

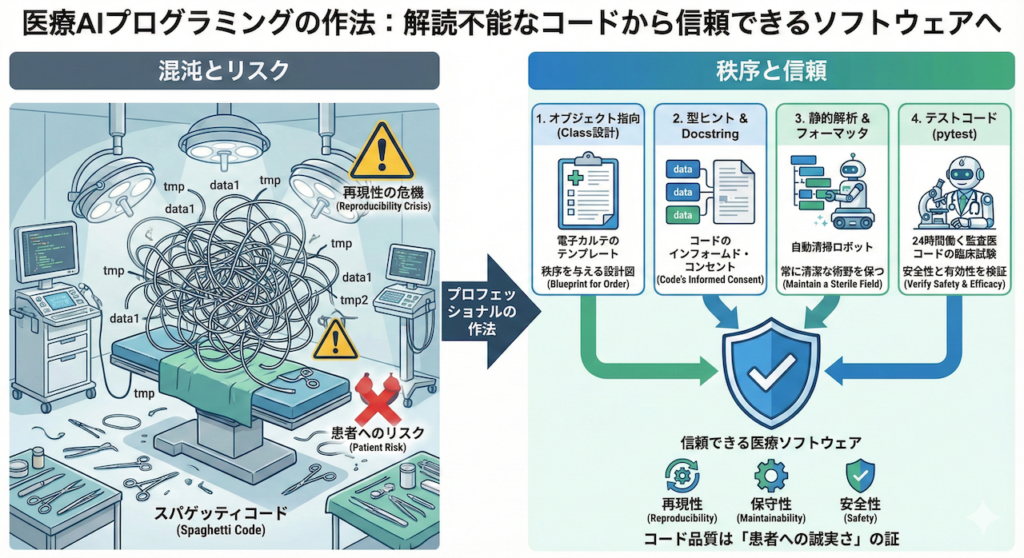
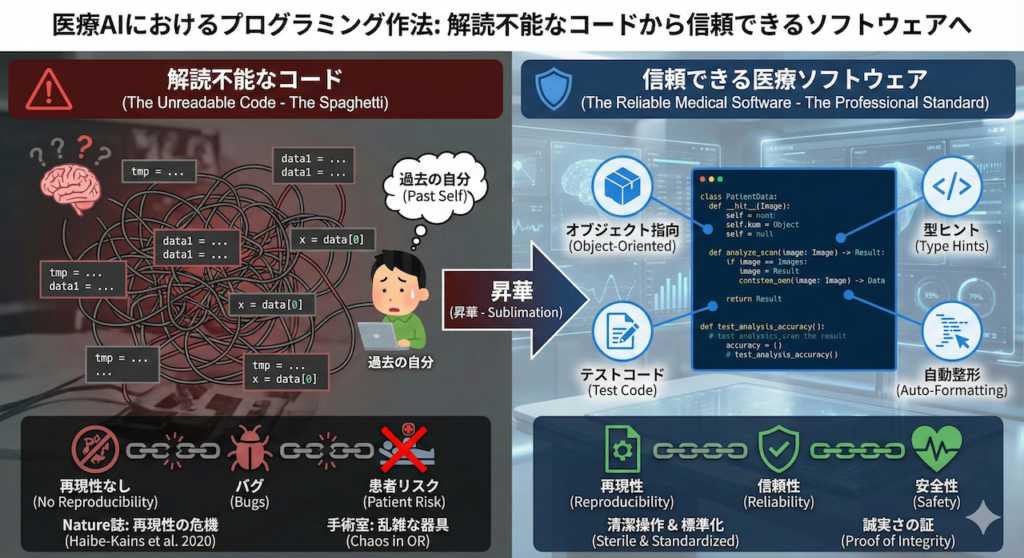
「半年前に自分が書いたコードの意味が全くわからない」。
これは、プログラミングを学ぶ誰もが一度は通る、ほろ苦い通過儀礼のようなものです。変数は tmp や data1 といった意味不明な名前で溢れ、処理はスパゲッティのように絡み合っている――そんな経験はありませんか?
趣味のプログラミングであれば、それは「過去の自分」への戒めで済みます。しかし、医療AI(Medical AI)の研究開発において、この「解読不能なコード」は致命的なリスク要因となります。
なぜなら、コードの可読性が低いことは、単なる時間の浪費に留まらず、研究の「再現性(Reproducibility)」を著しく損なうからです。実際、Nature誌に掲載された研究では、AIモデルの多くがコードやデータの不備により第三者による検証が困難であり、これが科学的進歩を妨げる「再現性の危機」であると警鐘を鳴らしています (Haibe-Kains et al. 2020)。最悪の場合、バグに気づかず誤った解析結果を導き出し、患者への不利益につながる可能性さえ否定できません。
想像してみてください。
手術室で器具が乱雑に散らばり、どのメスが滅菌済みかわからない状態だったらどうでしょうか?
あるいは、電子カルテの記載方法が医師ごとにバラバラで、誰も解読できない状態だったら?
医療現場で「清潔操作」や「標準化されたカルテ記載」が徹底されているように、医療AIのプログラミングにも守るべき「プロフェッショナルの作法(Best Practices)」が存在します。
今回は、あなたの書くPythonコードを「とりあえず動くスクリプト」から、他者が検証可能で、安全かつ堅牢な「信頼できる医療ソフトウェア」へと昇華させるための必須技術について解説します。具体的には、混沌とした処理を整理するオブジェクト指向(クラス設計)、コードの意図を明示する型ヒント、品質を保証するテストコード、そして清潔なコードを保つ自動整形ツールを取り上げます。
これらは一見、遠回りに見えるかもしれません。しかし、急がば回れ。これらの作法を身につけることは、将来のあなた自身と、あなたの研究成果を受け取る医療現場への誠実さの証となるのです。
1. なぜ「動けばいい」ではダメなのか?:医療AIにおける再現性の危機
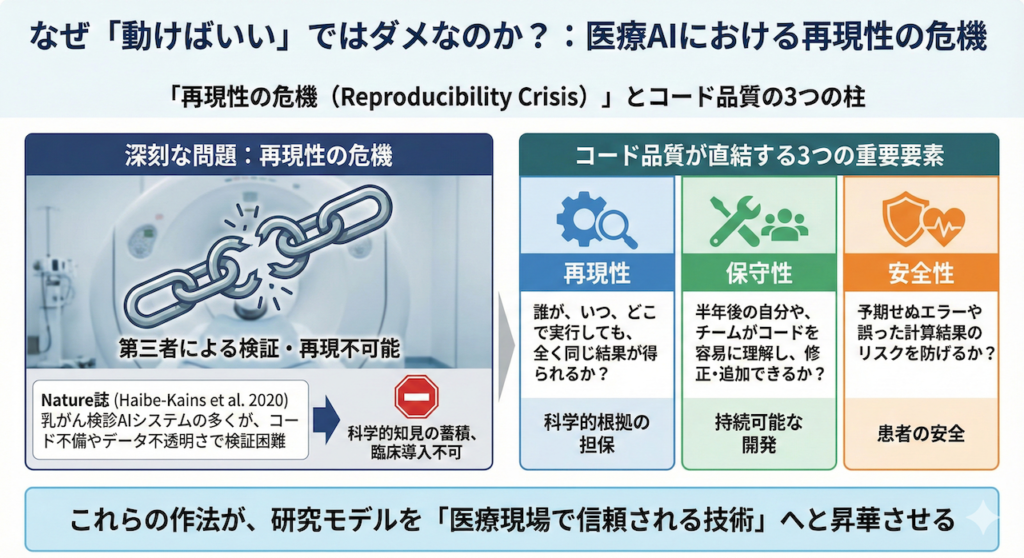
近年、AI研究、とりわけ人命に関わる医療応用において深刻な問題となっているのが「再現性の危機(Reproducibility Crisis)」です。「自分のPCでは動いた」「論文の通りの精度が出た」だけでは、科学として、そして医療機器として不十分なのです。
実際、権威ある科学誌 Nature に掲載された衝撃的な報告があります。そこでは、乳がん検診におけるAIシステムの多くが、コードの不備やデータの不透明さが原因で、第三者による検証や再現が不可能であったと厳しく指摘されています (Haibe-Kains et al. 2020)。再現できない研究は、科学的知見として積み上げることができず、臨床現場への導入も到底叶いません。
なぜ、面倒な作法を守ってまでコードを綺麗に書く必要があるのでしょうか?それは、医療AI開発においてコードの品質が、以下の3つの極めて重要な要素に直結するからです。
- 再現性 (Reproducibility):
誰が、いつ、どこで実行しても、全く同じ結果が得られるか?(科学的根拠の担保) - 保守性 (Maintainability):
半年後の自分や、チームの他のメンバーがコードを読んだ際、容易に理解し、バグの修正や機能追加ができるか?(持続可能な開発) - 安全性 (Safety):
予期せぬエラーでシステムが停止したり、誤った計算結果を医師に提示したりするリスクを防げるか?(患者の安全)
これらを担保し、研究室の実験モデルを「医療現場で信頼される技術」へと昇華させるために不可欠なのが、今回ご紹介する「エンジニアリングの作法」なのです。
2. 混沌に秩序を与える「クラス(Class)」の設計
プログラミング初学者が最初に陥りやすいのが、処理を上から順にだらだらと書き連ねる「手続き型」の記述です。小規模なスクリプトならそれでも動きますが、コードが長くなるにつれ、変数は散乱し、どの変数がどの処理に使われているのか追えなくなります。これはまるで、手術器具と薬剤が分類されずに散乱したオペ室のような状態で、極めて危険(バグの温床)です。
ここで登場するのが、この混沌に秩序をもたらすオブジェクト指向プログラミング (Object-Oriented Programming: OOP) というパラダイムです。
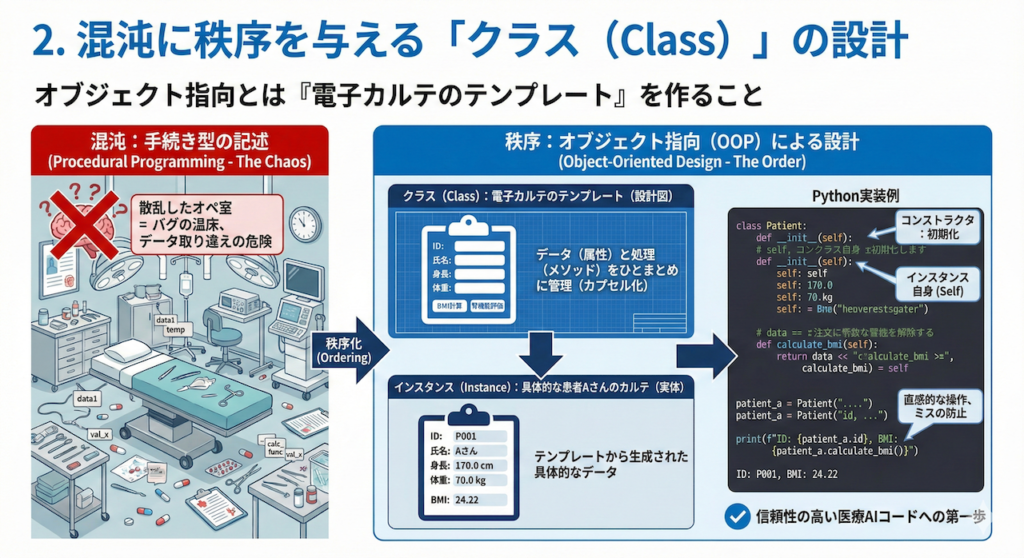
オブジェクト指向とは「電子カルテのテンプレート」を作ること
オブジェクト指向を医療の現場に例えてみましょう。
クラス (Class) とは、「電子カルテのテンプレート(設計図)」のことです。まだ特定の患者の情報は入っていませんが、「氏名」「年齢」「検査値」を記入する欄があり、「BMI計算」や「腎機能評価」といった機能が備わっている型枠です。
一方、インスタンス (Instance) とは、そのテンプレートを使って作成された「具体的な患者Aさんのカルテ(実体)」のことです。
クラスを使う最大のメリットは、「データ(属性)」と「処理(メソッド)」をひとまとめに管理できる(カプセル化)点にあります。例えば、「患者」クラスを作れば、その中に「身長・体重」というデータと、「BMIを計算する」という処理をセットで閉じ込めることができます。これにより、Aさんの身長データを使って誤ってBさんのBMIを計算してしまう、といった取り違えミスを構造的に防ぐことができるのです。
以下に、Pythonでのクラス実装例を示します。__init__ や self といった独特の記法が出てきますが、一つずつコメントで解説します。
import numpy as np
class Patient:
"""
患者情報を管理するクラス(設計図)
属性 (Attributes):
id (str): 患者ID
height_cm (float): 身長 (cm)
weight_kg (float): 体重 (kg)
"""
def __init__(self, patient_id, height_cm, weight_kg):
# __init__ は「コンストラクタ」と呼ばれ、インスタンス作成時に自動で実行される初期化処理です。
# self は「作成されるインスタンス自身」を指します。
# "self.id = ..." は、「このカルテ(self)のID欄に、渡されたpatient_idを書き込む」という意味です。
self.id = patient_id
self.height_cm = height_cm
self.weight_kg = weight_kg
def calculate_bmi(self):
"""
この患者のBMIを計算して返すメソッド(処理)
データは self.height_cm, self.weight_kg から直接参照するため、
引数で再度渡す必要がありません。これがミスを防ぐポイントです。
"""
# 身長が0以下の場合のエラーハンドリング(安全策)
if self.height_cm <= 0:
raise ValueError("身長は0より大きい必要があります。")
# メートル単位に変換
height_m = self.height_cm / 100
# BMI計算式: 体重(kg) / 身長(m)^2
bmi = self.weight_kg / (height_m ** 2)
# 小数点第2位で丸めて返す
return round(bmi, 2)
# --- ここからが実際の使用例 ---
# 1. クラス(設計図)からインスタンス(実体)を生成
# "P001"というIDを持つ具体的な患者データを作成します
patient_a = Patient(patient_id="P001", height_cm=170.0, weight_kg=70.0)
# 2. メソッドを呼び出して計算を実行
# patient_a という特定の患者データに基づいて計算が行われます
print(f"ID: {patient_a.id}, BMI: {patient_a.calculate_bmi()}")ID: P001, BMI: 24.22このようにデータと処理をセットにすることで、patient_a.calculate_bmi() のように直感的な操作だけで計算が完結します。「どの変数を引数に渡すべきか?」と悩む必要も、計算式を毎回書き直して間違えるリスクもありません。これが、信頼性の高い医療AIコードを書くための第一歩です。
3. コードの「インフォームド・コンセント」:型ヒントとDocstring
Pythonは「動的型付け言語」と呼ばれ、変数の型(整数か、文字列か、など)を宣言せずに x = 10 のように書ける手軽さが魅力です。しかし、この柔軟性は、大規模な医療AI開発においては諸刃の剣となります。
想像してみてください。電子カルテに「検査値:100」とだけ書かれていたらどうでしょうか?
単位は mg/dL なのか mmol/L なのか? 対象は血糖値なのか血圧なのか?
情報が不足していると、後からそのデータを見た医師は判断に迷い、最悪の場合、医療過誤につながりかねません。
プログラミングも同じです。def calculate(data): という関数があったとき、data に渡すべきなのは「患者1人の検査値リスト」なのか、「全患者のデータフレーム」なのか、コードを書いた本人以外(あるいは半年後の自分)には分からなくなってしまうのです。
そこで重要になるのが、コードにおける「インフォームド・コンセント(説明と同意)」とも言える、型ヒントとDocstringです。

型ヒント (Type Hints)
Python 3.5以降では、変数の型を明示する型ヒントが導入されました (van Rossum et al. 2014)。data: List[float] のように書くことで、「この data という変数には、小数のリストが入りますよ」と明示できます。
これはプログラムの実行自体には影響しません(強制力はありません)が、VS Codeなどの開発ツールがこれを読み取り、誤った型のデータを渡そうとした時に「型が違います」と警告を出してくれるようになります。あたかも、処方オーダリングシステムが「用量間違い」をアラートで知らせてくれるような安全装置として機能するのです。
Docstring(ドックストリング)
Docstringとは、関数やクラスの冒頭に """(トリプルクォート)で囲んで記述する説明文のことです。ここには以下の情報を記載します。
- Args(引数): この関数は何を受け取るのか?(例:患者の年齢、検査画像のパス)
- Returns(戻り値): 処理結果として何を返すのか?(例:リスクスコア、判定ラベル)
- Raises(例外): どんな時にエラーが発生するか?(例:データが空の場合)
医療において、医薬品に「添付文書」が必須であるように、関数にも「正しい使い方とリスク」を明記する必要があります。
以下に、型ヒントとDocstringを適切に使ったコード例を示します。
# 型ヒントを使うために、標準ライブラリtypingからListとOptionalをインポート
from typing import List, Optional
def analyze_risk_scores(scores: List[float], threshold: float = 0.5) -> str:
"""
リスクスコアのリストを受け取り、閾値を超える割合に基づき判定を返す。
この関数は、入力されたスコアのリストの中に、指定された閾値を超えるものが
どの程度含まれているかを計算し、その割合が30%以上であれば'High Risk'と判定します。
Args:
scores (List[float]): 0.0〜1.0の範囲のリスクスコアが格納されたリスト。
threshold (float, optional): リスクありとみなすスコアの閾値。デフォルトは 0.5。
Returns:
str: 判定結果として 'High Risk' または 'Low Risk' を返す。
入力リストが空の場合は 'No Data' を返す。
Raises:
ValueError: スコアが0.0〜1.0の範囲外の場合に発生(※本実装では省略)。
"""
# データの存在チェック:リストが空の場合は早期リターン
if not scores:
return "No Data"
# リスト内包表記を使って、閾値(threshold)を超えているスコアの個数をカウント
# sum([True, False, True]) は sum([1, 0, 1]) と同じく 2 になる性質を利用
high_risk_count = sum([1 for s in scores if s > threshold])
# 全データに対する高リスクスコアの割合を計算
ratio = high_risk_count / len(scores)
# 割合が30% (0.3) 以上であれば高リスクと判定
if ratio >= 0.3:
return "High Risk"
else:
return "Low Risk"このように記述することで、この関数を使う人は中身のロジックを一行一行読まなくても、「何を入れたら何が返ってくるか」を一目で理解できるようになります。
4. 常に清潔野を保つ:静的解析とフォーマッタ
どんなに手技に優れた外科医であっても、疲労が蓄積すれば手順を誤るリスクは高まります。人間である以上、ケアレスミスをゼロにすることは不可能です。だからこそ、医療現場ではダブルチェックや安全確認の仕組みが何重にも張り巡らされています。
プログラミングも同様です。コードの書き方(スタイル)を人間が手動で整えようとするのは、非効率的であり、ミスの温床です。現代のソフトウェア開発、とりわけ品質が重視される医療AI開発においては、コードの整形やチェックをツールに任せるのが鉄則です。これを実現するのが静的解析ツールとフォーマッタです。

3つの必須ツール:Black, isort, Flake8
Python開発において、以下の3つのツールは「三種の神器」と言っても過言ではありません。
- Black (フォーマッタ):
「妥協のないコードフォーマッタ」として知られています。開発者の好みを排除し、コードの見た目(スペースの数、改行の位置など)を強制的に統一します。これにより、「誰が書いても同じ見た目」になり、チーム開発における「クォーテーションはシングルかダブルか」といった不毛な論争(派閥争い)を終結させます。 - isort (フォーマッタ):
ファイルの先頭にあるimport文の順序を、自動でアルファベット順・タイプ別(標準ライブラリ、サードパーティ、自作モジュール)に整列させます。薬剤棚が整理整頓されているように、どこから何を読み込んでいるかが一目で分かるようになります。 - Flake8 (リンター):
コードを実行する前に、文法エラーや、Pythonの標準コーディング規約であるPEP 8(Van Rossum et al. 2001)への違反を検出します。未使用の変数や、長すぎる行などを指摘してくれるため、潜在的なバグの早期発見につながります。
VS Codeでの自動化:手術室の「自動清掃ロボット」
これらのツールは、コマンドラインから手動で実行することもできますが、VS Codeなどのエディタに設定し、「ファイルを保存するたびに自動実行(Format on Save)」させるのがベストプラクティスです。
これは例えるなら、手術室に「自動清掃ロボット」を導入するようなものです。手術(コーディング)が進んでも、ロボットが即座に清掃・整理整頓を行ってくれるため、術野(コード)は常に清潔で整った状態が保たれます。これにより、開発者は「コードの見た目を整える」という本質的でない作業から解放され、ロジックの構築に集中できるようになるのです。
5. コードの臨床試験:pytestによるテスト
医療において、新しい薬剤や治療法を現場に導入する際、必ず「臨床試験(治験)」を経て安全性と有効性を確認します。「理論上は効くはずだ(In vitroでは効いた)」という思い込みだけで、いきなり人間に投与することは決して許されません。
プログラミングも全く同じです。「自分のPCでは動いた」というコードは、あくまで試験管レベルの実験結果に過ぎません。未知のデータが入力されたり、環境が変わったりした時、予期せぬ挙動(副作用)を示す可能性があります。医療AI開発において、バグは単なるエラーではなく、誤診や誤判断のリスクそのものです。
そこで必要になるのが、コードのための臨床試験、すなわち「テストコード(Unit Test)」です。
pytest:あなたのための「24時間働く監査医」
pytest(パイテスト)とは、Pythonの世界で現在最も信頼され、広く採用されている「標準的なテストフレームワーク(検査ツール)」です。
研究や開発の現場にこれを導入する意味は、単に便利なツールを入れるということではありません。それは、あなたの研究チームに「24時間365日、一瞬の休みもなく全ての電子カルテ(コードとデータ)をダブルチェックし、人間には気づかない微細な異常値も見逃さずに即座に報告してくれる、超優秀な専属監査医」を雇うことと同義です。
人間は疲れますし、慣れればミスもします。しかし、pytestは疲れません。あなたがコードを1行書き換えるたびに、過去の全ての検査項目を数秒で再チェックし、「先生、今の修正でこちらの数値に異常が出ました!」と教えてくれるのです。
テストコードの解剖学:3ステップ診療(AAAパターン)
では、具体的にどのような手順でテストを行うのでしょうか?
実は、テストコードの設計は、医療における標準的な「診断・治療プロセス」と驚くほど似ています。ソフトウェアエンジニアリングの世界では、これを「AAAパターン(Arrange-Act-Assert)」と呼びます。この3つのステップを理解すれば、誰でも迷わずにテストを書くことができます。
- Arrange(準備・問診):シミュレーション環境の構築
まず、テストを行うための舞台を整えます。実際の患者さんで実験するわけにはいきませんので、特定の条件を持った「テスト用の模擬患者データ(ダミーデータ)」を作成します。
(例:「身長170cm、体重60kgの患者Aさん」というデータオブジェクトをメモリ上に作成するステップです) - Act(実行・処置):検査・介入の実施
準備したデータに対して、検証したい機能(作成した計算関数やAIモデル)を実際に適用します。医療で言えば、薬剤を投与したり、検査機器のスイッチを入れたりする瞬間にあたります。
(例:作成した BMI計算関数に、患者Aさんのデータを渡して実行し、その計算結果を受け取ります) - Assert(検証・評価):予後判定と合否
ここが最も重要なステップです。Actで得られた「実際の実行結果」が、事前に定義しておいた「期待される結果(正解)」と、1ミリの狂いもなく一致するかを厳密に判定します。
(例:計算結果が『20.76』になっているか確認します。もし『20.76001』や『Error』になっていれば、テストは「失敗(Fail)」とみなされ、赤信号が点灯します)
この「準備(Arrange)→実行(Act)→確認(Assert)」というサイクルを小さな機能単位で積み重ねていくことが、堅牢で信頼できる医療AI開発の基本となります。
以下に、先ほどの Patient クラス(BMI計算機能)に対する具体的な臨床試験プロトコルを示します。
import pytest
# --- テスト対象のクラス(本来は別ファイルからimportします) ---
class Patient:
def __init__(self, patient_id, height_cm, weight_kg):
self.height_cm = height_cm
self.weight_kg = weight_kg
def calculate_bmi(self):
# 安全装置:身長が0以下ならエラーを投げる
if self.height_cm <= 0:
raise ValueError("Invalid height")
return round(self.weight_kg / ((self.height_cm / 100) ** 2), 2)
# --- ここからが「臨床試験プロトコル(テストコード)」 ---
def test_bmi_calculation_normal():
"""
【試験1:有効性確認】
典型的な症例(身長170cm, 体重70kg)において、
計算式が正しい数値をはじき出すか?
"""
# 1. Arrange (準備): 患者Aさんを用意
p = Patient("test01", 170.0, 70.0)
# 2. Act (処置): BMIを計算させる
result = p.calculate_bmi()
# 3. Assert (評価): 結果は「24.22」でなければならない
# もし違っていれば、ここでテストは「Fail(不合格)」となる
assert result == 24.22
def test_height_zero_error():
"""
【試験2:安全性確認(異常系)】
あり得ない入力(身長0cm)があった場合、
システムは沈黙せず、正しく「アラート(エラー)」を鳴らせるか?
"""
# 1. Arrange: あり得ないデータの患者Bさん
p = Patient("test02", 0, 50.0)
# 2 & 3. Act & Assert:
# 「この処理を行ったら ValueError が起きるはずだ」という期待を記述
# もしエラーが起きずに処理が進んでしまったら、安全装置の故障として「Fail」にする
with pytest.raises(ValueError):
p.calculate_bmi()なぜこれが強力なのか?:「デグレ」という副作用を防ぐ
テストコードを書く最大のメリットは、将来のコード変更に対する保険、すなわち「デグレ(リグレッション:先祖返り)」の防止にあります。医療に例えるなら、ある疾患の治療を行った結果、別の予期せぬ「副作用」が出てしまっては意味がありません。同様に、プログラムの修正が原因で、元々正常に動いていた機能が壊れてしまうことを防ぐ必要があります。
例えば半年後、あなたが「BMI計算式を少し最適化しよう」としてコードを触り、誤ってメートル換算の / 100 を削除してしまったとします。目視確認(視診)だけでは、この小さな論理的病変に気づかないかもしれません。
しかし、pytest コマンドを一回実行すれば、システムは即座に異常を検知します。
$ pytest
test_patient.py F. [50%]
FAILURES _________________________________________________________________
___ test_bmi_calculation_normal ___
assert 0.0024 == 24.22
# 先生、計算結果がおかしいです! 24.22のはずが 0.0024 になっています!
# (単位変換の消失による桁ズレを即座に検知)このように、テストコードはコードを変更した瞬間に「意図しない副作用」を検出し、バグが患者さんの元へ届くのを未然に防いでくれます。医療現場で「ダブルチェック」がヒューマンエラーを防ぐ最後の砦であるように、プログラミングにおいては「自動テスト」が、あなたの研究の再現性を担保し、医療安全を守る最強の盾となるのです。
6. 一流のコードへのリファクタリング実践
ここまで、オブジェクト指向(クラス)、型ヒント、例外処理といった個別の技術(手技)を解説してきました。これらは単独でも役に立ちますが、全てを統合したときに初めて、医療現場で通用する「実用的で堅牢なソフトウェア」となります。
最後は、これらを組み合わせて、現場で使えるレベルの「実用的なデータローダークラス(臨床データ読み込みプログラム)」を作成してみましょう。
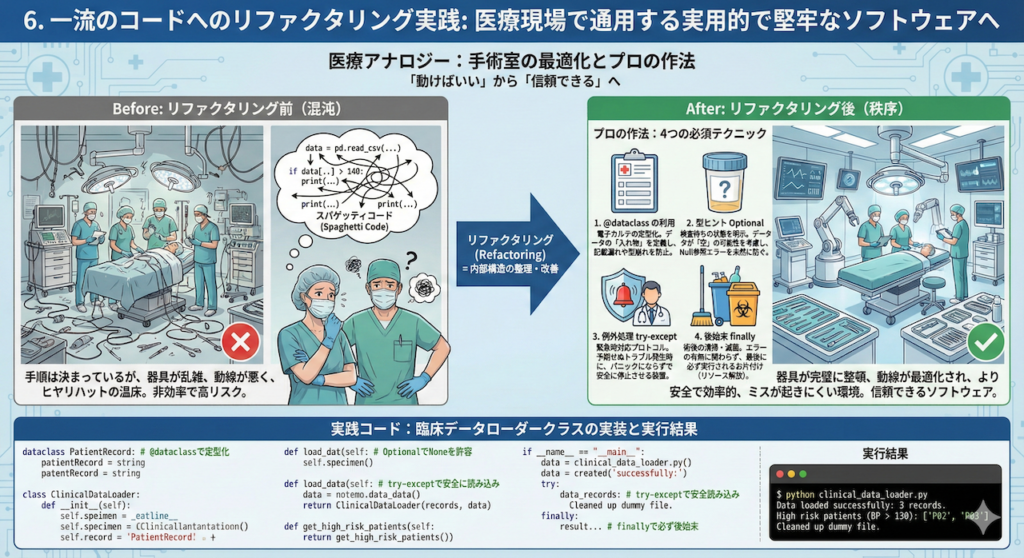
「リファクタリング」とは何か?:手術室の最適化
プログラミングの世界には「リファクタリング(Refactoring)」という重要な概念があります。
これは、プログラムの「外部から見た挙動(機能)」は変えずに、「内部の構造」を整理・改善することを指します。医療の現場に例えるなら、以下のような改善活動に似ています。
- Before(改善前): 手術の手順は決まっているが、器具が乱雑に置かれ、看護師の動線が悪く、ヒヤリハットが起きやすい状態。
- After(改善後): 手術の手順(機能)は全く同じだが、器具が完璧に整頓され、動線が最適化され、より安全で効率的、かつミスが起きにくい環境になっている状態。
コードも同じです。「動けばいい」だけのスパゲッティコードを、他人が読んでも理解でき、将来の修正にも耐えうる「清潔なコード」に書き換える作業、それがリファクタリングです。
プロの作法:4つの必須テクニック
今回のコードでは、単なるスクリプトではなく、以下の4つの「プロの作法」を駆使しています。
@dataclassの利用(電子カルテの定型化):PatientRecordクラスの定義に使用しています。これは「データの入れ物」を簡単に作るための機能です。手書きのメモではなく、項目が決まった「電子カルテの入力フォーム」を用意するようなもので、データの記載漏れや型崩れを防ぎます。- 型ヒント
Optional(検査待ちの状態):self.data: Optional[pd.DataFrame] = Noneという記述が登場します。これは、「最初はデータが入っていない(None)けれど、読み込み処理が終わった後にはDataFrame(データ)が入るよ」ということを明示しています。
医療で言えば、「まだ結果が出ていない検査容器(空の状態)」をラベル付きで用意しておくことに似ています。これにより、「中身が空なのに解析しようとしてしまう」という初歩的なミス(Null参照エラー)を未然に防ぎます。 - 例外処理
try-except(緊急時対応プロトコル):
ファイルが見つからない(FileNotFoundError)など、予期せぬトラブルが発生した際に、プログラムをいきなりクラッシュ(強制終了)させるのではなく、適切なエラーメッセージを出して安全に停止させる装置です。
これは、急変時にパニックになるのではなく、「ACLS(二次救命処置)」などのプロトコルに従って冷静に対処するのと同じ考え方です。 - 後始末
finally(術後の清掃・滅菌):finallyブロックに書かれた処理は、エラーが起きても起きなくても、「最後に必ず」実行されます。ここでは、テスト用に作成した一時的なダミーファイルを確実に削除(お片付け)するために使用しています。
手術が成功しても中止になっても、使用したメスやガーゼは必ず廃棄・片付けを行うのが医療のマナーであるように、プログラムも「来た時よりも美しく」終了するのが鉄則です。
実践コード:臨床データローダーの実装
それでは、これらの技術を統合した実際のコードを見てみましょう。このコードは、架空の患者CSVデータを読み込み、高血圧リスクのある患者IDを抽出する一連の流れを自動化しています。
import pandas as pd
import numpy as np
from typing import List, Dict, Optional
from dataclasses import dataclass
import os
# --- 1. データ構造の定義 ---
# @dataclassを使うことで、データの「型枠(スキーマ)」を簡潔に定義できます。
# これにより、「どんなデータが必要か」が一目瞭然になり、可読性が劇的に向上します。
@dataclass
class PatientRecord:
id: str # 患者ID(文字列)
age: int # 年齢(整数)
blood_pressure: int # 收縮期血圧(整数)
is_diabetes: bool # 糖尿病の有無(真偽値)
class ClinicalDataLoader:
"""
臨床データを読み込み、前処理や抽出を行う「専門家」クラス
責任範囲:ファイルの読み込み、エラーハンドリング、特定条件の抽出
"""
def __init__(self, file_path: str):
# クラスが作られた瞬間は、ファイルパスだけ受け取り、データは「空(None)」にしておきます。
self.file_path = file_path
# Optional[...] は「Noneが入る可能性がある」ことを明示する重要な型ヒントです。
self.data: Optional[pd.DataFrame] = None
def load_data(self) -> None:
"""
CSVファイルを読み込んでメモリに格納するメソッド。
ファイルが存在しない場合のエラーハンドリング(安全装置)を含みます。
"""
try:
# データの読み込みを試みる(Try)
self.data = pd.read_csv(self.file_path)
print(f"Data loaded successfully: {len(self.data)} records.")
except FileNotFoundError:
# もしファイルが見つからなかった場合(Except)、パニックにならずに
# わかりやすいメッセージ付きのエラーとして報告し直す。
raise FileNotFoundError(f"Error: 臨床データファイルが見つかりません: {self.file_path}")
def get_high_risk_patients(self, bp_threshold: int = 140) -> List[str]:
"""
指定した血圧閾値を超える患者IDのリストを返します。
Args:
bp_threshold (int): 高血圧の閾値 (mmHg)。デフォルトはガイドライン準拠の140。
Returns:
List[str]: 該当する患者IDのリスト(文字列の配列)
"""
# ガード節(Guard Clause):
# 「データがロードされていない状態」でこの処理を呼び出すのは手順ミスです。
# 早期にエラーを出し、バグの温床になるのを防ぎます。
if self.data is None:
raise ValueError("Data not loaded. Call load_data() first. (データをロードしてから解析してください)")
# クエリによるフィルタリング:
# Pandasの機能を使って、血圧(blood_pressure)が閾値(bp_threshold)より高い行を抽出
high_risk_df = self.data[self.data['blood_pressure'] > bp_threshold]
# 抽出されたデータの 'id' 列だけを取り出し、Pythonの標準リストに変換して返却
return high_risk_df['id'].tolist()
# --- 2. 実行用メインスクリプト ---
# if __name__ == "__main__": は、このファイルが直接実行された時だけ動くブロックです。
# 他のファイルから import された時は実行されません(誤作動防止)。
if __name__ == "__main__":
# ダミーデータの作成(実行テスト用)
dummy_csv = 'dummy_patients.csv'
# 辞書型からDataFrameを作成(Excelのような表データを作るイメージ)
df_dummy = pd.DataFrame({
'id': ['P01', 'P02', 'P03'],
'age': [65, 50, 72],
'blood_pressure': [120, 150, 135],
'is_diabetes': [False, True, True]
})
# CSVファイルとして保存 (index=False は、行番号を出力しない設定)
df_dummy.to_csv(dummy_csv, index=False)
try:
# 1. クラスのインスタンス化(設計図から実体を作成)
loader = ClinicalDataLoader(dummy_csv)
# 2. データの読み込み(ここで self.data に中身が入る)
loader.load_data()
# 3. 高リスク患者の抽出 (閾値を130mmHgに厳しく設定して判定)
high_risk_ids = loader.get_high_risk_patients(bp_threshold=130)
print(f"High risk patients (BP > 130): {high_risk_ids}")
finally:
# 後始末(Clean-up):
# テストで作ったダミーファイルは、処理が成功しようが失敗しようが、必ず削除する。
# これが「来た時よりも美しく」の精神です。
if os.path.exists(dummy_csv):
os.remove(dummy_csv)
print("Cleaned up dummy file.")実行結果
Data loaded successfully: 3 records.
High risk patients (BP > 130): ['P02', 'P03']
Cleaned up dummy file.このコードを実行すると、まずダミーのCSVファイルが作成され、それをクラス経由で安全に読み込み、高血圧患者(P02, P03)を抽出して表示し、最後にCSVファイルをきれいに削除して終了します。
このように、クラス設計(整理整頓)、型定義(説明責任)、エラー処理(安全対策)を組み合わせることで、コードは単なる命令の羅列から、「誰が使っても安全で、何をしているかが明確な、信頼できる医療ソフトウェア」へと進化します。これこそが、医療AIエンジニアが目指すべき一流の作法(Best Practices)なのです。
まとめ:コード品質は「患者への誠実さ」である
まとめ:コード品質は「患者への誠実さ」である
一見すると、型ヒントの記述やテストコードの作成は、開発スピードを落とす「面倒な作業」に見えるかもしれません。しかし、これらは決して無駄な装飾ではありません。これらは、「未来の自分」と「共同研究者」、そして何より「そのAIの恩恵を受けるはずの患者さん」を守るための堅牢な防壁なのです。
一流の外科医が、メスの切れ味や鉗子の整備に一切の妥協を許さないのと同じように、一流の医療AI開発者は、コードの品質に妥協しません。汚れた器具で手術を行えば感染症のリスクがあるように、乱雑なコードで開発されたAIは、医療過誤という最悪の結果を招きかねないからです。
今日から、あなたの書くPythonコードに「型(Type)」と「説明(Docstring)」と「テスト(Test)」を与えてあげてください。その小さな手間の積み重ねこそが、研究室のアイデアを臨床現場で信頼される技術へと育てる、最も確実な一歩となります。
参考文献
- Haibe-Kains, B. et al. (2020). Transparency and reproducibility in artificial intelligence. Nature, 586, E14–E16.
- van Rossum, G., Warsaw, B. and Coghlan, N. (2001). PEP 8 – Style Guide for Python Code. Python Software Foundation.
- van Rossum, G., Lehtosalo, J. and Langa, Ł. (2014). PEP 484 – Type Hints. Python Software Foundation.
- Krekel, H. et al. (2023). pytest: simple powerful testing with Python. pytest documentation.
- Martin, R.C. (2008). Clean Code: A Handbook of Agile Software Craftsmanship. Upper Saddle River, NJ: Prentice Hall.
- Sommerville, I. (2015). Software Engineering. 10th edn. Harlow: Pearson Education.
- Fowler, M. (2018). Refactoring: Improving the Design of Existing Code. 2nd edn. Boston, MA: Addison-Wesley Professional.
- U.S. Food and Drug Administration (2023). General Principles of Software Validation; Final Guidance for Industry and FDA Staff. Silver Spring, MD: FDA.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




