

日々の診療、本当にお疲れ様です。臨床現場は、まさに情報の洪水ですよね。例えば、敗血症が疑われる一人の患者さんを前にしたとき、私たちの頭には膨大なデータが流れ込んできます。数十項目に及ぶ血液検査データ、時系列で変動するバイタルサイン、画像所見、そして最近では遺伝子発現プロファイルといったゲノム情報まで…。
「このたくさんのマーカーの中で、いま患者さんの病態を最も的確に反映しているのは、一体どの組み合わせなんだろう?」
そんな風に、無数の情報のピースを前に、どれが本質的なのかを見極めようと頭を悩ませた経験、一度はあるかもしれません。もし、この複雑に絡み合ったデータの中から、「本当に大事な情報の軸」だけをスッと抜き出して、全体像をシンプルに見せてくれる魔法のメガネがあったとしたら、臨床判断の強力な助けになると思いませんか?
実は、AIの世界にはまさにそんな役割を果たす、非常にエレガントで強力な道具が存在します。それが今回お話しする主成分分析(Principal Component Analysis, PCA)です。そして、その魔法のメガネのレンズの役割を担っているのが、「固有値」と「固有ベクトル」という、一見すると少し不思議な名前の数学の概念なんです。
「うわ、また難しい数学の話か…」と身構える必要はまったくありません。ご安心ください。これらの言葉が持つ本当の意味は、驚くほど直感的です。この記事を読み終える頃には、AIがどのようにして情報の洪水から「本質」だけを効率よく見抜いているのか、その視点をきっとご自身のものにしていただけるはずです。さあ、一緒にAIの思考を覗いてみましょう。
たくさんの情報、その「最大の特徴」はどっちを向いている?
さて、PCAの核心に迫るために、まずは身近な例で考えてみましょう。ここに、ある疾患を持つ患者さん100人分の「炎症マーカーX」と「代謝マーカーY」の測定値があるとします。これら2つのマーカーの間には何らかの関係がありそうで、横軸にX、縦軸にYをとってプロットしてみると、下のような点の集まり、いわば「データの雲」が浮かび上がってきました。
このデータの雲を、じっと眺めてみてください。何か気づくことはありませんか?
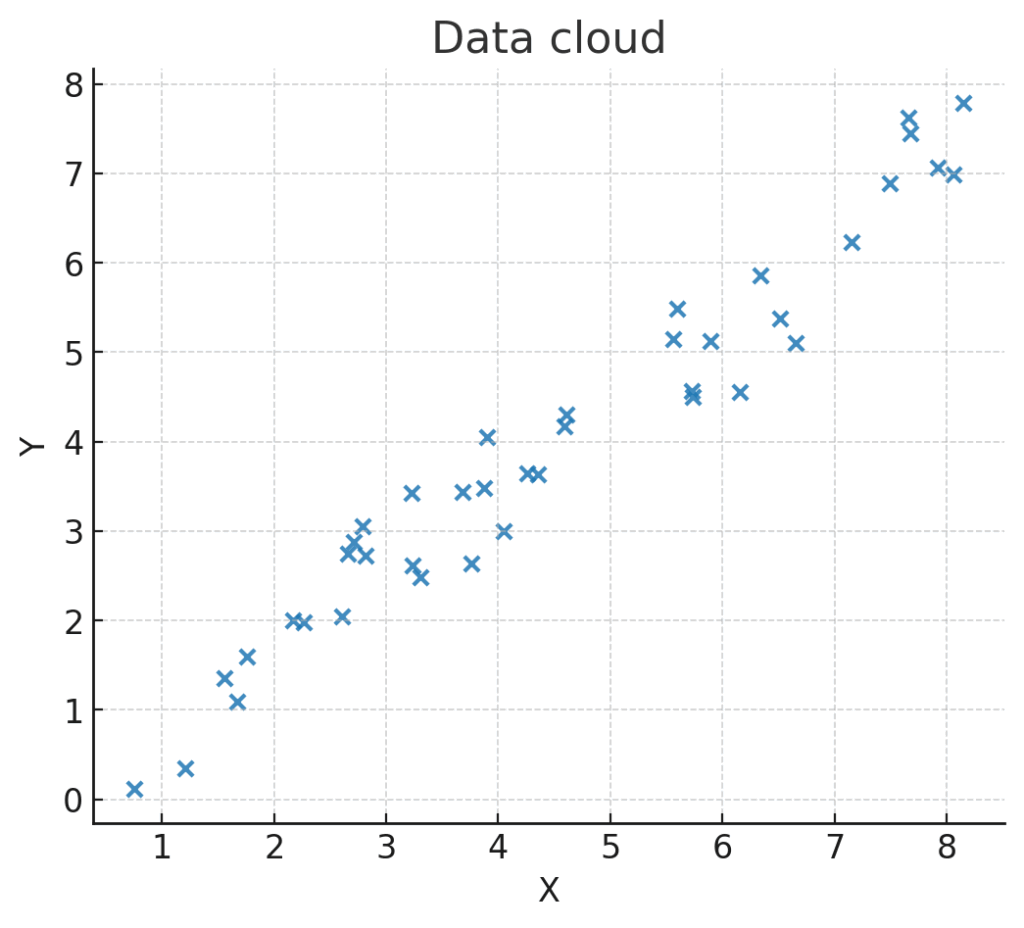
そう、点は全体的に、なんとなく右斜め上に広がっていますよね。真上や真横に広がるよりも、この右斜め上の方向に最も「ばらつき」が大きいように見えます。もし、このデータの雲に最もフィットする一本の軸(線を引くとしたら、それはきっとこの右斜め上の方向になるはずです。
PCAが目指しているのは、一言でいえば「データ全体を最も雄弁に語る、最高の『視点』を見つけ出すこと」です。
ちょっと想像してみてください。あなたは、たくさんのホタルが飛び交う野原に立っているとします。ホタルは三次元空間を自由に飛び回っており、その全体像を一枚の写真に収めたいと考えています。どの角度から撮影すれば、ホタルの群れが最も「広がって」見え、その分布の様子が一番よく伝わるでしょうか?
- 悪い視点: 群れの真正面から撮ると、奥行きが失われ、すべてのホタルが一点に重なるように見えてしまうかもしれません。これでは、群れの広がり(ばらつき)がほとんど分かりません。
- 良い視点: 少し斜め上から、群れが最も長く伸びている方向を捉えるように撮影すれば、ホタルたちの位置関係や全体の形がくっきりと写し出されるはずです。
この「最も群れの広がり(ばらつき)が大きく見える視点・角度」を探すことこそ、PCAがやっていることの本質です。
データの世界に戻りましょう。
- ホタル: 一つひとつのデータ点(例:各患者さんのデータ)
- 空間: 特徴量の数だけ存在する高次元の空間(例:「炎症マーカーX」と「代謝マーカーY」なら2次元空間、50項目の血液検査なら50次元空間)
- ばらつき (分散): データがどれだけ広がっているか。ばらつきが大きいほど、そこには多くの情報が含まれていると考えます。もし、全員のデータが全く同じ値なら、その特徴量から得られる情報は何もありませんよね。
PCAは、この高次元空間に散らばるデータの雲を眺め、「どの方向にプロット(射影)すれば、データのばらつきが最大になるか?」を数学的に計算します。 そして、見つけ出した「ばらつきが最大になる方向」、つまり最も情報量豊かな「最高の視点」。これこそが、第1主成分 (Principal Component 1; PC1) なのです。
このPC1という新しい「ものさし」を使えば、たくさんの特徴量をたった一つの数値で代表させても、元のデータが持っていた情報の多くを失わずに済む、というわけです。
下の図で、PC1がその方向です。そして、PC1に直交する方向(直角に交わる方向)で、次にデータのばらつきが大きいのが「第2主成分(PC2)」となります。

ここで、先ほどのキーワードが登場します。
- この最も重要な「方向」(PC1やPC2)を数学的に示してくれるのが、固有ベクトルです。言わば、データの「本質を貫く軸」そのものです。
- そして、その軸がどれくらいのばらつき(重要度)を持っているか、その「大きさ」を示すのが固有値です。
つまり、固有値が大きい固有ベクトル(主成分)の方向ほど、そのデータにとってより本質的で、重要な情報軸だと言えるわけです。PCAは、この「固有値」を指標にして、データにとって重要な軸のランキング付けを行っている、と考えるとイメージしやすいかもしれませんね。
なぜ「固有値の大きさ=情報量」なのでしょうか?
「固有値が大きい方向が重要」と言われても、なぜそう断言できるのか、少し不思議に思いませんか?その答えは、PCAが「データのばらつき(分散)」を「情報量」と同一視している点に隠されています。
少し考えてみてください。もし、ある検査項目の値が、全患者さんで全く同じだったらどうでしょう?そのデータから、患者さんごとの違いに関する情報は何も得られませんよね。逆に、値が大きくばらついているほど、その項目は患者さん一人ひとりを特徴づける、より多くの「情報」を含んでいると考えられます。
PCAは、この考え方を多次元空間に拡張したものです。つまり、「データのばらつき(分散)が最も大きい方向こそ、そのデータセットの情報を最も多く含んだ、最も重要な方向である」と考えるのです。
そして、ここからが数学の美しいところなのですが、共分散行列の固有値分解を行うと、ある驚くべき事実が明らかになります。
ある主成分(固有ベクトル)の方向にデータを射影したときの「分散」の大きさは、その主成分に対応する「固有値」の大きさと完全に一致するのです。
つまり、こういうことです。
- 第1主成分(PC1)の固有値が \( \lambda_1 = 50 \) であった場合、それはPC1の軸に沿ったデータのばらつき(分散)が「50」であることを意味します。
- 第2主成分(PC2)の固有値が \( \lambda_2 = 10 \) であった場合、それはPC2の軸に沿ったデータの分散が「10」であることを意味します。
さらに、データ全体の総分散(すべての情報量)は、すべての固有値の合計(\( \lambda_1 + \lambda_2 + \dots \))に等しくなります。 この性質により、各主成分が全体の何パーセントの情報を説明しているか(寄与率)を正確に計算できます。
【各主成分が説明する情報量の割合(寄与率)】
\[ \text{総情報量(総分散)} = \lambda_1 + \lambda_2 + \dots + \lambda_n \]
\[ \text{PC1の寄与率} = \dfrac{\lambda_1}{\lambda_1 + \lambda_2 + \dots + \lambda_n} \]
\[ \text{PC2の寄与率} = \dfrac{\lambda_2}{\lambda_1 + \lambda_2 + \dots + \lambda_n} \]
…
この例では、PC1はPC2の5倍の分散(情報量)を持っていることになります。だからこそ私たちは、「固有値が大きい = その方向の分散が大きい = その方向が持つ情報量が大きい = したがって、重要な軸である」と自信を持って言うことができるのです。
固有値は、単なるランキング付けのスコアではなく、各主成分がデータ全体の物語をどれだけ語っているかを定量的に示す、信頼できる指標なのです。
固有値と固有ベクトル — 行列による「変換」の”芯”を見抜く数学
もう少しだけ、この固有値と固有ベクトルという不思議な概念の正体に、グッと迫ってみましょう。一言でいうと、これらは行列が引き起こす「変換」に対して、向きを変えずに、ただ伸び縮みだけする特別なベクトルのことです。
これをイメージするために、ゴムシートの上に描かれた円を想像してみてください。そのゴムシートを、誰かがグーッと真横に引っ張ったとします。円は、横に伸びた楕円に変形しますよね。このとき、もともと円の上にあったほとんどの点は、斜め方向など、あらぬ方向へ移動してしまいます。しかし、たった2つの特別な方向の点だけは違います。
- 真横の方向: 引っ張られた方向にあった点は、向きを変えず、ただ外側へ移動するだけです。
- 真縦の方向: 横に引っ張られた分、縦には縮みますが、これも向きは変わらず、中心に向かって近づくだけです。
この「引っ張る」という変換(行列 \(A\))を加えても、方向が変わらなかった「真横」や「真縦」の方向。これこそが固有ベクトル(\(\mathbf{v}\))です。そして、その方向にどれだけ伸びたか(あるいは縮んだか)という倍率が固有値(\(\lambda\))なのです。
ベクトルvを行列Aで変換
結果は等しい
ベクトルvをλ倍に伸縮
vに行列Aの複雑な変換を施した結果(左辺)が、驚くことに、元のベクトルvをただ単純にλ倍したもの(右辺)と全く同じになる」という、非常に特別な関係が成り立つベクトル v と数値 λ のペアが存在する、ということです。
A によって全く違う方向を向いてしまいます。しかし、固有ベクトルだけは、その行列が持つ「変換の本質的な軸」に沿っているため、方向を変えずにいられるのです。主成分分析(PCA)などの技術は、この性質を巧みに利用しています。
数式が語る「変換の物語」
この直感的なイメージは、次の一本のシンプルな数式に集約されています。
\[ A\mathbf{v} = \lambda\mathbf{v} \]
この式の登場人物は次の通りです。
- \(A\): 変換役の行列。ベクトルを別のベクトルに変える「変換装置」です。
- \(\mathbf{v}\): 向きの変わらない特別なベクトル(固有ベクトル)。
- \(\lambda\): 伸縮の倍率(固有値)。
この等式が意味するのは、「ベクトル\(\mathbf{v}\)に行列\(A\)の変換を施した結果(左辺)が、元のベクトル\(\mathbf{v}\)をただ単純に\(\lambda\)倍したもの(右辺)と全く同じになる」という、非常に特別な関係でしたね。
ところで、固有値や固有ベクトルはどうやって計算するの? 💻
さて、固有値と固有ベクトルの「概念」について学んできましたが、「で、この不思議な値やベクトルは、具体的にどうやって見つけるの?」という疑問が湧いてきますよね。素晴らしい質問です。
実は、行列から固有値・固有ベクトルを手計算で求めるには、高校数学を少し超えた、次のような手順が必要になります。
- 「特性方程式」という“鍵”を作る: まず、行列 A を使って
det(A - λI) = 0という、λ を見つけ出すための特別な方程式を立てます。 - 方程式を解いて「固有値」を見つける: この方程式を解くことで、候補となる固有値 λ がすべて求まります。
- 各固有値の「相棒」を探す: 求めた固有値 λ を一つずつ
(A - λI)v = 0という式に代入し、連立方程式を解くことで、その固有値の相棒である固有ベクトル v を見つけ出します。
ただ、ここで大事なことをお伝えします。AIやデータサイエンスを学ぶ現代において、この計算をあなたが手で行う必要は、ほとんどありません。
実際の現場では、こうした計算はPythonのNumPyといった専門のライブラリが、一瞬で、かつ正確に実行してくれます。
この記事の最大の目的は、計算機になることではなく、「ライブラリが弾き出した固有値や固有ベクトルという数字が、一体何を意味しているのか」を深く、直感的に理解することです。そのため、この記事ではあえて手計算のプロセスは省略し、その分、AIの思考を理解する上で最も重要な「数学的な意味」の解説に焦点を当てています。
【発展】PCAの核心:数学的になぜ「固有値=分散」と言えるのか 🏛️
さて、ここまでの解説で、「固有値が大きいほど、その主成分は重要である」という、PCAにおける最も基本的なルールが見えてきました。
しかし、なぜそう断言できるのでしょうか?これは、私たちがただ覚えるべき「お約束」なのでしょうか。それとも、その背後には、誰もが納得せざるを得ない、美しく、そして揺るぎない数学的な理由があるのでしょうか?
ここからが、今回の解説の最も重要な核心部分です。この法則がなぜ数学的に保証されているのか、そのエレガントな論理のステップを、一つひとつ丁寧に解き明かしていきましょう。読み終える頃には、「固有値が大きいほど重要」というルールが、単なる暗記事項ではなく、必然的な帰結であることが、きっと腑に落ちるはずです。
ステップ1:舞台設定 – PCAの目標と主役「共分散行列」
PCAの最終目標:データの「メインストリート」を探す旅
まず、PCAが何をしたいのか、その目的地のイメージをもう一度はっきりさせておきましょう。
たくさんのデータ点が雲のように散らばっている(これをデータクラウドと呼びます)とき、PCAの目標はただ一つです。
「このデータクラウドの最も中心的な、最も『伸びて』いる方向、いわばデータの『メインストリート』を見つけ出すこと」
もしデータクラウドが完全な球体であれば、どの方向も平等で「メインストリート」は存在しません。しかし、実際のデータは多くの場合、ラグビーボールのように特定の方向に伸びていたり、傾いていたりします。この「最も伸びている方向」こそが、データが持つ最も多くの情報を要約している、と考えるのがPCAの出発点です。
主役の登場:なぜ「共分散行列 \( S \)」が必要なのか?
では、このデータクラウドの「形」や「傾き」を、数学の世界でどう表現すれば良いのでしょうか?ここで、PCAの絶対的な主役である共分散行列 \( S \) が登場します。
なぜこの行列が唐突に主役になるのか、その理由を理解するために、まず2つの基本的な統計量を思い出してみましょう。
- 分散 (Variance):「軸方向への広がり」を測る 分散は、データが一つの軸に沿ってどれだけ散らばっているかを示す指標です。例えば、患者さんたちの「コレステロール値」だけを見たとき、その値がどれだけ広がっているか、これが分散です。データクラウドで言えば、各軸方向への「幅」や「厚み」を測るようなものです。
- 共分散 (Covariance):「データ全体の傾き」を測る 共分散は、2つの異なる特徴量がどのように一緒に動くか、その関係性を示す指標です。例えば、「睡眠時間」が長い人ほど「翌朝の血圧」が低い、といった傾向があれば、この2つの特徴量の間には負の共分散がある、と言えます。これは、データクラウドの「傾き」や「相関」を教えてくれます。
共分散行列 \( S \) は、これらすべての「広がり」と「傾き」の情報を、一つの行列に整理整頓した『データのカルテ』のようなものです。
2つの特徴量(\(X, Y\))を持つデータの場合、共分散行列は次のように構成されます。
| 特徴量 \( X \) | 特徴量 \( Y \) | |
|---|---|---|
| 特徴量 \( X \) | \( \text{Var}(X) \) | \( \text{Cov}(X,Y) \) |
| 特徴量 \( Y \) | \( \text{Cov}(Y,X) \) | \( \text{Var}(Y) \) |
- \( \text{Var}(X) \): 特徴量\(X\)の「分散」(\(X\)軸方向への広がり)
- \( \text{Var}(Y) \): 特徴量\(Y\)の「分散」(\(Y\)軸方向への広がり)
- \( \text{Cov}(X,Y) \): 特徴量\(X\)と\(Y\)の「共分散」(データ全体の傾き)。\( \text{Cov}(Y,X) \) と同じ値になります。
この行列 \( S \) を見るだけで、データが\(X\)軸方向にどれだけ広がり、\(Y\)軸方向にどれだけ広がり、そして全体としてどちらの方向に傾いているのか、その幾何学的な特徴がすべて数学的に記述できるのです。
私たちが探している「メインストリート(最も伸びている方向)」は、必ずしも元の\(X\)軸や\(Y\)軸と一致しません。それは、この分散と共分散が組み合わさって生まれる、新しい『斜めの軸』のはずです。
だからこそ、PCAはまず、この「データの設計図」とも言える共分散行列 \( S \) を計算し、それを徹底的に分析することで、データの本質的な方向(主成分)を探り出すのです。
ステップ2:数学で「影の広がり」を測る — \( \mathbf{u}^T S \mathbf{u} \) の徹底解説
さて、私たちは「データの設計図」である共分散行列 \( S \) を手に入れました。次に進むべきステップは、この設計図を使って、特定の方向におけるデータの「広がり(分散)」を具体的に計算する方法を確立することです。
PCAの目標は「分散が最大になる方向を見つける」ことでしたね。では、ある任意の方向(単位ベクトル \( \mathbf{u} \) で表します)の分散は、どう計算できるのでしょうか?これが今回の最重要ポイントです。
結論から言うと、その分散は \( \mathbf{u}^T S \mathbf{u} \) という、驚くほどシンプルで美しい式で計算できます。なぜそうなるのか、その導出プロセスを一緒に見ていきましょう。
1. データを射影(影を落とす)する
まず、個々のデータ点 \( x_i \) が、私たちが注目している方向 \( \mathbf{u} \) に対して、どれくらいの位置にいるのかを知る必要があります。これは、データ点 \( x_i \) から \( \mathbf{u} \) が示す軸に対して垂線を下ろし、その「影」の位置を特定する作業です。
数学的には、この影の原点からの距離(座標)は、2つのベクトル \( x_i \) と \( \mathbf{u} \) の内積を取ることで計算できます。ベクトルを縦ベクトルで表現する場合、内積は \( x_i^T \mathbf{u} \) と書けます。これはスカラー(ただの数値)になります。
2. 影の分散を計算する(定義からの出発)
分散の基本的な定義を思い出しましょう。分散とは「(値 – 平均)の2乗の平均」です。
今回の分析では、あらかじめデータ全体の平均が原点 (0) になるように中心化を行っています。そのため、平均は0と考えることができ、分散の計算はもっとシンプルになります。
分散 = 「値の2乗の平均」
今回、私たちが扱っている「値」とは、先ほど計算した「影の座標 \( x_i^T \mathbf{u} \)」のことです。データ点がN個あるとすると、影の分散の定義式は次のようになります。
\[ \text{分散} = \dfrac{1}{N} \sum_{i=1}^{N} (x_i^T \mathbf{u})^2 \]
この式が、私たちのすべての計算の出発点です。
3. 数式の「着せ替え」で本質に迫る
さて、ここからが数学の面白いところです。一見複雑に見えるこの定義式を、行列の性質を使いながら、もっと見通しの良い形に「着せ替え」していきましょう。
まず、式の中の \( (x_i^T \mathbf{u})^2 \) に注目します。\( x_i^T \mathbf{u} \) は内積の結果なので、ただの数値(スカラー)です。数値の2乗は、単に同じものを2回掛けることと同じです。
\[ (x_i^T \mathbf{u})^2 = (x_i^T \mathbf{u})(x_i^T \mathbf{u}) \]
ここで一つ、巧妙なテクニックを使います。数値(1×1行列と見なせます)は、転置しても値が変わりません。そこで、2つの \( (x_i^T \mathbf{u}) \) のうち、片方を転置してみます。行列の積の転置には \( (AB)^T = B^T A^T \) という法則があるので、
\[ (x_i^T \mathbf{u})^T = \mathbf{u}^T (x_i^T)^T = \mathbf{u}^T x_i \]
となります。これを使って、2乗の式を次のように書き換えることができます。
\[ (x_i^T \mathbf{u})^2 = (\mathbf{u}^T x_i)(x_i^T \mathbf{u}) \]
なぜわざわざこんなことをしたのか?それは、後で行列としてまとめる際に、この順番が非常に都合が良いからです。これを分散の式全体に戻してみましょう。
\[ \text{分散} = \dfrac{1}{N} \sum_{i=1}^{N} (\mathbf{u}^T x_i)(x_i^T \mathbf{u}) \]
この式では、\( \mathbf{u}^T \) と \( \mathbf{u} \) は、総和 \( \sum \) の対象であるデータ点 \( i \) には依存しません。つまり、\( \sum \) の中では定数のようなものです。行列計算のルールに従って、これらを \( \sum \) の外側に括り出すことができます。
\[ \text{分散} = \mathbf{u}^T \left( \dfrac{1}{N} \sum_{i=1}^{N} x_i x_i^T \right) \mathbf{u} \]
4. 共分散行列との運命的な再会
さあ、式の核心部分が見えてきました。真ん中の角括弧 \( [ \ ] \) で囲まれた部分を、もう一度よく見てください。
\[ \dfrac{1}{N} \sum_{i=1}^{N} x_i x_i^T \]
これは、まさに私たちがステップ1で学んだ共分散行列 \( S \) の定義そのものなのです!
この運命的な再会により、分散を求めるための複雑だった計算式は、最終的に次の驚くほどシンプルで、かつ本質的な形にたどり着きます。
\[ \text{Variance}(\text{direction } \mathbf{u}) = \mathbf{u}^T S \mathbf{u} \]
この一つの式が、PCAの理論の根幹をなしています。それは、「ある方向 \( \mathbf{u} \) の分散を知りたければ、その方向ベクトル \( \mathbf{u} \) で、データの『設計図』である共分散行列 \( S \) をサンドイッチのように挟んで計算すればよい」という、深く美しい関係を示しているのです。
ステップ3:最大値を探す旅 — レイリー商と固有値の運命的な出会い
さあ、いよいよ旅のクライマックスです。私たちは、データのある方向 \( \mathbf{u} \) における分散(情報の広がり)を測るための万能な数式、\( \mathbf{u}^T S \mathbf{u} \) を手に入れました。
私たちの最終目標は、この \( \mathbf{u}^T S \mathbf{u} \) の値を最大にする、つまり「影が最も広がる方向 \( \mathbf{u} \)」を見つけ出すことです。ただし、\( \mathbf{u} \) はあくまで「方向」を示すベクトルなので、その長さは1でなければならない(\( \mathbf{u}^T \mathbf{u} = 1 \))という制約があります。
この \( \mathbf{u}^T S \mathbf{u} \) という形は、数学の世界ではレイリー商 (Rayleigh quotient) という由緒正しい名前で知られています。そして、このレイリー商は、まさしく私たちのために用意されたかのような、驚くべき性質を持っています。
レイリー商が指し示す「宝の地図」
線形代数の世界で、レイリー商について次のような非常に強力な定理が証明されています。これは、PCAの理論全体の正当性を保証する、まさに「宝の地図」のようなものです。
レイリー商の性質:
ある行列 \( S \) と、長さが1のベクトル \( \mathbf{u} \) があるとき、レイリー商 \( R(S, \mathbf{u}) = \mathbf{u}^T S \mathbf{u} \) が取りうる値の範囲は、行列 \( S \) の最小の固有値から最大の固有値の間に必ず収まる。
そして、最も重要なことに、
- \( R(S, \mathbf{u}) \) の最大値は、\( S \) の最大の固有値 \( \lambda_{\text{max}} \) と完全に一致する。
- その最大値を実現する方向 \( \mathbf{u} \) は、その最大の固有値 \( \lambda_{\text{max}} \) に対応する固有ベクトル \( \mathbf{v}_{\text{max}} \) である。
すべての点が線で繋がった瞬間
この定理が何を意味するか、お分かりでしょうか?
- 私たちが最大化したい「分散」は、レイリー商 \( \mathbf{u}^T S \mathbf{u} \) そのものでした。
- そのレイリー商の最大値は、最大の固有値 \( \lambda_{\text{max}} \) であることが保証されています。
- そして、その最大値を達成する「方向」は、最大の固有値に対応する固有ベクトル \( \mathbf{v}_{\text{max}} \) であることも保証されています。
これはまさに、私たちが探し求めていた答えそのものです!この定理によって、私たちの探求の旅は、ゴールへと一直線に繋がりました。
「データの分散を最大化する方向を探す」という統計学的な問題は、「共分散行列の最大の固有値と、それに対応する固有ベクトルを探す」という線形代数学の問題と、完全に等価だったのです。
これ以上に美しく、直接的な関係があるでしょうか。この数学的な保証があるからこそ、私たちは自信を持って「最大の固有値を持つ固有ベクトルこそが、最も重要な主成分(PC1)である」と断言できるのです。
ステップ4:最後のピース — なぜ分散が固有値に一致するのか?
さあ、物語の最後のピースがはまる瞬間です。前のステップで、「分散を最大化する方向は、最大の固有値を持つ固有ベクトルである」という強力な定理を紹介しました。
ここでは、その定理がなぜ成り立つのかを、固有値の基本定義 \( Sv = \lambda v \) を使って確かめてみましょう。これは、すべての理論が一点に収束する、非常に美しい証明です。
証明のステップを一緒に歩いてみよう
私たちの出発点は、方向 \( \mathbf{u} \) における分散の公式 \( \mathbf{u}^T S \mathbf{u} \) です。
ここで、「もし、その方向 \( \mathbf{u} \) が、たまたま共分散行列 \( S \) の固有ベクトル \( \mathbf{v} \) だったとしたら?」と考えて、\( \mathbf{u} \) を \( \mathbf{v} \) に置き換えてみましょう。
1. 出発点:分散の公式
\[ \text{分散} = \mathbf{v}^T S \mathbf{v} \]
これは、固有ベクトル \( \mathbf{v} \) の方向における分散を計算する、という意味の式です。
2. 固有値の定義を適用
\[ = \mathbf{v}^T (\lambda \mathbf{v}) \]
ここが最も重要なステップです!固有ベクトルの定義 \( Sv = \lambda v \) を思い出してください。これは、「ベクトル \( \mathbf{v} \) に行列 \( S \) の変換をかけることは、ベクトル \( \mathbf{v} \) を単純に \( \lambda \) 倍することと全く同じ」という意味でした。そこで、式の中の \( Sv \) を、その等価な表現である \( \lambda v \) に置き換えます。
3. スカラー \( \lambda \) を外に出す
\[ = \lambda (\mathbf{v}^T \mathbf{v}) \]
固有値 \( \lambda \) は、ベクトルではなく、ただの数値(スカラー)です。行列計算のルールでは、スカラーは積のどこにいてもよいため、式の先頭に移動させることができます。これにより、「伸縮率」である \( \lambda \) と、「方向」であるベクトルの部分を分けることができました。
4. 単位ベクトルの性質
\[ = \lambda \times 1 \]
\( \mathbf{v}^T \mathbf{v} \) は、ベクトル \( \mathbf{v} \) と自分自身の内積を意味します。これは、ベクトルの「長さの2乗」を計算する操作です。PCAで扱う方向ベクトル \( \mathbf{v} \) は、方向のみを示すために長さが \( 1 \) の単位ベクトルとして定義されています。したがって、その長さの2乗は \( 1^2 = 1 \) となります。
5. 結論
\[ = \lambda \]
すべての計算が終わり、最終的に残ったのは固有値 \( \lambda \) ただ一つでした。
この短い証明が示しているのは、「共分散行列の固有ベクトル方向にデータを射影したときの分散は、その固有ベクトルの固有値に完全に、そして美しく一致する」という、衝撃的な事実です。
したがって、「最大の分散を探す」という私たちの統計的な目標は、「最大の固有値を探す」という線形代数の問題と完全に等価であることが、ここに証明されました。固有値とは、もはや単なる「重要度のスコア」ではなく、「その方向が持つ情報量(分散)そのものを表す、揺るぎない数値」なのです。
さらに発展!:なぜ分散を最大化すると固有値問題になるのか? (ラグランジュの未定乗数法)
さて、本編で「分散を最大化する方向は、都合よく固有ベクトルになる」という結論に至りました。しかし、なぜそんなにうまく話がまとまるのでしょうか?その背後には、ラグランジュの未定乗数法という、制約付き最適化問題を解くための強力な数学的アプローチがあります。
このコラムでは、その思考のプロセスを、数式が苦手な方でもイメージで追えるように解説します。
1. 私たちの「願い」と「現実の壁」
まず、私たちの状況を整理しましょう。
- 私たちの願い(最大化したい関数): とにかく分散 \( f(\mathbf{u}) = \mathbf{u}^T S \mathbf{u} \) を大きくしたい。この関数は、方向 \( \mathbf{u} \) をインプットすると、その方向の分散(標高)を返してくれる「地形図」のようなものです。私たちは、この地形図の最も高い場所を目指します。
- 現実の壁(守りたい制約条件): ただし、方向ベクトル \( \mathbf{u} \) の長さは \( 1 \) でなければなりません。\( g(\mathbf{u}) = \mathbf{u}^T \mathbf{u} – 1 = 0 \) というこの制約は、私たちが移動できる範囲を半径1の円(または球面)の上に縛り付けます。
つまり、私たちの問題は「円周上だけを歩いて、地形図の最も標高が高い地点を探す」という冒険に例えることができます。
2. 「勾配」というコンパスを手に入れる
この冒険には勾配(\( \nabla \))という、強力なコンパスが必要です。
- 地形の勾配 \( \nabla f \): その地点で、最も急な上り坂がどちらを向いているかを示す矢印(ベクトル)です。矢印が長いほど、坂が急であることを意味します。
- 制約の勾配 \( \nabla g \): 円周上の点において、円の中心から外側へ向かう、円周に対して常に垂直な方向を示す矢印です。
3. 最高地点で起きる「奇跡」
円周上を歩きながら、手元のコンパス \( \nabla f \)(地形の上り坂方向)を見てみましょう。
- まだ最高地点ではない場合: コンパス \( \nabla f \) が指す方向には、多かれ少なかれ「円周に沿った成分」が残っています。つまり、円周から外れずに、まだ少しでも標高を上げられる方向がある、ということです。
- ついに最高地点に到達した瞬間: その地点では、もう円周に沿ってどちらに動いても、標高は下がるだけです。これは、一体どういう状況でしょうか?
それは、「最も急な上り坂」の方向(\( \nabla f \))が、私たちの進路(円周)に対して完全に垂直になっている状態です。つまり、\( \nabla f \) が、円の中心から外に向かう方向(\( \nabla g \))と、完全に平行になっているのです。
もし平行でなければ、まだ円周に沿って登れるはずなので、そこは最高地点ではありません。この「2つの勾配ベクトルが平行になる」という奇跡の瞬間こそが、私たちの探す最高地点の条件なのです。
4. 数学が「奇跡」を記述する
この「\( \nabla f \) と \( \nabla g \) が平行である」という幾何学的なイメージを、一本の数式で表現したものが、ラグランジュの未定乗数法の核心です。
\[ \nabla f = \lambda \nabla g \]
\( \lambda \)(ラムダ)は、2つの矢印の長さ(勢い)の違いを調整するための、ただの定数(スカラー)です。これをラグランジュ乗数と呼びます。
5. 正体を現す方程式
さて、実際に \( f(\mathbf{u}) = \mathbf{u}^T S \mathbf{u} \) と \( g(\mathbf{u}) = \mathbf{u}^T \mathbf{u} – 1 \) の勾配を計算すると(これは大学レベルの微分の計算になりますが、結果はシンプルです)、
- \( \nabla f = 2S\mathbf{u} \)
- \( \nabla g = 2\mathbf{u} \)
という形になります。これを先ほどの条件式 \( \nabla f = \lambda \nabla g \) に代入してみましょう。
\[ 2S\mathbf{u} = \lambda (2\mathbf{u}) \]
両辺を \( 2 \) で割ると、
\[ S\mathbf{u} = \lambda \mathbf{u} \]
という、見覚えのある固有値・固有ベクトルの定義式が、まるで魔法のように現れました!
これは、「分散を最大化する」という最適化問題の解が、数学的に「共分散行列の固有値問題を解くこと」と完全に同じであることを示しています。そして、方程式の調整役でしかなかったラグランジュ乗数 \( \lambda \) の正体は、私たちが探し求めていた固有値そのものだったのです。
固有値は全部でいくつ存在するのか? — データの次元との関係
さて、固有値がデータにとって重要なものであることは分かりました。では、あるデータセットを与えられたとき、固有値(と、それに対応する主成分)は一体いくつ得られるのでしょうか?
この答えは非常にシンプルです。
得られる固有値の総数は、分析対象のデータの「特徴量の数(次元の数)」と完全に一致します。
具体的に見てみましょう。
- 2つの特徴量: 「炎症マーカーX」と「代謝マーカーY」の2つの特徴量でデータを分析する場合、共分散行列は2×2の正方行列になります。このとき得られる固有値は2つです。
- 50の検査項目: 50項目の血液検査データ(50次元のデータ)を分析する場合、共分散行列は50×50の巨大な正方行列になります。このとき得られる固有値は50個です。
これは、「n次元の空間には、互いに直交する(90度で交わる)独立した軸はn本しか引けない」という幾何学的な性質を考えれば、直感的に理解しやすいかもしれません。PCAにおける固有値分解というプロセスは、n次元のデータ空間に存在するn個の「本質的な軸」を、その重要度(固有値)と共に、余すところなくすべて見つけ出す作業なのです。
このプロセスを、多次元のデータ構造を調べるための「CTスキャン」に例えることができます。
- データ: 調査対象の立体的な臓器
- 次元の数 (n): その臓器を撮影するときの「断層写真」の総枚数
- 固有値分解: CTスキャンを実行する行為
- n個の固有値と固有ベクトル: 撮影によって得られた、n枚すべての断層写真(主成分)と、それぞれの写真の「鮮明度」(固有値)
つまり、固有値分解は、データの次元数と同じ数の「断層写真」をすべて出力してくれるのです。そして、それらの写真には「鮮明度」というランクが付いているため、私たちはその後の分析で、どの写真(主成分)が診断に有用かを選ぶことができる、というわけです。
したがって、「n次元のデータからは、必ずn個の固有値が得られる」という事実が、次の「では、そのn個の中から、いくつを選べば良いのか?」という問いに繋がっていくのです。
では、主成分はいくつ選べば良いのか? — 羅針盤の使い方 🧭
さて、私たちはデータの「本質的な軸」(固有ベクトル)を見つけ出し、それぞれの重要度(固有値)を定量化することに成功しました。しかし、ここで新たな疑問が生まれます。
「結局、何個の主成分を採用すれば良いのだろうか?」
50次元のデータを2次元に削減するのか、あるいは10次元まで残しておくべきなのか。この判断は、「どれだけ情報をシンプルにしたいか」と「どれだけ元の情報を保持したいか」というトレードオフの関係にあり、分析の目的によって答えが変わります。幸い、この判断を助けてくれる、標準的な3つのアプローチが存在します。
方法1:スクリープロットで「肘」を見つける (Elbow Method)
これは、最も直感的で視覚的な方法の一つです。まず、各主成分を横軸に、その固有値を縦軸にとり、大きい順にプロットします。このグラフをスクリープロット(Scree Plot)と呼びます。
「Scree」とは、崖の麓にたまった「がれき」を意味します。グラフを見ると、通常は最初の数個の固有値が大きく(崖の部分)、その後、急に値が小さくなり、なだらかな傾斜(がれき部分)が続く形になります。
この急な崖からなだらかながれきへと傾きが大きく変わる点を「肘(Elbow)」と呼びます。この「肘」までの主成分がデータの本質的な情報を担っており、それ以降のなだらかな部分はノイズに近い、と解釈します。この方法では、「肘」にあたる部分までの主成分を採用するのが一般的です。シンプルで分かりやすい反面、どこを「肘」と見るかが分析者の主観に委ねられるという側面もあります。
方法2:累積寄与率で「情報ターゲット」を決める (Cumulative Explained Variance)
こちらは、より定量的で、実務で最も広く使われている方法です。
まず、各主成分がデータ全体の情報量(総分散)のうち、何パーセントを説明しているかを示す「寄与率」を計算します。そして、その寄与率をPC1から順に足し上げていき、「累積寄与率」を算出します。
| 主成分 | 固有値 | 寄与率 | 累積寄与率 |
|---|---|---|---|
| PC1 | 4.2 | 42% | 42% |
| PC2 | 1.9 | 19% | 61% (42+19) |
| PC3 | 1.2 | 12% | 73% (61+12) |
| PC4 | 0.8 | 8% | 81% (73+8) |
| PC5 | 0.6 | 6% | 87% (81+6) |
| … | … | … | … |
次に、分析者は「全体の情報の何パーセントを保持したいか」という目標(閾値)を事前に設定します。一般的には80%〜95%の間に設定されることが多いです。
そして、累積寄与率がこの目標を初めて超えるまでの主成分を採用します。上の表の例で、「最低でも80%の情報は保持したい」と決めた場合、PC4まで採用すれば累積寄与率が81%に達するため、「採用する主成分の数は4つ」と決定できます。この方法は客観的で、再現性が高いのが大きなメリットです。
方法3:カイザー基準というシンプルな経験則 (Kaiser’s Criterion)
これは、非常にシンプルで有名な経験則です。ただし、適用できる場面には一つ注意点があります。
カイザー基準: 固有値が1より大きい主成分のみを採用する
なぜ「1」なのでしょうか?これは、PCAを適用する前にデータを標準化(平均0, 分散1に変換)した場合に意味を持ちます。データを標準化すると、元の各変数が持つ分散は「1」になります。
つまり、ある主成分の固有値(=その主成分が持つ分散)が1を下回るということは、「その主成分は、元のたった一つの変数よりも少ない情報しか持っていない」ことを意味します。それならば、わざわざ複数の変数を合成してまで、その主成分を採用する価値は低いだろう、という考え方です。
非常に手軽な方法ですが、あくまで経験則であり、データの性質によっては最適な成分数を与えない可能性もあるため、他の方法と組み合わせて判断するのが賢明です。
まとめ:目的に応じた使い分けが肝心
これらの方法に絶対的な正解はありません。
- データを可視化したい場合: 問答無用で2つか3つの主成分を採用します。
- 他のAIモデルへの入力データを作りたい場合: 累積寄与率(例: 95%)で厳密に決めることが多いです。
- 探索的に分析したい場合: スクリープロットやカイザー基準で当たりをつけます。
最終的には、これらの手法を参考にしながら、「いくつの主成分までなら臨床的な解釈が可能か」「どのくらい情報を削ぎ落としても目的を達成できるか」といった、分析の目的と照らし合わせて、総合的に判断することが最も重要です。
PCAで医療データをスッキリさせる3つのステップ
では、ここからが本番です。PCAは具体的にどのような手順で、大量の医療データの中から本質的な情報だけを抜き出しているのでしょうか。そのプロセスを、3つのステップに分けて一緒に追いかけてみましょう。まるで探偵が複雑な事件の真相に迫るようなプロセスです。
分析の前に、データの中心を座標の原点 (0, 0) に移動させます。これを「中心化」と呼びます。これにより、データの位置ではなく、純粋な「ばらつきの構造」だけを解析できるようになります。
次に、データ内の関係性を「共分散行列」に要約し、それを数学的に分解(固有値分解)します。これにより、データのばらつきが最も大きい方向、すなわち「主成分(Principal Component)」が明らかになります。
最も重要な主軸(この場合はPC1)だけを選び、元のデータをその軸上に「射影」します。これにより、2次元のデータが1次元の情報に要約され、次元が削減されます。複雑なデータの中に隠れたパターンが見えてきます。
ステップ0:下準備 — データを「世界の中心」に揃える
本格的な分析に入る前に、とても大切な下準備があります。それは、データの中心化(Centering)です。 各特徴量(血液検査項目など)について、全体の平均値を計算し、すべてのデータからその平均値を引き算します。
なぜこれが必要かというと、PCAが知りたいのはデータの「ばらつきの方向」であって、「どこにデータがあるか」という位置情報ではないからです。すべてのデータを原点(0,0)中心に移動させることで、純粋に「ばらつきの構造」だけを解析の対象にすることができるのです。 これを忘れると、意図しない結果につながることがあるので、重要なステップです。
ステップ1:データの「関係性」を要約する(共分散行列の計算)
下準備が済んだら、いよいよデータの「性格」を捉えにかかります。手元にある数十種類の血液検査項目が、全体としてどのような「形」や「傾向」を持っているのかを、一つの行列に凝縮します。これが共分散行列です。
共分散行列は、いわば「データ内の関係性を記したカルテ」のようなものです。
- 対角成分: 各検査項目が、それ単体でどれだけばらついているか(分散)を示します。値が大きいほど、その項目の測定値が患者さんごとによく散らばっていることを意味します。
- 非対角成分: 2つの異なる検査項目のペアが、どのように一緒に動くか(共分散)を示します。
- 正の大きな値: 片方が増えると、もう片方も増える強い傾向がある(例:肥満とインリン抵抗性)。
- 負の大きな値: 片方が増えると、もう片方は減る強い傾向がある(例:運動量と体脂肪率)。
- 0に近い値: 2つの項目はあまり連動しない(無相関)。
例えば、3つの特徴量(A, B, C)からなるデータなら、共分散行列は次のようになります。
この行列には、データ全体のばらつき方や相関関係がギュッと詰まっています。そして、この共分散行列こそが、先ほどの数式における「変換役の行列 (A)」の正体なのです。
ステップ2:データの「主軸」を抜き出す(固有値分解)
次に、ステップ1で作成した共分散行列を「固有値分解」します。 これは、行列を「固有値」と「固有ベクトル」のセットに分解する操作で、言わば「カルテ(共分散行列)を読み解き、最も重要な所見(主成分)を抜き出す」作業にあたります。
この操作により、以下の2つが手に入ります。
- 固有ベクトル: データのばらつきが最も大きい方向から順に並んだ、新しい「座標軸」。これが主成分です。
- 固有値: それぞれの主成分(固有ベクトル)が、どれだけのばらつき(情報量)を担っているかを示す「重要度スコア」。
最大の固有値を持つ固有ベクトルが「第1主成分(PC1)」、2番目に大きい固有値を持つものが「第2主成分(PC2)」…というように、固有値の大きさ順にランキングが決まります。PC1が、そのデータセットの情報を最も強力に要約する一本の軸であり、PC2はPC1とは直交する(90度で交わる)方向で、次に多くの情報を要約する軸となります。
ステップ3:重要な軸だけで世界を再構成する(次元削減)
最後は、これまでの分析結果をもとに、新しい視点でデータを眺めるステップです。計算した主成分のうち、固有値の大きいもの(つまり、情報量を多く含んでいるもの)をいくつか選び、固有値の小さな重要でない軸は思い切って「無視」します。
例えば、50次元もあった血液検査データを、PC1とPC2という、たった2つの新しい軸で表現し直すのです。これは、元の50次元空間に散らばるデータ点たちを、PC1とPC2が作る2次元の平面に「射影する(影を落とす)」ようなイメージです。
これにより、50次元では決して見ることのできなかったデータの全体像が、2次元の散布図として可視化できるようになります。 その結果、患者さんがいくつかのクラスター(集団)に分かれていることや、ある治療法が効く群と効かない群の傾向の違いなどが、一目瞭然になることがあるのです。これこそが次元削減の威力です。
2008年に科学雑誌『Nature Biotechnology』で発表された解説記事でRingnér氏が述べたように、PCAは特にマイクロアレイなどの高次元な遺伝子発現データの解析で威力を発揮し、複雑なデータセットに隠されたパターンを発見するための標準的なツールとなりました (Ringnér, 2008)。 このシンプルかつ強力なアプローチは、医療AIの分野でデータを理解するための、まさに第一歩と言えるでしょう。
PCAを使いこなすための注意点:その限界を知る
さて、ここまでPCAの強力な側面を見てきましたが、どんなに優れた道具にも、得意なことと苦手なことがあります。PCAを医療現場で賢く活用するためには、その限界を正しく理解しておくことが不可欠です。ここでは、特に重要な3つの注意点についてお話しします。
1. 直線的な関係しか見つけられない(線形性の仮定)
PCAが最も得意なのは、データの特徴間の関係が直線的(線形)な場合です。先ほどの例のように、片方が増えればもう片方も(だいたい)まっすぐに増えていく、といった関係です。
しかし、もしデータの関係性が「S字カーブ」や「渦巻き」のような複雑な非線形構造をしていたらどうでしょう?PCAは、その曲がりくねった構造を無理やり一本の直線で近似しようとします。これは、カーブが続く山道を、一直線のトンネルで要約するようなものです。大まかな方向はわかっても、道のりの重要なディテールはすべて失われてしまいますよね。
このような複雑な構造を持つデータに対しては、t-SNEや多様体学習といった、より高度な次元削減手法(後の講座で詳しく解説します)の出番となります。
2. 新しい「軸」の解釈が難しいことがある
PCAが生み出す主成分(PC1, PC2など)は、元の特徴量を混ぜ合わせて作られた、まったく新しい「合成変数」です。その計算式は、例えば次のようになります。
PC1 = (0.7 × コレステロール値) + (0.4 × 中性脂肪) - (0.2 × 血糖値) + ...
これは、様々な果物や野菜をミキサーにかけて作る「特製スムージー」のようなものだと考えてみてください。出来上がったスムージー(主成分)が患者さんの全体的な状態をうまく表していることはわかっても、「この味は、どの材料がどれくらい貢献しているのだろう?」と、その内訳を正確に説明するのは難しい場合があります。
この「解釈の難しさ」はPCAの宿命とも言え、臨床的な意味付けを考える際には常に念頭に置く必要があります。
3. 変数の「単位」に大きく影響される(スケールの問題)
PCAはデータの「ばらつき(分散)」が大きい方向を探す手法でした。ここに、一つ大きな落とし穴があります。もし、単位が全く違う変数をそのまま投入してしまったら、どうなるでしょうか?
例えば、「血糖値(mg/dL)」のように数百単位の値をとる変数と、「あるホルモンの濃度(ng/mL)」のように非常に小さな値をとる変数を一緒に分析したとします。計算上、値の尺度が大きい血糖値のばらつきが圧倒的に大きくなるため、PCAは「血糖値の方向が最も重要だ!」と判断してしまいます。他の変数が持つかもしれない重要な情報が、スケールの違いによってかき消されてしまうのです。
これを防ぐため、PCAを適用する前には、必ずすべての特徴量のスケールを揃えるという前処理を行います。具体的には、各特徴量を平均が0、分散が1になるように「標準化(Standardization)」するのが一般的です。これにより、すべての変数が対等な立場で分析に参加できるようになります。
これらの注意点は、PCAの欠点を指摘しているわけではありません。むしろ、この手法が1901年に数学者カール・ピアソンによって発表されて以来 (Pearson, 1901)、1世紀以上にわたってデータサイエンスの基本ツールとして生き残ってきた理由を示唆しています。 Jolliffe氏らのレビューが示すように、PCAはそのシンプルさと強力さから、様々な分野で発展を遂げてきました (Jolliffe & Cadima, 2016)。その限界を理解し、適切に使うことで、PCAは初めて医療データという複雑な情報の海を航海するための、信頼できる羅針盤となるのです。
まとめ:情報の霧を晴らし、データの本質を見通す視点
今回は、情報の洪水の中から「本当に大事な軸」を見つけ出す主成分分析(PCA)と、その心臓部である固有値・固有ベクトルの考え方について、一緒に探求してきました。
思い出してみてください。私たちの旅は、無数の検査データという、どこから手をつければ良いかわからない情報の霧の中から始まりました。しかし、PCAという羅針盤を手に入れることで、霧の中に隠されていた道筋が見えてきました。
- 固有ベクトルが、データのばらつきが最も大きい「進むべき方向」を指し示し、
- 固有値が、その方向がどれだけ確かで「重要」な道であるかを教えてくれる。
このシンプルな仕組みによって、AIは一見カオスに見える複雑な医療データを、より本質的で扱いやすい情報へと変換しているのです。
PCAは、AIがデータを理解するための、いわば「オーダーメイドの視力矯正メガネ」のようなものだと言えるでしょう。一人ひとりの患者さんが持つ、ぼやけて見えづらかった高次元のデータが、このメガネをかけることで、その特徴がくっきりと浮かび上がってきます。
この新しい視点を通してデータを見ることで、私たちはこれまで気づかなかった患者さんの隠れた特徴や、疾患の新たなパターンを発見できる可能性を手にします。数学という強力な言語が、AIを通じてこれからの医療をどう変革していくのか、その冒険はまだ始まったばかりです。ワクワクしてきませんか?
参考文献
- Pearson, K. 1901. On Lines and Planes of Closest Fit to Systems of Points in Space. Philosophical Magazine 2(11):559–572. doi:10.1080/14786435.1901.10395182
- Hotelling, H. 1933. Analysis of a Complex of Statistical Variables into Principal Components. Journal of Educational Psychology 24(6):417–441. doi:10.1037/h0071325
- Eckart, C., & Young, G. 1936. The Approximation of One Matrix by Another of Lower Rank. Psychometrika 1(3):211–218. doi:10.1007/BF02288367
- Golub, G. H., & Reinsch, C. 1970. Singular Value Decomposition and Least Squares Solutions. Numerische Mathematik 14:403–420. doi:10.1007/BF02163027
- Gabriel, K. R. 1971. The Biplot Graphic Display of Matrices with Application to Principal Component Analysis. Biometrika 58(3):453–467. doi:10.1093/biomet/58.3.453
- Horn, J. L. 1965. A Rationale and Test for the Number of Factors in Factor Analysis. Psychometrika 30:179–185. doi:10.1007/BF02289447 PMID:14306381
- Cattell, R. B. 1966. The Scree Test for the Number of Factors. Multivariate Behavioral Research 1(2):245–276. doi:10.1207/s15327906mbr0102_10 PMID:26828106
- Schölkopf, B., Smola, A., & Müller, K.-R. 1998. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Computation 10(5):1299–1319. doi:10.1162/089976698300017467
- Tipping, M. E., & Bishop, C. M. 1999. Probabilistic Principal Component Analysis. Journal of the Royal Statistical Society: Series B 61(3):611–622. doi:10.1111/1467-9868.00196
- Tenenbaum, J. B., de Silva, V., & Langford, J. C. 2000. A Global Geometric Framework for Nonlinear Dimensionality Reduction (Isomap). Science 290(5500):2319–2323. doi:10.1126/science.290.5500.2319
- Roweis, S. T., & Saul, L. K. 2000. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 290(5500):2323–2326. doi:10.1126/science.290.5500.2323
- van den Berg, R. A., Hoefsloot, H. C. J., Westerhuis, J. A., Smilde, A. K., & van der Werf, M. J. 2006. Centering, Scaling, and Transformations: Improving the Biological Information Content of Metabolomics Data. BMC Genomics 7:142. doi:10.1186/1471-2164-7-142
- van der Maaten, L., & Hinton, G. 2008. Visualizing Data Using t-SNE. Journal of Machine Learning Research 9:2579–2605. Link【NO-DOI】
- McInnes, L., Healy, J., & Melville, J. 2018. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 1802.03426. Link [Preprint]
- Jolliffe, I. T., & Cadima, J. 2016. Principal Component Analysis: A Review and Recent Developments. Philosophical Transactions of the Royal Society A 374(2065):20150202. doi:10.1098/rsta.2015.0202 PMID:26953178
- Bro, R., & Smilde, A. K. 2014. Principal Component Analysis. Analytical Methods 6(9):2812–2831. doi:10.1039/C3AY41907J
- Abdi, H., & Williams, L. J. 2010. Principal Component Analysis. Wiley Interdisciplinary Reviews: Computational Statistics 2(4):433–459. doi:10.1002/wics.101
- Ringnér, M. 2008. What Is Principal Component Analysis? Nature Biotechnology 26(3):303–304. doi:10.1038/nbt0308-303
- Greenacre, M., Blasius, J., & Nenadić, O. 2022. Principal Component Analysis. Nature Reviews Methods Primers 2:41. Link
- Jolliffe, I. T. 2002. Principal Component Analysis (2nd ed.). Springer. doi:10.1007/b98835
- Bishop, C. M. 2006. Pattern Recognition and Machine Learning. Springer. doi:10.1007/978-0-387-45528-0
- Hastie, T., Tibshirani, R., & Friedman, J. 2009. The Elements of Statistical Learning (2nd ed.). Springer. doi:10.1007/978-0-387-84858-7
- Izenman, A. J. 2008. Modern Multivariate Statistical Techniques: Regression, Classification and Manifold Learning. Springer. doi:10.1007/978-0-387-78189-1
- Shlens, J. 2014. A Tutorial on Principal Component Analysis. arXiv 1404.1100. Link [Preprint]
- Luecken, M. D., & Theis, F. J. 2019. Current Best Practices in Single-Cell RNA-seq Analysis: A Tutorial. Molecular Systems Biology 15(6):e8746. doi:10.15252/msb.20188746
- Satija, R., Farrell, J. A., Gennert, D., Schier, A. F., & Regev, A. 2015. Spatial Reconstruction of Single-Cell Gene Expression Data. Nature Biotechnology 33:495–502. doi:10.1038/nbt.3192
- Elhaik, E. 2022. PCA-Based Findings in Population Genetics: Reassessment. Scientific Reports 12:14651. doi:10.1038/s41598-022-14395-4
- 大塚 芳嵩. 2023. 【日本語】中級の統計解析(5)~主成分分析~. 日本放射線技術学会雑誌 49(2):217–226. doi:10.7211/jjsrt.49.217
- 中森 義輝. 2003. 【日本語】感性評価データの主成分分析に関する考察. 日本知能情報ファジィ学会誌 15(6). Link【NO-DOI】
- 大阪研究開発型企業振興協会(ORIST). 2021. 【日本語】データ解析入門3<主成分分析によるデータマイニング>. 技術シート. Link【NO-DOI】
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




