

臨床現場にあふれるデータの「ばらつき」の奥には、統計学の美しい秩序が隠されています。この要約では、「大数の法則」から始まり、魔法のような「中心極限定理」を経て、推定の精度を示す「標準誤差」に至るまで、一つの標本から真実を読み解くための一連の物語を4つのステップで解説します。
たくさんのデータを集めると、その平均値は「本来あるべき真の値」に近づきます。大規模な臨床試験の信頼性は、このシンプルな法則に支えられています。
「もし調査を何度も繰り返したら?」という思考実験上の分布です。手元のたった一つの標本平均が、全体の中でどの位置にあるかを考えるための土台となります。
元のデータがどんな形でも、標本平均の分布はサンプルサイズが大きければ正規分布に近づきます。この魔法により、予測や比較が可能になります。
標本平均のばらつき具合を示す指標です。値が小さいほど推定の信頼性が高く、95%信頼区間など、より精度の高い報告を可能にする重要なコンパスです。
臨床の現場は、まさに情報の洪水です。日々のカンファレンスで目にする検査データ、外来で測定する一人ひとりの血圧、新薬の治験で報告される効果のばらつき…。これらの数字は、一つひとつが貴重な情報である一方、そのあまりの多様性に「結局のところ、何が言えるんだろう?」と途方に暮れてしまうことはありませんか? 📈
ある患者さんには劇的に効いた治療法が、別の患者さんには今ひとつだったり。先月の平均待ち時間は15分だったのに、今月は25分だったり。この絶え間ない「ばらつき」というノイズの嵐の中で、私たちはどうすれば、信頼できる「シグナル」、つまり物事の本当の姿や真の効果を掴み取ることができるのでしょうか。
実は、一見カオスに見えるこのデータの世界には、そのノイズの奥に隠された真実を見通すための、驚くほど強力な羅針盤が存在します。その一つが、今回ご紹介する「中心極限定理(Central Limit Theorem, CLT)」です。
この、まるで魔法のような名前の定理を理解すると、これまでバラバラの「点」にしか見えなかったデータ群から、意味のある「傾向」や「パターン」という名の線を、自信を持って引き出すことができるようになります。それは、臨床医として、あるいは研究者として、エビデンスを読み解き、自ら作り出していく上で、とてつもなく大きな力になるはずです。
この美しい魔法の核心に迫るため、今回はその最高の仲間たちである「大数の法則」や「標本分布」といった、統計学の基本的ながらも極めて重要な概念たちも一緒に紹介します。さあ、データの海から真実の宝を探し出す、スリリングな探検に出発しましょう!
まずは準備運動:「大数の法則」
中心極限定理という主役の登場をより楽しむために、まずは最高の助演男優、「大数の法則(Law of Large Numbers)」について少しだけお話しさせてください。この法則、実は統計学の世界におけるすべての信頼性の基礎を築いている、と言っても過言ではないほど重要な考え方なんです。
一言でいうと、大数の法則は「試す回数を増やせば増やすほど、その結果の平均は『本来あるべき真の値』にどんどん近づいていく」という、非常にシンプルで直感的な法則です。
この考え方の基礎は古く、1713年に数学者のヤコブ・ベルヌーイがその著書『推測術』の中で示したものとされています (Bernoulli, 1713)。何百年も前から、人々は経験的にこの真理に気づいていたんですね。
サイコロを振り続けると「3.5」が見えてくる
一番わかりやすいのが、やはりサイコロの例です。
ちょっと想像してみてください。サイコロを1回振ります。出た目は「6」でした。この時点での平均値は、もちろん「6.0」です。
もう一度振ると「1」が出ました。これまでの合計は 6 + 1 = 7。回数は2回なので、平均値は 7 ÷ 2 = 3.5 になりました。
さらに振ると「5」。合計は 12、回数は3回。平均値は 12 ÷ 3 = 4.0 です。
このように、最初のうちは一回ごとの結果に大きく影響されて、平均値は激しく上下します。でも、これを100回、1,000回、1万回と続けていくと、どうなるでしょうか?
面白いことに、あれだけ暴れていた平均値が、まるで何かに吸い寄せられるかのように、理論上の期待値である「3.5」という一点に向かって、どんどん収束していくんです。
この様子を簡単な図で見てみましょう。
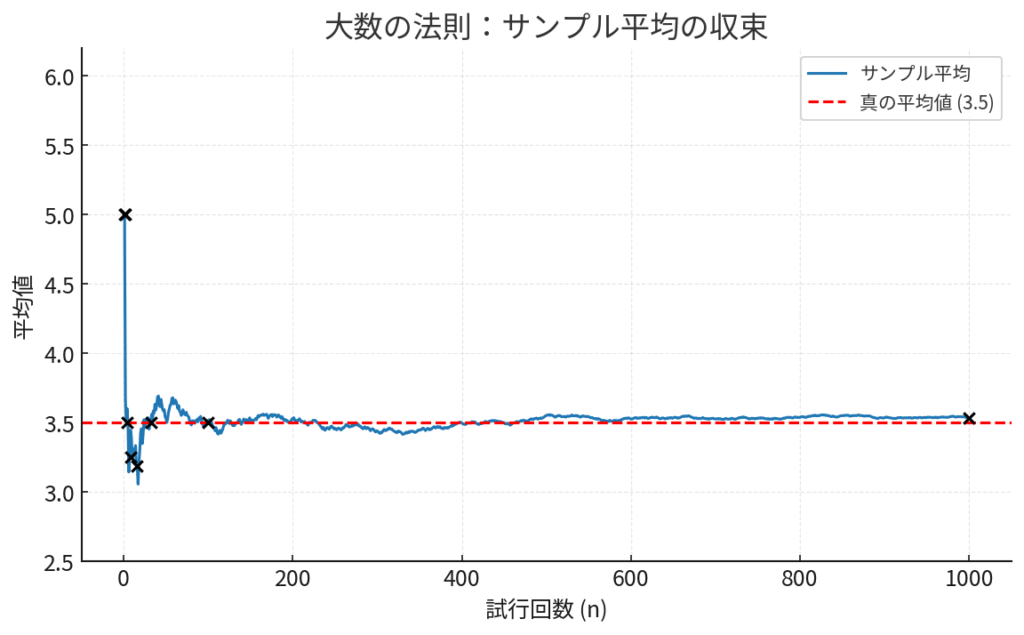
図の解説: この図は、横軸にサイコロを振った回数(試行回数)、縦軸に出た目の平均値を示しています。最初はxの位置が大きくブレていますが、試行回数が増えるにつれて、平均値が真の値である3.5の水平線に近づいていく様子がイメージできるかと思います。
臨床現場における大数の法則
この「回数を増やせば真実に近づく」という考え方は、私たちの臨床や研究の世界では、ごく当たり前に応用されています。
例えば、新しい降圧薬の効果を検証する臨床試験を考えてみましょう。もし被験者がたった5人だったらどうでしょう? たまたま薬がものすごく効く体質の人ばかりが集まれば、その薬は「奇跡の薬」に見えるかもしれません。逆に、効果が出にくい人ばかりだったら、「全く効かない薬」という誤った結論になってしまいますよね。
だからこそ、臨床試験では何百人、何千人という多くの被験者にご協力いただくわけです。被験者の数(サンプルサイズ)を増やすことで、個人の体質や生活習慣といった「ばらつき」の影響が平均化され、その薬が持つ「真の効果」をより正確に推定できる。これもまさに大数の法則の力です (DeGroot & Schervish, 2012)。
つまり、私たちが日頃から「エビデンスレベルが高い」と考える大規模臨床試験の信頼性は、この大数の法則というシンプルな原理に支えられているのです。
では、本題へのバトンタッチ
さて、大数の法則が教えてくれたのは、「平均が『ある一点(真の平均)』に収束していく」という、ゴール地点の話でした。
でも、ここで一つ新しい疑問が湧いてきませんか?
「平均値は確かに真の値に近づいていく。でも、その近づいていく過程での『ばらつき方』には、何かルールがあるんだろうか?」
サイコロの例で言えば、100回振った時点での平均値も、1000回振った時点での平均値も、ぴったり3.5になるわけではありません。必ず少しはズレていますよね。その「ズレ方(ばらつき方)」の分布は、一体どんな形をしているのでしょうか。
この問いに答えてくれるのが、いよいよ登場する主役、中心極限定理なのです。
主役の登場!の前に:標本分布ってなんだ?
大数の法則で、「たくさんのデータを集めれば、その平均は『真の値』に近づいていく」という心強い事実を知りましたね。でも、ここで現実の世界を考えてみてください。私たちの研究や臨床調査では、何度も何度も無限に調査を繰り返すなんてことは、まず不可能です。通常、私たちが手にできるのは「たった1回」の調査で得られた「1つの標本(サンプル)」だけです。
「たった1つの標本から得られた平均値」を頼りに、どうやって「決して知ることのできない母集団全体の真の平均値」について語ればいいのでしょうか?
この絶望的にも思える問いに、光明を差してくれるのが「標本分布(Sampling Distribution)」という考え方です。これは、いわば思考実験の世界に作り上げる、統計的推論のためのシミュレーション舞台のようなものです。
まずは言葉の整理から:母集団と標本、パラメータと統計量
この舞台設定を理解するために、少しだけ言葉の定義をはっきりさせておきましょう。ごちゃごちゃになりやすいのですが、ここを区別できると、この後の話が驚くほどクリアになります。
統計用語の比較表
| 用語 | 意味 | 具体例 | ポイント |
|---|---|---|---|
| 母集団 (Population) | 関心のある対象すべてを含む集団 | 日本の2型糖尿病患者全員 | 全体を把握するのは不可能 |
| 標本 (Sample) | 母集団から選び出された一部分 | A病院に通院する2型糖尿病患者200人 | 実際に私たちが観察できるデータ |
| 母数 (Parameter) | 母集団の特性を表す値(母平均 μ, 母分散 σ2 など) | 日本の2型糖尿病患者全員の真の平均HbA1c値 | 知りたいけど知ることができない真の値 |
| 統計量 (Statistic) | 標本から計算される値(標本平均 x, 標本分散 s2 など) | 200人の患者の計算された平均HbA1c値 | 私たちの手元にある唯一の手がかり |
私たちの目的は、手元にある統計量(標本データ)を手がかりにして、未知なる母数(真の値)を賢く推測する「統計的推論」を行うことです。そして、その推論のロジックを支える土台こそが、標本分布なのです。
思考実験:標本分布を作ってみよう!
では、この標本分布という舞台を、思考実験で一緒に組み立てていきましょう。テーマは「日本人成人男性の収縮期血圧」とします。
Step 1:母集団から、標本を1つ取り出す
まず、巨大な壺(母集団)の中に、日本人成人男性全員の血圧データが書かれた紙が入っていると想像してください。この壺の中から、目を閉じてランダムに100枚(サンプルサイズ \(n=100\))の紙を引いてきます。これが1つ目の「標本」です。
Step 2:標本の平均値を計算し、記録する
取り出した100枚の紙に書かれた血圧の値をすべて足し、100で割ります。これが1つ目の「標本平均 \(\bar{x}_1\) 」です。計算したら、その数値をグラフ用紙の横軸上の対応する場所に、小さな点でプロットします。
Step 3:標本を母集団に戻し、シャッフルする
ここが思考実験のミソです。一度引いた100枚の紙を、再び壺の中に戻して、よーくかき混ぜます。これにより、次に引くときも条件は全く同じになります。(理論上、これを復元抽出と呼びます)
Step 4:Step 1と2を、何度も何度も…繰り返す!
再び壺から100枚の紙を引き、2つ目の標本平均 \(\bar{x}_2\) を計算して、同じグラフ用紙にプロットします。また紙を戻してシャッフルし、3つ目の標本平均 \(\bar{x}_3\) を計算してプロット…。
この作業を、コンピュータの力を借りて、1万回、10万回と繰り返したとしましょう。グラフ用紙の上には、無数の「標本平均」の点がプロットされていきます。
するとどうでしょう。最初はバラバラに打たれていた点たちが、次第にある一点を中心に、一つのなだらかな山のような形を形成していきます。この、無数の標本平均たちが作り上げた分布、それこそが「標本分布」の正体です。
このプロセスを図で見てみましょう。
図の解説: 左側にあるのが、元の母集団の分布です。これは正規分布のように綺麗な形とは限りません。この母集団から、標本(サンプル)を何度も何度も取り出し、その都度「標本平均(\(\bar{x}\))」を計算します。そうして得られたたくさんの標本平均をプロットしていくと、右側のような一つの山なりの分布(標本分布)が形成される、という思考実験のプロセスを表しています。
で、この「舞台」がなぜ重要なの?
「なるほど、標本分布が何なのかは分かった。でも、現実には1回しか調査しないのに、なぜこんな架空の分布を考える必要があるの?」
素晴らしい疑問だと思います。
標本分布が教えてくれるのは、「もし仮に、あなたの調査と同じことを何度も繰り返したとしたら、得られるであろう『標本平均』という値は、どのような確率で、どのあたりにばらつくのか」という、統計量の振る舞いそのものなんです。
この振る舞い(=分布の形や中心、ばらつき具合)が予測できれば、私たちがたった一度の調査で手にした「たった1つの標本平均」が、その分布の中のどのあたりに位置するのかを客観的に評価できます。そして、その位置情報から、「真の母平均は、おそらくこのへんだろう」と、根拠を持って推測する道が開けるのです。
さあ、舞台は完璧に整いました。
この「標本分布」という舞台の上で、一体どんな美しくてパワフルな魔法が起きるというのでしょうか?
いよいよ、主役である中心極限定理の登場です。
これぞ魔法:中心極限定理のすごいところ
さあ、舞台は整いました。「標本分布」という、思考実験上のシミュレーション舞台です。この舞台の上で、統計学の主役とも言える、驚くほど美しくてパワフルな法則が姿を現します。それが中心極限定理(Central Limit Theorem, CLT)です。
私がこの定理を初めて学んだとき、「これはまるで魔法だ」と素直に感動したのを覚えています。この定理が、バラバラに見えるデータの世界に、いかに美しい秩序を与えてくれるか、ぜひ体感してみてください。
この定理の主張は、こうです。
元の母集団がどんな形の分布をしていようとも(たとえ正規分布でなくても)、そこから取り出した標本のサイズ \( n \) が十分に大きければ、その標本平均の分布(標本分布)は、近似的に正規分布に従う。
すごいと思いませんか? ここが一番面白いところなんです。元の材料がどんな形であれ、そこから取り出したサンプル(標本)の「平均」という操作を加えるだけで、その平均値たちの分布は、あの美しい釣り鐘型の正規分布へと姿を変えるのです。
いびつな分布が、なぜか綺麗な正規分布に
例えば、病院の外来患者さんの「待ち時間」を思い出してください。ほとんどの方は10〜20分で診察に呼ばれる一方、緊急の患者さん対応などがあれば、ごく稀に1時間以上待つ方もいるかもしれません。この「待ち時間」のデータを集めて分布を見ると、おそらく正規分布のような左右対称の形にはならず、長い待ち時間の方に裾が伸びた、いびつな形(右に歪んだ分布)をしているはずです。
しかし、ここからが魔法の始まりです。
この病院で、毎日ランダムに30人(\(n=30\))の患者さんを選び、その30人の「平均待ち時間」を計算して記録します。この作業を何百日、何千日と繰り返して、「平均待ち時間」のデータがたくさん集まったとしましょう。
この「平均待ち時間」たちの分布を描いてみると…なんと、元の分布がいびつだったことなど嘘のように、平均値を中心とした左右対称の、美しい正規分布が浮かび上がってくるのです。
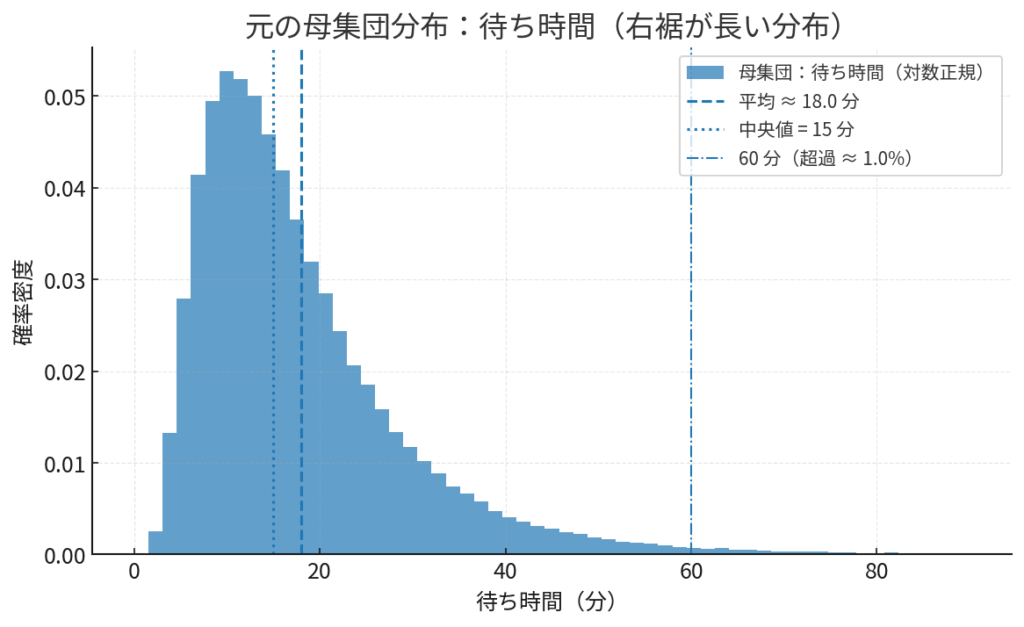
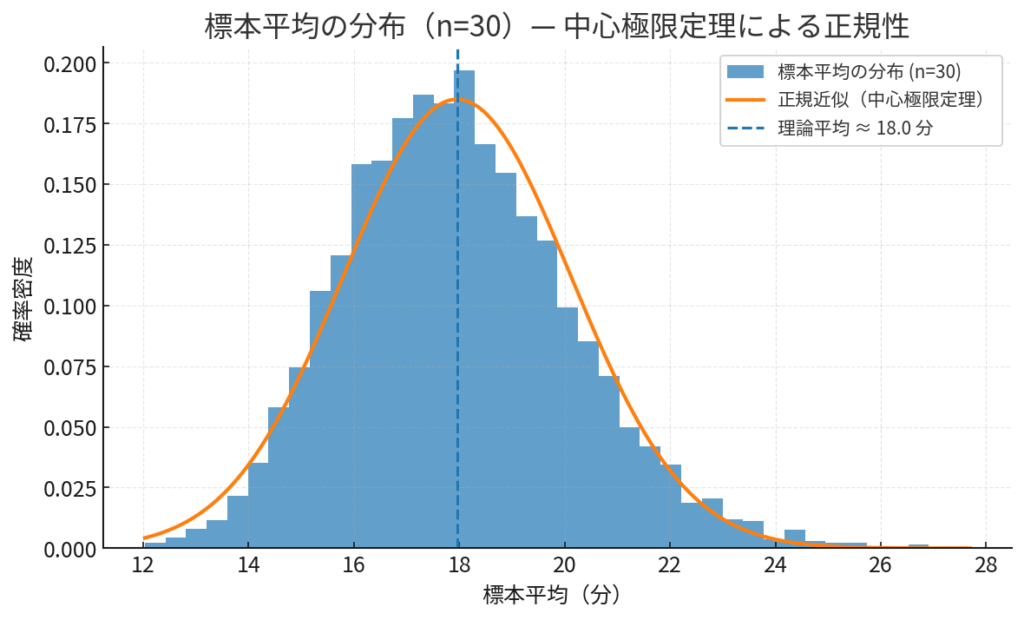
図の解説: 左側が、元の個々の患者さんの待ち時間の分布です。右に歪んでいるのが特徴です。しかし、この母集団から30人ずつの標本を取り出し、その「平均値」を何度も計算して集めると、右側のような綺麗な正規分布(標本分布)が生まれます。これが中心極限定理の視覚的なイメージです。
一体なぜこんな不思議なことが起きるのでしょうか?
厳密な証明は大学レベルの数学が必要ですが、直感的なイメージは「たくさんの独立した偶然が足し合わされると、お互いの極端な値が打ち消し合い、結果は『平均的な値』に落ち着きやすくなる」というものです。極端に大きい値も、極端に小さい値も、平均を取る過程でならされていき、結果として真ん中が一番多い「山なり」の分布に収斂していく、とイメージすると分かりやすいかもしれません (Nishiyama, 2013)。
「十分に大きい」って、どれくらい?
定理の中にある「標本のサイズ \( n \) が十分に大きければ」という部分、気になりますよね。一体どれくらいが「十分」なのでしょうか。
これはケースバイケースですが、統計学の世界では、古くからの経験則として「 \( n \geq 30 \) 」というのが一つの目安とされています (Walpole et al., 2012)。サンプルサイズが30以上あれば、多くの場合、中心極限定理がかなり良く成り立つと考えてよいでしょう。
ただし、これはあくまで目安です。元の母集団の分布の歪みが非常に大きい場合は、標本分布が正規分布に近づくためにもっと多くのサンプルサイズ(例えば\(n=50\)や\(n=100\)など)が必要になることもあります。
この魔法が、私たちにくれる「贈り物」
中心極限定理のおかげで、私たちは元のデータがどんな性質を持っているか詳しく知らなくても、「標本平均は正規分布という、非常に性質がよく知られた扱いやすい分布に従う」と考えることができます。
これがどれほど強力なことかというと、
- 予測の武器になる: 正規分布は、その平均と標準偏差さえ分かれば、データがどの範囲にどのくらいの確率で収まるかを完全に記述できます。つまり、標本平均の振る舞いを確率的に予測できるようになります。
- 比較の土台になる: 医療統計でよく使われるt検定や分散分析といった多くの統計手法は、データが正規分布に従うことを前提としています。中心極限定理は、サンプルサイズが十分にあれば、この前提をクリアしてくれるため、これらの強力な分析手法を使うためのお墨付きを与えてくれるのです。
- 推論の扉を開く: 「私たちの手元にあるたった一つの標本平均は、この正規分布のどこか一点からやってきた」と考えることで、「では、この分布の真ん中(=真の母平均 \( \mu \))は、どのあたりにある可能性が高いだろうか?」という推論(区間推定)への道が拓けます。
実は、中心極限定理は標本分布の形だけでなく、そのスペック(平均と分散)についても教えてくれます。
- 標本分布の平均は、なんと母集団の平均 \( \mu \) と等しくなります。
- 標本分布の分散は、母集団の分散 \( \sigma^2 \) をサンプルサイズ \( n \) で割った値 \( \frac{\sigma^2}{n} \) になります。
これは、「標本平均のばらつきは、元のデータのばらつきが小さいほど、そしてサンプルサイズが大きいほど小さくなる」という直感とも一致しますよね。
そして、この標本分布の標準偏差 \( \sqrt{\frac{\sigma^2}{n}} = \frac{\sigma}{\sqrt{n}} \) こそが、次のセクションで登場する「標準誤差」の正体なのです。
魔法の杖を手に入れる:標準誤差という名のコンパス
中心極限定理という魔法によって、私たちの舞台(標本分布)には、必ず「正規分布」という美しい山が現れることがわかりました。素晴らしいですよね。でも、ここで一つ考えてみてください。その山の形は、いつも同じでしょうか?
あるときは、富士山のように雄大でなだらかな山かもしれませんし、またあるときは、槍ヶ岳のように天を突く鋭い山かもしれません。この山の「鋭さ」、すなわち推定の精度を測るための道具、それこそが今回ご紹介する「標準誤差(Standard Error, SE)」です。これは、不確かなデータの世界で、私たちが進むべき方向と確からしさを教えてくれる、まさに「魔法の杖」や「コンパス」のような存在です。
最重要!「標準偏差」と「標準誤差」、あなたは見分けられますか?
本題に入る前に、多くの方が一度は混乱するであろう、二つの「標準」の付く言葉の違いを、ここで完全にクリアにしておきましょう。「標準偏差 (Standard Deviation, SD)」と「標準誤差 (Standard Error, SE)」です。この二つは似て非なるもので、目的が全く違います。
この違いを理解することが、統計的な論文を正しく読むための第一歩と言っても過言ではありません。
| 項目 | 標準偏差 (Standard Deviation, SD) | 標準誤差 (Standard Error, SE) |
|---|---|---|
| 何を表す? | 1つの標本内での、個々のデータのばらつき具合 | 標本平均のばらつき具合(=推定の不確かさ) |
| 誰のばらつき? | データ(患者さん一人ひとり)のばらつき | 統計量(標本平均という代表値)のばらつき |
| 目的は? | 手元にあるデータの分布の広がりを記述 (Describe) する | 母集団の平均をどれだけ正確に推測 (Infer) できているか |
| たとえるなら? | クラス全員の身長のばらつき | 何度もクラスから5人選んだ時の「5人の平均身長」のばらつき |
標準偏差 (SD) は、あくまで手元にあるサンプル内の話です。200人の患者さんの血圧データがあれば、その200人のデータが平均値からどれくらい散らばっているかを示します。
一方、標準誤差 (SE) は、思考実験の世界(標本分布)の話です。「もし、同じように200人の患者調査を何度も繰り返したら、その都度計算される『平均血圧』は、どれくらいばらつくだろうか?」という、平均値そのものの信頼性・安定性を示す指標なのです。
標準誤差の計算式と、そのココロ
では、この標準誤差はどうやって計算されるのでしょうか。その式は、驚くほどシンプルです。
\[ SE = \frac{\sigma}{\sqrt{n}} \]
この式の各パーツが、私たちのコンパスの精度をどう決めているのか、じっくり見ていきましょう。
- \( SE \): これが標準誤差です。標本平均のばらつきの大きさを示します。
- \( \sigma \) (シグマ): これは母集団の標準偏差です。私たちが知りたい集団の、元々の個人差の大きさだと思ってください。
- \( n \): これは標本のサイズ(サンプルサイズ)です。
この式が教えてくれるのは、推定の精度(SEの小ささ)を上げる方法は二つしかない、ということです。
- 分子 \( \sigma \) を小さくする: 元々のばらつきが小さい集団を対象にすれば、当然、そこから得られる平均値も安定します。例えば、厳密に管理された同じ系統の実験動物のデータは、多様な背景を持つヒトのデータよりも \( \sigma \) が小さく、結果としてSEも小さくなる傾向があります。
- 分母 \( n \) を大きくする: これが、私たちが現実的にコントロールできる、最も強力な方法です。サンプルサイズ \( n \) を増やせば増やすほど、分母が大きくなり、SEは小さくなります。
サンプルサイズ \( n \) が大きくなると、標本分布の山がどう変わるか、イメージしてみましょう。
図の解説: サンプルサイズ(n)が小さいと、標本平均のばらつき(SE)は大きくなり、標本分布は幅の広いなだらかな山になります。一方、サンプルサイズを大きくすると、SEは小さくなり、標本平均は真の値の周りに密集するため、分布は幅の狭い鋭い山になります。つまり、推定の信頼性が格段に向上するわけです。
現実世界での使い方:未知の \( \sigma \) をどうするか?
「なるほど、理屈はわかった。でも、母標準偏差の \( \sigma \) なんて、母平均と同じで事前に分からない『神のみぞ知る値』じゃないか」と思われた方、その通りです。素晴らしい洞察です。
そこで実務上は、手元にある標本標準偏差 ( \( s \) ) を、未知の \( \sigma \) の代わり(推定値)として使います。
\[ \hat{SE} = \frac{s}{\sqrt{n}} \]
(\( \hat{SE} \) のようにハット記号が付いているのは、これが母数そのものではなく、データから計算した「推定値」であることを示しています。)
この一本の式によって、私たちは手元のデータ(\( s \) と \( n \))だけで、そのデータの代表値である「平均値」が、どれくらい信頼できるのかを数値化できるようになったのです。
標準誤差が拓く未来:「95%信頼区間」への扉
さて、この標準誤差という杖を手に入れた私たちは、一体どんな新しいことができるようになるのでしょうか?その最大の応用が、論文や学会発表で必ず目にする「95%信頼区間 (95% Confidence Interval, 95% CI)」の計算です。
正規分布の性質を思い出してください。平均値から±約2標準偏差(正確には1.96)の範囲に、データの約95%が含まれます。この性質を中心極限定理によって正規分布に従う「標本分布」に当てはめてみましょう。
つまり、「もし調査を100回繰り返せば、そのうち95回は、得られた標本平均 \( \bar{x} \) が、真の母平均 \( \mu \) を中心とした \( \mu \pm 1.96 \times SE \) の範囲内に収まる」と期待できます。
この関係を、今いる「手元の標本平均 \( \bar{x} \)」の視点からひっくり返して解釈すると、
「\( \bar{x} – 1.96 \times SE \) から \( \bar{x} + 1.96 \times SE \) までの区間」を計算すれば、その区間の中に真の母平均 \( \mu \) が含まれていると、95%の確信度で言える。
これが、95%信頼区間の本質的な考え方です (Altman & Bland, 2005)。
標準誤差という杖を使うことで、私たちは「A群の平均値は125でした」という点の報告だけでなく、「A群の真の平均値は、95%の信頼度で120から130の間に含まれるでしょう」という、推定の精度情報を含んだ「幅(区間)」で結果を語ることができるようになったのです。これは、科学的なコミュニケーションにおける、とてつもなく大きな進歩でした。
まとめ:バラつきの奥にある「秩序」を見つける旅
さて、統計学の心臓部を巡る私たちの旅も、いよいよ終着点です。振り返ってみると、私たちは一見バラバラで、混沌としているように見えるデータの世界に、いかに美しく、力強い「秩序」が隠されているかを見てきました。
旅の始まりは、一つの素朴な信条からでした。大数の法則という名のコンパスは、「たくさんデータを集めさえすれば、その平均は必ず『真実』の一点を指し示す」と教えてくれました。これは、私たちがデータという大海原へ漕ぎ出すための、最初の、そして最も重要な道しるべでした。
しかし、現実の世界では、無限に航海を続けることはできません。私たちの手元にあるのは、たった一回の航海で得られた、一枚の海図(標本)だけです。そこで私たちは、思考実験の力を借りて、「もし、この航海を何度も繰り返したら、どんな海図が描かれるだろうか?」というシミュレーションの舞台、標本分布を心の中に描き出しました。
すると、その舞台の上で、私たちは魔法のような光景を目撃します。主役である中心極限定理が、元の海の形(母集団分布)がどんなに荒れていようとも、海図の中心点(標本平均)の描く軌跡は、必ず美しく予測可能な「正規分布」という航路を描くことを見せてくれたのです。カオスの中から、普遍的なパターンが浮かび上がった瞬間でした。
そして最後に、私たちはその航路の精度を測るための道具、標準誤差という名の杖を手に入れました。この杖は、私たちの現在地(手元の標本平均)が、真の目的地(母平均)からどれくらい離れている可能性があるのか、その「推定のブレ」を数値化して教えてくれます。
この一連の知識、すなわち「大数の法則」「標本分布」「中心極限定理」「標準誤差」は、独立したバラバラの概念ではありません。これらは一つながりの物語であり、私たちが「たった一つの標本」という限られた情報から、「決して全貌を見ることのできない母集団」という壮大な真実を、いかに論理的に、いかに謙虚に推測していくかのプロセスそのものです。
この旅を終えた今、あなたが研究論文の結果を目にするとき、そこに書かれた平均値やp値は、もはや単なる数字には見えないはずです。その数字の背後にあるデータの広がり、推定の確かさ、そして「もし研究を繰り返したら…」という無数の可能性の世界が、以前よりもずっと豊かに見えてくるのではないでしょうか。
一見すると複雑な数式や概念も、その一つひとつの意味と役割を物語として捉え直してみると、そこには驚くほどシンプルで合理的な世界が広がっている。この感覚が、少しでも伝わっていたら、これほど嬉しいことはありません。
参考文献
- Altman, D. G., & Bland, J. M. (2005). Standard deviations and standard errors. BMJ, 331(7521), 903.
- Bernoulli, J. (1713). Ars conjectandi, opus posthumum. Basileae, Impensis Thurnisiorum, fratrum.
- Cumming, G., Fidler, F., & Vaux, D. L. (2007). Error bars in experimental biology. The Journal of Cell Biology, 177(1), 7-11.
- DeGroot, M. H., & Schervish, M. J. (2012). Probability and statistics (4th ed.). Addison-Wesley.
- Flegal, K.M., Carroll, M.D., Kit, B.K. and Ogden, C.L. (2012) ‘Prevalence of obesity and trends in the distribution of body mass index among US adults, 1999-2010’, JAMA, 307(5), pp. 491–497.
- Kwak, S. and Kim, J. (2017) ‘Central limit theorem: the cornerstone of modern statistics’, Korean Journal of Anesthesiology, 70(2), p. 144.
- Montgomery, D.C. and Runger, G.C. (2018) Applied statistics and probability for engineers. 7th edn. John Wiley & Sons.
- Nishiyama, Y. (2013). The central limit theorem, a fascinating and beautiful principle of probability theory. International Journal of Mathematical Education, 3(2), pp. 91-102.
- Rosen, B. (1995) ‘Asymptotic theory for order sampling’, Journal of Statistical Planning and Inference, 46(2), pp. 135–158.
- Walpole, R. E., Myers, R. H., Myers, S. L., & Ye, K. (2012). Probability & statistics for engineers & scientists (9th ed.). Prentice Hall.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




