

医療現場の膨大なテキストデータ(言葉の宝)をAIで解析する強力な技術、LSTMについて解説します。LSTMは文章の「文脈」を記憶・理解するのが得意で、電子カルテの分析や診断支援など、医療分野で大きな可能性を秘めています。この章では、その仕組みからPyTorchでの実装までを学びます。
単純なAIが苦手な「遠い過去の記憶」を保持できるのが特徴です。「ゲート」と呼ばれる仕組みで、どの情報を記憶し、忘れ、出力するかを賢く制御します。これにより、文章全体の文脈を深く理解することができます。
1. 前処理: テキストをAIがわかる数値(ID)に変換します。
2. モデル構築: PyTorchでEmbedding, LSTM, Linear層を組み合わせます。
3. 学習: データでモデルを訓練し、予測精度を向上させます。
電子カルテから重要情報を抽出したり、医療文献を要約・解析。診断支援や副作用の早期発見に貢献し、医療従事者の負担を軽減して、より質の高い医療の実現を目指します。
図を読み込んでいます…
はじめに
医療の現場って、毎日たくさんの「言葉」が生まれる場所ですよね。電子カルテに綴られる日々の記録、看護師さんが細やかに記すケアの内容、検査結果を伝えるレポート、そして世界中から発信される新しい医学論文。患者さんからの切実な声や、ちょっとしたつぶやきも、そこには含まれているかもしれません。これら一つひとつが、実はものすごく貴重な情報源であり、いわば「宝の山」なんです。
でも、その「宝の山」を十分に活かせているかというと…うーん、なかなか難しいのが現状ではないでしょうか。紙の記録はもちろん、デジタルのテキストデータだって、ただ蓄積されているだけでは、その真価を発揮できません。山積みのテキストデータの中から、本当に必要な情報、例えば「ある治療法が効果的だった患者さんの共通点」や「見逃されがちな副作用の初期兆候」といった貴重な手がかりを見つけ出すのは、まるで広大な図書館で一冊の特定のページを探し出すような、根気のいる作業に感じることもあるかもしれませんね。私自身も、以前は「この大量の記録、もっと効率的に分析できたらどんなにいいだろう…」と何度思ったことか。
そこで、この章では、そんなテキストデータという「言葉の海」を航海するための、非常に強力な羅針盤の一つをご紹介したいと思います。それが、LSTM(Long Short-Term Memory:ロング・ショートターム・メモリー) という技術です。なんだか少し難しそうな名前ですが、これはリカレントニューラルネットワーク(RNN)という、時系列に並んだデータ、例えば文章のように単語が順番に連なったデータを扱うのが得意なAIの一種なんです。
(ちょっとイメージしてみてください)
文章(言葉の列): [単語1] → [単語2] → [単語3] → ... → [単語N]
過去の情報 現在の情報
LSTMは、この単語の列を順番に読み解きながら、
「前にこんな言葉があったから、次はこういう意味合いかな?」
「この言葉は、ずっと前に出てきたあの言葉と関連しているぞ!」
といった、言葉と言葉の間の「つながり」や「文脈」を記憶し、理解するのがとても上手なんです。
まるで、記憶力の良い読書家が、物語の伏線をしっかり覚えていて、
後の展開を予測するのに似ているかもしれませんね。
このLSTMという読書家(AIモデル)に、医療現場で生まれる様々なテキストデータを「読ませて」分析し、そこから有用な知見を引き出す。これが、本章で皆さんと一緒に取り組む「医療自然言語処理(Medical Natural Language Processing, Medical NLP)」の第一歩です。なんだか、これまで見過ごされてきた「言葉の宝」を発掘できるような気がして、少しワクワクしてきませんか?
この章を読み終える頃には、皆さんがご自身の研究テーマや、日々の臨床で「もしかしたら、このテキストデータからAIで何か新しい発見ができるかも!」とか「患者さんのこの言葉のパターン、何かのサインじゃないかな?」といった疑問やアイデアに対して、具体的な分析の一歩を踏み出せるようになることを目指しています。そして願わくば、それが皆さんの研究や臨床を、ほんの少しでも豊かにするお手伝いができれば、と思っています。
「AIとかプログラミングって難しそう…」と感じる方もいらっしゃるかもしれませんが、ご安心ください。このシリーズでは、比較的取り組みやすい「Python」というプログラミング言語と、AI開発の世界で広く使われている「PyTorch(パイトーチ)」というフレームワークを使って、実際に手を動かしながら、一歩一歩進んでいきます。理論だけでなく、実践を通して「なるほど、こうやって動くのか!」という体験を大切にしたいと考えています。
とはいえ、全くのゼロからだと、さすがに少し大変かもしれませんね。この章をよりスムーズに進めていただくために、事前に以下の内容に触れておかれることをお勧めします。
- Pythonの基本的な書き方:本当に最初の最初、変数って何?ループってどう書くの?くらいで大丈夫です。
- PyTorchの基本的な操作:データを「テンソル」という箱に入れて扱う方法や、ニューラルネットワークの骨組みを作る初歩的な部分です。本シリーズで言うと、第7回「PyTorch入門」や第8回「ニューラルネットワークをPyTorchで定義してみよう」あたりが参考になるかと思います。
- RNNの基本的な考え方:LSTMの「ご先祖様」にあたるRNNが、どうやって系列データを扱おうとしているのか、その雰囲気を掴んでおくと、LSTMのありがたみがより一層わかるかもしれません。こちらは、第1章「PyTorchで再帰型ニューラルネット(RNN):医療時系列データ編」や第2章「PyTorchで再帰型ニューラルネット(RNN):医療自然言語処理編」(本章の前に位置する章)で少し詳しくお話ししています。
もし、読み進める中で「あれ?この言葉、どういう意味だったっけ?」とか「この操作、前にも出てきたような…」と感じることがあっても、全く心配いりません。本シリーズは、皆さんが自分のペースで学べるように、関連する章への道しるべを示しながら進んでいきますので、気軽に前の章を覗いたり、少し寄り道したりしながら、じっくりと理解を深めていってくださいね。さあ、準備はよろしいでしょうか?一緒に医療NLPの世界を探検しましょう!
1. LSTMとは何か?(おさらいと自然言語処理における重要性)
さて、いよいよこの章の主役であるLSTM(Long Short-Term Memory)について、その魅力と、特に「言葉」を扱う自然言語処理(NLP)という分野でなぜこんなにも重宝されるのか、その秘密に一緒に迫っていきましょう! もしかしたら、前の章(本シリーズ第3章:PyTorchでLSTM:医療時系列データ編)で、LSTMの少し複雑そうに見える内部構造や、ズラッと並んだ数式に触れて、「おお、なんだかすごい精密機械みたいだな…」と圧倒された方もいらっしゃるかもしれませんね。あの時お話しした、まるで賢い門番のような「ゲート」という巧妙な仕組み、少しでも覚えていらっしゃいますか? 大丈夫、この章でもう一度、今度は「言葉を読み解く」という視点から、そのすごさをじっくりと味わっていきますよ。
このLSTMというスターが登場する背景には、実はその先輩にあたる、比較的シンプルな構造のRNN(Recurrent Neural Network:再帰型ニューラルネットワーク)が抱えていた、ちょっとした悩みの種がありました。RNNも、時系列データ、つまり時間の流れに沿って変化していく情報(例えば、日々のバイタルサインの推移や、心電図の波形、そしてもちろん文章のような単語の連なりなど)を扱うために生まれてきた、とても優秀なモデルなんです。過去の情報を「隠れ状態(hidden state)」という形で記憶し、それを現在の情報とミックスして次の判断に活かす、という「ループ構造」を持っていましたよね。これによって、前の情報が次の情報に影響を与えるような、連続的なパターンを学習しようとします。
ところが、このRNN君、時系列が長くなればなるほど、つまり、ずっと昔の情報を現在の判断材料にしようとすると、ちょっと困ったクセが出てきてしまったんです。それが、本シリーズでも何度か触れている「長期依存性の消失問題 (Vanishing Gradient Problem for Long-Term Dependencies)」です。なんだか呪文のような名前ですが、平たく言えば「遠い過去の重要な記憶が、現在までうまく伝わらない(あるいは、学習の際にその重要性が薄れてしまう)」という、ちょっと残念な現象なんです。
例えば、ある患者さんの非常に長い経過記録をAIに読ませて、最終的な診断の参考にさせたいとします。その記録の最初のページに書かれていた「数ヶ月前に海外渡航歴あり」という一見些細な記述が、実は最後のページに書かれた「珍しい感染症の疑い」という診断を理解する上で、ものすごく重要な手がかりだったとしましょう。でも、単純なRNNだと、この「海外渡航歴」という情報が、ページをめくるように時系列を遡って学習(これを「誤差逆伝播」と言います)される過程で、だんだんその情報の影響力、専門的に言うと「勾配(gradient)」という学習の手がかりが小さくなってしまうんですね。まるで伝言ゲームで、最初の重要な言葉が、最後の人に届く頃にはすっかり別の言葉に変わってしまったり、あるいはほとんど聞き取れなくなってしまったりするのに、少し似ているかもしれません。結果として、単純なRNNは、比較的短いスパンの前後関係しか上手く捉えられない、という傾向があったのです。これでは、医療のように長期的な視点や、過去の些細な情報が後々重要になるような分野では、少し心許ないですよね。
そこで颯爽と現れたのが、我らがヒーロー、LSTM (Long Short-Term Memory) なんです! まさにその名の通り「“長い”期間の記憶も、“短い”期間の記憶も、どっちも上手に対処しますよ!」と宣言しているかのような、頼もしい名前ですよね。このLSTMは、前述の「長期依存性の消失問題」を克服するために、1997年にSepp HochreiterさんとJürgen Schmidhuberさんという、非常に先見の明のある研究者たちによって提案されました(1)。RNNを進化させた、より洗練されたアーキテクチャ(構造)を持っているんです。
では、LSTMがこの難問を一体どんな ingenious(独創的)なアイデアで解決したのでしょうか? その核心は、第3章でも詳しく見てきた、情報の流れをコントロールするための、いくつかの巧妙な「ゲート (Gate)」という名の関所を、神経細胞(ユニット)の内部に設けたことにあります。これらのゲートがオーケストラのように連携し合うことで、LSTMの内部では、「この情報は長期記憶に残しておこう」「あ、この古い情報はもう今の文脈には必要ないから忘れよう」「そして、今の記憶の中から、この情報を取り出して次の判断に使おう」といった、情報の取捨選択を、まるで経験豊富な情報管理者のように、データに基づいて学習しながら判断できるようになったのです。情報の流れを自動で最適化する、ものすごく賢い仕組みが組み込まれている、とイメージしてみてください。
まずは、LSTMユニットの全体像と、その中での情報の流れを、もう一度大まかに掴んでみましょうか。第3章で見た図を少し言葉を補って見てみましょう。
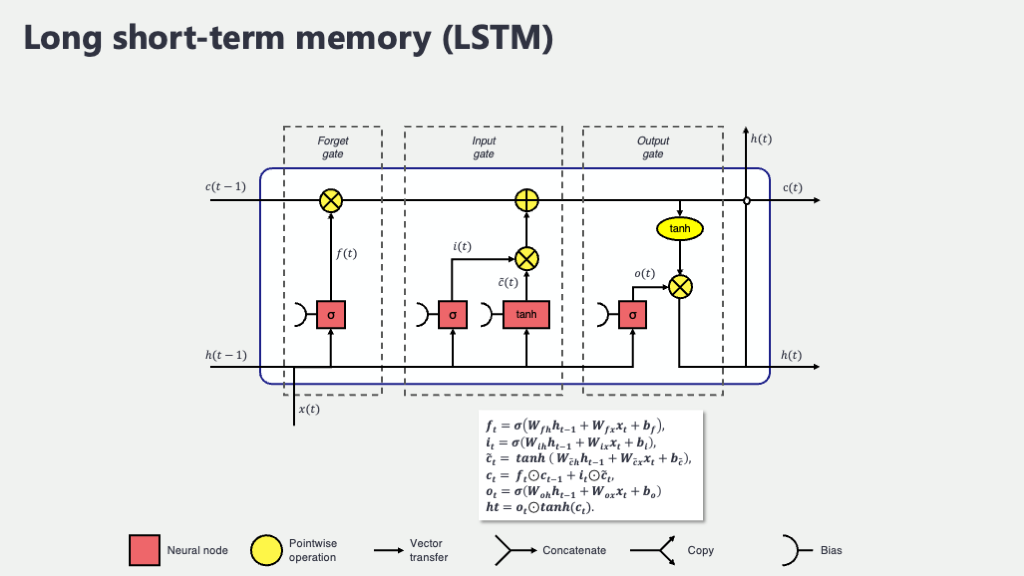
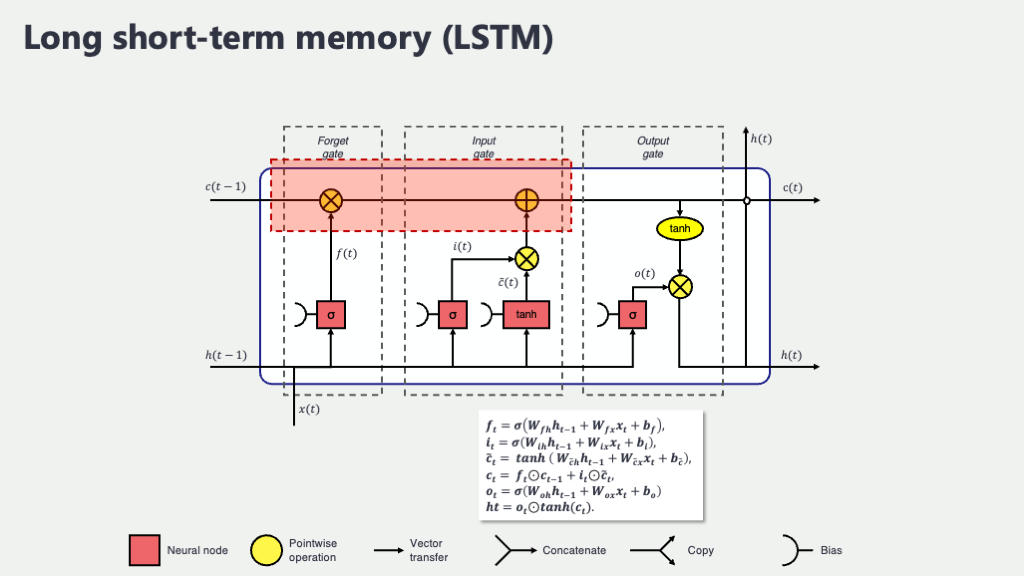
この図は、LSTMユニット一個が、ある時刻 \(t\) でどんな情報を受け取り、どんな情報を次の時刻や出力として渡していくのかを示しています。
- \(x_t\) (エックス・ティー): 時刻 \(t\) における入力データです。例えば、文章を読んでいるなら、その瞬間に処理している単語の情報(通常は単語をベクトル化したもの)がこれにあたります。
- \(C_{t-1}\) (シー・ティーマイナスワン): 一つ前の時刻 \(t-1\) から引き継がれてきた「セル状態 (Cell State)」です。これがLSTMの“長期記憶”の役割を果たす、いわば情報のハイウェイです。このラインのおかげで、重要な情報が比較的薄まらずに長く保持されやすいんです。
- \(h_{t-1}\) (エイチ・ティーマイナスワン): 一つ前の時刻 \(t-1\) の「隠れ状態 (Hidden State)」です。これは“短期的な記憶”であり、また、前の時刻の出力とも考えることができます。
- \(C_t\) (シー・ティー): 現在の時刻 \(t\) で更新された新しいセル状態です。これが次の時刻 \(t+1\) へと引き継がれていきます。
- \(h_t\) (エイチ・ティー): 現在の時刻 \(t\) で計算された新しい隠れ状態です。これが次の時刻 \(t+1\) へ、そして現在の時刻の出力 \(y_t\)(例えば、次の単語の予測や、現在の単語の感情分類など)として使われます。
そして、このLSTMユニットの中で、情報の流れを賢くコントロールしているのが、以下の3つの主要な「ゲート」たちです。それぞれのゲートがどんな役割を果たし、どんな計算をしているのか、数式も交えながら見ていきましょう。数式が出てくると身構えてしまうかもしれませんが、「何と何を使って、何を作ろうとしているのか」という物語として捉えると、少し親しみやすくなるかもしれませんよ。
忘却ゲート (Forget Gate), \(f_t\) : 「何を忘れるか」を決める門番
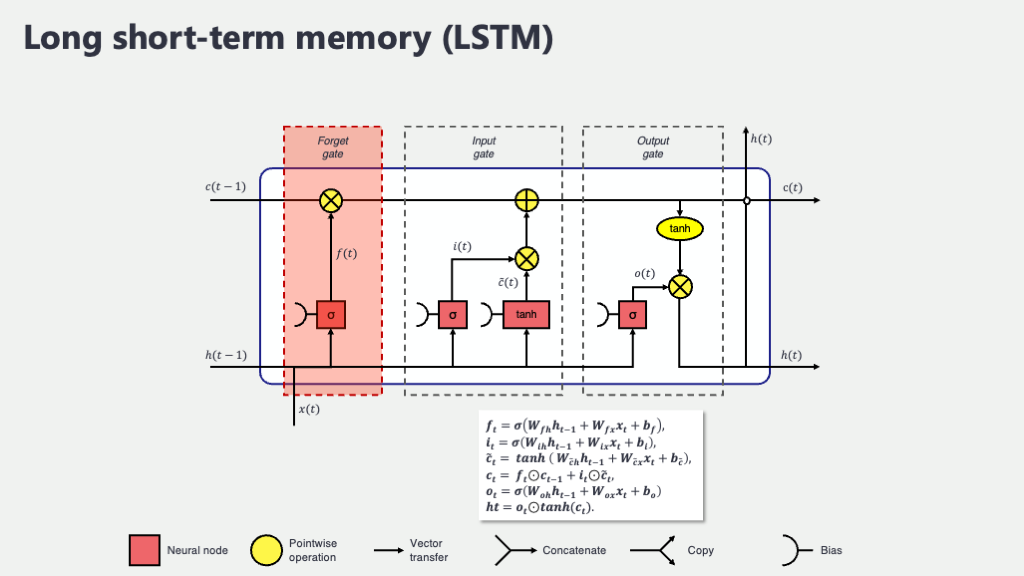
人間も、新しいことを効率よく覚えるためには、時には古い情報を整理したり、重要度の低い情報を忘れたりする必要がありますよね。LSTMの忘却ゲートは、まさにその「何をどの程度忘れるか」を判断する役割を担います。具体的には、「過去の長期記憶(前のセル状態 \(C_{t-1}\))のうち、今の状況(現在の入力 \(x_t\) と少し前の文脈 \(h_{t-1}\))を考えると、どの情報をどの程度薄める(忘れる)べきか」を決定するのです。
この忘却ゲート \(f_t\) の開閉度合いは、次の式で計算されます:
\[ f_t = \sigma(W_f [h_{t-1}, x_t] + b_f) \]
ここで各記号が意味するものは以下の通りです。
- \([h_{t-1}, x_t]\) : これは、前の隠れ状態 \(h_{t-1}\) と現在の入力 \(x_t\) を一つに連結したベクトルです。過去の文脈と現在の情報を両方使って判断するための「判断材料セット」のようなものです。
- \(W_f\) (ダブリュー・エフ) : 忘却ゲートの「重み行列」と呼ばれるもので、学習によって値が決まるパラメータです。この行列が、判断材料セットのどの部分をどれだけ重視して「忘れる度合い」を決めるかのさじ加減を学習します。
- \(b_f\) (ビー・エフ) : 忘却ゲートの「バイアス項」で、これも学習パラメータです。出力の微調整を行います。
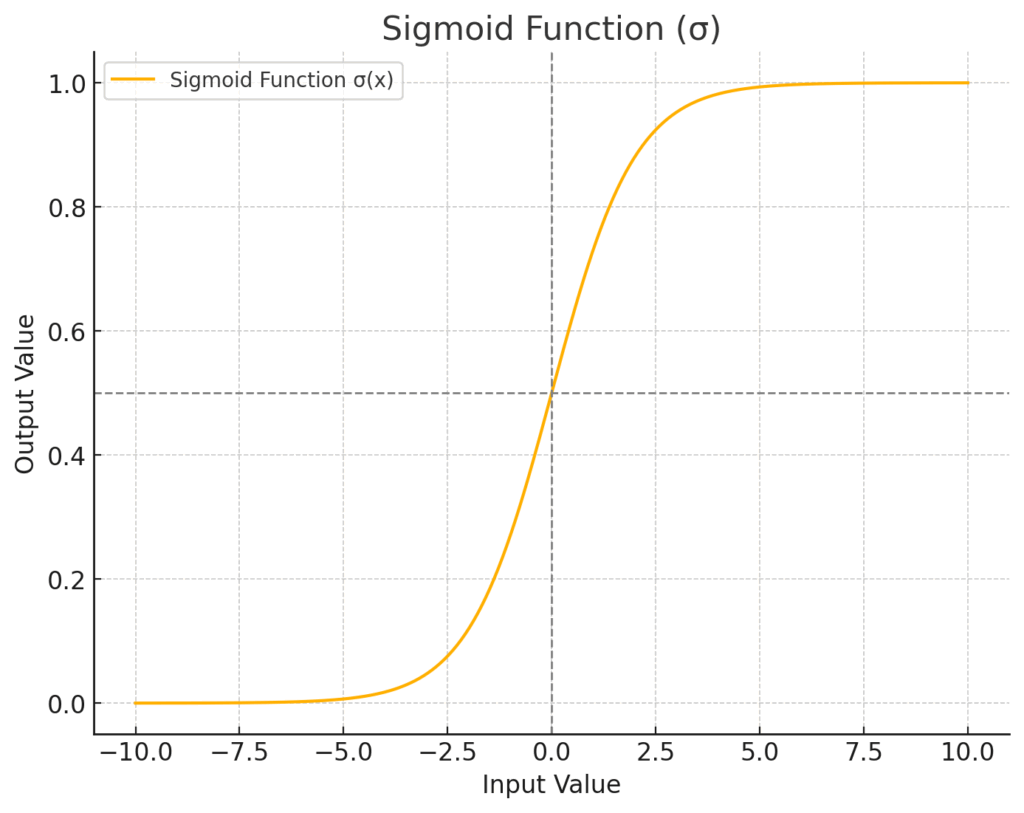
- \(\sigma\) (シグマ) : これは「シグモイド関数」という、S字カーブを描く関数です。どんな入力値も、必ず0から1の間の値に変換してくれます。この出力値が、忘却ゲートの「開閉度合い」そのものを表します。値が0に近ければ「ゲートを固く閉じて、その情報を完全に忘れる」、1に近ければ「ゲートを全開にして、その情報を完全に記憶し続ける(全く忘れない)」という意味になります。そして、0.5なら「半分くらい忘れる」といった具合です。この「0か1か」のスイッチのような性質(実際には0から1の連続値ですが)が、ゲート処理にピッタリなんですね。
ちょっと行列計算のイメージも見てみましょうか。例えば、\([h_{t-1}, x_t]\) という判断材料セット(ベクトルの形をしています)に、重み行列 \(W_f\) を掛けるというのは、こんな感じです。
入力ベクトル [h_{t-1}, x_t] 重み行列 W_f (忘却ゲート用)
( (dim_h + dim_x) × 1 ) ( dim_c × (dim_h + dim_x) ) ※dim_cはセル状態の次元数
┌───────┐ ┌─┬─┬─────┬─┐
│ h_val1│ │w w ... w w│
│ h_val2│ ├─┼─┼─────┼─┤
│ ... │ 行列積 (掛ける) │w w ... w w│
│ x_val1│ ─────────────────→ ├─┼─┼─────┼─┤
│ x_val2│ │: : ... : :│
│ ... │ ├─┼─┼─────┼─┤
└───────┘ └─┴─┴─────┴─┘
↓
変換後のベクトル (dim_c × 1)
↓ + バイアス b_f
↓ シグモイド関数 σ
忘却ゲート出力 f_t (dim_c × 1) ← 各要素が0~1
この \(f_t\) のベクトルが、後で古いセル状態 \(C_{t-1}\) の各要素に掛け合わされることで、「選択的忘却」が実現されるわけです。
入力ゲート (Input Gate), \(i_t\) と 新しい記憶の候補 \(\tilde{C}_t\) : 「何を新しく覚えるか」を決める賢いコンビ
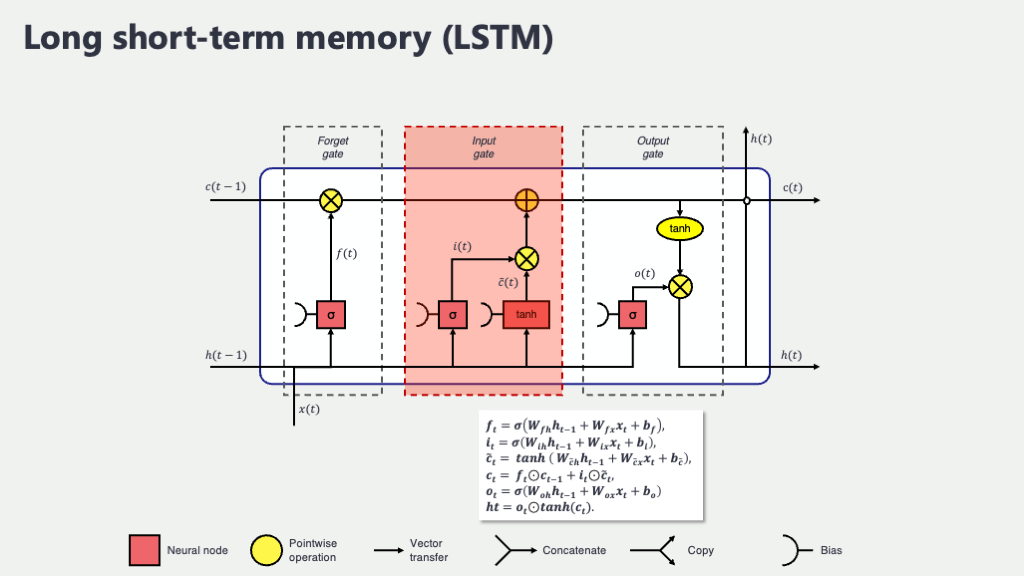
さて、忘却ゲートで過去の記憶の整理整頓が一段落したら、次はいよいよ新しい情報を私たちの記憶のメインストリートである「セル状態」に迎え入れる番です。でも、どんな情報でもウェルカム!というわけにはいきませんよね。本当に必要な情報だけを選び出し、適切な形で記憶に追加したいものです。この重要な役割を担うのが、「入力ゲート (\(i_t\))」と「新しい記憶の候補 (\(\tilde{C}_t\))」という、まさに二人三脚で働く賢いコンビなんです。
彼らは、「現在の入力 \(x_t\)(今まさに読んでいる単語など)」と「少し前の文脈(前の隠れ状態 \(h_{t-1}\))」をじっくりと吟味して、「この新しい情報の中から、どの部分を、どんな形で、そしてどれくらいの強さで、長期記憶(セル状態)に書き加えるべきか」を判断します。この判断プロセスは、大きく分けて2つの巧妙なステップで進められるんですよ。
ステップ1:どの情報を「通す」か? スイッチ役の入力ゲート \(i_t\) (シグモイド関数)
まず登場するのが、入力ゲート \(i_t\) です。このゲートの役割は、新しい情報(具体的には、後述する\(\tilde{C}_t\)が運んでくる情報)のうち、「どの情報を実際にセル状態に書き込むか」その“許可度合い”を決めることです。まるで、記憶の扉を開けるための「調光スイッチ」や「フィルター」のようなものだと考えてみてください。光をたくさん通すか(情報を強く記憶するか)、少しだけ通すか(情報を弱く記憶するか)、あるいは全く通さないか(情報を無視するか)を、0から1の間の数値で細かく調整するんです。
この「許可度合い」を計算するために使われるのが、おなじみの「シグモイド関数 (\(\sigma\))」です。忘却ゲートでも活躍していましたね。思い出していただきたいのですが、シグモイド関数は、どんな入力値がきても、その出力値を必ず0と1の間にギュッと押し込めるS字カーブの関数でした。
この性質が、「ゲート」の開閉具合を表現するのにピッタリなんです。入力ゲート \(i_t\) の計算式は以下のようになります。
\[ i_t = \sigma(W_i [h_{t-1}, x_t] + b_i) \]
ここで、\(W_i\) と \(b_i\) は、入力ゲート専用の「学習可能な重み行列とバイアス項」です。これらが、過去の文脈 \([h_{t-1}, x_t]\) をどう解釈すれば、最適な「許可度合い」\(i_t\)(0~1の間の値を持つベクトル)が得られるかを、学習を通じて賢く調整していきます。例えば、ある単語の情報がすごく重要だと判断されれば、\(i_t\) の対応する要素の値は1に近くなり、「この情報は記憶にしっかり通せ!」という指令が出るわけです。
ステップ2:どんな情報を「加える」か? 内容担当の新しい記憶候補 \(\tilde{C}_t\) (tanh関数)
入力ゲート \(i_t\) が「どれだけ通すか」のスイッチの役割を果たしたのに対し、次に登場する \(\tilde{C}_t\) (「シーチルダ・ティー」とか「シーティルダ・ティー」と読みます) は、「じゃあ、実際にどんな“内容”の情報をセル状態に追加するの?」という、記憶の「中身そのもの」を作り出す役割を担います。いわば、記憶の候補生ですね。
この \(\tilde{C}_t\) を生成する際には、シグモイド関数ではなく、もう一つのS字カーブの関数、「ハイパボリックタンジェント関数 (\(\tanh\))」が使われます。このtanh関数、シグモイド関数と形は似ているんですが、出力値が0から1ではなく、-1から1の間に収まるという大きな違いがあります。
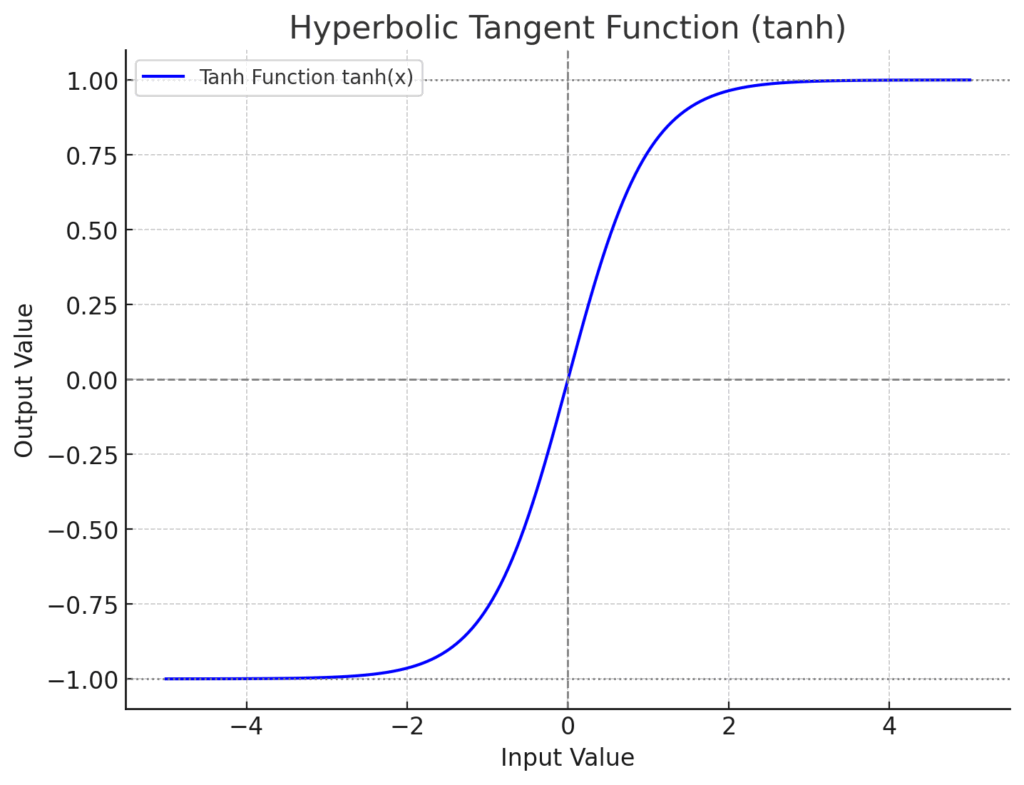
この-1から1という出力範囲がミソでして、これによって、新しく生成される情報に、単に「ある/ない」や「強い/弱い」だけでなく、プラス方向やマイナス方向といった「情報の方向性」や「意味合いの極性」を持たせることができるようになるんです。例えば、「この単語は記憶に対して『非常に肯定的な影響』を与えるべきだ(例: 値が+0.9に近い)」とか、「この単語は『やや否定的なニュアンス』を記憶に反映させるべきだ(例: 値が-0.3に近い)」といった、より豊かな情報表現が可能になります。新しい記憶の候補 \(\tilde{C}_t\) の計算式は以下の通りです。
\[ \tilde{C}_t = \tanh(W_C [h_{t-1}, x_t] + b_C) \]
こちらも同様に、\(W_C\) と \(b_C\) は、この新しい記憶候補を生成するために学習される専用の重み行列とバイアス項です。「過去の文脈と現在の入力から判断して、こんな感じの新しい情報を記憶の候補として提案してみるけど、どうかな?」といったニュアンスですね。
なぜシグモイドとtanhを使い分けるの? それがLSTMの賢さの秘訣!
ここで、「あれ? なんで入力ゲート\(i_t\)はシグモイドで、記憶候補\(\tilde{C}_t\)はtanhなの? どっちもS字カーブなら、どっちか一つで良くない?」なんて疑問が湧いてくるかもしれません。とっても良い疑問ですね! 実は、この2つの関数を巧みに使い分けることこそが、LSTMが情報を柔軟にコントロールできる秘訣の一つなんです。
もう一度整理すると、
- 入力ゲート \(i_t\) (シグモイド関数, 出力 0~1) は、「情報の取捨選択の“度合い”」を決める係数、つまり「どれだけ重要か」「どれだけ通すか」というゲートの開閉バルブの役割。
- 新しい記憶の候補 \(\tilde{C}_t\) (tanh関数, 出力 -1~1) は、「実際に記憶される可能性のある“情報の内容そのもの”」であり、その情報の方向性や強弱を表現する役割。
この2つが組み合わさることで、LSTMは非常に表現力豊かに新しい情報を処理できるのです。例えば、水道の蛇口に例えてみましょうか。
図を読み込んでいます…
入力ゲート \(i_t\) が「蛇口のひねり具合」(0%〜100%開栓)を決めるのに対し、新しい記憶候補 \(\tilde{C}_t\) は「どんな種類の水が、どれくらいの温度で出てくるか」(例えば、-1がすごく冷たい水、+1がすごく熱いお湯、0が無味無臭の常温水、といった具合)を決める、というイメージです。いくら記憶候補 \(\tilde{C}_t\) が「ものすごく重要な情報だ!(例えば+1に近い値)」と主張しても、入力ゲート \(i_t\) が「いや、今はその情報はほとんど必要ないよ(0に近い値)」と蛇口を絞ってしまえば、セル状態にはほとんど影響を与えません。逆に、平凡な情報(\(\tilde{C}_t\) が0に近い値)でも、入力ゲート \(i_t\) が「これは絶対に通すべき!(1に近い値)」と判断すれば、その情報は(ほぼそのままの形で)セル状態に加わることになります。
このように、シグモイド関数で「通すか通さないか、通すならどの程度か」というON/OFFスイッチ的・割合的な制御を行い、tanh関数で「通す情報の内容自体に方向性や強弱を付ける」という役割分担をすることで、LSTMは非常に柔軟かつ効果的に、新しい情報を既存の記憶(セル状態)へと統合していくことができるのです。いやはや、本当に巧みな設計ですよね!
まとめると、入力ゲート \(i_t\) は「どの新しい情報をどれだけ真剣に受け止めるか(あるいはスルーするか)の選択の度合い」、そして新しい記憶の候補 \(\tilde{C}_t\) は「受け止めるとしたら、それはどんな性質の情報なのか」をそれぞれ決定し、この二つの情報を掛け合わせる(次のセル状態更新のステップで \(i_t \odot \tilde{C}_t\) として出てきます)ことで、セル状態に加えるべき新しい情報が賢く作り出される、というわけです。このコンビネーションプレーがあるからこそ、LSTMは複雑な文脈の中から本当に必要な情報だけを選び出して記憶に留めることができるんですね。この仕組みを初めて知ったとき、私は「なるほど、だからLSTMは賢いのか!」と、なんだか腑に落ちたのを覚えています。
セル状態の更新 (Cell State Update), \(C_t\) : 過去と現在の記憶の融合、そして長期記憶の形成
さあ、門番たちの準備が整いました! 忘却ゲート \(f_t\) で「何を忘れるか」が決まり、入力ゲート \(i_t\) と新しい記憶候補 \(\tilde{C}_t\) で「何を新しく覚えるか」とその内容が決まりました。いよいよ、これらを使って、前の時刻のセル状態 \(C_{t-1}\) から現在の時刻の新しいセル状態 \(C_t\) を計算します。この計算式こそ、LSTMの記憶更新メカニズムの心臓部と言えるでしょう!
\[ C_t = (f_t \odot C_{t-1}) + (i_t \odot \tilde{C}_t) \]
ここで、\(\odot\) (マルの中に点が入った記号) は、「要素ごとの積(アダマール積)」を表します。これは、同じサイズのベクトルや行列の、同じ位置にある要素同士をそれぞれ掛け算するという、ちょっと特殊な掛け算です。行列全体の掛け算(行列積)とは違うので、少し注意してくださいね。(第4回の線形代数の基本を思い出してみましょう!)
この式が何をやっているか、じっくり見てみましょう。
- 最初の項 \((f_t \odot C_{t-1})\) : 「過去の記憶の整理」です。前のセル状態 \(C_{t-1}\) の各要素に、忘却ゲート \(f_t\) の出力(0~1の値)を要素ごとに掛け合わせています。これにより、\(f_t\) の値が0に近い要素の情報は弱められ(忘れられ)、1に近い要素の情報はそのまま保持されます。まさに「選択的忘却」ですね。
- 次の項 \((i_t \odot \tilde{C}_t)\) : 「新しい情報の取り込み」です。新しい記憶の候補 \(\tilde{C}_t\) の各要素に、入力ゲート \(i_t\) の出力(0~1の値)を要素ごとに掛け合わせています。これにより、\(i_t\) の値が1に近い要素の情報が選択的に採用され、0に近い要素の情報は無視されます。これが「選択的記憶」です。
そして、この2つの結果を「足し合わせる」ことで、新しいセル状態 \(C_t\) が完成します! 古い記憶の一部を保持しつつ(忘れるべきは賢く忘れ)、新しい情報を吟味して追加する。なんだか、私たち人間がノートを取ったり、記憶を整理したりするプロセスにも少し似ているような気がしませんか? このエレガントなプロセスのおかげで、重要な情報は長く保持され、不要な情報は流れていく、というダイナミックで柔軟な記憶の更新が可能になるのです。
出力ゲート (Output Gate), \(o_t\) と 隠れ状態の出力 (Hidden State Output), \(h_t\) : 「何を出力するか」を決め、短期記憶を形成
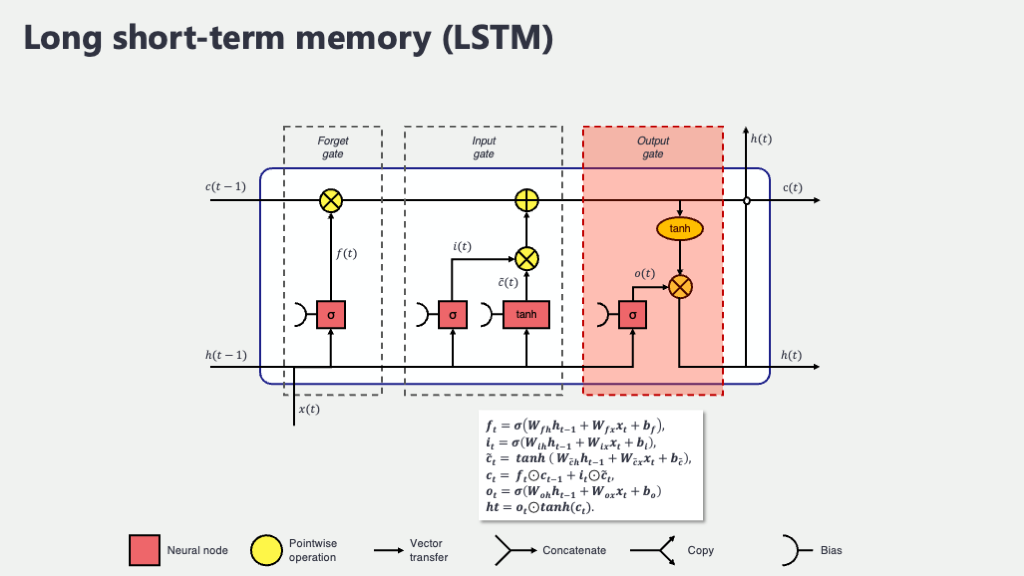
長期記憶であるセル状態 \(C_t\) が無事に最新版にアップデートされました。しかし、この豊富な長期記憶の中から、現在の時刻 \(t\) で「実際に何を出力として使うか」あるいは「もしこのLSTMユニットの上にさらに別の層があるなら、その層にどんな情報を渡すか」を決めなければなりません。いくら素晴らしい情報がセル状態という名のデータベースに蓄えられていても、その時々で適切な情報を取り出して活用できなければ、宝の持ち腐れになってしまいますよね。その最終的な情報取り出しの役割を担うのが、出力ゲート \(o_t\) です。
出力ゲート \(o_t\) も、これまでのゲートと同様に、前の隠れ状態 \(h_{t-1}\) と現在の入力 \(x_t\) を材料にして、どの情報をどの程度出力するかの「許可度合い」をシグモイド関数 \(\sigma\) で計算します。
\[ o_t = \sigma(W_o [h_{t-1}, x_t] + b_o) \]
ここで、\(W_o\) と \(b_o\) は出力ゲート専用の学習パラメータです。
そして、この出力ゲート \(o_t\) の値(0~1のスイッチ)と、現在のセル状態 \(C_t\) を一度 \(\tanh\) 関数で処理したもの(値を-1から1の範囲にギュッと押し込めて、使いやすい形に整えるイメージです)を、再び要素ごとに掛け合わせる(\(\odot\))ことで、最終的な現在の時刻の隠れ状態 \(h_t\) が決まります。この \(h_t\) が、単純なRNNで言うところの「短期的な記憶」であり、また、このLSTMユニットの(あるいは層全体の)最終出力や、もしLSTM層が複数積み重なっている場合は次のLSTM層への入力となるわけです。
\[ h_t = o_t \odot \tanh(C_t) \]
ここがミソなのですが、セル状態 \(C_t\) の情報をそのまま出すのではなく、一度 \(\tanh\) で値を整え、さらに出力ゲート \(o_t\) で「どの情報を表に出すか」をフィルタリングする、という一手間を加えているのがポイントです。これにより、長期記憶の中から、現在の文脈において本当に必要な情報だけを選択的に、かつ適切な形で取り出すことができるようになるわけですね。
ここまでのまとめ
ふぅ…ちょっと数式とゲートの話でお腹いっぱいになってしまったでしょうか? 大丈夫です、全部の数式を一度に完璧に暗記する必要は全くありません。ここで一番大切なのは、「セル状態」という長期記憶を運ぶメインストリートがあって、そこに「忘却ゲート」「入力ゲート」「出力ゲート」という3つの非常に賢い「門番」たちがいて、それぞれの判断(0から1の間の開閉度合いや、-1から1の間の情報候補)に基づいて、情報の流れをきめ細かく、ダイナミックにコントロールしているんだな、という大きなイメージを掴むことです。そして、これらのゲートは、それぞれがシグモイド関数やハイパボリックタンジェント関数といった活性化関数と、学習によって賢くなっていく重み \(W\) やバイアス \(b\) を持った、いわば小さな判断ユニット(小さなニューラルネットワークのようなもの)だと考えると、少しはスッキリするかもしれませんね。
この一見すると複雑に見えるかもしれない洗練されたゲート機構こそが、LSTMが単純なRNNの「長期依存性の消失」という大きな壁を打ち破り、時系列データ(特に長い系列!)の中に潜む「遠く離れた場所にあるけど実は重要な関連性」を効果的に学習できるようになった秘密なのです。まさに、この能力のおかげで、LSTMは特に、単語が順番に並んで初めて意味を成す「文章」のような系列データの解析、すなわち自然言語処理(NLP)の分野で、革命的な成果を次々と叩き出してきたのです。
言葉って、本当に不思議ですよね。単語がただランダムに集まっているだけでは、何も伝わりません。その「順番」、文中での「位置」、そして前後の単語との「関係性」によって、意味がガラッと変わってきます。例えば、「この薬は効果があった」という文と、「この薬は効果があったが、副作用も強かった」という文では、後半の文脈によって前半の意味合いの評価も変わってくることがあります。LSTMは、そのゲート機構を駆使して、こうした言葉の「行間」や、文全体を流れる「文脈」を、まるで熟練の読者のように丹念に読み解くのが非常に得意なんです。
そして、このコースのテーマである「医療文書」のことを考えてみてください。電子カルテに記された日々の経過、患者さんがポツリと語る症状の変化、検査レポートに書かれた専門的な所見…。そこには、単なる事実の羅列だけでなく、時間的な繋がりや、その言葉が発せられた背景、微妙なニュアンスといった、いわゆる「文脈」がぎっしりと詰まっています。LSTMが持つ、この「長期的な情報を記憶する力」と「必要な情報を的確に取捨選択する能力」は、まさにそうした医療特有の、時に複雑で、時に機微に富んだ情報を的確に捉え、深く理解するのに、うってつけの技術だと言えるでしょう。だからこそ、医療NLPという、言葉を通じて医療に貢献しようとする分野で、LSTMがこれほどまでに重要な役割を担い、私たちの期待を集めているんですね。いやはや、本当にエレガントでパワフルな仕組みだなと、改めて感じます。
2. 医療自然言語処理におけるLSTMの応用例
さて、前のセクションでLSTMがどうしてそんなに賢く言葉の文脈を読み解けるのか、その秘密の一端に触れていただきました。まるで高性能な読解アシスタントを手に入れたような気分になりませんか? では、この頼もしい相棒、LSTMを実際の医療という、日々たくさんの「言葉」が飛び交う世界に連れて行ったら、一体どんな素敵なこと、あるいは今まで難しかったことができるようになるのでしょう? ちょっと想像するだけでワクワクしてきますよね。実は、もう既に世界中の多くの研究者や開発者の方々が、このLSTM(や、その進化版にあたる他の深層学習モデルたち)を使って、私たちが医療現場で日々直面している様々な課題に、新しい光を当てようと奮闘しているんです。ここでは、その中でも特に「なるほど、そんな使い方があったのか!」とか「それは是非、実現してほしい!」と思っていただけそうな代表的な応用例をいくつか、一緒に覗いてみることにしましょう。もしかしたら、この中に「あ、これって、私が普段の研究や業務で悩んでいる、あの問題にも応用できるんじゃないかな?」なんて、素敵なひらめきが舞い降りてくるかもしれませんよ。
- 電子カルテからの情報抽出(Mining from Electronic Health Records): 電子カルテって、今や医療の現場に無くてはならない、まさに中核をなす情報システムですよね。毎日、膨大な量の情報がそこに記録されていきます。その中でも特に、医師や看護師の方々が日々の診療やケアの中で、自由な言葉で書き綴る「自由記述」の部分。ここには、数値データだけでは決して表現しきれない、患者さんの状態に関する詳細な情報、診断に至るまでの思考プロセス、治療効果の微妙なニュアンスといった、まさに「情報の宝」が眠っているんです。でも、その宝を十分に活かせているかというと…うーん、なかなか難しいのが現状ではないでしょうか。「あの患者さんのアレルギー情報、確かにどこかに書いたはずだけど、どの記録だっけ…?」とか、「似たような症状で、過去にこの治療が効いた患者さんをリストアップしたいんだけど、どうやって検索すれば…」なんて、カルテのページをめくりながら、あるいは検索窓にどんなキーワードを入れようか悩みながら、貴重な時間を使った経験、きっと少なからずおありだと思います。 LSTMのような自然言語処理(NLP)技術は、この「眠れる情報の巨人」を優しく揺り起こし、私たちが必要とする情報を、まるで経験豊富な医療秘書やリサーチャーのように、的確かつ迅速に見つけ出してくれる可能性を秘めているんです(2)。例えば、ある患者さんの膨大な診療記録の中から、「主要な症状はこれとこれ」「過去にこの薬剤でこのような副作用が出現したことがある」「ご家族にこういう病歴の方がいる」といった、診断や治療計画を立てる上でクリティカル(決定的)なキーポイントを、AIが自動的にピックアップして、構造化されたデータとして整理してくれる。そんな未来を想像してみてください。これが当たり前の技術になれば、例えば「特定の遺伝子変異があり、かつ、この特徴的な症状を訴えている患者さんを、過去10年間の記録から全てリストアップして」といった、これまで非常に手間のかかった複雑な情報検索も、瞬時に行えるようになるかもしれません。日々の診療記録が、そのまま質の高い臨床研究のデータベースへと姿を変えることだって夢ではないでしょう。何よりも、私たちが「情報を探す」という作業に費やしていた時間から解放されて、その分もっと患者さんと向き合ったり、より深い医学的考察に時間を使えたりするようになるかもしれない、と考えると、ちょっと未来が明るく、そして楽しみになってきませんか?
- 医療文献の解析(Analyzing Medical Literature): 医療の世界は、まさに日進月歩。昨日まで標準とされていた治療法が、新しいエビデンスの登場によって今日にはもう過去のものになっている、なんてことも珍しくありません。だからこそ、医療に携わる私たちは、常に最新の医学知識をアップデートし続けることが求められるわけですが…正直なところ、世界中から毎日、それこそ洪水のように押し寄せてくる新しい医学論文の波に、どうやってキャッチアップしていけばいいんだ!と、時々途方に暮れてしまうこともありますよね。私自身、週末に「よし、今週こそは!」と意気込んで積み上げた論文の束を前にして、そっと目を閉じてしまった経験が何度か…(苦笑)。 でも、もしLSTMが、この広大な医学情報の海を航海するための、超優秀なナビゲーターになってくれたとしたら、どうでしょう? 例えば、PubMedや医学中央雑誌のような膨大な医学文献データベースの中から、今まさに自分が関心を持っている特定の疾患の最新治療法や、あるいは目の前の患者さんが抱える稀な病態に関連する重要な論文を、AIが賢くスクリーニングして推薦してくれたり。さらには、長い英語の論文の要点を、重要なポイントを外さずにギュギュッと数段落にまとめて、「先生、まずはこちらの要約から目を通してみてはいかがですか?」と提示してくれたりする(3)。そんな技術が実現すれば、私たちが最新の知見にアクセスする効率は劇的に向上し、その結果、より質の高い研究活動や、根拠に基づいた的確な臨床判断へと繋がっていくはずです。情報収集という、時に骨の折れる作業から解放されれば、その分、新しいアイデアを練ったり、同僚と議論を深めたりする、より創造的な時間に頭を使うことができるようになるかもしれませんね。
- 問診記録・患者報告の分析(Interpreting Consultations and Patient Reports): 診察室で交わされる、患者さんと医療者の間の何気ない会話。あるいは、患者さんが一生懸命に記入してくださる問診票やアンケート、最近ではスマートフォンアプリなどを通じて日々記録される体調の報告。こういったテキストデータには、血液検査の数値や画像診断の結果だけでは決して捉えきれない、その人ならではの「物語」や「生きた情報」が、ぎっしりと詰まっていると私は常々感じています。「最近、なんだか食欲がなくて、以前は大好きだった料理も喉を通らないんです…」「夜、ちょっとした物音でも目が覚めてしまって、熟睡できた感じがしない日が続いていて…」。こうした一つ一つの言葉の裏には、ご本人の生活の質(QOL:Quality of Life)に深く関わる重要なヒントや、もしかすると、まだ表面化していない病気の、本当にごく初期のサインが隠されているかもしれません。 LSTMは、こうした患者さんの「生の声」に含まれる言葉の選び方、表現のニュアンス、感情のトーン、症状の出現パターンなどを繊細に読み解くことで、これまで医療者が見過ごしてしまっていたかもしれない、あるいは気づくのに時間がかかっていたかもしれない、微妙な変化の兆候を捉えるお手伝いができる可能性があります。例えば、うつ病の本当に初期の段階で見られる特有の言語表現の変化(使用する単語の種類が減る、否定的な言葉が増えるなど)を客観的に検知したり、あるいは慢性疾患を抱える患者さんが日々記録するちょっとした体調の変化(「今日はいつもより少し息苦しい気がする」「足のむくみが昨日より強いみたい」など)から、心不全の増悪といった合併症の兆候を早期にアラートしたり…。まるで、患者さんの言葉に、より深く、より共感的に耳を傾けるための、新しい高性能な「聴診器」のような役割を果たしてくれるかもしれない、そんな大きな期待が寄せられています。
- 臨床試験における有害事象報告の解析(Detecting Adverse Events in Clinical Trials): 新しいお薬や画期的な治療法が、厳しい審査を経て、私たちのもとに実際に届けられるまでには、本当に長い長い道のりと、多くの方々の並々ならぬ努力、そして厳格な科学的検証がありますよね。そのプロセスの中でも特に重要なのが、開発中の薬や治療法の「有効性(どれだけ効くのか)」と「安全性(危険はないのか)」を、実際の患者さんの協力を得て慎重に評価する「臨床試験」です。この臨床試験の過程では、時に予期せぬ身体の変化や好ましくない症状、専門用語で言うところの「有害事象(Adverse Event)」と呼ばれるものが報告されることがあります。これらの報告は、いつ、誰に、どのような状況で、何が起こったのか、といった詳細な情報が、自由記述のテキスト形式で記録されることも多く、その一件一件を丹念に分析し、評価することが、医薬品や治療法の安全性を確立し、向上させる上で欠かせない作業となります。 ここにLSTMのようなNLP技術の力を借りることで、例えば、国内外から集められる膨大な数の有害事象報告の中から、これまで個々の報告だけでは見過ごされていたかもしれない稀な副作用のパターンや、あるいは特定の背景を持つ患者さん(例えば、高齢の方、複数の薬剤を併用している方、特定の遺伝的素因を持つ方など)において、特に注意が必要となるかもしれないリスクの組み合わせや傾向などを、統計的な根拠を持って、より早期に、より網羅的に見つけ出す試みが進められています(4)。こうした地道で緻密な分析の積み重ねが、未来の医療をより安全で、より信頼できるものへと進化させていく、大切な礎になるのだと私は考えています。
- 診断支援(Assisting Medical Diagnosis): 「AIが人間の医師に取って代わって診断する時代が来るの?」なんて、少しセンセーショナルな話を耳にすることもあるかもしれませんが、少なくとも現時点でのAI研究の主な方向性は、少し違うところにあります。むしろ、日々膨大な情報と向き合い、複雑な判断を迫られる人間の医師にとっての「頼れる相談相手」や、「多忙な中での見落としを防ぐための注意力鋭いセカンドオピニオン」として、AIが活躍する未来の方が、より現実的で、そして望ましい姿かもしれませんね。例えば、患者さんの訴える様々な症状、これまでの詳しい病歴、山のような検査結果のテキスト情報などをLSTMに入力すると、「先生、この症状の組み合わせと経過を考慮しますと、Aという疾患の可能性が最も高いと考えられますが、鑑別診断としてBやCといった比較的稀な疾患の可能性も、文献的には報告されています。関連する最新の論文はこちらです」といった形で、診断のヒントや考慮すべき情報、参照すべきエビデンスなどを、客観的かつ網羅的に提示してくれるようなシステムが研究されています(5)。 特に、非常に多くの疾患が鑑別に挙がるような複雑なケースや、教科書的には稀とされる疾患、あるいは症状が非典型的で診断に迷うような場合などでは、人間の医師が限られた時間の中で全ての可能性を瞬時に想起し、評価するのは本当に大変なことです。そんな時、AIが客観的なデータと学習されたパターンに基づいて、「こんな視点もありますよ」「この可能性も忘れていませんか?」と別の角度からの光を当ててくれることは、診断の精度を向上させ、あるいは診断に至るまでの時間を短縮する上で、大きな助けになるかもしれません。もちろん、最終的な診断を下し、その責任を負うのは、常に人間の医師であるべきです。しかし、AIとの賢い連携、いわば「人間とAIの協奏」が、より良い医療、より迅速で正確な診断への確かな近道になるかもしれない、そんな期待が、この分野の研究を力強く後押ししています。
さて、ここまでいくつかの具体的な応用例を駆け足で見てきましたが、いかがでしたでしょうか? これらは、LSTMという名の、まるで言葉を理解する魔法の杖のようなツールが、医療という、どこまでも深く、そしてどこまでも「言葉」に満ちた世界で、一体どんな驚くべき奇跡(あるいは、地道な改善)を起こしうるのか、そのほんの入り口の景色を示したに過ぎません。まるで、これまで分厚い霧に覆われていた広大な未開の地が、少しずつその霧が晴れて、豊かな可能性に満ちた大地が姿を現し始めたような、そんなワクワクとした興奮を感じていただけたなら、これほど嬉しいことはありません。
次章からは、実際にPyTorchでLSTMを実装していき、より深く学んでいきましょう!
3. PyTorchでLSTMを実装する準備
さて、前のセクションではLSTMが医療の言葉の世界でどんな活躍を見せてくれそうか、そのワクワクするような可能性の一端を覗いてみました。理論や応用例を知ると、「じゃあ、実際に自分でも動かしてみたい!」という気持ちがむくむくと湧いてきますよね。ここからは、いよいよその第一歩! PyTorchという強力なツールを使って、実際にLSTMモデルを私たちの手で組み立てていくための準備を始めましょう。料理で言えば、まずは最高の食材と調理器具を揃えるところからですね。
3.1. 必要なライブラリのインポート
プログラミングの世界では、何か新しいことを始めようとするとき、多くの場合、先人たちが作ってくれた便利な「道具箱(ライブラリ)」を借りてくるところからスタートします。これによって、複雑な処理も数行のコードで実現できたりするんですよ。今回、私たちがLSTMモデルを作って動かすためにも、いくつか頼りになるライブラリをPythonのプログラムに「こんにちは、これからお世話になります!」と呼び出す(インポートする)必要があります。
具体的には、AIモデル構築の心強い味方である「PyTorch」関連のライブラリたち、そして今回は日本語のテキストを扱うので、日本語を単語単位に上手に区切ってくれる「Janome(じゃのめ)」という形態素解析ライブラリを使ってみようと思います。JanomeはPythonだけで動くので、導入が比較的簡単なのが嬉しいポイントですね。では、早速コードを見てみましょう。
# --- ライブラリの準備体操をしましょう! ---
# まずはPyTorch関連の仲間たちを呼び出します
import torch # PyTorchの本体。多次元配列「テンソル」を扱ったり、GPUで高速計算したりする土台です。
import torch.nn as nn # ニューラルネットワークの部品(層、活性化関数など)が詰まったモジュール。nnはNeural Networkの略ですね。
import torch.optim as optim # モデルの学習を上手に行うための最適化アルゴリズム(SGDやAdamなど)が入っています。
from torch.utils.data import Dataset, DataLoader # 大量のデータを効率よく扱い、モデルに少しずつ供給するための便利な道具です。
# 次に、日本語の文章を単語に区切る名人、Janomeさんを呼び出します
# もし「Janomeなんて知らないよ」とPythonに怒られたら、
# ターミナルやコマンドプロンプトで「pip install janome」と打ってインストールしてあげてくださいね。
from janome.tokenizer import Tokenizer
# そして、数値計算のベテラン、NumPyさんもお呼びしましょう(データの準備などでたまに登場します)
import numpy as np
# --- 実験の再現性を高めるためのおまじない ---
# これを書いておくと、何度実行しても同じ結果になりやすくなるので、実験やデバッグがしやすくなります。
torch.manual_seed(42) # PyTorch側の乱数の種を「42」に固定
np.random.seed(42) # NumPy側の乱数の種も「42」に固定 (この42という数字自体に深い意味はないんですよ!)
print("ライブラリの準備ができました!いつでも始められますよ。")
少しだけ、今回呼び出した主な「道具」たちについて、何をするものなのか補足しておきますね。
torch: PyTorchを使う上での基本中の基本となるライブラリです。AIが扱うデータは、多くの場合「テンソル」という、数字が詰まった多次元の箱のような形で表現されるのですが、このテンソルを作ったり計算したりするのが得意です。GPUを使った高速計算の恩恵も、このtorchを通じて受けることができます。torch.nn(nnとして呼び出しました): ニューラルネットワーク、つまりAIの脳みそを作るための「部品」がたくさん詰まっているモジュールです。例えば、情報を伝える神経細胞の層(nn.Linear)や、今回主役のLSTM層(nn.LSTM)、単語をベクトルに変換する埋め込み層(nn.Embedding)といった部品が、この中に用意されています。私たちはこれらの部品を組み合わせて、オリジナルのAIモデルを設計していくわけです。nn.Moduleは、これら全てのモデル部品の親玉(基底クラス)みたいな存在ですね。torch.optim(optimとして呼び出しました): AIモデルは、たくさんのデータから「学習」することで賢くなっていきます。この「学習」を効率よく進めるための「戦略」や「方法論」(最適化アルゴリズムと言います)を提供してくれるのが、このモジュールです。例えば、SGDやAdamといった有名なアルゴリズムがここに入っています。DatasetとDataLoader: AIの学習には、しばしば大量のデータが必要になります。これらのデータを効率的に管理し、モデルが学習しやすいように適切な量(ミニバッチと言います)に分けて、順番に供給してくれるのが、この二人の役割です。Datasetがデータ全体を保持する役割、DataLoaderがそこからデータを取り出してくる役割、といったイメージでしょうか。Tokenizer(Janomeライブラリより): 今回は日本語のテキストを扱いますよね。日本語って、英語と違って単語と単語の間にスペースがないので、どこで区切るかが結構難しいんです。この「文章を意味のある最小単位(形態素と言います。例えば「私/は/医療/を/学ぶ」のように)」に分解し、それぞれの品詞などを判別する作業を「形態素解析」と呼びます。JanomeのTokenizerは、この形態素解析を手軽に行ってくれるツールです。今回は、文章を単語(表層形といいます)のリストに変換するために使います。numpy(npとして呼び出しました): Pythonで数値計算を行う際の定番ライブラリです。PyTorchのテンソルと相互に変換しやすかったり、データの前処理でちょっとした計算をしたい時などに便利なので、よく一緒に使われます。torch.manual_seed(42)とnp.random.seed(42): AIの学習では、最初にモデルの重みをランダムに初期化したり、学習データをランダムにシャッフルしたりすることがあります。この「ランダム」さが毎回変わってしまうと、同じコードを実行しても結果が微妙に変わってしまい、実験の比較やバグの原因特定が難しくなることがあります。そこで、この「乱数の種(シード)」を固定することで、何度実行しても同じ乱数列が生成されるようにし、実験の「再現性」を確保するんです。一種のおまじないのようなものですが、研究や開発ではとても大切なんですよ。ちなみに、「42」という数字は、ある有名なSF作品に由来するジョークとしてよく使われるだけで、数字自体に特別な意味はありません。好きな数字に変えても大丈夫です!
これで、私たちの調理台には、必要な道具が一通り揃いましたね!
3.2. データセットの準備
さあ、道具が揃ったら、次はいよいよ「食材」の準備です。AIモデルを学習させるためには、お手本となるデータ、つまり「こういう入力があったら、こういう答えを出してほしい」という例をたくさん集めた「データセット」が必要になります。今回は、医療に関連する日本語の短いテキスト(例えば、患者さんの症状の訴えのようなもの)と、それがどの診療科に関連しそうか、というラベル(正解情報)をペアにした、ごくごく簡単な「ダミーデータセット」を自分たちで作ってみることにしましょう。
もちろん、実際の医療現場で使われるAIを開発するには、もっともっと大規模で、質の高い、そして偏りのないデータセットが不可欠です。でも、まずはこの小さなデータセットで、データがAIモデルに入力されるまでにどんな準備が必要なのか、その一連の流れを体験してみることが、とても大切なんですよ。ここで掴んだ感覚は、将来もっと大きなデータに挑戦するときの、きっと大きな力になるはずです。
今回想定するサンプルデータはこんな感じです:
- テキスト: 患者さんが訴える症状や状況を表す、短い日本語の文章。
- ラベル: そのテキスト内容が、どの診療科(例: 内科, 外科, 眼科)に関連が深そうかを示す情報。
では、Pythonのコードで、この小さな食材リスト(corpusという名前のリストに格納します)を作ってみましょう。
# --- 今回使う、とっても小さな「お試し医療テキストデータセット」を作りましょう ---
# corpus(コーパス)とは、自然言語処理の分野で「テキストの集合体」を指す言葉です。
corpus = [
("熱があり、咳と喉の痛みがあります。", "内科"), # テキストと、それに対応する診療科ラベルのペア
("お腹が急に痛み出し、吐き気もします。", "内科"),
("転んで手首を強く打ち、腫れてきました。", "外科"),
("最近、視力が落ちてきた気がします。", "眼科"),
("鼻水が止まらず、くしゃみが頻繁に出ます。", "内科"), # 本当は耳鼻咽喉科かもしれませんが、今回は簡略化のため内科に分類してみます
("切り傷が深く、血が止まりません。", "外科"),
("目がかすんで、細かい文字が見えにくいです。", "眼科"),
("頭痛がひどく、めまいも感じます。", "内科"), # こちらも神経内科など、より専門的な科があり得ますが、今回は内科とします
("足首を捻挫し、歩くと痛みます。", "外科"),
("充血していて、目やにも多いです。", "眼科")
]
# 形態素解析器さん(JanomeのTokenizer)に、一度だけ「こんにちは」と挨拶(インスタンス化)しておきます。
# これで、t さんに文章を渡せば、単語に区切ってくれるようになります。
# (もし t = Tokenizer(wakachigaki=True) とすると、品詞情報なしで単語のリストだけを返してくれますが、
# 今回は後で詳しく見たい場合も考えて、デフォルトのままにしておきましょう。)
t = Tokenizer()
# 用意したcorpusから、テキスト部分だけ、ラベル部分だけを、それぞれ別のリストに分けて格納しておきます。
# こうしておくと、後で扱いやすいんですね。
texts = [data[0] for data in corpus] # corpusの中の各ペア(data)から、0番目の要素(つまりテキスト)だけを取り出してtextsリストへ
labels = [data[1] for data in corpus] # 同様に、1番目の要素(つまりラベル)だけを取り出してlabelsリストへ
# ちょっと中身を確認してみましょうか。
print("--- 元のテキストデータとラベルのペアを見てみましょう ---")
for i, text in enumerate(texts): # textsリストの要素を、インデックス番号(i)と一緒にとりだしてループ
print(f"テキスト{i+1}: 「{text}」 --- ラベル: {labels[i]}") # 画面に出力します
このコードを実行すると、私たちが用意した10個のテキストと、それに対応する診療科のラベルがリスト形式で表示されるはずです。例えば、こんな感じですね。
--- 元のテキストデータとラベルのペアを見てみましょう ---
テキスト1: 「熱があり、咳と喉の痛みがあります。」 --- ラベル: 内科
テキスト2: 「お腹が急に痛み出し、吐き気もします。」 --- ラベル: 内科
テキスト3: 「転んで手首を強く打ち、腫れてきました。」 --- ラベル: 外科
テキスト4: 「最近、視力が落ちてきた気がします。」 --- ラベル: 眼科
テキスト5: 「鼻水が止まらず、くしゃみが頻繁に出ます。」 --- ラベル: 内科
テキスト6: 「切り傷が深く、血が止まりません。」 --- ラベル: 外科
テキスト7: 「目がかすんで、細かい文字が見えにくいです。」 --- ラベル: 眼科
テキスト8: 「頭痛がひどく、めまいも感じます。」 --- ラベル: 内科
テキスト9: 「足首を捻挫し、歩くと痛みます。」 --- ラベル: 外科
テキスト10: 「充血していて、目やにも多いです。」 --- ラベル: 眼科
どうでしょう? なんとなく、医療現場でありそうな短い訴えですよね。今回は、こんな身近な(?)テキストを使って、AIに「この症状なら、何科っぽいかな?」と予測させるモデル作りに挑戦していくわけです。
3.3. テキストデータの前処理:AIにもわかる言葉への翻訳
さて、美味しそうな食材(テキストデータ)が集まりましたが、このままではAIシェフ(LSTMモデル)は調理を始めることができません。なぜなら、コンピュータって、実は私たち人間が日常的に使っている「言葉」そのものを、そのままでは理解できないんですよね。まるで、日本語しか話せないシェフに、英語のレシピを渡すようなものかもしれません。シェフが調理を始めるには、まずレシピを日本語に「翻訳」してあげる必要があります。
AIにとっても同じで、私たちが集めたテキストデータを、AIが理解できる形式、つまり「数値」の列に変換してあげる必要があるんです。この、AIが食べやすいように食材を加工する工程を「前処理 (Preprocessing)」と呼びます。これは自然言語処理において、地味だけれども、ものすごーく大切なステップなんですよ。どんなに高性能なAIシェフでも、下ごしらえがメチャクチャだったら、美味しい料理は作れませんからね。
具体的には、主に以下の4つのステップで、私たちのテキストデータをAI向けの「レシピ」に変換していきます。
【テキストデータ前処理の主なステップ(イメージ)】
1. 元の日本語テキスト: 「熱があり、咳と喉の痛みがあります。」
│
└─→ 2. トークン化 (Tokenization) :文章を意味のある最小単位(単語など)に分割!
例: ["熱", "が", "あり", "、", "咳", "と", "喉", "の", "痛み", "が", "あり", "ます", "。"]
│
└─→ 3. 語彙の構築 (Vocabulary Building) と 単語IDへの変換:
登場する全単語にユニークな背番号(ID)を割り振り、単語列をID列に!
例: [2, 3, 4, 5, 6, 7, 8, 9, 10, 3, 4, 11, 12]
(語彙の例: {"<PAD>":0, "<UNK>":1, "熱":2, "が":3, ...})
│
└─→ 4. パディング (Padding) :全文章の長さを、一番長いものに合わせて揃える!
短い文章には、特別な目印(例:<PAD>トークンのIDである0)を詰める。
例: [2,3,4,5,6,7,8,9,10,3,4,11,12,0,0] (もし最大長が15なら)
│
└─→ PyTorchテンソルへ変換!
これでLSTMモデルへの入力準備がほぼ完了!
そして、ラベル(正解情報)も忘れてはいけません。
ラベル: 「内科」 ───────→ ラベルの数値化:こちらもAIが扱いやすい数値に変換!
例: 「内科」→ 0, 「外科」→ 1, 「眼科」→ 2ね、なんだか大変そうに見えるかもしれませんが、一つ一つのステップは、実はそんなに難しいことではないんです。それぞれのステップが「なぜ必要なのか」を理解しながら進めていきましょう。
- トークン化 (Tokenization): 文章を「単語」という部品に分解する まず最初のステップは、文章を意味のある最小単位、多くは「単語」に分割する作業です。これを「トークン化」と言います。英語のような言語だと、単語と単語の間がスペースで区切られているので比較的簡単なんですが、日本語はご存知の通り、単語が連続して書かれていますよね。「東京都知事」を「東京」「都知事」と区切るのか、「東京都」「知事」と区切るのか、はたまた「東京都知事」で一つの単語と見なすのか…。この区切り方一つで、意味の捉え方が変わってきてしまうこともあります。そこで、日本語のトークン化には、「形態素解析」という専門技術を持ったツール(形態素解析器)の助けを借りるのが一般的です。今回は、先ほどインポートしたJanomeライブラリの
Tokenizerが、この日本語の文章を単語(正確には形態素の表層形)のリストへと上手に分解してくれます。 - 語彙の構築 (Vocabulary Building) と 単語IDへの変換: 単語に「背番号」を振る 無事に文章を単語のリストにできたら、次はいよいよAIが理解できる「数値」へと変換していきます。コンピュータは、「熱」や「咳」といった単語そのものではなく、数字の形で情報を扱うのが得意だからです。そこで、私たちのデータセットに出てくる全てのユニークな単語を集めてきて、それぞれに重複しない番号(ID)を割り振っていきます。この「登場単語リストとそのIDの対応表」のようなものを「語彙(Vocabulary)」や「単語辞書」と呼びます。そして、元の単語の列を、このIDの列に置き換えるのです。例えば、「熱」という単語にはID「2」、「咳」にはID「6」を割り当てる、といった具合ですね。これで、テキストが数値の列に変わりました! ちなみに、学習データには出てこなかった未知の単語が、後で予測する際などに出てくることもあります。そんな時のために、「
<UNK>(Unknownの略)」という特別なトークン(IDは例えば1)を用意しておき、語彙にない単語は全てこの<UNK>に置き換える、という処理もよく行われます。一種の安全策ですね。 - パディング (Padding): 文章の長さを「同じサイズ」に揃える さて、単語をIDの列に変換できましたが、ここで一つ問題があります。それは、文章によって長さ(含まれる単語の数)がバラバラだということです。例えば、「熱と咳。」は3単語(IDが3つ)かもしれませんが、「お腹が急に痛み出し、吐き気もします。」はもっとたくさんの単語(IDがたくさん)になりますよね。でも、多くのAIモデル(LSTMもその一つです)は、入力されるデータの「形」がある程度揃っていることを期待します。特に、複数のデータをまとめて処理する(バッチ処理と言います)際には、各データの長さが同じである必要があるんです。 そこで登場するのが「パディング (Padding)」というテクニックです。これは、データセットの中で一番長い文章の長さに合わせて、それよりも短い文章の後ろ(あるいは前)に、何か特別な意味を持たない値(トークン)を詰めて、見かけ上の長さを揃えてあげる作業です。まるで、運動会でクラス全員が同じ長さの縄跳びをするために、縄が短い子には、余分な縄を継ぎ足してあげるようなイメージでしょうか。この「継ぎ足すための特別な値」として、よく「
<PAD>(Paddingの略)」というトークン(IDは例えば0)が使われます。この<PAD>トークンは、後でAIモデルが計算する際に「これは意味のない詰め物ですよ」と無視されるように処理されるのが一般的です。 - ラベルの数値化: 正解情報も「数値」に変換する AIに入力するテキストデータだけでなく、AIに予測してほしい「正解」の情報(今回は「内科」「外科」「眼科」といった診療科のラベルですね)も、AIが扱える数値形式に変換してあげる必要があります。これも単語IDへの変換と似ていて、「内科」という文字列にはID「0」、「外科」にはID「1」、「眼科」にはID「2」を割り当てる、といった具合です。これで、AIは「この症状のテキスト(ID列)が来たら、答えは0(つまり内科)だよ」という形で学習できるようになります。
さあ、これでAIに入力するためのデータの下ごしらえの考え方が、だいぶクリアになってきたのではないでしょうか? それでは、これらのステップをPythonのコードで実際に見ていきましょう!
graph TD
subgraph "A. 元データ"
InputText["元の文章リスト (texts)"]
InputLabel["元の正解ラベルリスト (labels)"]
end
subgraph "B. 前処理パイプライン"
Step1["ステップ1: トークン化
文章を単語リストに分割"]
Step2["ステップ2: 語彙構築 & ID変換
単語リストをIDの列に変換"]
Step3["ステップ3: パディング
ID列の長さを統一"]
Step4["ステップ4: ラベルの数値化
正解ラベルを数値IDに変換"]
end
subgraph "C. 完成したモデル用データ (Tensor形式)"
OutputX["入力データ (X)
パディング済みIDテンソル"]
OutputY["正解ラベルデータ (y)
数値化ラベルテンソル"]
end
%% データフローの接続
InputText --> Step1
Step1 --> Step2
Step2 --> Step3
Step3 --> OutputX
InputLabel --> Step4
Step4 --> OutputY
# --- ステップ1: トークン化 (Janomeを使って日本語の文章を単語リストへ) ---
print("\n--- ステップ1: トークン化の様子を見てみましょう ---")
tokenized_texts = [] # トークン化されたテキスト(単語のリスト)を、ここに格納していきます
for text in texts: # 用意した各テキスト文章について、順番に処理します
# t.tokenize(text)で形態素解析を実行し、各トークン(token)の表層形(token.surface)つまり単語そのものをリストに集めます
tokens = [token.surface for token in t.tokenize(text)]
tokenized_texts.append(tokens) # 出来上がった単語リストを、tokenized_texts に追加します
# 最初の3つの文章がどうなったか、ちょっと覗いてみましょう
for i in range(3):
print(f"元の文{i+1}: 「{texts[i]}」")
print(f"トークン化後{i+1}: {tokenized_texts[i]}")
print("-" * 30) # 見やすいように区切り線
# --- ステップ2: 語彙の構築と単語IDへの変換 ---
print("\n--- ステップ2: 語彙を作って、単語をIDに変換します ---")
word_to_id = {} # 「単語」をキーにして、その「ID」を値として格納する辞書(単語→ID変換用)
id_to_word = {} # 「ID」をキーにして、その「単語」を値として格納する辞書(ID→単語変換用、デバッグや結果確認に便利)
# まず、特別なトークンを登録しておきましょう
# <PAD>: パディング(長さを揃えるための穴埋め)に使うトークン
# <UNK>: 未知語(語彙に登録されていない初めて見る単語)を表すトークン
PAD_TOKEN = "<PAD>"
UNK_TOKEN = "<UNK>"
word_to_id[PAD_TOKEN] = 0 # <PAD> にはID 0番を割り当て
id_to_word[0] = PAD_TOKEN
word_to_id[UNK_TOKEN] = 1 # <UNK> にはID 1番を割り当て
id_to_word[1] = UNK_TOKEN
# 次に、データ中の全単語を調べて、語彙(word_to_id と id_to_word)に追加していきます
for tokens in tokenized_texts: # トークン化済みの各文章(単語リスト)について処理
for token in tokens: # その文章の中の各単語について処理
if token not in word_to_id: # もし、その単語がまだword_to_idに登録されていなければ(つまり新しい単語なら)
new_id = len(word_to_id) # 新しいIDとして、現在のword_to_idの登録数(これが次の空きIDになる)を採番
word_to_id[token] = new_id # 新しい単語とIDのペアを登録
id_to_word[new_id] = token # IDと単語のペアも登録
vocab_size = len(word_to_id) # 語彙に含まれる総単語数(<PAD>, <UNK>も含む)
print(f"作成された語彙のサイズ: {vocab_size} 単語")
# print(f"単語からIDへの対応辞書 (最初のいくつか): {dict(list(word_to_id.items())[:10])}") # 確認用
# 作成した語彙(word_to_id)を使って、トークン化されたテキストをIDの列(シーケンス)に変換します
sequences = [] # IDの列をここに格納していきます
for tokens in tokenized_texts: # トークン化済みの各文章(単語リスト)について処理
# 各単語をIDに変換します。もし語彙にない単語(未知語)が出てきたら、<UNK>トークンのIDを使います。
sequence = [word_to_id.get(token, word_to_id[UNK_TOKEN]) for token in tokens]
sequences.append(sequence) # 出来上がったID列をsequencesに追加
# こちらも最初の3つの文章がどうなったか、見てみましょう
print("\n--- 単語ID列への変換結果 (最初の3件) ---")
for i in range(3):
print(f"元のトークン列{i+1}: {tokenized_texts[i]}")
print(f"ID列に変換後{i+1}: {sequences[i]}")
print("-" * 30)
# --- ステップ3: パディング (系列長の統一) ---
print("\n--- ステップ3: パディングで文章の長さを揃えます ---")
# まず、データセットの中で一番長い文章(ID列)が、単語何個分なのかを調べます
max_len = 0
for seq in sequences:
if len(seq) > max_len:
max_len = len(seq)
print(f"データ中の最も長い文章の単語数(ID数): {max_len}")
padded_sequences = [] # パディング後のID列をここに格納します
for seq in sequences: # 各ID列について処理
# パディングが必要な長さ(足りない単語の数)を計算します
padding_length = max_len - len(seq)
# 元のID列の後ろに、<PAD>トークンのID (0) を足りない分だけ追加します
padded_seq = seq + [word_to_id[PAD_TOKEN]] * padding_length
padded_sequences.append(padded_seq) # パディングされたID列をpadded_sequencesに追加
# PyTorchのテンソルという形式に変換します。これはAIモデルが直接扱える数値の箱のようなものです。
# 特に、IDのような整数はLongTensorという型で扱うことが多いです。
X = torch.LongTensor(padded_sequences) # これがモデルへの入力データになります
print(f"\nパディング後の最大系列長: {max_len}")
print("--- パディングされテンソルに変換された入力データ (X) の一部を見てみましょう ---")
print(X) # Xの中身(IDがたくさん並んだ行列のように見えます)
print(f"入力データXの形状 (データの個数, 1データあたりの最大単語数): {X.shape}")
# 例えば torch.Size([10, 13]) と出たら、10個の文章データがあり、
# 各文章はパディングされて13個のID(単語)の列になっている、という意味です。
# --- ステップ4: ラベルの数値化 ---
print("\n--- ステップ4: 正解ラベル(診療科名)も数値に変換します ---")
label_to_id = {} # 「ラベル名」をキーにして、その「ID」を値として格納する辞書
id_to_label = {} # 「ID」をキーにして、その「ラベル名」を値として格納する辞書
for label in labels: # 用意した各ラベル(診療科名)について処理
if label not in label_to_id: # もし、そのラベルがまだ登録されていなければ
new_id = len(label_to_id) # 新しいIDを採番
label_to_id[label] = new_id # ラベル名とIDのペアを登録
id_to_label[new_id] = label # IDとラベル名のペアも登録
# 各ラベル名をIDに変換します
y_labels_numerical = [label_to_id[label] for label in labels]
y = torch.LongTensor(y_labels_numerical) # これがモデルの正解データになります
num_classes = len(label_to_id) # 分類したいクラスの総数(今回は診療科の数)
print(f"ラベルとIDの対応関係: {label_to_id}")
print(f"数値化されたラベル (y): {y}")
print(f"分類するクラスの総数: {num_classes}")
print("\nこれで、AIモデルに入力するためのデータ準備が整いました!いよいよモデル構築ですね!")--- ステップ1: トークン化の様子を見てみましょう ---
元の文1: 「熱があり、咳と喉の痛みがあります。」
トークン化後1: ['熱', 'が', 'あり', '、', '咳', 'と', '喉', 'の', '痛み', 'が', 'あり', 'ます', '。']
------------------------------
元の文2: 「お腹が急に痛み出し、吐き気もします。」
トークン化後2: ['お腹', 'が', '急', 'に', '痛み', '出し', '、', '吐き気', 'も', 'し', 'ます', '。']
------------------------------
元の文3: 「転んで手首を強く打ち、腫れてきました。」
トークン化後3: ['転ん', 'で', '手首', 'を', '強く', '打ち', '、', '腫れ', 'て', 'き', 'まし', 'た', '。']
------------------------------
--- ステップ2: 語彙を作って、単語をIDに変換します ---
作成された語彙のサイズ: 65 単語
--- 単語ID列への変換結果 (最初の3件) ---
元のトークン列1: ['熱', 'が', 'あり', '、', '咳', 'と', '喉', 'の', '痛み', 'が', 'あり', 'ます', '。']
ID列に変換後1: [2, 3, 4, 5, 6, 7, 8, 9, 10, 3, 4, 11, 12]
------------------------------
元のトークン列2: ['お腹', 'が', '急', 'に', '痛み', '出し', '、', '吐き気', 'も', 'し', 'ます', '。']
ID列に変換後2: [13, 3, 14, 15, 10, 16, 5, 17, 18, 19, 11, 12]
------------------------------
元のトークン列3: ['転ん', 'で', '手首', 'を', '強く', '打ち', '、', '腫れ', 'て', 'き', 'まし', 'た', '。']
ID列に変換後3: [20, 21, 22, 23, 24, 25, 5, 26, 27, 28, 29, 30, 12]
------------------------------
--- ステップ3: パディングで文章の長さを揃えます ---
データ中の最も長い文章の単語数(ID数): 13
パディング後の最大系列長: 13
--- パディングされテンソルに変換された入力データ (X) の一部を見てみましょう ---
tensor([[ 2, 3, 4, 5, 6, 7, 8, 9, 10, 3, 4, 11, 12],
[13, 3, 14, 15, 10, 16, 5, 17, 18, 19, 11, 12, 0],
[20, 21, 22, 23, 24, 25, 5, 26, 27, 28, 29, 30, 12],
[31, 5, 32, 3, 33, 27, 28, 30, 34, 3, 19, 11, 12],
[35, 3, 36, 37, 5, 38, 3, 39, 15, 40, 11, 12, 0],
[41, 3, 42, 5, 43, 3, 44, 45, 46, 12, 0, 0, 0],
[47, 3, 48, 21, 5, 49, 50, 3, 51, 52, 53, 12, 0],
[54, 3, 55, 5, 56, 18, 57, 11, 12, 0, 0, 0, 0],
[58, 23, 59, 19, 5, 60, 7, 10, 11, 12, 0, 0, 0],
[61, 19, 27, 62, 27, 5, 63, 18, 64, 53, 12, 0, 0]])
入力データXの形状 (データの個数, 1データあたりの最大単語数): torch.Size([10, 13])
--- ステップ4: 正解ラベル(診療科名)も数値に変換します ---
ラベルとIDの対応関係: {'内科': 0, '外科': 1, '眼科': 2}
数値化されたラベル (y): tensor([0, 0, 1, 2, 0, 1, 2, 0, 1, 2])
分類するクラスの総数: 3
これで、AIモデルに入力するためのデータ準備が整いました!いよいよモデル構築ですね!このコードを実行すると、各ステップでの変換の様子や、最終的に出来上がる入力データX(パディング済みの単語ID列の集まり)と正解ラベルy(数値化された診療科IDの集まり)の中身や形(テンソルのサイズ)が確認できるはずです。例えば、Xの形状が torch.Size([10, 13]) と表示されたら、それは「10個のサンプル(文章)があって、各サンプルは(パディングによって)13個の単語IDで表現されていますよ」という意味になります。
ここまでで、私たちの手元には、AIが「読んで」「学習する」ための、数値化され、形が整えられたテキストデータが用意できました。ちょっと地道な作業でしたが、この丁寧な下ごしらえが、後々のAIモデルの性能に大きく関わってくるんですよ。さあ、これでようやくAIモデル(今回はLSTMですね!)の設計と訓練に進む準備が整いました!
4. LSTMモデルの構築 (PyTorch):私たちのAIの設計図を描こう!
さあ、データの下ごしらえという、地道だけれどもとっても大切な準備運動が終わりましたね! これで、私たちの手元には、AIが「読んで」「学習する」ための、キレイに整形された「数値のレシピ」が用意できました。いよいよここからは、このレシピを使って美味しい料理を作り出すAIシェフ、つまりLSTMモデルそのものを設計し、PyTorchという調理器具を使って実際に組み立てていく工程に入ります。まさに、AI開発のクライマックスの一つと言っても良いかもしれませんね!
今回私たちが作るLSTMモデルは、大きく分けて3つの主要な部品(これをニューラルネットワークの世界では「層(Layer)」と呼びます)から構成されます。それぞれの層が連携し合うことで、入力された文章(実際には単語IDの列ですね)から、最終的な予測(今回はどの診療科に属するか)を導き出すのです。ちょっと料理に例えるなら、こんな感じでしょうか。
- 埋め込み層 (Embedding Layer): まず最初の工程は、私たちが用意した単語IDという「背番号」の状態の食材を、もっと情報豊かな形に加工するところから始まります。この埋め込み層は、それぞれの単語IDを、「単語埋め込みベクトル (Word Embedding Vector)」と呼ばれる、数十~数百次元の密な数値のベクトルに変換する役割を担います。このベクトルは、単にIDを置き換えるだけでなく、単語の「意味」や「ニュアンス」、あるいは他の単語との「関連性」といった情報を、ベクトル空間の中での位置や方向として表現しようとする、とっても賢い仕組みなんです。例えば、「熱」と「発熱」という単語は、意味が近いので、ベクトル空間の中でも比較的近い場所に位置づけられるようになる、といったイメージですね。まるで、一つ一つの単語に、その単語の個性や特徴を表す詳細なプロフィール情報(ベクトル)を持たせてあげるようなものです。この処理には、PyTorchの
nn.Embeddingという部品を使います。 - LSTM層 (LSTM Layer): 次に登場するのが、いよいよ本日の主役、LSTM層です! 埋め込み層で作られた、意味を持つ単語ベクトルの「列(シーケンス)」を順番に読み込んでいき、文章全体の文脈や、単語間の長期的な依存関係(「あの時のあの言葉が、今のこの言葉に繋がっているぞ!」といった関係ですね)を捉える、まさにこのモデルの“頭脳”にあたる部分です。前のセクションでじっくり見た、あの忘却ゲート、入力ゲート、出力ゲートたちが、この層の中で大活躍し、情報の取捨選択を行いながら、文章の意味を深く理解しようと努めます。このLSTM層の出力として、文章全体の情報を集約したベクトル(通常は最後の時刻の隠れ状態や、全時刻の隠れ状態をまとめたもの)が得られます。これを、次の分類ステップのための重要な「特徴量」として利用するわけです。この処理には、PyTorchの
nn.LSTMという部品を使います。 - 全結合層 (Fully Connected Layer / Linear Layer): 最後の仕上げです! LSTM層が一生懸命読み解いて抽出してくれた、文章全体の文脈情報が詰まったベクトルを受け取り、これを基にして、最終的に「この文章は、どの診療科に分類されるべきか」という予測を行うのが、この全結合層の役割です。具体的には、入力されたベクトルを、私たちが予測したい診療科の数(今回は3つでしたね、「内科」「外科」「眼科」)に対応する数値(スコア)へと変換します。そして、このスコアが最も高かった診療科を、モデルの予測結果とするわけです。まさに、料理の最後に味を調え、どのラベル(お皿)に盛り付けるかを決める、最終判断の工程ですね。この処理には、PyTorchの
nn.Linearという部品を使います。
これらの部品を組み合わせて、私たちはTextLSTMClassifierという名前の、オリジナルのAIモデルクラス(設計図のようなもの)をPythonで定義していきます。PyTorchでAIモデルを自作する際には、nn.Moduleという、PyTorchが提供する便利な機能(例えば、モデル内の学習可能なパラメータを自動で集めてくれたり、GPUでの計算を簡単にしてくれたりします)がたくさん詰まった「親クラス(設計図のテンプレートのようなもの)」を継承(inherit)する、というお作法があるんです。これを「お借りしますね」と宣言することで、私たちはAIモデル作りに専念できるわけです。
では、実際にその設計図(クラス定義)を見てみましょう!
graph TD
subgraph "入力"
Input("入力データ (text_batch)
単語IDのバッチ")
end
subgraph "モデルの処理フロー (forwardメソッド)"
Embedding["1. 埋め込み層 (Embedding)
単語IDを単語ベクトルに変換"]
Dropout1["(Dropoutを適用)"]
LSTM["2. LSTM層
単語ベクトルの列から文脈を抽出"]
GetState["3. 最後の隠れ状態を取得
文全体の情報をベクトルとして集約"]
Dropout2["(Dropoutを適用)"]
FC["4. 全結合層 (Linear)
文脈ベクトルから最終スコアを予測"]
end
subgraph "出力"
Output("出力データ (output)
各クラスの予測スコア")
end
%% 処理の接続
Input --> Embedding
Embedding --> Dropout1
Dropout1 --> LSTM
LSTM --> GetState
GetState --> Dropout2
Dropout2 --> FC
FC --> Output
# nn.Moduleという、PyTorchのAIモデルの「設計図の親玉」をお借りして、
# 私たちオリジナルのTextLSTMClassifierという設計図(クラス)を作ります。
class TextLSTMClassifier(nn.Module):
# --- モデルが「誕生」する瞬間に呼ばれる設計指示書:__init__ (コンストラクタ) ---
# ここで、モデルがどんな部品(層)を持っていて、それぞれがどんな設定なのかを定義します。
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, lstm_layers=1, dropout_rate=0.2):
# vocab_size: 私たちが作った語彙に含まれる総単語数。埋め込み層が「何種類の単語IDが来るか」を知るために必要。
# embedding_dim: 各単語を何次元のベクトルで表現するか(単語埋め込みベクトルの「豊かさ」)。
# hidden_dim: LSTM層の記憶容量の大きさ。大きいほど複雑な文脈を捉えられますが、計算も大変に。
# output_dim: 最終的に分類したいクラスの数(今回は診療科の数なので3)。
# lstm_layers: LSTM層を何層重ねるか(デフォルトは1層)。深くすると表現力が増すことも。
# dropout_rate: 学習中にどれくらいの割合で神経細胞を「お休み」させるか(過学習防止のため、デフォルトは20%)。
super(TextLSTMClassifier, self).__init__() # まずは親クラスnn.Moduleの初期化処理を呼び出すお約束。
# --- 1. 埋め込み層 (Embedding Layer) の準備 ---
# 単語IDの列を、意味を持つベクトルの列に変換する魔法の箱です。
# num_embeddings: 語彙の総サイズ (vocab_size) を指定します。
# embedding_dim: 出力される単語ベクトルの次元数を指定します。
# padding_idx: パディングに使ったID (今回は0番の<PAD>トークン) を指定すると、
# そのIDの単語は学習時に無視されるようになり、計算に影響を与えません。賢いですね!
self.embedding = nn.Embedding(num_embeddings=vocab_size,
embedding_dim=embedding_dim,
padding_idx=word_to_id[PAD_TOKEN]) # word_to_idは前処理で作った辞書
# --- 2. LSTM層 (LSTM Layer) の準備 ---
# 埋め込みベクトル(単語の意味ベクトル)の列を順番に読み込み、文全体の文脈を捉えます。
# input_size: LSTM層に入力される各要素(今回は各単語の埋め込みベクトル)の次元数 (embedding_dim)。
# hidden_size: LSTM層の内部で情報を記憶・処理する隠れ状態ベクトルの次元数 (hidden_dim)。
# num_layers: LSTM層を何層重ねるか (lstm_layers)。今回は1層ですが、深くすることも可能です。
# batch_first=True: 入力データの形を (バッチサイズ, 系列長, 特徴量次元) という順番にしますよ、というお約束。
# これに合わせておかないと、LSTMがデータを正しく解釈できません。
# bidirectional=False: LSTMを一方向(文頭から文末へ)だけで処理します。Trueにすると双方向になりますが、今回はFalse。
# dropout: LSTM層を複数重ねた場合に、層と層の間でドロップアウトを適用する割合 (dropout_rate)。
# 1層の場合はこのdropoutは効果がないので、lstm_layers > 1 の時だけ設定します。
self.lstm = nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_dim,
num_layers=lstm_layers,
batch_first=True,
bidirectional=False,
dropout=dropout_rate if lstm_layers > 1 else 0)
# --- 3. 全結合層(線形層: Fully Connected Layer / Linear Layer) の準備 ---
# LSTMが捉えた文脈情報(ベクトル)を元に、最終的に「これはどの診療科か」を予測します。
# in_features: この層に入力されるベクトルの次元数(LSTMの隠れ状態の次元数 hidden_dim)。
# out_features: この層が出力するベクトルの次元数(分類したいクラスの数 output_dim)。
self.fc = nn.Linear(in_features=hidden_dim, out_features=output_dim)
# --- おまけ:ドロップアウト層 (Dropout Layer) の準備 ---
# モデルが学習データに慣れすぎること(過学習)を防ぐためのお守りです。
# 指定された確率 (dropout_rate) で、学習中にランダムに一部のニューロンの働きを「オフ」にします。
# これにより、モデルは一部の情報が欠けても予測できるように、より頑健になろうとします。
self.dropout = nn.Dropout(dropout_rate)
# --- モデルにデータが入力されたときの「処理の流れ」を定義:forward メソッド ---
# ここで、__init__で用意した部品たちが、どういう順番で、どんな風にデータを処理していくかを記述します。
# text_batch: 入力されるテキストデータのバッチ。形状は (バッチサイズ, 系列長) の単語IDのテンソル。
def forward(self, text_batch):
# 1. 埋め込み層を通過:単語IDの列が、意味を持つベクトルの列に!
# 入力形状: (バッチサイズ, 系列長)
# 出力形状: (バッチサイズ, 系列長, embedding_dim)
# 例: (2, 13) → (2, 13, 100) (バッチサイズ2、最大系列長13、埋め込み次元100の場合)
embedded = self.embedding(text_batch)
# print(f"埋め込み層出力形状: {embedded.shape}") # デバッグ用
# 埋め込み層の出力にもドロップアウトを適用して、ちょっとだけ情報を揺さぶります(過学習防止)。
embedded = self.dropout(embedded)
# 2. LSTM層を通過:単語ベクトルの列から、文全体の文脈情報を抽出!
# 入力形状: (バッチサイズ, 系列長, embedding_dim)
# lstm_out: LSTMの各時刻における隠れ状態の出力。(バッチサイズ, 系列長, hidden_dim)
# hidden: 最後の時刻の隠れ状態。(層の数*方向数, バッチサイズ, hidden_dim)
# cell: 最後の時刻のセル状態。(層の数*方向数, バッチサイズ, hidden_dim)
lstm_out, (hidden, cell) = self.lstm(embedded)
# print(f"LSTM層 hidden形状: {hidden.shape}") # デバッグ用
# print(f"LSTM層 cell形状: {cell.shape}") # デバッグ用
# print(f"LSTM層 lstm_out形状: {lstm_out.shape}") # デバッグ用
# 今回は、文章全体の情報を集約した「最後の隠れ状態」を使います。
# hiddenテンソルの形状は (層の数 * 方向の数, バッチサイズ, hidden_dim) となっています。
# 今回は単層(lstm_layers=1)かつ単方向(bidirectional=False)なので、
# (1, バッチサイズ, hidden_dim) という形です。
# この最初の次元(層/方向の次元)の最後の要素を取り出すために hidden[-1] とします。
# これにより、形状は (バッチサイズ, hidden_dim) になります。
# これが、各文章がhidden_dim次元のベクトルで表現されたもの、と解釈できます。
final_hidden_state = hidden[-1]
# print(f"使用する最終隠れ状態形状: {final_hidden_state.shape}") # デバッグ用
# (別案として、lstm_out の最後の時刻の出力 lstm_out[:, -1, :] を使うこともよくあります。
# 結果はほぼ同じ形状 (バッチサイズ, hidden_dim) になります。)
# LSTMの出力(最終隠れ状態)にもドロップアウトを適用します。
final_hidden_state = self.dropout(final_hidden_state)
# 3. 全結合層を通過:文脈ベクトルから、各診療科への予測スコアを算出!
# 入力形状: (バッチサイズ, hidden_dim)
# 出力形状: (バッチサイズ, output_dim)
# 例: (2, 128) → (2, 3) (バッチサイズ2、LSTM隠れ層128次元、出力クラス3つの場合)
output = self.fc(final_hidden_state)
# print(f"全結合層出力形状: {output.shape}") # デバッグ用
return output # 最終的な予測スコアを返すどうでしょう? __init__で部品を用意し、forwardでそれらを繋げてデータの流れを作る、というAIモデル構築の基本的な流れが、なんとなくイメージできたでしょうか。このforwardメソッドに、前処理で作った単語IDのテンソル(text_batch)を渡すと、最終的に各診療科に属する確率のようなもの(正確にはスコアですが)が計算されて出てくる、という仕組みになっているんですね。
Deep Dive! LSTM層のデータ処理:入力と出力の形状解説
ニューラルネットワークのLSTM層が入力データ(単語ベクトル列)をどのように処理し、どのような情報を出力するのかを、行列の形状や次元数のイメージを交えながら解説します。
簡単に言うと、LSTMは文章のような一連のデータを順番に読み込んで、その「文脈」を理解しようとします。
Pythonコード:LSTM層の処理
以下は、PyTorchにおけるLSTM層の一般的な処理を示すコードスニペットです。
# 2. LSTM層を通過:単語ベクトルの列から、文全体の文脈情報を抽出します!
# 入力形状 (input shape): (バッチサイズ, 系列長, embedding_dim) - 一度に処理する文章の数、各文章の長さ(単語数)、各単語を表すベクトルの次元数
# lstm_out: LSTMの各時刻 (単語ごと) における隠れ状態の出力。(バッチサイズ, 系列長, hidden_dim) - hidden_dimはLSTMが記憶する文脈情報の次元数
# hidden: 最後の時刻の隠れ状態。(層の数*方向数, バッチサイズ, hidden_dim) - 文章全体を読み終えた後の最終的な文脈情報
# cell: 最後の時刻のセル状態。(層の数*方向数, バッチサイズ, hidden_dim) - LSTM内部の記憶セルの最終状態
lstm_out, (hidden, cell) = self.lstm(embedded) # self.lstmがLSTM層のインスタンス、embeddedが入力データ
データの流れと行列の形について 📏
以下に、各変数がどのような行列(テンソル)の形をしているか、テキストベースの図で示します。
処理の前提となる次元数
説明を具体的にするために、以下の次元数を仮定します。
| 変数名 (MathJax) | 説明 | 具体例 |
|---|---|---|
| バッチサイズ ( \(B\) ) | 同時に処理する文章の数 | 例: 2 |
| 系列長 ( \(S\) ) | 1つの文章の最大単語数 | 例: 10 単語 |
| 埋め込み次元 ( \(E\) ) | 1つの単語を表すベクトルの次元数 (単語の意味の豊かさ) | 例: 100 |
| 隠れ層次元 ( \(H\) ) | LSTMが内部で記憶する情報の次元数 (文脈の複雑さ) | 例: 128 |
| 層の数×方向数 ( \(L\) ) | LSTM層の深さや双方向性。今回は簡単のため 1 (単層・一方向) とします。 | 例: 1 |
1. LSTMへの入力: embedded
これはLSTM層に入力されるデータで、各文章の各単語がベクトル(数値の集まり)で表現されたものです。形状は(バッチサイズ, 系列長, 埋め込み次元)となります。
数式で形状を表すと次のようになります:
\[ \text{shape}(\text{embedded}) = (B, S, E) \]
これは、\(B\)個の文章があり、各文章は \(S\)個の単語で構成され、各単語は \(E\)次元のベクトルで表現されていることを意味します。
embedded (入力):
--------------------------------------------------------------------
文章1: [ 単語1ベクトル (E次元), 単語2ベクトル (E次元), ..., 単語Sベクトル (E次元) ] <-- S個の単語ベクトル
文章2: [ 単語1ベクトル (E次元), 単語2ベクトル (E次元), ..., 単語Sベクトル (E次元) ]
...
文章B: [ 単語1ベクトル (E次元), 単語2ベクトル (E次元), ..., 単語Sベクトル (E次元) ]
--------------------------------------------------------------------
全体として、(B × S × E) のブロックのようなイメージ。
例: (2, 10, 100) の場合
文章1:
単語1: [v1, v2, ..., v100] (100次元のベクトル)
単語2: [v1, v2, ..., v100] (100次元のベクトル)
...
単語10: [v1, v2, ..., v100] (100次元のベクトル)
文章2:
単語1: [v1, v2, ..., v100] (100次元のベクトル)
...
単語10: [v1, v2, ..., v100] (100次元のベクトル)
2. LSTM層の処理: self.lstm(...)
self.lstm は embedded を入力として受け取り、3つの主要な情報を出力します。この処理により、入力された単語の並びから文脈が抽出されます。
3. LSTMからの出力1: lstm_out
lstm_out は、文章中の各単語を処理した時点での「文脈情報」(隠れ状態)です。形状は(バッチサイズ, 系列長, 隠れ層次元)です。
数式で形状を表すと次のようになります:
\[ \text{shape}(\text{lstm\_out}) = (B, S, H) \]
これは、\(B\)個の文章それぞれについて、\(S\)個の各単語位置での文脈を捉えた \(H\)次元のベクトルが出力されることを意味します。
lstm_out (各時刻の出力):
--------------------------------------------------------------------------
文章1: [ 時刻1の出力 (H次元), 時刻2の出力 (H次元), ..., 時刻Sの出力 (H次元) ]
文章2: [ 時刻1の出力 (H次元), 時刻2の出力 (H次元), ..., 時刻Sの出力 (H次元) ]
...
文章B: [ 時刻1の出力 (H次元), 時刻2の出力 (H次元), ..., 時刻Sの出力 (H次元) ]
--------------------------------------------------------------------------
全体として、(B × S × H) のブロックのようなイメージ。
例: (2, 10, 128) の場合
文章1:
単語1処理後: [h1, h2, ..., h128] (128次元のベクトル)
単語2処理後: [h1, h2, ..., h128] (128次元のベクトル)
...
単語10処理後: [h1, h2, ..., h128] (128次元のベクトル)
文章2:
単語1処理後: [h1, h2, ..., h128] (128次元のベクトル)
...
単語10処理後: [h1, h2, ..., h128] (128次元のベクトル)
4. LSTMからの出力2: hidden
hidden は、文章全体を読み終わった最後の時点での「文脈情報」(隠れ状態)です。これが文章全体の代表的な情報としてよく利用されます。形状は(層の数×方向数, バッチサイズ, 隠れ層次元)です。
数式で形状を表すと次のようになります:
\[ \text{shape}(\text{hidden}) = (L, B, H) \]
これは、\(L\)個の層/方向について(今回は \(L=1\) と仮定)、\(B\)個の各文章の最終的な文脈を表す \(H\)次元のベクトルが得られることを意味します。
hidden (最終隠れ状態):
--------------------------------------------------
層/方向1:
文章1の最終状態 (H次元)
文章2の最終状態 (H次元)
...
文章Bの最終状態 (H次元)
--------------------------------------------------
(層/方向が複数ある場合は、このブロックがL個重なるイメージ)
全体として、(L × B × H) のブロックのようなイメージ。
例 (L=1 の場合): (1, 2, 128)
層1:
文章1の最終状態: [h1, h2, ..., h128] (128次元のベクトル)
文章2の最終状態: [h1, h2, ..., h128] (128次元のベクトル)`hidden` テンソルの形状ビジュアライゼーション: (L, B, H)
--------------------------------------------------------------------------
LSTMが各文章の単語列 [W_1, W_2, ..., W_S] を最後まで処理し終えた「後」の
「最終隠れ状態ベクトル」が、以下のように格納されます。
<< L の次元 (層の数 * 方向の数) >>
深さ方向に L 個の「(B, H) 行列」が積み重なるイメージ
[層/方向 1 (L_idx = 0)] の (B, H) 行列 (シート):
<------------------ H (hidden_dim) ------------------->
^ +-----------------------------------------------------+
| | [h_1,1 ... h_1,H]_B1L0 (文章1の"最終"隠れ状態) |
| | [h_2,1 ... h_2,H]_B2L0 (文章2の"最終"隠れ状態) |
B | | ... |
(batch| | [h_B,1 ... h_B,H]_BBL0 (文章Bの"最終"隠れ状態) |
_size)v +-----------------------------------------------------+
[層/方向 2 (L_idx = 1)] の (B, H) 行列 (シート) (もし L > 1 の場合):
<------------------ H (hidden_dim) ------------------->
^ +-----------------------------------------------------+
| | [h_1,1 ... h_1,H]_B1L1 (文章1の"最終"隠れ状態) |
| | [h_2,1 ... h_2,H]_B2L1 (文章2の"最終"隠れ状態) |
B | | ... |
v +-----------------------------------------------------+
... (同様に L_idx = L-1 まで続く) ...
--------------------------------------------------------------------------
解説:
* `L` (num_layers * num_directions): LSTMの層の数や方向性を示します。図では、この (B, H) の「シート」が何枚重なっているかに相当します。
* 単層・単方向LSTMなら L=1 で、このシートは1枚だけです。
* `B` (batch_size): 同時に処理される文章の数です。各シートの中で、行数がBとなります。
* 各行 `[h_i,1 ... h_i,H]_BiLj` が、バッチ内のi番目の文章の最終隠れ状態ベクトルです。
* `H` (hidden_dim): 各最終隠れ状態ベクトルの次元数(ベクトルの長さ)です。各シートの中で、列数がHとなります。
重要なのは、この `hidden` テンソルに格納されている各ベクトル `[h_x,y ... h_x,z]` が、
対応する文章の**全ての単語を処理し終えた後の「最後の時点」**での隠れ状態であるという点です。
これは、系列全体の情報を集約した結果と言えます。
`lstm_out` が系列の各単語位置ごとの隠れ状態を全て保持する [(B, S, H) の形状] のに対し、
`hidden` はその「最後」の情報を層/方向ごとに抽出・整理したもの [(L, B, H) の形状] となります。
`cell`(最終セル状態)も同様の構造と意味を持ちます。5. LSTMからの出力3: cell
cell は、LSTM内部で使われる、文章全体を読み終わった最後の時点での「記憶セル」の状態です。hidden とセットでLSTMの内部状態を表します。形状は hidden と同じく(層の数×方向数, バッチサイズ, 隠れ層次元)です。
数式で形状を表すと次のようになります:
\[ \text{shape}(\text{cell}) = (L, B, H) \]
これは、\(L\)個の層/方向について(今回は \(L=1\) と仮定)、\(B\)個の各文章の最終的な記憶セルの内容を表す \(H\)次元のベクトルが得られることを意味します。
cell (最終セル状態):
--------------------------------------------------
層/方向1:
文章1の最終セル状態 (H次元)
文章2の最終セル状態 (H次元)
...
文章Bの最終セル状態 (H次元)
--------------------------------------------------
(形状は hidden と全く同じ)
全体として、(L × B × H) のブロックのようなイメージ。
例 (L=1 の場合): (1, 2, 128)
層1:
文章1の最終セル: [c1, c2, ..., c128] (128次元のベクトル)
文章2の最終セル: [c1, c2, ..., c128] (128次元のベクトル)
まとめ
このように、embedded (単語ベクトルの集まり) がLSTMに入力されると、以下の3つの主要な情報が出力されます:
lstm_out: 各単語を処理した時点での文脈情報。hidden: 文章全体を読み終えた後の最終的な文脈情報(隠れ状態)。cell: 文章全体を読み終えた後の最終的な記憶セルの状態。
これらの出力、特に hidden の情報(または lstm_out の最後の時刻の情報)を利用して、文章がどのような内容なのかを判断したり、感情分析を行ったり、機械翻訳の次の単語を予測するなど、様々なタスクに応用されます。
次に、この設計図(TextLSTMClassifierクラス)を使って、実際にモデルの「実体(インスタンス)」を作ってみましょう。そのためには、モデルの性能や特性を左右するいくつかの重要な「ハイパーパラメータ」の値を決めてあげる必要があります。これらは、私たちがモデルに与える「設定値」のようなもので、学習を通じてAI自身が調整する「パラメータ(重みやバイアス)」とは区別されます。どんな値を設定するがいいかは、実はケースバイケースで、実験を繰り返しながら見つけていくことが多い、ちょっと職人芸的なところもあるんですよ。
# --- モデルに与える「設定値」(ハイパーパラメータ)を決めていきましょう ---
# これらの値は、後で色々試して、モデルの性能が良くなるように調整していくことが多いです。
# EMBEDDING_DIM: 単語を何次元のベクトルで表現するか。
# 大きいほど豊かな表現ができますが、計算量も増えます。医療用語は専門的なので、少し大きめが良いかも?
EMBEDDING_DIM = 100
# HIDDEN_DIM: LSTM層が持つ「記憶力」や「思考力」のキャパシティのようなもの。
# これも大きいほど複雑なパターンを学習できますが、過学習のリスクや計算コストも考慮します。
HIDDEN_DIM = 128
# OUTPUT_DIM: モデルが最終的に分類したいクラスの数。
# 今回は「内科」「外科」「眼科」の3つなので、前処理で作った num_classes を使います。
OUTPUT_DIM = num_classes
# LSTM_LAYERS: LSTM層を何層重ねるか。
# 1層でも十分な場合も多いですが、より複雑な時系列パターンを捉えたい場合に増やすことがあります。
LSTM_LAYERS = 1
# DROPOUT_RATE: ドロップアウトを適用する割合(0.0~1.0)。
# 例えば0.3なら、30%のニューロンが学習中にランダムでお休みします。過学習を防ぐのに役立ちます。
DROPOUT_RATE = 0.3
# --- さあ、設計図と設定値を使って、AIモデルの実体を作りましょう! ---
model = TextLSTMClassifier(vocab_size, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM, LSTM_LAYERS, DROPOUT_RATE)
# どんな構造のモデルができたか、ちょっと覗いてみましょうか。
print("\n--- 作成されたLSTMモデルの構造 ---")
print(model)
このコードを実行すると、私たちが定義したTextLSTMClassifierの構造(どんな層がどんな順番で並んでいるか、それぞれの層のパラメータ数など)が表示されます。例えば、こんな感じになるはずです(数値は設定によって変わります)。
--- 作成されたLSTMモデルの構造 ---
TextLSTMClassifier(
(embedding): Embedding(50, 100, padding_idx=0) # 語彙サイズ50、埋め込み次元100、パディングIDは0
(lstm): LSTM(100, 128, batch_first=True) # 入力100次元、隠れ層128次元
(fc): Linear(in_features=128, out_features=3, bias=True) # 入力128次元、出力3次元
(dropout): Dropout(p=0.3, inplace=False) # ドロップアウト率0.3
)
ここまでで、私たちのAIモデルの骨格がバッチリ組み上がりました! でも、まだこのモデルは生まれたての赤ちゃんのようで、何も学習していません。なので、本当にちゃんと動くのか、設計図通りにデータが流れるのか、簡単なダミー入力を使って、ちょっとだけ試運転してみましょう。こういう確認作業、意外と大事なんですよ。
# --- モデルがちゃんと動くか、お試し運転してみましょう! ---
# 前処理で作った入力データXの中から、最初の2サンプルだけ取り出して、モデルに入れてみます。
dummy_input_batch = X[0:2] # 形状は (2, 最大系列長) になっているはずです。
print(f"\n--- モデルに入れるお試し入力データ (最初の2サンプル、形状: {dummy_input_batch.shape}) ---")
print(dummy_input_batch)
# モデルに実際にお試し入力を通してみます。
# この時点ではモデルはまだ何も学習していないので、出てくる出力は全くデタラメな値です。
# 大切なのは、エラーが出ずに、期待した形の出力が出てくるか、です。
# torch.no_grad() のブロック内で実行すると、勾配計算(学習に必要な計算)が一時的にオフになり、
# メモリの節約や計算の高速化に繋がります。推論(予測)や、こういう動作確認の時にはよく使います。
with torch.no_grad():
dummy_output = model(dummy_input_batch) # モデルのforwardメソッドが呼び出されます
print(f"\n--- モデルから出てきたお試し出力 (形状: {dummy_output.shape}) ---")
print(dummy_output)
# 出力形状は (バッチサイズ, クラス数) になっているはずです。
# 例えば (2, 3) なら、2つの入力サンプルそれぞれに対して、3つのクラス(診療科)の予測スコアが出た、という意味です。
このお試し運転で、エラーが出ずに、期待した形状(今回はバッチサイズ2、クラス数3なので、torch.Size([2, 3])のような形)の出力が得られれば、モデルの組み立ては一旦成功です! 出てくる数値自体は、まだ学習前なのでランダムなものですが、ちゃんとデータが入力から出力まで流れた、ということですね。例えば、以下のような出力イメージです。
--- モデルに入れるお試し入力データ (最初の2サンプル、形状: torch.Size([2, 13])) ---
tensor([[ 2, 3, 4, 5, 6, 7, 8, 9, 10, 3, 4, 11, 12],
[13, 3, 14, 15, 5, 16, 17, 18, 11, 12, 0, 0, 0]])
--- モデルから出てきたお試し出力 (形状: torch.Size([2, 3])) ---
tensor([[ 0.1234, -0.5678, 0.9012], # 1サンプル目の各クラスに対するデタラメなスコア
[-0.4321, 0.8765, -0.2468]]) # 2サンプル目の各クラスに対するデタラメなスコア
やったー! これで、私たちのAIモデルの「体」が無事に組み上がりました。まるで、新しいロボットの組み立てが完了したような気分でしょうか。次はいよいよ、この生まれたてのモデルに、たくさんのデータで「学習」をさせて、賢いAIへと育てていくステップに進みます。どんな風に学習が進んでいくのか、楽しみですね!
ここで出てきた専門的な部品や考え方について、もう一度まとめておきましょう。
nn.Module: PyTorchでAIモデルを自作するときの、いわば「設計図のテンプレート」です。これを継承することで、モデルの部品(層)を定義したり、データが流れる順序(forwardメソッド)を記述したり、PyTorchの便利な機能をフル活用できるようになります。nn.Embedding: 単語に割り振られたID(ただの整数)を、その単語の意味や文脈的特徴を捉えた固定長の数値ベクトル(単語埋め込みベクトル)に変換する層です。vocab_size(語彙の総数)とembedding_dim(埋め込みベクトルの次元数)が主な設定項目です。padding_idxを指定すると、特定のID(パディング用IDなど)を計算時に無視してくれる賢い機能も持っています。nn.LSTM: このモデルの心臓部であるLSTM層です。単語埋め込みベクトルの列を受け取り、ゲート機構を駆使して長期的な依存関係を学習し、文脈を理解しようとします。input_size(入力ベクトルの次元)、hidden_size(LSTMの記憶容量や出力ベクトルの次元)、num_layers(LSTM層を何層重ねるか)、batch_first=True(入力データの次元の順番を指定)などが主な設定項目です。nn.Linear: 全結合層や線形層とも呼ばれ、入力されたベクトルに対して線形変換(行列を掛けてバイアスを足す計算)を行い、出力ベクトルを生成します。分類問題では、最終層で各クラスに属する確率(の元になるスコア)を出力するためによく使われます。in_features(入力ベクトルの次元数)とout_features(出力ベクトルの次元数)を設定します。nn.Dropout: 学習時に、指定された確率でランダムに一部のニューロン(神経細胞のようなもの)の接続を一時的に「切断」する層です。これにより、モデルが特定のニューロンに過度に依存するのを防ぎ、未知のデータに対する汎化性能を高める(過学習を抑制する)効果が期待できます。pでドロップアウトする確率を指定します。forward(self, text_batch)メソッド:nn.Moduleを継承したクラスで必ず定義する必要があるメソッドで、モデルにデータが入力されたときに、具体的にどのような計算処理を経て出力に至るのか、その「データの流れ」を記述します。- 隠れ状態 (Hidden State): RNNやLSTMが系列データを処理する過程で、過去の情報を要約して保持している内部的なベクトルです。LSTMでは、短期的な記憶や現在の文脈情報を反映し、出力の計算にも使われます。
- セル状態 (Cell State): LSTMに特有の、情報を長期的に保持するための専用の経路です。忘却ゲートや入力ゲートによって、このセル状態の内容がダイナミックに更新されていきます。
bidirectional=True: LSTM層の設定でこれをTrueにすると、通常の順方向(文頭から文末へ)の処理に加えて、逆方向(文末から文頭へ)からも情報を処理し、両方の情報を統合して文脈理解を深めようとします。よりリッチな表現が得られる反面、計算コストは増加します。torch.no_grad(): このwithブロック内で行われるPyTorchの計算では、勾配(学習に必要な情報)の計算が一時的にオフになります。これにより、メモリ使用量を削減し、計算速度を向上させることができます。モデルの学習が不要な推論時や、今回のような動作確認の際に非常に役立ちます。
これらの部品と概念を理解しておけば、これから先、もっと複雑なAIモデルに出会ったときも、きっと臆することなくその構造を読み解いていけるはずですよ!
5. 学習処理の実装:AIモデルに「魂」を吹き込む!
さて、前のセクションで、私たちの手でLSTMモデルというAIの「体」を無事に組み立てることができましたね! まるで、ピカピカのロボットが完成したような気分でしょうか。でも、この時点ではまだ、このロボットはただの置物。どうやって動けばいいのか、何をすれば褒められるのか、何も知らない状態なんです。ここからが、AI開発のもう一つの、そして非常に重要な山場、「学習処理」の始まりです! この学習プロセスを通じて、私たちはモデルに大量のデータ(お手本)を見せ、モデルが賢く成長していくように、いわば「魂」を吹き込んでいくのです。
この学習処理を実装するには、大きく分けて2つの大切な要素を決める必要があります。それは、「損失関数 (Loss Function)」と「最適化アルゴリズム (Optimizer)」の選定、そして、実際に学習を何度も繰り返す「学習ループ (Training Loop)」の作成です。なんだか難しそうに聞こえるかもしれませんが、一つ一つ見ていけば大丈夫。一緒にモデルを育てていきましょう!
5.1. 損失関数と最適化アルゴリズム:AIの「成績表」と「熱血コーチ」
AIモデルを学習させるというのは、例えるなら、モデルにたくさんの問題(入力データ)を解かせて、その答え(予測)がどれだけ正解に近いかを評価し、間違っていたら「こうすればもっと良くなるよ」と教えてあげる、という作業の繰り返しです。この「評価」と「教える」役割を担ってくれるのが、損失関数と最適化アルゴリズムなんですよ。
- 損失関数 (Loss Function):「モデル君、今回のテストは何点だったかな?」と評価する係 モデルが予測を出したとき、それが実際の正解ラベルとどれだけ「ズレているか」を測るための物差しが、この損失関数です。この「ズレ」が大きいほど、損失関数の値は大きくなります。つまり、モデルの成績が悪い、ということですね。逆に、予測が正解に近ければ近いほど、損失関数の値は小さくなります。学習の目標は、この損失関数の値をできるだけ小さくすること、つまりモデルの「間違い」を最小限に抑えることなんです。 今回のような、複数の選択肢(今回は「内科」「外科」「眼科」の3つの診療科)の中から正しいものを一つ選ぶ「多クラス分類タスク」では、一般的に「クロスエントロピー損失 (Cross-Entropy Loss)」という損失関数がよく用いられます。これは、モデルが出した各クラスに対する「自信度(確率のようなもの)」と、実際の正解(例えば「内科」が正解なら、「内科」の確率が1で他は0)との間の「情報のズレ具合」を測るのに適しているからなんですね。PyTorchでは、
nn.CrossEntropyLossという便利なクラスが用意されています。面白いことに、このnn.CrossEntropyLossは、モデルの最終出力層でよく使われる「ソフトマックス関数(各クラスのスコアを合計1になるような確率値に変換する関数)」の計算も内部で一緒に行ってくれるので、私たちのモデル設計(前のセクションのTextLSTMClassifier)の出力層には、別途ソフトマックス関数を入れる必要がないんですよ。ちょっとお得な感じですね! - 最適化アルゴリズム (Optimizer):「よし、次はこうやって改善しよう!」と導く熱血コーチ 損失関数でモデルの間違い度合い(損失)が分かったら、次はその間違いを減らすように、モデルの内部のパラメータ(たくさんの重み \(W\) やバイアス \(b\) のことでしたね)を調整してあげる必要があります。この「どうやってパラメータを調整すれば損失が小さくなるか」という具体的な更新方法を指示し、実行してくれるのが、最適化アルゴリズム、略してオプティマイザです。まるで、テストの点数が悪かった生徒(モデル)に対して、「君の弱点はここだから、次はこういう勉強法(パラメータ調整)で頑張ってみよう!」と指導してくれる熱血コーチのような存在ですね。 世の中には色々な個性を持ったコーチ(オプティマイザ)がいるのですが、今回はその中でも特に人気が高く、多くの場合で安定して良い成績を出してくれる「Adam (Adaptive Moment Estimation)」というアルゴリズムを使ってみましょう。Adamコーチは、過去の学習の様子(勾配の平均やばらつき)を考慮しながら、生徒一人ひとり(パラメータごと)に最適な学習の進め方(学習率)をある程度自動で調整してくれる、かなり賢くて頼りになるコーチなんです。PyTorchでは、
optim.Adamとして簡単に呼び出すことができます。 このコーチに指示を出す上で、私たちが一つだけ決めてあげないといけない重要な「ツマミ」があります。それが「学習率 (Learning Rate)」です。これは、コーチが生徒に「一度にどれくらいの幅で改善しなさい」と指示するか、その「一歩の大きさ」を決めるものです。学習率が大きすぎると、改善しようとしすぎて逆に目標から遠ざかってしまったり(学習が発散する、と言います)、小さすぎると、いつまで経ってもなかなか目標にたどり着けなかったり(学習が非常に遅い、あるいは途中でサボってしまう「局所解」に陥る)してしまいます。この学習率の調整は、AIの性能を左右するとてもデリケートな部分で、まさに職人技が光るところでもあるんですよ。今回は、まずは一般的な値として0.001から始めてみましょう。
では、これらの「成績評価係」と「熱血コーチ」を、Pythonコードで準備しましょう!
# --- 5.1. 損失関数と最適化アルゴリズムを準備しましょう! ---
# まずは「成績評価係」である損失関数から。
# 今回は多クラス分類なので、クロスエントロピー損失 (nn.CrossEntropyLoss) を使います。
# この子は、モデルの出力層にソフトマックス関数を適用する処理も内部でやってくれる賢い子です。
criterion = nn.CrossEntropyLoss() # criterion(クライテリオン:基準)という変数名でインスタンス化するのが慣例です。
# 次に「熱血コーチ」である最適化アルゴリズムです。
# 今回は賢くて頼りになるAdamさん (optim.Adam) を採用!
# コーチには、どの生徒(モデルのどのパラメータ)を指導するか (model.parameters()) と、
# 指導の厳しさ(学習率 lr)を教えてあげる必要があります。
LEARNING_RATE = 0.001 # 学習率。最初はこれくらいから試してみることが多いです。
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE) # modelは前のセクションで作った私たちのLSTMモデルのインスタンスです。
print(f"損失関数として {type(criterion).__name__} を、")
print(f"最適化アルゴリズムとして {type(optimizer).__name__} を準備しました。学習率: {LEARNING_RATE}")
これで、モデルの成績を測る道具と、モデルを成長させるための指導者が揃いました。いよいよ、実際にモデルを鍛え上げる「学習ループ」の作成に進みます!
5.2. 学習ループ:AIモデルの「反復練習」ドリル!
さあ、いよいよモデルの「筋トレ」であり「反復練習ドリル」である、学習ループを実装していきますよ! AIの学習というのは、基本的に同じような処理を何度も何度も、それこそ何十回、何百回(時にはそれ以上!)と繰り返すことで、モデルが少しずつデータの中にあるパターンを掴み、賢くなっていくプロセスなんです。
この「繰り返し」の基本的な単位が「エポック (Epoch)」です。1エポックとは、私たちが用意した学習データセット全体(教科書全体みたいなものですね)を、モデルが一通り学習し終えた、という区切りを指します。もちろん、教科書を1回読んだだけではなかなか全てを覚えられないのと同じで、AIモデルも通常、何エポックも学習を繰り返すことで、より高い性能を目指します。
そして、1エポックの中でも、教科書全体を一度にドサッとモデルに見せるのではなく、もう少し扱いやすい小さな束(これを「ミニバッチ (Mini-batch)」と言います)に分けて、少しずつモデルに与えて学習させていくのが一般的です。これは、一度に大量のデータを処理しようとするとコンピュータのメモリが足りなくなってしまう、という現実的な理由もありますし、また、少しずつ色々なパターンのデータを見せることで、学習がよりスムーズに進みやすい、という効果も期待できるからなんですね。このミニバッチのサイズ(一度に何個のデータを見るか)を「バッチサイズ (Batch Size)」と呼びます。
PyTorchでは、このデータセットの管理(「私たちの手作りデータセットはこれですよ」と教える)と、そこからミニバッチを効率的に取り出してくる作業(「じゃあ、次はこのお弁当ね」と供給する)を、それぞれDatasetクラスとDataLoaderクラスという、とっても便利な道具が手伝ってくれます。まずは、私たちの手作りデータセット(Xとyでしたね)を、PyTorchが理解できる形、いわば「PyTorch特製お弁当箱」に詰める作業から始めましょう。そのために、MedicalTextDatasetという名前のカスタムクラスを作ります。
# --- PyTorch特製お弁当箱 (Dataset) と給食当番 (DataLoader) の準備 ---
# まずは、私たちのデータ(X:入力テキストID列、y:正解ラベルID)を
# PyTorchが扱いやすい形に詰めるための「お弁当箱の設計図」(Datasetクラス)を作ります。
class MedicalTextDataset(Dataset): # torch.utils.data.Dataset クラスの機能を「お借りします」と宣言
# このお弁当箱が作られるとき(インスタンス化されるとき)に、食材(データ)を渡します。
def __init__(self, texts_tensor, labels_tensor):
# texts_tensor: 入力テキストデータのテンソル (形状: データ数, 系列長)
# labels_tensor: 正解ラベルのテンソル (形状: データ数)
self.texts = texts_tensor # 材料のテキストデータを、お弁当箱の中に保存
self.labels = labels_tensor # 材料の正解ラベルも、お弁当箱の中に保存
# このお弁当箱に「全部で何個お弁当が入ってるの?」と聞かれたときに答えるための関数。
def __len__(self):
return len(self.labels) # 正解ラベルの数 = お弁当の総数、ですね。
# このお弁当箱に「じゃあ、idx番目のお弁当ちょうだい!」と頼まれたときに、
# 対応する入力テキストと正解ラベルのペアを渡すための関数。
def __getitem__(self, idx):
return self.texts[idx], self.labels[idx] # idx番目のテキストとラベルをセットで「はい、どうぞ」。
# 作ったお弁当箱の設計図を使って、実際にお弁当箱(Datasetのインスタンス)を作ります。
# 食材は、前処理で作った X (入力テンソル) と y (ラベルテンソル) です。
dataset = MedicalTextDataset(X, y)
# 次に「給食当番」(DataLoader)の準備です。
# この給食当番は、お弁当箱(dataset)から、一度に食べる分だけ(batch_size)取り分けてくれます。
# shuffle=True にしておくと、エポックごとにデータの順番をランダムにかき混ぜてくれるので、
# モデルがデータの出てくる順番に変に慣れてしまう(過学習の一因)のを防ぐ効果があります。
BATCH_SIZE = 2 # 1回に2個ずつお弁当(データ)をモデルに見せることにしましょう。
# (今回はデータが10個しかないので非常に小さいですが、実際はもっと大きな値にします)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
print(f"お弁当箱に {len(dataset)} 個のデータ(お弁当)を詰め、")
print(f"給食当番が一度に {BATCH_SIZE} 個ずつ配膳する準備ができました。")
よし、これで学習に必要なデータ供給の仕組みも整いました! いよいよ、学習ループ本体の構築です。学習ループでは、大まかに言って、エポックごとに以下のステップを繰り返します。
【学習ループの1ステップ(1バッチ分の処理)って何してるの?】
テキストベース図
+---------------------------------+
│ データローダーから │
│ お弁当(ミニバッチ)を取り出す │
+---------------------------------+
│ (入力データ batch_texts, 正解ラベル batch_labels)
▼
+---------------------------------+
│ モデルを「学習モード」に設定! │◀―― model.train()
│ (ドロップアウト等を有効にする) │
+---------------------------------+
│
▼
+---------------------------------+
│ 前回の「反省点」をリセット! │◀―― optimizer.zero_grad()
│ (勾配情報をクリアする) │
+---------------------------------+
│
▼
+-----------------------▶ +---------------------------------+
│ │ モデルに問題を解かせる │
│ │ predictions = model(batch_texts)│◀―― フォワードパス
│ 何度も繰り返す +---------------------------------+
│ (全バッチ処理するまで) │ (モデルの予測結果)
│ ▼
│ +---------------------------------+
│ │ モデルの答えと本当の答えを見比べ│
│ │ loss = criterion(predictions, │◀―― 損失計算
│ │ batch_labels) │
│ +---------------------------------+
│ │ (どれだけ間違えたか)
│ ▼
│ +---------------------------------+
│ │ 間違いの原因を分析! │
│ │ (どこをどう直せば良かったか) │◀―― loss.backward() (誤差逆伝播)
│ +---------------------------------+
│ │ (各パラメータへの勾配)
│ ▼
│ +---------------------------------+
│ │ コーチの指示でモデルを修正! │◀―― optimizer.step()
│ │ (パラメータを更新する) │
+-------------------------+---------------------------------+
│
▼
+---------------------------------+
│ (次のバッチへ or 次のエポックへ)│
+---------------------------------+
この図にあるように、一つ一つのミニバッチに対して、モデルに予測させて、その予測と正解を比べて損失を計算し、その損失を元にモデルのパラメータを少しだけ更新する、というサイクルを回していくんですね。それでは、この流れをコードにしてみましょう!
graph TD
subgraph "学習フェーズ (エポック単位で反復)"
A["1. エポック開始
モデルを学習モードに設定"]
subgraph "ミニバッチ処理 (データセットを一周するまで反復)"
B["a. 勾配リセット"]
C["b. 予測実行 (フォワードパス)"]
D["c. 損失を計算"]
E["d. 誤差を逆伝播 (勾配計算)"]
F["e. パラメータを更新"]
end
G["2. エポック終了
平均損失・正解率を計算・表示"]
end
subgraph "評価フェーズ"
H["1. モデルを評価モードに設定"]
I["2. テストデータで予測
(勾配計算なし)"]
J["3. 予測結果を正解と比較・表示"]
end
%% フローの接続
A --> B
B --> C --> D --> E --> F
F --> G
G --> H
H --> I --> J
# --- いよいよ学習ループの始まりです! モデルの「反復練習ドリル」開始! ---
NUM_EPOCHS = 50 # 教科書(全学習データ)を何周するか(エポック数)。
# 今回はデータが非常に少ないので、多めに50周してみます。
# 実際には、検証データを見ながら適切なエポック数を見極めます。
print(f"\n--- 学習開始! 全 {NUM_EPOCHS} エポックのトレーニングを行います ---")
for epoch in range(NUM_EPOCHS): # 指定したエポック数だけ、このループを繰り返します
# --- 1エポックの開始 ---
model.train() # モデルに「今から学習モードですよ!」と伝えます。
# これにより、Dropout層などが学習時特有の振る舞いをするようになります。
epoch_loss = 0.0 # このエポックで発生した損失の合計を記録する変数
epoch_corrects = 0 # このエポックで正解したサンプル数を記録する変数
total_samples_in_epoch = 0 # このエポックで処理した総サンプル数を記録する変数
# DataLoader(給食当番)から、ミニバッチ単位でお弁当(データ)を取り出してループ処理します
for batch_texts, batch_labels in dataloader:
# batch_texts: 形状 (BATCH_SIZE, 最大系列長) の入力テキストIDテンソル
# batch_labels: 形状 (BATCH_SIZE) の正解ラベルIDテンソル
# 1. 前回の勾配情報をリセット! (超重要!)
# これをやらないと、前回のミニバッチの時の「反省点」が残ったままになってしまい、
# 学習が正しく進みません。毎回、ノートを真っさらにするイメージですね。
# 私も最初はよくこれを書き忘れて「なんで学習しないんだー!」って悩みました(笑)
optimizer.zero_grad()
# 2. モデルに問題(入力バッチ)を解かせて、答え(予測スコア)を出させます (フォワードパス)
predictions = model(batch_texts)
# predictions の形状は (BATCH_SIZE, クラス数) になっているはずです。
# 3. モデルの答えと本当の答えを見比べて、どれだけ間違えたか(損失)を計算します
loss = criterion(predictions, batch_labels)
# 4. この「間違い(損失)」を元に、モデルのどこをどう直せば良かったのか、
# 各パラメータへの「反省点(勾配)」を自動で計算します (誤差逆伝播法)
loss.backward()
# 5. 熱血コーチ(オプティマイザ)が、計算された反省点(勾配)に従って、
# モデルの各パラメータを少しだけ賢くなるように修正(更新)します
optimizer.step()
# --- このバッチでの学習状況を記録 ---
# loss.item() で、テンソル形式の損失からPythonの数値を取り出せます。
# バッチのサンプル数を掛けているのは、後でエポック全体の平均損失を出すためです。
epoch_loss += loss.item() * batch_texts.size(0)
# 予測されたクラスID(最もスコアが高いクラスのインデックス)を取得します
# torch.max(predictions, 1) は、predictionsの各行(次元1)ごとに最大値とそのインデックスを返します。
# ここではインデックスだけが欲しいので、 _ (アンダースコア)で最大値自体は無視しています。
_, predicted_ids = torch.max(predictions, 1)
# 予測が正解ラベルと一致した数を数え上げます
epoch_corrects += torch.sum(predicted_ids == batch_labels).item()
total_samples_in_epoch += batch_labels.size(0) # このバッチで処理したサンプル数を加算
# --- 1エポックの終了 ---
# このエポックでの平均損失と平均正解率を計算して表示します
avg_epoch_loss = epoch_loss / total_samples_in_epoch
epoch_accuracy = epoch_corrects / total_samples_in_epoch
# f-stringを使って、見やすく整形して表示します
print(f"エポック {epoch+1:2d}/{NUM_EPOCHS} | 平均損失: {avg_epoch_loss:.4f} | 正解率: {epoch_accuracy:.4f}")
print("--- 学習終了! お疲れ様でした! ---")
# --- 学習が終わったモデルで、ちょっとだけ予測を試してみましょう (簡単な評価) ---
model.eval() # モデルに「今度はテストモードですよ!」と伝えます。
# これにより、Dropout層などが推論時特有の(つまり、ランダム性をオフにした)振る舞いになります。
# torch.no_grad() のブロック内では、勾配計算が一時的にオフになります。
# テスト(推論)の時は新しいことを覚える必要はないので、勾配計算は不要ですよね。
# これにより、メモリ使用量を節約でき、計算も少し速くなります。
with torch.no_grad():
# 学習に使ったデータの中から、最初の5件だけ取り出して試してみましょう
# (本当は学習に使っていない「テストデータ」で評価すべきですが、今回はお試しなので)
test_texts_tensor = X[0:5] # 入力データの最初の5件
test_labels_tensor = y[0:5] # 対応する正解ラベルの最初の5件
outputs = model(test_texts_tensor) # モデルにテストデータを入力し、予測スコアを取得
_, predicted_labels = torch.max(outputs, 1) # 最もスコアが高いクラスを予測ラベルとする
print("\n--- 簡単な予測テストの結果 (学習データの一部を使用) ---")
for i in range(len(test_texts_tensor)):
original_text = texts[i] # 元のテキスト(トークン化する前の文章)
true_label_str = id_to_label[test_labels_tensor[i].item()] # 正解ラベルを文字列に戻す
predicted_label_str = id_to_label[predicted_labels[i].item()] # 予測ラベルを文字列に戻す
print(f"\n原文: 「{original_text}」")
print(f" 正解ラベル: {true_label_str}")
print(f" モデルの予測: {predicted_label_str}")
if true_label_str == predicted_label_str:
print(" -> お見事、正解です!")
else:
# outputs[i].numpy() で、そのサンプルに対する各クラスの生のスコアを見てみましょう
print(f" -> 残念、不正解… (各クラスのスコア: {outputs[i].numpy()})")
このコードを実行すると、学習の各エポックで「平均損失」と「正解率」がどのように変化していくかが出力されるはずです。最初はメチャクチャな予測しかできなかったモデルが、エポックを重ねるごとに損失が減り、正解率が上がっていく様子が観察できたら、学習が上手く進んでいる証拠ですね! 例えば、こんな出力が得られるかもしれません(数値は実行ごとに多少変わります)。
--- 学習開始! 全 50 エポックのトレーニングを行います ---
エポック 1/50 | 平均損失: 1.1192 | 正解率: 0.2000
エポック 2/50 | 平均損失: 1.0595 | 正解率: 0.4000
... (中略) ...
エポック 49/50 | 平均損失: 0.0045 | 正解率: 1.0000
エポック 50/50 | 平均損失: 0.0033 | 正解率: 1.0000
--- 学習終了! お疲れ様でした! ---
--- 簡単な予測テストの結果 (学習データの一部を使用) ---
原文: 「熱があり、咳と喉の痛みがあります。」
正解ラベル: 内科
モデルの予測: 内科
-> お見事、正解です!
原文: 「お腹が急に痛み出し、吐き気もします。」
正解ラベル: 内科
モデルの予測: 内科
-> お見事、正解です!
... (以下略) ...
ただし、ここで一つ、とっても大切な注意点があります! 今回のサンプルコードは、ものすごーく小さなデータセット(たった10個の文章!)で学習とテストを行っています。そのため、上の例のように、学習データに対する正解率が簡単に100%に達してしまうことがよくあります。これは、モデルが賢くなったというよりは、むしろ「テストに出る問題と答えを丸暗記しちゃった」状態、いわゆる「過学習 (Overfitting)」に陥っている可能性が高いんです。丸暗記が得意な生徒は、定期テストでは高得点を取れるかもしれませんが、範囲外の応用問題(未知の新しいデータ)が出ると、途端に手も足も出なくなってしまいますよね。AIモデルも全く同じです。
実際の医療応用を目指す上では、この過学習を防ぎ、本当に「賢い」(つまり、未知のデータに対しても高い性能を発揮できる「汎化性能」が高い)モデルを育てるために、以下のような点が非常に重要になってきます。これらの点については、本シリーズの後の回(特に第13回や第16回など)で、もっと詳しく触れていきますので、今は「ふむふむ、そういう大事なポイントがあるんだな」と頭の片隅に置いておいてくださいね。
- 大規模で質の高い、多様なデータセットの準備: やはり、AIモデルの性能は、元になるデータの「量」と「質」に大きく左右されます。偏りが少なく、様々なパターンの情報を含んだ、できるだけたくさんのデータで学習させることが基本です。
- 適切なデータ分割(訓練・検証・テスト): 用意したデータ全てを学習に使ってしまうと、モデルが本当に新しいデータに対応できるかどうかが分かりません。そのため、通常はデータを「訓練用データ(モデルが勉強する教科書)」「検証用データ(学習の途中でモデルの調子を見るための模擬試験)」「テスト用データ(最終的にモデルの実力を測る本番の試験)」の3つに分割して使います。
- ハイパーパラメータの念入りな調整: 今回決めた学習率、バッチサイズ、LSTMの隠れ層の次元数、層の数といったハイパーパラメータは、実は「これぞ正解!」という万能な値は存在しません。データの特性やモデルの構造によって最適な値は変わってくるので、検証用データの性能を見ながら、根気強く調整していく作業(チューニングと言います)が必要になります。
- 適切な評価指標の選択: 単純な「正解率」だけを見ていると、時々モデルの本当の実力を見誤ることがあります。特に医療の分野では、例えば「見逃しをどれだけ減らせたか(再現率)」や「誤って陽性と判断しなかったか(適合率)」といった、タスクの目的に応じた、よりきめ細かい評価指標(F1スコア、混同行列、AUCなど。本シリーズ第12回参照)を使って、多角的にモデルの性能を評価することが大切です。
ふぅ、学習処理の実装、いかがでしたでしょうか? ちょっとコードも長くなって、新しい概念もたくさん出てきましたが、AIモデルが「学習する」とはどういうことか、その具体的なステップや注意点が、少しでもクリアになっていれば嬉しいです。次はいよいよ、この学習させたモデルを使って、もう少し詳しく結果を分析したり、医療応用への夢を膨らませたりするセクションに進みますよ!
6. 結果の解釈と医療応用への示唆:小さな一歩から大きな未来へ
さて、前のセクションでは、私たちが手塩にかけて育てた(?)小さなLSTMモデルが、短い症状の記述から関連する診療科を予測しようと頑張ってくれる様子を見ましたね。学習データでは、最終的にかなり高い正解率を出してくれて、「お、なかなかやるじゃないか!」と少し嬉しくなったのではないでしょうか。もちろん、思い出してください、あれは非常に小さな、いわば「おままごと」のようなデータセットでの結果です。実際の医療現場で直面するデータの複雑さや多様性を考えると、あのモデルがそのまま通用するわけでは決してありません。でも、あの小さな成功体験は、「もしかしたら、AIって本当に医療の役に立てるかもしれないぞ」という、大きな可能性の扉をほんの少しだけ開けてくれた、そんな風に感じていただけたなら嬉しいです。
では、あのささやかな一歩から、私たちはどんな大きな夢を描くことができるのでしょう? LSTMのような自然言語処理技術が、実際の医療現場で花開いたとしたら、私たちの日常は、そして患者さんの経験は、どのように変わっていくのでしょうか。少し想像の翼を広げてみましょう。
医療現場での応用を考える上での、いくつかのヒント
今回の小さなデモンストレーションで垣間見えた「テキストから何かを読み取る力」。これをスケールアップし、より賢くしていくことで、医療の様々な場面で私たちの強力なサポーターになってくれる可能性が考えられます。
- トリアージ支援:緊急度を要する声に、いち早く気づくために 例えば、夜間の救急外来や、あるいは日中のクリニックの電話窓口。そこには、様々な状態の患者さんからの問い合わせや訴えが、次々と寄せられますよね。「胸が苦しいんです」「昨日から熱があって…」「子供が転んで頭を打ってしまって」。限られた医療スタッフで、これらの声一つひとつに迅速かつ的確に対応していくのは、本当に大変なことだと思います。もし、AIが患者さんの訴えのテキスト(あるいは音声認識でテキスト化されたもの)を瞬時に解析し、その言葉の選び方、症状の深刻さ、緊急性などを客観的に評価して、「この方は重症度が高いかもしれません、優先的な対応を検討してください」とか「この症状であれば、まずはオンライン相談や近隣のAクリニックへの受診をご案内してはいかがでしょうか」といった形で、そっと医療スタッフに助言をしてくれたらどうでしょう? 受付業務の効率化はもちろん、何よりも緊急を要する患者さんへの対応の遅れを防ぎ、より多くの命を救うための一助となるかもしれませんね。患者さんにとっても、自分の状況が迅速に理解され、適切なアクションに繋がる安心感は大きいのではないでしょうか。
- 診療記録の構造化:情報の海から「宝」を掘り起こす 電子カルテに日々蓄積されていく膨大な診療記録。その多くは、私たち医療者が自由な言葉で記述したテキストデータです。ここには、患者さんの詳細な病状、治療の経過、検査結果の解釈、そして私たちの臨床的な思考プロセスそのものが、まるで航海日誌のように記録されています。まさに「情報の宝庫」なのですが、その情報が必要な時にすぐに見つからなかったり、あるいは特定の条件(例えば「〇〇という薬を使い始めてから△△という症状が出た患者さん」)に合致する記録を網羅的に探し出すのが非常に困難だったりするのも、また事実ですよね。「あれ、あの患者さんの、あの時のあの検査結果、どこに書いてあったかな…」と、カルテのページを延々とスクロールしたり、検索キーワードをあれこれ変えてみたり…そんな経験、きっと皆さんにもおありだと思います。 LSTMのようなNLP技術は、この「情報の海」から、私たちが必要とする「宝」、つまり重要な情報を自動的に抽出し、構造化されたデータ(例えば、データベースの特定の項目に整理された形)として整理整頓するお手伝いができるかもしれません(2)。AIが「先生、お探しの『〇〇という症状』に関する記述は、この日の記録のこの部分ですね。関連する可能性のある他の情報も、こちらにまとめておきましたよ」と、まるで優秀な図書館の司書のように、あるいは臨床研究の頼れるアシスタントのようにサポートしてくれたら、どうでしょう? 例えば、「△△という新しい治療法を試した患者さんグループと、従来治療のグループで、その後のQOL(生活の質)にどんな違いが見られたか」といった臨床研究も、格段に効率的に、そしてより大規模に行えるようになるかもしれません。日々の診療の質が向上するだけでなく、新しい医学的知見の発見が加速される、そんな未来も夢ではないかもしれませんね。
- 副作用・有害事象の早期発見:見過ごされがちな「小さなサイン」を捉えるために 新しい医薬品の登場は、多くの患者さんに希望をもたらしますが、同時に、予期せぬ副作用や有害事象のリスクも伴います。これらを早期に発見し、適切に対応することは、医療安全において極めて重要です。診療記録や、患者さん自身からの服薬後の体調変化に関する報告テキスト(最近では、患者さんがアプリなどを通じて積極的に情報発信するケースも増えていますよね)を、AIが継続的にモニタリングし、特定の薬剤と関連する可能性のある副作用の微かな兆候(例えば、特定の単語やフレーズの出現頻度の変化、これまで報告されていなかった症状の組み合わせなど)を、人間の目では捉えきれないレベルで検知することができたら…(6)。もしかしたら、それは重篤な副作用が発生する前の、本当に「小さなサイン」かもしれません。AIが「この薬剤を服用開始後、この種の訴えが増加傾向にあります。関連性を調査する必要があるかもしれません」とアラートを上げてくれることで、早期の介入や、より詳細な安全性情報の収集、そして必要であれば迅速な注意喚起へと繋がり、多くの患者さんを潜在的なリスクから守ることができるかもしれません。
- 医療従事者の負担軽減:もっと「人にしかできない仕事」に集中するために 医療現場は、日々、本当に多くの業務に追われています。その中には、診断や治療といった高度な専門知識と思考を要する仕事もあれば、定型的な報告書の作成、過去の診療情報の検索、あるいは患者さんからのよくある質問への対応といった、ある程度パターン化できる作業も少なくないのではないでしょうか。もし、AIが後者のようなタスクの一部を、正確かつ効率的に肩代わりしてくれるようになったら、どうでしょう? 例えば、検査結果の数値と画像所見のテキストから、報告書のドラフトを自動生成してくれたり、あるいは関連ガイドラインや過去の類似症例の情報を、必要な時にサッと提示してくれたり。そうすれば、私たち医療従事者は、事務的な作業に費やす時間を減らし、その分、もっと患者さん一人ひとりとじっくり向き合う時間や、新しい知識や技術を学ぶための時間、あるいは複雑な症例についてチームで深く議論する時間を確保できるようになるかもしれません。AIは決して医療者に取って代わるものではなく、むしろ医療者が、より人間らしい、創造的で温かい医療を提供するための、強力なパートナーになり得るのだと、私は考えています。
限界と今後の発展:夢を現実に変えるために、私たちが乗り越えるべき壁
ここまで、LSTMが拓く医療NLPの明るい未来について、たくさんの夢を語ってきました。ですが、もちろん、これらの夢を現実のものにするためには、まだまだ乗り越えなければならない壁もたくさんあります。今回の私たちの小さなモデルが、ほんの数行の症状記述から診療科を予測しようと健気に頑張ってくれたように、現在のAI技術もまた、発展途上のチャレンジャーなんです。具体的にどんな壁があって、それを乗り越えるためにどんな努力がなされているのか、少しだけ見ていきましょう。これは、私たちがAIを過信せず、適切に理解し、そして賢く育てていくために、とても大切な視点だと思います。
- 文脈理解の深化:「行間を読む」AIへの道は、まだ半ば 今回の私たちのモデルは、本当に短い文章しか扱えませんでしたし、その「読解力」も、まだまだ赤ちゃんのようだったと言えるでしょう。しかし、実際の医療文書、例えば詳細な退院時サマリーや、複数の専門医が関わった複雑な症例のカンファレンス記録などを読んでみると、その情報量は膨大で、文脈は幾重にも絡み合っています。まるで、数ページの短編小説と、何十巻にも及ぶ壮大な大河ドラマくらいの違いがあるかもしれません。現在のLSTMも、ある程度の長さの文脈は記憶できますが、本当に長い文書全体にわたる伏線や、非常に遠く離れた部分にある情報同士の複雑な関連性を完璧に捉えきることは、まだ得意とは言えません。だからこそ、研究者たちは、より記憶力が良く、より深い読解力を持つAIを目指して、例えば文章を順方向と逆方向の両方から読んで文脈理解を深める「双方向LSTM (Bidirectional LSTM)」や、文章の中の「今、特にこの部分が重要だよ!」とAI自身が注目すべきポイントに重み付けをする「アテンション機構 (Attention Mechanism)」、そして最近では、このアテンション機構をさらに進化させ、自然言語処理の世界に革命をもたらしたと言われる「Transformer(トランスフォーマー)」(本シリーズ第22回で詳しくお話ししますね!)といった、より高度でパワフルなモデル構造の開発に、日夜取り組んでいるのです(7, 8)。これらの新しい技術によって、AIがまるで経験豊かな臨床医のように、複雑な医療文書の行間まで読み解いてくれる日が来るかもしれませんね。
- 専門用語と曖昧性への対応:医療現場の「言葉の壁」を乗り越える 医療の現場って、本当に独特な専門用語や、アルファベット数文字の略語、あるいは施設や診療科ごとのローカルな言い回しが、まるで共通言語のように飛び交っていますよね。「NS(エヌエス)」と聞けばすぐに「生理食塩水」のことだと分かりますし、「アポ」と聞けば「(外来の)予約」のことだとピンと来る。でも、これらをAIが最初から理解するのは、実はものすごく大変なことなんです。さらに、同じ言葉でも文脈によって意味が変わったり(例えば「モニター」という言葉一つとっても、心電図モニターなのか、治験のモニターなのか、文脈次第ですよね)、あるいは患者さんが使う言葉は、医学的に正確な表現ではなかったり、感情的なニュアンスを多く含んでいたりと、本当に様々です。こういった医療現場特有の「言葉の壁」や「表現の揺れ(曖昧性)」をAIが賢く乗り越えるためには、いくつかの工夫が必要になります。例えば、膨大な医療文献やカルテデータを学習させて、医療分野の言葉の使われ方や専門用語間の関連性を深く理解した「医療ドメイン特化の単語埋め込みモデル」(例えば、BioWordVec (9) や Med-BERT (10) といったものが有名です)を利用したり、あるいはSNOMED-CTやMedDRAといった標準化された医療用語の辞書(シソーラスやオントロジーといった「知識ベース」)とAIを連携させて、言葉の正規化や意味の disambiguation(曖昧性解消)を行ったりするアプローチが研究されています。AIが、まるでその道のベテランのように、医療現場の言葉を使いこなせるようになるには、こうした地道な努力が不可欠なんですね。
- データの機密性と倫理:技術の進歩と「守るべきもの」の調和 そして、どんなに強調してもしすぎることはない、最も重要な課題の一つが、データの機密性と倫理の問題です。私たち医療者が日々扱っている診療情報というのは、患者さんの病気や治療に関する情報だけでなく、その方の人生やプライバシーに深く関わる、この上なくセンシティブな個人情報ですよね。どんなに賢くて便利なAIを開発できたとしても、その過程で、あるいはその結果として、患者さんの大切な情報が万が一にも外部に漏洩したり、不適切に利用されたりするようなことがあっては、絶対にあってはならないことです。これは、技術的な問題であると同時に、私たちの職業倫理の根幹に関わる大原則です。だからこそ、AIモデルの開発や利用にあたっては、例えば、個人を特定できる情報を最初から徹底的に削除・匿名化する処理を施したり、あるいはAIに学習させる際にも、個々のデータの内容が特定できないように特別なノイズを加えたり(これを「差分プライバシー」と言います)、そもそもデータを一箇所に集めずに、各医療機関がデータを保持したまま分散的に学習を行う「連合学習 (Federated Learning)」といったプライバシー保護技術を導入したりと、技術的な対策と厳格な運用ルールの両面から、細心の注意を払い続ける必要があります(11)。技術の進歩は素晴らしいものですが、その進歩が、私たちが守るべき最も大切なもの――患者さんの信頼や尊厳――と常に調和していなければ、真に医療に貢献することはできないのだと、肝に銘じておく必要があると思います。
- 説明可能性(XAI):AIの「思考プロセス」を、私たちにも理解できるように AIが、例えば「この患者さんのカルテを読むと、内科系の疾患の可能性が高いですね」と予測したとして、私たち人間、特に医療の専門家であれば、「え、どうしてそう思ったの? どの部分の記述から、あるいはどんな検査結果から、そう判断したの?」と、その根拠や理由を知りたくなりますよね。特に医療という、人の命や健康に直結する意思決定が求められる分野では、AIが出した答えをただ鵜呑みにするのではなく、その判断プロセスを人間が理解し、検証した上で、最終的な判断は人間の医療者が責任を持って行う、という姿勢が不可欠です。しかし、残念ながら、LSTMのような深層学習モデルは、その内部構造が非常に複雑であるため、なぜそのような予測結果に至ったのか、その具体的な理由を人間が直感的に理解するのが難しい、「ブラックボックス」と見なされることが少なくありません。 そこで今、非常に活発に研究が進められているのが、「説明可能なAI(XAI: Explainable AI)」という分野です(12)。これは、AIの判断根拠を、人間にとって分かりやすい形で提示しようとする技術の総称です。例えば、LSTMが文章を読んで何かを判断した際に、「私はこの文章の中の、特にこの単語やこのフレーズのパターンに注目して、こう判断しましたよ」と、判断に寄与した部分をハイライトして見せてくれたり(アテンションの可視化などがこれにあたります)、あるいは、「過去の似たような症例の、この部分のデータパターンと類似性が高かったためです」といった形で、具体的な類似ケースを提示してくれたりするような技術が開発されています。AIが、単に答えを出すだけでなく、その「思考の道筋」を私たちと共有してくれるようになれば、私たちはAIの判断をより深く吟味し、信頼し、そして最終的にはAIをより賢明な臨床判断のための、真の「協働パートナー」として迎え入れることができるようになるのではないでしょうか。そんな未来に、私は大きな期待を寄せています。
これらの「限界」は、決して私たちを落胆させるためのものではありません。むしろ、これらは私たち研究者や開発者にとって、次なる挑戦へのモチベーションであり、AI技術をさらに磨き上げ、医療の未来をより良いものへと変えていくための、道しるべとなるべきものなのだと思います。そして、その挑戦には、AIの専門家だけでなく、医療現場の最前線で日々奮闘されている皆さん一人ひとりの知恵と経験、そして「こんなことができたらいいな」という熱い思いが、不可欠なのです。
7. まとめ:この章で手にした「言葉を読み解く力」を、次の一歩へ!
いやー、ここまで本当にお疲れ様でした! この第4章では、PyTorchという頼もしい道具を片手に、まるで言葉のパズルを一つひとつ丁寧に解き明かすように、LSTMモデルを一から組み立て、医療の現場で日々生まれるかもしれない「言葉のデータ」を分析する、そのエキサイティングな冒険の第一歩を、皆さんと一緒に踏み出してきました。
生の日本語テキストが、Janomeという形態素解析の名人によって単語に分割され、次にそれらの単語がコンピュータにも理解できる「背番号(単語ID)」へと姿を変え、文章ごとの長さの違いは「パディング」という工夫で吸収され…。そうして整えられた数値の列(テンソルですね!)が、いよいよ私たちが設計したLSTMモデルへと入力され、モデルはその数値の列から一生懸命に意味を学習し、最終的には「この症状の訴えは、何科に関連が深そうかな?」という予測を出そうと奮闘する…。そんな一連のプロセスを、実際に手を動かしながら体験していただけたのではないでしょうか。
もしかしたら、最初は「AIって、どうやって言葉を理解するんだろう?」と、ぼんやりとした霧の中にいたような感覚だったかもしれません。でも、この章を通じて、その霧が少し晴れて、「なるほど、AIはこんな風に、段階を踏んで言葉を扱おうとするのか!」「LSTMのあのゲートの仕組みが、文脈を捉えるのに役立っているんだな」という、具体的なイメージや手応えのようなものを、少しでも掴んでいただけていたら、本当に嬉しいです。特に、あの小さなダミーデータセットでも、モデルが学習を進めるにつれて正解率が上がっていく様子を見たときは、ちょっとした感動があったかもしれませんね(過学習には要注意でしたが!)。
そして何より、この章で皆さんが手にした知識やスキル――テキストデータの前処理のノウハウ、PyTorchを使って系列データを扱うモデル(今回はLSTMでしたが)を基本的ながらも一から組み立てる考え方、そしてLSTMがなぜ文章のような「順番」が大切なデータの理解に強いのかという感覚――これらは、実はものすごく応用範囲の広い、今後皆さんがAIという道具を使いこなしていく上での、強力な「基礎体力」になるはずです。
例えば、電子カルテの中に眠っている膨大な自由記述の記録から、これまで気づかなかった新しい治療効果のヒントや副作用のパターンを掘り起こしたり(医療情報マイニングですね!)。あるいは、世界中から日々発表される膨大な数の医学論文の海の中から、今まさに自分が知りたい情報や、次に読むべき重要な論文を効率的にキャッチしたり(文献検索の自動化や要約)。さらには、患者さんが直接伝えてくれる日々の体調の変化や、生活の中での困りごと、治療への思いといった「生の声」を丁寧に分析して、より一人ひとりに寄り添ったケアプランの作成に活かしたり…。これから先、皆さんが「こんな医療AIがあったらいいな」「この医療課題をAIで解決できないかな」と考え、取り組みたいと思うかもしれない、より高度で専門的な医療AIアプリケーションの開発の、まさに「はじめの一歩」であり「確かな土台」を、この章で皆さんと一緒に築くことができた、と自信を持ってください。
もちろん、このシリーズはまだまだ続きます。次章以降では、さらに進んだモデルのアーキテクチャ(例えば、今回少し触れたTransformerなどですね!)や、より高度な学習テクニック、そしてAIを医療に応用する上での様々な実践的な知恵について、一緒に学んでいくことになります。でも、今回皆さんがLSTMと系列データ処理の基礎と格闘した経験があれば、きっと「あ、これはあの時のLSTMの考え方の応用だな!」「なるほど、あの時学んだ前処理がここでも活きてくるのか!」と、新しい知識がスムーズに、そしてより深く、楽しく吸収していけるはずですよ。
最後に、これは私が常々感じていることなのですが、医療AIという分野は、本当に広大で、日進月歩で進化していて、そして何よりも、信じられないほど大きな可能性に満ち溢れています。でも、忘れてはならないのは、どんなに素晴らしい技術も、それを使う私たち人間の知恵と、倫理観と、そして温かい心が伴って初めて、真に医療の現場で輝きを放ち、最終的には一人でも多くの患者さんの笑顔に繋がるのだということ。AIの仕組みを技術的に深く理解することはもちろん大切ですが、それと同じくらい、実際の医療現場がどんなことに困っていて、何を本当に必要としているのか、その「生の声」に真摯に耳を傾けること。そして、AIという強力なツールを使うことの倫理的な側面や社会的な影響について、常に深く、謙虚に考え続けること。これら全てが揃って初めて、私たちはAIという、時に魔法のようにも見えるこの強力なツールを、本当に正しい方向に、そしてその力を最大限に活かして、医療の未来をより良いものへと変えていくことができるのだと、私は強く信じています。
この『Medical AI with Python』シリーズが、皆さんの知的好奇心を満たし、プログラミングのスキルを高めるだけでなく、そんな技術と心、両方のバランス感覚を養うための一助となれたなら、これ以上の喜びはありません。この章で得た達成感を胸に、ぜひ次の冒険へと進んでいきましょう!
8. 参考文献
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9(8):1735-80.
- Jagannatha AN, Yu H. Structured prediction models for RNN based sequence labeling in clinical text. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas: Association for Computational Linguistics; 2016. p. 856-65.
- Yoon W, Lee S, Kim M, Kim D, Kim K, Kang J. CollaboNet: A new approach for literature-based discovery of gene-disease associations via latent collaborative-filtering. Bioinformatics. 2018;34(13):i361-i369.
- Stanfill M, Lall R, Caskey R, Johnson T, Chui M, Zayas-Cabán T, et al. Active adverse event surveillance in the FDA’s Sentinel System: A chemoinformatic approach. Drug Saf. 2019;42(1):117-27.
- Liang H, Tsui BY, Ni H, Valentim CCS, Baxter SL, Liu G, et al. Evaluation and accurate diagnoses of pediatric diseases using artificial intelligence. Nat Med. 2019;25(3):433-8.
- Zhang T, Lin H, Yang Z, Wang J, Li Y, Xu B. A hybrid deep learning model for automated abstraction of medical information from clinical narratives of breast cancer patients. J Biomed Inform. 2019;94:103187.
- Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: Association for Computational Linguistics; 2014. p. 1724-34.
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Advances in Neural Information Processing Systems 30 (NIPS 2017). Long Beach, CA, USA; 2017. p. 5998-6008.
- Zhang Y, Chen Q, Yang Z, Lin H, Lu Z. BioWordVec, improving biomedical word embeddings with subword information and MeSH. Sci Data. 2019;6:52.
- Lee J, Yoon W, Kim S, Kim D, Kim S, So CH, Kang J. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020;36(4):1234-40.
- Price WN 2nd, Cohen IG. Privacy in the age of medical big data. Nat Med. 2019;25(1):37-43.
- Arrieta AB, Díaz-Rodríguez N, Del Ser J, Bennetot A, Tabik S, Barbado A, et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf Fusion. 2020;58:82-115.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




