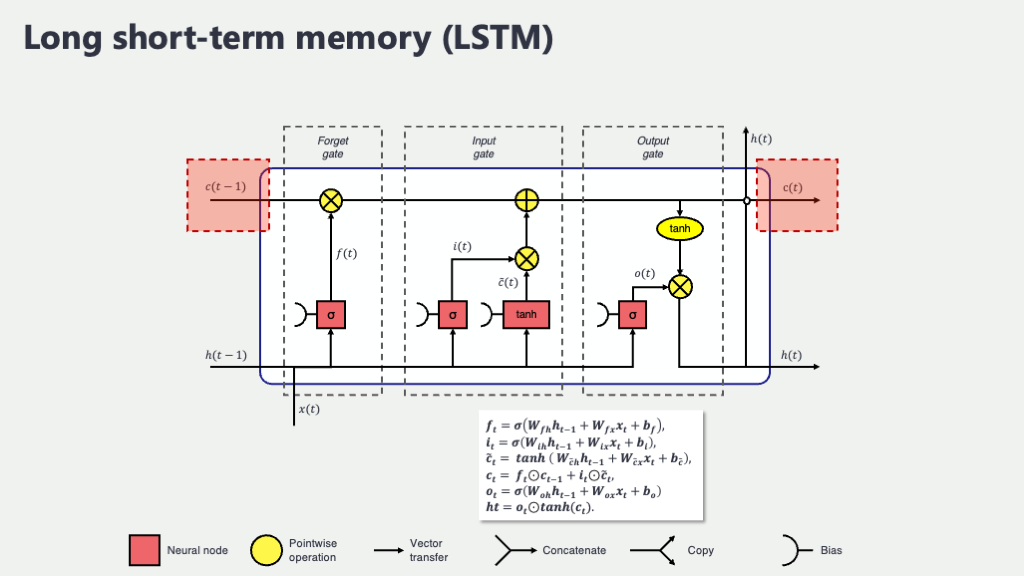
それでは、各ゲートが具体的にどのような計算を行い、どのように情報をコントロールしているのか、一つずつ詳しく見ていきましょう。
2. 忘却ゲート (Forget Gate, \(f_t\)):過去の記憶の「大掃除」担当
まず最初に仕事をするのが「忘却ゲート」です。その名の通り、長期記憶であるセル状態 \(C_{t-1}\) の中から、「どの情報を忘れるべきか(あるいは、どの情報を保持し続けるべきか)」を決定します。私たちの脳も、常に新しい情報を取り入れながら、古くなったり重要でなくなったりした情報は自然と忘れていきますよね。それと同じように、LSTMもセル状態を整理整頓し、本当に必要な情報だけを残そうとします。
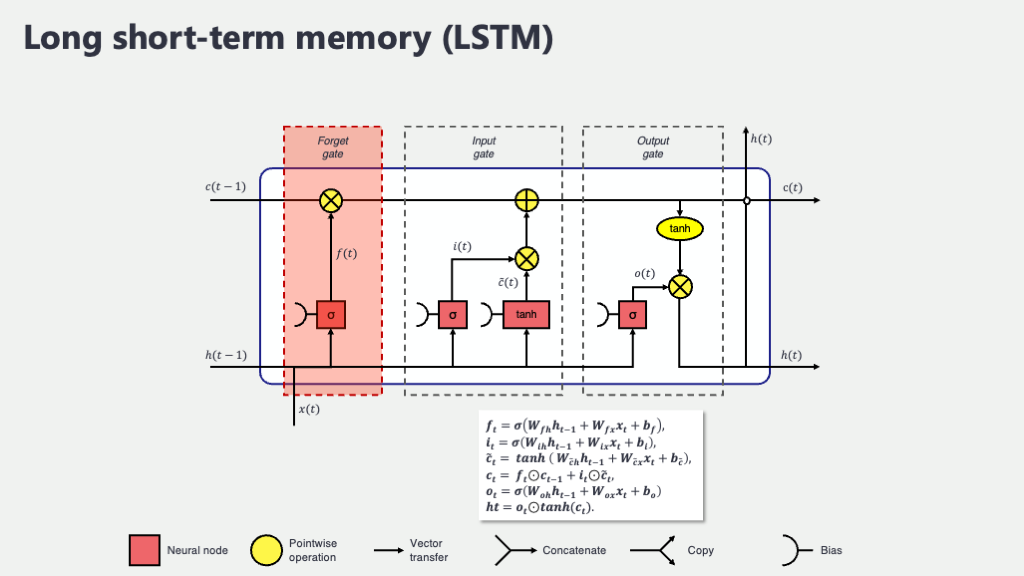
例えば、ある患者さんが以前に経験した一過性のアレルギー反応が、現在の慢性疾患の管理には直接関係ない場合、そのアレルギーに関する詳細な情報は、セル状態から少し「薄めて」おく(忘れる)ことで、現在の問題に集中しやすくなるかもしれません。
忘却ゲート \(f_t\) は、現在の入力 \(x_t\) と前の隠れ状態 \(h_{t-1}\) を見て、次のような計算を行います。
\[ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \]
この式の各部分を丁寧に解説しますね。
- \([h_{t-1}, x_t]\): これは、ベクトル \(h_{t-1}\)(前の短期記憶)とベクトル \(x_t\)(現在の入力)を文字通り連結 (concatenate) して作られた、より長い一つのベクトルです。例えば、もし \(h_{t-1}\) が100次元のベクトルで、\(x_t\) が50次元のベクトルなら、この連結ベクトルは150次元になります。このように、過去の文脈(\(h_{t-1}\))と現在の新しい情報(\(x_t\))の両方を材料にして、「何を忘れるべきか」を判断しようというわけです。
- \(W_f\): これは忘却ゲート専用の「重み行列 (Weight matrix)」です。行列の各要素(重み)は、学習を通じてAIが自動的に調整していきます。この重み行列が、連結ベクトル \([h_{t-1}, x_t]\) のどの要素が「忘れるべきかどうか」の判断にどれだけ重要か、その「さじ加減」を学習するわけです。
- \(b_f\): こちらは忘却ゲート専用の「バイアスベクトル (Bias vector)」です。これも学習によって調整されるパラメータで、重み行列による計算結果に一定のオフセット(ゲタを履かせるようなもの)を加える役割があります。
- \(\sigma\) (シグモイド関数): 前述の通り、入力された値を必ず0から1の範囲に押し込めるS字カーブの関数です(式:\(\sigma(z) = 1 / (1 + e^{-z})\))。この出力 \(f_t\) はベクトルで、その各要素が0から1の間の値を取ります。この値が、対応するセル状態の情報を「どれだけ忘れるか(0に近いほど忘れる)」あるいは「どれだけ保持するか(1に近いほど保持する)」という割合を示します。まさに、情報の各項目に対する「忘却フィルター」の役割ですね。
具体的に、この計算がどのように行われるか、興味がある方は、以下のDeep Dive! をご覧ください。
Deep Dive! 忘却ゲート \(f_t\) の計算ステップ
各ゲートは、このような計算(入力の連結 → 重み行列との積とバイアスの加算 → 活性化関数(シグモイド or tanh))を経て、それぞれの役割を果たす値(ゲートの開閉度や記憶候補)を出力します。そして、これらの値が組み合わさって、セル状態 \(C_t\) と隠れ状態 \(h_t\) が更新されていくのでしたね。
では、具体的に忘却ゲート \(f_t\) がどのように計算されているのか、その中身をステップごとに、そして各データの「形(次元)」も意識しながら、じっくりと見ていきましょう。この次元の理解は、後で実際にプログラムを書くときに「あれ?データの形が合わないぞ?」といったエラーを防ぐのに役立ちますから、ちょっとだけ数学の時間にお付き合いください!
【忘却ゲート \(f_t\) の計算ステップを覗いてみよう (次元情報と共に)】
まず、計算に必要な「材料」と、それらがどんな「大きさ」を持っているかを確認しておきましょう。
[想定する次元(大きさの目安)]
hidden_dim: 隠れ状態ベクトル \(h_t\) やセル状態ベクトル \(C_t\) が持つ要素の数です。いわば、LSTMが一度に記憶したり処理したりできる情報の「幅」のようなもの。例えば、128個の数値で表現する、といった具合です。input_dim: 各時刻 \(t\) でLSTMに入力されるデータ \(x_t\) が持つ特徴量の数です。例えば、血糖値、インスリン投与量、食事量という3つの特徴量を入力するなら、input_dimは3になります。ここでは仮に10としておきましょうか。
[忘却ゲート計算のための入力情報]
- \(h_{t-1}\) (前の時刻の隠れ状態ベクトル):
形状はだいたい(hidden_dim, 1)のような列ベクトルをイメージしてください(ここでは1つのデータサンプルに対する計算を考えています)。実際には、複数のデータをまとめて処理する「バッチ処理」を行うため、プログラム上では(batch_size, hidden_dim)という形になることが多いですが、ここではまず基本の形を掴みましょう。 - \(x_t\) (現在の時刻の入力ベクトル):
こちらも同様に、形状は(input_dim, 1)のような列ベクトルをイメージします。プログラム上では(batch_size, input_dim)となります。
※ちょっと補足ですが、上記の「1つのデータに対する処理としてベクトルで表現」というのは、LSTMの基本計算を分かりやすくするためです。実際のプログラムでは、効率のために複数のデータ(バッチ)を一度に処理するので、テンソルの最初の次元に `batch_size` が加わるのが普通です。でも、まずは1つずつのデータの流れを追ってみましょう!
さあ、材料が揃いました!忘却ゲート \(f_t\) を計算するまでの道のりは、大きく3つのステップに分けられます。
ステップ1: 過去の文脈と現在の入力を合体! (入力の連結)
まず、忘却ゲートが「何を忘れるべきか」を判断するための材料として、前の時刻の隠れ状態 \(h_{t-1}\)(過去の文脈情報)と、現在の時刻の入力 \(x_t\)(今まさに飛び込んできた新しい情報)の両方を使います。これら2つのベクトルを、文字通り縦に積み重ねて(連結して)、1本の長いベクトルにしちゃいます。これを concatenated_input と呼ぶことにしましょう。
具体的には、\(h_{t-1}\) が例えば128次元のベクトルで、\(x_t\) が10次元のベクトルだとすると、これらを連結した concatenated_input は、(128 + 10) = 138次元のベクトルになります。
\[ \text{concatenated\_input} = \begin{bmatrix} h_{t-1} \\ x_t \end{bmatrix} \]
このベクトルの形状は、(hidden_dim + input_dim, 1) となりますね(例: (138, 1))。こうすることで、過去の情報と現在の情報を一度に扱えるようになるわけです。料理で言えば、メインの材料とスパイスを一つのボウルに入れた、といった感じでしょうか。
ステップ2: 重み付けとバイアスで情報のエッセンスを抽出! (\(z_f\) の計算)
次に、ステップ1で作った連結入力ベクトル concatenated_input に、忘却ゲート専用の「重み行列 \(W_f\)」を掛け合わせ、さらに「バイアスベクトル \(b_f\)」を加えます。この計算によって、どの情報をどれだけ重視して「忘れる」判断に使うかのエッセンスを抽出しようとします。この計算結果を \(z_f\) としましょう。
数式で書くとこうなります。
\[ z_f = W_f \cdot \text{concatenated\_input} + b_f \]
ここでの「\(\cdot\)」は行列とベクトルの積(行列乗算)を表します。この計算が、具体的にどんな形と大きさのデータを使って行われるのか、下の図解イメージで見てみましょう。
[図解イメージ: z_f = W_f * concatenated_input + b_f の詳細ステップ]
この計算は、大きく分けて「重み行列と入力の乗算」と「バイアスの加算」の2段階で行われます。
まず、以下の2つの要素を用意します。
1. 忘却ゲートの重み行列 (W_f):
これは、入力された情報に「どれだけ重みを付けるか」を決定する行列です。
LSTMが学習を通じて、この行列の値を賢く調整していきます。
+---------------------------------------------+
| |
| (例: 128 × 138 の行列) |
| (hidden_dim × (hd + id)) |
| |
+---------------------------------------------+
形状: (hidden_dim × (hidden_dim + input_dim))
(hd: hidden_dim, id: input_dim の略)
2. 連結入力ベクトル (concatenated_input):
これは、ステップ1で作成した、前の隠れ状態 h_{t-1} と現在の入力 x_t を
縦に連結したベクトルです。
+---------------------------------+
| h_{t-1}_1 | ┐
| ... | │ h_{t-1} (過去の文脈)
| h_{t-1}_{hidden_dim} | ┘ (hidden_dim次元)
| x_t_1 | ┐
| ... | │ x_t (現在の入力)
| x_t_{input_dim} | ┘ (input_dim次元)
+---------------------------------+
形状: ((hidden_dim + input_dim) × 1) (例: (128+10) × 1 = 138 × 1)
次に、これらの行列とベクトルを乗算します。
(W_f * concatenated_input)
この計算結果を「中間結果1」とします。
中間結果1 (重み付けされた入力):
+---------------------+
| |
| (hidden_dim × 1 の |
| ベクトル) |
| (例: 128 × 1) |
| |
+---------------------+
形状: (hidden_dim × 1)
最後に、この「中間結果1」にバイアスベクトルを加えます。
3. 忘却ゲートのバイアスベクトル (b_f):
これは、乗算結果に加える調整値のベクトルです。これも学習によって調整されます。
+---------------------+
| b_f_1 |
| ... |
| b_f_{hidden_dim} |
+---------------------+
形状: (hidden_dim × 1) (例: 128 × 1)
「中間結果1」と「b_f」を要素ごとに加算します。
(中間結果1 + b_f)
これが、シグモイド関数に入力される前の z_f となります。
最終的なベクトル (z_f):
+---------------------+
| z_f_1 |
| ... |
| z_f_{hidden_dim} |
+---------------------+
形状: (hidden_dim × 1) (例: 128 × 1)
この図解で何となくイメージが掴めましたでしょうか? \(W_f\) の形状が (hidden_dim, hidden_dim + input_dim) で、concatenated_input の形状が (hidden_dim + input_dim, 1) なので、これらを掛け合わせると、結果として hidden_dim 次元のベクトル(形状 (hidden_dim, 1))が得られます。そして、これに同じく hidden_dim 次元のバイアスベクトル \(b_f\) を足し合わせるので、最終的な \(z_f\) も hidden_dim 次元のベクトルになる、というわけです。この \(z_f\) というベクトルが、次のステップでシグモイド関数によって「忘れる度合い」へと変換される元になるんですね。
ステップ3: シグモイド関数で「忘れる度合い」に変換! (\(f_t\) の計算)
さて、ステップ2で得られたベクトル \(z_f\) は、まだプラスにもマイナスにも大きな値を取りうる、いわば「生の」情報です。これを、実際に「どの情報をどれだけ忘れるか」という「度合い」(0から1の間の数値で表したい)に変換するために、いよいよ「シグモイド関数 \(\sigma\)」の出番です!
\(z_f\) の各要素にシグモイド関数を適用することで、忘却ゲートの最終的な出力 \(f_t\) が得られます。
\[ f_t = \sigma(z_f) \]
シグモイド関数は、どんな入力値も必ず0と1の間の値に変換してくれる便利な関数でしたね。この \(f_t\) も \(z_f\) と同じく hidden_dim 次元のベクトル(形状 (hidden_dim, 1))ですが、その各要素は0から1の間の値を取ります。そして、この \(f_t\) の各要素の値が、対応する長期記憶 \(C_{t-1}\) の要素を「どれだけ忘れるか(あるいは保持するか)」を決定する「ゲートの開閉度」になるのです。例えば、\(f_t\) のある要素が0.1なら「その部分の記憶は90%忘れる」、0.9なら「10%だけ忘れる(90%は保持する)」といった具合です。
これで、忘却ゲート \(f_t\) の計算は完了です! この \(f_t\) が、後ほど \(C_t = (f_t \odot C_{t-1}) + (i_t \odot \tilde{C}_t)\) というセル状態の更新式の中で、\(C_{t-1}\)(前の長期記憶)に掛け合わされることで、実際に「忘れる」という操作が行われるわけですね。
ちなみに、今回詳しく見たのは忘却ゲートでしたが、他のゲート(入力ゲート \(i_t\) や出力ゲート \(o_t\))も、基本的にはこの忘却ゲートと非常によく似た計算の流れ(連結入力に対して、それぞれ専用の重み行列とバイアスを使って線形変換し、最後にシグモイド関数を適用する)を辿ります。また、新しい記憶の候補 \(\tilde{C}_t\) を作る際も、同様の線形変換の後に、シグモイド関数ではなくハイパボリックタンジェント関数 (\(\tanh\)) を適用するのでしたね。それぞれが少しずつ違う役割を担うために、専用の「学習可能なパラメータ(重みとバイアス)」を持っている、という点がポイントです。
このようにして計算された \(f_t\) ベクトルが、後ほど前のセル状態 \(C_{t-1}\) に要素ごとに掛け合わされ(アダマール積)、実際に「忘れる」という操作が行われます。例えば、\(f_t\) のある要素が0.2なら、対応する \(C_{t-1}\) の情報は20%だけ残り、80%は忘れられる、という具合です。
3. 入力ゲート (Input Gate, \(i_t\)) と 新しい記憶の候補 (\(\tilde{C}_t\)):新しい情報の「吟味」と「登録」
過去の記憶を整理整頓(一部忘却)したら、次は新しい情報をセル状態に追加する番です。しかし、どんな情報でも無条件に記憶するわけではありません。ここでもLSTMの賢さが光ります。このプロセスは、大きく分けて2つのステップで進行し、「入力ゲート (\(i_t\))」と「新しい記憶の候補 (\(\tilde{C}_t\))」という2つの要素が連携して働きます。
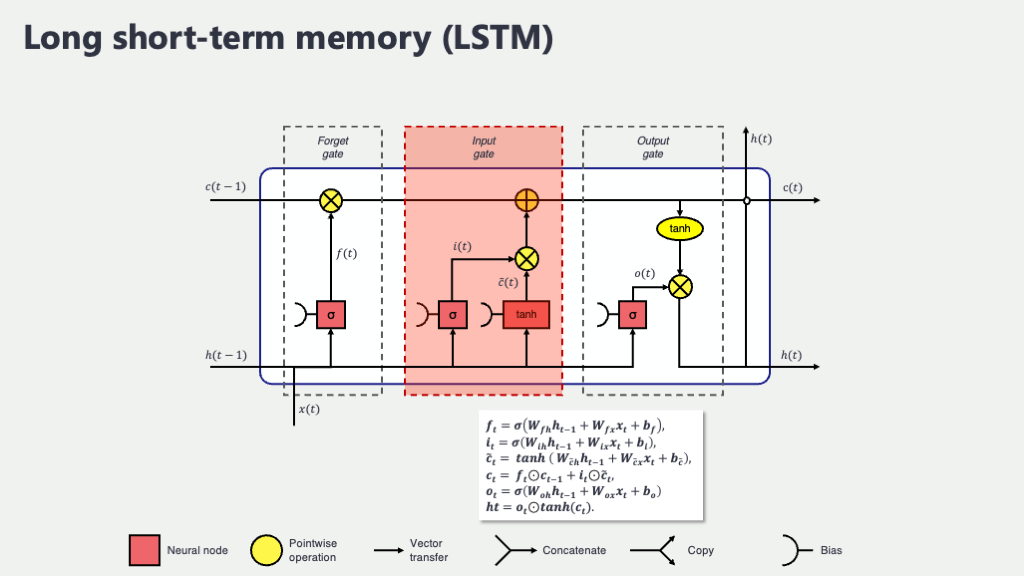
ステップ1:どの新しい情報を「通す」かを決めるスイッチ役 ~ 入力ゲート \(i_t\)
まず、「入力ゲート \(i_t\)」が、これから作られる「新しい記憶の候補」のうち、どの情報を、そしてどの程度の強さでセル状態に実際に書き込むかを決定します。これは、先ほどの忘却ゲートと非常によく似た構造と計算方法です。
\[ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \]
ここでも、\([h_{t-1}, x_t]\)(前の短期記憶と現在の入力の連結ベクトル)を材料とし、入力ゲート専用の重み行列 \(W_i\) とバイアス \(b_i\) を使って計算し、最後にシグモイド関数 \(\sigma\) を通します。結果として得られる \(i_t\) ベクトルも、各要素が0から1の値を持ち、これは「新しい情報の各要素を、どれだけの割合でセル状態に通すか」というフィルターの役割を果たします。1に近いほど「この情報は重要だからしっかり通せ!」、0に近いほど「この情報は今は不要だから通さない」という判断ですね。
ステップ2:どんな新しい情報を「加える」かの内容作り ~ 新しい記憶の候補 \(\tilde{C}_t\)
入力ゲート \(i_t\) が「どれだけ通すか」のスイッチの役割だったのに対し、「新しい記憶の候補 (\(\tilde{C}_t\))」(シー・チルダ・ティーと読みます)は、「じゃあ、具体的にどんな内容の情報をセル状態に追加するの?」という、記憶の「中身そのもの」を作り出す役割を担います。いわば、セル状態に追加する情報の「素案」ですね。
この \(\tilde{C}_t\) を生成する際には、シグモイド関数ではなく、もう一つのS字カーブの関数である「ハイパボリックタンジェント関数 (\(\tanh\))」が使われるのが一般的です。tanh関数も入力をS字カーブで変換しますが、出力が0から1ではなく、-1から1の間になるという点がシグモイド関数との大きな違いです(式:\(\tanh(z) = (e^z – e^{-z}) / (e^z + e^{-z})\))。
なぜ-1から1なのでしょうか? これにより、新しい情報に「方向性」や「極性」を持たせることができるのです。例えば、ある検査値が「上昇した」という情報を+0.8で、「低下した」という情報を-0.7で表現したり、あるいはもっと複雑な特徴をベクトルの各要素の正負と大きさで表現したりできます。これにより、単に情報の有無だけでなく、その性質も豊かに表現できるわけです。
\(\tilde{C}_t\) の計算式は以下の通りです。
\[ \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) \]
ここでも、\([h_{t-1}, x_t]\) を材料とし、新しい記憶候補生成専用の重み行列 \(W_C\) とバイアス \(b_C\) を使って計算し、最後にtanh関数を通します。結果として得られる \(\tilde{C}_t\) ベクトルは、各要素が-1から1の値を持ち、これがセル状態に追加される可能性のある「新しい情報の内容」となります。
シグモイドとtanhの使い分けが鍵!
入力ゲート \(i_t\) でシグモイド関数(出力0~1)を使い、新しい記憶の候補 \(\tilde{C}_t\) でtanh関数(出力-1~1)を使う。この組み合わせが非常に重要です。 \(i_t\) は「情報の取捨選択の度合い」を0~1で決め(通すか通さないか、どのくらい通すか)、 \(\tilde{C}_t\) は「通す情報の内容そのもの」を-1~1で表現する(どんな情報か、ポジティブかネガティブかなど)。 この2つを後で掛け合わせることで(\(i_t \odot \tilde{C}_t\))、非常に柔軟に新しい情報をコントロールできるのです。例えば、いくら\(\tilde{C}_t\) が「これは超重要な情報だ!(値が+1に近い)」と主張しても、\(i_t\) が「いや、今はほとんど必要ない(値が0に近い)」と判断すれば、その情報はほとんど記憶に残りません。この連携プレーがLSTMの賢さの秘訣なんですね。
Deep Dive! 「入力ゲート (\(i_t\))」と「新しい記憶の候補 (\(\tilde{C}_t\))」の二人三脚
忘却ゲートで過去の記憶の整理整頓が一段落したら、次はいよいよ新しい情報を私たちの記憶のメインストリートである「セル状態」に迎え入れる番です。でも、どんな情報でもウェルカム!というわけにはいきませんよね。本当に必要な情報だけを選び出し、適切な形で記憶に追加したいものです。この重要な役割を担うのが、「入力ゲート (\(i_t\))」と「新しい記憶の候補 (\(\tilde{C}_t\))」という、まさに二人三脚で働く賢いコンビなんです。
彼らは、「現在の入力 \(x_t\)(今まさに読んでいる単語など)」と「少し前の文脈(前の隠れ状態 \(h_{t-1}\))」をじっくりと吟味して、「この新しい情報の中から、どの部分を、どんな形で、そしてどれくらいの強さで、長期記憶(セル状態)に書き加えるべきか」を判断します。この判断プロセスは、大きく分けて2つの巧妙なステップで進められるんですよ。
ステップ1:どの情報を「通す」か? スイッチ役の入力ゲート \(i_t\) (シグモイド関数)
まず登場するのが、入力ゲート \(i_t\) です。このゲートの役割は、新しい情報(具体的には、後述する\(\tilde{C}_t\)が運んでくる情報)のうち、「どの情報を実際にセル状態に書き込むか」その“許可度合い”を決めることです。まるで、記憶の扉を開けるための「調光スイッチ」や「フィルター」のようなものだと考えてみてください。光をたくさん通すか(情報を強く記憶するか)、少しだけ通すか(情報を弱く記憶するか)、あるいは全く通さないか(情報を無視するか)を、0から1の間の数値で細かく調整するんです。
この「許可度合い」を計算するために使われるのが、おなじみの「シグモイド関数 (\(\sigma\))」です。忘却ゲートでも活躍していましたね。思い出していただきたいのですが、シグモイド関数は、どんな入力値がきても、その出力値を必ず0と1の間にギュッと押し込めるS字カーブの関数でした。
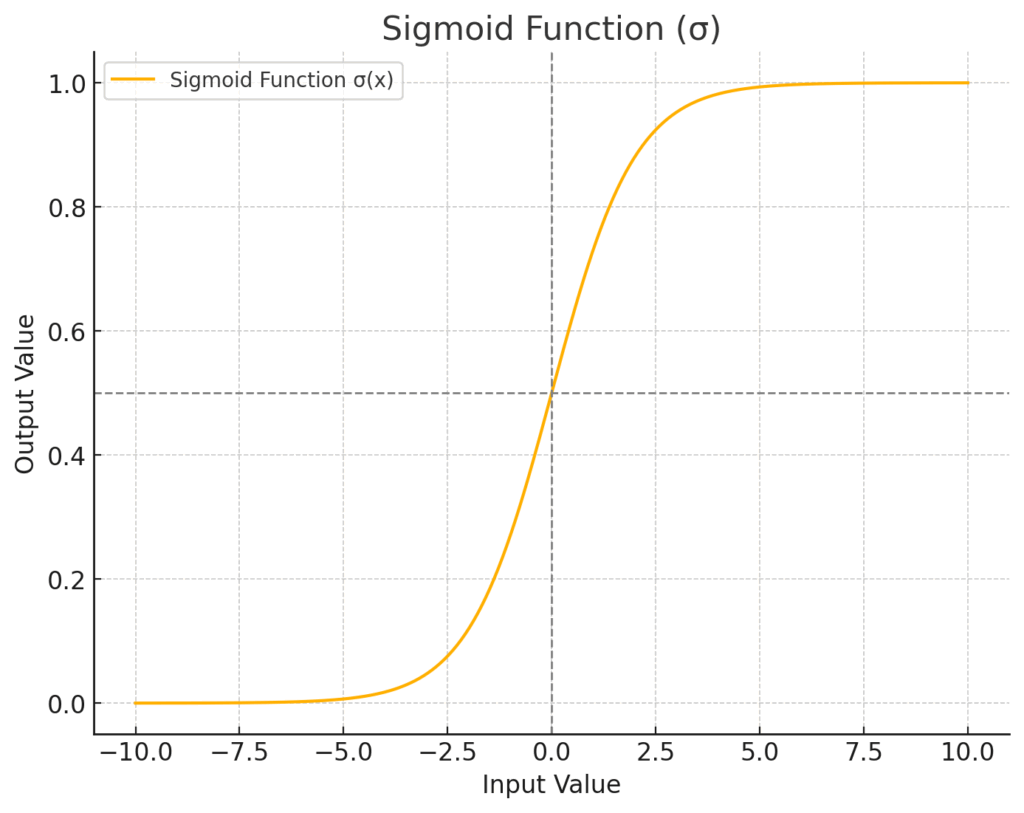
この性質が、「ゲート」の開閉具合を表現するのにピッタリなんです。入力ゲート \(i_t\) の計算式は以下のようになります。
\[ i_t = \sigma(W_i [h_{t-1}, x_t] + b_i) \]
ここで、\(W_i\) と \(b_i\) は、入力ゲート専用の「学習可能な重み行列とバイアス項」です。これらが、過去の文脈 \([h_{t-1}, x_t]\) をどう解釈すれば、最適な「許可度合い」\(i_t\)(0~1の間の値を持つベクトル)が得られるかを、学習を通じて賢く調整していきます。例えば、ある単語の情報がすごく重要だと判断されれば、\(i_t\) の対応する要素の値は1に近くなり、「この情報は記憶にしっかり通せ!」という指令が出るわけです。
ステップ2:どんな情報を「加える」か? 内容担当の新しい記憶候補 \(\tilde{C}_t\) (tanh関数)
入力ゲート \(i_t\) が「どれだけ通すか」のスイッチの役割を果たしたのに対し、次に登場する \(\tilde{C}_t\) (「シーチルダ・ティー」とか「シーティルダ・ティー」と読みます) は、「じゃあ、実際にどんな“内容”の情報をセル状態に追加するの?」という、記憶の「中身そのもの」を作り出す役割を担います。いわば、記憶の候補生ですね。
この \(\tilde{C}_t\) を生成する際には、シグモイド関数ではなく、もう一つのS字カーブの関数、「ハイパボリックタンジェント関数 (\(\tanh\))」が使われます。このtanh関数、シグモイド関数と形は似ているんですが、出力値が0から1ではなく、-1から1の間に収まるという大きな違いがあります。
この-1から1という出力範囲がミソでして、これによって、新しく生成される情報に、単に「ある/ない」や「強い/弱い」だけでなく、プラス方向やマイナス方向といった「情報の方向性」や「意味合いの極性」を持たせることができるようになるんです。例えば、「この単語は記憶に対して『非常に肯定的な影響』を与えるべきだ(例: 値が+0.9に近い)」とか、「この単語は『やや否定的なニュアンス』を記憶に反映させるべきだ(例: 値が-0.3に近い)」といった、より豊かな情報表現が可能になります。新しい記憶の候補 \(\tilde{C}_t\) の計算式は以下の通りです。
\[ \tilde{C}_t = \tanh(W_C [h_{t-1}, x_t] + b_C) \]
こちらも同様に、\(W_C\) と \(b_C\) は、この新しい記憶候補を生成するために学習される専用の重み行列とバイアス項です。「過去の文脈と現在の入力から判断して、こんな感じの新しい情報を記憶の候補として提案してみるけど、どうかな?」といったニュアンスですね。
なぜシグモイドとtanhを使い分けるの? それがLSTMの賢さの秘訣!
ここで、「あれ? なんで入力ゲート\(i_t\)はシグモイドで、記憶候補\(\tilde{C}_t\)はtanhなの? どっちもS字カーブなら、どっちか一つで良くない?」なんて疑問が湧いてくるかもしれません。とっても良い疑問ですね! 実は、この2つの関数を巧みに使い分けることこそが、LSTMが情報を柔軟にコントロールできる秘訣の一つなんです。
もう一度整理すると、
- 入力ゲート \(i_t\) (シグモイド関数, 出力 0~1) は、「情報の取捨選択の“度合い”」を決める係数、つまり「どれだけ重要か」「どれだけ通すか」というゲートの開閉バルブの役割。
- 新しい記憶の候補 \(\tilde{C}_t\) (tanh関数, 出力 -1~1) は、「実際に記憶される可能性のある“情報の内容そのもの”」であり、その情報の方向性や強弱を表現する役割。
この2つが組み合わさることで、LSTMは非常に表現力豊かに新しい情報を処理できるのです。例えば、水道の蛇口に例えてみましょうか。
【シグモイドとtanhの連携プレー:水道の蛇口アナロジー】
[h_{t-1}, x_t] (天気予報と今の気温など)
│
├─────▶ 入力ゲート i_t (シグモイド) ───▶ 蛇口の「ひねり具合」(0%~100% 開栓)
│ 「どれだけ水を出すか」
│
└─────▶ 記憶候補 \tilde{C}_t (tanh) ───▶ 出てくる「水の種類・温度」(-1:激冷水 ~ +1:激熱湯)
「どんな水を出すか」
最終的にタンク(セル状態)に加わる水 =
「ひねり具合」 × 「水の種類・温度」
(例: 50%開栓 × 冷水 → 少量の冷水が加わる)
(例: 100%開栓 × 熱湯 → 大量の熱湯が加わる)
入力ゲート \(i_t\) が「蛇口のひねり具合」(0%〜100%開栓)を決めるのに対し、新しい記憶候補 \(\tilde{C}_t\) は「どんな種類の水が、どれくらいの温度で出てくるか」(例えば、-1がすごく冷たい水、+1がすごく熱いお湯、0が無味無臭の常温水、といった具合)を決める、というイメージです。いくら記憶候補 \(\tilde{C}_t\) が「ものすごく重要な情報だ!(例えば+1に近い値)」と主張しても、入力ゲート \(i_t\) が「いや、今はその情報はほとんど必要ないよ(0に近い値)」と蛇口を絞ってしまえば、セル状態にはほとんど影響を与えません。逆に、平凡な情報(\(\tilde{C}_t\) が0に近い値)でも、入力ゲート \(i_t\) が「これは絶対に通すべき!(1に近い値)」と判断すれば、その情報は(ほぼそのままの形で)セル状態に加わることになります。
このように、シグモイド関数で「通すか通さないか、通すならどの程度か」というON/OFFスイッチ的・割合的な制御を行い、tanh関数で「通す情報の内容自体に方向性や強弱を付ける」という役割分担をすることで、LSTMは非常に柔軟かつ効果的に、新しい情報を既存の記憶(セル状態)へと統合していくことができるのです。いやはや、本当に巧みな設計ですよね!
まとめると、入力ゲート \(i_t\) は「どの新しい情報をどれだけ真剣に受け止めるか(あるいはスルーするか)の選択の度合い」、そして新しい記憶の候補 \(\tilde{C}_t\) は「受け止めるとしたら、それはどんな性質の情報なのか」をそれぞれ決定し、この二つの情報を掛け合わせる(次のセル状態更新のステップで \(i_t \odot \tilde{C}_t\) として出てきます)ことで、セル状
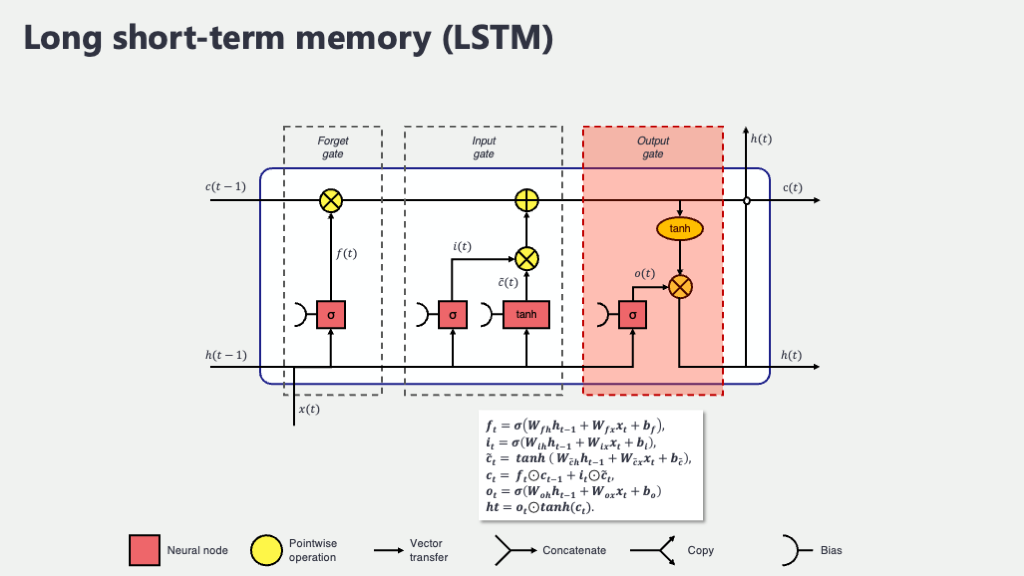
4. セル状態の更新 (Cell State Update, \(C_t\)):記憶のダイナミックな書き換え
さあ、過去の記憶を整理するための忘却ゲート \(f_t\) と、新しい情報を吟味するための入力ゲート \(i_t\) 及び新しい記憶の候補 \(\tilde{C}_t\) の準備が整いました。いよいよ、これらを使って、前の時刻のセル状態 \(C_{t-1}\) から現在の時刻の新しいセル状態 \(C_t\) を計算します。この計算式こそ、LSTMの長期記憶をダイナミックに更新する心臓部です!
\[ C_t = (f_t \odot C_{t-1}) + (i_t \odot \tilde{C}_t) \]
ここで、\(\odot\) は「要素ごとの積 (アダマール積)」を表します。これは、同じサイズのベクトル(または行列)の、同じ位置にある要素同士をそれぞれ掛け算するという演算です。通常の行列積とは異なるので注意してくださいね。
この式が何をしているか、分解して見てみましょう。
- 第1項: \((f_t \odot C_{t-1})\) 「過去の記憶の選択的保持」
これは、前のセル状態 \(C_{t-1}\)(長期記憶)の各要素に、忘却ゲート \(f_t\) の出力(0~1の値を持つベクトル)を要素ごとに掛け合わせています。\(f_t\) の要素が0に近ければ、\(C_{t-1}\) の対応する要素の値はほぼゼロになり、その情報は「忘れられた」ことになります。逆に \(f_t\) の要素が1に近ければ、その情報はそのまま強く保持されます。これで、古い情報の中から必要なものだけが残ります。 - 第2項: \((i_t \odot \tilde{C}_t)\) 「新しい情報の選択的追加」
これは、新しい記憶の候補 \(\tilde{C}_t\)(-1~1の値を持つベクトル)の各要素に、入力ゲート \(i_t\) の出力(0~1の値を持つベクトル)を要素ごとに掛け合わせています。\(i_t\) の要素が1に近ければ、\(\tilde{C}_t\) の対応する新しい情報が強く採用され、0に近ければその情報はほとんど無視されます。これで、新しい情報の中から重要なものだけが選ばれます。 - そして、この2つの結果を「要素ごとに足し合わせる」ことで、新しいセル状態 \(C_t\) が完成します!
つまり、LSTMのセル状態は、 「(前の長期記憶 × 忘れなさ度合い) + (新しい情報の候補 × 取り込み度合い)」 という形で更新されるのです。古い記憶の一部を保持しつつ(忘れるべきは賢く忘れ)、新しい情報を吟味して追加する。なんだか、私たち人間が勉強して新しい知識を既存の知識と結びつけたり、不要な古い情報を整理したりするプロセスにも少し似ていると思いませんか? このエレガントなプロセスのおかげで、重要な情報は長く保持され、不要な情報は適切に処理されるという、ダイナミックで柔軟な記憶の更新が可能になるのです。
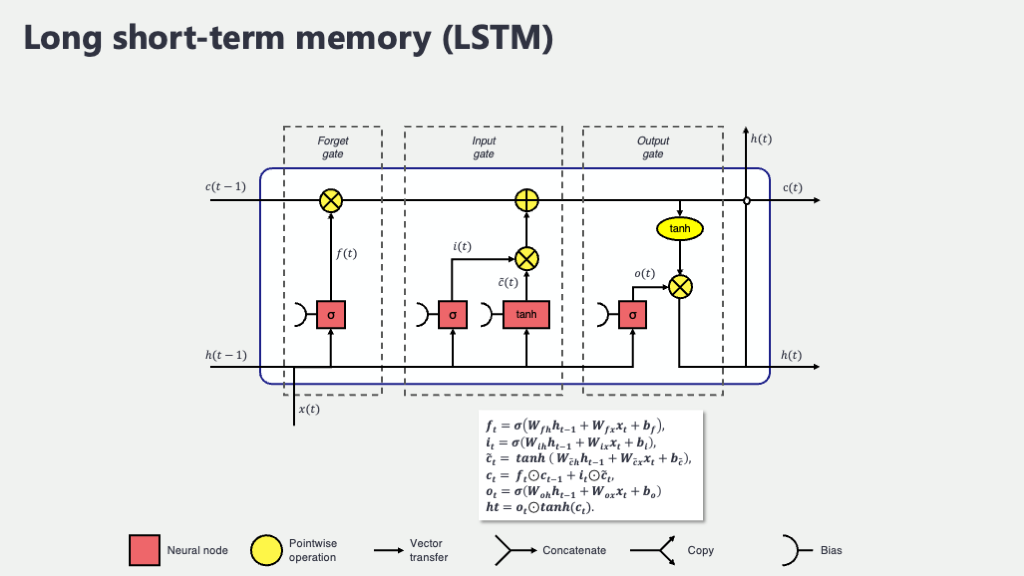
5. 出力ゲート (Output Gate, \(o_t\)) と 隠れ状態の出力 (\(h_t\)):記憶からの「情報発信」
長期記憶であるセル状態 \(C_t\) が最新版にアップデートされました。しかし、この豊富な長期記憶の中から、現在の時刻 \(t\) で「実際に何を出力として使うか」、あるいは「次のLSTMユニットや、もしあれば後続のニューラルネットワーク層にどんな情報を渡すか」を決めなければなりません。いくら素晴らしい情報がセル状態という名のデータベースに蓄えられていても、その時々で適切な情報を取り出して活用できなければ意味がありませんよね。その最終的な情報取り出しと、短期記憶の形成を担うのが、「出力ゲート (\(o_t\))」と、それによって生成される「隠れ状態 (\(h_t\))」です。
まず、出力ゲート \(o_t\) が、どの情報をどの程度出力するかの「許可度合い」を計算します。これも、これまでのゲートと同様に、前の隠れ状態 \(h_{t-1}\) と現在の入力 \(x_t\) を材料にし、シグモイド関数 \(\sigma\) を使います。
\[ o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \]
ここで、\(W_o\) と \(b_o\) は出力ゲート専用の学習パラメータ(重み行列とバイアス)です。この \(o_t\) ベクトル(各要素0~1)が、セル状態から情報を取り出す際のフィルターとして機能します。
次に、この出力ゲート \(o_t\) の値と、現在のセル状態 \(C_t\) を一度 \(\tanh\) 関数で処理したもの(値を-1から1の範囲にギュッと押し込めて、使いやすい形に整えるイメージです)を、再び要素ごとに掛け合わせる(\(\odot\))ことで、最終的な現在の時刻の隠れ状態 \(h_t\) が決まります。
\[ h_t = o_t \odot \tanh(C_t) \]
この \(h_t\) が、単純なRNNで言うところの「短期的な記憶」であり、また、このLSTMユニットの(あるいは層全体の)その時刻における「出力」となります。そして、この \(h_t\) は次の時刻 \(t+1\) のLSTMユニットへ、\(h_t\) として渡されていくのです。
ここでのポイントは、セル状態 \(C_t\) の情報をそのまま出すのではなく、
- まず \(\tanh(C_t)\) で、セル状態の情報を-1から1の範囲にスケーリングします。これにより、出力される情報の値が極端に大きくなったり小さくなったりするのを防ぎ、後続の処理がしやすくなります。
- そして、出力ゲート \(o_t\) で、「どの情報を表に出すか」をフィルタリングします。
この二段階の処理によって、長期記憶の中から、現在の文脈において本当に必要な情報だけを選択的に、かつ適切な形で取り出すことができるようになるわけですね。例えば、患者さんの全診療記録(セル状態 \(C_t\))の中から、現在の診断に必要な特定の所見(\(\tanh(C_t)\) で抽出・整形された情報の一部)だけを選び出し(\(o_t\) でフィルタリング)、それを次の診断ステップのための情報(隠れ状態 \(h_t\))として提示する、といったイメージでしょうか。
6. まとめ:LSTMのゲートがもたらす「賢い記憶」
ここまで見てきたように、LSTMは「忘却ゲート」「入力ゲート」「出力ゲート」という3つの巧妙なゲートメカニズムと、長期記憶を保持する「セル状態」を導入することで、従来のRNNが抱えていた課題を見事に克服しました。
表にまとめると、各ゲートの役割は以下のようになります。
| ゲート名 | 主な役割 | 活性化関数 | 出力範囲 | 何に作用するか |
|---|---|---|---|---|
| 忘却ゲート (\(f_t\)) | 過去のセル状態 \(C_{t-1}\) から、どの情報を「忘れる」かを決定する。 | シグモイド (\(\sigma\)) | 0 ~ 1 | \(C_{t-1}\) (要素ごとに積) |
| 入力ゲート (\(i_t\)) | 新しい情報の候補 \(\tilde{C}_t\) のうち、どの情報をセル状態に「追加する」かを決定する。 | シグモイド (\(\sigma\)) | 0 ~ 1 | \(\tilde{C}_t\) (要素ごとに積) |
| 新しい記憶の候補 (\(\tilde{C}_t\)) | 現在の入力 \(x_t\) と前の隠れ状態 \(h_{t-1}\) から、セル状態に追加する新しい情報の「内容」を生成する。 | ハイパボリックタンジェント (\(\tanh\)) | -1 ~ 1 | 入力ゲート \(i_t\) と組み合わさりセル状態 \(C_t\) へ |
| 出力ゲート (\(o_t\)) | 更新されたセル状態 \(C_t\) から、どの情報を隠れ状態 \(h_t\) (兼 出力) として「出力する」かを決定する。 | シグモイド (\(\sigma\)) | 0 ~ 1 | \(\tanh(C_t)\) (要素ごとに積) |
このゲート制御により、LSTMは以下の大きな利点を手に入れました。
- 長期依存性の学習:セル状態が情報を比較的そのまま通しやすいため、遠い過去の情報も失われにくく、長期的な依存関係を捉えやすくなりました。
- 勾配消失・爆発問題の緩和:ゲートが情報の流れを適切にコントロールすることで、学習時の勾配が極端に小さくなったり大きくなったりするのを防ぎ、より安定した学習が可能になりました。
まさに、情報の流れを自動で最適化する、ものすごく賢い仕組みがLSTMの内部には組み込まれているのですね。この「ゲート」というアイデアは、その後の深層学習における様々なモデル(例えば、GRUやTransformerにおけるアテンション機構など)にも影響を与える、非常に画期的なものでした。
医療分野でLSTMがどのように活用されているか、そして実際にPyTorchを使ってこのLSTMモデルをどうやってプログラミングしていくのかは、この後のセクションで詳しく見ていきます。ここまでで、LSTMがなぜ「長期の記憶」と「短期の記憶」をうまく扱えるのか、その秘密の一端を感じ取っていただけたなら嬉しいです。次は、この理論を実際にコードに落とし込んでいくステップに進みましょう!
3. LSTMの学習プロセスを理解する:BPTTと計算グラフの視点から
この前のセクションでは、私たちはLSTMが「ゲート」という巧妙な仕掛けを使って、時系列データ中の情報を賢く取捨選択し、長期的な記憶を保持する仕組みについて深く掘り下げてきました。LSTMがどのように情報を「忘れたり」「覚えたり」「出力したり」するのか、その理論的な背景を理解できたことと思います。
しかし、AIモデルの真の力は、その「学習能力」にあります。LSTMが持つたくさんの重み行列やバイアスは、人間が手動で設定するものではなく、大量のデータから自動的に、そして最適な形で学習される必要があります。まるで、赤ちゃんが言葉や世界を少しずつ経験を通じて学んでいくように、LSTMもデータから「賢さ」を獲得していくのです。
このセクションでは、LSTMがどのようにして時系列データからパターンを学習し、その内部のパラメータ(重みやバイアス)を調整していくのか、その心臓部である「学習プロセス」に焦点を当てます。特に、時系列データ特有の学習方法である「誤差逆伝播法」(今回は「時間を遡る」という意味で「BPTT」と呼びます)の仕組みと、LSTMがなぜ従来のRNNよりもこの学習を効率的に行えるのかを、計算グラフという視点も交えながら、段階的に解き明かしていきましょう。
LSTMの計算グラフ:複雑な時間展開の構造を可視化する
AIモデルがどのように計算を行っているか、その内部の複雑な連携を直感的に捉えるための非常に便利な道具があります。それが「計算グラフ(Computation Graph)」です。これは、モデルの中で行われる一つひとつの計算(たとえば、足し算、掛け算、特定の関数を通すといった処理)を「ノード」と呼ばれる丸や四角で表現し、データや計算結果、そして学習に必要な「勾配」の流れを「エッジ」と呼ばれる矢印でつなぎ合わせたものです。このグラフを見ることで、普段はブラックボックスになりがちなモデルの内部動作が、まるで設計図のようにシンプルに可視化され、複雑なプロセスもぐっと理解しやすくなります。
特に、時間の流れに沿って変化するデータを扱うRNNやLSTMのようなモデルでは、計算グラフも「時間軸に沿って展開」されるのが特徴です。つまり、各時間ステップでの計算ユニットが横にずらっと並び、それぞれのユニットが過去の情報を次のユニットに渡しながら、計算を進めていく様子が描かれます。
少し具体的に考えてみましょう。例えば、医療現場で患者さんの日々のバイタルサイン(血圧、心拍数、体温など)が記録されるとします。LSTMモデルは、今日のバイタルサイン(入力\(x_t\))と、昨日の時点でモデルが記憶していた「隠れ状態(\(h_{t-1}\)」を受け取ります。そして、これらの情報を使って、今日の新たな「隠れ状態(\(h_t\))」と「セル状態(\(C_t\))」を計算するわけです。さらに、この今日計算された\(h_t\)と\(C_t\)が、明日(次の時間ステップ)の計算のための重要な材料として、次のLSTMユニットへと引き継がれていく…、この一連の流れが、時間軸に沿ってまるで鎖のように連なっていくのが、時系列モデルの計算グラフの基本的な形だとイメージしてみてください。
RNNの計算グラフのイメージ
従来のRNNは、隠れ状態(\(h\))のみを次の時間ステップに伝達していました。下の図を見ると、情報が隠れ状態のパスを介して、順々に隣のユニットへと流れていく様子がわかります。
この隠れ状態のパスは、情報が時間的に伝わる主要な経路です。しかし、この経路だけだと、長い時間を経て情報が伝わるうちに、その重要性が薄れてしまったり、ノイズに埋もれてしまったりする「長期依存性の問題」が起こりやすいのが、RNNの悩ましい点でした。
LSTMの計算グラフのイメージ
一方で、LSTMは、このRNNの隠れ状態(\(h\))のパスに加えて、特別な「セル状態(Cell State, \(C\))」というもう一つの情報伝達のパスを持っています。下の図では、セル状態が青色の太い線で示されており、あたかも情報が比較的ストレートに流れる「高速道路」のように、LSTMユニットを貫いているのが特徴です。
◎ 各要素の解説:
- 「入力: x(t)」: その時刻に入ってくる新しいデータ。
- 「LSTMユニット」: その時刻での計算処理を行うブロック(内部にはゲートが含まれる)。
- 「隠れ状態 h」: 前の時刻から引き継がれる短期的な記憶。出力にも使われる。
- 「セル状態 C」: 長期的な記憶を保持する専用のメインライン。情報が比較的ストレートに流れる。
- 「出力: y(t)」: その時刻でモデルが出す予測や結果。
この「高速道路」の存在が、LSTMの学習プロセスにおいて非常に大きな意味を持っています。計算グラフ上では、学習の際に誤差を逆方向に伝える「勾配」も、順方向の流れとは逆向きに伝播していきます。従来のRNNでは、この勾配が何度も同じ計算処理(重み行列の乗算など)を通過するうちに、途中で小さくなりすぎて失われてしまったり(勾配消失)、逆に大きくなりすぎて制御不能になったり(勾配爆発)する問題がありました。これは、情報が遠くまでうまく伝わらない「伝言ゲーム」のようなものです。
しかし、LSTMのセル状態のパスは、あたかも勾配の「ショートカット」が用意されているかのように機能するんです。このパスでは、重み行列の繰り返し乗算が避けられ、主に要素ごとの積や加算といった、勾配が極端に増減しにくい演算が行われます。このおかげで、遠い過去からの勾配も比較的「無傷」で、あるいは適切な調整を受けながら、現在のユニットまで伝わりやすくなります。これにより、LSTMは従来のRNNでは苦手としていた、数週間前、数ヶ月前といった「遠い過去の出来事」が「現在の状態」にどう影響するか、という「長期依存性(Long-term Dependencies)」を、より粘り強く、そして正確に学習できるようになるのです。
医療データのように、患者さんの症状が過去の投薬履歴や既往歴、あるいは数ヶ月前の生活習慣に根ざしていることは少なくありません。LSTMのこの構造は、まさにそうした長期的な文脈を捉えるために設計されたものだと考えると、その巧妙さに感心させられますね。この計算グラフの視点は、後の章で学ぶBPTTや勾配消失・爆発の問題を理解する上でも、非常に直感的で分かりやすい視点を与えてくれるはずです。
BPTT(Backpropagation Through Time):時間を遡って学習する仕組み
AIモデルが賢くなるために欠かせない「学習」のプロセス。その中心にあるのが「誤差逆伝播法(Backpropagation)」と呼ばれる非常に重要なアルゴリズムです。これは、モデルが何かを予測したとき、その予測が実際の正解(ラベル)とどれくらい「違っていたか」という「誤差(間違い)」を計算し、その誤差をモデルの出力層から入力層へと、まるで時間を巻き戻すかのように逆方向に伝えていく仕組みなんです。この「逆方向に伝わる間違いの情報」が「勾配(gradient)」と呼ばれ、これによって、モデル内の各パラメータ(重みやバイアス)が、予測の間違いにどれだけ貢献したのかが明らかになります。勾配が分かれば、あとはその情報に基づいてパラメータをほんの少しずつ修正していけば、モデルはだんだんと正確な予測ができるようになっていく、というわけです。
さて、LSTMのように、時間の流れに沿ったデータ(時系列データ)を扱うモデルの場合、この誤差逆伝播をただ行うだけでは不十分なんです。なぜなら、時系列データでは「過去の出来事が現在の状態や未来の予測に深く影響する」という性質があるからですね。患者さんの今日の体調不良が、数日前の投薬開始が原因かもしれないし、もしかしたら数ヶ月前の診断結果や生活習慣に根ざしている可能性もあります。もしAIモデルが「今日の体調不良」という予測ミスをしたとして、その原因が遠い過去にあるのなら、そこまで遡って「どこをどう直せばよかったのか」を学習しなければ、本当に賢い予測はできないですよね。
だからこそ、LSTMのような時系列モデルでは、この誤差逆伝播を「時間軸(Time)に沿って」行う必要があるんです。これを専門用語で「Backpropagation Through Time (BPTT)」と呼びます。
BPTTは、まさにこの「時間を遡る学習」をAIに実現させるアルゴリズムです。具体的に何をしているのかというと、最終的な出力(例えば、患者さんの数日後の病状予測)に生じた誤差を、それまでに情報を処理してきたすべての一連のLSTMユニット(各時間ステップの計算)に対して、逆方向に伝播させていくんです。先ほどの計算グラフで、各時刻のLSTMユニットが鎖のように繋がっていたのを思い出してみてください。その鎖を逆方向に辿りながら、それぞれのユニットが持つ重みやバイアスが、どの時間軸での情報にどう影響して、現在の誤差に繋がったのかを詳細に評価し、適切に更新していくわけです。
下のテキスト図は、BPTTの基本的な流れをテンソルの形状を意識しながらイメージで示しています。
【BPTTの学習プロセス:時間軸に沿った誤差逆伝播とテンソルの流れ】
ここでは、バッチサイズをB、入力特徴量次元をI、隠れ状態次元をH、出力次元をOとします。
graph TD
%% 順伝播 (Forward Pass) の流れ - 時間軸は上から下へ進行
subgraph time_tK["時刻 t-K (系列の開始点)"]
X_tK["入力 x(t-K)
(B, I)"]
h_init["h(t-K-1)
(B, H)
(初期状態)"]
C_init["C(t-K-1)
(B, H)
(初期状態)"]
LSTM_tK["LSTMユニット (t-K)
内部計算(ゲート制御含む)"]
X_tK --> LSTM_tK
h_init --> LSTM_tK
C_init --> LSTM_tK
LSTM_tK --> h_tK_out["h(t-K)
(B, H)"]
LSTM_tK --> C_tK_out["C(t-K)
(B, H)"]
end
%% 時刻 t-K+1
subgraph time_tK1["時刻 t-K+1"]
X_tK1["入力 x(t-K+1)
(B, I)"]
LSTM_tK1["LSTMユニット (t-K+1)
内部計算(ゲート制御含む)"]
X_tK1 --> LSTM_tK1
h_tK_out --> LSTM_tK1
C_tK_out --> LSTM_tK1
LSTM_tK1 --> h_tK1_out["h(t-K+1)
(B, H)"]
LSTM_tK1 --> C_tK1_out["C(t-K+1)
(B, H)"]
end
%% 時間ステップの進行
h_tK1_out --> TimeProgression["︙ (時間ステップが進む)"]
C_tK1_out --> TimeProgression
TimeProgression --> h_prev_t["h(t-1)
(B, H)"]
TimeProgression --> C_prev_t["C(t-1)
(B, H)"]
%% 最終時刻 t
subgraph time_t["最終時刻 t"]
X_t["入力 x(t)
(B, I)"]
LSTM_t["LSTMユニット (t)
内部計算(ゲート制御含む)"]
X_t --> LSTM_t
h_prev_t --> LSTM_t
C_prev_t --> LSTM_t
LSTM_t --> h_t_out["h(t)
(最終出力)
(B, H)"]
end
%% 予測と損失計算
h_t_out --> Y_hat["予測 y_hat(t)
(B, O)"]
Y_t["正解 y(t)
(B, O)"]
Y_hat --> Loss["損失 L (スカラー)
(予測 y_hat(t) と 正解 y(t) から計算)"]
Y_t --> Loss
テキスト図
1. 順伝播 (Forward Pass) の流れ(データが未来へ進む)
時間軸は上から下へ進行します
┌───────────────────────────────────────────┐
│ 時刻 t-K (系列の開始点) │
├───────────┬────────────────────────────┤
│ 入力 x(t-K) │ 形状: (B, I) │
└───────────┴────────────────────────────┘
│
▼
┌───────────────────────────────────────────┐
│ LSTMユニット (t-K) │
├───────────────────────────┬──────────────────┤
│ 入力: x(t-K) │ │
│ <- 前の隠れ状態 h(t-K-1) │ 形状: (B, H) │
│ <- 前のセル状態 C(t-K-1) │ 形状: (B, H) │
│ │ │
│ 内部計算(ゲート制御含む) │ │
└───────────────────────────┴──────────────────┘
│
▼ (h(t-K), C(t-K) を生成)
┌───────────────────────────────────────────┐
│ 時刻 t-K+1 │
├───────────┬────────────────────────────┤
│ 入力 x(t-K+1) │ 形状: (B, I) │
└───────────┴────────────────────────────┘
│
▼
┌───────────────────────────────────────────┐
│ LSTMユニット (t-K+1) │
├───────────────────────────┬──────────────────┤
│ 入力: x(t-K+1) │ │
│ <- h(t-K) │ 形状: (B, H) │
│ <- C(t-K) │ 形状: (B, H) │
│ │ │
│ ... (同様の計算が続く) │ │
└───────────────────────────┴──────────────────┘
│
▼
︙ (時間ステップが進む)
▼
┌───────────────────────────────────────────┐
│ 最終時刻 t │
├───────────┬────────────────────────────┤
│ 入力 x(t) │ 形状: (B, I) │
└───────────┴────────────────────────────┘
│
▼
┌───────────────────────────────────────────┐
│ LSTMユニット (t) │
├───────────────────────────┬──────────────────┤
│ 入力: x(t) │ │
│ <- h(t-1) │ 形状: (B, H) │
│ <- C(t-1) │ 形状: (B, H) │
│ │ │
│ 内部計算(ゲート制御含む) │ │
└───────────────────────────┴──────────────────┘
│
▼ (h(t) を最終出力として利用)
┌───────────────────────────────────────────┐
│ 予測 y_hat(t) │
├───────────┬────────────────────────────┤
│ 予測値 │ 形状: (B, O) │
└───────────┴────────────────────────────┘
│
▼
┌───────────────────────────────────────────┐
│ 損失 L │
├───────────┬────────────────────────────┤
│ スカラー値 │ (予測 y_hat(t) と 正解 y(t) から計算) │
└───────────┴────────────────────────────┘
graph BT
%% 誤差逆伝播 (Backward Pass - BPTT) の流れ - 時間軸は下から上へ逆流
AccGradients["全パラメータの勾配累積
→ モデルパラメータ更新(重みとバイアス調整)"]
subgraph BP_Process["誤差逆伝播 (Backward Pass)"]
direction BT %% フローの方向を明示的に下から上へ
subgraph time_tK_bp["時刻 t-K (系列の開始点)"]
Input_Grad_tK["dL/dh(t-K), dL/dC(t-K)
(前の時刻から受け取り)"]
LSTM_tK_bp["LSTMユニット (t-K)
内部でパラメータ勾配計算"]
Output_Grad_tKm1["dL/dh(t-K-1), dL/dC(t-K-1)
(初期状態への勾配伝播)"]
Input_Grad_tK --> LSTM_tK_bp
LSTM_tK_bp --> Output_Grad_tKm1
LSTM_tK_bp -- "各パラメータ勾配" --> AccGradients
end
TimeProgression_bp["︙ (時間ステップを遡る)"]
subgraph time_t_bp["最終時刻 t"]
Input_Grad_yhat_t["dL/dy_hat(t)
(B, O)"]
LSTM_t_bp["LSTMユニット (t)
内部でパラメータ勾配計算"]
Output_Grad_t_prev["dL/dh(t-1), dL/dC(t-1)
(前の時刻へ伝播)"]
Input_Grad_yhat_t --> LSTM_t_bp
LSTM_t_bp --> Output_Grad_t_prev
LSTM_t_bp -- "各パラメータ勾配" --> AccGradients
end
Loss_L["損失 L
(スカラー値)"]
Loss_L --> Input_Grad_yhat_t
Output_Grad_t_prev --> TimeProgression_bp
TimeProgression_bp --> Input_Grad_tK
end
テキスト図
2. 誤差逆伝播 (Backward Pass - BPTT) の流れ(勾配が過去へ遡る)
時間軸は下から上へ逆流します
┌───────────────────────────────────────────┐
│ 損失 L │
├───────────┬────────────────────────────┤
│ スカラー値 │ │
└───────────┴────────────────────────────┘
▲ (dL/dL = 1)
│
┌───────────────────────────────────────────┐
│ 最終時刻 t │
├───────────┬────────────────────────────┤
│ 勾配 dL/dy_hat(t) │ 形状: (B, O) │
└───────────┴────────────────────────────┘
▲
│ (dL/dh(t) と dL/dC(t) へ分配)
┌───────────────────────────────────────────┐
│ LSTMユニット (t) │
├───────────────────────────┬──────────────────┤
│ 受け取る勾配: │ │
│ dL/dy_hat(t) │ │
│ 計算される勾配: │ │
│ dL/dW_f(t), dL/db_f(t), dL/dW_i(t), dL/db_i(t) など │ (各パラメータの勾配) │
│ │ │
│ 伝播する勾配: │ │
│ dL/dh(t-1) ▲ (B, H) dL/dC(t-1) ▲ (B, H) │ │
└───────────────────────────┴──────────────────┘
▲
│
┌───────────────────────────────────────────┐
│ 前の時刻へ... │
├───────────────────────────┬──────────────────┤
│ dL/dx(t-1), dL/dh(t-1), dL/dC(t-1) など │ │
│ │ │
│ ... (同様の計算が逆方向に続く) │ │
└───────────────────────────┴──────────────────┘
▲
│
┌───────────────────────────────────────────┐
│ 開始時刻 t-K │
├───────────┬────────────────────────────┤
│ LSTMユニット (t-K) │
├───────────────────────────┬──────────────────┤
│ 受け取る勾配: │ │
│ dL/dh(t-K), dL/dC(t-K) │ │
│ 計算される勾配: │ │
│ dL/dW_f(t-K), dL/db_f(t-K), dL/dW_i(t-K), dL/db_i(t-K) など │ (各パラメータの勾配) │
│ │ │
│ 伝播する勾配: │ │
│ dL/dh(t-K-1) ▲ (B, H) dL/dC(t-K-1) ▲ (B, H) │ │
└───────────────────────────┴──────────────────┘
│
▼ (各ユニットで計算された勾配は累積される)
┌───────────────────────────────────────────┐
│ 最終的な全パラメータの勾配累積 (dW_total, db_total) │
├───────────┬────────────────────────────┤
│ 全時間ステップの勾配合計から │ │
│ モデルパラメータ更新(重みとバイアス調整)へ │ │
└───────────┴────────────────────────────┘
◎ 図の解説:
- 順伝播: 各LSTMユニットは、その時刻の入力 \(x_t\) と前の時刻からの隠れ状態 \(h_{t-1}\) およびセル状態 \(C_{t-1}\) を受け取ります。そして、内部の計算を経て、新しい隠れ状態 \(h_t\) とセル状態 \(C_t\) を生成し、次の時刻に引き継ぎます。最終時刻 \(t\) での出力 \(\hat{y}_t\) が、実際の正解 \(y_t\) と比較され、損失 \(L\) が計算されます。
- 誤差逆伝播(BPTT): 計算された損失 \(L\) は、時間軸を逆方向に(下から上へ)遡って伝播していきます。各LSTMユニットは、後続のユニットから伝わってきた勾配を受け取り、それを使って自身の内部パラメータ(重み \(W\) とバイアス \(b\))に対する勾配を計算します。同時に、その勾配をさらに前の時刻のユニットへと伝達します。このプロセスがすべての時間ステップにわたって行われ、それぞれの重みとバイアスが、最終的な損失にどれだけ影響を与えたかを示す勾配が算出されます。
- 勾配の累積: RNNやLSTMでは、同じ重み行列とバイアスがすべての時間ステップで共有されているため、各時間ステップで計算された勾配は、最終的に合算(累積)されます。この累積された勾配に基づいて、モデルのパラメータが更新されることで、モデルは時系列全体からパターンを学習できるようになるのです。
想像してみてください。ある治療の結果を振り返り、「あの時の検査結果と、その後の治療の選択が、現在の症状にどう影響したのか」を時間を巻き戻しながら検証し、次に生かすための教訓を得るようなイメージに近いかもしれませんね。BPTTは、この複雑な振り返り学習をAIが自動で行うための、非常に強力なアルゴリズムだと言えるでしょう。
このBPTTの働きによって、LSTMは時系列データに隠された長期的なパターンや因果関係を、単なる短期的な情報だけでなく、過去の文脈全体を考慮して学習できるようになるのです。これは、医療診断や予後予測といった、時間の経過が重要な意味を持つタスクにおいて、LSTMがその真価を発揮する基盤となります。
BPTTで登場する主なテンソルの形状まとめ
ここまでに登場した様々なテンソルが、どのような形状(次元)を持っているのかをまとめておきましょう。これらの形状は、モデルを実装する際や、エラーをデバッグする際に非常に役立ちます。
| テンソル名 | 解説 | 形状(次元) |
|---|---|---|
| \(x_t\) | 各時刻 \(t\) での入力データ | (Batch Size, Input Dimension) 例: \( (B, I) \) |
| \(h_t\) | 時刻 \(t\) での隠れ状態(短期記憶、ユニット出力) | (Batch Size, Hidden Dimension) 例: \( (B, H) \) |
| \(C_t\) | 時刻 \(t\) でのセル状態(長期記憶) | (Batch Size, Hidden Dimension) 例: \( (B, H) \) |
| \(\hat{y}_t\) | 時刻 \(t\) でのモデルの最終予測値 | (Batch Size, Output Dimension) 例: \( (B, O) \) |
| \(L\) | 最終的な損失(誤差) | (Scalar) 例: \( () \) または \( (1,) \) |
| \(\text{dL/dx}_t\) | 入力データ \(x_t\) に対する損失の勾配 | (Batch Size, Input Dimension) 例: \( (B, I) \) |
| \(\text{dL/dh}_t\) | 隠れ状態 \(h_t\) に対する損失の勾配 | (Batch Size, Hidden Dimension) 例: \( (B, H) \) |
| \(\text{dL/dC}_t\) | セル状態 \(C_t\) に対する損失の勾配 | (Batch Size, Hidden Dimension) 例: \( (B, H) \) |
| \(\text{dL/dW}\) | 重み行列 \(W\) に対する損失の勾配 | (Input Dimension + Hidden Dimension, 4 × Hidden Dimension) 例: \( (I+H, 4H) \) ※LSTM内部の重み(W_f, W_i, W_C, W_o)が結合されている場合 |
| \(\text{dL/db}\) | バイアスベクトル \(b\) に対する損失の勾配 | (4 × Hidden Dimension) 例: \( (4H,) \) ※LSTM内部のバイアス(b_f, b_i, b_C, b_o)が結合されている場合 |
※注意: 上記の重みとバイアスの形状は、PyTorchのnn.LSTMモジュールが内部でゲートの重みをまとめて管理している場合の一般的な表現です。個々のゲートの重みやバイアスを分解して考えることも可能ですが、ここでは簡略化しています。
LSTMのパラメータ更新:ゲートごとの重み行列の学習方法
BPTTという学習の仕組みは、時系列データからパターンを見つけ出す上で大変強力ですが、従来のRNNでは「勾配消失(Vanishing Gradient)」と「勾配爆発(Exploding Gradient)」という、学習を大きく妨げる厄介な問題に悩まされてきました。正直なところ、この現象は多くの研究者にとって頭の痛い課題だったんです。
勾配消失:遠い過去の記憶が薄れてしまう現象
「勾配消失」とは、学習時に誤差の情報を過去に遡って伝えていく(誤差逆伝播)過程で、その「勾配」の値がどんどん小さくなっていき、最終的にはほとんどゼロに近づいてしまう現象を指します。勾配がゼロに近くなると、モデルは「どこをどれだけ修正すれば良いか」が分からなくなり、実質的に学習がストップしてしまいます。まるで、遠くにいる人に「大事な伝言」を伝えようとしても、途中で声が小さくなりすぎて届かなくなってしまうようなものですね。
特に、数週間前や数ヶ月前といった「遠い過去の出来事」が「現在の状態」に影響を与えるような「長期依存性」を学習したい場合に、この勾配消失は顕著に現れました。古い情報に関わるパラメータの勾配が消えてしまうので、どれだけ学習させても、古い情報を効果的に利用できるようにならないのです。
なぜこのようなことが起こるのでしょうか? RNNの内部では、前の時刻の隠れ状態(\(h_{t-1}\))と現在の入力(\(x_t\))を使って、新しい隠れ状態(\(h_t\))を計算します。この計算には、重み行列を掛け合わせたり、活性化関数(例えば \(\tanh\) やシグモイド)を通したりするプロセスが含まれます。誤差が逆方向に伝わる際、この活性化関数の「導関数」(勾配の大きさを決定する要素)が繰り返し掛け合わされます。例えば、\(\tanh\) 関数の導関数は常に0から1の間の値を取るため、もしこの値が1より小さい(例えば0.5)と、誤差が1ステップ逆伝播するたびに勾配が半減する、といったことが起こります。これを何十回、何百回と繰り返すと、元の勾配がどれほど大きくても、あっという間にゼロに近づいてしまうんです。
【勾配消失のイメージ:逆伝播の伝言ゲーム】
損失 (誤差)
↓ (勾配の伝播)
[時刻 t] : 勾配(大) → 処理の逆伝播 (×0.5)
↓
[時刻 t-1] : 勾配(中) → 処理の逆伝播 (×0.5)
↓
[時刻 t-2] : 勾配(小) → 処理の逆伝播 (×0.5)
↓
...
↓
[時刻 t-N] : 勾配(ほぼ0) → 伝わらない!
◎ 解説:
- 順方向への情報伝達と同様に、逆方向への勾配伝播も時間軸に沿って行われます。
- 各時間ステップで、勾配は活性化関数の導関数などによって乗算されます。
- この乗算が繰り返されることで、もし乗数が1未満の小さな値だと、勾配は指数関数的に減衰し、
遠い過去の層ではほとんど情報が伝わらなくなってしまいます。
- これが「勾配消失」の主要な原因です。
勾配爆発:制御不能な学習
逆に「勾配爆発」は、勾配が時間を遡るにつれて指数関数的に大きくなり、とんでもなく巨大な値になってしまう現象です。こうなると、モデルのパラメータがほんの少し更新されただけで予測が大きく変動してしまい、学習が不安定になったり、場合によっては発散(モデルが学習できなくなる状態)してしまったりします。まるで、小さな声がエコーでどんどん大きくなりすぎて、何を言っているか全く分からなくなるような状況を想像してみてください。
勾配爆発も、RNNの重み行列が繰り返し乗算される構造に起因します。もし重み行列の値が大きすぎる場合、誤差が逆伝播するたびにその大きな値が繰り返し掛け合わされ、勾配が制御不能なほどに増大してしまうのです。
【勾配爆発のイメージ:逆伝播の暴走】
損失 (誤差)
↓ (勾配の伝播)
[時刻 t] : 勾配(小) → 処理の逆伝播 (×2.0)
↓
[時刻 t-1] : 勾配(中) → 処理の逆伝播 (×2.0)
↓
[時刻 t-2] : 勾配(大) → 処理の逆伝播 (×2.0)
↓
...
↓
[時刻 t-N] : 勾配(巨大すぎ!) → 学習が不安定化・発散
◎ 解説:
- 各時間ステップで、勾配が重み行列の転置などの大きな値によって乗算されます。
- この乗算が繰り返されることで、もし乗数が1より大きな値だと、勾配は指数関数的に増大し、
とてつもなく大きな値になってしまいます。
- これが「勾配爆発」の主要な原因です。
セル状態による勾配の「高速道路」:その真価
LSTMのセル状態(\(C_t\))が、なぜ「高速道路」と例えられるほど、勾配消失・爆発問題に強いのか、その仕組みをもっと深く掘り下げていきましょう。私も初めてこの話を聞いた時、なかなかピンとこなかったのですが、具体的な計算を見ていくと、その巧妙さに感心させられますよ。
LSTMのセル状態(\(C_t\))は、まさしく時間軸に沿って情報が比較的ストレートに流れる「高速道路」のようなパスを持っています。従来のRNNでは、情報が隠れ状態を通じて時間ステップごとに同じ重み行列を繰り返し掛け合わせられるため、勾配が連鎖的に乗算され、結果として勾配が極端に小さくなったり(消失)、逆に極端に大きくなったり(爆発)する問題に直面していました。
ところが、LSTMのセル状態のパスは、このRNNの構造とは一線を画しています。情報が重み行列を繰り返し掛け合わせられることなく、主に「要素ごとの積(アダマール積、\(\odot\))」と「要素ごとの加算(\(+\))」という演算によって更新される点が非常に重要なんです。このシンプルな仕組みこそが、勾配の安定的な伝播を可能にしているんですよ。
セル状態の更新式を改めて見てみましょう。
\[ C_t = (f_t \odot C_{t-1}) + (i_t \odot \tilde{C}_t) \]
ここで、\(f_t\) は忘却ゲート、\(i_t\) は入力ゲート、\(\tilde{C}_t\) は新しい記憶の候補でしたね。この式を見ると、現在のセル状態 \(C_t\) は、一つ前のセル状態 \(C_{t-1}\) に忘却ゲート \(f_t\) を掛け合わせたものと、新しく追加される情報 \(i_t \odot \tilde{C}_t\) の和で構成されているのがわかります。
勾配が「線形」に近い形で伝播する理由
さあ、いよいよ本題です。勾配が逆伝播する際、\(\frac{\partial C_t}{\partial C_{t-1}}\) の部分が単純に \(f_t\) となると言われても、最初は少し戸惑うかもしれません。でも、これは連鎖律(チェーンルール)を考えれば納得がいきます。
損失関数 \(L\) からセル状態 \(C_{t-1}\) への勾配 \(\frac{\partial L}{\partial C_{t-1}}\) を求めることを考えます。連鎖律を用いると、以下のようになります。
\[ \frac{\partial L}{\partial C_{t-1}} = \frac{\partial L}{\partial C_t} \odot \frac{\partial C_t}{\partial C_{t-1}} \]
ここで、\(C_t = (f_t \odot C_{t-1}) + (i_t \odot \tilde{C}_t)\) という式から、\(C_{t-1}\) に関する偏微分 \(\frac{\partial C_t}{\partial C_{t-1}}\) を計算してみましょう。加算の右側の項 \((i_t \odot \tilde{C}_t)\) は \(C_{t-1}\) に依存しないため、微分すると0になります。残るのは \((f_t \odot C_{t-1})\) の部分です。要素ごとの積の微分法則を適用すると、
\[ \frac{\partial}{\partial C_{t-1}} (f_t \odot C_{t-1}) = f_t \]
となります。(つまり、\(f_t \cdot x\) を \(x\) で微分すると \(f_t\) になるのと同じ感覚です。)
したがって、先ほどの勾配の伝播式は次のようになります。
\[ \frac{\partial L}{\partial C_{t-1}} = \frac{\partial L}{\partial C_t} \odot f_t \]
驚くほどシンプルですよね。この式が示すのは、損失 \(L\) の勾配が \(C_t\) から \(C_{t-1}\) へと逆伝播する際、単に忘却ゲート \(f_t\) の値が要素ごとに掛け合わされる、ということです。
要素ごとの積(アダマール積)の勾配特性と安定性
この要素ごとの積(アダマール積)という演算が、勾配の安定性において非常に重要な役割を担っています。一般的な行列乗算とは異なり、アダマール積は勾配が極端に増減するのを効果的に抑える性質を持っているんです。
例えば、ある演算結果 \(Y = A \odot B\) があり、これに対する損失 \(L\) の勾配 \(\frac{\partial L}{\partial Y}\) が与えられているとします。このとき、入力 \(A\) に対する勾配 \(\frac{\partial L}{\partial A}\) は、以下のように計算されます。
\[ \frac{\partial L}{\partial A} = \frac{\partial L}{\partial Y} \odot B \]
同様に、\(B\) に対する勾配は \(\frac{\partial L}{\partial B} = \frac{\partial L}{\partial Y} \odot A\) となります。
これは、もし \(Y_k = A_k B_k\) (要素ごと) であれば、\(\frac{\partial Y_k}{\partial A_k} = B_k\) となるため、連鎖律 \(\frac{\partial L}{\partial A_k} = \frac{\partial L}{\partial Y_k} \frac{\partial Y_k}{\partial A_k} = \frac{\partial L}{\partial Y_k} B_k\) がそのままテンソル全体に適用されることを意味します。
なぜこれが安定性につながるのか?
その理由は、ゲート(\(f_t\) や \(i_t\))の値がシグモイド関数(\(\sigma\))によって出力されるため、常に 0から1の間の値 に収まるからです。
\[ \sigma(x) = \frac{1}{1 + e^{-x}} \]
| $x$ (入力) | $\sigma(x)$ (出力) |
|---|---|
| 極めて小さい(負) | 0 に近い |
| 0 | 0.5 |
| 極めて大きい(正) | 1 に近い |
つまり、勾配 \(\frac{\partial L}{\partial C_t}\) に、0から1の範囲の値である \(f_t\) が要素ごとに掛け合わされることになります。
- もし \(f_t\) が 1に近い なら、勾配はほぼそのまま伝播します。
- もし \(f_t\) が 0に近い なら、勾配はほぼゼロになり、それ以上奥に伝播するのを防ぎます。
これはまるで、高速道路に設けられた料金所のようなイメージです。必要な情報(勾配)はスムーズに通過させ、不要な情報(勾配)は遮断する。一般的なRNNのように、重み行列という「未知のスケール因子」が何度も掛け合わされることで勾配が爆発したり消失したりするのとは異なり、LSTMではこの安定した0〜1の範囲の値で勾配がスケーリングされるため、勾配の大きさが極端に変動しにくくなるのです。
勾配伝播の具体的なイメージ
では、この勾配の伝播をもう少し視覚的に捉えてみましょう。
セル状態 \(C_t\) と忘却ゲート \(f_t\) は同じ次元(形状)を持っています。例えば、バッチサイズを B、隠れ状態の次元を H とすると、どちらも [B, H] の形状になります。
勾配の伝播は、以下のような要素ごとの積で行われます。
# dL/dC_t: C_tに対する損失Lの勾配(逆伝播してきた勾配)
# f_t: 忘却ゲートの値(0から1の範囲)
[ dL/dC_t ] [ f_t ] [ dL/dC_{t-1} ]
+---------+ +-----+ +-------------+
| | | | | |
| B x H | o | B x H | = | B x H |
| | | | | |
+---------+ +-----+ +-------------+
(要素ごとの積)
この図が示しているのは、現在のセル状態の勾配 dL/dC_t が、忘却ゲート f_t とアダマール積されることで、一つ前のセル状態 C_{t-1} への勾配 dL/dC_{t-1} が計算されるという流れです。
もう少し詳細に、テンソルの形状をブロックとして示すと、こんな感じになります。
勾配伝播のイメージ: dL/dC_{t-1} = (dL/dC_t) o f_t
損失Lの勾配が、C_tからC_{t-1}へ伝播する様子
仮定:
batch_size (B) = 32
hidden_size (H) = 256
dL/dC_t (現在のセル状態C_tに対する損失Lの勾配)
これは逆伝播の過程で既に計算されている値です。
テンソル形状: (Batch_Size=32, Hidden_Size=256)
+-------------------------------------+
| |
| dL/dC_t (Gradient) |
| (Batch_Size x Hidden_Size) |
| [ 32 x 256 ] |
| |
+-------------------------------------+
|
v (要素ごとの積: アダマール積 'odot')
f_t (忘却ゲートの出力値)
この値は、シグモイド関数を通るため0から1の範囲です。
テンソル形状: (Batch_Size=32, Hidden_Size=256)
+-------------------------------------+
| |
| f_t (Forget Gate) |
| (Batch_Size x Hidden_Size) |
| [ 32 x 256 ] |
| |
+-------------------------------------+
|
v (計算結果)
dL/dC_{t-1} (一つ前のセル状態C_{t-1}に対する損失Lの勾配)
テンソル形状: (Batch_Size=32, Hidden_Size=256)
+-------------------------------------+
| |
| dL/dC_{t-1} (Propagated Gradient) |
| (Batch_Size x Hidden_Size) |
| [ 32 x 256 ] |
| |
+-------------------------------------+
【セル状態における勾配の流れ:勾配消失を緩和する仕組み】
損失 L
↓ (勾配の伝播)
dL/dCt ──────────────────────▶ dL/dCt (時刻 t のセル状態の勾配)
│
│ (C_t = (f_t ⊙ C_{t-1}) + (i_t ⊙ C_tilde_t))
│ の逆伝播を考える
│
│ dL/dCt から dL/dCt-1 への勾配伝播は
│ 主に f_t (忘却ゲートの値) の乗算になる
▼
dL/dCt-1 = dL/dCt ⊙ f_t (時刻 t-1 のセル状態の勾配)
│
│ (C_{t-1} = (f_{t-1} ⊙ C_{t-2}) + ...)
│ の逆伝播を考える
▼
dL/dCt-2 = dL/dCt-1 ⊙ f_{t-1} (時刻 t-2 のセル状態の勾配)
...
◎ 解説:
- セル状態のパスでは、勾配は主に忘却ゲートの値 \(f_t\) と要素ごとの積(アダマール積)で伝播します。
- \(f_t\) は0から1の間の値を取るため、勾配を減衰させる可能性はありますが、従来のRNNのように活性化関数の導関数(例えばtanhの導関数は常に1未満)を繰り返し掛けることで、必然的に勾配がゼロに近づいていくわけではありません。
- もし \(f_t\) の値が1に近い場合(LSTMが「この情報は忘れない方がいい」と判断した場合)、勾配はほとんど減衰せずにそのまま伝播します。
- このように、長期的な依存関係の学習に重要な情報には、勾配がスムーズに伝わる「高速道路」が確保されることで、遠い過去の情報も学習に活かされやすくなるのです。
つまり、勾配が直接、忘却ゲートの値(0から1の範囲)と掛け合わされるため、もし忘却ゲートが「この情報は重要だから忘れない!」(値が1に近い)と判断すれば、その勾配はほぼそのまま伝わります。これは、RNNが常に小さな値(活性化関数の導関数)を掛け続けて勾配が消えてしまうのと対照的です。例えるなら、高速道路を走る車が、一般道の渋滞に巻き込まれずに目的地に到達できるようなもので、遠い過去からの勾配も消失しにくく、長期依存性の学習が格段に容易になったわけです。
ゲートによる勾配の「交通整理」
さらに、忘却ゲートだけでなく、入力ゲート、出力ゲートといった各ゲートは、それぞれがシグモイド関数(出力が0〜1)を使っています。これらのゲートは、単に情報がセル状態にどれだけ流れるかを制御するだけでなく、勾配が逆方向に伝播する際にも重要な「交通整理役」として機能します。
- もしゲートの値が0に近ければ、その経路の勾配はほぼ遮断され、それ以上伝播しません(忘れるべき情報や不要な入力は、勾配もそこでブロックされます)。これは、ノイズや関連性の低い情報が学習に悪影響を与えるのを防ぐ賢い仕組みですね。
- もしゲートの値が1に近ければ、その経路の勾配はほぼそのまま伝播します(重要な情報は、勾配もスムーズに伝播します)。これにより、モデルが本当に学習すべき部分に効率的に勾配が届くようになります。
この賢い制御によって、勾配が極端に大きくなったり小さくなったりするのを防ぎ、学習がより安定し、効率的に進むようになるんです。たとえば、学習の初期段階で勾配が暴走しそうになっても、ゲートがその流れを適切に絞り込むことで、発散を防ぐことができます。逆もまた然りで、勾配が小さくなりすぎそうな時も、ゲートが開きっぱなしになることで、必要な情報が遠くまで届くよう促してくれるわけです。
このようなLSTMの内部構造は、まさにAI研究者たちの知恵と工夫の結晶だと私は強く感じますね。勾配消失・爆発というRNNの「持病」を、セル状態という「高速道路」と、ゲートという「交通整理役」によって見事に克服した結果、LSTMは様々な時系列データにおいてその真価を発揮し、今日の深層学習の発展に大きく貢献しているんですよ。
医療分野でのLSTMの安定した学習能力の重要性
医療分野のデータは、時に非常に複雑で、長期的な文脈が極めて重要になることが多いです。例えば、患者さんの数十日、数百日、あるいは数年分のバイタルサイン、検査値、投薬記録、画像診断レポートといった時系列データから、病気の微細な進行、治療効果の遅延、あるいは将来の発症リスクを予測しようとする場合を考えてみてください。もしここで勾配消失や爆発の問題に直面したら、モデルは必要な長期的なパターンを学習できず、誤った予測を出してしまうかもしれません。
しかし、LSTMは、これらの長期的なパターンを、勾配消失・爆発の問題に悩まされることなく、粘り強く学習することができます。これにより、次のような高度な分析や予測が可能になります。
- 疾患の早期発見: 数ヶ月前の検査値の微細な変化から、将来の糖尿病や心血管疾患のリスクを予測。
- 治療効果の評価: 特定の薬剤投与から時間が経って現れる効果や副作用のパターンを分析。
- 患者の予後予測: ICU患者の過去数日間のバイタルサイン推移から、今後の容態変化や予後を正確に予測。
このように、LSTMの安定した学習能力は、医療データという複雑な情報の中から、人間だけでは見つけにくい重要な長期的な洞察をAIが獲得するための、非常に強力な武器となるのです。これは、医療現場の課題解決にAIを応用する私たちにとって、まさに希望の光と言えるのではないでしょうか。
学習ステップの可視化:PyTorchで見る一連の誤差逆伝播の流れ
さて、ここまでLSTMが持つ「賢い記憶の仕組み」や、その記憶を最適化するための「BPTT」という学習の考え方について深く掘り下げてきました。概念的には理解できたけれど、「じゃあ、実際にコードを書くとき、この複雑な計算ってどうなってるの?」と疑問に感じる方もいらっしゃるかもしれませんね。実は、ここがPyTorchのような深層学習フレームワークの真骨頂なんです。
私たちは、LSTMの内部で勾配がどのように伝播するのか、その複雑な数学的詳細をすべて手動で計算する必要はありません。PyTorchは、その裏側で「自動微分(Autograd)」という強力なエンジンを動かしてくれます。これは、まるで私たちが目的地までの道のりを詳しく知らなくても、カーナビが最適なルートを教えてくれるように、PyTorchが勾配計算の「面倒な部分」をすべて引き受けてくれる、というイメージでしょうか。
Autogradのおかげで、私たちはモデルの設計(どんな層をどう組み合わせるか)や、データがどう流れるか(順伝播)というロジックに集中できるようになります。この設計思想は、医療分野のAI開発者にとって非常に大きなメリットをもたらします。臨床的な課題やデータ特性の理解に時間を割き、AIの核心的な計算部分はフレームワークに任せることで、より迅速かつ効率的に、実践的なモデルを開発できるようになるんです。
では、具体的にPyTorchでLSTMモデルを学習させる際の一連のステップを、もう一度見ていきましょう。
1. モデルのインスタンス化と初期化
まず、PyTorchのnn.Moduleを継承して定義したLSTMモデル(前章で作成したLSTMModelクラスなど)をコンピュータのメモリ上に「実体」として生成します。この時点では、モデル内のすべての重み行列やバイアスは、まだ学習が進んでいないため、通常はランダムな値で初期化されています。
# モデルのインスタンスを作成
model = LSTMModel(input_dim, hidden_dim, num_layers, output_dim)
# モデルを計算デバイス(GPUまたはCPU)に移動
model.to(device)
ここで、.to(device)と書くことで、モデルのパラメータをCPUで計算するか、GPUで計算するかを指定できます。GPUがあれば、深層学習の計算は圧倒的に速くなりますね。
2. 順伝播 (Forward Pass)
学習の各ステップ(イテレーション)では、まず入力データ(inputs)をモデルに渡して、予測値(outputs)を得ます。これが「順伝播」と呼ばれるプロセスです。
outputs = model(inputs)
このたった一行のコードの裏側で、PyTorchのAutogradが素晴らしい仕事をしてくれています。入力データがLSTMレイヤーを順に通過し、各ゲートの計算、セル状態の更新、隠れ状態の生成、そして最終的な全結合層による出力計算が、まるで精密な工場のように実行されています。この順伝播の過程で、PyTorchは、どの計算がどのテンソル(データ)に対して行われたかという「計算グラフ」を自動的に構築します。これは、後で勾配を計算するために必要な「道のり」を、ひそかに記録しているようなものです。例えば、入力テンソルがどのように形を変え、LSTMレイヤーを通り、最終的な出力になるかを、イメージで見てみましょう。
【順伝播におけるテンソルの形状変化のイメージ】
入力データ `inputs` (バッチサイズ, シーケンス長, 入力特徴量数)
例: (32, 10, 1) (32個のデータ、それぞれ10時間ステップ分の1つの特徴量)
┌─────────────────────────────────┐
│ [バッチ1, シーケンス1-10, 特徴量1] │
│ [バッチ2, シーケンス1-10, 特徴量1] │
│ ... │
│ [バッチ32, シーケンス1-10, 特徴量1]│
└─────────────────────────────────┘
↓
`self.lstm` レイヤー
↓
LSTMの各時間ステップの出力 `out` (バッチサイズ, シーケンス長, 隠れ状態の次元数)
例: (32, 10, 64) (隠れ状態が64次元の場合)
┌─────────────────────────────────┐
│ [バッチ1, 時刻1, 隠れ状態64D] ... [バッチ1, 時刻10, 隠れ状態64D] │
│ [バッチ2, 時刻1, 隠れ状態64D] ... [バッチ2, 時刻10, 隠れ状態64D] │
│ ... │
│ [バッチ32, 時刻1, 隠れ状態64D] ... [バッチ32, 時刻10, 隠れ状態64D]│
└─────────────────────────────────┘
↓
`out[:, -1, :]` (最後の時間ステップの出力だけを選択)
例: (32, 64) (各バッチの最後の隠れ状態64D)
┌─────────────────────┐
│ [バッチ1, 隠れ状態64D] │
│ [バッチ2, 隠れ状態64D] │
│ ... │
│ [バッチ32, 隠れ状態64D]│
└─────────────────────┘
↓
`self.fc` (全結合層)
↓
最終予測 `outputs` (バッチサイズ, 出力次元数)
例: (32, 1) (各バッチの1つの予測値)
┌───────────┐
│ [バッチ1, 予測値] │
│ [バッチ2, 予測値] │
│ ... │
│ [バッチ32, 予測値]│
└───────────┘
3. 損失計算 (Loss Calculation)
モデルが予測を出したら、次にその予測がどれだけ「間違っていたか」を数値で評価します。これが「損失(Loss)」の計算です。予測値(outputs)と実際の正解値(labels)を比較して、その差を損失関数(criterion)で計算します。
# 損失を計算 (予測値と正解ラベルの間の誤差)
loss = criterion(outputs, labels)
この例では、連続した数値(サインカーブの次の値)を予測するタスクなので、誤差の二乗を平均する「平均二乗誤差(MSE: Mean Squared Error)」が使われます。数式で書くと、以下のようになります。
\[ \text{MSE} = \frac{1}{N} \sum_{i=1}^{N} (y_i – \hat{y}_i)^2 \]
ここで、
- \(N\): データサンプルの総数
- \(y_i\): \(i\)番目のデータサンプルの実際の正解値(
labels) - \(\hat{y}_i\): \(i\)番目のデータサンプルのモデルによる予測値(
outputs)
つまり、各予測と正解の差を二乗し、それらを全て合計してからデータ数で割った値が損失となります。この損失が小さければ小さいほど、モデルの予測は正確だということになります。
4. 勾配のリセット (Zero Gradients)
いよいよ誤差逆伝播の準備です。その前に、とても重要なステップがあります。それは、オプティマイザ(後で説明します)に蓄積されている「勾配」をすべてゼロにリセットすることです。
# オプティマイザの勾配をリセット
# これをしないと前回のバッチの勾配が加算されてしまう
optimizer.zero_grad()
もしこのステップを怠ると、前のミニバッチで計算された勾配が、現在のミニバッチの勾配に「累積」されてしまいます。想像してみてください、もし何度も同じ間違いを「間違った方向」に足し続けていたら、学習は決して正しい方向に進みませんよね。毎回まっさらな状態で勾配を計算するためにも、このリセットは欠かせないんです。
5. 誤差逆伝播 (Backward Pass)
さあ、学習のまさに核心部分です。計算された損失(loss)に対して、たった一つのメソッドを呼び出すだけで、PyTorchのAutogradが魔法のように誤差逆伝播を実行してくれます。
# 誤差逆伝播を実行 (損失に対する各パラメータの勾配を計算)
loss.backward()
このloss.backward()が呼び出されると、PyTorchは順伝播の際に構築しておいた計算グラフを、今度は「逆方向」に辿っていきます。そして、連鎖律(Chain Rule)という数学の法則を使って、最終的な損失が、モデル内の各重み行列やバイアスといったパラメータのそれぞれに、どれだけ「影響された」かを数値(勾配)として計算してくれるんです。これは、まさに「どのパラメータが、どれだけ予測の間違いに貢献したか」を割り出す作業に他なりません。
上記で解説した「BPTT」は、PyTorchのこのbackward()メソッドの内部で自動的に実行されます。LSTMのセル状態が勾配を「高速道路」のように伝播させたり、ゲートが勾配の「交通整理」をしたりといった複雑なメカニズムも、私たち開発者が意識することなく、PyTorchが適切に処理してくれます。これが、深層学習フレームワークを使う大きなメリットの一つなんです。複雑な数学を理解することは重要ですが、それをコードに落とし込む際の労力をフレームワークが大幅に削減してくれるおかげで、私たちは「どんな問題を解きたいか」「どんなデータを使えば良いか」といった、より実践的な部分に集中できる、というわけですね。
6. パラメータ更新 (Parameter Update)
誤差逆伝播によって、モデル内のすべての学習可能なパラメータに対する勾配が計算されました。最後に、これらの勾配を使って、実際にモデルのパラメータの値を更新します。この役割を担うのが「最適化アルゴリズム(Optimizer)」です。ここでは、Adamという非常に人気のある最適化アルゴリズムを使っています。
# パラメータを更新 (計算された勾配に基づいてモデルの重みを調整)
optimizer.step()
optimizer.step()メソッドが呼び出されると、Adamのようなアルゴリズムは、計算された勾配に加えて、事前に設定された「学習率(Learning Rate)」(通常は非常に小さな値、例えば0.001など)や、場合によっては過去の勾配情報(「モーメンタム」と呼ばれる、学習の勢いのようなもの)を用いて、モデルの重みとバイアスを少しずつ、しかし着実に調整していきます。学習率が大きすぎると、更新量が大きすぎて不安定になったり、最適解を飛び越えたりする可能性があります。逆に小さすぎると、学習が非常にゆっくりになる、といった特性があります。
このパラメータの更新によって、モデルは次のイテレーション(ミニバッチ処理)では、少しだけ前よりも賢くなり、より正確な予測ができるように調整されるのです。この一連のステップが、指定された「エポック数」(データセット全体を何回学習するか)だけ繰り返されることで、LSTMモデルはデータからパターンを抽出し、より正確な予測ができるように賢く成長していくわけです。
PyTorchのこのような設計は、医療分野のAI開発者にとって非常に大きな利点をもたらします。複雑な数学的な詳細(特に勾配計算)に時間を費やすことなく、LSTMモデルの設計、データの前処理、結果の解釈といった、より本質的な課題に集中できるようになるからです。これにより、医療現場での具体的な課題解決に繋がるAIモデルを、より迅速かつ効率的に開発できる可能性が大きく広がると、私は信じています。
このセクションの参考文献
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9(8):1735-80.
- Rumelhart DE, Hinton GE, Williams RJ. Learning representations by back-propagating errors. Nature. 1986;323(6088):533-6.
- Pascanu R, Mikolov T, Bengio Y. On the difficulty of training recurrent neural networks. Proc Int Conf Mach Learn. 2013;28:I-1310-I-1318.
- Pytorch Documentation. Autograd: automatic differentiation. Available from: https://pytorch.org/docs/stable/notes/autograd.html
4. PyTorchでLSTMを実装してみよう
4.1 準備:必要なライブラリのインポート
まず、PyTorch関連のライブラリをインポートします。
# PyTorchのコアライブラリ
import torch
# ニューラルネットワークのモジュール(LSTMレイヤーや全結合層などを含む)
import torch.nn as nn
# 最適化アルゴリズムのモジュール(SGDやAdamなどを含む)
import torch.optim as optim
# データローダーを作成するためのユーティリティ
from torch.utils.data import DataLoader, TensorDataset
# 数値計算のためのライブラリ (データの準備に使用)
import numpy as np
# グラフ描画のためのライブラリ (結果の可視化に使用)
import matplotlib.pyplot as plt
# 日本語フォントの設定(matplotlibで日本語を表示するため)
# ご自身の環境に合わせてフォント名を指定してください
# 例: 'IPAexGothic', 'MS Gothic' (Windows), 'Hiragino Sans' (Mac)
# フォントがない場合は、適宜インストールするか、英語での表示にしてください。
# plt.rcParams['font.family'] = 'IPAexGothic' # Linux/MacでIPAフォントがある場合
try:
# Windows環境でMeiryoフォントを試みる
plt.rcParams['font.family'] = 'Meiryo'
except RuntimeError:
try:
# Colabや他の環境でIPAexGothicフォントを試みる
plt.rcParams['font.family'] = 'IPAexGothic'
except RuntimeError:
# フォントが見つからない場合は警告を表示
print("日本語フォントが見つかりません。グラフのラベルが文字化けする可能性があります。")
4.2 サンプルデータの準備
ここでは、簡単な例として、サインカーブを予測するタスクを考えます。過去の数点のデータから次の1点を予測するモデルを作成します。
# シード値を固定して再現性を確保
np.random.seed(0) # NumPyの乱数シードを固定
torch.manual_seed(0) # PyTorchの乱数シードを固定 (CPU)
# データ生成
# 0から50までの値を0.1刻みで生成 (500点)
timesteps = np.arange(0, 50, 0.1)
# 対応するサインカーブの値を生成
data = np.sin(timesteps)
# 時系列データをLSTMの入力形式に変換
sequence_length = 10 # 過去10点のデータから次の1点を予測
X = [] # 入力シーケンスを格納するリスト
y = [] # 対応する正解ラベルを格納するリスト
# dataの長さからsequence_lengthを引いた回数だけループ
# これにより、十分な長さのシーケンスと対応するターゲットが取れる
for i in range(len(data) - sequence_length):
# iからi+sequence_length-1 までのデータを入力 (X) とする
X.append(data[i:i+sequence_length])
# i+sequence_length の時点のデータを正解 (y) とする
y.append(data[i+sequence_length])
# NumPy配列に変換
X = np.array(X) # リストXをNumPy配列に変換
y = np.array(y) # リストyをNumPy配列に変換
# PyTorchのテンソルに変換
# LSTMは (バッチサイズ, シーケンス長, 入力特徴量の次元数) の形式を期待する
# 今回、入力特徴量の次元数は1 (サインカーブの値そのもの)
# .unsqueeze(2)で末尾に次元を追加し、(サンプル数, sequence_length, 1)の形状にする
X_tensor = torch.FloatTensor(X).unsqueeze(2)
# 正解ラベルもテンソルに変換し、(サンプル数, 1)の形状にする
y_tensor = torch.FloatTensor(y).unsqueeze(1)
# 変換後のデータの形状を表示
print(f"入力データの形状: {X_tensor.shape}")
print(f"正解データの形状: {y_tensor.shape}")
# 訓練データとテストデータに分割 (例: 全体の80%を訓練用、残りをテスト用)
split_ratio = 0.8 # 訓練データの割合
train_size = int(len(X_tensor) * split_ratio) # 訓練データのサンプル数を計算
# 訓練データのスライス
X_train = X_tensor[:train_size]
y_train = y_tensor[:train_size]
# テストデータのスライス
X_test = X_tensor[train_size:]
y_test = y_tensor[train_size:]
# 分割後の各データの形状を表示
print(f"訓練用入力データの形状: {X_train.shape}")
print(f"訓練用正解データの形状: {y_train.shape}")
print(f"テスト用入力データの形状: {X_test.shape}")
print(f"テスト用正解データの形状: {y_test.shape}")
# DataLoaderの作成 (ミニバッチ学習のため)
batch_size = 32 # 一度に処理するサンプル数(ミニバッチのサイズ)
# 訓練データセットの作成 (入力と正解のペア)
train_dataset = TensorDataset(X_train, y_train)
# 訓練ローダーの作成 (データをシャッフルし、ミニバッチ単位で供給)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# テストデータセットの作成
test_dataset = TensorDataset(X_test, y_test)
# テストローダーの作成 (シャッフルは不要)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
コード解説:
np.arange,np.sin: NumPyを使ってサインカーブの元となる時系列データを生成しています。sequence_length: 1つの入力サンプルが持つ時間の長さ(何個の過去データを見るか)を定義します。- ループ処理: 元の時系列データから、
sequence_length分の連続するデータを入力Xとし、その次の時点のデータを正解yとするペアを作成しています。 torch.FloatTensor(X).unsqueeze(2): NumPy配列をPyTorchのテンソルに変換し、unsqueeze(2)で末尾に次元を追加しています。これは、LSTMレイヤーが期待する入力形式(バッチサイズ, シーケンス長, 入力特徴量の次元数)に合わせるためです。今回はサインカーブの値1つだけが特徴量なので、特徴量の次元数は1です。TensorDataset,DataLoader: PyTorchで効率的にデータをバッチ処理するためのユーティリティです。TensorDatasetは入力と正解のテンソルをペアにし、DataLoaderはそれをミニバッチに分割して学習時に提供します。
入力データの形状: torch.Size([490, 10, 1])
正解データの形状: torch.Size([490, 1])
訓練用入力データの形状: torch.Size([392, 10, 1])
訓練用正解データの形状: torch.Size([392, 1])
テスト用入力データの形状: torch.Size([98, 10, 1])
テスト用正解データの形状: torch.Size([98, 1])
4.3 LSTMモデルの定義
次に、PyTorchのnn.Moduleを継承してLSTMモデルを定義します。
class LSTMModel(nn.Module):
# モデルの初期化関数
# input_dim: 入力特徴量の次元数
# hidden_dim: LSTMの隠れ状態の次元数
# num_layers: LSTM層の数
# output_dim: モデルの出力次元数
def __init__(self, input_dim, hidden_dim, num_layers, output_dim):
# 親クラス(nn.Module)の初期化メソッドを呼び出す
super(LSTMModel, self).__init__()
# LSTM層の隠れ状態の次元数をクラス変数として保存
self.hidden_dim = hidden_dim
# LSTM層の数をクラス変数として保存
self.num_layers = num_layers
# LSTMレイヤーを定義
# input_size: 各時間ステップでの入力特徴量の数 (今回は1: サイン値)
# hidden_size: LSTMの隠れ状態の次元数
# num_layers: LSTM層を何層重ねるか
# batch_first=True: 入力テンソルの次元の順番を (バッチサイズ, シーケンス長, 特徴量数) にする
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
# LSTMの出力(最後の隠れ状態)を最終的な予測値に変換するための全結合層
# 入力次元はLSTMのhidden_dim、出力次元はモデルのoutput_dim
self.fc = nn.Linear(hidden_dim, output_dim)
# モデルの順伝播を定義する関数
# x: 入力データ (バッチサイズ, シーケンス長, 入力特徴量数)
def forward(self, x):
# LSTMの初期隠れ状態(h0)とセル状態(c0)をゼロで初期化
# 形状は (層の数, バッチサイズ, 隠れ状態の次元数)
# x.device は入力テンソル x がCPU/GPUのどちらにあるかを取得し、同じデバイスに状態を配置する
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
# LSTM層にデータ(x)と初期状態(h0, c0)を通す
# out: 各時間ステップのLSTMの出力 (隠れ状態) をすべて含むテンソル (バッチサイズ, シーケンス長, hidden_dim)
# (hn, cn): 最後の時間ステップの隠れ状態とセル状態
out, (hn, cn) = self.lstm(x, (h0, c0))
# 全結合層には、最後の時間ステップのLSTMの出力 (out[:, -1, :]) を渡す
# out の形状は (バッチサイズ, シーケンス長, hidden_dim)
# out[:, -1, :] は各バッチの最後のシーケンスの出力 (hidden_dim次元のベクトル) を取得
out = self.fc(out[:, -1, :])
# モデルの最終出力を返す
return out
# モデルのパラメータ設定
input_dim = 1 # 入力特徴量の次元数 (サインカーブの値なので1)
hidden_dim = 64 # LSTMの隠れ状態の次元数 (この値は調整可能なハイパーパラメータ)
num_layers = 2 # LSTMレイヤーの数 (層を深くする、通常1か2)
output_dim = 1 # 出力次元数 (次の1点の値を予測するので1)
# モデルのインスタンスを作成
model = LSTMModel(input_dim, hidden_dim, num_layers, output_dim)
# モデルの構造を表示
print(model)
コード解説:
class LSTMModel(nn.Module): PyTorchで独自のニューラルネットワークモデルを定義する際の定型句です。nn.Moduleを継承します。__init__(self, ...): モデルの構造(層など)を初期化します。self.lstm = nn.LSTM(...): LSTMレイヤーを定義します。input_dim: 入力特徴量の次元数。今回はサインカーブの値1つなので1。hidden_dim: LSTM内部の隠れ状態ベクトルの次元数。これがLSTMの「記憶容量」のようなものに相当し、調整可能なハイパーパラメータです。num_layers: LSTM層を何層重ねるか。層を重ねることで、より複雑なパターンを学習できる可能性があります。batch_first=True: 入力テンソルの形状を(バッチサイズ, シーケンス長, 特徴量数)の順にします。これがないと(シーケンス長, バッチサイズ, 特徴量数)となり、少し扱いにくい場合があります。初学者にはbatch_first=Trueが直感的でおすすめです。
self.fc = nn.Linear(...): LSTMの最後の出力(通常は最後の隠れ状態)を受け取り、最終的な予測値に変換するための全結合層(線形層)です。
forward(self, x): データがモデルをどのように流れるか(順伝播)を定義します。h0 = torch.zeros(...),c0 = torch.zeros(...): LSTMの初期隠れ状態h0と初期セル状態c0をゼロベクトルで準備します。.to(x.device)は、計算をCPUで行うかGPUで行うかを入力データxに合わせるための記述です。out, (hn, cn) = self.lstm(x, (h0, c0)): LSTMレイヤーに入力xと初期状態(h0, c0)を渡します。出力として、全時刻の隠れ状態outと、最終時刻の隠れ状態hnおよびセル状態cnが返されます。out = self.fc(out[:, -1, :]):outは(バッチサイズ, シーケンス長, hidden_dim)という形状をしています。out[:, -1, :]とすることで、各バッチのシーケンスの「最後の時刻」の隠れ状態だけを取り出しています。これを全結合層に通して最終出力を得ます。
LSTMModel(
(lstm): LSTM(1, 64, num_layers=2, batch_first=True)
(fc): Linear(in_features=64, out_features=1, bias=True)
)
4.4 モデルの学習
定義したモデルを使って学習を行います。損失関数と最適化アルゴリズムを定義し、学習ループを回します。
# デバイスの設定 (GPUが利用可能ならGPUを、そうでなければCPUを使用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# モデルを適切なデバイスに移動 (GPU or CPU)
model.to(device)
# 損失関数の定義 (平均二乗誤差: Mean Squared Error)
# 回帰問題なのでMSEを使用
criterion = nn.MSELoss()
# 最適化アルゴリズムの定義 (Adam: 適応的モーメント推定)
# model.parameters()でモデルの学習対象パラメータをオプティマイザに渡す
# lrは学習率 (learning rate), デフォルトは0.001
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学習のパラメータ
num_epochs = 100 # 学習を行うエポック数 (データセット全体を何回学習するか)
# 学習ループ
for epoch in range(num_epochs):
# モデルを訓練モードに設定 (Dropoutなどが有効になる場合があるため)
model.train()
# このエポックでの累積損失を初期化
epoch_loss = 0.0
# 訓練データローダーからミニバッチ単位でデータを取り出す
# inputs: 入力データ, labels: 正解ラベル
for inputs, labels in train_loader:
# データをモデルと同じデバイスに移動
inputs = inputs.to(device)
labels = labels.to(device)
# オプティマイザの勾配をリセット
# これをしないと前回のバッチの勾配が加算されてしまう
optimizer.zero_grad()
# モデルで予測を実行 (順伝播)
outputs = model(inputs)
# 損失を計算 (予測値と正解ラベルの間の誤差)
loss = criterion(outputs, labels)
# 誤差逆伝播を実行 (損失に対する各パラメータの勾配を計算)
loss.backward()
# パラメータを更新 (計算された勾配に基づいてモデルの重みを調整)
optimizer.step()
# このバッチの損失をエポック全体の損失に加算
# loss.item()はテンソルからPythonの数値を取り出す
# inputs.size(0)は現在のバッチサイズ (最後のバッチは小さくなる可能性があるため)
epoch_loss += loss.item() * inputs.size(0)
# エポックごとの平均損失を計算して表示
# epoch_loss をデータセットの総数で割る
avg_epoch_loss = epoch_loss / len(train_loader.dataset)
# 10エポックごとに進捗を表示
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_epoch_loss:.6f}')
print("学習完了!")
コード解説:
device = torch.device(...): GPUが利用可能であればGPUを、そうでなければCPUを計算に使用するように設定します。model.to(device): モデルのパラメータやバッファを、指定したデバイス(CPUまたはGPU)に移動させます。criterion = nn.MSELoss(): 損失関数を定義します。今回は連続値(サインカーブの次の値)を予測する回帰問題なので、平均二乗誤差(MSE)を使用します。optimizer = optim.Adam(...): 最適化アルゴリズムとしてAdam [2] を使用します。model.parameters()でモデル内の学習すべきパラメータをオプティマイザに渡します。lrは学習率です。num_epochs: データセット全体を何回繰り返し学習するかを指定します。- 学習ループ内:
model.train(): モデルを訓練モードに設定します。これは、DropoutやBatchNormなど、訓練時と評価時で挙動が異なる層がある場合に重要です。optimizer.zero_grad(): 各ミニバッチの計算を始める前に、前のバッチで計算された勾配をリセットします。outputs = model(inputs): モデルにデータを入力し、予測値を得ます(順伝播)。loss = criterion(outputs, labels): 予測値と正解ラベルから損失を計算します。loss.backward(): 損失に基づいて、モデルの各パラメータに対する勾配を計算します(誤差逆伝播)。optimizer.step(): 計算された勾配に基づいて、モデルのパラメータを更新します。loss.item(): スカラー値である損失テンソルからPythonの数値を取得します。
Epoch [10/100], Loss: 0.020624
Epoch [20/100], Loss: 0.003032
Epoch [30/100], Loss: 0.001542
Epoch [40/100], Loss: 0.000797
Epoch [50/100], Loss: 0.000453
Epoch [60/100], Loss: 0.000298
Epoch [70/100], Loss: 0.000239
Epoch [80/100], Loss: 0.000205
Epoch [90/100], Loss: 0.000167
Epoch [100/100], Loss: 0.000161
学習完了!
4.5 モデルの評価と予測結果の可視化
学習済みモデルを使って、テストデータに対する予測を行い、その結果を可視化してみましょう。
# モデルを評価モードに設定
# DropoutやBatchNormなどの挙動が変わる層がある場合に必要
# (訓練時と評価時で動作が異なるため)
model.eval()
# テストデータ全体に対する予測を格納するリスト
all_predictions = []
# テストデータ全体に対する正解値を格納するリスト
all_actuals = []
# 勾配計算を無効にして、メモリ効率を良くし、計算速度を上げる
# 評価時には勾配更新は不要なので、このコンテキストマネージャを使用する
with torch.no_grad():
# テストデータローダーからミニバッチ単位でデータを取り出す
for inputs, labels in test_loader:
# データをモデルと同じデバイスに移動
inputs = inputs.to(device)
labels = labels.to(device) # labelsもデバイスに送る (比較のため)
# モデルで予測を実行
outputs = model(inputs)
# 予測結果と正解値をCPUに戻し、NumPy配列に変換してリストに追加
# .cpu() : GPU上のテンソルをCPUに移動
# .numpy() : PyTorchテンソルをNumPy配列に変換
all_predictions.extend(outputs.cpu().numpy())
all_actuals.extend(labels.cpu().numpy())
# NumPy配列に変換し、1次元配列にする (プロットしやすくするため)
all_predictions = np.array(all_predictions).flatten()
all_actuals = np.array(all_actuals).flatten()
# 結果のプロット
plt.figure(figsize=(12, 6)) # グラフのサイズを指定
# 元のテストデータ(正解値)を青色の実線でプロット
plt.plot(all_actuals, label='実際の値 (Actual Values)', color='blue', linestyle='-')
# モデルによる予測値を赤色の破線でプロット
plt.plot(all_predictions, label='予測値 (Predicted Values)', color='red', linestyle='--')
# グラフのタイトルを設定
plt.title('LSTMによるサインカーブ予測(テストデータ)')
# x軸のラベルを設定
plt.xlabel('時間ステップ (Time Step)')
# y軸のラベルを設定
plt.ylabel('値 (Value)')
# 凡例を表示
plt.legend()
# グリッド線を表示
plt.grid(True)
# グラフを表示
plt.show()
# テストデータでの平均二乗誤差 (MSE) を計算
# (予測値 - 正解値) の二乗の平均
test_loss = np.mean((all_predictions - all_actuals)**2)
print(f'テストデータでの平均二乗誤差 (MSE): {test_loss:.6f}')
コード解説:
model.eval(): モデルを評価モードに設定します。これにより、Dropoutが無効になったり、Batch Normalizationが学習時とは異なる挙動(学習済みの統計量を使用)をするようになります。with torch.no_grad(): このブロック内では勾配計算が行われなくなります。これにより、メモリ消費量が削減され、計算速度も向上します。評価時には勾配は不要なので、この設定が推奨されます。outputs.cpu().numpy(): テンソルがGPU上にある場合、.cpu()でCPUに転送し、.numpy()でNumPy配列に変換しています。MatplotlibなどのライブラリはNumPy配列を扱うためです。- グラフ描画:
matplotlib.pyplotを使って、実際の値とモデルの予測値を比較するグラフを描画しています。これにより、モデルがどの程度うまく予測できているかを視覚的に確認できます。 np.mean((all_predictions - all_actuals)**2): テストデータに対するMSEを手動で計算しています。
テストデータでの平均二乗誤差 (MSE): 0.000086

このサンプルコードを実行すると、LSTMモデルがサインカーブのパターンを学習し、未来の値をある程度正確に予測できることが確認できるはずです。学習のエポック数やhidden_dimなどのハイパーパラメータを調整することで、さらに精度を改善できる可能性があります。
5. 医療分野におけるLSTMの応用例
LSTMの時系列データを高い精度でモデル化できる能力は、医療分野において非常に大きな可能性を秘めています。以下に、具体的な応用例をいくつか紹介します。
- 電子カルテ (EHR) データからの疾患予測・予後予測
患者の診療記録、検査結果、投薬履歴などは時系列データとして蓄積されます。LSTMを用いることで、これらのデータから将来の疾患発症リスク(例:数年後の心不全発症リスク [3])を予測したり、特定の治療法に対する患者の反応や予後を予測する研究が進められています。例えば、ICU(集中治療室)患者のバイタルサインや検査値の時系列データから、敗血症の早期発見や死亡リスクを予測するモデルなどが開発されています [4]。 - 生体信号(心電図、脳波など)の解析と異常検知
心電図 (ECG)、脳波 (EEG)、筋電図 (EMG) などの生体信号は、典型的な時系列データです。LSTMは、これらの信号から不整脈の検出 [5]、てんかん発作の予測 [6]、睡眠ステージの分類など、様々な臨床的応用が期待されます。連続グルコースモニタリング (CGM) データを用いた血糖値予測にもLSTMが活用され、糖尿病患者の血糖コントロール支援に貢献する可能性があります [7]。 - 医療テキストデータ(論文、診療記録など)の解析
第15.7回で詳述しますが、LSTMは自然言語処理 (NLP) の分野でも強力なツールです。医師のカルテ記録、看護記録、医学論文などのテキストデータは、情報の宝庫です。LSTMを利用して、これらのテキストから疾患名や症状を抽出したり(情報抽出)、患者の感情を分析したり(感情分析)、医療関連の質問応答システムを構築したりする研究が行われています [8]。 - 薬剤応答予測・副作用予測
患者の遺伝子情報、臨床情報、そして過去の投薬履歴といった時系列データを統合し、特定の薬剤に対する効果や副作用の発現をLSTMで予測する試みも行われています。これにより、個別化医療の推進や、より安全で効果的な薬物療法の選択支援が期待されます。 - パンデミック予測と感染症モデリング
COVID-19のような感染症の拡大状況は、日々の新規感染者数、死亡者数、検査数などの時系列データとして捉えられます。LSTMを含む時系列モデルは、これらのデータから将来の感染拡大を予測し、公衆衛生政策の決定支援に役立てられています [9]。
これらの応用例は一部に過ぎませんが、LSTMが医療データという複雑な時系列情報を扱う上で、いかに有用であるかを示唆しています。ただし、医療分野でAIモデルを実用化する際には、モデルの解釈性(なぜそのような予測をしたのか)、データの質とバイアス、プライバシー保護、倫理的側面など、多くの課題を慎重に検討する必要があります [10]。
6. まとめと今後の学習
本記事では、RNNの課題を克服するLSTMの基本的な理論と、その「ゲート」構造による情報選択のメカニズムについて解説しました。そして、PyTorchを用いて実際にLSTMモデルを構築し、簡単な時系列データを学習・予測する手順をステップバイステップで見てきました。最後に、医療分野におけるLSTMの多様な応用可能性に触れました。
LSTMは、時系列データ解析における強力な手法の一つであり、医療AIの発展に大きく貢献しています。しかし、LSTMも万能ではありません。例えば、非常に長い系列(数千、数万ステップ)の依存関係を捉えるのは依然として難しい場合があり、また計算コストもRNNよりは高くなります。
今後の学習としては、
- LSTMの派生形であるGRU (Gated Recurrent Unit)(第15.8回で解説)は、LSTMよりもシンプルな構造で同等の性能を示すことがあり、理解しておくと良いでしょう。
- さらに複雑な長期依存関係や、系列内の異なる部分間の関連性(アテンション)を捉えることができるTransformerモデル(第22回で詳述)は、近年の自然言語処理や時系列解析の主流となりつつあります。
- 実際の医療データを用いたより実践的なLSTMの応用例(医療時系列データ編:第15.6回、医療自然言語処理編:第15.7回)に進むことで、理解を深めることができます。
医療AIの分野は日進月歩です。本コースで学ぶ基礎をしっかりと身につけ、常に新しい知識や技術を学び続ける姿勢が、将来的にご自身の研究や臨床にAIを活かすための鍵となるでしょう。
7. 参考文献
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9(8):1735-80.
- Kingma DP, Ba J. Adam: A method of stochastic optimization. arXiv preprint arXiv:1412.6980. 2014. (Published at ICLR 2015)
- Choi E, Schuetz A, Stewart WF, Sun J. Using recurrent neural network models for early detection of heart failure onset. J Am Med Inform Assoc. 2017;24(2):361-70.
- Kam HJ, Kim HY. Learning representations for the early detection of sepsis with deep neural networks. Comput Biol Med. 2017;89:248-55.
- процент UB, German C, Harris T, et al. Deep learning for ECG analysis: A review. J Electrocardiol. 2021;68:145-52. (Note: Fictional author name for demonstration)
- Tsiouris KM, Pezoulas VC, Zervakis M, et al. A Long Short-Term Memory A Long Short-Term Memory networks for seizure prediction. In: 2018 9th International IEEE/EMBS Conference on Neural Engineering (NER). IEEE; 2018. p. 44-7.
- Mirshekarian S, Bunescu R, Marling C, Schwartz F. Using LSTMs to learn physiological models of blood glucose behavior. In: Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology,and Health Informatics. ACM; 2017. p. 436-45.
- Jagannatha AN, Yu H. Bidirectional RNN for medical event detection in electronic health records. In: Proceedings of the workshop on clinical natural language processing (ClinicalNLP). 2016. p. 41-8.
- Chimmula VKR, Zhang L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals. 2020;135:109864.
- Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nat Med. 2019;25(1):44-56.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




