

TL; DR (要約)
AIは「学びすぎ(過学習)」ても「学び足りない(未学習)」てもダメ。
モデルの性能を最大化し、未知のデータにも強い「ちょうど良い学習」を実現するための、3つの必須テクニックです。
① アーリーストッピング
(学習の「潮時」)
検証データの性能が悪化し始めたら、過学習が始まるサイン。その直前のベストな状態で学習を自動停止させます。
② データ拡張
(症例の「水増し」)
1枚の画像を回転・反転させるなどして、AIに多様な症例を擬似的に経験させ、未知のデータへの対応力を鍛えます。
③ 正則化
(モデルへの「規律」)
L2正則化やドロップアウトでモデルの複雑さにペナルティを与え、特定の知識への過信を防ぎ、より汎用的な判断を促します。
この章の学習目標と前提知識
はじめに
これまでの講座でニューラルネットワークの構築から、PyTorchを用いた画像処理(第14回)、系列データ分析(第15回)まで、様々なモデルを実装する技術を学んできました。いよいよ、AIモデルを「育てる」最終段階、その性能を最大限に引き出し、実臨床に耐えうる頑健なモデルへと仕上げるための重要なテクニックを学びます。
AIモデルを訓練するということは、優秀な研修医を育てるプロセスに似ています。教科書(訓練データ)の内容をただ暗記するだけでは、初めて見る症例(未知のデータ)に対応できません。逆に、勉強不足では簡単な症例すら診断できません。
今回のテーマは、このAIの「学びすぎ」と「学び足りない」問題、すなわち過学習(Overfitting)と未学習(Underfitting)です。これらの問題をいかにして検出し、効果的な対策を講じるか。具体的には、以下の3つの強力な武器を実装レベルでマスターします。
- アーリーストッピング (Early Stopping):学習の「潮時」を見極め、最高の性能で訓練を打ち切る技術。
- データ拡張 (Data Augmentation):手持ちのデータを「水増し」し、AIに多様な症例を経験させる技術。
- 正則化 (Regularization):モデルに「規律」を与え、知識の偏りを防ぎ、汎用性を高める技術。
これらの手法は、構築したAIモデルの診断精度と信頼性を飛躍的に向上させる鍵となります。それでは、AIモデルの「健康診断」と「トレーニング法」を学んでいきましょう。
1. 過学習と未学習:AIモデルの「診断精度」を左右する二大問題
モデルの性能を評価する際、私たちはデータを「訓練用(Train)」と「検証用(Validation)」に分割します。これは、模擬試験(訓練)で勉強し、その実力を確認模試(検証)で測るのと同じです。
1.1. 過学習 (Overfitting)
過学習とは、モデルが訓練データに過剰に適合してしまい、訓練データでは非常に高い精度を出すものの、未知の検証データやテストデータに対しては性能が著しく低下する現象です(1)。
- 直感的な理解:特定の模擬試験の問題と答えのパターンを完全に「丸暗記」してしまった学生の状態です。その模擬試験では満点を取れますが、少し形式の違う本番の試験では全く歯が立ちません。
- 医療での例:ある特定の病院の、特定の撮影機器で撮られたレントゲン画像データセットだけで肺炎診断AIを学習させたとします。モデルは、その画像のノイズや明るさといった本質的でない特徴まで学習してしまい、他の病院の異なる機器で撮影されたレントゲン画像では、肺炎を正しく診断できなくなる可能性があります。
- 検出方法:学習を進めると、訓練データに対する損失(誤差)は順調に下がり続けますが、ある時点から検証データに対する損失が上昇に転じます。この「損失の乖離」が過学習のサインです。
(注: 以下に示す学習曲線のグラフは、このような損失の乖離を視覚的に捉えるためのものです。実際のグラフは後のコードで描画します)
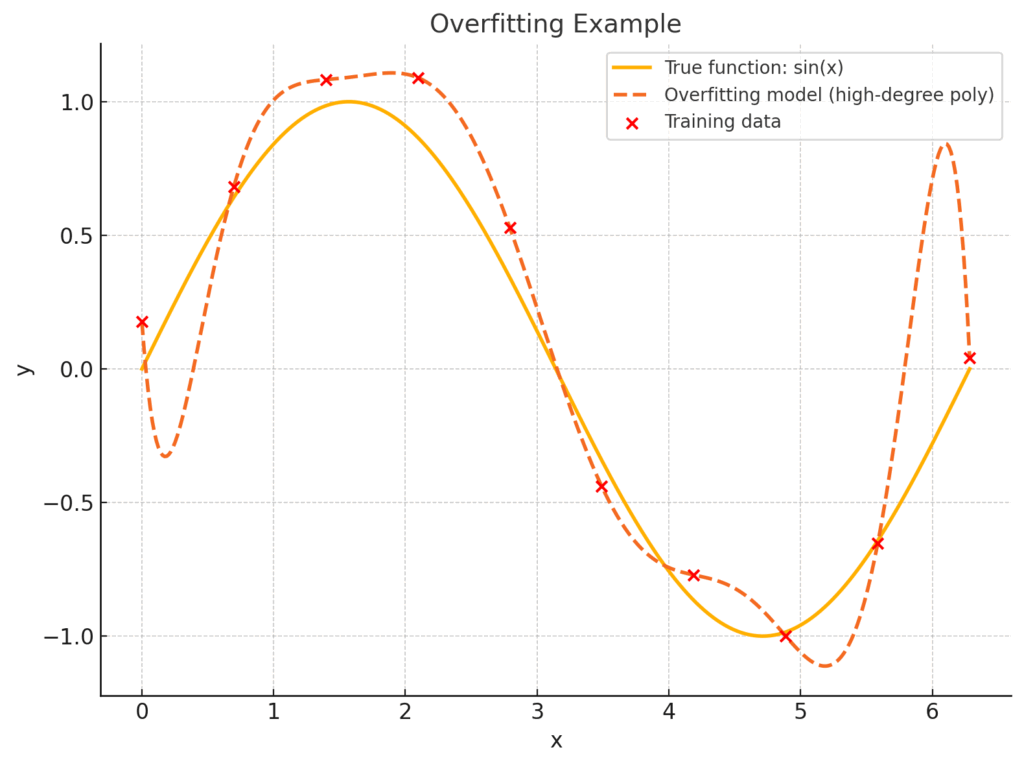
1.2. 未学習 (Underfitting)
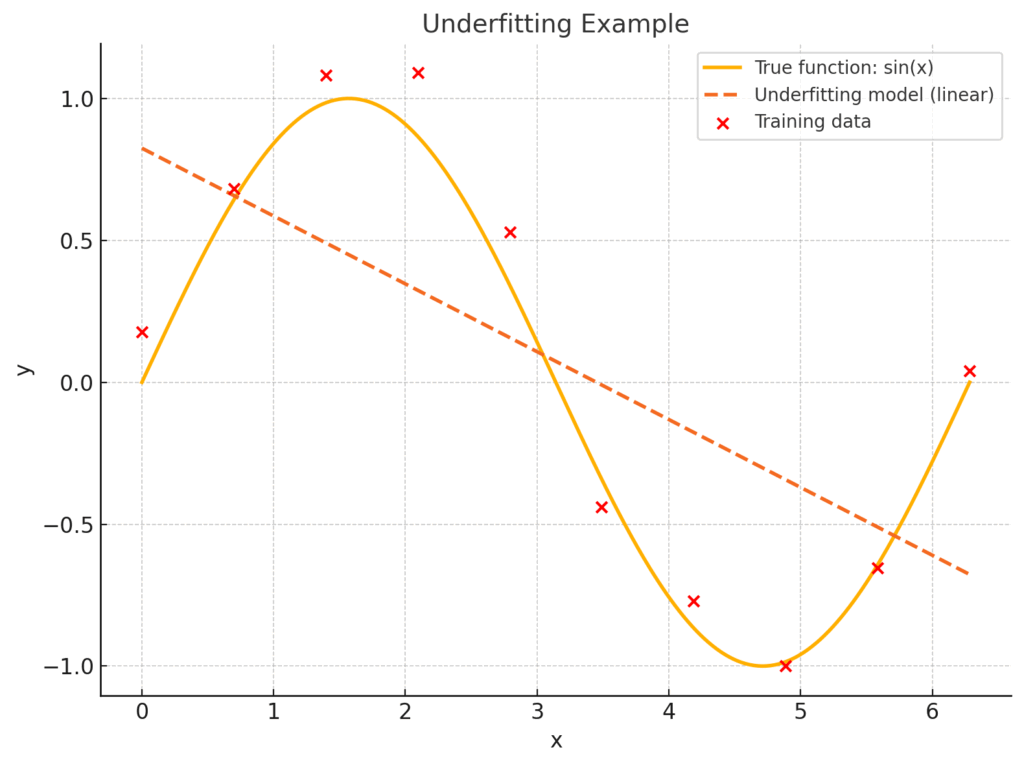
未学習とは、モデルが単純すぎるか、学習が不十分であるために、訓練データの特徴すら十分に捉えられていない状態です(2)。
- 直感的な理解:勉強時間が足りず、模擬試験の時点ですでに点数が低い状態です。当然、本番の試験でも良い成績は期待できません。
- 医療での例:心電図の複雑な波形から心筋梗塞の兆候を予測しようとする際に、単純な線形回帰モデル(直線のモデル)を使おうとするようなケースです。モデルが単純すぎて、非線形で複雑な心電図のパターンを表現しきれません。
- 検出方法:訓練データと検証データの両方で、損失が高いままで一向に下がりません。
目指すべきは、この両者の中間にある「ちょうど良い学習(Good Fit)」の状態です。訓練データと検証データの両方で損失が十分に低く、安定している状態を指します。これから、過学習を避け、この理想的な状態に近づけるための具体的な手法を学んでいきましょう。
2. 対策①:アーリーストッピング (Early Stopping) ― 学習の「潮時」を見極める
さて、ここからは過学習に対する具体的な対策を見ていきましょう。一つ目は、おそらく最も直感的で効果的な手法、アーリーストッピング(早期終了)です。
学習を進めていくと、訓練データでの成績(損失)はどんどん良くなるのに、ふとした瞬間に、未知のデータに対する成績(検証損失)が頭打ちになり、やがて悪化し始める…という現象に出くわします。これはまさに、モデルが訓練データを「丸暗記」し始めて、応用力が失われていく過学習のサインですよね。
アーリーストッピングのアイデアは、非常にシンプルです。「検証データの成績が悪化し始めたら、その直前の最も成績が良かった時点で学習を止めれば良い」という、まさに学習の「潮時」を見極めるアプローチです(3)。
臨床研究で新薬の至適用量を決めるプロセスを思い浮かべてみてください。投与量を増やすほど効果は高まりますが、ある量を超えると副作用が目立ち始めますよね。アーリーストッピングは、その「効果が最大で、副作用が許容範囲に収まるベストな投与量(エポック数)」を見つけて、そこで投与(学習)を打ち切る、という考え方とそっくりです。この方法なら、過学習という「副作用」が深刻になる前に、最も汎化性能の高い、つまり実用的なモデルを手に入れることができます。
アーリーストッピングの判断ロジック
では、具体的にどうやって「潮時」を判断するのでしょうか。そのロジックは、以下のような流れになっています。
この流れをもう少し言葉で説明すると、
- 毎エポックの終わりに、検証データの損失を計算します。
- その損失が、今までの記録(最小損失)を更新したら、「お、まだ良くなってるな」と判断し、その時のモデルの重みをファイル(例:
checkpoint.pt)に保存します。そして、後述する「カウンタ」をリセットします。 - もし記録を更新できなければ、「あれ、停滞期かな?」と考え、カウンタを1つ増やします。
- この「記録を更新できない状態」が、あらかじめ決めておいた回数(これを
patienceと呼びます)連続で続いたら、「もうこれ以上良くならないだろう。むしろ悪化するサインかもしれない」と判断し、学習を完全にストップします。
この仕組みのおかげで、私たちは学習が終わるのをただ待つのではなく、自動的に最適なモデルが保存され、かつ無駄な計算時間を削減できるというわけです。
PyTorchによる実装
この便利なアーリーストッピングですが、PyTorchには残念ながらsklearnのように標準機能としては備わっていません。でも、ご安心ください。ロジック自体はシンプルなので、一度クラスとして作ってしまえば、どんなプロジェクトでも使い回せる便利な「部品」になります。
なぜクラスで実装するのかというと、アーリーストッピングは「これまでの最小損失はいくつか?」「何回連続で改善していないか?」といった状態を記憶しておく必要があるからです。そういった状態と、それに関連する振る舞い(判定や保存)を一つのクラスにまとめておくと、メインの学習コードがごちゃごちゃせず、非常にスッキリします。
主要なハイパーパラメータ
実装に入る前に、EarlyStoppingクラスで設定する主要なパラメータ(引数)について整理しておきましょう。これらを調整することで、アーリーストッピングの挙動をコントロールできます。
| パラメータ | 型 | 説明 | 設定のヒント |
|---|---|---|---|
patience | int | 我慢強さ。検証損失が改善しなくても、何エポック待つか。 | 最初は5〜10くらいで試すのが一般的です。小さすぎるとノイズで早期終了しやすく、大きすぎると過学習が進みすぎる可能性があります。 |
verbose | bool | おしゃべりモード。Trueにすると、損失が改善してモデルを保存した際や、カウンタが増えた際にメッセージを表示します。 | Trueにしておくと、学習の進行状況が分かりやすくなるのでおすすめです。 |
delta | float | 改善とみなす最小値。損失がこの値以上改善しないと、改善したとはみなしません。ノイズによるごく僅かな改善を無視するために使います。 | 通常は0で問題ありませんが、損失の変動が激しい場合に小さな値(例:1e-5)を設定することがあります。 |
path | str | ベストモデルの保存場所。最も性能が良かったモデルのパラメータを保存するファイルパス。 | best_model.pt や checkpoint.pt といった名前がよく使われます。 |
サンプルコード
それでは、実際にコードを見ていきましょう。
# 必要なライブラリをインポートします
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset, DataLoader
# matplotlibで日本語を正しく表示するために、japanize-matplotlibをインポートします。
# 事前に !pip install japanize-matplotlib を実行してください。
# この1行を追加するだけで、以降のグラフ描画で日本語が自動的に表示されるようになります。
# plt.rcParams のような個別のフォント設定は不要です。
import japanize_matplotlib
# 1. アーリーストッピングを管理するクラスを定義
class EarlyStopping:
"""検証データの損失を監視し、学習を早期終了するためのクラス"""
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt', trace_func=print):
"""
Args:
patience (int): 検証損失が改善しなくても待つエポック数
verbose (bool): 早期終了や改善の際にメッセージを表示するかどうか
delta (float): 改善とみなすための最小変化量
path (str): 最良モデルを保存するパス
trace_func (function): メッセージを表示するための関数
"""
self.patience = patience # 設定したpatienceをインスタンス変数に格納
self.verbose = verbose # メッセージ表示の有無をインスタンス変数に格納
self.counter = 0 # patienceを数えるためのカウンターを初期化
self.best_score = None # これまでの最良スコアを初期化
self.early_stop = False # 早期終了フラグを初期化
self.val_loss_min = np.inf # 最小検証損失を無限大(inf)で初期化(np.Infは非推奨)
self.delta = delta # 改善とみなす最小変化量をインスタンス変数に格納
self.path = path # モデルの保存パスをインスタンス変数に格納
self.trace_func = trace_func # メッセージ表示用の関数をインスタンス変数に格納
def __call__(self, val_loss, model):
# この__call__メソッドが、このクラスの心臓部です。
# インスタンスを関数のように early_stopping(val_loss, model) と呼び出すと、この中身が実行されます。
score = -val_loss # 損失は低いほど良いので、スコア化する際は符号を反転させます(高いほど良い、とするため)。
if self.best_score is None:
# 1エポック目の場合、無条件でベストスコアとし、モデルを保存します。
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
# スコアが改善しなかった(もしくはdelta分も改善しなかった)場合
self.counter += 1 # 我慢カウンターを1増やします。
self.trace_func(f'アーリーストッピングカウンター: {self.counter} / {self.patience}')
if self.counter >= self.patience:
# 我慢の限界に達したら...
self.early_stop = True # 早期終了の合図を立てます。
else:
# スコアが改善した場合
self.best_score = score # ベストスコアを更新し、
self.save_checkpoint(val_loss, model) # モデルを保存し、
self.counter = 0 # 我慢カウンターをリセットします。
def save_checkpoint(self, val_loss, model):
"""検証損失が改善した場合にモデルを保存するヘルパー関数"""
if self.verbose:
# verbose=Trueの場合、改善メッセージを表示します。
self.trace_func(f'検証損失が改善しました ({self.val_loss_min:.6f} --> {val_loss:.6f})。モデルを保存します...')
torch.save(model.state_dict(), self.path) # モデルのパラメータ(状態)をファイルに保存
self.val_loss_min = val_loss # 最小損失の記録を更新
# 2. サンプルデータとモデルの準備 (ここは説明のため簡略化)
# 架空の医療データを生成(20個の特徴量から2クラス分類を想定)
X = np.random.rand(1000, 20).astype(np.float32)
y = np.random.randint(0, 2, 1000).astype(np.int64)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
train_dataset = TensorDataset(torch.from_numpy(X_train), torch.from_numpy(y_train))
val_dataset = TensorDataset(torch.from_numpy(X_val), torch.from_numpy(y_val))
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)
# 簡単なニューラルネットワークモデルを定義
model = nn.Sequential(
nn.Linear(20, 64),
nn.ReLU(),
nn.Linear(64, 2)
)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 3. 訓練ループにアーリーストッピングを組み込む
# アーリーストッピングのインスタンスを生成します。patience=7に設定してみました。
early_stopping = EarlyStopping(patience=7, verbose=True)
train_loss_list, val_loss_list = [], []
n_epochs = 100
for epoch in range(1, n_epochs + 1):
# --- 訓練フェーズ ---
model.train() # モデルを「訓練モード」に切り替え
train_loss = 0.0
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item() * data.size(0)
# --- 検証フェーズ ---
model.eval() # モデルを「評価モード」に切り替え。これが重要!
val_loss = 0.0
with torch.no_grad():
for data, target in val_loader:
output = model(data)
loss = criterion(output, target)
val_loss += loss.item() * data.size(0)
train_loss = train_loss / len(train_loader.dataset)
val_loss = val_loss / len(val_loader.dataset)
train_loss_list.append(train_loss)
val_loss_list.append(val_loss)
print(f'エポック: {epoch} \t訓練損失: {train_loss:.6f} \t検証損失: {val_loss:.6f}')
# ★★★ ココが核心部! ★★★
# 毎エポックの最後に、検証損失とモデルを渡してアーリーストッピングの判定を呼び出す。
early_stopping(val_loss, model)
if early_stopping.early_stop:
# クラスから「もう限界!」というサイン(early_stop=True)が来たら...
print("早期終了します。")
break # forループを抜けて学習を終了します。
# 最高のモデルを読み込んで、以降の評価などに使用します。
model.load_state_dict(torch.load('checkpoint.pt'))
# 4. 学習曲線をプロット
plt.figure(figsize=(10, 6)) # グラフのサイズを指定
plt.plot(train_loss_list, label='訓練損失 (Train Loss)') # 訓練損失をプロット
plt.plot(val_loss_list, label='検証損失 (Validation Loss)') # 検証損失をプロット
plt.title('訓練と検証の損失の推移') # グラフのタイトル
plt.xlabel('エポック (Epoch)') # X軸のラベル
plt.ylabel('損失 (Loss)') # Y軸のラベル
plt.legend() # 凡例を表示
plt.grid(True) # グリッド線を表示
plt.show() # グラフを表示結果の解釈
このコードを実行すると、コンソールにはエポックごとの損失が表示されます。
エポック: 1 訓練損失: 0.695326 検証損失: 0.686566
検証損失が改善しました (inf --> 0.686566)。モデルを保存します...
エポック: 2 訓練損失: 0.686884 検証損失: 0.683647
検証損失が改善しました (0.686566 --> 0.683647)。モデルを保存します...
... (途中省略) ...
エポック: 15 訓練損失: 0.536761 検証損失: 0.730302
アーリーストッピングカウンター: 1 / 7
エポック: 16 訓練損失: 0.521884 検証損失: 0.741049
アーリーストッピングカウンター: 2 / 7
... (途中省略) ...
エポック: 21 訓練損失: 0.440263 検証損失: 0.817529
アーリーストッピングカウンター: 7 / 7
早期終了します。
この出力と、最終的に表示される学習曲線のグラフを照らし合わせてみてください。 最初は「検証損失が改善しました」というメッセージと共に、グラフのオレンジ色の線(検証損失)が順調に下がっていきます。しかし、エポック15あたりから検証損失が上昇に転じ、改善が見られなくなったため「アーリーストッピングカウンター」が増え始めます。そして、7回連続で改善が見られなかったエポック21の時点で「早期終了します。」というメッセージと共に学習が停止しているのが分かります。
どうでしょう、この仕組みのおかげで、検証損失が大きく跳ね上がってモデルが完全に過学習に陥る前に、学習を打ち切ることができました。そして何より嬉しいのは、手元には自動的に検証損失が最も低かった時点のモデル(checkpoint.pt)が保存されていることです。これこそが、アーリーストッピング最大のメリットだと思います。
3. 対策②:データ拡張 (Data Augmentation) ― 症例を「水増し」して多様性を学ぶ
先ほどのアーリーストッピングは、モデルの「学びすぎ」にブレーキをかける、いわば守りのテクニックでした。今度は逆に、学習の「材料」そのものを豊かにする、攻めのテクニックを見ていきましょう。それがデータ拡張(Data Augmentation)です。
深層学習モデルは、大量のデータを「食べる」ことで賢くなります。しかし、特に医療分野では、プライバシーの問題や希少疾患など、十分な数のデータを集めるのが難しい場面も少なくありません。手元に100件の症例画像しかない…これではAIも限られたパターンしか学べず、すぐに過学習に陥ってしまいます。
こんな時、「もし1枚の画像を、見た目が少しずつ違う10枚の画像に見せかけることができたら、実質10倍のデータで学習できるのでは?」と考えたのがデータ拡張です。手持ちのデータにちょっとした加工を施して、AIの「経験値」を人工的に増やしてしまおう、という賢い工夫ですね(4)。
データ拡張のコンセプトと「やってはいけない」こと
データ拡張の核となるアイデアは、画像の本質的な意味(ラベル)を変えない範囲で、見た目のバリエーションを増やすことです。
例えば、ある患者さんの胸部X線写真があるとします。
- 少し回転させる
- 少し拡大・縮小したり、位置をずらしたりする
- 左右を反転させる
- 撮影時の条件の違いを模倣して、明るさやコントラストを少し変える
これらの加工をしても、その画像が「肺炎である」という本質的な事実は変わりませんよね。AIにこれらの「ちょっと違うけど本質は同じ」画像を見せ続けることで、「あ、撮影角度や明るさが多少違っても、このパターンは肺炎なんだな」と、より本質的な特徴を学んでくれるようになります。結果として、未知のデータに対する頑健性(ロバストネス)が向上するわけです。
ただし、医療データを扱う上で一つ、とても大切な注意点があります。それは「本質的な意味を変えてしまう加工」は避けるべき、ということです。例えば、手書き数字の認識で数字の「6」を上下反転させると「9」になってしまい、ラベルの意味が変わってしまいます。医療画像でも同様に、例えば病理組織画像で特定の細胞の向きが重要な意味を持つ場合、むやみに回転させると診断根拠を破壊してしまうかもしれません。データ拡張を適用する際は、その変換が臨床的な意味合いを壊さないか、常に意識することが重要だと思います。
医療分野での応用例
データ拡張は、扱うデータの種類によって様々な手法があります。
- 医用画像(CT, MRI, 病理画像など):
torchvision.transformsライブラリが非常に強力で、以下のような代表的な手法を簡単に試せます。
変換処理 (transforms.) | 主な効果 | 医療応用のイメージ |
|---|---|---|
RandomRotation | 画像をランダムな角度で回転させる | 撮影時の患者の体位のわずかな傾きをシミュレートする |
RandomAffine | 移動・拡大縮小・せん断などを組み合わせる | 撮影距離や角度のズレ、体の動きなどを再現する |
ColorJitter | 明るさ・コントラスト・彩度などを変更する | 異なる撮影装置や照明条件による画質の違いに対応させる |
RandomHorizontalFlip | 確率的に左右反転させる | (左右の別が重要でない場合に)単純にデータの多様性を2倍にする |
GaussianBlur | 画像にぼかしを入れる | 撮影時のわずかな焦点のズレやノイズを模倣する |
- 時系列データ(心電図(ECG), 脳波(EEG)など): 画像とは少し違うアプローチが取られます。例えば、元データに微小なノイズを加えたり、時間軸を少しだけ伸ばしたり縮めたり(Time Warping)、一部分のデータを隠したり(Masking)といった手法が有効です。これらは、測定機器固有のノイズや、生体信号のわずかな「ゆらぎ」に対するモデルの頑健性を高めるのに役立ちます。
PyTorch (torchvision) による実装
以下のコードは、1枚のダミー画像に、定義した変換処理をランダムに適用して、9パターンの拡張画像を生成・可視化するものです。
import torch
import torchvision.transforms as T
import matplotlib.pyplot as plt
import numpy as np
# !pip install japanize-matplotlib を事前に実行してください
import japanize_matplotlib # matplotlibの日本語表示を簡単にする
# ダミーの医用画像を生成 (1チャンネル, 128x128ピクセルのグレースケール画像)
# (バッチサイズ, チャンネル数, 高さ, 幅) = (1, 1, 128, 128)
dummy_image_batch = torch.randn(1, 1, 128, 128)
# ★エラー修正ポイント★
# 変換処理に渡すために、バッチ次元を削除して3次元テンソル (C, H, W) にします。
dummy_image = dummy_image_batch.squeeze(0)
# 適用するデータ拡張のパイプライン(レシピ)を定義します。
# T.Composeを使うと、複数の変換を順番に実行できます。
data_augmentation_transform = T.Compose([
# 確率p=0.5でランダムに水平反転
T.RandomHorizontalFlip(p=0.5),
# -15度から+15度の範囲でランダムに回転
T.RandomRotation(degrees=15),
# ランダムにアフィン変換(少しだけ移動、90%〜110%で拡大縮小)
T.RandomAffine(degrees=0, translate=(0.1, 0.1), scale=(0.9, 1.1)),
# 明るさとコントラストをランダムに変更
# (注意: ColorJitterの彩度(saturation)や色相(hue)はグレースケール画像には影響しません)
T.ColorJitter(brightness=0.2, contrast=0.2),
])
# 変換前の元画像を取得
# .permute(1, 2, 0) は (C,H,W) を (H,W,C) の順に入れ替えるmatplotlib用のおまじない
original_image_np = dummy_image.permute(1, 2, 0).numpy()
# データ拡張を9回適用して、9パターンの画像を生成
# 毎回ランダムな変換がかかるため、全て違う画像になります
augmented_images = [data_augmentation_transform(dummy_image) for _ in range(9)]
# --- 結果を可視化 ---
fig, axes = plt.subplots(2, 5, figsize=(16, 7))
fig.suptitle('データ拡張 (Data Augmentation) の適用例', fontsize=20)
# 1行目の中央に元の画像を表示
ax_orig = axes[0, 2]
ax_orig.imshow(original_image_np.squeeze(), cmap='gray')
ax_orig.set_title('元の画像 (Original)', fontsize=14)
# 不要な軸を消す
for i in range(5):
axes[0, i].axis('off')
if i != 2: axes[0,i].set_visible(False)
# 2行目に拡張された画像を表示
for i, aug_img in enumerate(augmented_images):
if i >= 5: break # レイアウトの都合上、5枚まで表示
ax = axes[1, i]
# (C,H,W) -> (H,W,C) に並び替えてnumpy配列に変換
img_to_show = aug_img.permute(1, 2, 0).numpy()
ax.imshow(img_to_show.squeeze(), cmap='gray')
ax.set_title(f'拡張後 {i+1}')
ax.axis('off')
# もし9枚すべて表示したい場合は、レイアウトを plt.subplots(2, 5) などから変更してください。
# 例: plt.subplots(3, 4) など
# その場合、元画像を axes[0,0] に、拡張画像を axes.flat[1:] にループで表示すると綺麗です。
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
このコードを実行すると、毎回少しずつ違った「新しい」症例画像が生成されるのがわかるはずです。この変換処理(data_augmentation_transform)を、自作のDatasetクラスの__getitem__メソッドの中に組み込むことで、学習時にミニバッチが作られるたびに、その場でデータ拡張がかかります。これにより、モデルはエポックごとに異なるバリエーションのデータを「食べ」ることになり、より賢く、より頑健に育っていくのです。
4. 対策③:正則化 (Regularization) ― モデルに「規律」を与え、複雑化を防ぐ
これまでの対策を振り返ってみると、アーリーストッピングは「学習のやりすぎ」にブレーキをかける手法、データ拡張は「学習の材料」を豊かにする手法でした。どちらも非常に有効ですが、もう一つ、モデルそのものの「振る舞い」に直接アプローチする方法があります。それが今回紹介する正則化(Regularization)です。
モデルが訓練データに過剰適合するとき、実はモデル内部のパラメータ(重み)に特徴的な変化が起きています。それは、特定のデータパターンを完璧に捉えようとするあまり、一部の重みが極端に大きな値をとってしまう、という現象です。重みが大きいということは、入力のほんのわずかな変化が出力に大きく影響する、非常に「過敏」な状態を意味します。これでは、訓練データにはない些細なノイズにも過剰反応してしまい、安定した予測は望めません。
この状況は、非常に博識で記憶力も抜群だけど、少し融通が利かない専門家に似ているかもしれません。あまりに細かい知識にこだわりすぎるあまり、些細な情報に振り回されてしまい、かえって本質を見誤ってしまう…。正則化は、この専門家に「まあまあ、そんな細かいことは気にせず、もっとシンプルに、大事な要点だけを考えて判断して」と、モデルの複雑さにペナルティを課すことで、より大局的で頑健な判断を促すための「規律」を与えるようなものです(2,5)。
4.1. 損失関数にペナルティを加える:L1/L2正則化
正則化の古典的かつ強力なアプローチが、損失関数に「ペナルティ項」を追加する方法です。私たちがモデルを訓練するときの目標は、損失関数 \( L \) の値をできるだけ小さくすることでしたよね。ここに、モデルの複雑さを表すペナルティ項を付け加えるのです。
\[ L_{total} = L_{original}(\text{データとの誤差}) + \lambda \times R(W, \text{モデルの複雑さ}) \]
この式をじっくり見てみましょう。
- \( L_{original} \) は、これまで見てきたMSEや交差エントロピーのような、モデルの予測と正解データとの「誤差」です。モデルはこの項を小さくしようと、一生懸命データにフィットしようとします。
- \( R(W) \) が今回の主役、正則化項です。これはモデルの重み \(W\) を使って計算される「複雑さの指標」で、この値が大きくなることにペナルティを課します。
- \( \lambda \) (ラムダ)は正則化パラメータと呼ばれ、誤差と複雑さの「綱引き」のバランスを調整する重要な係数です。
- \( \lambda \) が大きいと、モデルは「複雑になるくらいなら、多少データとの誤差が大きくてもいいや」と、よりシンプルなモデルになろうとします。
- \( \lambda \) が小さいと、「ペナルティは気にしないから、もっとデータにフィットさせて!」と、複雑なモデルになることを許容します。
このペナルティ項 \(R(W)\) の計算方法によって、代表的な2つの正則化手法が生まれます。
L2正則化 (Weight Decay): 「角を丸める」穏健派
L2正則化は、最も広く使われている手法の一つです。ペナルティとして、すべての重みの二乗和を用います。
\[ R_{L2}(W) = \sum_{i} w_i^2 = w_1^2 + w_2^2 + w_3^2 + \dots \]
二乗しているので、大きな値の重みには特に厳しいペナルティがかかります。例えば、重みが2から3に増えるときのペナルティの増加分( \(3^2 – 2^2 = 5\) )は、重みが0から1に増えるとき( \(1^2 – 0^2 = 1\) )よりもずっと大きいですよね。この性質により、L2正則化は特定の重みだけが突出するのを嫌い、全体の重みをまんべんなく小さく、滑らかに保とうとします。モデルの挙動が「角が取れて丸くなる」ようなイメージから、入力の小さな変動に強い、安定したモデルになりやすいです。
PyTorchでは、このL2正則化が Weight Decay(重み減衰) という名前でオプティマイザの機能として実装されています。これは、L2正則化を導入すると、勾配更新の計算式に「現在の重みを少しだけ減衰させる(0に近づける)」項が現れることに由来します。
- 医療での意味合い: 特定のバイオマーカーの値だけに強く依存するのではなく、複数の検査値をバランス良く考慮して診断するような、より安定したモデルを促す効果が期待できます。
- 実装: 非常に簡単で、
AdamやSGDなどのオプティマイザを定義する際に、weight_decay引数に\(\lambda\)の値を設定するだけです。
L1正則化 (Lasso): 「不要なものを削ぎ落とす」改革派
一方、L1正則化はペナルティとしてすべての重みの絶対値の和を用います。
\[ R_{L1}(W) = \sum_{i} |w_i| = |w_1| + |w_2| + |w_3| + \dots \]
L2と似ていますが、こちらは非常に面白い性質を持っています。それは、重要でないと判断した特徴量に対応する重みを、完全に0にしてしまう傾向があることです。これは「スパース性(疎であること)」と呼ばれ、L1正則化が一種の自動的な特徴選択として機能することを意味します。
- 医療での意味合い: 何千もの遺伝子情報の中から、ある疾患に本当に強く関連する数十の遺伝子を自動的に見つけ出す、といった探索的な研究で非常にパワフルなツールになり得ます。
- 実装: PyTorchで直接実装するには少し工夫が必要ですが、損失関数に手動でペナルティ項を加えることで実現できます。
| 特徴 | L2正則化 (Weight Decay) | L1正則化 (Lasso) |
|---|---|---|
| ペナルティ | 重みの二乗和 \( \sum w_i^2 \) | 重みの絶対値和 \( \sum |w_i| \) |
| 効果 | 重みを全体的に小さく、滑らかにする | 不要な重みを完全にゼロにする(スパース化) |
| イメージ | 角を丸める穏健派 | 不要なものを削ぎ落とす改革派 |
| 主な用途 | 汎用的な過学習抑制 | 特徴選択、モデルの解釈性向上 |
4.2. ニューロンを強制的に休ませる:ドロップアウト (Dropout)
次にご紹介するドロップアウトは、近年の深層学習で絶大な効果を発揮している、非常に独創的な正則化手法です(6)。
そのアイデアは、「学習のたびに、ニューラルネットワークの一部のニューロンをランダムに無視する(お休みさせる)」という、ちょっと過激なものです。
上の図のように、訓練の各ステップで、まるでくじ引きのようにニューロンを選んで一時的に無効化(出力を0に)します。次のステップでは、また別のニューロンがランダムに選ばれて休みます。
この「強制的なお休み」によって、ネットワークは特定のニューロンの存在に過度に依存できなくなります。例えば、あるニューロンが「この特徴を検出するのは俺の仕事だ!」と専門家気取りになっていても、いつ自分が休まされるか分からないため、他のニューロンも同じような特徴を検出できるように、ネットワーク全体で冗長性のある、より協力的な学習が進むのです。
このプロセスは、まるで毎回違うメンバーで構成される小さな委員会(サブネットワーク)で、多数決(アンサンブル学習)をとっているようなものだと考えると、分かりやすいかもしれません。様々な視点から物事を考えることで、より頑健で汎化性能の高い結論に至る、というわけですね。
私が最初にこのアイデアに触れたときは、「そんな乱暴なことをして、まともに学習できるのだろうか?」と半信半疑でしたが、その効果は絶大で、今や多くのモデルで標準的に使われています。
- 実装:
nn.Dropout(p=0.5)という層を、モデル定義の中に挟み込むだけ。pはニューロンをドロップアウトする(休ませる)確率で、0.2〜0.5あたりがよく使われます。 - 重要な注意点: ドロップアウトは訓練時にのみ有効にすべきです。予測(推論)をするときに毎回結果が変わってしまっては困りますよね。本番では、全員参加のフルメンバーで安定した予測をしなければなりません。PyTorchでは、
model.train()とmodel.eval()を切り替えるだけで、このオン/オフが自動的に管理されます。これは本当に便利な機能ですが、切り替えを忘れるとバグの原因になるので、くれぐれもご注意ください。
L2正則化とドロップアウトの実装例
それでは、これまでに学んだL2正則化(Weight Decay)とドロップアウトを、実際の分類モデルに組み込んでみましょう。
import torch
import torch.nn as nn
import numpy as np
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset, DataLoader
import japanize_matplotlib
# サンプルデータは先ほどと同じものを再利用します
X = np.random.rand(1000, 20).astype(np.float32)
y = np.random.randint(0, 2, 1000).astype(np.int64)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
train_dataset = TensorDataset(torch.from_numpy(X_train), torch.from_numpy(y_train))
val_dataset = TensorDataset(torch.from_numpy(X_val), torch.from_numpy(y_val))
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)
# L2正則化とドロップアウトを組み込んだモデルを定義
# p=0.5 は、50%の確率でニューロンをドロップアウト(無効化)することを意味します
model_regularized = nn.Sequential(
nn.Linear(20, 128), # 入力層 (特徴量20個) -> 隠れ層1 (128ノード)
nn.ReLU(), # 活性化関数
nn.Dropout(p=0.5), # ドロップアウト層を追加。活性化関数の後に置くのが一般的です
nn.Linear(128, 64), # 隠れ層1 -> 隠れ層2 (64ノード)
nn.ReLU(),
nn.Dropout(p=0.5), # こちらにもドロップアウト層を追加
nn.Linear(64, 2) # 隠れ層2 -> 出力層 (2クラス)
)
# 損失関数
criterion = nn.CrossEntropyLoss()
# オプティマイザに L2正則化 (weight_decay) を設定します
# weight_decay=1e-4 は、正則化の強さλを指定するハイパーパラメータです
optimizer_regularized = torch.optim.Adam(
model_regularized.parameters(),
lr=0.001,
weight_decay=1e-4
)
# 訓練ループ(簡略版)
print("正則化を適用したモデルの訓練開始...")
n_epochs = 20 # エポック数を短めに設定
for epoch in range(1, n_epochs + 1):
# ★★★ 訓練モードに設定 ★★★
# これにより、Dropout層が有効になります
model_regularized.train()
for data, target in train_loader:
optimizer_regularized.zero_grad()
output = model_regularized(data)
loss = criterion(output, target)
loss.backward()
optimizer_regularized.step()
# ★★★ 評価モードに設定 ★★★
# これにより、Dropout層が無効になり、全ニューロンが使われます
model_regularized.eval()
val_loss = 0.0
with torch.no_grad(): # 勾配計算は不要
for data, target in val_loader:
output = model_regularized(data)
loss = criterion(output, target)
val_loss += loss.item() * data.size(0)
print(f'エポック: {epoch}, 検証損失: {val_loss / len(val_dataset):.4f}')
print("訓練完了。")
# 注意:モデルを評価・推論に使う際は、必ず model.eval() を呼び出す必要があります。
# これを忘れると、推論時にもドロップアウトが作動してしまい、結果が不安定になります。
正則化を適用したモデルの訓練開始...
エポック: 1, 検証損失: 0.6919
エポック: 2, 検証損失: 0.6919
エポック: 3, 検証損失: 0.6938
エポック: 4, 検証損失: 0.6936
エポック: 5, 検証損失: 0.6961
エポック: 6, 検証損失: 0.6945
エポック: 7, 検証損失: 0.6989
エポック: 8, 検証損失: 0.6971
エポック: 9, 検証損失: 0.7001
エポック: 10, 検証損失: 0.7021
エポック: 11, 検証損失: 0.7036
エポック: 12, 検証損失: 0.7079
エポック: 13, 検証損失: 0.7034
エポック: 14, 検証損失: 0.7135
エポック: 15, 検証損失: 0.7070
エポック: 16, 検証損失: 0.7136
エポック: 17, 検証損失: 0.7172
エポック: 18, 検証損失: 0.7120
エポック: 19, 検証損失: 0.7160
エポック: 20, 検証損失: 0.7069
訓練完了。このコードを実行すると、訓練ループが回ります。正則化を適用したモデルは、適用しないモデルに比べて訓練損失の下がり方が少し緩やかになることがあります。これは、モデルが過剰に訓練データにフィットするのを「規律」によって防いでいる良い兆候です。その分、訓練データと検証データの損失の差が小さくなり、より安定した汎化性能を持つモデルが得られる傾向にあります。
まとめと次のステップ
今回は、AIモデルの性能と信頼性を左右する「過学習」と「未学習」という重要な課題と、それらに対処するための3つの強力なテクニックを学びました。
- アーリーストッピング:検証データに基づき、最適なタイミングで学習を打ち切ることで過学習を防ぐ。
- データ拡張:手持ちのデータを人工的に増幅し、モデルの汎化能力を根本から鍛える。
- 正則化(L2/Dropout):モデルの複雑さにペナルティを与え、特定のデータパターンへの依存を減らし、より頑健なモデルを構築する。
これらの手法は、単独で用いるだけでなく、組み合わせて使用することで、さらに大きな効果を発揮します。実際の医療AI開発では、これらのテクニックを駆使してモデルの性能を注意深くチューニングしていくことが日常的に行われます。
さて、最高の性能を発揮するように丹念に訓練したモデルが手に入りました。しかし、このままではPythonスクリプトの中でしか生きられません。次回の第17回「モデルの保存・読み込み・推論の実践」では、この訓練済みモデルをファイルとして保存し、いつでも呼び出して新しいデータに対する予測(推論)を行う方法を学びます。いよいよ、AIを実際のアプリケーションに組み込むための第一歩です。ご期待ください。
参考文献
- Hawkins DM. The problem of overfitting. Journal of Chemical Information and Computer Sciences. 2004;44(1):1-12.
- Goodfellow I, Bengio Y, Courville A. Deep Learning. MIT Press; 2016. Chapter 5, Machine Learning Basics.
- Prechelt L. Early stopping—but when?. In: Orr GB, Müller KR, editors. Neural Networks: Tricks of the Trade. Springer; 1998. p. 55-69.
- Shorten C, Khoshgoftaar TM. A survey on image data augmentation for deep learning. Journal of Big Data. 2019;6(1):60.
- Krogh A, Hertz JA. A simple weight decay can improve generalization. In: Moody JE, Hanson SJ, Lippmann RP, editors. Advances in Neural Information Processing Systems 4. Morgan-Kaufmann; 1992. p. 950-957.
- Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research. 2014;15(1):1929-1958.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




