

現代の自然言語処理に革命をもたらした「Transformer」モデル。一つずつ単語を追う逐次的なアプローチ(LSTM)から脱却し、文章全体の単語間の関連性を一度に捉える「並列処理」を実現しました。この革新的な仕組みと医療分野への応用可能性を、3つのポイントで解説します。
文章を単語一つずつ順に読み解く「勤勉な読書家」のようなモデルでした。 [15] この逐次的な性質のため、非常に長い文章の初めの情報を最後まで記憶するのが難しく(長期依存性の問題)、GPUによる並列計算を活かせず処理に時間がかかるという弱点がありました。 [4]
文章の全単語が参加する「専門家パネル」のように、全単語の関係性を一度に並列で計算します。 [5] これにより、単語間の距離に関係なく文脈を深く理解でき、GPUの性能を最大限に引き出して高速な学習が可能になりました。 [6, 7]
膨大な医療文献やカルテデータで事前学習した賢い「基盤モデル」を、少量の専門データで個別タスク(例:診断支援)に再学習(ファインチューニング)させることで、高精度な医療AIを効率的に開発する道が拓かれました。 [8, 9, 13, 16]
1. はじめに
医療の現場は、日々、本当にたくさんの「言葉」によって動いていますよね。電子カルテに綴られる日々の記録、世界中から発信される新しい医学論文、そして何より、患者さん一人ひとりが語る切実な声。これらはすべて、より良い医療を実現するための貴重な情報源であり、いわば「情報の宝の山」です。
この講座では、この宝の山を航海するためのAIという強力な羅針盤の使い方を学んできました。以前(第15回)で扱ったLSTM (Long Short-Term Memory)は、文章を前から一つずつ丁寧に読み解く「勤勉な読書家」のようなモデルでした。単語の並び順に沿って文脈を記憶していくその姿は、系列データを扱う上で非常に強力で、自然言語処理の一時代を築いた素晴らしい技術だったと思います。
しかし、その「勤勉さ」ゆえの弱点も、私たちは少しだけ目の当たりにしました。例えば、非常に長い文章の最初に出てきた重要な情報を最後まで覚えておくことの難しさや、一つずつ順番に処理するために計算に時間がかかってしまう、といった点です。
そこでこの章では、その限界を打ち破り、現代の自然言語処理の世界に革命をもたらした、まさに「新時代の羅針盤」とも言えるTransformer(トランスフォーマー)について、その仕組みから実践までを一緒に探求していきたいと思います。
Transformerは、LSTMとは全く異なるアプローチで文章を読み解きます。例えるなら、LSTMが一人の読書家だとすれば、Transformerは専門家たちによるパネルディスカッションのようなものです。
パネルに参加した専門家(AIの各処理単位)は、文章全体を一度に見渡し、「この単語は、文中のあの単語と非常に関連が深い」「いや、こちらの単語との結びつきの方が重要だ」といった議論(計算)を、すべての単語間で同時並行で行います。この「全体を俯瞰して、単語間のあらゆる関係性を直接捉える」という驚異的な能力こそが、Transformerの核心であり、その心臓部が、これから私たちが深く学ぶことになる自己注意機構(Self-Attention)なのです。
この革新的な仕組みは、電子カルテの自動要約、膨大な医療文献からの高速な情報検索、そしてより高度な診断支援AIといった、これまで夢物語だったかもしれない応用を現実のものとし、医療分野に革命的な進歩をもたらしつつあります。
この章では、まずTransformerがなぜこれほど強力なのか、その理論的な背景をおさらいした後、PyTorchを使って実際に医療テキストを分類するモデルをゼロから実装していきます。そして最後に、この技術を医療現場で活用していく上での大きな可能性と、私たちが向き合うべき課題(光と影)についても一緒に考えていきたいと思います。さあ、準備はよろしいでしょうか?言葉の奥に潜む意味のネットワークを解き明かす、エキサイティングな旅を始めましょう!
2. Transformerとは何か?(おさらいと医療NLPにおける重要性)
さて、いよいよ本章の主役であるTransformerの核心に迫っていきましょう。本シリーズのP22.0~P22.9では、その複雑でエレガントな内部構造(自己注意機構、Multi-Head Attention、位置エンコーディング、FFNなど)を、数式も交えてじっくりと解き明かしてきました。ここでは、それらの知識を少し思い出しながら、「なぜTransformerが医療NLPでこれほどまでに画期的なのか」という視点から、その重要性を改めて確認していきたいと思います。
Transformerが登場する以前、自然言語処理の主役はRNNやLSTMでした。これらは人間の読書のように、単語を一つずつ順番に処理していく逐次処理モデルです。このアプローチはとても直感的でわかりやすいのですが、今思えば2つの大きな課題を抱えていました。
- 長期依存性の問題:
LSTMはゲートという巧妙な仕組みでこの問題を大きく改善しましたが、それでも限界はありました。例えば、非常に長い経過記録の1ページ目に書かれた「海外渡航歴あり」という情報が、20ページ目に出てくる「原因不明の発熱」を解釈する上で決定的に重要だったとします。LSTMにとって、この距離はあまりに遠く、まるで伝言ゲームのように、最初の重要な情報の影響力が最後まで届きにくい、という性質があったのです。 - 計算のボトルネック:
一つ前の単語の処理が終わらないと、次の単語の処理に進めない。この「一つずつ」という逐次的な性質は、本質的に並列計算ができないことを意味します。これは、せっかく強力な計算能力を持つGPUがあるのに、その性能を全く活かしきれない、非常にもったいない状況だったと言えるでしょう。
Transformerは、この「逐次処理」という長年の制約を、自己注意機構(Self-Attention)という、今から思えば天才的な発想で打ち破りました。2017年に発表された独創的な論文 “Attention Is All You Need” (1) で提案されたこのアイデアこそが、革命の始まりでした。
自己注意機構(Self-Attention):文脈を捉える新しい視点
自己注意機構のコンセプトは、非常にシンプルでありながらパワフルです。それは、「文中のある単語の意味は、文中の他のすべての単語との関係性によって決まる」という考え方に基づいています。
例えば、「患者は発熱と関節痛を訴えた。インフルエンザを疑い、検査を実施した。」という文を考えてみましょう。
この文脈において「検査」という単語が何を指すのか、その意味合いを深く理解するためには、それが「発熱」「関節痛」「インフルエンザ」といった単語と強く関連していることを捉える必要がありますよね。
LSTMがこの情報を順番に伝言していくのに対し、自己注意機構は、いわば全単語が参加する円卓会議を開きます。「検査」という単語は、他のすべての単語に対して、「私を理解する上で、あなたはどれくらい重要ですか?」と一斉に問い合わせ、その関連性のスコアを計算するのです。
この「関連性スコア」の計算が、文中のあらゆる単語のペアについて直接的かつ同時に行われる。これが自己注意機構の魔法です。単語間の距離はもはや関係ありません。これにより、どんなに長い文章でも、重要な文脈上のつながりを見つけ出すことができるのです。
さらに素晴らしいことに、この計算はすべての単語ペアで独立して行えるため、GPUによる大規模な並列計算が真に可能となり、学習速度が飛躍的に向上しました。
位置エンコーディング(Positional Encoding):語順という情報の付与
ここで、賢明な方はこう思うかもしれません。「すべての単語を同時に見るなら、単語の順番という大切な情報が失われてしまうのでは?」と。
その通りです。「薬は効果があった」と「効果は薬にあった」では、使われている単語は同じでも意味が全く異なります。このままでは、Transformerはただの単語の「袋」しか見ていないことになってしまいます。
この致命的な問題を解決するのが位置エンコーディング(Positional Encoding)です。これは、各単語が文の先頭から何番目に位置するか、という「住所」のような情報を、特殊なベクトルとして単語ベクトルに加算してあげる処理です。
ただ単に「1番目、2番目…」という数値を加えるのではなく、sin関数とcos関数という周期的な関数を組み合わせることで、各位置にユニークな信号を与えつつ、モデルが単語間の相対的な位置関係(例えば、「この単語の2つ隣にある」といった情報)も学習しやすくする、という非常に巧妙な工夫がなされています。私自身、この仕組みを初めて知ったときは、その数学的なエレガンスに少し感動したのを覚えています。
より深く知りたい方はこちら!
Transformerが医療NLPにもたらした革命
この「自己注意機構による深い文脈理解」と「並列計算による高速化」という2つの強力な武器は、医療NLPの研究開発の風景を一変させました。それは、学習のパラダイムシフトを引き起こしたのです。
- 膨大な事前学習:
Transformerは、PubMedに収載されている数千万件の論文や、大規模な電子カルテデータといった、人間が一生かかっても読みきれない量のテキストで事前に学習させる(事前学習)ことが可能です。これにより、医療分野の膨大な専門知識や特有の言語パターンを内在化した、非常に賢い基盤モデル(Foundation Model)が生まれます。 - 転移学習の威力:
こうして作られたBioBERT (2)やMed-BERTといった医療特化の事前学習済みモデルを、私たちが解きたい個別のタスク(例えば、特定の疾患名の抽出や、患者の感情分析など)に合わせて、比較的小さなデータセットで追加学習(ファインチューニング)させることで、驚くほど高い性能を、しかも効率的に達成できるようになったのです。
このプロセスは、医学部で6年間かけて膨大な基礎医学・臨床医学を学んだ医師が、その後、各診療科で専門的な研修を受けて専門医になる流れによく似ていると思いませんか?事前学習が一般教養と基礎医学の習得、ファインチューニングが専門研修にあたるわけです。
このように、Transformerは単なる一つのモデルというだけでなく、医療NLPの研究開発のあり方を「ゼロからのモデル構築」から「巨大な事前学習済みモデルの賢い活用」へと劇的にシフトさせた、まさにゲームチェンジャーなのです。
3. 医療自然言語処理におけるTransformerの応用例
Transformerが持つこの強力な能力は、医療現場のどのような課題を解決しうるのでしょうか。前の章で触れたLSTMの応用例も、Transformerによって、より高い精度や、より大きなスケールで実現可能になっている、と言えるかもしれません。ここでは、具体的な応用シーンをもう少し深掘りして、未来の医療がどう変わっていくのか、一緒に想像を膨らませてみましょう。
電子カルテからの高精度な情報抽出
日々の診療で、電子カルテの自由記述欄を延々とスクロールして、「あれ、あの患者さんのアレルギー情報、どこに書いたかな…」「確かご家族に心疾患の既往があったはずだけど…」と、貴重な時間を費やした経験は、きっと少なくないはずです。自由記述欄は、数値データでは捉えきれない臨床の機微が詰まった「宝の山」であると同時に、構造化されていない「情報の海」でもありますよね。
ここに、TransformerベースのAIが、まるで優秀な臨床研究コーディネーターのように介在してくれます。
膨大な自由記述の中から、診断名、症状、投薬歴、検査結果といった重要な情報を、標準化されたコード(ICD-10やSNOMED-CTなど)に紐付けながら自動的に抽出する。Transformerの深い文脈理解能力は、単純なキーワード検索とは一線を画します。「咳はなし」といった否定表現や、「父が糖尿病」といった本人以外の情報などを正確に区別して解釈できるため、情報の質が格段に向上するのです(3)。
これが実現すれば、日々の診療記録が、そのままリアルワールドデータとして質の高い臨床研究に活用できるデータベースへと姿を変えます。これまで何ヶ月もかかっていたデータの収集と整理が劇的に加速する未来を想像すると、少しワクワクしてきませんか?

医療文献の要約と質問応答
最新の知識をアップデートし続けることは、私たちの責務ですが、正直なところ、世界中から毎日洪水のように発表される新しい医学論文をすべて追いかけるのは、物理的に不可能に近いと感じることもあります。
そんな時、TransformerベースのAIは、超人的な記憶力を持つ図書館の司書のように振る舞ってくれます。
例えば、PubMedに収載されている数千万件の論文を事前に学習したAIに、「この患者背景における〇〇病の二次治療として、最新のガイドラインで推奨されるレジメンは?」と、まるで同僚に尋ねるかのように自然言語で質問する。するとAIは、関連する文献を瞬時に探し出し、その要点をまとめ、根拠となる論文と共に回答を提示してくれる。そんなシステムが、実際に研究されています(4)。
これにより、私たちは情報収集という骨の折れる作業から解放され、その知見をどう臨床に活かすか、という、より本質的で創造的な思考に時間を使えるようになるかもしれません。

診断支援と予後予測
特に複雑な症例では、鑑別診断のリストは膨大になり、稀な疾患を見落とさないように常に神経を尖らせています。人間の認知能力には限界があるのも事実でしょう。
ここでAIは、医師に取って代わるのではなく、決して疲れない、知識豊富な相談相手としての役割を果たし始めます。患者の全診療記録(症状の経過、検査データ、画像所見レポートなど)を時系列に沿って読み込み、人間では見落としがちな微細なパターンを捉えることで、診断のヒントや、将来の疾患増悪リスク、治療への反応性などを予測します。
特に、Googleが開発したMed-PaLMのような医療に特化した大規模言語モデルは、医師国家試験で専門医に匹敵する高い正答率を示すなど、その驚異的な能力で世界中の注目を集めています(5)。AIが「この臨床経過と検査値のパターンは、教科書的には稀ですが〇〇病の可能性も示唆されます。関連文献はこちらです」と、客観的な根拠と共に別の視点を提示してくれることは、診断の精度を高めるための強力な安全網となりうるでしょう。
創薬と臨床試験のマッチング
新しい治療法が患者さんの元に届くまでには、基礎研究から臨床試験まで、長く険しい道のりがあります。Transformerは、このプロセスを加速させる触媒としての役割も期待されています。
例えば、創薬の分野では、膨大な生命科学の文献をAIが読み解き、これまで知られていなかった遺伝子と疾患の関連性や、新しい治療薬のターゲットとなりうる分子経路を予測する研究が進んでいます。
また、臨床の現場では、非常に複雑な適格基準(Inclusion/Exclusion Criteria)を持つ臨床試験に参加可能な患者を、電子カルテの情報から自動的にスクリーニングする応用も始まっています(6)。これにより、患者さんにとっては新しい治療の選択肢にアクセスしやすくなり、研究者にとっては試験の遂行が効率化されるという、双方にとって大きなメリットが生まれます。

これらの応用例を眺めてみると、Transformerという技術が、単なるテキスト分類器という枠をはるかに超え、医療の「質」「効率」、そして「科学的発見」そのものを加速させる、強力なエンジンとなりうる可能性を秘めていることが、お分かりいただけるのではないでしょうか。
4. PyTorchでTransformerを実装する準備
さて、理論と応用例でTransformerがいかに強力なツールであるか、その片鱗に触れていただけたかと思います。ここからは、いよいよ自分たちの手でその力を動かしてみる、最もエキサイティングなパートです。PyTorchという強力なフレームワークを使い、医療テキストを分類するTransformerモデルをゼロから構築していきます。
料理に例えるなら、レシピの理論を学んだ後、実際にキッチンに立って調理を始めるようなものですね。そして、どんなに素晴らしいレシピでも、最初に行うべき最も大切な工程は「食材の下ごしらえ」、つまりデータの前処理です。AIというシェフが最高のパフォーマンスを発揮できるよう、丁寧にデータを準備していきましょう。
4.1. 厨房と調理器具の準備:ライブラリと環境設定
まずは、私たちの厨房となるプログラミング環境に、必要な調理器具(ライブラリ)を揃えるところから始めます。プログラミングの世界では、先人たちが作ってくれた便利な「道具箱」を借りてくることで、複雑な処理も驚くほど簡潔に記述できるんですよ。
- PyTorch (`torch`, `torch.nn`など): AIモデルを作るためのキッチンそのものです。ニューラルネットワークというオーブンやコンロ、テンソルという調理用のボウルや鍋など、基本的な調理器具一式を提供してくれます。
- Scikit-learn (`sklearn`): データを適切に分けたり、モデルの性能を客観的に評価したりするための、精密な計量カップや温度計のような役割を果たします。
- Janome: 日本語という、少し特殊な食材を捌くための専門の包丁です。単語の区切りがない日本語の文章を、意味のある単位(単語)に切り分けてくれます。
- dataclass: 今回のレシピの材料や手順(設定値)を綺麗にまとめておくための、便利なレシピカードのようなものです。
【実行前の準備】
以下のコードを実行する前に、必要なライブラリをインストールしてください。
ターミナルやコマンドプロンプトで、次のコマンドを入力します:
pip install japanize-matplotlib janomejapanize-matplotlib:グラフの日本語表示用janome:日本語の形態素解析に使用
graph TD
A["プログラム開始"] --> B["1. ライブラリを準備 (PyTorch等)"];
B --> C["2. 設定の設計図を定義 (TransformerConfig クラス)"];
C --> D["3. 設計図から具体的な設定を作成 (config インスタンス)"];
D --> E{"4. GPUは利用可能か?"};
E -- はい --> F["デバイスを 'cuda' (GPU) に設定"];
E -- いいえ --> H["デバイスを 'cpu' に設定"];
F --> I["5. 使用するデバイスをログに出力"];
H --> I;
I --> J["...後続の処理(モデル構築・学習)へ"];
# --- 0. 必要なライブラリと設定 ---
# PyTorch関連: AIモデルの構築、学習、データ管理の心臓部
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torch.optim.lr_scheduler import ReduceLROnPlateau # 学習率を自動調整するスケジューラ
# データサイエンス関連: 数値計算、データ分割、性能評価、可視化のツール
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # データを訓練/検証/テスト用に分割
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score # 性能評価のためのツール
# 自然言語処理関連: 日本語の形態素解析
from janome.tokenizer import Tokenizer
# Python補助ツール: コードの整理や可読性向上のための道具
from dataclasses import dataclass # 設定をまとめるのに便利なクラス
import math # 数学関数(Positional Encodingで使用)
import logging # 処理の進捗を記録するロギング
import time # 処理時間を計測
from typing import List, Dict, Tuple # 型ヒント(コードの可読性向上)
# 処理の進捗がわかりやすいようにロギング(実況中継)を設定
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
# ハイパーパラメータや設定を一つの「レシピカード」にまとめて管理します。
# こうすることで、後から「学習率だけ変えて試してみよう」といった調整が非常に楽になります。
@dataclass
class TransformerConfig:
"""モデルと学習に関する設定を管理するクラス"""
# データ関連
test_size: float = 0.3 # 全データのうちテストデータとして使う割合
val_size: float = 0.2 # 訓練データのうち検証データとして使う割合
random_state: int = 42 # 乱数シード(結果の再現性を確保するための「おまじない」)
# モデルのハイパーパラメータ
vocab_size: int = 0 # 語彙サイズ(後でデータから自動設定)
embedding_dim: int = 128 # 単語を表現するベクトルの次元数(意味の豊かさ)
nhead: int = 4 # Multi-Head Attentionのヘッド数。注意: embedding_dimはnheadで割り切れる必要があります
num_encoder_layers: int = 2 # Transformer Encoder層を何層重ねるか(モデルの深さ)
dim_feedforward: int = 512 # Encoder内部のFFNの次元数
dropout_rate: float = 0.1 # ドロップアウト率(過学習防止)
num_classes: int = 0 # 分類したいクラス数(後で自動設定)
# 学習関連
learning_rate: float = 1e-4 # 学習率(モデルが学習する歩幅)
batch_size: int = 4 # バッチサイズ(一度にモデルに見せるデータ数)
num_epochs: int = 30 # エポック数(データセット全体を何周学習するか)
model_save_path: str = "best_transformer_model.pth" # 最良モデルの保存先
# 設定クラスのインスタンスを作成
config = TransformerConfig()
# 計算にGPUが使えるか確認し、使えるならGPU(cuda)を、使えないならCPUを選択
# GPUを使うと、計算が劇的に速くなります。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
logging.info(f"使用デバイス: {device}")4.2. 食材の下ごしらえ:テキストデータの前処理
キッチンと道具が揃ったので、次はいよいよ食材(テキストデータ)の準備です。今回は、私たちがAIに学習させたい、簡単な医療関連のテキストと、それに対応する診療科のラベルを用意しました。いわば、模擬的な臨床ケース集のようなものですね。
# --- 1. データセットの準備 ---
# LSTMの時より少しデータを増やし、より実践的な状況に近づけます
corpus = [
("熱があり、咳と喉の痛みがあります。", "内科"),
("お腹が急に痛み出し、吐き気もします。", "内科"),
("転んで手首を強く打ち、腫れてきました。", "外科"),
("最近、視力が落ちてきた気がします。", "眼科"),
("鼻水が止まらず、くしゃみが頻繁に出ます。", "内科"),
("切り傷が深く、血が止まりません。", "外科"),
("目がかすんで、細かい文字が見えにくいです。", "眼科"),
("頭痛がひどく、めまいも感じます。", "内科"),
("足首を捻挫し、歩くと痛みます。", "外科"),
("充血していて、目やにも多いです。", "眼科"),
("定期的な健康診断と予防接種を希望します。", "内科"),
("骨折した可能性があり、レントゲンが必要です。", "外科"),
("コンタクトレンズの処方箋が欲しいです。", "眼科"),
("血糖値が高く、食事指導をお願いしたい。", "内科"),
("スポーツで膝を痛め、動かすと激痛が走る。", "外科"),
("物が二重に見える時があります。", "眼科"),
("動悸がして、時々胸が苦しくなる。", "内科"),
("やけどをしてしまい、水ぶくれができた。", "外科"),
("ドライアイで目が乾き、ゴロゴロする。", "眼科"),
("血圧が高めで、生活習慣の相談がしたい。", "内科")
]
# テキスト部分とラベル部分をそれぞれ別のリストに格納しておくと、後の処理が楽になります。
texts = [data[0] for data in corpus]
labels_str = [data[1] for data in corpus]さて、このままではAIシェフはこの食材を調理できません。AIが理解できるのは「言葉」ではなく「数値」だからです。そこで、これから一連の前処理を通して、テキストデータを数値の列に変換していきます。この面倒な下ごしらえを自動で行ってくれるTextPreprocessorという便利なクラスを定義しましょう。
このクラスが行う処理の流れは、以下の図のようになります。
テキストベースの図
【テキストデータ前処理のパイプライン】
1. 元の日本語テキスト
「熱があり、咳と喉の痛みがあります。」
│
▼
2. トークン化 (Tokenization) :文章を意味のある最小単位(単語)に分割
["熱", "が", "あり", "、", "咳", "と", "喉", "の", "痛み", "が", "あり", "ます", "。"]
│
▼
3. 語彙の構築 & IDへの変換 :登場する全単語にユニークな背番号(ID)を割り振り
[2, 3, 4, 5, 6, 7, 8, 9, 10, 3, 4, 11, 12]
(語彙辞書の例: {"<PAD>":0, "<UNK>":1, "熱":2, "が":3, ...})
│
▼
4. パディング (Padding) :全文章の長さを、一番長いものに合わせて揃える
[2, 3, 4, 5, 6, 7, 8, 9, 10, 3, 4, 11, 12, 0, 0, ...]
(短い文章には、特別な目印であるID:0 (<PAD>)を詰める)
解説:
この4ステップを経て、人間が読むための「文章」が、AIが計算できる「数値の行列(テンソル)」へと変換されます。
一つ一つのステップが、AIがデータを効率よく、かつ正確に学習するために不可欠です。
特に、文章の長さを揃える「パディング」は、GPUでデータをまとめて高速処理するための重要な下準備となります。この各ステップがなぜ必要なのか、もう少しだけ詳しく見ていきましょう。
- トークン化: コンピュータは文章をひとかたまりのままでは扱えません。Janomeという日本語の専門家にお願いして、意味のある最小単位(トークン)に分解してもらう必要があります。
- 語彙の構築とID化: 「熱」や「咳」といった単語そのものではなく、それぞれに割り当てたユニークな背番号(ID)でAIは情報を扱います。データセットに出てくる全ての単語をリストアップし、IDを振った対応表が「語彙」です。
- パディング: AI、特にGPUを使った計算では、データを綺麗な長方形の行列(テンソルのことですね)の形でまとめて処理するのが大得意です。文章の長さがバラバラだとこの形が作れないため、一番長い文章に合わせて、短い文章には
<PAD>(Pad=埋める)という特殊なトークンを詰めて、見かけ上の長さを揃えてあげるわけです。
それでは、この一連の処理を実装したクラスを見てみましょう。
graph TD
Start["入力データ群\n(文章リスト, ラベルリスト)"]
subgraph "テキスト前処理 (TextPreprocessor)"
A["1. 語彙の準備 (fit)"]
A --> A1["全文章を単語に分解"]
A1 --> A2["『単語⇔ID』の辞書を作成\n一番長い文章の単語数を記録"]
A2 --> B["2. 文章の数値化 (transform)"]
B --> B1["各文章を『単語ID』の列に変換"]
B1 --> B2["全ての文章を一番長いものに\n長さを揃える (パディング)"]
B2 --> B3["AIが扱える数値データ (テンソル) に変換"]
B3 --> OutputX["出力X\n(数値化された文章データ)"]
end
subgraph "ラベル(分類名)の前処理"
C["A. 『ラベル⇔ID』の辞書を作成"]
C --> D["B. 各ラベルをIDに変換し\n数値データ (テンソル) へ"]
D --> OutputY["出力Y\n(数値化されたラベルデータ)"]
end
Start --> A
Start --> C
OutputX --> EndPoint["完了: AIモデルへの入力データ (X, y)"]
OutputY --> EndPoint
# --- 2. 前処理クラスと実行 ---
class TextPreprocessor:
"""テキストの前処理(トークン化、語彙構築、ID化、パディング)を責務とするクラス"""
def __init__(self):
# JanomeのTokenizerインスタンスを生成
self.tokenizer = Tokenizer()
# 単語からIDへの辞書
self.word_to_id: Dict[str, int] = {}
# IDから単語への辞書
self.id_to_word: Dict[int, str] = {}
# 文章の最大長
self.max_len: int = 0
# 特殊トークンの定義
self.pad_token = "<PAD>" # パディング用
self.unk_token = "<UNK>" # 未知語用 (語彙にない単語が出てきた時に使う)
def fit(self, texts: List[str]):
"""データセットから語彙を構築し、最大系列長を計算する"""
logging.info("語彙の構築を開始...")
# 特殊トークンをID=0, 1として、最初に辞書に登録
self.word_to_id = {self.pad_token: 0, self.unk_token: 1}
# 全テキストをトークン化(単語のリストのリストになる)
tokenized_texts = [self._tokenize(text) for text in texts]
# 語彙にない新しい単語を見つけたら、辞書に追加していく
for tokens in tokenized_texts:
for token in tokens:
if token not in self.word_to_id:
# 新しいIDとして、現在の辞書のサイズ(=次の空き番号)を割り当てる
self.word_to_id[token] = len(self.word_to_id)
# IDから単語への逆引き辞書も作成(後で結果を確認するのに便利)
self.id_to_word = {v: k for k, v in self.word_to_id.items()}
# データセット中の最も長い文章の単語数を計算し、保存
self.max_len = max(len(tokens) for tokens in tokenized_texts)
logging.info(f"語彙サイズ: {len(self.word_to_id)} 単語")
logging.info(f"最大系列長: {self.max_len} トークン")
def transform(self, texts: List[str]) -> torch.Tensor:
"""テキストをID化し、パディングしてテンソルに変換する"""
# 1. テキストをトークン化
tokenized_texts = [self._tokenize(text) for text in texts]
# 2. トークンをIDに変換(語彙になければ未知語ID:1を使用)
sequences = [[self.word_to_id.get(token, self.word_to_id[self.unk_token]) for token in tokens] for tokens in tokenized_texts]
# 3. パディング処理(最大長に満たない部分をPADトークンのID:0で埋める)
padded_sequences = [seq + [self.word_to_id[self.pad_token]] * (self.max_len - len(seq)) for seq in sequences]
# 4. PyTorchが扱えるLongTensorという形式に変換
return torch.LongTensor(padded_sequences)
def _tokenize(self, text: str) -> List[str]:
# Janomeを使って文章を単語(表層形)のリストに分割
return [token.surface for token in self.tokenizer.tokenize(text)]
# 前処理クラスのインスタンスを作成して実行
preprocessor = TextPreprocessor()
preprocessor.fit(texts) # 訓練データ全体から語彙を構築
X = preprocessor.transform(texts) # テキストをID化・パディングしてテンソルに
# ラベル(診療科名)も、AIが扱える数値IDに変換します
# {"内科": 0, "外科": 1, "眼科": 2} のような辞書を作成
label_map = {label: i for i, label in enumerate(sorted(list(set(labels_str))))}
id_to_label = {i: label for label, i in label_map.items()}
y = torch.LongTensor([label_map[label] for label in labels_str])
# データから得られた語彙サイズとクラス数を、設定ファイルに反映
config.vocab_size = len(preprocessor.word_to_id)
config.num_classes = len(label_map)
logging.info(f"入力データ(X)の形状: {X.shape}")
logging.info(f"ラベルデータ(y)の形状: {y.shape}")
logging.info(f"ラベルとIDの対応: {label_map}")これで、AIモデルという名のシェフが腕を振るうための、完璧に下ごしらえされた食材が揃いました!Xというテンソルには入力となる文章の情報が、yというテンソルには正解となる診療科の情報が、それぞれ数値の形で格納されています。いよいよ、モデル本体の構築に進みましょう。
5. Transformerモデルの構築 (PyTorch):私たちのAIの設計図を描こう!
さあ、データの下ごしらえという、地道だけれどもとっても大切な準備運動が終わりましたね! これで、私たちの手元には、AIが「読んで」「学習する」ための、キレイに整形された「数値のレシピ」が用意できました。いよいよここからは、このレシピを使って美味しい料理を作り出すAIシェフ、つまりTransformerモデルそのものを設計し、PyTorchという調理器具を使って実際に組み立てていく工程に入ります。
PyTorchでAIモデルを自作する際には、nn.Moduleという、便利な機能がたくさん詰まった「設計図のテンプレート」のようなものを継承(inherit)して、私たち独自のクラス(今回はMedicalTextTransformer)を作成するのが一般的です。このテンプレートをお借りすることで、私たちはモデルの構造設計という、最も創造的な部分に集中できるというわけです。
モデルの主要な構成要素
今回私たちが作るTransformerモデルは、大きく分けて4つの主要な部品(層(Layer))から構成されます。それぞれの層が連携し合うことで、入力された文章(実際には単語IDの列ですね)から、最終的な予測(どの診療科に属するか)を導き出します。それぞれの部品がどんな役割を持っているのか、まずはイメージを掴んでみましょう。
- 埋め込み層 (
nn.Embedding):
最初の工程は、単語IDという無機質な「背番号」を、意味を持つ豊かな情報に変換するところから始まります。この層は、各IDを「単語埋め込みベクトル」と呼ばれる、数十〜数百次元の密な数値のベクトルに変換します。これは、単なる背番号を、その選手の能力や特徴、他の選手との相性などを詳細に記述した「選手プロフィール」に変換するようなものです。意味が近い単語(例えば「発熱」と「高体温」)は、このベクトル空間の中でも近い位置に配置されるよう学習されていきます。 - 位置エンコーディング (
PositionalEncoding):
Transformerの「専門家パネル」は、全単語を一度に見るため、そのままでは語順がわからなくなってしまいます。そこで、この層が各単語のベクトルに「文の先頭から何番目か」という位置情報を、特殊な数学的信号(sin/cos関数)として焼き付けます。これにより、モデルは語順という重要な文脈を失わずに済みます。 - Transformerエンコーダ層 (
nn.TransformerEncoder):
このモデルのまさに心臓部であり、頭脳です。位置情報が加わった単語ベクトルたちが、この層に送られてきます。内部では、あの強力な自己注意機構(Self-Attention)がフル稼働し、「どの単語が、他のどの単語に注目すべきか」という、文脈上の重み付けを計算します。PyTorchでは、この複雑な計算が便利な部品として提供されているため、私たちはその恩恵を手軽に受けることができます。 - 分類層 (
nn.Linear):
最後の仕上げです。エンコーダ層がじっくりと読み解き、文章全体の文脈を凝縮した一つのベクトルを生成します。このベクトルを受け取り、最終的に「この文章は、どの診療科に分類されるべきか」という予測スコアを算出するのが、この分類層の役割です。パネルディスカッションの末に、最終的な結論を出すための投票を行うようなイメージですね。
Transformerモデルの全体像:設計図(クラス定義)
それでは、これらの部品を組み合わせたモデル全体の設計図(Pythonクラス)を見ていきましょう。
graph TD
Start["入力データ\n(ID化された文章のテンソル)"]
--> L1["1. 埋め込み層 (Embedding)"]
L1_Desc["単語IDを、意味や文法情報を持つ\n高次元の『単語ベクトル』に変換する"]
L1 --> L1_Desc
--> L2["2. 位置エンコーディング (Positional Encoding)"]
L2_Desc["各単語ベクトルに、文章内での\n『位置・順番』に関する情報を加える"]
L2 --> L2_Desc
--> L3["3. Transformerエンコーダ (Encoder)"]
subgraph " "
direction LR
L3_A["自己注意機構 (Self-Attention)\n単語同士の関連性を計算し、\n文脈における重要度を学習する"]
--> L3_B["情報更新\n計算された関連性に基づき、\n各単語のベクトル表現をより洗練させる"]
end
L3_C["(このエンコーダ処理を複数回繰り返す)"]
L3 --> L3_C
--> L4["4. 集約処理 (Pooling)"]
L4_Desc["全単語の出力ベクトルを平均化し、\n『文章全体を代表する一つのベクトル』を生成する"]
L4 --> L4_Desc
--> L5["5. 分類層 (Classifier)"]
L5_Desc["文章全体のベクトルに基づき、\n最終的な分類(例: 診療科)の\n可能性スコアを計算する"]
L5 --> L5_Desc
--> EndPoint["出力\n(各分類の予測スコア)"]
subgraph Legenda["凡例"]
direction LR
Node1(["処理ステップ"])
Node2(("データの状態や説明"))
end
style L1 fill:#E3F2FD,stroke:#333,stroke-width:2px
style L2 fill:#E3F2FD,stroke:#333,stroke-width:2px
style L3 fill:#E3F2FD,stroke:#333,stroke-width:2px
style L4 fill:#E3F2FD,stroke:#333,stroke-width:2px
style L5 fill:#E3F2FD,stroke:#333,stroke-width:2px
style L1_Desc fill:#FFF,stroke:#999,stroke-width:1px,stroke-dasharray: 5 5
style L2_Desc fill:#FFF,stroke:#999,stroke-width:1px,stroke-dasharray: 5 5
style L3_C fill:#FFF,stroke:#999,stroke-width:1px,stroke-dasharray: 5 5
style L4_Desc fill:#FFF,stroke:#999,stroke-width:1px,stroke-dasharray: 5 5
style L5_Desc fill:#FFF,stroke:#999,stroke-width:1px,stroke-dasharray: 5 5
style Start fill:#E8F5E9,stroke:#333,stroke-width:2px
style EndPoint fill:#FCE4EC,stroke:#333,stroke-width:2px
# --- 3. Transformerモデルの定義 ---
class PositionalEncoding(nn.Module):
"""Transformerのための位置エンコーディングを計算するクラス"""
def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):
# d_model: 単語ベクトルの次元数 (embedding_dim)
# dropout: ドロップアウト率
# max_len: 想定される文章の最大長
super().__init__()
self.dropout = nn.Dropout(p=dropout)
# 各位置(0, 1, ..., max_len-1)を示すテンソルを作成
position = torch.arange(max_len).unsqueeze(1)
# sin/cos関数に適用するための除算項を計算(論文通りの式)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
# 位置エンコーディングのテンソル(pe)を初期化 (max_len, 1, d_model)
pe = torch.zeros(max_len, 1, d_model)
# 偶数次元にはsin関数を、奇数次元にはcos関数を適用し、ユニークな位置ベクトルを生成
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
# peをモデルのバッファとして登録。これは学習されるパラメータではないですが、モデルの状態として保存されます。
self.register_buffer('pe', pe)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
入力テンソルに位置エンコーディングを加算する
Args:
x: Tensor, 形状 [系列長, バッチサイズ, 埋め込み次元]
"""
# 入力x (単語埋め込みベクトル) に、対応する位置のエンコーディングを加算
x = x + self.pe[:x.size(0)]
return self.dropout(x)
class MedicalTextTransformer(nn.Module):
"""テキスト分類のためのTransformerエンコーダモデル"""
def __init__(self, config: TransformerConfig):
super().__init__()
self.config = config
# 1. 埋め込み層: vocab_size種類の単語を、embedding_dim次元のベクトルに変換
# padding_idx=0とすることで、PADトークン(ID=0)は計算時に無視されるようになります。
self.embedding = nn.Embedding(config.vocab_size, config.embedding_dim, padding_idx=0)
# 2. 位置エンコーディング層
self.pos_encoder = PositionalEncoding(config.embedding_dim, config.dropout_rate)
# 3. Transformerエンコーダの基本部品(これを複数重ねるためのテンプレート)
encoder_layers = nn.TransformerEncoderLayer(
d_model=config.embedding_dim, # 入力ベクトルの次元数
nhead=config.nhead, # Multi-Head Attentionのヘッド数
dim_feedforward=config.dim_feedforward, # Encoder内部のFFNの次元数
dropout=config.dropout_rate, # ドロップアウト率
batch_first=True # これが重要!入力テンソルの形状を(バッチ, 系列長, 次元)の順にします。
)
# 4. Transformerエンコーダ本体(基本部品をnum_encoder_layers層重ねる)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=config.num_encoder_layers)
# 5. 分類層: Transformerの出力を受け取り、最終的にクラス数分のスコアを出力
self.classifier = nn.Linear(config.embedding_dim, config.num_classes)
self.d_model = config.embedding_dim
def forward(self, src: torch.Tensor) -> torch.Tensor:
# src: 入力テンソル, 形状 (バッチサイズ, 系列長)
# PADトークン(ID=0)の位置を特定するマスクを作成します。
# Attention計算時に、このマスクでTrueになっている部分は無視されるようになります。
src_key_padding_mask = (src == 0)
# 埋め込みベクトルに変換し、ベクトルの大きさを調整します(論文で推奨されているテクニックです)。
embedded = self.embedding(src) * math.sqrt(self.d_model)
# PositionalEncoding層は(系列長, バッチ, 次元)の形状を期待するため、
# 一時的に次元を入れ替えて(permute)適用し、また元に戻します。
pos_encoded = self.pos_encoder(embedded.permute(1, 0, 2)).permute(1, 0, 2)
# いよいよエンコーダに入力。ここで自己注意機構が働き、文脈がリッチな表現に変換されます。
output = self.transformer_encoder(pos_encoded, src_key_padding_mask=src_key_padding_mask)
# [重要] 分類のための集約処理:
# LSTMでは最後の隠れ状態を使いましたが、Transformerでは全単語の出力が得られます。
# そこで、PADでないトークンの出力ベクトルだけを平均(平均プーリング)し、
# 文章全体を代表する一つのベクトルを生成します。
mask_for_avg = ~src_key_padding_mask # マスクを反転 (PADでない部分がTrueになる)
num_non_pad = mask_for_avg.sum(dim=1, keepdim=True).float() # 文章ごとの非PADトークンの数を計算
output = output * mask_for_avg.unsqueeze(-1) # PAD部分の出力を0でマスクして無効化
pooled_output = output.sum(dim=1) / num_non_pad # 合計を非PADトークン数で割り、平均を計算
# 集約されたベクトルを分類層に入力し、最終的な予測スコア(ロジット)を得ます。
logits = self.classifier(pooled_output)
return logitsデータの流れを追う:forwardメソッドの働き
__init__でモデルの部品を定義しましたが、実際にデータがどのように処理されていくのか、その流れを定義しているのがforwardメソッドです。この部分の流れを、テンソルの形状(データの形)の変化と共に追ってみましょう。
テキストベースの図
【forwardメソッドにおけるテンソルの形状変化】
入力: src (単語IDの列)
形状: (batch_size, max_len)
例: (4, 15) <- 4つの文章、各文章は15単語(ID)で表現
│
▼
1. 埋め込み層 & 位置エンコーディング
処理: 各IDをembedding_dim次元のベクトルに変換し、位置情報を加算
│
▼
中間出力: pos_encoded (単語ベクトルの列)
形状: (batch_size, max_len, embedding_dim)
例: (4, 15, 128) <- 各単語が128次元の意味ベクトルに
│
▼
2. Transformerエンコーダ層
処理: 自己注意機構により、各単語のベクトルが文脈全体を反映した表現に更新される
│
▼
中間出力: output (文脈化された単語ベクトルの列)
形状: (batch_size, max_len, embedding_dim)
例: (4, 15, 128) <- 形状は同じだが、中身の意味がよりリッチに
│
▼
3. 平均プーリングによる集約
処理: パディング部分を除いた全単語のベクトルを平均し、文章全体を代表する1つのベクトルを作成
│
▼
中間出力: pooled_output (文章ベクトル)
形状: (batch_size, embedding_dim)
例: (4, 128) <- 各文章が128次元のベクトルに集約された
│
▼
4. 分類層
処理: 文章ベクトルを、予測したいクラス数(診療科の数)のスコアに変換
│
▼
最終出力: logits (各クラスの予測スコア)
形状: (batch_size, num_classes)
例: (4, 3) <- 4つの文章それぞれについて、3つの診療科のスコアが出力されたこのように、forwardメソッドは、単なる単語IDの列から、段階的に情報を豊かにし、最後にはタスクを解くための予測スコアへと変換していく、まさにAIの思考プロセスそのものを記述している部分だと言えるでしょう。特に、平均プーリングの部分は、Transformerを分類タスクに使う際の定石の一つなので、しっかりイメージを掴んでおくと良いと思います。
6. 学習処理の実装:AIモデルに「魂」を吹き込む!
さあ、前のセクションで、私たちの手でTransformerモデルというAIの「体」を無事に組み立てることができましたね! まるで、ピカピカのロボットが完成したような気分でしょうか。でも、この時点ではまだ、このロボットはただの置物。どうやって動けばいいのか、何をすれば褒められるのか、何も知らない、いわば生まれたての赤ちゃんのような状態なんです。
ここからが、AI開発のもう一つの、そして非常に重要な山場、「学習処理」の始まりです! この学習プロセスを通じて、私たちはモデルに大量のデータ(お手本)を見せ、モデルが賢く成長していくように、いわば「魂」を吹き込んでいくのです。
このプロセスは、一人の医学生を育てるプロセスによく似ていると私は思います。優れた医学生を育てるには、何が必要でしょうか?
- 質の高い教科書と、自分の実力を測るための模擬試験、そして最終的な能力を評価する本試験。(データの分割)
- 解答がどれだけ正解からズレているかを採点する成績表。(損失関数)
- 間違えた問題の直し方を指導し、成長を促す熱血コーチ。(最適化アルゴリズム)
- これらを使って反復練習をこなす、体系的な学習スケジュール。(学習ループ)
このセクションでは、これらの要素を一つずつ、PyTorchで実装していきます。
6.1. AIの教科書、模試、本試験:訓練・検証・テストデータの分割
AI開発において、私たちが最初に学ぶべき最も重要な作法の一つが、手持ちのデータを適切に分割することです。なぜなら、モデルが学習に使った問題をそのままテストに出しても、それは単なる「答えの丸暗記」能力しか測れないからです。私たちが本当に知りたいのは、モデルが未知のデータ(=初見の症例)に対して、どれだけ正しく推論できるか、その汎化性能ですよね。
そのために、私たちはデータを通常3つのグループに分割します。
- 訓練(Train)データ: モデルが学習するための教科書であり、練習問題集です。モデルはこのデータを何度も見て、パターンを学びます。
- 検証(Validation)データ: 学習の途中でモデルの実力を測るための模擬試験です。モデルはこのデータで学習はしません。私たちは、各エポック(教科書を1周する単位)の終わりに検証データの成績を見ることで、「学習は順調か?」「過学習(丸暗記)に陥っていないか?」などを判断し、学習の軌道修正(ハイパーパラメータ調整)を行います。
- テスト(Test)データ: すべての学習と調整が終わった後に、一度だけ使う本番の国家試験です。このデータは、モデルにとって完全に未知のものであり、ここでの成績がモデルの最終的な実力評価となります。
この分割は、研究の信頼性を担保する上で極めて重要です。
graph TD
Start["全データセット\n(数値化された文章X, ラベルy)"]
--> Split["1. データを3種類に分割する"]
Split_Desc["(元のデータのクラス比率を保ちながら分割)"]
Split --> Split_Desc
Split --> TrainData["訓練用データ"]
Split --> ValData["検証用データ"]
Split --> TestData["テスト用データ"]
subgraph "2. データ供給の準備 (Dataset & DataLoader)"
direction LR
subgraph "訓練 (Training)"
TrainData --> T1["Dataset化\n(データとラベルをペアにする)"]
T1 --> T2["DataLoader化\n(ミニバッチに分割、順番をシャッフル)"]
T2 --> TrainLoader["訓練ローダー"]
end
subgraph "検証 (Validation)"
ValData --> V1["Dataset化\n(データとラベルをペアにする)"]
V1 --> V2["DataLoader化\n(ミニバッチに分割)"]
V2 --> ValLoader["検証ローダー"]
end
subgraph "テスト (Testing)"
TestData --> E1["Dataset化\n(データとラベルをペアにする)"]
E1 --> E2["DataLoader化\n(ミニバッチに分割)"]
E2 --> TestLoader["テストローダー"]
end
end
TrainLoader --> EndPoint
ValLoader --> EndPoint
TestLoader --> EndPoint
EndPoint["完了: 3種類のDataLoader\n(モデルの学習・評価ループで使用)"]
style Start fill:#E8F5E9,stroke:#333,stroke-width:2px
style Split fill:#E3F2FD,stroke:#333,stroke-width:2px
style Split_Desc fill:#FFF,stroke:#999,stroke-width:1px,stroke-dasharray: 5 5
style EndPoint fill:#FCE4EC,stroke:#333,stroke-width:2px
# --- 4. データセットの準備と分割 ---
# PyTorchが扱いやすいように、Datasetクラスを定義します。
# これは、私たちのデータ(X, y)をPyTorch仕様のお弁当箱に詰めるようなイメージです。
class MedicalTextDataset(Dataset):
def __init__(self, texts_tensor: torch.Tensor, labels_tensor: torch.Tensor):
self.texts = texts_tensor
self.labels = labels_tensor
# データセットの総数を返す関数
def __len__(self) -> int:
return len(self.labels)
# 指定されたインデックスのデータとラベルのペアを返す関数
def __getitem__(self, idx: int) -> Tuple[torch.Tensor, torch.Tensor]:
return self.texts[idx], self.labels[idx]
# Scikit-learnの機能を使って、データを分割します。
# まずは訓練用と、残りの(検証+テスト)用に分けます。
# stratify=yとすることで、元のデータのクラス比率(内科・外科・眼科の割合)を保ったまま分割してくれます。
# これは、データが不均衡な場合に特に重要です。
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=config.test_size, random_state=config.random_state, stratify=y
)
# 次に、残りのデータを検証用とテスト用に半分ずつ分けます。
X_val, X_test, y_val, y_test = train_test_split(
X_temp, y_temp, test_size=0.5, random_state=config.random_state, stratify=y_temp
)
# 各データセットのインスタンス(お弁当箱)を作成
train_dataset = MedicalTextDataset(X_train, y_train)
val_dataset = MedicalTextDataset(X_val, y_val)
test_dataset = MedicalTextDataset(X_test, y_test)
# DataLoaderを作成します。これは、お弁当箱からデータをミニバッチ単位で取り出し、
# モデルに供給してくれる「給食当番」のような役割です。
# shuffle=Trueにすることで、訓練データはエポックごとに順番をランダムにかき混ぜてくれます。
# これにより、モデルがデータの出現順を覚えてしまうのを防ぎ、学習効果を高めます。
train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=config.batch_size)
test_loader = DataLoader(test_dataset, batch_size=config.batch_size)
logging.info(f"データセットサイズ - 訓練: {len(train_dataset)}, 検証: {len(val_dataset)}, テスト: {len(test_dataset)}")6.2. 成績表と熱血コーチ:損失関数と最適化アルゴリズム
データが準備できたら、次はモデルの学習方法を定義します。
- 損失関数 (Loss Function): モデルの予測が、正解とどれだけ「ズレているか」を計算する成績表です。このズレ(損失)が大きいほど、モデルの成績が悪いことを意味します。学習の目標は、この損失をできるだけ小さくすることです。
今回の多クラス分類タスクでは、最も一般的なクロスエントロピー損失 (`nn.CrossEntropyLoss`) を使います。これは、モデルが出力した各クラスの「自信度(スコア)」と正解ラベルを比較し、その隔たりを測るのに適した関数です。 - 最適化アルゴリズム (Optimizer): 損失という成績を受け取り、それを元にモデルの内部パラメータ(重み)をどう調整すれば成績が上がるかを考え、実行してくれる熱血コーチです。
今回は、数あるコーチの中でも特に優秀で人気のあるAdam (`optim.Adam`) を採用します。Adamは、学習の進捗状況を見ながら、パラメータごとに学習の歩幅(学習率, Learning Rate)をある程度自動で調整してくれる賢いコーチです。 - 学習率スケジューラ: Adamは賢いですが、学習が進むと、同じ歩幅で進み続けるのが最適とは限りません。学習が停滞してきたら、歩幅を小さくして、より細かく最適な地点を探した方が良い場合があります。`ReduceLROnPlateau` は、検証データの成績(損失)が改善しなくなったら、自動で学習率を下げてくれる、いわば「学習戦略アドバイザー」のような役割を果たします。
6.3. 反復練習ドリル:学習ループの構築
さあ、すべての準備が整いました!いよいよ、モデルに教科書(訓練データ)で反復練習をさせる学習ループを実装します。1エポック(教科書1周)の中で、モデルはミニバッチ単位で以下の「学習の基本サイクル」を何度も繰り返します。
このサイクルを、データセット全体にわたって、そして何エポックも繰り返すことで、モデルは少しずつ賢くなっていきます。
graph TD
Start["データの一塊(ミニバッチ)で訓練開始"]
--> Step1["1. 勾配のリセット (zero_grad)"]
Step1_Desc["前回ステップの計算結果(勾配)を消去し、\n今回の計算に備えて真っさらにする"]
Step1 --> Step1_Desc
--> Step2["2. 順伝播 (Forward Pass)"]
Step2_Desc["モデルがデータを読み込み、\n予測を出力する"]
Step2 --> Step2_Desc
--> Step3["3. 損失の計算 (Calculate Loss)"]
Step3_Desc["モデルの『予測』と、用意された『正解』の\nズレ(誤差)を計算する"]
Step3 --> Step3_Desc
--> Step4["4. 逆伝播 (Backward Pass)"]
Step4_Desc["計算した誤差を元に、\n『モデルのどこを、どう直せば誤差が減るか』\nという修正案(勾配)を計算する"]
Step4 --> Step4_Desc
--> Step5["5. パラメータ更新 (step)"]
Step5_Desc["計算された修正案に基づき、\n実際にモデルのパラメータを更新する\n(ここでモデルが賢くなる!)"]
Step5 --> Step5_Desc
--> EndPoint["このミニバッチでの訓練完了"]
subgraph Legenda["凡例"]
direction LR
Node1(["処理ステップ"])
Node2(("処理の目的・説明"))
end
style Start fill:#E8F5E9,stroke:#333,stroke-width:2px
style EndPoint fill:#FCE4EC,stroke:#333,stroke-width:2px
style Step1 fill:#E3F2FD,stroke:#333,stroke-width:2px
style Step2 fill:#E3F2FD,stroke:#333,stroke-width:2px
style Step3 fill:#E3F2FD,stroke:#333,stroke-width:2px
style Step4 fill:#E3F2FD,stroke:#333,stroke-width:2px
style Step5 fill:#D1C4E9,stroke:#333,stroke-width:2px
# --- 5. 学習・評価関数の定義 ---
def train_one_epoch(model, dataloader, criterion, optimizer, device):
"""1エポック分の訓練を行う関数"""
model.train() # モデルを「訓練モード」に切り替え。Dropoutなどが有効になります。
total_loss = 0
total_corrects = 0
# DataLoaderからミニバッチ単位でデータを取り出す
for texts, labels in dataloader:
# データを計算デバイス(GPU or CPU)に転送
texts, labels = texts.to(device), labels.to(device)
# --- 学習の基本サイクル ---
optimizer.zero_grad() # 1. 勾配をリセット
outputs = model(texts) # 2. 順伝播(予測)
loss = criterion(outputs, labels) # 3. 損失を計算
loss.backward() # 4. 逆伝播(勾配を計算)
optimizer.step() # 5. パラメータを更新
# このバッチでの損失と正解数を記録
total_loss += loss.item() * len(labels)
_, preds = torch.max(outputs, 1) # 最もスコアが高いクラスを予測結果とする
total_corrects += torch.sum(preds == labels)
# このエポックでの平均損失と平均精度を計算して返す
avg_loss = total_loss / len(dataloader.dataset)
accuracy = total_corrects.double() / len(dataloader.dataset)
return avg_loss, accuracy
def evaluate(model, dataloader, criterion, device):
"""モデルの評価(検証orテスト)を行う関数"""
model.eval() # モデルを「評価モード」に切り替え。Dropoutなどが無効になります。
total_loss = 0
all_preds = []
all_labels = []
# 評価時は勾配計算が不要なので、計算を効率化
with torch.no_grad():
for texts, labels in dataloader:
texts, labels = texts.to(device), labels.to(device)
outputs = model(texts)
loss = criterion(outputs, labels)
total_loss += loss.item() * len(labels)
_, preds = torch.max(outputs, 1)
all_preds.extend(preds.cpu().numpy()) # 予測結果をリストに保存
all_labels.extend(labels.cpu().numpy()) # 正解ラベルをリストに保存
avg_loss = total_loss / len(dataloader.dataset)
return avg_loss, all_preds, all_labels
# --- 6. 学習ループの実行 ---
# モデル、損失関数、最適化器、スケジューラの初期化
model = MedicalTextTransformer(config).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
scheduler = ReduceLROnPlateau(optimizer, 'min', factor=0.5, patience=3, verbose=True)
best_val_loss = float('inf') # 最良の検証損失を無限大で初期化
# 指定したエポック数だけ学習を繰り返す
for epoch in range(config.num_epochs):
start_time = time.time()
# 1. 訓練データで学習
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer, device)
# 2. 検証データで実力評価
val_loss, _, _ = evaluate(model, val_loader, criterion, device)
# 3. スケジューラの更新(検証損失を見て、学習率を調整)
scheduler.step(val_loss)
elapsed_time = time.time() - start_time
# 学習の進捗状況を表示
logging.info(f"エポック {epoch+1:2d}/{config.num_epochs} | "
f"訓練損失: {train_loss:.4f} | 訓練精度: {train_acc:.4f} | "
f"検証損失: {val_loss:.4f} | 時間: {elapsed_time:.2f}s")
# 4. 検証データの成績が過去最高だったら、その時点のモデルを保存
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), config.model_save_path)
logging.info(f"*** 検証損失が改善しました。モデルを保存します: {config.model_save_path} ***")7. 結果の解釈と医療応用への示唆:AIの成績評価と未来への展望
長い道のりでしたが、いよいよ私たちのAIモデルの学習が完了しました。手塩にかけて育てた医学生が、いよいよ最終試験に臨むような、少し緊張する瞬間ですね。このセクションでは、学習に一切使っていない、完全に未知の「テストデータ」を使ってモデルの最終的な実力を評価し、その結果をどう解釈すればよいのか、そして、この小さな一歩が医療の未来にどう繋がっていくのかを一緒に考えていきましょう。
7.1. 本番試験:テストデータによる最終評価
訓練データで良い成績を出すのは、ある意味当然です。検証データでの評価は、学習の方向性を決めるための模擬試験でした。モデルの真の価値、つまり汎化性能(未知のデータに対応できる能力)を測るには、この「本番試験」であるテストデータでの成績が最も重要になります。
早速、学習中に最も検証成績が良かったモデルをロードし、テストデータで評価を実行してみましょう。
# --- 7. 最終評価 ---
logging.info("学習が終了しました。テストデータで最終評価を行います。")
# 保存しておいた最良モデルの状態(重みパラメータ)をロードします
model.load_state_dict(torch.load(config.model_save_path))
# evaluate関数を使い、テストデータで損失、予測、正解ラベルを取得します
test_loss, test_preds, test_labels = evaluate(model, test_loader, criterion, device)
# 結果を見やすくするために、IDを診療科名に戻す準備
class_names = [id_to_label[i] for i in range(config.num_classes)]
logging.info(f"テスト損失: {test_loss:.4f}")
logging.info(f"テスト精度 (Accuracy): {accuracy_score(test_labels, test_preds):.4f}")
print("\n--- 分類レポート (Classification Report) ---")
# 適合率(Precision), 再現率(Recall), F1スコアなどをクラスごとに表示
print(classification_report(test_labels, test_preds, target_names=class_names, zero_division=0))
import matplotlib.pyplot as plt
import japanize_matplotlib
# 混同行列(どのクラスをどう間違えたか)をプロットする関数
def plot_confusion_matrix(y_true, y_pred, class_names):
cm = confusion_matrix(y_true, y_pred)
df_cm = pd.DataFrame(cm, index=class_names, columns=class_names)
plt.figure(figsize=(8, 6))
sns.heatmap(df_cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix (混同行列)')
plt.ylabel('正解ラベル (True Label)')
plt.xlabel('予測ラベル (Predicted Label)')
plt.show()
print("\n--- 混同行列 (Confusion Matrix) ---")
plot_confusion_matrix(test_labels, test_preds, class_names)
--- 分類レポート (Classification Report) ---
precision recall f1-score support
内科 0.00 0.00 0.00 1
外科 0.00 0.00 0.00 1
眼科 0.33 1.00 0.50 1
accuracy 0.33 3
macro avg 0.11 0.33 0.17 3
weighted avg 0.11 0.33 0.17 3
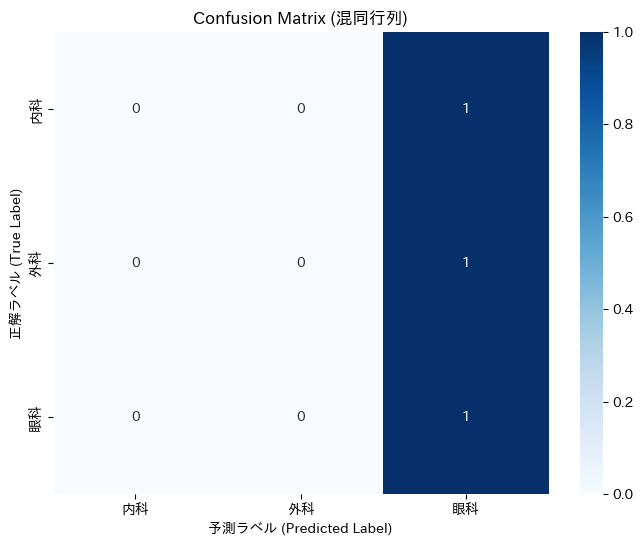
7.2. 成績表を読み解く:精度、混同行列、分類レポート
さて、コードを実行すると、いくつかの評価指標が出力されたかと思います。おそらく、驚くほど低い精度に「あれ?何か間違えたかな?」と思われたかもしれませんね。
まず最初にお伝えしたいのは、その結果は、ある意味で「大成功」だということです。
なぜなら、今回の演習の真の目的は、高精度なAIを作ることではなく、「ごく少量のデータでは、どんなに優れたアーキテクチャ(Transformer)を使っても、意味のあるモデルは学習できない」という、AI開発における最も重要な原則の一つを体感することだからです。そして、性能が低いモデルの「成績表」を正しく読み解き、次の一手を考えるための分析手法を学ぶことこそが、今回のゴールなのです。
まさに今回の結果が芳しくないからこそ、これらの「成績表」が何を教えてくれるのかを学ぶ絶好の機会です。
- 正解率 (Accuracy): 全体のサンプルに対し、モデルがどれだけ正しく予測できたかを示す、最も直感的な指標です。しかし、今回の私たちのテストデータは各クラス数件しかなく、偶然の一致で値が大きく変動してしまうため、この数値だけで一喜一憂することにはあまり意味がありません。
- 分類レポート (Classification Report): こちらが、より詳細な分析のための重要なツールです。
- 適合率 (Precision): 「モデルが『外科』と予測したもののうち、本当に『外科』だった割合」を示します。将来、私たちが作るAIが「外科の可能性が高いです」とアラートを出した時、その信頼性を測る指標になります。
- 再現率 (Recall): 「実際に『外科』であるべき症例のうち、モデルがどれだけ『外科』と見つけ出せたかの割合」です。見逃しを減らすことが重要なタスクでは、特に重視される指標です。
- F1スコア: 適合率と再現率は、一方が高くなるともう一方が低くなるトレードオフの関係にあることが多く、そのバランスを取った指標がF1スコアです。
- 混同行列 (Confusion Matrix): モデルの「間違い方の癖」を可視化した、私たち開発者にとって最も有益な診断ツールの一つです。縦軸が「正解の診療科」、横軸が「モデルが予測した診療科」を表します。対角線上の数字が正解数、それ以外が不正解の内訳です。 例えば、もし「内科」の行の「外科」の列に数字が入っていれば、それは「本来は内科に分類すべき症例を、モデルが外科と間違えてしまった」ことを意味します。このような間違いの傾向を分析することで、「”痛み”という単語に引っ張られて、内科の腹痛も外科と判断してしまっているのかもしれない。腹痛に関する内科のデータを増やそう」といった、具体的な改善策のヒントが得られるのです。
このレポートに表示される低い数値の一つひとつが、「もっとたくさんの、多様な症例(データ)で勉強させてください!」という、私たちのAIモデルからの悲鳴なのだと考えてみてください。この気づきこそが、次のステップに進むための最も重要な学習成果と言えるでしょう。
7.3. 私たちの小さな一歩と、その先に広がる地平線
前のセクションで表示された成績表を見て、正直なところ、少しがっかりした方もいるかもしれませんね。低い精度、まばらな混同行列—これらはコードのミスではなく、AI開発における最も根源的で、最も重要な教訓を、私たちのモデルが身をもって示してくれた結果なのです。
しかし、スコア以上に大切なのは、皆さんがこの章を通じて、Transformerという強力なモデルの設計図を描き、データの前処理から学習、そして客観的な評価に至るまでの一連のサイクルを、ご自身の力で回し切ったという事実です。
その確かな手応えを胸に、ここからは、この小さな一歩の先に広がる、医療AIの壮大な可能性と、私たちが真摯に向き合うべき現実的な課題について、一緒に考えていきましょう。
乗り越えるべき壁:医療AIの実用化に向けた課題
夢のある話をする前に、現実的な課題を直視することは、科学者・医療者として非常に大切な姿勢だと思います。
- データの質と量: AIの性能は、元になるデータの質と量に大きく依存します。いわゆる「Garbage in, garbage out(ゴミを入れれば、ゴミしか出てこない)」の原則です。実際の医療応用には、今回のような数十件のデータではなく、多様で、偏りがなく、適切にアノテーションされた、何万、何十万件という大規模なデータセットが不可欠です。
- 計算コスト: 今回は小さなモデルなので手元のPCでも動かせましたが、実世界で活躍するTransformerモデル、特に大規模言語モデルは、その学習に膨大な計算資源(高性能なGPUと時間)を要します。これは、誰もが気軽に最先端モデルを開発することの障壁にもなっています。
- 説明可能性 (XAI): 私たち医療者が臨床現場で「なぜ?」と常に問うように、AIの出す答えにもその根拠が求められます。「このAIは、カルテのどの記述を根拠に、この診断候補を挙げたのか?」を説明できなければ、私たちはその答えを信頼し、責任ある意思決定に活かすことはできません。Transformerの自己注意機構の可視化など、判断根拠を明らかにしようとする研究(XAI: Explainable AI)が活発に進められていますが、まだ発展途上の分野です (7)。
- 倫理とプライバシー: そして、何よりも重要なのがこの問題です。患者の機密情報を扱う上で、個人情報の保護は絶対条件です。データを匿名化することはもちろん、個々のデータから個人が特定されないようにする技術(差分プライバシー)や、データを一箇所に集めずに各施設内で学習を行う連合学習 (Federated Learning) (8) といった、プライバシー保護技術の徹底が、社会的な信頼を得る上で不可欠となります。
未来への羅針盤:基盤モデルと転移学習
これらの課題は決して小さくありませんが、世界中の研究者が解決に向けて取り組んでいます。そして、その中心にあるのが、本章の冒頭で触れた「学習パラダイムのシフト」です。
本章で私たちが行ったように、タスクごとにAIモデルをゼロから学習させるアプローチは、教育的な意味では非常に有益ですが、現代では主流ではありません。
現在の王道は、巨大な基盤モデル(Foundation Model)をファインチューニングするアプローチです。これは、膨大なテキストデータ(例えば、PubMedの全論文など)で事前学習された、いわば「医学知識の基礎が叩き込まれた超優秀な研修医」のようなAIをまず用意し、私たちの手元にある少量の専門データで、特定のタスク(例えば、私たちの診療科のカルテ分類)に適応するように追加学習させる方法です。
GoogleのMed-PaLM 2 (9)のようなモデルは、まさにこのアプローチの最先端であり、専門医レベルの知識と推論能力を示し始めています。この章で皆さんが学んだTransformerの基礎知識、モデル構築の経験、そして評価の考え方は、これらの最先端技術が一体何をしているのかを深く理解し、将来ご自身の研究や臨床で賢く活用していくための、確かな土台となるでしょう。
8. 実践編:Hugging Face pipelineで、AI実装を劇的に効率化する
これまでの章で、私たちはAIモデル『Transformer』の心臓部である自己注意機構の理論を学び、PyTorchを使ってゼロからモデルを組み立て、そして育て上げるという、非常に奥深く、かつ挑戦的な旅を経験してきました。このプロセスは、AIがどのようにして「思考」するのか、その内部構造を深く理解するために不可欠な経験であり、皆さんの知識の確かな土台となったはずです。
しかし、実際の研究開発や臨床応用では、毎回エンジンを部品から組み立てる(=モデルをゼロから実装する)ことは稀です。多くの場合、私たちは先人たちが築き上げた優れた成果、つまり巨大で強力な事前学習済みモデルという「巨人の肩の上」に立ち、そこから自分たちの目的に合わせて素早く開発を進めます。
このセクションでは、そのための最も強力なツールボックスである Hugging Face Transformers ライブラリと、その中でも特に便利なpipeline機能を使って、これまで何十行ものコードを書いて実現してきたテキスト分類が、いかに簡単に実現できるかを体験していただきます。
8.1. 「車輪の再発明」から「ツールの活用」へ
セクション6で実装した学習ループを思い出してみてください。データセットの準備、ミニバッチへの分割、勾配のリセット、順伝播、損失計算、逆伝播、パラメータ更新…。これら一連の複雑な処理を、私たちは一つひとつ丁寧に実装しました。
Hugging Faceのpipelineは、こうした一連の定型的な処理を、すべて裏側で自動的に実行してくれる、まさに「魔法の杖」のような機能です。
| アプローチ | ゼロから実装(本講座のセクション4-7) | Hugging Face pipelineの活用 |
|---|---|---|
| 目的 | 教育的価値: モデルの内部構造を深く理解する | 実践的価値: 最小限のコードで素早く高精度な結果を得る |
| 主な作業 | データ前処理、モデル定義、学習ループ、評価コードの完全な実装 | 目的(タスク)とモデルを指定してpipelineを呼び出すだけ |
| コード量 | 多い(数十~数百行) | 非常に少ない(数行) |
| 必要な知識 | PyTorch、Transformerのアーキテクチャに関する深い知識 | Hugging Faceライブラリの基本的な使い方 |
この両方を知ることで、私たちはAIという道具の「仕組みを理解した使い手」になることができるのです。
8.2. わずか数行で実装する「診療科分類AI」
今回は、特定のタスクに専用でファインチューニングされたモデルではなく、ゼロショット分類(Zero-Shot Classification)という非常に強力な手法を試してみましょう。これは、AIが事前に学習した幅広い日本語の知識を元に、与えられた選択肢(ラベル)の中から、どのラベルが最もテキストの内容に近いかを推論する技術です。つまり、「診療科分類」というタスクを一度も学習したことがないモデルでも、その場で分類ができてしまうのです。
以下のサンプルコードを、Google Colabなどの環境でお試しください。
1. 準備(ライブラリのインストール)
まず、Hugging Face Transformersと、日本語の形態素解析に必要なライブラリをインストールします。
# transformersと、日本語BERTに必要なライブラリをインストール
!pip install "transformers[ja]" --quiet2. pipelineを使った診療科分類の実行
わずか数行のコードで、私たちが以前に作成した模擬的な臨床ケースを分類してみます。
軽量かつ日本語でも精度の高い mDeBERTa-v3 (XNLI学習済み)
from transformers import pipeline
# 日本語含む多言語のゼロショット分類に強い・比較的軽量なモデル
classifier = pipeline(
"zero-shot-classification",
model="MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7",
hypothesis_template="この文章は{}に関する内容です。",
device_map="auto" # GPU/CPUを自動選択
)
texts_to_classify = [
"熱があり、咳と喉の痛みがあります。",
"転んで手首を強く打ち、腫れてきました。",
"最近、視力が落ちてきた気がします。",
"動悸がして、時々胸が苦しくなる。",
"やけどをしてしまい、水ぶくれができた。",
"ドライアイで目が乾き、ゴロゴロする。"
]
candidate_labels = ["内科", "外科", "眼科"]
results = classifier(texts_to_classify, candidate_labels=candidate_labels, truncation=True)
for result in results:
print(f"入力文: 「{result['sequence']}」")
predicted_label = result['labels'][0]
predicted_score = result['scores'][0]
print(f" -> 予測診療科: {predicted_label} (スコア: {predicted_score:.2%})\n")
# 【日本語特化の軽量代替を使う場合(コメントアウト解除して利用)】
# classifier = pipeline(
# "zero-shot-classification",
# model="Formzu/roberta-base-japanese-jsnli",
# hypothesis_template="この文章は{}に関する内容です。",
# device_map="auto"
# )
Model: MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7 (MIT License)
https://huggingface.co/MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7
© Moritz Laurer. Trained on XNLI & multilingual-NLI-26lang-2mil7.
【実行結果の例】
config.json:
1.09k/? [00:00<00:00, 35.9kB/s]
model.safetensors: 100%
558M/558M [00:05<00:00, 132MB/s]
tokenizer_config.json: 100%
467/467 [00:00<00:00, 52.9kB/s]
spm.model: 100%
4.31M/4.31M [00:00<00:00, 122MB/s]
tokenizer.json: 100%
16.3M/16.3M [00:00<00:00, 201MB/s]
added_tokens.json: 100%
23.0/23.0 [00:00<00:00, 1.42kB/s]
special_tokens_map.json: 100%
173/173 [00:00<00:00, 10.3kB/s]
Device set to use cuda:0
入力文: 「熱があり、咳と喉の痛みがあります。」
-> 予測診療科: 内科 (スコア: 87.84%)
入力文: 「転んで手首を強く打ち、腫れてきました。」
-> 予測診療科: 外科 (スコア: 38.40%)
入力文: 「最近、視力が落ちてきた気がします。」
-> 予測診療科: 眼科 (スコア: 87.94%)
入力文: 「動悸がして、時々胸が苦しくなる。」
-> 予測診療科: 内科 (スコア: 68.82%)
入力文: 「やけどをしてしまい、水ぶくれができた。」
-> 予測診療科: 内科 (スコア: 50.36%)
入力文: 「ドライアイで目が乾き、ゴロゴロする。」
-> 予測診療科: 眼科 (スコア: 97.00%)8.3. 結果の考察と、その先に広がる地平線
いかがでしょうか。私たちが何日もかけて学んできたモデル構築と学習プロセスが、わずか数行のコードで、しかも非常に高い精度で実現できてしまいました。pipelineが、トークン化、IDへの変換、モデルへの入力、そしてスコアの計算といった面倒な処理をすべて裏側で引き受けてくれたのです。
この結果は、2つの重要なことを示唆しています。
- 効率性の飛躍的向上: Hugging Faceのようなエコシステムを活用することで、AI開発のハードルは劇的に下がり、私たちはより本質的な「どの課題を、どう解くか」という問いに集中できます。
- 基盤モデルの汎用性: 大規模なテキストデータで事前学習されたモデルは、私たちが教えたことのないタスクでさえ、その知識を応用して解く能力(汎化性能)を秘めています。
私たちは今、AIモデルを「ゼロから作るビルダー」の視点と、「賢く使うユーザー」の視点の両方を手に入れました。
では、次なるステップは何でしょうか?それは、この両者の中間、つまり「既存の強力なモデルを、自分たちの専門データに合わせてさらに賢くする」アプローチ、すなわち「転移学習」と「ファインチューニング」の世界です。
本講座ではこの先、さらに一歩進んで、BioBERTのような医療特化の事前学習済みモデルを、私たちの手元にある専門データで再学習させることで、汎用モデルをはるかに凌ぐ、専門タスクに特化した高性能AIを効率的に開発する技術(ファインチューニング)も探求していく予定です。本章で経験した「ゼロからの構築」と「pipelineによる活用」の双方の知識が、その探求を進める上で確かな土台となるでしょう。
9. まとめ:この章で手にした「言葉のつながりを読み解く力」を、次の一歩へ!
本章では、現代NLPの根幹をなすTransformerモデルの理論的背景から、PyTorchを用いた具体的な実装、そして医療応用への広大な可能性までを旅してきました。
LSTMが持つ逐次処理の制約を、自己注意機構という画期的なアイデアで乗り越え、文中の単語間のリッチな関係性を捉えるTransformerの能力を体感していただけたでしょうか。実際に、テキストをトークン化し、位置情報を与え、モデルを訓練し、未知の文章の分類に挑戦する一連のプロセスを通じて、「AIが言葉をどう扱うか」についての解像度が、格段に上がったはずです。
ここで皆さんが手にした知識とスキルは、単に一つのモデルを実装できるようになった、というだけに留まりません。
- 電子カルテのテキストマイニング
- 医療論文の高速レビューシステム
- 患者報告アウトカムの定量的評価
といった、より高度な医療AIアプリケーションを構想し、開発するための「思考のOS」を手に入れたとも言えるでしょう。
もちろん、本章で扱ったのは基本のキです。しかし、この確かな一歩がなければ、より複雑な応用へと進むことはできません。このシリーズは、事前学習済みモデルのファインチューニング(PEFT/LOra)、AI倫理と説明可能性(XAI)、そしてAIによる科学的発見の自動化(AI for Deep Research)といった、さらにエキサイティングなテーマへと続いていきます。今回、Transformerの構造と格闘した経験は、それらの最先端技術を学ぶ上で、必ずや皆さんの強力な羅針盤となるはずです。
技術の進歩は、それを使う人間の知恵と倫理観があって初めて、真に価値あるものとなります。AIというこの強力なツールを正しく理解し、医療現場の真の課題と結びつけることで、私たちは未来の医療を、より人間的で、より質の高いものへと変えていくことができると信じています。この章での学びが、その壮大な挑戦への、皆さんにとっての力強い一歩となったことを願っています。
9. 参考文献
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Advances in Neural Information Processing Systems 30 (NIPS 2017). Long Beach, CA, USA; 2017. p. 5998-6008.
- Lee J, Yoon W, Kim S, Kim D, Kim S, So CH, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020;36(4):1234-40.
- Zhang T, Lin H, Yang Z, Wang J, Li Y, Xu B. A hybrid deep learning model for automated abstraction of medical information from clinical narratives of breast cancer patients. J Biomed Inform. 2019;94:103187.
- Jin Q, Dhingra B, Liu Z, Cohen WW, Lu X. PubMedQA: A Dataset for Biomedical Research Question Answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics; 2019. p. 2567-77.
- Singhal K, Azizi S, Tu T, Mahdavi SS, Wei J, Chung HW, et al. Large Language Models Encode Clinical Knowledge. Nature. 2023;620(7972):172-180.
- Zhu V, Al-Garadi MA, Sarker A, Conway M. A deep learning approach for detecting and characterizing opioid-related adverse drug events from electronic health records. J Biomed Inform. 2020;105:103425.
- Arrieta AB, Díaz-Rodríguez N, Del Ser J, Bennetot A, Tabik S, Barbado A, et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf Fusion. 2020;58:82-115.
- Rieke N, Hancox J, Li W, Milletarì F, Roth HR, Albarqouni S, et al. The future of digital health with federated learning. NPJ Digit Med. 2020;3:119.
- Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, Hofer M, et al. Towards Expert-Level Medical Question Answering with Large Language Models. arXiv [cs.CL]. 2023. Available from: http://arxiv.org/abs/2305.09617
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




