
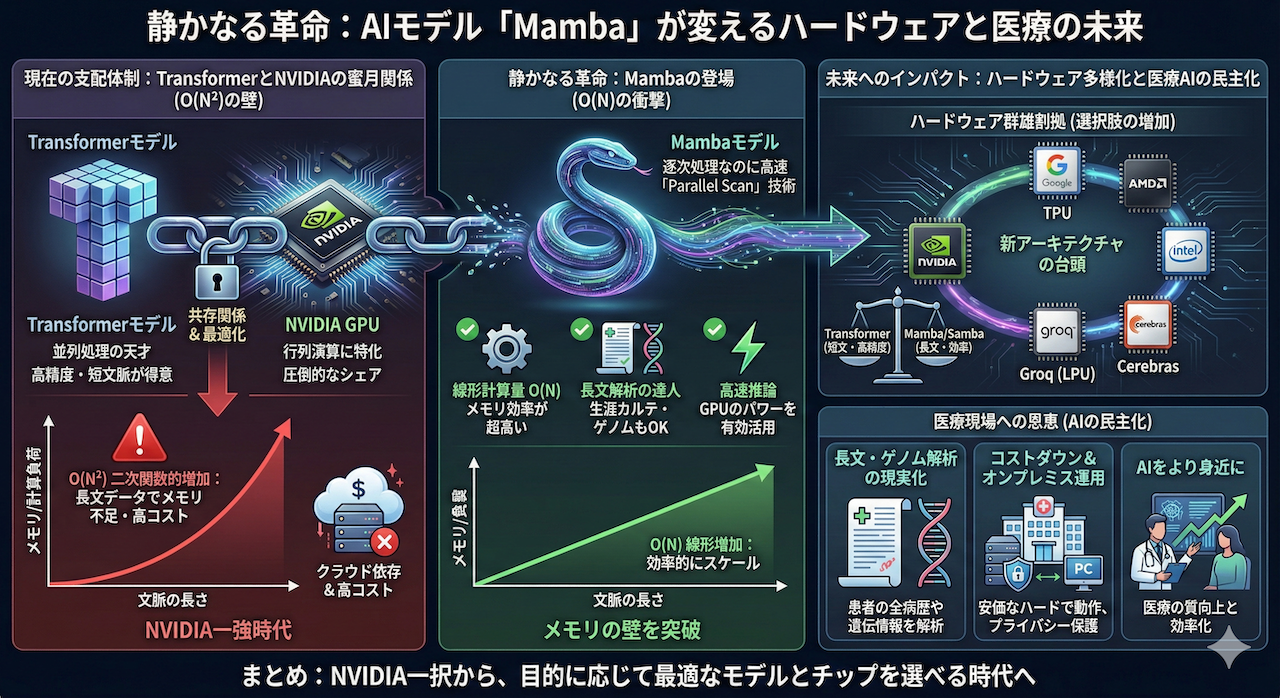
静かなる革命:AIモデル「Mamba」が変えるハードウェアと医療の未来
今、生成AIの世界で「静かなる革命」が起きています。
それは、現在のAIブームを牽引する絶対王者への挑戦状です。
皆さんは、「ChatGPT」の「T」が何を意味するかご存知でしょうか?
実はこれ、「Transformer(トランスフォーマー)」というAIモデル(技術的な仕組み)の頭文字なのです。2017年に登場して以来、このTransformerがあまりに優秀だったため、現在、商業的に成功している生成AIのほとんどはこの技術をベースに作られています。
しかし今、その「Transformer一強」の時代に風穴を開けようとする新たな挑戦者たちが現れました。その筆頭が「Mamba(マンバ)」です。他にもRWKVなど、いくつか有力な候補が存在します。
「新しいAIのソフトが出ただけでしょ?」と思われるかもしれません。しかし、この交代劇は単なるソフトウェアの話にとどまらず、「AIを動かすハードウェア(半導体)」の勢力図さえも塗り替える可能性を秘めているのです。
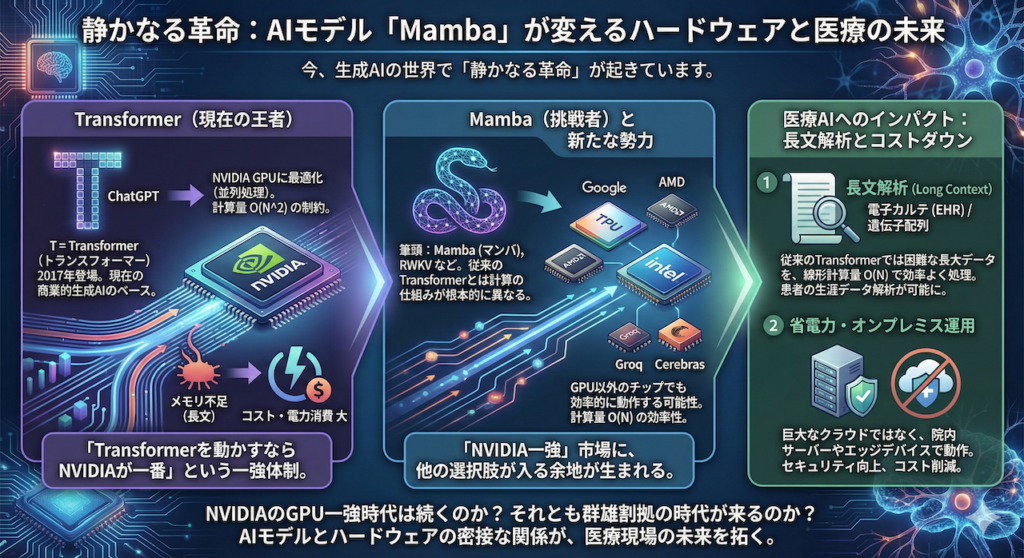
ソフトウェアとハードウェアの「共存関係」
現在のAI業界は、NVIDIAのGPU(画像処理半導体)なしには語れません。なぜなら、現在の主流であるTransformerモデルが、NVIDIAのGPUが得意とする「並列処理(大量の計算を同時にこなすこと)」に極めて最適化されているからです。
つまり、「Transformerを動かすならNVIDIAが一番」という状況が、現在のNVIDIAの圧倒的なシェアを支えています。
しかし、Mambaのような新しいアーキテクチャは、その計算の仕組みが根本的に異なります。従来のTransformerほどGPUの大規模な並列計算に依存しない特性を持つため、理論上は「GPU以外のチップ」でも効率的に動作する可能性があります。
これにより、「NVIDIA一強」だった市場に、他の選択肢が入る余地が生まれます。GoogleのTPU はもちろん、AMDやIntelといった半導体大手、さらにはGroqやCerebrasといった新興のAIチップメーカーなどが、このパラダイムシフトを機に巻き返しを図るシナリオも現実味を帯びてくるのです。
医療AIへのインパクト:長文解析とコストダウン
この「次世代モデル」への移行は、私たち医療従事者にとっても他人事ではありません。Mamba等が持つ特性は、医療現場における以下の課題解決に直結するからです。
- 長文解析(Long Context): 患者の生涯にわたる電子カルテ(EHR)や、長大な遺伝子配列情報など、従来のTransformerでは計算量 \( O(N^2) \) の制約によりメモリ不足で扱うのが困難だったデータを、線形計算量 \( O(N) \) で効率よく処理できる可能性があります。
- 省電力・オンプレミス運用: 計算効率が良いため、巨大なクラウドサーバーではなく、院内のサーバーやエッジデバイス(PCや医療機器)でAIを動かせる可能性が高まります。これはセキュリティやコストの面で大きなメリットとなります。
NVIDIAのGPU一強時代は続くのか? それとも群雄割拠の時代が来るのか?
今回は、数式やコードを一切使わず、この「AIモデルとハードウェアの密接な関係」を、医療現場の視点も交えながら解き明かしていきます。
1. 「富豪的」なTransformerと、NVIDIAの蜜月関係
まず、なぜ現在NVIDIAのGPU(H100など)がこれほどまでに重宝されているのか、その理由をお話ししましょう。それは、現在のAIの主流であるTransformerと「相性が良すぎる」からです。
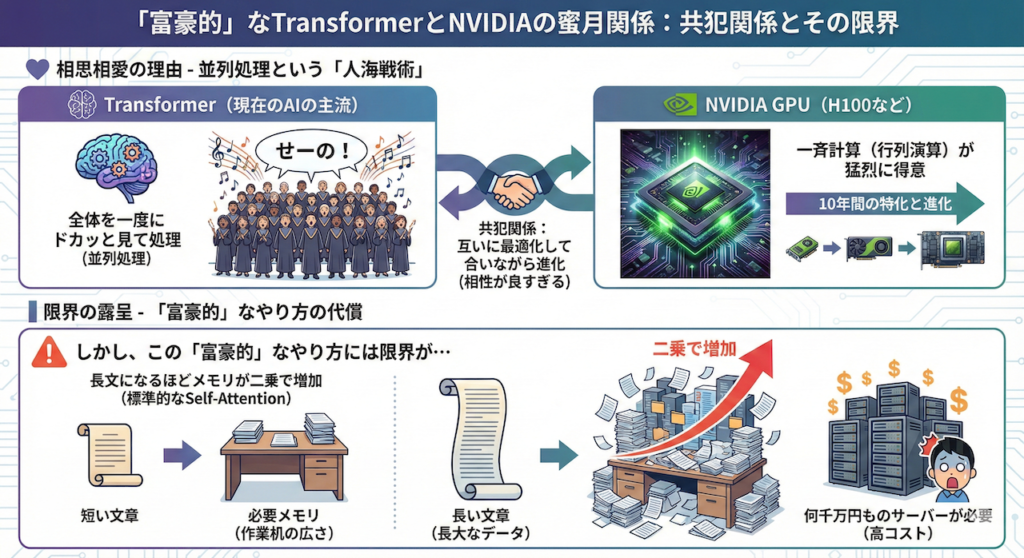
並列処理という「人海戦術」
Transformerの最大の特徴は、文章を頭から順に読むのではなく、「全体を一度にドカッと見て処理する(並列処理)」点にあります (Vaswani et al. 2017)。
- イメージ: 100人の聖歌隊が一斉に「せーの」で歌い出すようなものです。
- NVIDIA GPU: この「一斉に計算する」作業(行列演算)が猛烈に得意なハードウェアです。
NVIDIAはこの10年間、この「行列演算」を極めることに特化してGPUを進化させてきました。つまり、Transformerという「ソフトウェア」と、NVIDIA GPUという「ハードウェア」は、互いに最適化し合いながら進化してきた「共存関係」にあると言えます (Hooker 2021)。
しかし、この「富豪的」なやり方には限界が見えてきました。標準的なSelf-Attentionを用いたTransformerの場合、文章が長くなればなるほど、必要なメモリ(作業机の広さ)が二乗で増えてしまうのです (Tay et al. 2022)。これが「長大なデータを処理するAIを動かすのに何千万円ものサーバーが必要」になる主な理由の一つです。
2. Mambaの衝撃:GPUの「苦手」を克服した革命児
そこで登場したのがMambaです。Mambaは、Transformerとは全く異なるアプローチを取ります。
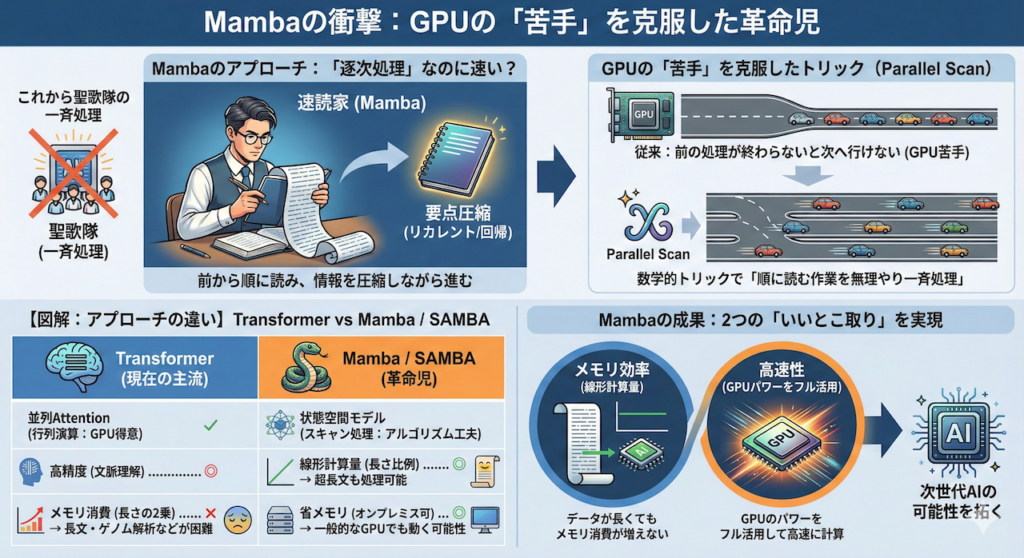
「逐次処理」なのに速い?
Mambaは、文章を前から順に読み込み、情報を圧縮しながら進む「リカレント(回帰)」と呼ばれる仕組みをベースにしています (Gu & Dao 2023)。

- イメージ: 聖歌隊ではなく、一人の優れた速読家が、本をパラパラとめくりながら要点をノートにまとめていくスタイルです。
従来、この「順に読む」スタイルはGPUが大の苦手でした。「前の文字を読み終わらないと次に行けない」ため、GPUの強みである「一斉処理」が使えなかったからです。
しかし、Mambaの発明者たちは、「Parallel Scan(並列スキャン)」という数学的なトリックを使うことで、「順に読む作業を、無理やりGPUで一斉に処理させる」ことに成功しました (Gu & Dao 2023)。
これにより、Mambaは以下の2つの「いいとこ取り」を実現しました。
- メモリ効率: データが長くてもメモリ消費が増えない(線形計算量)。
- 高速性: GPUのパワーをフル活用して高速に計算できる。
ハードウェアの話に入る前に、少しだけ技術的な補足をしましょう。
Mambaは「記憶力」と「速さ」に優れますが、実はTransformerが得意とする「文章の特定の場所をピンポイントで振り返る能力(コピー&ペーストのような作業)」は少し苦手とする場合があります。
そこで近年研究されているのが、MambaとTransformerを組み合わせたハイブリッドモデルです。その代表例の一つが「Samba」です。
- 構造: 基本はMamba(SSM)で構成しつつ、要所要所にTransformerの「Attention(注意機構)」をサンドイッチのように挟み込んでいます(Sliding Window Attention)。
- メリット: これにより、「Mambaの超長文処理・高速性」と「Transformerの高精度な記憶検索」の長所を組み合わせられる可能性が示されています。
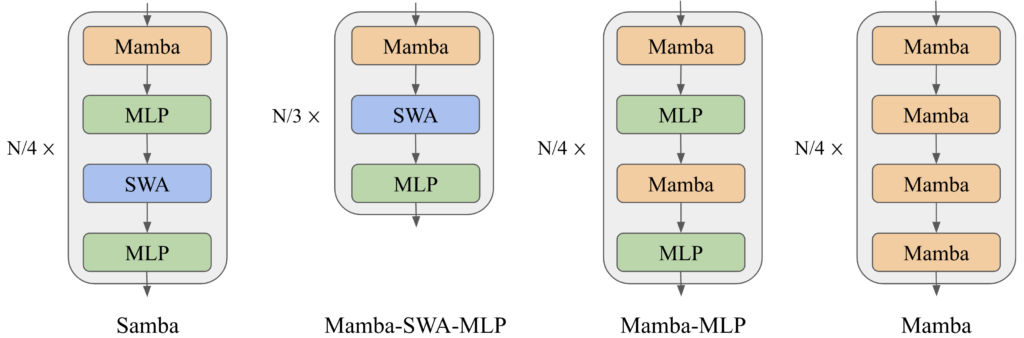
3. ハードウェア戦争への影響:NVIDIA vs Google・新興勢力
では、Mambaや、その派生形であるハイブリッドモデルが普及すると、半導体メーカーの勢力図にはどのような影響があるのでしょうか?
① NVIDIAへの影響:「Attention依存」からの脱却?
Transformerの計算負荷の大部分は、Attention機構特有の「大規模な行列演算」にあります。NVIDIAのGPUには「Tensor Core」という、この演算に特化した回路が大量に積まれています。
一方、MambaやSambaのようなモデルでは、Attentionへの依存度が相対的に減り、代わりに「メモリの読み書き」や「スキャン操作(順次処理)」の重要性が増します。
- 懸念: 「今のNVIDIA GPUはTransformerに特化しすぎていて、Mamba系のモデルにはオーバースペック(回路の無駄遣い)ではないか?」という議論が一部でなされています。
- 実際: それでもNVIDIAは強力です。最大の強みはハードそのものより、「CUDA」という圧倒的に柔軟な開発環境にあります。実際、Mambaの公式実装もCUDAを使って高度にチューニングされており、現時点ではNVIDIA GPU上で極めて高速に動作します (Gu & Dao 2023)。NVIDIA帝国がただちに崩れることはないでしょう。
② 競合の逆襲:Google TPUと新興勢力のチャンス
しかし、「NVIDIAのGPU一択」の状況には変化の兆しがあります。新しい計算パターンの台頭は、GPU以外のアーキテクチャにとって追い風になる可能性があるからです。
- Google TPU (Tensor Processing Unit):
元々は大規模な行列演算に特化したチップですが (Jouppi et al. 2023)、その巨大なメモリ帯域とチップ間通信の速さは、将来的にSambaのような大規模ハイブリッドモデルを学習させる際、有利に働く可能性があります。特に「数万個のチップを繋いで超巨大モデルを作る」スケーラビリティにおいては、依然として最強の対抗馬です。 - 新興勢力 (Groq, Cerebras等):
実は今、最も注目されているのがここです。例えばGroqのようなLPU(Language Processing Unit)は、GPUのような並列処理ではなく、データの流れをスムーズにすること(決定論的データフロー)に特化した設計をしています。これは、Mambaのような「前から順に処理する(シーケンシャルな)」モデルと構造的に相性が良く、特に推論速度においてGPUを凌駕する可能性があります。
つまり、「TransformerならNVIDIA一強だが、Mamba/Sambaの世界では、どのチップが覇権を握るかまだ決着がついていない」というのが、現時点での科学的に誠実な評価です。
4. 医療現場への恩恵:AIの「民主化」
このハードウェアとソフトウェアの戦いは、私たち医療従事者に何をもたらすのでしょうか? 答えは「AIのコストダウン」と「プライバシーの保護」です。
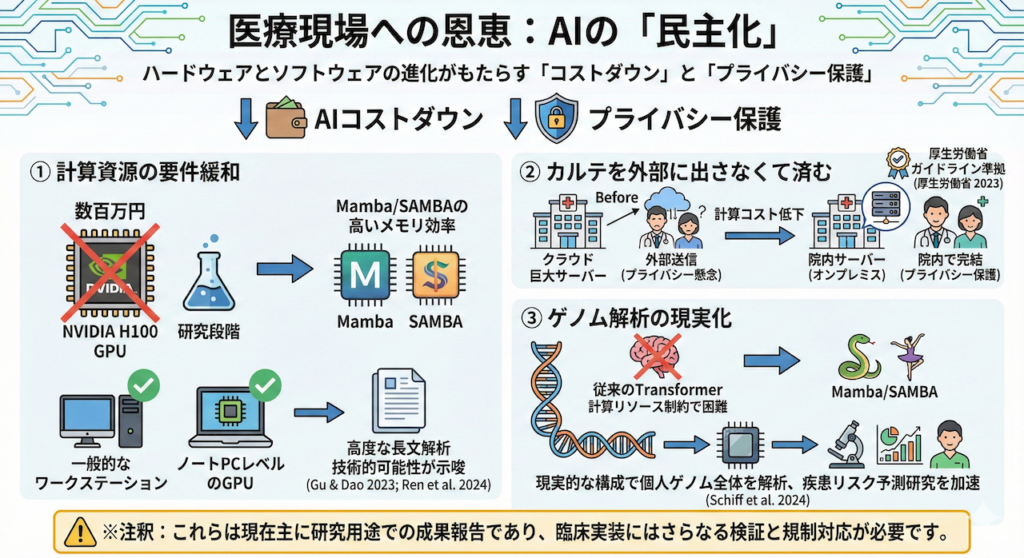
- 計算資源の要件緩和
研究段階ではありますが、Mamba/Sambaの高いメモリ効率により、NVIDIA H100のような数百万円するGPUでなくても、従来より低い計算資源(例:院内の一般的なワークステーションや一部のノートPCレベルのGPU)で高度な長文解析が可能になる技術的可能性が示されています (Gu & Dao 2023; Ren et al. 2024)。 - カルテを外部に出さなくて済む
「計算コストが下がる」ということは、「クラウド上の巨大サーバーにデータを送らなくても、院内のサーバー(オンプレミス)でAIを動かせる」可能性が高まることを意味します。これは、厚生労働省のガイドライン等でも重視される個人情報保護の観点から決定的なメリットとなり得ます (厚生労働省 2023)。 - ゲノム解析の現実化
数億文字に及ぶDNA配列の解析は、従来のTransformerでは計算リソースの制約が大きく困難でした。Mamba/Sambaなら、より現実的なハードウェア構成で、個人のゲノム全体を読み込み、疾患リスク予測の研究を加速させることが期待されています (Schiff et al. 2024)。
※これらは現在主に研究用途での成果報告であり、臨床実装にはさらなる検証と規制対応が必要です。
まとめ:選択肢が増える未来
MambaやSambaの登場は、NVIDIAを脅かすというよりは、「NVIDIA一択」だった世界に選択肢をもたらすものです。
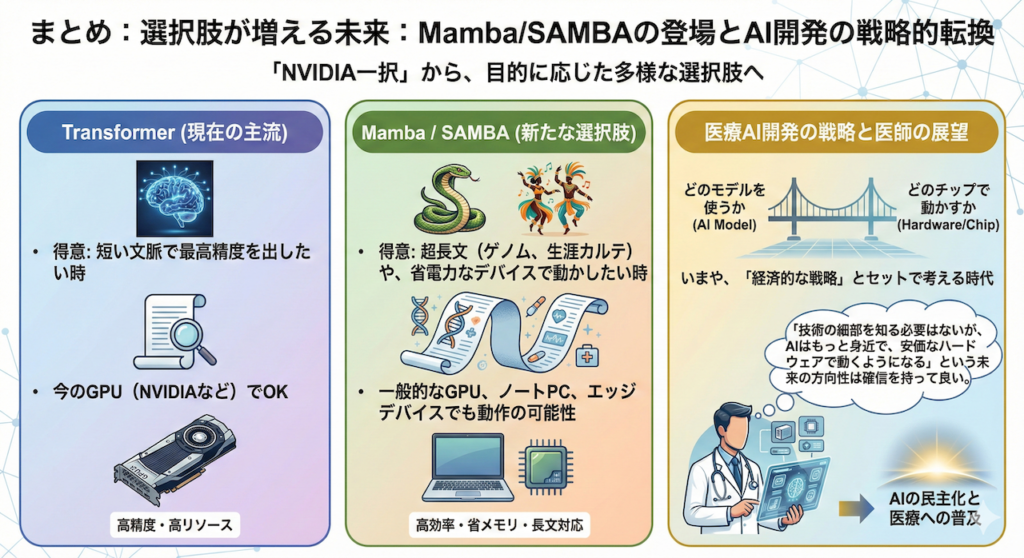
- Transformer: 短い文脈で最高精度を出したい時(今のGPUでOK)。
- Mamba/Samba: 超長文(ゲノム、生涯カルテ)や、省電力なデバイスで動かしたい時。
医療AI開発において、「どのモデルを使うか」は、いまや「どのチップで動かすか」という経済的な戦略とセットで考える時代に入りました。
私たち医師も、技術の細部を知る必要はありませんが、「AIはもっと身近で、安価なハードウェアで動くようになる」という未来の方向性は、確信を持って良いでしょう。
参考文献
- Gu, A. and Dao, T. (2023) ‘Mamba: Linear-Time Sequence Modeling with Selective State Spaces’, arXiv preprint, arXiv:2312.00752.
- Hooker, S. (2021) ‘The Hardware Lottery’, Communications of the ACM, 64(12), pp. 58–65. doi:10.1145/3467017.
- Jouppi, N.P. et al. (2023) ‘TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings’, Proceedings of the 50th Annual International Symposium on Computer Architecture (ISCA ’23). doi:10.1145/3579371.3589350.
- Ren, L. et al. (2024) ‘Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling’, arXiv preprint, arXiv:2406.07522.
- Schiff, Y. et al. (2024) ‘Caduceus: Bi-directional Equivariant Long-range DNA Sequence Modeling’, arXiv preprint, arXiv:2403.03234.
- Tay, Y. et al. (2022) ‘Efficient Transformers: A Survey’, ACM Computing Surveys, 55(6), pp. 1–28. doi:10.1145/3530811.
- Vaswani, A. et al. (2017) ‘Attention Is All You Need’, Advances in Neural Information Processing Systems, 30.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




