

AI研究の信頼性を支える「仮想環境」の重要性と、クリーンな環境にPyTorchをセットアップする基本手順を学びます。これは、誰が実行しても同じ結果を得られる「再現性の高い研究」を行うための必須スキルです。
PC全体を一つの実験室と見なすと、プロジェクト毎にライブラリのバージョンが衝突する「環境汚染」が起こりがちです。仮想環境はプロジェクト毎に独立した「無菌室」を作り、研究の再現性を技術的に保証します。
1. 作成: `python3 -m venv venv`
2. 有効化: `source venv/bin/activate`
3. 無効化: `deactivate`
このシンプルなサイクルが、再現性の高いAI開発の基本の「型」となります。
無菌室(仮想環境)に入った後、公式サイトでCUDAバージョンに合わせたコマンドを取得しPyTorchを導入します。最後に`torch.cuda.is_available()`で`True`が返ればGPUとの連携は成功です。
この記事は、AI研究の再現性を担保するための仮想環境の重要性を理解し、そのクリーンな環境にPyTorchをGPUと連携させて導入する手順を解説します。
1. 仮想環境の基本作法 (デジタル無菌操作)
プロジェクトごとにライブラリ(試薬)を隔離し、バージョン衝突(環境汚染)を防ぎます。これが研究の信頼性を守る基本です。
① 無菌室の作成 (初回のみ):
# プロジェクト用フォルダに移動後、'venv'という名前の環境を作成
python3 -m venv venv
② 無菌室に入る (作業開始時):
# 仮想環境を有効化。プロンプトの先頭に (venv) が表示される
source venv/bin/activate
③ 無菌室から出る (作業終了時):
# 仮想環境を無効化
deactivate
2. PyTorch (GPU版) のインストール手順
必ず仮想環境を有効化 (source venv/bin/activate) してから以下の手順に進んでください。
CUDAバージョンの確認:
ターミナルで nvidia-smi を実行し、右上に表示されるCUDA Version(例: 12.2)を確認します。
インストールコマンドの生成:
PyTorch公式サイト(https://pytorch.org/get-started/locally/)にアクセスし、お使いの環境(Linux, Pip, Python, 確認したCUDAバージョン以下で最新のもの)を選択して、インストールコマンドを生成・コピーします。
PyTorchのインストール:
ターミナルにコピーしたコマンド(以下は一例)を貼り付けて実行します。
# (venv) が表示されていることを確認!
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
最終確認:
python3 で対話モードを起動し、以下のコマンドで True と表示されれば成功です。
# Python対話モードで実行
import torch
torch.cuda.is_available()
医療AI研究の再現性を高めるプロの作法を学ぶ
これまでの道のりで、私たちはAI開発という家を建てるための、揺るぎない「土台」を築いてきました。OSを整え、NVIDIAドライバという名の「電気」を引き、nvidia-smiでGPUが力強く脈打っていることを確認しましたね。本当にお疲れ様でした。
さあ、いよいよ今回はその土台の上に、私たちの研究の拠点となる「実験室」そのものを建て、中に最先端の分析機器を搬入していく、最もワクワクする工程です。具体的には、AI・データサイエンスの世界の公用語であるPythonと、その中でも特にアカデミックの世界で絶大な信頼を得ている深層学習ライブラリPyTorchを、GPUのパワーをフル活用できる形で導入していきます。
しかし、本題に入る前に、一つだけ皆さんに習得していただきたい、極めて重要な「作法」があります。それは、ただツールをインストールするのではなく、「クリーンな環境で、再現性の高い研究を行うための技術」です。医療の世界で、実験器具の滅菌や手洗いが基本中の基本であるように、計算科学の世界にも、絶対に守るべき「デジタルな無菌操作」が存在します。それが、今回学ぶ「仮想環境」という考え方です。
この概念を自分のものにすること。それこそが、この記事を通じて皆さんに届けたい最大の価値であり、今後のあなたの研究者としてのキャリアを支える、一生モノのスキルになると私は信じています。
研究者の作法:なぜ「仮想環境」が絶対に必要か?
本格的なインストール作業に入る前に、まずAI研究者として、そして科学者として最も大切な習慣、「仮想環境」について、その神髄を理解しましょう。これは単なるテクニックではなく、あなたの研究の信頼性を守るための「哲学」です。
汚染された実験室の悲劇
医療や生命科学の研究室では、実験ごとに器具を滅菌し、手袋を交換するのは当たり前ですよね。もし、ある実験で使ったピペットを洗浄せずに、そのまま別の実験に使ってしまったらどうなるでしょう?コンタミネーション(汚染)が起き、得られたデータは全く信頼できないものになってしまいます。
実は、PC上でのAI開発もこれと全く同じです。PC全体を一つの「大きな実験室」だと考えてみてください。
プロジェクトA(肺がんの画像診断モデル開発)では、medical-image-library というライブラリのバージョン1.0を使い、素晴らしい結果を得て、論文を投稿しました。
半年後、新しいプロジェクトB(電子カルテのテキスト解析)を始めました。このプロジェクトでは、最新の機能を使うために、同じ medical-image-library を最新のバージョン2.0にアップデートする必要がありました。
もし、この二つのプロジェクトを同じ「実験室」(PCのグローバル環境)で行っていたら…恐ろしいことが起こります。プロジェクトBのためにライブラリをアップデートした瞬間、プロジェクトAのコードは、依存するライブラリのバージョンが変わってしまったため、論文と同じ結果を再現できなくなってしまうのです。査読者から「このコードを動かしてみたい」と言われても、もはや動かない。これは、研究者にとって悪夢以外の何物でもありません。
「デジタルな無菌操作」としての仮想環境
この「環境のコンタミネーション」という悪夢を防ぐ、唯一にして完璧な解決策が「仮想環境」です。
仮想環境とは、プロジェクトごとに、完全に隔離され、使い捨て可能な、まっさらな「無菌室(クリーンルーム)」をソフトウェア的に作り出す技術です。各無菌室には、そのプロジェクトで必要なバージョンの試薬(ライブラリ)だけを、必要な分だけ揃えます。
あなたのPC(研究棟全体)
│
├─📁 プロジェクトA用の無菌室 (venv-lung-cancer)
│ │ 【室内の棚】
│ ├─ Python 3.10
│ ├─ PyTorch 2.1
│ └─ medical-image-library v1.0
│
├─📁 プロジェクトB用の無菌室 (venv-emr-text)
│ │ 【室内の棚】
│ ├─ Python 3.10
│ ├─ PyTorch 2.3
│ └─ medical-image-library v2.0
│
└─📁 プロジェクトC用の無菌室 (venv-genomics)
│ 【室内の棚】
├─ Python 3.11
├─ TensorFlow 2.15
└─ genomics-toolkit v4.2
このように、プロジェクトごとに完全に独立した環境を用意することで、ある実験室での作業が、隣の実験室に影響を及ぼすことは一切なくなります。
これにより、科学の根幹である「再現性(Reproducibility)」、つまり「いつ、誰が、どこでやっても、同じ条件なら同じ結果が得られること」を、技術的に保証することができるのです。これは、あなたの研究成果の信頼性を守るための、何よりも強力な盾となります。
ハンズオン:3つのコマンドで学ぶ「デジタル無菌室 (venv)」の作り方と使い方
さて、理論はもう十分ですね。ここからは、先ほど学んだ「デジタルな無菌操作」としての仮想環境を、実際にあなたの手で作り、操作する体験をしてみましょう。これから紹介する一連のコマンドは、一度覚えてしまえば、今後のAI開発プロジェクトで毎回のように使う、あなたの強力な武器になります。
今回は、Pythonに標準で付属しているvenvという、最も基本的で信頼性の高いツールを使います。
実行用の安全なコマンド一覧 (Ubuntu)
# 1. 前提パッケージのインストール(初回のみ)
sudo apt update && sudo apt install python3-pip python3-venv
# 2. プロジェクト用ディレクトリを作成して移動
mkdir "medical-ai-project-1" && cd "medical-ai-project-1"
# 3. 'venv' という名前の仮想環境を作成
python3 -m venv venv
# 4. 仮想環境を有効化(プロンプトの先頭に (venv) と表示)
source venv/bin/activate
# --- ここでライブラリのインストール(pip install)など作業を行う ---
# 5. 作業が終わったら仮想環境を無効化
deactivate
準備:Pythonとpipの存在確認
まずは、あなたのUbuntu環境に、Python本体とその「試薬(ライブラリ)」を管理するためのパッケージ管理ツールpipが正しくインストールされているかを確認します。ターミナルを開き、以下の2つのコマンドをそれぞれ実行してみてください。
# python3 のバージョン情報を表示します。
python3 --version
# python3 に対応するパッケージ管理ツール pip3 のバージョン情報を表示します。
pip3 --version
それぞれ Python 3.10.x や pip 22.x.x のようなバージョン番号が表示されれば、準備は万端です。
【もしも…】コマンドが見つからない場合
もし command not found と表示された場合は、以下のコマンドを一度だけ実行して、pipとvenvをインストールしてください。sudo apt update && sudo apt install python3-pip python3-venv
Step 1: プロジェクトの「無菌室」を建てる
それでは、最初のAIプロジェクトのための、まっさらな「無菌室」を建てましょう。
まず、その研究室を建てるための土地(ディレクトリ/フォルダ)を用意し、そこに移動します。今後の作業はすべて、このプロジェクト専用のディレクトリの中で行います。
# "medical-ai-project-1" という名前で、このプロジェクト専用のディレクトリを作成します。
mkdir "medical-ai-project-1"
# 作成したディレクトリの中に移動します。
cd "medical-ai-project-1"
# python3 の venv モジュール(-m venv)を使い、"venv" という名前の仮想環境を作成します。
python3 -m venv venv
この python3 -m venv venv というコマンド、少し不思議に見えませんか?これは以下のように分解できます。
python3: 「Python 3を使って、これから命令を実行します」-m venv: 「Pythonに付属する venv というツール(モジュール)を呼び出します」venv: 「作成する仮想環境のフォルダ名を venv にします」
最後のフォルダ名は my_env など好きな名前にできますが、venv という名前にするのが慣習として一般的です。これを実行すると、現在のディレクトリに venv というサブディレクトリが作成されます。このフォルダの中に、隔離されたPython実行環境や、これからインストールするライブラリを保管する場所など、無菌室を構成する全ての要素が格納されます。
Step 2: 「無菌室」に入る (source …/activate)
研究室を建てただけでは、まだ中には入れません。次に、ターミナルに対して「これから、この無菌室に入って作業を開始します」と宣言する有効化(activate)のコマンドを実行します。
# 'venv' フォルダの中にある 'bin' フォルダの中の 'activate' というスクリプトを実行(source)します。
source venv/bin/activate
このコマンドを実行した瞬間、あなたのターミナルの表示に変化が起きます。コマンドを入力する行の先頭に、(venv) という文字が追加されたはずです。
(venv) your_username@your_pc:~/medical-ai-project-1$
これが、あなたが無菌室の中にいることを示す、何よりの証拠です。おめでとうございます!この (venv) が表示されている間に行った pip install は、全てこの無菌室の中だけにインストールされ、PCの他の部分を一切「汚染」することはありません。
Step 3: 「無菌室」から出る (deactivate)
プロジェクトの作業が一段落し、無菌室から退出して、PC全体の環境に戻りたい時はどうすればよいでしょうか?答えは驚くほど簡単です。以下のコマンドを一つ、実行するだけです。
# 現在有効化されている仮想環境を停止します。
deactivate
これを実行すると、プロンプトの先頭から (venv) の表示がすっと消え、元の状態に戻ります。まるで、白衣を脱いで研究室から退出するようですね。
この「mkdir & cd → python3 -m venv venv → source venv/bin/activate → (作業) → deactivate」という一連の流れ。これが、再現性の高い研究を行うための、基本的かつ最も重要なワークフローです。ぜひ、何度も繰り返して、呼吸をするように自然にできるようになってください。
分析機器の搬入:主役の「PyTorch」をGPUと共に導入する
私たちの「無菌室(仮想環境)」の準備が整いました。いよいよ、このまっさらな実験室に、メインとなる最先端の分析機器を搬入します。その主役こそが、PyTorchです。
Meta社(旧Facebook)が主導で開発するPyTorchは、その柔軟性と、まるで通常のPythonコードを書くような直感的な書き心地から、特に論文執筆などを行う学術研究の世界で絶大な支持を得ている深層学習フレームワークです。
実行用のコマンドとPro-Tip
# 1. 仮想環境を有効化(最重要!)
source venv/bin/activate
# 2. GPUドライバとCUDAバージョンを確認
nvidia-smi
# 3. PyTorch公式サイトで生成したコマンドを実行(※以下は一例)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 4. Python対話モードでインストールを検証
python3
# >>> import torch
# >>> print(torch.cuda.is_available())
# Trueと表示されれば成功
# >>> exit()
# AIの学習結果にほぼ影響を与えずに計算速度を向上させるおまじない
import torch
torch.backends.cuda.matmul.allow_tf32 = True
インストールの鍵は公式サイトにあり
PyTorchのインストールで成功と失敗を分ける最大のポイントは、あなたのPC環境(OS、Pythonのバージョン、そしてCUDAのバージョン)に完璧に合致した、正しいインストールコマンドを使うことです。これらの組み合わせは非常に多く、また日々更新されていくため、手探りでコマンドを推測するのはエラーの元です。
幸い、PyTorchの公式サイトには、その「完璧なコマンド」を自動で生成してくれる、非常に親切なウィジェットが用意されています。インストールは必ずここから始めましょう。
- PyTorch公式サイトのGet Startedページにアクセスします。
https://pytorch.org/get-started/locally/ - あなたの環境に合わせて、対話形式で選択肢を埋めていきます。
- PyTorch Build:
Stable(安定版) を選びます。 - Your OS:
Linuxを選択します(WSL2をお使いの場合もLinuxです)。 - Package:
Pipを選択します。 - Language:
Pythonを選択します。 - Compute Platform:
CUDAと書かれた選択肢の中から、あなたの環境に合ったものを選びます。
- PyTorch Build:
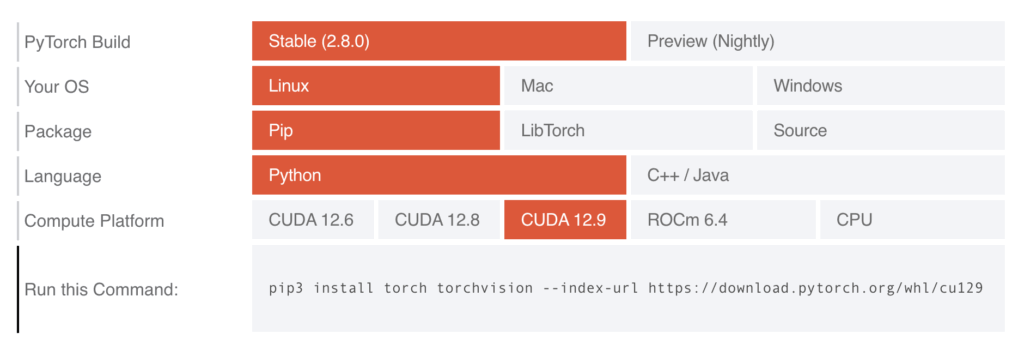
【重要】Compute Platform (CUDA) の選び方
Compute Platformの選択は、GPU性能を引き出すための最重要項目です。まず、ターミナルで nvidia-smi を実行し、右上に表示される CUDA Version を確認してください。例えば、CUDA Version: 12.2 と表示されたとします。
この場合、PyTorchのサイトでは CUDA 12.1 や CUDA 11.8 といった、表示されたバージョン以下の選択肢を選ぶのが基本です(PyTorchは前方互換性があるため、新しいドライバで古いCUDAツールキット向けにビルドされたものも動作します)。一般的には、表示されている選択肢の中で最も新しい安定版(例: CUDA 12.1)を選んでおけば問題ありません。
全ての項目を選択すると、Run this Command: の下に、あなたが実行すべき唯一無二のコマンドが自動で生成されます。これをクリップボードにコピーしてください。
ハンズオン:PyTorchを仮想環境にインストールする
さあ、「完璧な呪文」が手に入りました。これを実行していきましょう。
【最重要】作業前に、必ず無菌室に入ってください!
PyTorchをインストールする前に、必ず、先ほど作成した仮想環境を有効化(activate)してください。ターミナルのプロンプトの先頭に (venv) が表示されていることを、必ず確認しましょう。これを忘れると、PC本体の環境が「汚染」されてしまいます。
source venv/bin/activate無菌室に入っていることを確認したら、公式サイトでコピーしたコマンドをターミナルに貼り付けて、Enterキーを押します。以下はCUDA 12.1を選んだ場合の一例です(繰り返しになりますが、必ずご自身の環境に合わせて公式サイトで生成したコマンドを使ってください)。
# PyTorch本体(torch)、画像処理ライブラリ(torchvision)、音声処理ライブラリ(torchaudio)を
# 指定されたCUDAバージョン(この例ではcu121)に対応する形でインストールします。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
PyTorchは比較的大さなライブラリですので、インストールには数分かかります。コーヒーでも飲みながら、気長に待ちましょう。
動作確認:PythonからGPUへ正しく繋がったかを確認する
インストールが完了したら、いよいよ最終確認です。この仮想環境(無菌室)に正しくPyTorchが導入され、かつGPUを認識できる状態にあるかを確かめます。
Python対話モードを起動
(venv) が表示されたターミナルで、python3と入力してEnterキーを押します。>>>という記号が表示され、Pythonと直接対話できるモードになります。
PyTorchをインポートし、GPUの可用性を確認
以下の2行を順番に入力してください。
# 最初に、インストールしたPyTorchライブラリをプログラムに読み込みます。
import torch
# 次に、PyTorchに対して「CUDA対応のGPUは利用可能ですか?」と尋ねます。
torch.cuda.is_available()
結果の確認
最後の torch.cuda.is_available() を実行した後、True という応答が返ってきたら、インストールは完璧に成功しています! 🎉
(venv) user@ubuntu:~/medical-ai-project-1$ python3
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
True
>>>
この True という一言は、「PyTorchがGPUを正しく認識し、いつでもその計算能力を使える状態にある」ことを示す、何よりの証拠です。
【Pro-Tip】ワンランク上のパフォーマンスを引き出す「TF32」
もしあなたがNVIDIAのAmpereアーキテクチャ以降(RTX 30シリーズ、40シリーズなど)のGPUをお使いなら、簡単な「ブーストスイッチ」を入れることで、多くの場合、学習速度を10-20%程度向上させることができます。
PyTorchのコードの冒頭に、以下の「おまじない」を一行追加するだけです。torch.backends.cuda.matmul.allow_tf32 = True
これは、行列計算の際に、完全な精度(FP32)よりほんの少しだけ「大雑把」なTF32 (TensorFloat-32)という形式の使用を許可する設定です。患者さんの身長をミリメートル単位(例: 1751.2mm)で測る代わりに、センチメートル単位(175.1cm)で記録するようなものです。最終的な診断結果にはほとんど影響しないのに、カルテに記録するスピードは格段に上がりますよね。これと同じで、AIの学習結果にほぼ影響を与えずに、計算速度だけを向上させることができる、最新GPUのハードウェア性能を活かした非常に賢いテクニックです。
最終確認:PythonからGPUへ、最初の「握手」を交わす
お疲れ様でした。理論を学び、無菌室(仮想環境)を作り、最先端の分析機器(PyTorch)を搬入しました。さあ、全ての準備が整った今、この実験室が本当に機能するのか、究極のテストを行います。
私たちの書いたPythonのコードが、PyTorchという通訳を介して、GPUというハードウェアの心臓部と、正しく「握手」を交わせるのか。その歴史的瞬間を確認しましょう。
まず、(venv) が表示されている、仮想環境が有効なターミナルで、python3 と入力してEnterキーを押し、Pythonとの対話モード(インタラクティブシェル)に入ってください。これは、Pythonと一行ずつおしゃべりをしながら、その応答をすぐに見ることができる、簡単な動作確認に最適なモードです。
>>> というプロンプトが表示されたら、以下のコードを一行ずつ、あるいはまとめてコピー&ペーストして、Enterキーを押してみてください。
# まず、私たちの通訳であるPyTorchライブラリを呼び出します。
import torch
# 次に、PyTorchに「CUDA対応のGPUは見えますか?」と尋ねます。
# `True` が返ってきたら、第一関門突破です!
is_available = torch.cuda.is_available()
print(f"PyTorch can see the GPU: {is_available}")
# もし見えていたら、さらに「GPUは何台ありますか?」と尋ねます。
# 個人用のPCなら、通常は `1` と返ってきます。
if is_available:
device_count = torch.cuda.device_count()
print(f"Number of available GPUs: {device_count}")
# 最後に「0番目のGPUの名前を教えてください」とお願いします。
# これで、具体的なGPUモデル名が表示されるはずです。
gpu_name = torch.cuda.get_device_name(0)
print(f"GPU Name: {gpu_name}")
これを実行し、あなたのターミナルに以下のような祝福のメッセージが表示されたなら… あなたの完全な勝利です!
PyTorch can see the GPU: True
Number of available GPUs: 1
GPU Name: NVIDIA GeForce RTX 4090
この数行のテキストは、これまでの全ての努力の集大成です。あなたが書いたPythonコードが、隔離された仮想環境の中から、OSの壁を越え、ドライバを介して、物理的なGPUハードウェアの能力を直接コマンドできるようになったことを示す、動かぬ証拠なのです。
もし False と表示されたら?
もし最初の行で PyTorch can see the GPU: False と表示された場合、最も一般的な原因はPyTorchのインストールミスです。慌てずに以下を確認してください。
- CPU版をインストールしていませんか? PyTorch公式サイトのウィジェットで、誤ってCompute Platformを「CPU」で選択してしまった可能性があります。もう一度公式サイトで、今度は正しく「CUDA」のバージョンを選択したコマンドを生成し、
pip installをやり直してみてください。 - 仮想環境は有効ですか? PyTorchをインストールした仮想環境(
(venv)が表示されている状態)で、正しくPythonを起動していますか?
まとめと次のステップへ
お疲れ様でした!この記事では、AI研究におけるプロの作法である「仮想環境」をマスターし、GPUのパワーを秘めたPyTorchをその中にインストールしました。これで、あなたの研究室には、最先端の実験機器が揃ったことになります。
次の最終回「E0.1.4: VS Codeによるリモート開発環境」では、この素晴らしい研究室を、最も快適で、最も効率的に使うための「働き方」をデザインします。ぜひ、最高の開発体験を手に入れるための、最後の一歩までお付き合いください。

Medical AI Nexus で学びを深めませんか?
【🔰 Medical AI Nexus とは】
日々の診療から生まれる膨大な医療データ――その価値を AI で最大化できれば、診断・治療・予防の姿は大きく変わります。
「Medical AI Nexus」は、AI を“医療者の最高のパートナー”に育てるための『知の羅針盤』です。
初心者でも実践的に学べる体系的コンテンツを通じて、
①「わからない」を解決する基礎講座、
②“使える”を支援する実装講座、
③専門分野への応用を探究する臨床シリーズを提供し、
医療者の能力拡張とデータ駆動型医療への航海を後押しします。
引用文献
- Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In: Wallach H, Larochelle H, Beygelzimer A, d’Alché-Buc F, Fox E, Garnett R, editors. Advances in Neural Information Processing Systems 32. Curran Associates, Inc.; 2019. p. 8024–8035.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




