

統計モデルは「作って終わり」ではありません。モデルが常に最高の性能を発揮できるよう、その健康状態を隅々までチェックし、調整するための重要な技術(精度管理)の要点を学びましょう。
モデルの「予測と現実のズレ(残差)」を可視化します。残差プロットに特定のパターンがなく、Q-Qプロットが直線状なら、データの特徴をうまく捉えている健康な証拠です。
たった一つのデータがモデル全体を歪める危険性を探ります。Cookの距離でモデル全体への影響度を、DFBETAで各係数への影響を特定し、その背景を調査します。
似た変数(例: BMIと体脂肪率)が互いの評価を邪魔する「多重共線性」をVIFで検出。VIF > 10 は危険信号で、変数の除外や統合を検討します。
AICやBICで当てはまりとシンプルさのバランスを評価。正則化回帰(Lasso/Ridge)で過学習を防ぎ、未知データへの対応力(汎化性能)を高めます。
臨床現場は、常に不確実性との闘いと言えるかもしれません。「この治療法は、この患者さんに本当に最善なのだろうか?」「この検査値のわずかな変動は、一体何を意味しているんだろう?」。私たちは日々、手元にある限られた情報から、最善と思われる判断を下すために思考を巡らせています。
そんな私たちを力強くサポートしてくれるのが、統計モデルやAIの世界です。膨大なデータから病態のパターンを学習し、未来のリスクを予測したり、画像から人では見逃してしまうような微細な変化を捉えたり。それはまるで、これまで見えなかった生体内の情報を可視化してくれる、新しい「診断の眼」を手に入れるようなものかもしれません。
しかし、ここで一つ、とても大切な問いかけがあります。その新しい「眼」、本当に正確に、クリアに見えているでしょうか? もし、その眼の焦点が少しでもズレていたり、レンズが曇っていたとしたら…。そのわずかな誤差が、診断の遅れや治療方針の選択に影響を与えてしまう可能性だって、ゼロではないはずです。統計モデルを「作って終わり」にしてしまうことの本当の怖さは、まさにここにあるのだと思います。
そこで今回は、私たちが作り上げた大切なモデルの「健康診断」を行う方法を、一緒に学んでいきましょう。これは、いわばモデルの精度管理(Quality Control)です。モデルという名の精密機器が、常に最高のパフォーマンスを発揮できるよう、その性能を隅々までチェックし、必要に応じて調整していくための重要な技術です。
これからご紹介する手法には、一見すると難しそうに聞こえる専門用語も出てきます。でも、どうか安心してください。一つひとつが、私たちが普段の診療で使っている「聴診器」や「打診器」、あるいは「カルテ」のような、モデルの状態を深く知るための大切な「道具」なんです。その道具たちの使い方を、身近な例え話を交えながら、じっくりと一緒に見ていきましょう。
モデルのフィット感を可視化する「残差分析」という名の試着室
立派な統計モデルを立てたとしましょう。これは、データを説明するための「オーダーメイドのスーツ」を作るようなものです。仕立て上がったスーツを見て、デザインは完璧に見えるかもしれません。しかし、本当に重要なのは「着心地」、つまり体に正しくフィットしているかどうかですよね。それを確かめる最初のステップが、この残差分析です。
残差(Residual)とは、一言でいえば「予測と現実のズレ」のこと。スーツの例えを借りるなら、「モデルが予測したウエストサイズ」と「実際のあなたのウエストサイズ」との差、そのものです。この「ズレ」が、ある特定の傾向を持つことなく、完全にランダム(でたらめ)であればあるほど、モデルはデータの特徴をうまく捉えられている、ということになります。残差分析は、モデルが説明しきれなかった「ズレ」の正体を突き止めるための、最初の診察なのです。
残差プロット:フィット感の歪みを暴く鏡
残差分析で最も基本的かつ強力な道具が残差プロットです。これは横軸にモデルの「予測値」、縦軸に「残差」をとった散布図で、モデルの健康状態を映し出す鏡のようなもの。
理想的なのは、残差が0のラインを中心に、上下均等に、何のパターンもなく散らばっている状態です。まるで、晴れた夜空に広がる星々のように。これは、モデルが説明すべきことをすべて説明し尽くし、残ったズレ(残差)にはもはや予測可能な情報が何も含まれていない「健全なノイズ」だけであることを示しています。
しかし、もしプロットに何らかのパターンが見えたら…?それはモデルが何らかの重要な情報を見逃しているという「警告サイン」です。
例えば、悪い例②の不均一分散は、臨床的には非常に重要です。軽症患者の予後は正確に予測できるのに、最も予測が重要になる重症患者の予後は大きく外れてしまう、といった事態につながりかねません。残差プロットは、そうしたモデルの「不得意な領域」を教えてくれるのです。
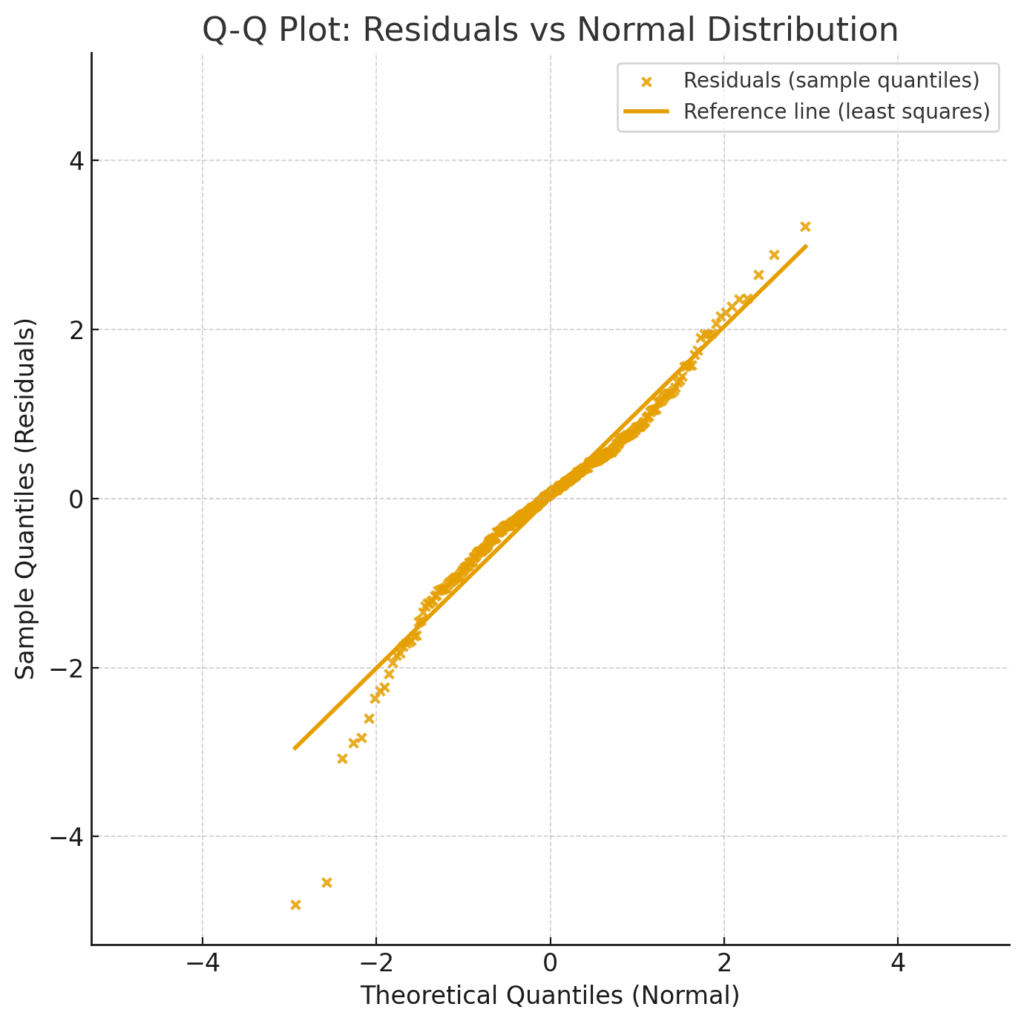
Q-Qプロット:残差の「素性」をチェックする
もう一つの便利な道具がQ-Qプロット (Quantile-Quantile Plot) です。これは、残差が統計モデルの重要な前提の一つである「正規分布」という理想的な形に従っているかどうかを、視覚的に確認するためのものです。
少し技術的な話になりますが、回帰モデルなどから得られるp値や信頼区間といった指標は、多くの場合「残差が正規分布に従う」ことを前提として計算されています。もしこの前提が大きく崩れていれば、私たちが目にするp値などの信頼性も揺らいでしまうわけです。
Q-Qプロットは、「理論上の理想的な残差の分布(正規分布)」と「実際の残差の分布」をプロット上で比較します。もし残差の「素性」が良ければ、点はほぼ一直線上に綺麗に並びます。しかし、点が直線から大きく逸脱していくようであれば、それは残差が正規分布からかけ離れている証拠。モデルの結論を鵜呑みにする前に、一度立ち止まって考える必要がある、というサインになります。
たった一つのデータがモデルを壊す?「影響力の強い点」を見つけ出す探偵術
データの中には、時としてモデル全体に不釣り合いなほど大きな影響を与える、いわば「クラスの秩序を乱す問題児」のような点が存在することがあります。こうしたデータ点を一つ見逃すだけで、モデルの結論が180度変わってしまうことすらあるため、彼らを見つけ出すのは非常に重要な工程です。
ただし、ここで少し正確な言葉の使い分けをしておきましょう。「外れ値」と「影響力の強い点」は、似ているようで少し違います。
- 外れ値 (Outlier): 他のデータから見て、単純に「変わった値」を持つ点。例えば、周りが皆170cmなのに一人だけ210cmの身長の人がいるようなケースです。結果(Y)が極端な値を示します。
- 高レバレッジ点 (High-leverage Point): 原因となる説明変数(X)が極端な値を持つ点。例えば、他の患者の年齢が30〜60歳なのに、一人だけ95歳のデータがあるようなケースです。
- 影響力の強い点 (Influential Observation): 上記の両方の性質を併せ持つことが多い、モデル全体に大きな影響を与える点です。
これをシーソーに例えると分かりやすいかもしれません。単なる「外れ値」は、シーソーの真ん中近くに座った体重の重い人のようなもの。少しは傾きますが、決定的な影響はありません。一方、「影響力の強い点」は、シーソーの一番端に座った体重の重い人です。たった一人で、シーソー全体の傾きを劇的に変えてしまいますよね。私たちの仕事は、この「シーソーの端に座る重い人」、つまり影響力の強い点を見つけ出すことなのです。
Cookの距離 (Cook’s distance):容疑者リストの筆頭は誰だ?
モデルへの影響度を調査するための、最も代表的な探偵道具がCookの距離です。これは、個々のデータ点がモデル全体にどれだけの影響を与えているかを、一つの数値で示してくれる指標です。
やっていることは、「もし、このデータ点(容疑者)がなかったとしたら、モデル全体の予測(事件の全体像)はどれくらい変わってしまうか?」というシミュレーションです。この値が突出して大きいデータ点は、モデルを不安定にしている主犯格、つまり「最重要容疑者」かもしれません。
慣例的に、Cookの距離が「4/n」(nはサンプルサイズ)を超える場合、あるいは1を大幅に超える場合には、影響力が強いと判断され、詳しい調査が必要になります。
DFBETA:どの犯行に、どう関与したのか?
Cookの距離が「総合的な影響度」を示すのに対し、DFBETAは、よりピンポイントな調査ツールです。例えるなら、容疑者一人ひとりに対して「あなたのせいで、Aという証言(係数A)はどれくらい捻じ曲げられたのか? Bという証言(係数B)は?」と個別に尋問していくようなものです。
DFBETAは、あるデータ点を取り除いたときに、回帰モデルの各係数(β1, β2, …)がそれぞれどれだけ変化するかを示します。これにより、「この患者のデータは、特に『年齢』の効果を過大評価させているな」とか、「この症例のせいで、新薬の効果が実際よりも小さく見えてしまっているな」といった、より詳細な影響の内訳まで特定できるのです。
こちらも慣例的に、DFBETAの絶対値が「2/√n」を超える場合には、その係数に対して無視できない影響を与えていると考えられます。
影響の強い点を見つけたらどうするか?
重要なのは、これらの「容疑者」を即座にデータから削除(逮捕)してはいけない、ということです。彼らは、単なる入力ミスや測定エラーかもしれませんし、あるいはこれまで知られていなかった極めて稀な病態を示す、医学的に非常に貴重な症例かもしれません。探偵の仕事は、犯人を決めて罰することではなく、真実を明らかにすること。まずはそのデータがなぜ影響力が強いのか、カルテを見直したり、測定プロセスを確認したりと、その背景を徹底的に調査することが何よりも大切なのです。
あなたのモデルは「仲間割れ」していないか?多重共線性の罠
回帰モデルに投入する説明変数は、それぞれが独立した役割を持つサッカーチームの選手のようなものであってほしいですよね。フォワードは得点、ミッドフィルダーはゲームメイク、ディフェンダーは守備、といったように、各選手が独自の貢献をすることでチーム全体のパフォーマンス(予測精度)が決まります。
しかし、もしチームに「役割が完全に被っている」選手が二人いたらどうなるでしょう? 例えば、二人とも全く同じ動きをするフォワードだった場合。ゴールが決まったとき、それは一体どちらの選手の手柄なのでしょうか? 監督(=モデル)は混乱し、選手の評価(=係数)を正しく決めることができなくなります。
臨床研究のデータでも、これと似たことが起こります。例えば、患者の予後を予測するのに「肥満度を表すBMI」と「体脂肪率」を両方モデルに投入したとします。この2つの指標は非常に強く相関していますよね。このように、説明変数同士の相関が非常に高い状態を多重共線性(Multicollinearity)、通称「マルチコ」と呼びます。
マルチコが発生すると、モデルはまさに「仲間割れ」を起こしているような状態になります。
- 係数が不安定になる: ほんの少しデータが変わっただけで、ある変数の係数がプラスからマイナスに変わるなど、評価が乱高下します。
- 標準誤差が大きくなる: 係数の推定値のばらつきが非常に大きくなり、「この変数がどれくらい重要なのか」という評価が非常に曖昧になります。
- 解釈が困難になる: 本来は予後を悪化させるはずの因子が、なぜかモデル上では予後を改善させるかのような逆の符号を持つことさえあります。
これでは、どの因子が本当に重要なのか、自信を持って結論づけることができません。
VIF (Variance Inflation Factor):変数の「役割かぶり度」を測る
この「役割のかぶり具合」を具体的に数値化してくれるのが、VIF (分散拡大要因) です。その名の通り、多重共線性によって、ある変数の係数の「分散(不確かさ)」がどれだけ「拡大(inflate)」してしまっているかを示す指標です。
\[ \text{VIF}_j = \dfrac{1}{1 – R_j^2} \]
数式の意味を紐解いてみましょう。ここでの \( R_j^2 \) は、少し特殊なものです。チームの中から選手 \(j\) を一人だけ選び出し、「他の全選手(j以外)の動きから、選手 \(j\) の動きをどれだけ予測できるか」を試したときの決定係数(予測の当てはまり度)なのです。
もし選手 \(j\) の動きが他の選手たちによって完全に予測できてしまうなら、\( R_j^2 \) は1に近づきます。すると分母の \( (1 – R_j^2) \) は0に近づき、VIFの値は無限大に跳ね上がります。これは、その選手 \(j\) がチームにとって「冗長な(いなくても他の選手で代わりが効く)存在」であることを意味します。
実務上は、以下の基準がよく用いられます。
- VIF > 10: 深刻な多重共線性が疑われます。早急な対処が必要です。
- VIF > 5: 注意が必要なレベルです。
- 研究分野によっては、より厳しく VIF > 2.5 などを基準とすることもあります。
多重共線性の治療法
もし高いVIFが検出されたら、どうすれば良いのでしょうか? 監督として、いくつか決断を下す必要があります。
- 選手を一人外す: 最もシンプルな解決策です。相関している変数ペアのうち、理論的・臨床的により重要でないと考えられる方をモデルから除外します。
- 役割を統合する: 相関する複数の変数を合わせて、一つの総合的な指標を作成します。(例:「BMI」と「体脂肪率」から「肥満指数」のような新しい変数を作る)。
- 専門的な戦術を使う: 正則化回帰(特にRidge回帰)のような、多重共線性の影響を受けにくい統計手法を用いることも有効な選択肢です。
どの方法を選択するかは、研究の目的やデータの背景によって異なりますが、まずはVIFを使ってモデルの「チームワーク」を診断することが、信頼できるモデルへの第一歩となります。
究極の選択:どちらのモデルがより「優れている」か?
さて、ここまでの診察でモデルの基本的な健康状態はチェックできました。では、もし手元に複数の治療方針(=モデルの候補)があったら、どうやって「最高の治療方針」を選べば良いのでしょうか?
例えば、予測に使う説明変数を5つに絞ったシンプルなモデルAと、関連しそうな変数を15個すべて投入した複雑なモデルBがあるとします。複雑なモデルBの方が、手元のデータ(=目の前の患者さん)はうまく説明できるかもしれません。しかし、それは単なる「その場しのぎの過剰な治療」であって、他の患者さん(=未知のデータ)には全く通用しない「副作用」の強いものである可能性も潜んでいます。
このジレンマを解決し、真に「汎用性の高い良いモデル」を選ぶための、2つの有力なアプローチを見ていきましょう。
AICとBIC:「当てはまり」と「倹約さ」の天秤
モデル選択における二大巨頭が、AIC (赤池情報量規準) と BIC (ベイズ情報量規準) です。これらは、モデルの性能を評価する冷静な審査員だと考えてください。彼らが評価するポイントは、たったの2つです。
- 当てはまりの良さ (尤度): モデルが、観測されたデータをどれだけうまく説明できているか。これは点数が高いほど良い。
- モデルの倹約さ (Parsimony / パラメータ数): モデルが、どれだけ少ない数の変数(シンプルな構造)で説明を達成しているか。不要に複雑なモデルはペナルティを受けます。
これはまさに、科学の基本原則である「オッカムの剃刀」(”説明は、必要以上に複雑であるべきではない”)を数式で表現したものです。数式を見てみましょう。
\[ \text{AIC} = -2 \ln(L) + 2k \]
\[ \text{BIC} = -2 \ln(L) + k \ln(n) \]
\(-2 \ln(L)\): この部分が「当てはまりの悪さ」を表します。\(L\)(尤度)が大きいほど、この項は小さくなります。\(+ 2k\)や\(+ k \ln(n)\): これが「複雑さに対するペナルティ」です。\(k\)(パラメータ数)が多いほど、この値は大きくなります。
AICもBICも、この2つの要素を足し合わせたスコアであり、このスコアが小さいほど「良いモデル」だと評価されます。
では、AICとBICの違いは何でしょうか? それはペナルティの厳しさです。BICのペナルティ項 \(k \ln(n)\) にはサンプルサイズ \(n\) が含まれており、データが大きくなるほどペナルティが指数関数的に厳しくなります。そのため、BICはAICよりも、よりシンプルなモデルを好む「厳格なミニマリスト」と言えるでしょう。どちらを使うかは目的によりますが、一般に予測性能を重視するならAIC、データ生成の真の構造を探求したいならBICが好まれる傾向があります。
クロスバリデーション (交差検証):未知の患者への「実力テスト」
AICやBICが、いわば「理論上の性能評価」であるのに対し、クロスバリデーション(交差検証)は、もっと実践的な「臨床シミュレーション」です。
「今いる患者さんのデータだけで最適化した治療法が、次に来る新しい患者さんに本当に通用するのか?」を試すために、手持ちの患者データを分割して、意図的に「未知の患者」を作り出してテストするのです。最も一般的な k-分割交差検証 (k-fold cross-validation) の流れは以下の通りです。
このように、データをK個のグループに分け、1つをテスト用、残りを訓練用としてモデルを構築し、性能を評価する。これをK回繰り返し、性能スコアの平均値を取ることで、モデルの汎化性能(未知のデータへの対応能力)をより頑健に評価します。
AIC/BICに比べて計算に時間はかかりますが、モデルの仮定にあまり依存せず、純粋な「予測の実力」を測れるため、特に機械学習の分野ではモデル選択のゴールドスタンダードとされています。
過学習を防ぐ「賢いブレーキ」:正則化回帰
皆さんは、試験勉強で「一夜漬け」をした経験はありますか? 練習問題の解答を丸暗記すれば、その練習問題と全く同じ問題が出れば100点が取れるかもしれません。しかし、少しひねった応用問題が出た途端、全く手が出せなくなってしまいます。
統計モデルにおける過学習(Overfitting)は、まさにこの「丸暗記」と同じ状態です。モデルが手元の訓練データに過剰に適合しすぎて、データの些細なノイズまでをも「重要なパターン」だと誤って記憶してしまい、結果として新しい未知のデータ(=本番の試験)に対する予測能力(=応用力)を失ってしまう現象を指します。
この過学習という「暴走」を防ぐための、極めて強力な手法が正則化回帰 (Regularized Regression) です。これは、モデルの学習プロセスに「なるべくシンプルな答えを導き出すように」という制約(ペナルティ)を課す、いわば「賢いブレーキ」のような仕組みです。
具体的には、モデルの係数(説明変数の重要度)が不必要に大きくなることを防ぎます。係数が大きいということは、モデルがデータのごく一部の変動に過敏に反応している証拠だからです。このブレーキの強さはλ(ラムダ)というパラメータで調整し、交差検証(クロスバリデーション)などを用いて最適な「踏み加減」を探っていきます。
Ridge回帰(L2正則化):係数をみんなで少しずつ抑える「協調的ブレーキ」
Ridge(リッジ)回帰は、ペナルティとして「全係数の二乗和」をモデルの評価関数に加えます。
例えるなら、「チーム全体のパフォーマンスを安定させるために、突出して目立っている選手の給料(係数)も、そうでない選手の給料も、全員の給料を全体的に少しずつ抑制する」という方針です。
この方法では、係数が0に近づくことはあっても、完全に0になることはほとんどありません。すべての変数を残したまま、その影響度を滑らかに縮小させることで、モデル全体を安定させ、特に多重共線性がある場合にその効果を発揮します。
Lasso回帰(L1正則化):不要な係数をゼロにする「選択的ブレーキ」
一方、Lasso(ラッソ)回帰は、ペナルティとして「全係数の絶対値の和」を加えます。
こちらは、「本当にチームに貢献しているトッププレイヤーの給料(係数)は維持・評価するが、貢献度の低い選手の給料は容赦なくゼロにする」という、より厳格な方針です。
Lassoの最も強力で興味深い特徴は、この仕組みによって、効果のない変数の係数を文字通り完全に「ゼロ」にしてしまう点にあります。これは、モデルが自動的に「この変数は予測に不要です」と判断し、捨ててくれることを意味します。
つまり、Lassoは単なる過学習防止のブレーキに留まらず、モデルの解釈性を高めるための「変数選択」ツールとしての機能も併せ持っているのです。特に、遺伝子データのように説明変数の候補が膨大にあるような状況で、真に重要な因子を絞り込む際に絶大な威力を発揮します。
RidgeとLassoの使い分け
| 特徴 | Ridge回帰 (L2) | Lasso回帰 (L1) |
|---|---|---|
| ペナルティ | 係数の 二乗 和 | 係数の 絶対値 和 |
| 係数への影響 | 0に近づけるが、0にはなりにくい | 完全に0になる係数が多数出現 |
| 主な目的 | モデルの安定化、多重共線性への対処 | 変数選択、スパースなモデルの構築 |
| たとえるなら | 全員で少しずつ負担を分かち合う | 貢献度に応じて大胆に取捨選択する |
RidgeとLassoには、それぞれ「Elastic Net」という両方の良いとこ取りをしたハイブリッド手法も存在します。どのブレーキを使うかは、データの特性や分析の目的(予測精度を極めたいのか、重要な因子を見つけたいのか)によって選択することが重要です。
その変数は本当に必要?仮説検定による最終判断
さて、モデルの評価もいよいよ大詰めです。最後に、モデルに新しく変数を追加したり、逆に変数を取り除いたりする際に、その判断が「統計的に意味のあるものか」を客観的に裏付けるための検定手法に触れておきましょう。
これは、山登りに例えると分かりやすいかもしれません。今、あなたは「シンプルなモデル」という名のベースキャンプにいます。そして、いくつかの新しい変数(装備)を追加して、より高い「複雑なモデル」という山頂を目指せるとします。
問題は、「その山頂まで苦労して登る価値は本当にあるのか?」ということです。山頂からの眺め(=モデルの当てはまり)は、ベースキャンプよりも少しは良くなるでしょう。しかし、その眺めの改善は、追加した装備の重さや労力(=モデルの複雑化)に見合うほど、劇的なものでしょうか?
この「登る価値があるか」を判定してくれるのが、尤度比検定、Wald検定、Score検定という3人の専門家(検定手法)です。
3人の専門家(検定手法)
これら3つの検定は、入れ子(nested)の関係にある2つのモデル、つまりシンプルなモデルが複雑なモデルの特殊なケース(特定の係数を0としたもの)になっている場合に利用できます。
- 尤度比検定 (Likelihood Ratio Test): 最も実直な登山家
この専門家は、実際にベースキャンプと山頂の両方に登り、それぞれの地点からの眺め(=尤度、モデルの当てはまりの良さ)を直接比較します。「山頂からの眺めは、ベースキャンプの眺めよりも“有意に”素晴らしいか?」を判断する、最も直感的で信頼性の高い方法です。ただし、2つのモデルを両方とも完全に構築(推定)する必要があるため、手間(計算コスト)は最もかかります。 - Wald検定 (Wald Test): 山頂にいる装備エンジニア
この専門家は、既に山頂に到達していることを前提とします。そして、山頂に到達するために使った追加の装備(=追加した変数の係数)を調べ、「この装備は、本当に頑丈で意味のあるもの(=係数が0と有意に異なる)だったのか?」を評価します。皆さんが統計ソフトの回帰分析結果で目にする、各説明変数の横に表示されるp値は、このWald検定に基づいています。山頂にさえ到達すれば評価できる手軽さから、広く使われています。 - Score検定 (Score Test): ベースキャンプにいる偵察兵
この専門家は、最も効率的です。ベースキャンプから一歩も動かず、山頂の方向を見上げ、その斜面の傾き(=Score)を調べます。「もし今から登り始めたら、最初の勢いはどれくらいあるか?」を評価するわけです。傾きが急であれば、登る価値はありそうだと判断します。実際に登る必要がないため、計算は3つの中で最も簡単。そのため、たくさんの追加変数候補の中から「登る価値がありそうな有望なルート」をスクリーニングする際に非常に役立ちます。
どの専門家を信じるか?
| 検定手法 | 評価の視点 | 必要な計算 | よく使われる場面 |
|---|---|---|---|
| 尤度比検定 | 2地点の「眺めの差」を直接比較 | 2つのモデルを推定 | 最終的なモデル同士の厳密な比較 |
| Wald検定 | 山頂で「追加装備の性能」を評価 | 複雑なモデルのみ推定 | 標準的な回帰分析のアウトプット |
| Score検定 | ベースキャンプから「斜面の傾き」を評価 | シンプル なモデルのみ推定 | 多数の変数候補のスクリーニング |
幸いなことに、サンプルサイズが十分に大きければ、これら3人の専門家の結論はほぼ一致することが知られています。それぞれの特徴を理解し、分析のフェーズや目的に応じて彼らの意見を参考にすることで、より説得力のあるモデル選択を行うことができるのです。
まとめ:良いモデルは「対話」から生まれる
今回は、統計モデルの「総合健康診断」で用いる、様々なツールとその使い方を巡る旅をしてきました。
残差プロットという「聴診器」でモデルの当てはまりの呼吸を聞き、影響の強い点を特定する「精密検査」で隠れた異常を見つけ、VIFという「血圧計」で変数間の不健康な関係性をチェックしました。そして、AICやBIC、さらには交差検証という「総合判定会議」を経て最適なモデルを選択し、正則化という「賢い生活習慣指導」で将来の過学習リスクを防ぐ方法を学びました。
これらは決して、ボタンを押せば終わるような単なる数学的な手続きではありません。これこそが、モデルとデータ、そして私たち分析者が行う「対話」そのものなのです。
モデルは、診断プロットや統計量を通じて、私たちに多くの「症状」を伝えてくれます。「この残差プロットのパターン、データのこの部分の関係性がうまく表現できていません」と。あるいは、「この高いVIFの値、どの変数の手柄なのか混乱しています」と。
私たちの役割は、その声に耳を傾けるモデルの「主治医」です。症状を正しく読み解き、原因を考察し、そして変数変換やモデルの修正といった適切な「治療」を施してあげる。この地道な評価と改善の繰り返し、すなわち丁寧な「対話」を経て初めて、モデルは机上の空論から、臨床現場や研究で本当に役立つ、信頼できるパートナーへと成長していくのです。
ぜひ、ご自身のモデルの主治医になったつもりで、じっくりと向き合ってみてください。この対話のスキルこそが、医療AI時代に不可欠な臨床能力の一つになっていくはずです。
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
参考文献
- Akaike, H. (1974) ‘A new look at the statistical model identification’, IEEE Transactions on Automatic Control, 19(6), pp. 716-723.
- Cook, R.D. (1977) ‘Detection of Influential Observation in Linear Regression’, Technometrics, 19(1), pp. 15-18.
- Hastie, T., Tibshirani, R. and Friedman, J. (2009) The elements of statistical learning: data mining, inference, and prediction. 2nd edn. New York: Springer.
- Schwarz, G. (1978) ‘Estimating the Dimension of a Model’, The Annals of Statistics, 6(2), pp. 461-464.
- Tibshirani, R. (1996) ‘Regression shrinkage and selection via the lasso’, Journal of the Royal Statistical Society, Series B (Methodological), 58(1), pp. 267-288.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




