


現代AIの心臓部、「Transformer」へようこそ
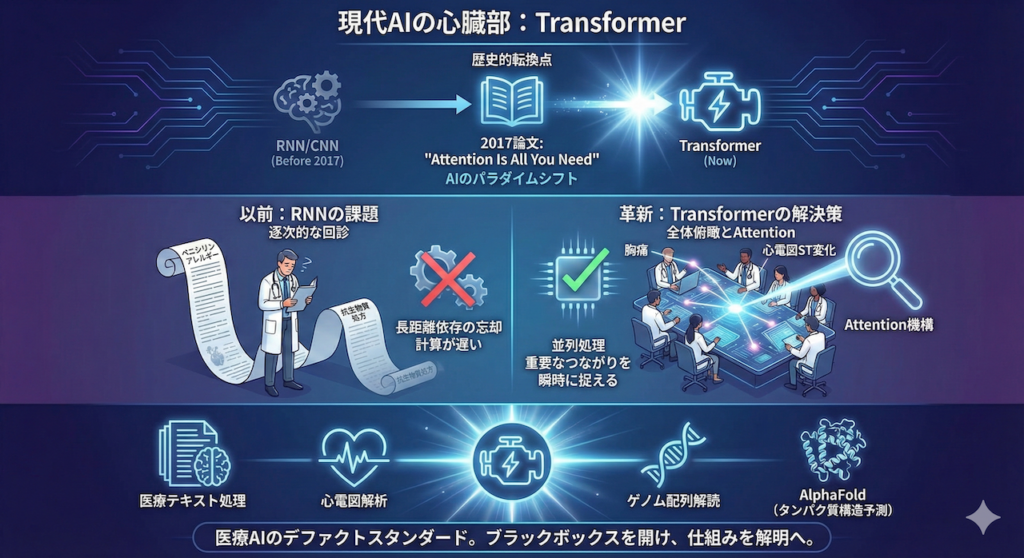
みなさん、こんにちは。これまでの連載で、私たちは画像診断の主役であるCNN(畳み込みニューラルネットワーク)で「AIの目」を、そして時系列データ解析の基礎であるRNN(回帰型ニューラルネットワーク)で「AIの記憶」を学んできました。
今回はいよいよ、現在のAIブームの立役者であり、ChatGPTやGPT-4、さらには医療用大規模言語モデル(LLM)の基礎となっているTransformer(トランスフォーマー)について深掘りしていきます。これは単なる「新しいモデル」ではありません。AIが言葉やデータを理解する方法を根本から変えた、歴史的な転換点なのです。
1. 2017年、AIの歴史が変わった

2017年、Googleの研究チームが発表した論文のタイトルは、AI研究者たちに衝撃を与えました。その名は “Attention Is All You Need”(必要なのは「注意(Attention)」だけ)。
それまでの自然言語処理や時系列解析では、RNNやCNNを使うことが「常識」でした。しかし、この論文は「過去のデータを順番に処理するRNNも、局所的な特徴を見るCNNも不要だ。Attention(注意機構)さえあれば、もっとうまくいく」と主張し、実際に最高性能(SOTA)を記録してしまったのです。
なぜTransformerが必要だったのか?
従来のRNNには、医療データの解析において致命的な弱点がありました。それは「長距離の依存関係に弱い」ということです。
例えば、長い経過記録の冒頭にある「ペニシリンアレルギー」という情報と、末尾にある「抗生物質の処方」という情報の関連性を、RNNは文章が長くなればなるほど忘れてしまいがちでした。また、データを先頭から順番に計算する必要があるため、計算の並列化ができず、学習に膨大な時間がかかっていました。
Transformerは、これらの問題を「並列処理」と「Attention」によって鮮やかに解決しました。
2. その秘密は「医療現場」に例えると直感的にわかる
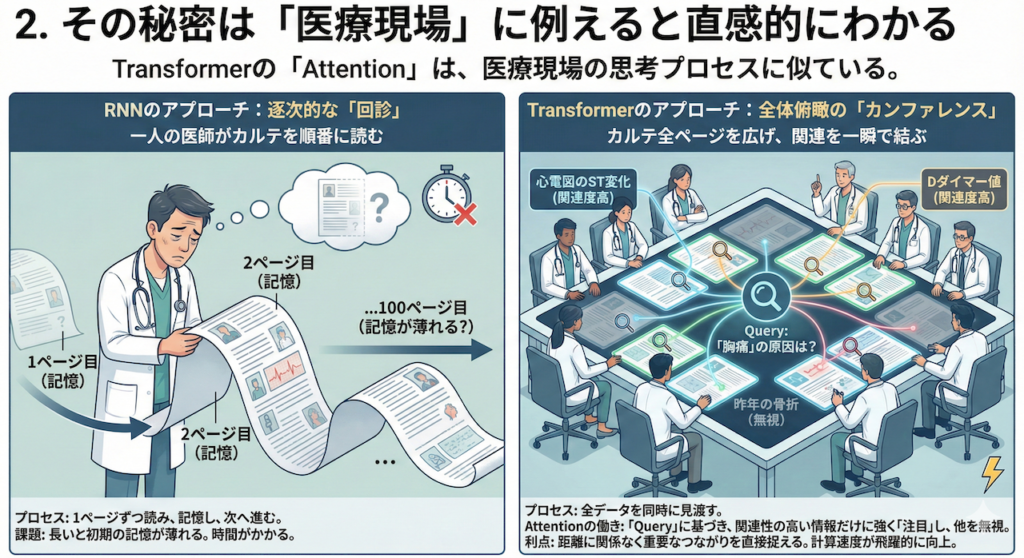
なぜTransformerがこれほどまでに強力なのか? その「Attention」の仕組みは、実は医療現場における私たちの思考プロセスに非常によく似ています。
RNNのアプローチ:逐次的な「回診」
RNNの処理は、いわば「一人の医師が、分厚いカルテを1ページ目から順番に読んでいく」ようなものです。
- プロセス: 1ページ目を読み、記憶し、2ページ目へ進む…。
- 課題: 100ページ目を読む頃には、1ページ目の詳細(例えば数年前の既往歴)の記憶が薄れているかもしれません。また、前のページを読み終わらないと次へ進めないため、時間がかかります。
Transformerのアプローチ:全体俯瞰の「カンファレンス」
一方、Transformer(Self-Attention)の処理は、「カルテの全ページを会議テーブルの上に広げ、関連する項目を一瞬で線で結ぶ」ようなものです。
- プロセス: 入力されたデータ(文章や時系列)のすべてを同時に見渡します。
- Attentionの働き: 「今、この患者さんの『胸痛』の原因を考えている」という文脈(Query)において、数百ページあるカルテの中から「心電図のST変化」や「Dダイマー値」といった関連性の高い情報だけに強く「注目(Attend)」し、それ以外の無関係な情報(例えば昨年の骨折の記録など)は無視します。
- 利点: 情報の距離に関係なく、重要なつながりを直接捉えることができます。また、全データを同時に処理できるため、計算速度が飛躍的に向上します。
3. 本記事のゴール:ブラックボックスを開け、実際に動かす
Transformerは、今やテキスト処理だけでなく、心電図解析、ゲノム配列の解読、さらにはタンパク質の立体構造予測(AlphaFold)など、医療AIのあらゆる領域でデファクトスタンダード(事実上の標準)となっています。
今日はその強力なエンジンの内部で何が起きているのか、ブラックボックスを開けてみましょう。「Attention」という概念がどのように数式で表現され、プログラムとして動いているのか。その仕組みを、医療データを題材にした数式とコードの概念を交えながら、徹底的に解剖していきます。
さらに今回は、実際にPythonコードを動かして、AIが医療テキストの「意味」をどのように計算しているのかを体験する実習も行います。「類似症例検索」のようなタスクを通じて、Transformerの威力を肌で感じてみましょう。
1. RNNの限界と「Attention」の登場
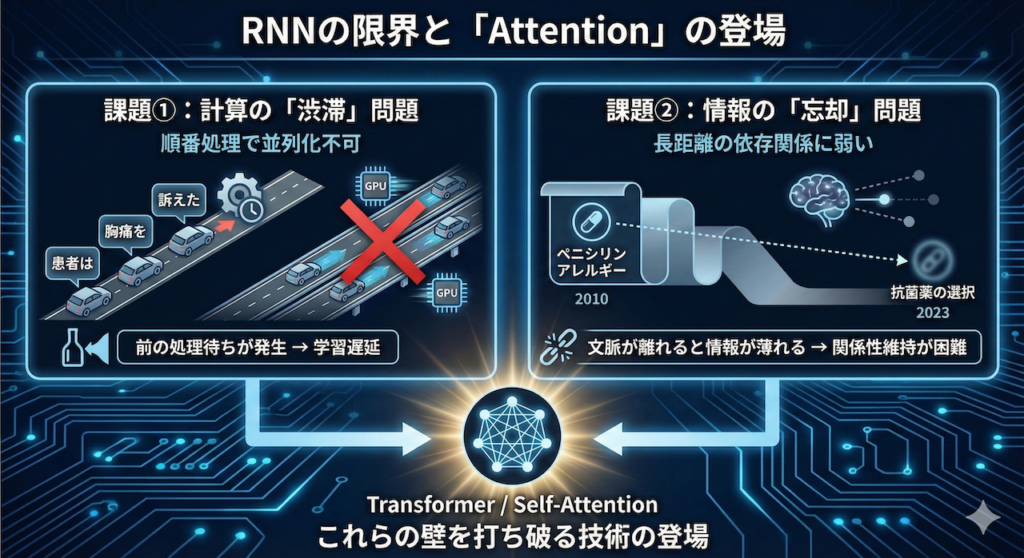
なぜ、これまでのAIでは不十分だったのか?
前述のように、また前回までの講義で、私たちは時系列データを扱うRNN(Recurrent Neural Network)や、その進化系であるLSTM/GRUについて学びました。これらは確かに画期的な技術であり、機械翻訳や音声認識の分野で一時代を築きました。しかし、医療現場のような複雑かつ膨大なデータを扱う場面において、RNNには構造上避けられない「2つの大きな壁」が存在していました。
2017年、この壁を打ち破るために登場したのがTransformerであり、その中核をなすSelf-Attention(自己注意機構)です。まずは、RNNが抱えていた具体的な課題を、医療の現場感覚に照らし合わせて理解していきましょう。
課題①:計算の「渋滞」問題(並列化ができない)
RNNの最大の特徴は、データを「先頭から順番に」処理することです。
例えば、「患者は、胸痛を、訴えた」という文を処理する場合、RNNは以下のように動きます。
- 「患者は」を処理する
- その結果(隠れ状態)を持って、「胸痛を」を処理する
- その結果を持って、「訴えた」を処理する
前の単語の計算が終わらないと、次の単語の計算に入れません。これは、どんなに高性能なGPU(並列処理が得意な計算機)を用意しても、前の処理が終わるのを「待つ時間」が発生することを意味します。
医療データ、例えば数万人の患者の数年分の経過記録を学習させようとした場合、この「順番待ち」は致命的な学習時間の遅延を招いていました(Vaswani et al. 2017)。
課題②:情報の「忘却」問題(長距離の依存関係に弱い)
もう一つの問題は、文章が長くなればなるほど、最初のほうにあった情報を忘れてしまうことです。
LSTMはこの問題を緩和するために「記憶セル」を導入しましたが、それでも限界はありました。
例えば、以下のような長い経過記録を想像してください。
「2010年、ペニシリンに対するアナフィラキシーショックの既往あり。(中略:数年分の風邪や生活習慣病の記録)……2023年、細菌性肺炎に対し、抗菌薬の選択を行う。」
RNNでこれを処理すると、2023年の「抗菌薬の選択」という単語にたどり着いた頃には、はるか昔(文頭)にあった「ペニシリンアレルギー」という極めて重要な情報の重みが薄れてしまっている可能性があります。文脈が離れれば離れるほど、その関係性(依存関係)を維持するのが難しくなるのです(Vaswani et al. 2017)。
Self-Attention:AIの視点を「順次」から「全景」へ
そこで登場した解決策が、Self-Attention(自己注意機構)です。
これは、データを端から順番に追うのではなく、「入力されたデータ全体を一度に見渡し、必要な情報同士を直接結びつける」というアプローチです。
この違いを、医療現場の業務スタイルに例えると、驚くほど直感的に理解できます。
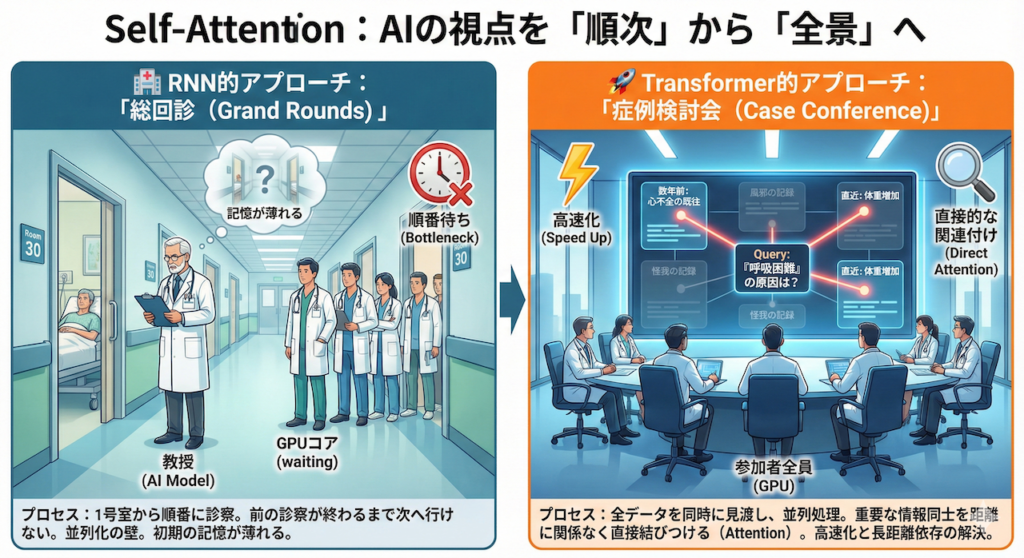
🏥 RNN的アプローチ:「総回診(Grand Rounds)」
RNNの処理は、古き良き「教授総回診」に似ています。
- プロセス: 教授(AIモデル)は、病棟の廊下を歩き、1号室の患者さんから順番に診察していきます。
- 並列化の壁: 1号室の診察が終わらないと、2号室には行けません。複数の医師(GPUコア)がいても、教授が一人なら、結局は順番待ちが発生します。
- 記憶の壁: 30人目の患者さんを診ているとき、教授は最初に診た1人目の患者さんの細かい検査値を、鮮明に覚えているでしょうか? 人間であれば(そしてRNNであれば)、直前の記憶に引きずられ、最初の方の記憶は薄れてしまいがちです。
🚀 Transformer的アプローチ:「症例検討会(Case Conference)」
一方、Transformer(Self-Attention)の処理は、すべてのデータが揃った状態で行う「症例検討カンファレンス」です。
- プロセス: 全員の患者データ(あるいは一人の患者の全経過)が、大きなホワイトボードやスクリーンに一斉に表示されています。
- 全体俯瞰(並列処理): 順番に見る必要はありません。参加者全員(GPU)で、すべてのデータを同時に見ることができます。
- 直接的な関連付け(Attention):
「この患者さんの『呼吸困難(現在の症状)』の原因は?」という問いに対して、数年前のカルテにある『心不全の既往』や、直近の『体重増加』というデータに、距離に関係なく一瞬で視線を向け(Attend)、赤ペンで線を結ぶことができます。
間にどれだけ関係のない記述(風邪や怪我の記録など)があっても、重要度(Attention Weight)が低いと判断すれば無視し、重要な情報だけをダイレクトに関連付けるのです。
このように、「全データを同時に処理し(高速化)」、「距離に関係なく重要な要素同士を結びつける(長距離依存の解決)」。これが、Transformerが従来のAIを凌駕した理由であり、現在のLLMの驚異的な能力の源泉となっているのです。
2. Self-Attention:AIは「どこ」を見ているのか?
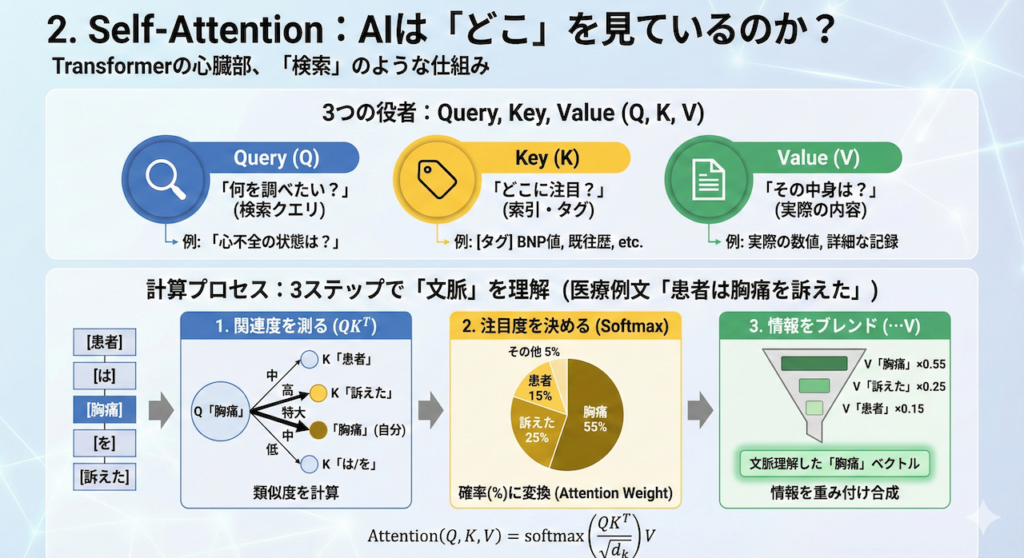
Transformerの心臓部、「Attention」の正体
前述の通り、Transformerの画期的な点は、データを順番に見るのではなく、「関連する情報を瞬時に検索して、文脈を理解する」点にあります。この機能を担うのが、Self-Attention(自己注意機構)です。
以下のSelf-Attentionの革新的な概念を表した数式は、一見すると複雑に見えますが、その本質は私たちが日常的に使っている「Google検索」や「電子カルテのキーワード検索」と全く同じ仕組みです。
3つの役者:Query, Key, Value

Self-Attentionでは、入力されたデータ(単語など)を、以下の3つの役割(ベクトル)に変換して扱います。これらを「Q, K, V」と呼びます(Vaswani et al. 2017)。
1. Query (\( Q \)): 「何を調べたいか?」(検索クエリ)
探索の「起点」となる情報です。
例:「今の患者さんの『心不全』の状態を知りたい」
2. Key (\( K \)): 「どこに注目すべきか?」(索引・タグ)
データの「見出し」に相当します。Queryとの関連度(マッチング)を測るために使われます。
例:カルテ内の各記述につけられたタグ(「高血圧の既往」「骨折の手術歴」「BNP値」…)
3. Value (\( V \)): 「その中身は何か?」(実際の内容)
実際に取得したい「情報の中身」です。
例:実際の検査数値や、詳細な経過記録の内容。
計算のプロセス:3ステップで理解する
論文で示されたAttentionの計算式は以下の通りです。この式が何を意味しているのか、医療現場の検索プロセスに当てはめて解読してみましょう。
\[ Attention(Q, K, V) = \text{softmax}\left(\dfrac{QK^T}{\sqrt{d_k}}\right)V \]
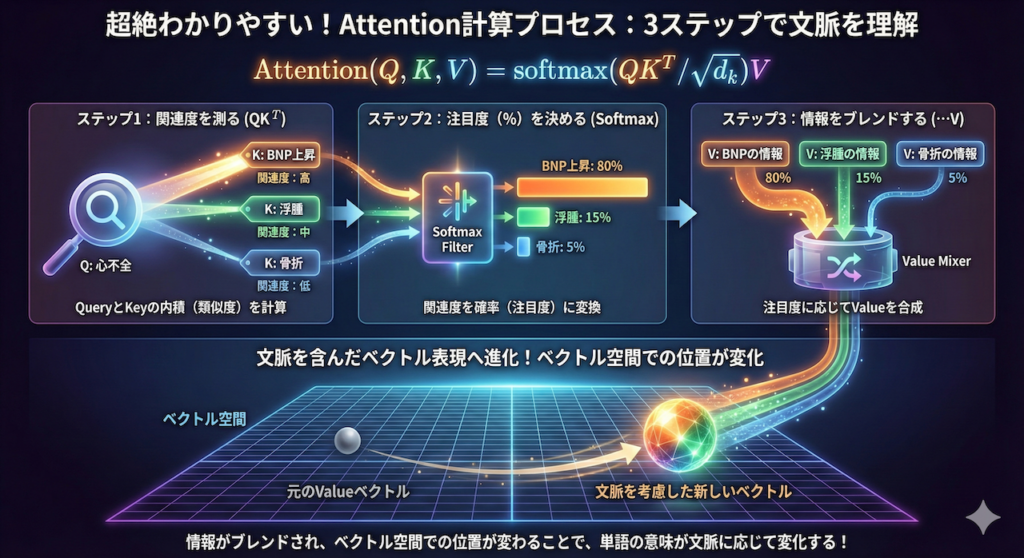
ステップ1:関連度を測る(\( QK^T \))
まず、Query(知りたいこと)とKey(見出し)の内積をとります。数学においてベクトルの内積は「類似度」を表します。
- Q「心不全」 vs K「BNP上昇」 \(\rightarrow\) 関連度:高
- Q「心不全」 vs K「右橈骨骨折」 \(\rightarrow\) 関連度:低
ステップ2:注目度(%)を決める(Softmax)
計算された関連度の数値を、合計が100%(1.0)になるように確率へ変換します。これをAttention Weight(注目度)と呼びます。
- 「BNP上昇」への注目度:80%
- 「浮腫」への注目度:15%
- 「骨折」への注目度:5%
ステップ3:情報をブレンドする(\( \dots V \))
最後に、このパーセンテージに従って、Value(情報の中身)を混ぜ合わせます。
「心不全」という言葉の意味を理解するために、「BNPの情報(80%分)」と「浮腫の情報(15%分)」を濃く取り込み、「骨折の情報(5%分)」は薄く取り込む。こうして作られた新しいベクトルが、「文脈を考慮した、その単語の新しい表現」となります。
【図解】「胸痛」という言葉をAIはどう理解するか
以下の図は、AIが「患者は胸痛を訴えた」という文の中で、「胸痛」という単語を処理する際の流れを可視化したものです。
この計算を、文章中のすべての単語に対して同時並列に行います(「患者」のQ、「訴えた」のQ…と全て同時に計算する)。これが行列演算としてGPU上で高速に処理できる理由であり、Transformerが圧倒的な性能と速度を両立できた秘訣なのです(Vaswani et al. 2017)。
3. Multi-Head Attention:複数の「専門家」の視点
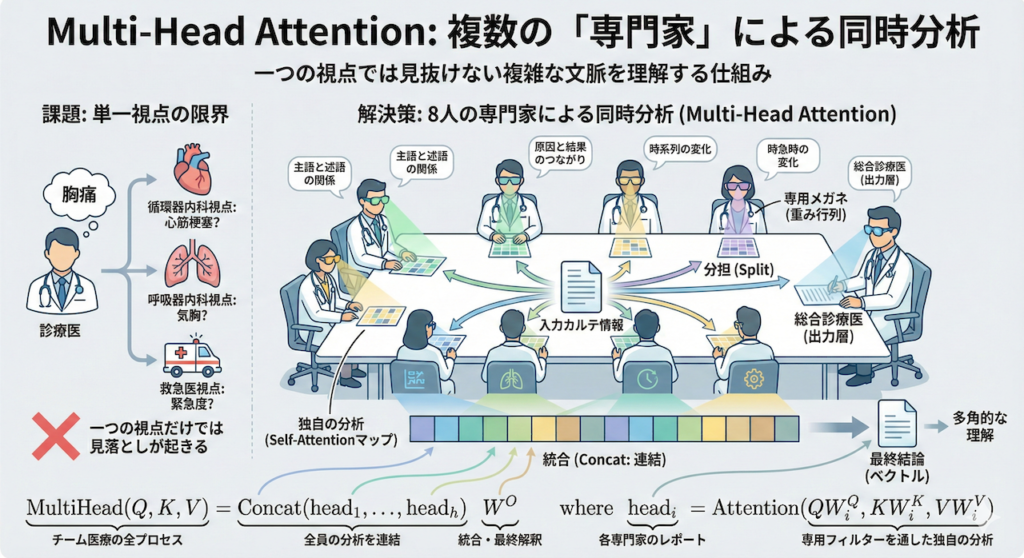
1つの視点だけでは、複雑な「文脈」は見抜けない
Self-Attentionを使えば、単語間の関連性を見抜けることは分かりました。しかし、言葉の意味というのは非常に多面的です。たった一つの「注目パターン」だけで、複雑な医療テキストの全てを理解することは可能でしょうか?
ここで、「胸痛」という一つの症状を例に考えてみましょう。この言葉を聞いたとき、医師が注目するポイントは診療科や役割によって全く異なります。
- 循環器内科医の視点: 「冷や汗はあるか? 放散痛は?」(心筋梗塞の兆候を探す)
- 呼吸器内科医の視点: 「呼吸苦はあるか? SpO2は?」(気胸や肺塞栓の兆候を探す)
- 救急医の視点: 「血圧は? 意識レベルは?」(緊急度・重症度を判断する)
もし、AIが「たった一つの視点(Attention)」しか持っていなかったらどうなるでしょうか? 「心臓のことは詳しく見たけれど、肺の兆候を見落とした」ということが起こりかねません。
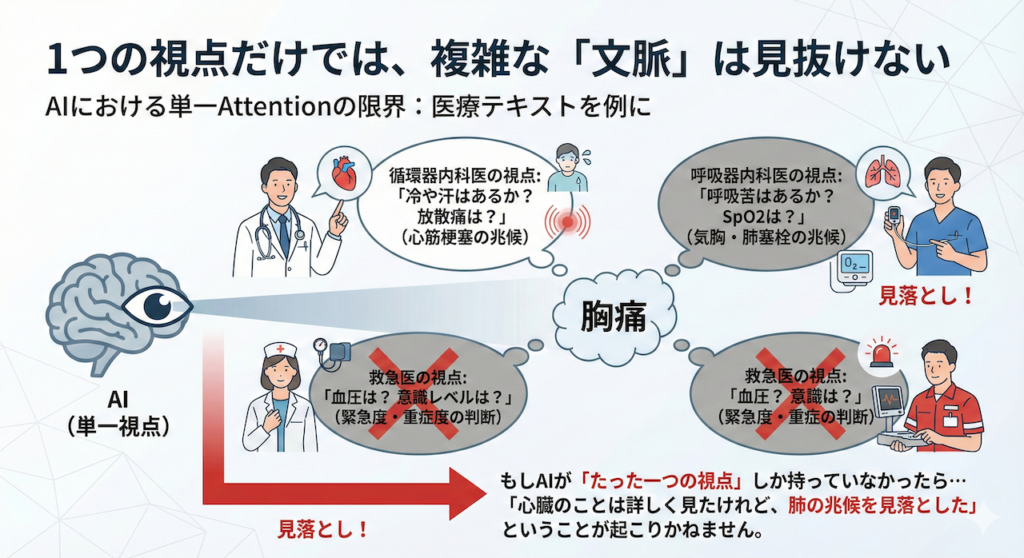
仕組み:8人の専門家による同時分析
そこでTransformerは、Multi-Head Attention(多頭注意機構)という仕組みを採用しました。
これは、文字通りAttentionを行う「頭(Head)」を複数個(論文では8個)用意し、「それぞれ異なる視点」で同時に分析させるアプローチです(Vaswani et al. 2017)。
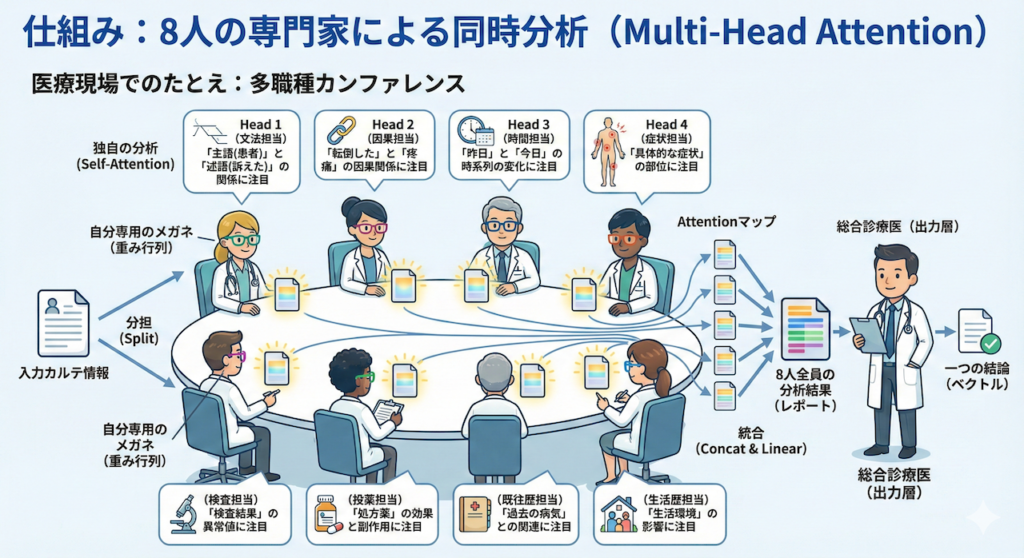
医療現場でのたとえ:多職種カンファレンス
この仕組みは、病院で行われる「多職種カンファレンス」そのものです。
- 分担(Split):
入力されたカルテ情報を、8人の異なる専門家(Head 1〜8)に渡します。 - 独自の分析(Self-Attention):
- Head 1(文法担当): 「主語(患者)」と「述語(訴えた)」の関係に注目する。
- Head 2(因果担当): 「転倒した」と「疼痛」の因果関係に注目する。
- Head 3(時間担当): 「昨日」と「今日」の時系列の変化に注目する。
- …といった具合に、それぞれのHeadが「自分専用のメガネ(重み行列)」を通して、独自のAttentionマップを作ります。
- 統合(Concat & Linear):
最後に、8人全員の分析結果(レポート)を机の上に並べて結合し、総合診療医(出力層)がそれをまとめて一つの結論(ベクトル)を出します。
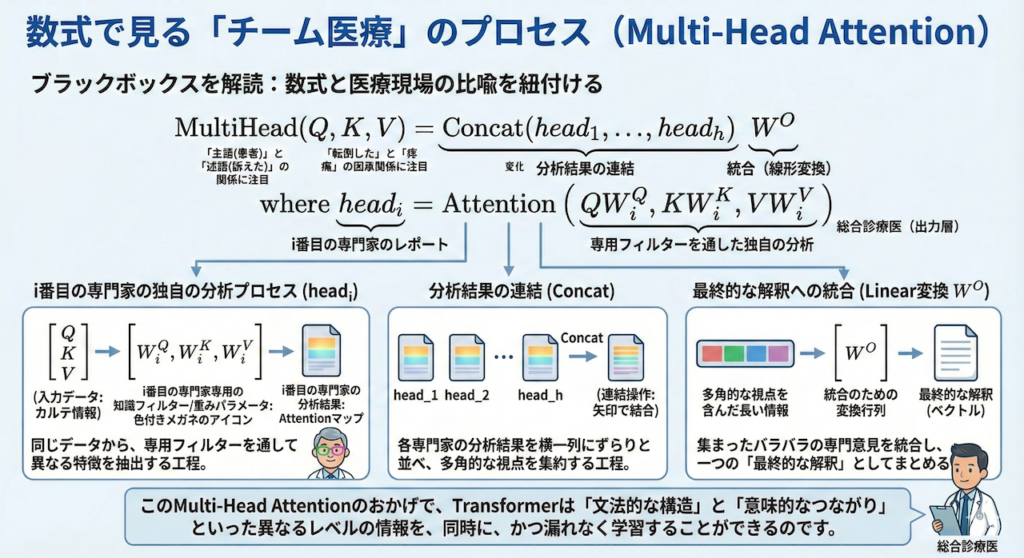
数式で見る「チーム医療」のプロセス
論文に記載されている数式は、このチームプレーを数学的に記述したものです。ブラックボックスにせず、一行ずつその意味を解読しましょう。
\[ \begin{aligned} \text{MultiHead}(Q, K, V) &= \text{Concat}(head_1, \dots, head_h)W^O \\ \text{where } head_i &= \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \end{aligned} \]
- \( head_i = \text{Attention}(\dots) \):
これは「i番目の専門家」の分析プロセスです。\( W_i^Q, W_i^K, W_i^V \) は、その専門家専用の「知識のフィルター(重みパラメータ)」です。これを通して見ることで、同じデータから異なる特徴を抽出します。 - \( \text{Concat}(head_1, \dots, head_h) \):
「Concat(Concatenate)」は「連結する」という意味です。各専門家が出した分析結果を、横一列にずらりと並べます。これで、多角的な視点を含んだ長い情報ができます。 - \( \dots W^O \):
最後に、並べられた情報を \( W^O \) という行列で線形変換(ミックス)します。これは、集まったバラバラの専門意見を統合し、「最終的な解釈」としてまとめる工程に相当します。
このMulti-Head Attentionのおかげで、Transformerは「文法的な構造」と「意味的なつながり」といった異なるレベルの情報を、同時に、かつ漏れなく学習することができるのです。
4. Positional Encoding:言葉の「順番」を教える
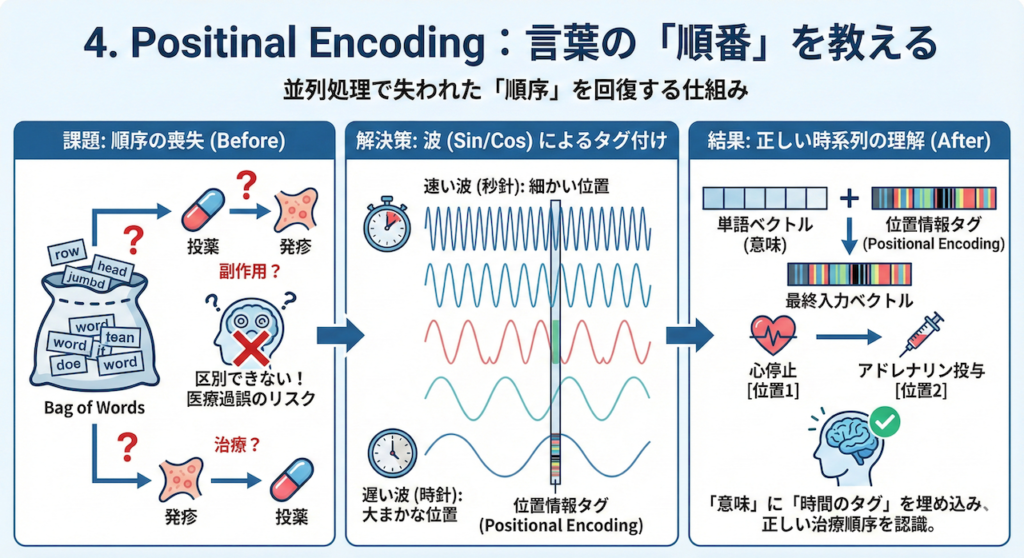
並列処理の代償:「順序」の喪失
Transformerは、文章を一気に並列処理することで劇的な高速化を実現しました。しかし、そこには大きな副作用がありました。それは、「言葉の順番」という概念が失われてしまうことです。
RNNのように「前から後ろへ」読んでいれば、自然と順序は保たれます。しかし、全単語を同時に「袋の中に放り込んで」処理するTransformer(Self-Attention)のままでは、以下の2つの文を区別することができません。
- 「犬が、人を、噛んだ」
- 「人が、犬を、噛んだ」
使われている単語セット(Bag of Words)は全く同じだからです。医療現場で言えば、「投薬したから、発疹が出た(副作用)」のか、「発疹が出たから、投薬した(治療)」のか、順序が逆転すれば医療過誤につながる重大な問題です。
解決策:位置情報の「タグ付け」
そこで考案されたのが、Positional Encoding(位置エンコーディング)です。
これは、各単語の意味を表すベクトルに、「これは何番目の単語ですよ」という情報を表すベクトルを足し合わせるという工夫です。
なぜ単純な「番号(1, 2, 3…)」ではダメなのか?
最も単純な方法は、1番目の単語に「1」、2番目に「2」を足すことですが、これには問題があります。
- 文章が長くなると数値が大きくなりすぎて、計算が不安定になる。
- 学習時に見たことがない長さの文章に対応できない。
そこで論文(Vaswani et al. 2017)では、「波(サイン波・コサイン波)」を使うというエレガントな方法が提案されました。
数式:波の組み合わせで「位置」を表現する
\[ \begin{aligned} PE_{(pos, 2i)} &= \sin(pos / 10000^{2i/d_{\text{model}}}) \\ PE_{(pos, 2i+1)} &= \cos(pos / 10000^{2i/d_{\text{model}}}) \end{aligned} \]
一見複雑に見えますが、これは「複数の異なる周期の時計の針」をイメージすると分かりやすくなります。
- \( pos \): 文の中での位置(何番目の単語か)
- \( i \): ベクトルの次元(要素のインデックス)
この式は、ベクトルの深い次元(\( i \)が大きい)ほど波の周期がゆっくりになることを意味しています。
- 秒針(速い波): 細かい位置の違いを表す。
- 分針・時針(遅い波): 大まかな位置関係を表す。
これらを組み合わせることで、AIは「AはBのすぐ隣にある」「CはDよりずっと後ろにある」といった相対的な位置関係を、文章の長さに関わらず柔軟に学習することができるのです。
医療テキストにおける意義
医療記録において、時系列(順序)は命です。
「心停止 \(\rightarrow\) アドレナリン投与」
この順序をAIが正しく認識できるのは、Positional Encodingが「単語の意味」に「時間のタグ」を埋め込んでくれているおかげなのです。
5. Transformerの応用:BERTとVision Transformer (ViT)
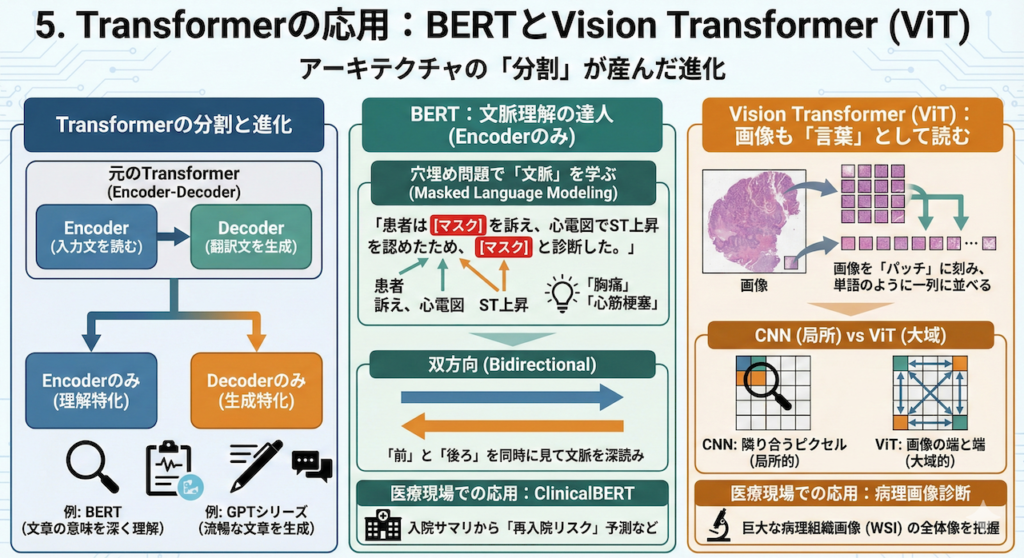
アーキテクチャの「分割」が産んだ進化
Transformerは元々、「翻訳」のために作られたモデルでした。そのため、元の論文では「入力文を読む部分(Encoder)」と「翻訳文を生成する部分(Decoder)」の2つがセットになっていました。
しかし、その後の研究で「片方だけでもものすごい能力があるのではないか?」という発見がなされ、現在は目的に応じてモデルを使い分けるのが主流になっています。
- Encoderのみ(理解特化): 文章の意味を深く理解する(例:BERT)
- Decoderのみ(生成特化): 流暢な文章を生成する(例:GPTシリーズ)
- Encoder-Decoder(変換特化): 翻訳や要約を行う(例:T5, BART)
ここでは、医療AIにおいて特に重要な「理解の達人」であるBERTと、画像診断の常識を覆したViTについて解説します。
BERT:文脈理解の達人 (Encoderのみ)
BERT (Bidirectional Encoder Representations from Transformers) は、2018年にGoogleが発表したモデルです。TransformerのEncoder部分だけを何層にも(12層〜24層)積み重ねた構造をしています(Devlin et al. 2019)。
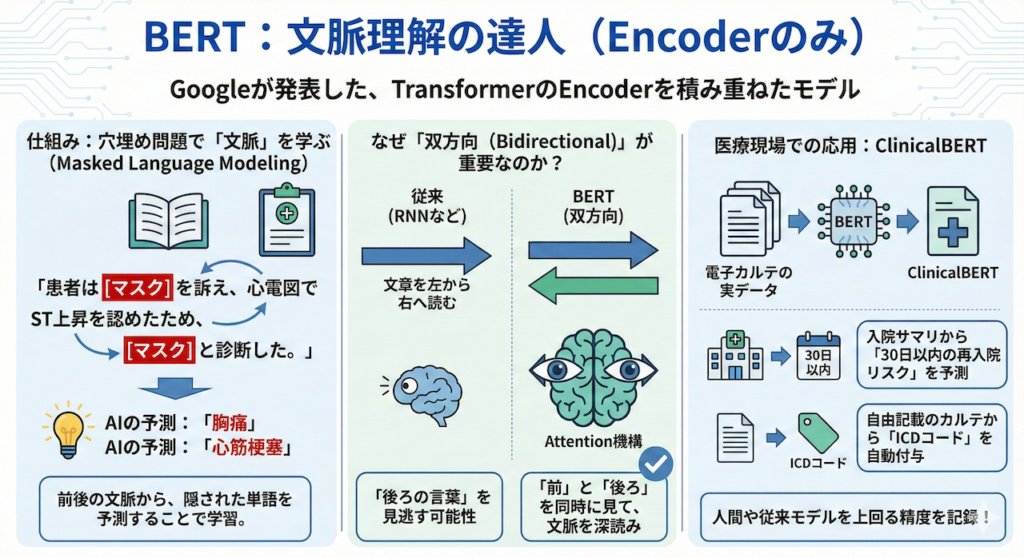
仕組み:穴埋め問題で「文脈」を学ぶ
BERTの学習方法は、非常にユニークです。AIに大量の医学書やカルテを読ませる際、わざと単語の一部を隠します(Mask)。
「患者は [マスク] を訴え、心電図でST上昇を認めたため、[マスク] と診断した。」
AIは、前後の文脈(「訴え」「心電図」「ST上昇」)から、隠された単語が「胸痛」や「心筋梗塞」であることを予測します。これを「マスク化言語モデリング(Masked Language Modeling)」と呼びます。
なぜ「双方向(Bidirectional)」が重要なのか?
従来のモデル(RNNなど)は、文章を左から右へ読んでいました。しかし、言葉の意味は「後ろの言葉」によって決まることもあります。
BERTは、Attention機構を使って文章の「前」と「後ろ」を同時に見る(双方向)ことができるため、「文脈の深読み」においては右に出るものがいません。
医療現場での応用:ClinicalBERT
この強力な読解力を活かし、電子カルテの実データで追加学習(事前学習)させたClinicalBERTなどが開発されています。
- タスク: 入院サマリから「30日以内の再入院リスク」を予測する、自由記載のカルテから「ICDコード」を自動付与する、といったタスクで人間や従来のモデルを上回る精度を記録しています。
Vision Transformer (ViT):画像も「言葉」として読む
「画像認識といえばCNN(畳み込みニューラルネットワーク)」というのが、AI業界の長年の常識でした。しかし2020年、その常識が覆されました。Transformerが画像の世界でも最高性能(SOTA)を叩き出したのです。それがVision Transformer (ViT) です(Dosovitskiy et al. 2021)。
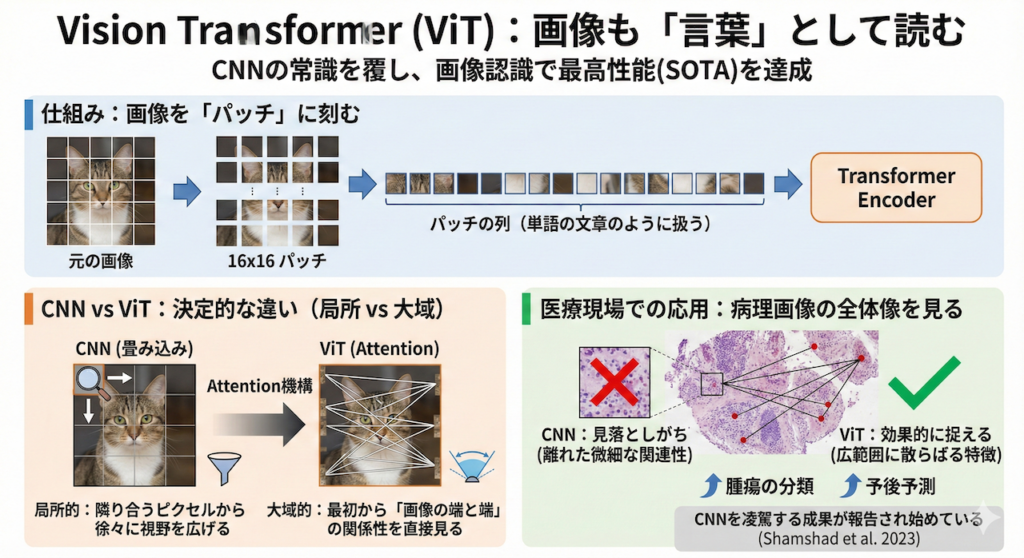
仕組み:画像を「パッチ」に刻む
Transformerは本来、「単語の列」を処理するためのものです。では、どうやって画像を読ませるのでしょうか?
ViTのアプローチは大胆です。画像を「16×16ピクセル」などの小さな正方形(パッチ)に切り刻み、それを一列に並べて、まるで「パッチという単語が並んだ文章」であるかのようにTransformerに入力するのです。
CNNとの決定的な違い:局所 vs 大域
- CNN(畳み込み): 「隣り合うピクセル」を見ることから始め、徐々に視野を広げていきます(局所的な特徴抽出が得意)。
- ViT(Attention): 最初の層から「画像の端と端」の関係性を直接見ることができます(大域的な特徴抽出が得意)。
医療現場での応用:病理画像の全体像を見る
この「離れた場所の関係性を見る」能力は、医療画像で真価を発揮します。
例えば、病理組織画像(WSI: Whole Slide Image)のような巨大な画像において、CNNでは見落としがちな「離れた組織間の微細な関連性」や「広範囲に散らばる特徴」を、ViTは効果的に捉えることができます。実際に、腫瘍の分類や予後予測において、CNNを凌駕する成果が報告され始めています(Shamshad et al. 2023)。
6. 【実習】Pythonで体験!最新AI「E5」による医療意味検索
前節まで、「ベクトル」や「Transformer」といった少し難しい理論の話をしてきました。ここからは、いよいよ実践編です。
Google Colab(グーグル・コラボ)という無料のプログラミング環境を使って、「実際に動く医療AI検索エンジン」を自分の手で作ってみましょう。
今回使用するのは、2024年〜2025年のAI開発で世界標準となっている「E5 (イーファイブ)」というモデルです。このAIは、単なる「単語の一致」ではなく、人間のように「文脈やニュアンス」を理解できるため、ChatGPTなどの裏側で動く「知識検索システム(RAG)」の心臓部として使われています。
今回は、以下の5つのステップで進めていきます。
- ステップ1:道具(ライブラリ)の準備
- ステップ2:文字化け対策と設定
- ステップ3:AIの脳(ベクトル化機能)を作る
- ステップ4:【重要】実験データの作成(AIが迷わない入力を準備)
- ステップ5:計算と結果の可視化
ステップ1:道具(ライブラリ)の準備
まずは、AIを動かすために必要な「道具」をGoogle Colabにインストールします。料理で言えば、まな板や包丁を揃える準備段階です。
【使い方】
Google Colabを開き、最初のセル(入力欄)に以下のコードを貼り付けて、実行ボタン(再生マーク)を押してください。
# --- ライブラリのインストール ---
# 以下のコマンドを実行すると、必要な道具が一括でGoogle Colabにダウンロードされます。
# transformers: 最新のAIモデル(E5など)を動かすための基本セット
# sentencepiece: 日本語のような複雑な言語を、AIが読める部品に分解するツール
# japanize-matplotlib: グラフを描くときに日本語が文字化け(豆腐化)しないようにする重要ツール
# seaborn: データを美しく、見やすいグラフにするためのツール
# torch: AIの計算(行列演算)を高速に行うための心臓部
# scikit-learn: 計算結果の「距離(類似度)」を測るための計算機
!pip install transformers sentencepiece japanize-matplotlib torch scikit-learn seaborn
ステップ2:文字化け対策と設定
道具のインストールが終わったら、プログラムを書き始めます。
まずは、グラフを描画したときに日本語が「□□□」のように文字化けしないための設定を行います。
import torch
import numpy as np
import pandas as pd
import seaborn as sns
import japanize_matplotlib # 日本語表示に対応させるライブラリ
import matplotlib.pyplot as plt
from transformers import AutoTokenizer, AutoModel
from sklearn.metrics.pairwise import cosine_similarity
# 余計な警告メッセージ(バージョン情報など)を非表示にして、結果を見やすくします
import warnings
warnings.simplefilter('ignore')
# ---------------------------------------------------------
# 【重要】文字化け(豆腐)防止設定
# ---------------------------------------------------------
# グラフを描画するツール(Seaborn)の設定です。
# 日本語フォント(IPAexGothic)をここで明示的に指定します。
# これを行わないと、Colab上で日本語が正しく表示されません。
sns.set(font="IPAexGothic")
print("設定完了:日本語フォントの準備ができました。")
ステップ3:AIの脳(ベクトル化機能)を作る
ここが最も重要なパートです。言葉(テキスト)を入力すると、その意味を数値の列(ベクトル)に変換してくれる「AIの脳」を作ります。
少しコードが長いですが、「ModernE5Embedder(モダン・イーファイブ・エンベッダー)」という名前の「変換機」を作っていると考えてください。
この変換において、AI内部では複雑な計算が行われますが、最終的には入力されたテキスト \( \mathbf{x} \) を、高次元のベクトル \( \mathbf{v} \in \mathbb{R}^{d} \) に変換します。
\[ \mathbf{v} = \text{E5Model}(\mathbf{x}) \]
# ---------------------------------------------------------
# 最新AI「E5」クラスの定義(AIの脳を作る)
# ---------------------------------------------------------
class ModernE5Embedder:
"""
最新のAIモデル(E5)を使って、テキストを「意味のベクトル」に変換するクラス(設計図)
"""
def __init__(self, model_name='intfloat/multilingual-e5-large'):
# クラスを作ったときに最初に実行される処理です
print(f"モデル '{model_name}' を読み込んでいます...(初回は数分かかります)")
# パソコンにGPU(高速計算機)があるか確認し、あれば自動で使います
# Google Colabで「T4 GPU」などを選んでいると爆速になります
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用デバイス: {self.device}")
# トークナイザ(言葉をIDにする翻訳機)とモデル(AI本体)の準備
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
# AIをGPUへ転送し、「推論モード(テストモード)」に設定します
self.model.to(self.device)
self.model.eval()
print("AIの準備が完了しました。")
def _average_pool(self, last_hidden_states, attention_mask):
"""
【専門的な処理】文章全体の意味を計算する(平均プーリング)
AIは単語ごとに数値を出しますが、ここでは文章全体の意味が知りたいので
それらの「平均値」を計算して、一つのベクトルにします。
"""
# 空白部分(パディング)を除外して計算する数式処理です
# last_hidden.masked_fill は、マスク位置の値を0にします
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
def get_embedding(self, text, is_query=False):
"""
テキストを入力すると、その意味を表す「数値の列(ベクトル)」を返す関数
"""
# E5モデルのルール:
# 質問する側には 'query: '、検索される側には 'passage: ' を先頭に付けます。
# これにより、AIが「あ、これは質問だな」「これは答えだな」と文脈を理解します。
prefix = "query: " if is_query else "passage: "
input_text = prefix + text
# テキストをAIが読めるID番号に変換します
batch_dict = self.tokenizer(
[input_text],
max_length=512, # 長すぎる文章はカット
padding=True, # 短い文章は穴埋め
truncation=True,
return_tensors='pt' # PyTorch形式に変換
)
# データをデバイス(GPU)に転送します
batch_dict = {k: v.to(self.device) for k, v in batch_dict.items()}
# 計算実行(学習はしないので no_grad で高速化します)
with torch.no_grad():
outputs = self.model(**batch_dict)
# 計算結果から、文章全体のベクトルを取り出します
embeddings = self._average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# ベクトルの長さを「1」に揃えます(正規化)
# これをすると、後で類似度を計算するときに精度が上がります
import torch.nn.functional as F
embeddings = F.normalize(embeddings, p=2, dim=1)
# 結果をPythonで扱いやすい形式にして返します
return embeddings.cpu().numpy()[0]
# ここで、実際にAIを起動(インスタンス化)します
embedder = ModernE5Embedder()
ステップ4:実験データ(患者の訴えと病名)の準備
AIの準備ができたので、検索させたい文章を定義します。
今回は、「心筋梗塞」と「それ以外の胸痛(例:神経痛など)」をAIがどう区別するかを検証します。
心筋梗塞に特有の「放散痛(肩への痛み)」や「冷や汗」「圧迫感」という具体的なキーワードを入力文に含め、AIがその緊急性と文脈を理解できるか試してみましょう。
# ---------------------------------------------------------
# 実験データの準備(ここが結果を左右します)
# ---------------------------------------------------------
# 【1. 患者さんの訴え】(検索クエリ)
# ただ「胸が痛い」だけでなく、心筋梗塞に特徴的な「締め付けられる感じ」
# 「左肩への痛み(放散痛)」「冷や汗」を入れます。
query_text = "胸の中央が締め付けられるような激しい圧迫感があり、冷や汗が出て、左肩の方まで痛む"
# 【2. 比較対象リスト】
# AIはこれらの中から「最も意味が近いもの」を選びます
candidates = [
"急性心筋梗塞の疑い(循環器内科)", # 【正解】症状・文脈が完全に一致します
"肋間神経痛による一瞬の鋭い痛み(整形外科)", # 【鑑別】「胸が痛い」点は同じですが、痛みの性質(ピリピリ・一瞬)が異なります
"転倒による足の脛骨骨折", # 【不正解】痛い場所が全く違います
"トヨタ自動車の株価が上昇した", # 【ノイズ1】経済ニュース(医療と無関係)
"Pythonのインストール方法について", # 【ノイズ2】技術文書(医療と無関係)
]
print(f"検索クエリ: {query_text}")
print(f"候補データ数: {len(candidates)}件")
ステップ5:計算と結果の可視化
いよいよ最後のステップです。AIに文章の意味を計算させ、どの候補が最も近いかをグラフで表示します。
ここで使う計算式は「コサイン類似度」と呼ばれ、2つのベクトル \(\mathbf{A}\)(質問)と \(\mathbf{B}\)(候補)の間の角度の近さを測ります。
\[ \text{Similarity} = \cos(\theta) = \dfrac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|} \]
この値が \(1.0\) に近いほど「意味が同じ」、\(0\) に近いほど「無関係」であることを示します。
# ---------------------------------------------------------
# 計算とランキング
# ---------------------------------------------------------
print("AIが意味の近さを計算中...\n")
# 1. まず、クエリ(質問)をベクトル化します
query_vec = embedder.get_embedding(query_text, is_query=True)
results = []
for cand in candidates:
# 2. 候補となる文章を一つずつベクトル化します
cand_vec = embedder.get_embedding(cand, is_query=False)
# 3. コサイン類似度を計算します(1.0に近いほど似ている)
score = cosine_similarity(
query_vec.reshape(1, -1),
cand_vec.reshape(1, -1)
)[0][0]
# 結果をリストに保存します
results.append({'Text': cand, 'Similarity': score})
# スコアが高い順に並び替えて、表(DataFrame)にします
df_results = pd.DataFrame(results).sort_values(by='Similarity', ascending=False)
# 数値で結果を表示します
print("--- 検索結果 (類似度スコア) ---")
print(df_results)
# ---------------------------------------------------------
# 結果の可視化(グラフ描画)
# ---------------------------------------------------------
def visualize_results(query, df):
# グラフのサイズ設定(横12インチ、縦6インチ)
plt.figure(figsize=(12, 6))
# 背景の設定(日本語フォントをここで確実に適用します)
sns.set(style="whitegrid", font="IPAexGothic")
# 棒グラフの描画(色は'viridis'という見やすいグラデーションを使用)
barplot = sns.barplot(data=df, x='Similarity', y='Text', palette='viridis')
# タイトルの設定
plt.title(f'患者主訴: 「{query}」 との意味的類似度 (Model: E5-Large)', fontsize=14, pad=20)
plt.xlabel('類似度スコア (1.0に近いほどAIが「関係あり」と判断)', fontsize=12)
# グラフの表示範囲設定
# 差を見やすくするために0.7から開始します
plt.xlim(0.70, 0.90)
# 各バーの上に、具体的な数値を書き込みます
for i, p in enumerate(barplot.patches):
width = p.get_width()
plt.text(
width + 0.002,
p.get_y() + p.get_height() / 2,
f'{width:.4f}',
ha='left', va='center', fontweight='bold', fontsize=11
)
# レイアウトを整えて表示します
plt.tight_layout()
plt.show()
# グラフを表示します
visualize_results(query_text, df_results)
実行結果の例
上記のコードを実行すると、以下のような結果が得られます(数値は環境により微差が生じます)。
AIが意味の近さを計算中...
--- 検索結果 (類似度スコア) ---
Text Similarity
0 急性心筋梗塞の疑い(循環器内科) 0.859143
1 肋間神経痛による一瞬の鋭い痛み(整形外科) 0.847077
2 転倒による足の脛骨骨折 0.822007
4 Pythonのインストール方法について 0.797849
3 トヨタ自動車の株価が上昇した 0.782165
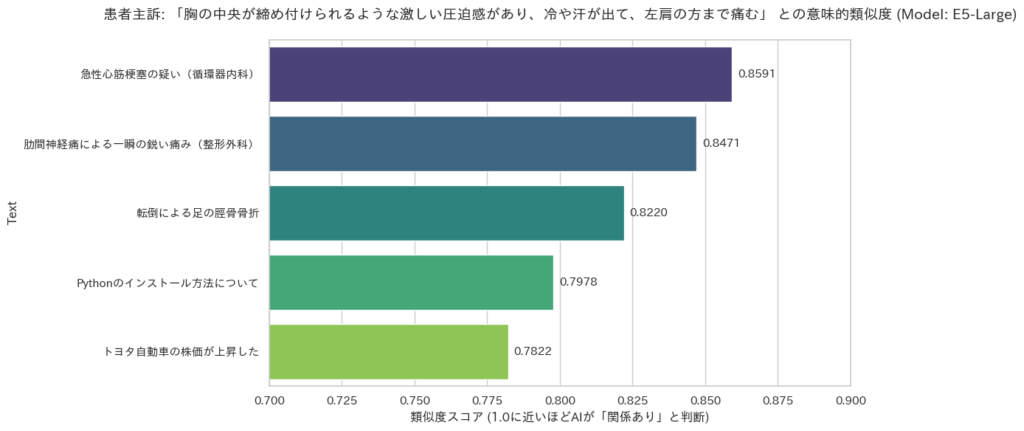
解説:結果の見方とAIの思考
今回の実行結果を見ると、1位と2位のスコアが非常に接近していることがわかります。これはAIの特性を知る上で非常に重要なデータです。それぞれの数値が何を意味しているのか、詳しく見ていきましょう。
1. 「心筋梗塞」が1位(約0.86)になった理由
「締め付けられる圧迫感」「冷や汗」「放散痛」という具体的なキーワードが、急性心筋梗塞の文脈と最も強く合致したため、AIはこれをトップに選びました。わずかな差であっても、緊急性の高い疾患を1位にランク付けできたことは、リスク回避の観点から非常に重要です。
2. 「肋間神経痛」との大接戦(約0.85)の背景
今回、肋間神経痛のスコアが1位に肉薄しました(その差わずか0.01程度)。これは、AIが「胸の痛み」や「鋭い痛み」という共通の概念(痛みのセマンティクス)に強く反応したためです。
人間であれば「冷や汗=心臓」と即座に切り分けられますが、汎用的な言語モデルにとって「痛みの種類」の重み付けは繊細なタスクです。この結果は、「AIは万能ではなく、紛らわしい症例では迷うこともある」という実情を示しており、最終判断に医師の知見が必要不可欠であることを裏付けています。
3. スコアの「インフレ」と相対評価の重要性
今回、無関係な「Python」や「株価」の話題でも、スコアが0.78〜0.80と非常に高く出ました。これはE5などの高性能モデルでよく見られる現象で、「すべての日本語テキストはある程度似ている(同じ言語空間にある)」と判定されるためです。
そのため、AI検索システムを作る際は、「スコアが0.8以上なら合格」といった絶対的な基準ではなく、「他の候補と比べてどれだけ高いか」という相対的な順位(ランキング)を重視する必要があることが、この実習からわかります。
このように、実際のデータを見ることで、AIの「強み(文脈理解)」と「癖(スコアの高止まり)」の両方を実感いただけたはずです。
7. まとめ:なぜ医療者がTransformerを学ぶべきか
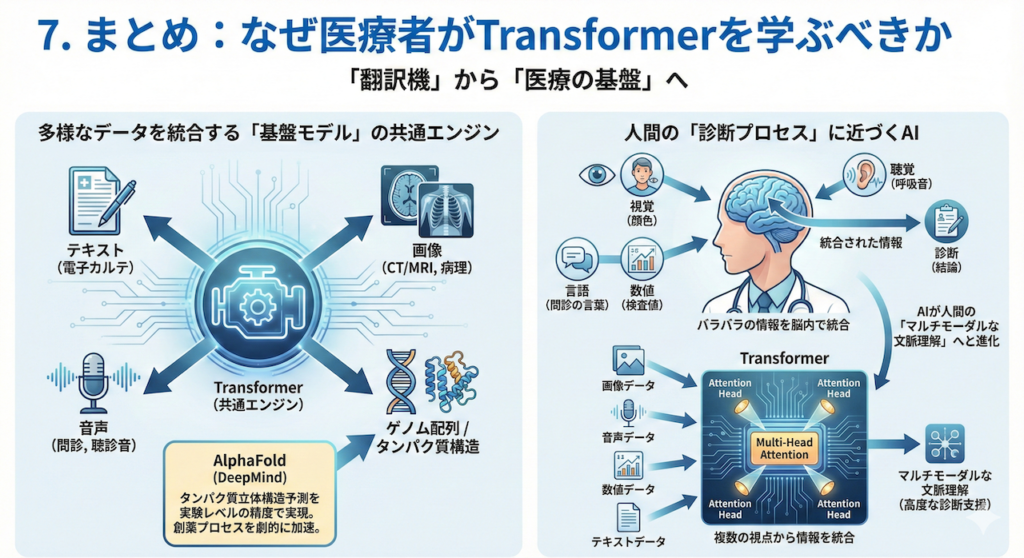
「翻訳機」から「医療の基盤」へ
Transformerは、もはや単なる「自動翻訳のための技術」ではありません。テキスト(電子カルテ)、画像(CT/MRI)、音声(問診)、さらにはゲノム配列やタンパク質構造に至るまで、あらゆるモダリティ(データの種類)を統一的に処理できる「基盤モデル(Foundation Model)」の共通エンジンとなっています。
その最も象徴的な例が、DeepMind社のAlphaFoldです。Transformerの技術を応用することで、長年の難問であったタンパク質の立体構造予測を、実験レベルの精度で解くことに成功しました(Jumper et al. 2021)。これは、創薬プロセスを劇的に加速させる可能性を秘めています。
人間の「診断プロセス」に近づくAI
私たちが普段、診療で行っているプロセスを思い出してください。
患者さんの顔色(視覚)、呼吸音(聴覚)、検査値(数値)、そして問診の言葉(言語)。これらバラバラの情報を脳内で統合し、「診断」という一つの結論を導き出しています。
Transformerが持つMulti-Head Attentionは、まさにこのプロセスを模倣する力を持っています。「画像のこの影」と「カルテのこの主訴」を関連付け、複数の視点から情報を統合する。これは、AIが従来の「パターン認識」を超えて、人間に近い「マルチモーダルな文脈理解」へと進化しつつあることを意味します(Moor et al. 2023)。
次回の予告:そのAIは「本当に」使えるのか?
さて、強力なモデルを手に入れたとしても、その性能を正しく測れなければ臨床応用はできません。
次回は、いよいよ「モデルの評価指標」について学びます。
「このAIの精度は99%です!」という売り文句に騙されないために。不均衡な医療データにおいて真に重要な指標であるF1スコアやAUC(ROC曲線)といった必須知識を、数式アレルギーの方にもわかるように解説します。
参考文献
- Devlin, J., Chang, M.-W., Lee, K. and Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4171–4186.
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J. and Houlsby, N. (2021). An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations.
- Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., Tunyasuvunakool, K., Bates, R., Žídek, A., Potapenko, A., Bridgland, A., Meyer, C., Kohl, S., Ballard, A. J., Cowie, A., Romera-Paredes, B., Nikolov, S., Jain, R., Adler, J., Back, T., Petersen, S., Reiman, D., Clancy, E., Zielinski, M., Steinegger, M., Pacholska, M., Berghammer, T., Bodenstein, S., Silver, D., Vinyals, O., Senior, A. W., Kavukcuoglu, K., Kohli, P. and Hassabis, D. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596, pp. 583–589.
- Moor, M., Banerjee, O., Abad, Z. S. H., Krumholz, H. M., Leskovec, J., Topol, E. J. and Rajpurkar, P. (2023). Foundation models for generalist medical artificial intelligence. Nature, 616, pp. 259–265.
- Shamshad, F., Khan, S., Zamir, S. W., Khan, M. H., Hayat, M., Khan, F. S. and Fu, H. (2023). Transformers in medical imaging: A survey. Medical Image Analysis, 88, 102802.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł. and Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30.
- Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M. and Brew, J. (2020). Transformers: State-of-the-Art Natural Language Processing. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




