
「正規化の基準値は、学習データ『のみ』から算出しましたか?」
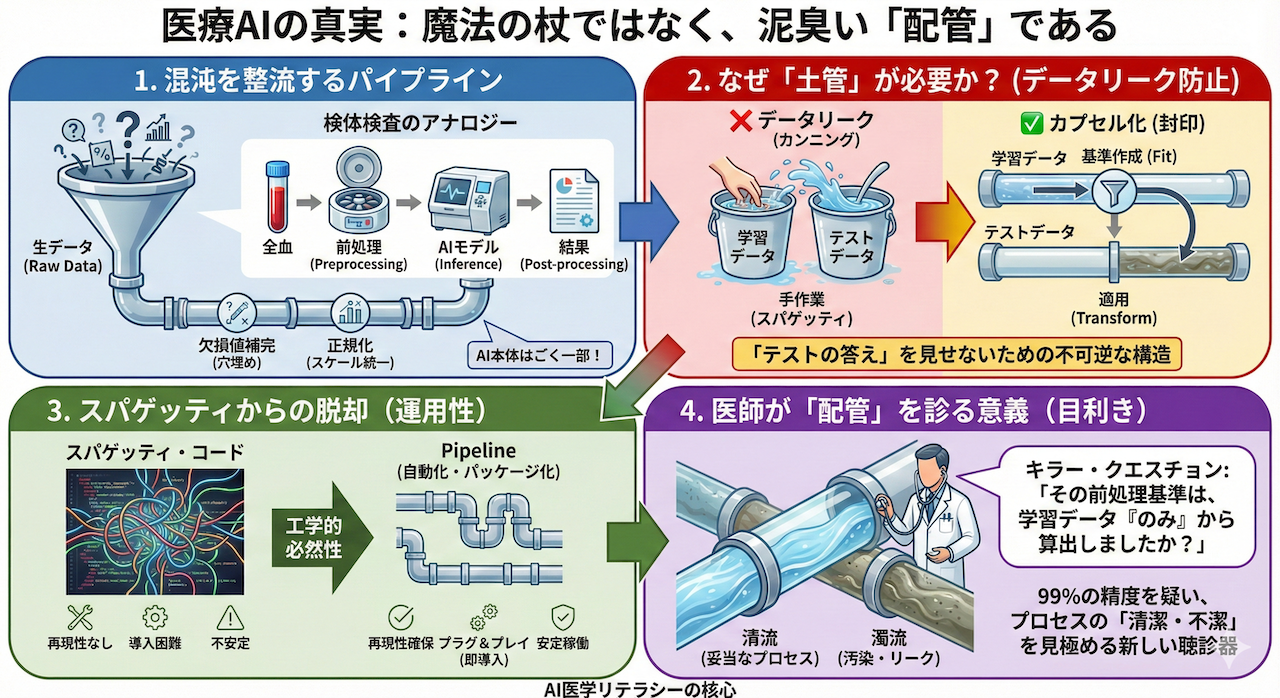
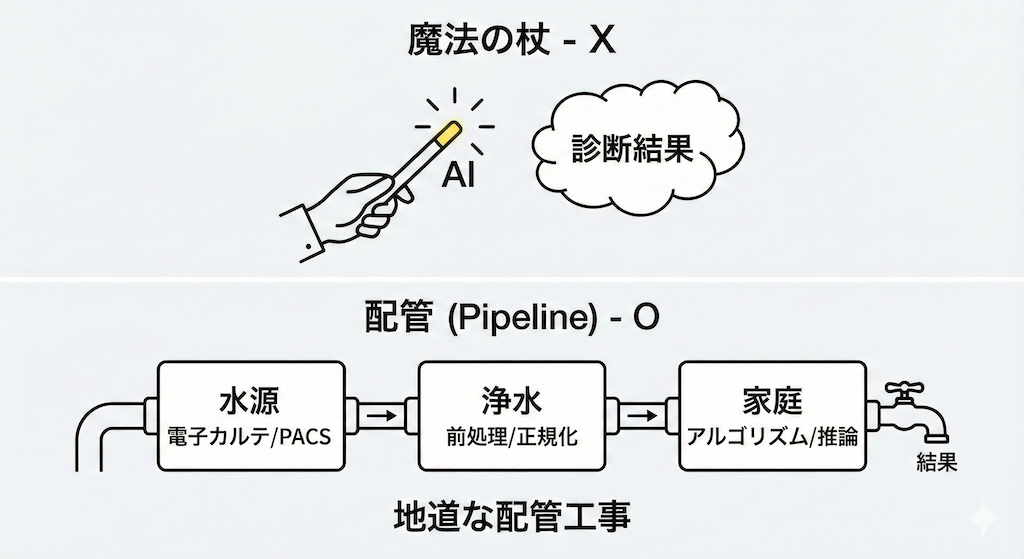
「AIは魔法の杖だ」──もしあなたがそう感じているとしたら、まずはその杖を地面に置いて、足元の「配管(パイプライン)」に目を向けてみませんか?
私たちは普段、蛇口をひねれば清潔な水が出ると信じています。しかし、その裏側には、水源の確保、浄水場での化学処理、送水ポンプによる加圧、そして各家庭まで繋がる複雑なパイプラインの建設と維持管理という、膨大で泥臭いインフラ技術が存在します。
医療AIもこの構造と全く同じです。魔法のように高精度な診断結果や予測が湧き出てくるわけではありません。電子カルテやPACS(医療画像保管伝送システム)という水源から、データという「水」を汲み上げ、ノイズや欠損という不純物を取り除き(前処理)、計算可能な形に整えて(正規化)、適切なアルゴリズムに流し込む(推論)。AI開発とは、実は極めて地道で工学的な「配管工事(Pipeline Construction)」そのものなのです。
今回は、AIを「ブラックボックス」から「透明なシステム」へと解像度を上げ、なぜ私たち医療従事者がその仕組み(パイプライン)を理解しなければならないのか、その本質に迫ります。
1. 混沌としたデータを「整流」する:パイプラインの解剖学
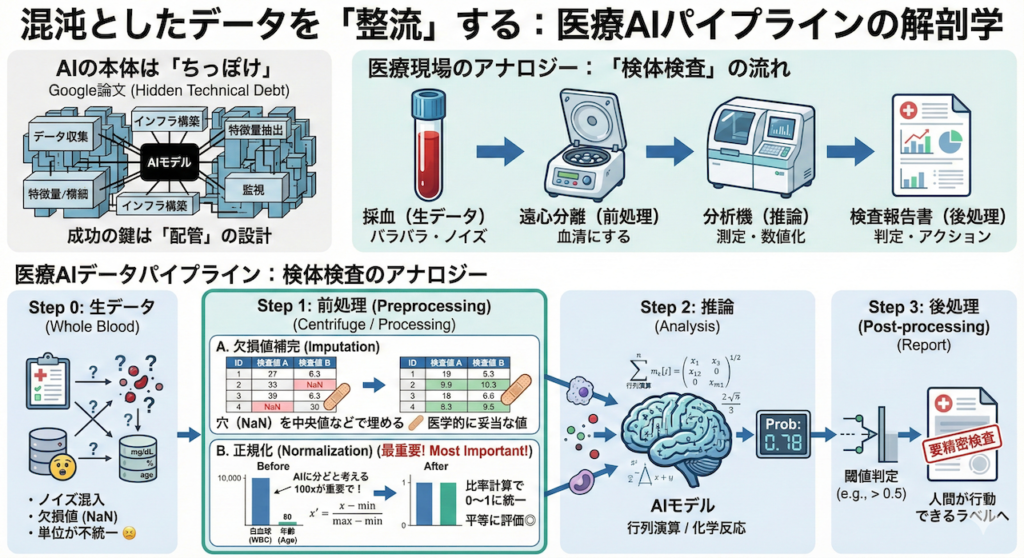
AIの本体は「ちっぽけ」である
AI開発において、私たちが「AI」と呼んでいる学習モデル(アルゴリズム)そのものが占める割合は、システム全体から見ればごくわずかであることをご存知でしょうか。
Googleの研究チームが発表した衝撃的な論文『Hidden Technical Debt in Machine Learning Systems(機械学習システムにおける隠された技術的負債)』では、実際の運用システムにおいて、モデルのコード自体は全体のほんの一部(図の中の小さな黒い箱)に過ぎず、周辺のデータ収集やインフラ構築が大半を占めると指摘されています(Sculley et al., 2015)。
つまり、AI開発の成否は、真ん中の「頭脳」の良し悪しよりも、その手前にある「配管」の設計にかかっているのです。
医療現場のアナロジー:「検体検査」の流れ
では、医療データがAIによって処理される一連の流れ──パイプライン──を見ていきましょう。これは、病院における「検体検査」のプロセスに例えると、驚くほどクリアに理解できます。
採血した血液(全血)をそのまま生化学分析機に流し込む検査技師はいません。そんなことをすれば、機械は詰まり、正しい数値は出ません。AIも全く同じです。
Step 1:前処理(検体処理)
電子カルテや検査システムから抽出された「生データ(Raw Data)」は、いわば採血直後の血液です。ノイズが混じり、形式もバラバラです。これを「分析できる状態(血清)」にするのが前処理です。
- 欠損値の補完(Imputation):
カルテには「未測定」の空欄がつきものです。しかし、計算機は「空欄(NaN)」を扱えません(計算エラーになります)。そこで、医学的に妥当な値(正常値の中央値や、前回の測定値など)で穴埋めを行います。これは「道路の穴を埋めてから車を走らせる」ような必須作業です。 - 正規化(Normalization):
ここが最重要ポイントです。AIは数字の「桁(スケール)」に極端に影響されます。
例えば、「年齢:80歳」と「白血球数:10,000 /μL」というデータがあったとします。人間なら単位が違うと分かりますが、AIは単純な数字として見るため、「10,000は80の100倍以上重要だ!」と勘違いしてしまうのです。
これを防ぐため、全てのデータを「0から1の間」などの統一された規格に押し込めます。これをMin-Max正規化と呼びます。
数式で書くと難しく見えますが、やっていることは単純な「比率計算」です。
\[ x’ = \dfrac{x – \min(x)}{\max(x) – \min(x)} \]
(ここで \(x\) は元の値、\(\min(x)\) と \(\max(x)\) はその項目の最小・最大値です)
この処理を経ることで、年齢も白血球数も平等な「特徴量」として扱われるようになります(Han et al., 2011)。
Step 2:推論(分析・測定)
ここでようやく、皆さんがイメージする「AI(モデル)」が登場します。
前処理できれいに整えられたデータ(血清)が入力され、行列演算という名の化学反応が行われます。これは検査室で言えば、調整済みの分析機が吸光度を測定し、数値を弾き出す工程にあたります。
Step 3:後処理(レポート作成)
AIが出力するのは、多くの場合「0.78」や「0.03」といった無機質な確率(Probability)の数値です。
臨床現場で「この患者の悪性確率は0.78です」と言われても、判断に困りますよね?
そこで、「閾値を0.5に設定し、それ以上なら『要精密検査』と表示する」といったルールを適用し、人間がアクション可能なラベル(判定)やリスクスコアに変換します。これが後処理(Post-processing)であり、検査結果レポートを作成する作業に相当します。
2. なぜ「土管(パイプ)」で繋ぐ必要があるのか?
「バケツリレー」ではなく「水道管」を作れ
「前処理」と「学習」が別々の作業なら、それぞれ手作業で順番に実行しても良いのではないか? そう思われるかもしれません。しかし、AI開発において、これらを強固なパイプラインとして連結することには、工学的な利便性を超えた「科学的な必然性」があります。
最大の理由は、AI開発における最大のタブー、「データリーク(Data Leakage)」の完全防止です。
データリーク:AIによる「カンニング」
データリークとは、一言で言えば「テスト本番の答えを、予習段階で見てしまうこと(カンニング)」です。
例えば、AIの性能を測るために、データを「学習用(過去問)」と「テスト用(本番)」に分割するとします。ここで、多くの初心者が陥る致命的なミスがあります。
- 間違い(手作業でやりがちなミス):
分割する前に、全データ(学習+テスト)を使って「正規化(最小値・最大値の計算)」をしてしまう。
→ この時点で、AIは「テストデータに含まれる最大値」という情報を、学習前に知ってしまいます。これは「テスト問題の範囲や傾向」を事前に知っている状態で受験するようなものです。 - 正解(パイプラインの挙動):
まずデータを分割する。
→ 「学習データだけ」を使って正規化の基準を作る。
→ その基準を、テストデータに適用する。
医療現場での致命的な「ぬか喜び」
このミスは、特に医療AI研究において頻繁に指摘される重大なバイアスの一つです(Kaufman et al., 2012)。
具体例で考えてみましょう。ある病院のMRI画像データセット全体を使って正規化を行い、素晴らしい精度のAIができたとします。しかし、このAIを別の病院に導入した途端、全く使い物にならなくなることが多々あります。
なぜなら、開発時のAIは「手元のデータ全体の分布(未来のテストデータ含む)」を知っているという「不正なアドバンテージ」を持っていたからです。未知のデータ(新規患者)に対しては、その魔法は解けてしまいます。
カプセル化による「封印」
パイプラインとして処理をパッケージ化(カプセル化)することは、この不正を防ぐための「強制ギプス」です。
プログラムコードの中で Pipeline を構築すれば、「学習データだけで基準を作り(fit)、その基準をテストデータに適用する(transform)」という厳格な手順が自動化され、人間が誤ってテストデータを覗き見る隙間がなくなります。
つまり、パイプラインとは、単なる自動化ツールではなく、科学的妥当性を担保するための「封印」なのです。
3. スパゲッティ・コードからの脱却
「研究室では動いた」が通用しない世界
現場の実装(デプロイ)という観点でも、パイプライン化は推奨ではなく「必須」です。
AI開発の初期段階では、試行錯誤の連続です。「あ、ここで欠損値を埋めるのを忘れていた」「やっぱ正規化はこのタイミングに変えよう」──こうして継ぎ接ぎだらけになったプログラムは、処理の流れが複雑に絡み合い、誰も(書いた本人でさえ)解読不能な状態になります。これをエンジニア用語で「スパゲッティ・コード」と呼びます。
研究論文を書くだけなら、スパゲッティでも構いません。しかし、患者さんの命に関わる臨床現場のシステムに、そんな不安定なコードを組み込むことは許されません。
「手作業」vs「土管(パイプライン)」
処理手順がバラバラに書かれたコードと、パイプライン化されてパッケージになったコードの違いを比較してみましょう。
| 項目 | バラバラの処理(手作業・スパゲッティ) | パイプライン化(自動化・土管) |
|---|---|---|
| 再現性 | 「あれ、どの順序で実行したっけ?」という手順ミスが起こりやすく、他者が再現困難。 | 誰がいつ実行しても、定義された通りに全く同じ処理順序が保証される。 |
| デプロイ(実装) | 複雑な手順書が必要になり、臨床現場の電子カルテシステム等に組み込むのが困難。 | ひとつの「部品(オブジェクト)」として保存・移動が可能。USBメモリを挿すような感覚で導入できる。 |
| 安全性 | 前述のデータリーク(カンニング)が無意識に発生しやすい。 | 構造的に学習データとテストデータが隔離され、リークを防ぎやすい。 |
現代のツールは「土管セット」を用意している
幸いなことに、現代の標準的なAI開発ライブラリ(scikit-learnなど)には、このパイプラインを構築するための専用機能(Pipelineクラスなど)が標準装備されています。
これを使えば、私たちは「前処理(穴埋め)」→「変換(正規化)」→「学習(推論)」という一連の工程を、あたかも一つの大きな土管セットのようにまとめて扱うことができます(Buitinck et al., 2013)。
「データを流し込めば、あとは出口から結果が出てくる」──この単純明快さこそが、医療現場での安定稼働を支える鍵となるのです。
4. 医師が「配管」を知る意義
コードは書けなくても、設計図は読めるようになれ
皆さんがご自身でPythonのコードを書き、パイプラインを実装する機会は少ないかもしれません。しかし、論文を批判的に読んだり、企業と共同研究を行ったり、あるいは病院に導入されるAI製品を選定する際、この「配管の知識」は強力な武器になります。
なぜなら、AIの品質評価とは、最終的な「正解率(Accuracy)」という数字を見ることではなく、その数字が算出されるまでの「プロセス(配管)」の妥当性を問うことだからです。
99%の精度を疑うための「キラー・クエスチョン」
例えば、ベンダーや共同研究者から「このAIの精度は99%です!完璧です!」という報告を受けたとします。
AIの仕組みを知らない人は、「すごいですね!」と感心して終わるでしょう。しかし、配管の知識がある医師は、その「魔法」のタネを見破るために、次のような鋭い質問(キラー・クエスチョン)を投げかけることができます。
「その前処理のパラメータ(正規化の最大値・最小値など)は、学習データ『のみ』から算出されていますか? それとも全データから計算しましたか? パイプラインの中で厳密に分離されていますか?」
もし相手が言葉に詰まったり、「とりあえず全データでやりました」と答えたりしたら、その99%という数字は「カンニングによる見せかけの成績(データリーク)」である可能性が極めて高いと判断できます。
「清流」か「濁流」かを見極める目
魔法のように見えるAIの結果も、蓋を開ければ泥臭いデータの流れ作業です。
その流れが、厳密なルール(パイプライン)によって守られた「清流」であるか、それとも手作業のミスやリークによって汚染された「濁流」であるか。
手術室で不潔な操作があれば指摘するように、データ処理における不潔な操作(リーク)を見抜き、指摘できること。それこそが、AI時代における医学的リテラシーの要であり、患者さんの安全を守るための「新しい聴診器」となるのです。
参考文献
- Buitinck, L. et al. (2013). API design for machine learning software: experiences from the scikit-learn project. arXiv preprint arXiv:1309.0238. https://arxiv.org/abs/1309.0238
- Han, J., Kamber, M. and Pei, J. (2011). Data Mining: Concepts and Techniques. 3rd edn. Waltham: Morgan Kaufmann.
- Kaufman, S. et al. (2012). Leakage in data mining: Formulation, detection, and avoidance. ACM Transactions on Knowledge Discovery from Data (TKDD), 6(4), art. 15. https://doi.org/10.1145/2382577.2382579
- Sculley, D. et al. (2015). Hidden technical debt in machine learning systems. Advances in Neural Information Processing Systems, 28, pp. 2503–2511. https://proceedings.neurips.cc/paper/2015/hash/86df7dcfd896fcba26e3831c829621cc-Abstract.html
- Sculley, D. et al. (2015). Hidden technical debt in machine learning systems. Advances in Neural Information Processing Systems, 28, pp. 2503–2511. https://proceedings.neurips.cc/paper/2015/hash/86df7dcfd896fcba26e3831c829621cc-Abstract.html
- Han, J., Kamber, M. and Pei, J. (2011). Data Mining: Concepts and Techniques. 3rd edn. Waltham: Morgan Kaufmann.
- Kaufman, S. et al. (2012). Leakage in data mining: Formulation, detection, and avoidance. ACM Transactions on Knowledge Discovery from Data (TKDD), 6(4), art. 15. https://doi.org/10.1145/2382577.2382579
- Buitinck, L. et al. (2013). API design for machine learning software: experiences from the scikit-learn project. arXiv preprint arXiv:1309.0238. https://arxiv.org/abs/1309.0238
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




