

TL; DR (要約)
AIの学習もマラソンと同じで「ペース配分」が重要。ずっと同じ速度では最高の性能は出ません。
学習率を賢く調整する学習率スケジューリングの要点です。
① ウォームアップ (助走)
学習のスタート
学習初期はごく低い学習率から始め、徐々に加速。AIが安定したスタートを切るための「準備運動」です。
② コサインアニーリング (軟着陸)
学習のゴール
学習終盤はコサインカーブに沿って滑らかに減速。最適解を飛び越えず、繊細に着地する「軟着陸」技術です。
③ 組み合わせ (王道戦略)
全体最適化
この2つを組み合わせ、「序盤は助走、終盤は軟着陸」させるのが現代の王道。学習を安定させ、性能を最大化します。
この章の学習目標と前提知識
はじめに:AIの学習にも「ペース配分」が必要なワケ
皆さん、こんにちは!いよいよ「拡張編」も本格的な内容に入ってきましたね。前回の講義では、ResNetとスキップ接続という、いわば深層学習の世界の「高速道路」を手に入れ、非常に「深い」ニューラルネットワークを安定して構築する技術を学びました。私たちのモデルは、より複雑なパターンを捉えるための、大きなポテンシャルを秘めています。
しかし、どんなに優れた設計の「スーパーカー(深いモデル)」でも、運転技術(学習プロセス)が未熟では、その性能を100%引き出すことはできません。最高の性能を引き出すためには、学習プロセスそのものを巧みにコントロールする「熟練ドライバー」のような役割が、どうしても必要になってくるのです。
その運転技術の中でも、最も重要と言っても過言ではないのが、学習率(learning rate)のコントロールです。
これまで、私たちは学習率(lr)を、例えば 0.001 のような固定値として設定してきました。これはシンプルで分かりやすいですが、常に最適なやり方とは限りません。ここで、マラソンを思い出してみてください。42.195kmを、スタートからゴールまで全く同じペースの全力疾走で走り抜けられる選手はいませんよね?序盤は体力を温存し、中盤でペースを上げ、そして最後の勝負どころでスパートをかける…というように、状況に応じた「ペース配分」が、良い記録を出すための鍵となります。
AIの学習も、これと全く同じです。学習のプロセスは、「損失関数」という広大な地形(損失ランドスケープ)の中で、最も低い谷底(最適解)を探す旅に例えられます。
損失ランドスケープと学習率のイメージ
- 学習の序盤(広い高原地帯): モデルの重みはランダムな状態から始まるため、私たちはこの広大な地形の、どこか見晴らしの良い高原のような場所にいます。ここから谷底までは、まだかなりの距離があります。この段階では、大きな学習率(大きな歩幅)で、大胆に、そして素早く谷底の方向へと下っていくのが効率的です。
- 学習の終盤(狭く深い谷底): 学習が進み、谷底(最適解)に近づいてくると、状況は一変します。ここで今までと同じ大きな歩幅で進もうとすると、谷底を飛び越えて反対側の斜面を行ったり来たりするだけで、なかなか一番低い地点に落ち着けなくなってしまいます(これをオーバーシュートと言います)。この段階では、小さな学習率(小さな歩幅)で、一歩一歩慎重に、そして繊細に、谷底のど真ん中(真の最適解)へと足を進めていく必要があるのです。
このように、学習のフェーズによって最適な学習率が異なる、というのがポイントです。
この、学習の進行状況に応じて学習の「ペース(学習率)」を動的に変化させていくテクニックの総称が、学習率スケジューリング (Learning Rate Scheduling) なんです。今回は、数あるスケジューリング戦略の中でも、特に現代的な深層学習モデルの訓練で効果的とされ、広く使われている2つの戦略、ウォームアップ (Warmup) と コサインアニーリング (Cosine Annealing) について、その考え方と使い方を学んでいきましょう。
1. ウォームアップ (Warmup) – 助走をつけて安定したスタートを
まずご紹介するのは、学習のスタートダッシュを成功させるためのウォームアップ (Warmup) です。その名の通り、本格的な学習に入る前の「準備運動」だと考えてください。
私たちは、運動を始める前に、軽いジョギングやストレッチで筋肉を温め、体を慣らしてから、徐々にパフォーマンスを上げていきますよね。いきなり100mを全力疾走したり、最も重いウェイトを持ち上げたりすると、筋肉を痛めてしまったり、本来の力を発揮できなかったりするからです。
AIモデルの学習も、実はこれと全く同じなんです。学習開始時にいきなり大きな学習率でスタートするのではなく、まずは非常に小さな学習率から始め、最初の数エポック(または数ステップ)をかけて、私たちが本来設定したい目標の学習率まで線形に(徐々に)上げていく。これがウォームアップの基本的な動きです。
ウォームアップの学習率の動き
なぜこんな「助走」が必要なのでしょうか?
学習開始直後のモデルは、重みがランダムな値で初期化されたばかりで、いわば「損失ランドスケープ」の、どこにいるかも分からない、非常に不安定な状態です。この状態で、いきなり大きな歩幅(高い学習率)で一歩を踏み出すと、谷底とは全く見当違いの方向に大きくジャンプしてしまい、学習が「爆発」して(損失が無限大に飛んでいって)しまう、という最悪の事態を招きかねません。
ウォームアップは、この最初の数歩を、ごくごく小さな歩幅で慎重に進むことで、モデルがまず「自分が今どこにいて、どちらに進むべきか」という大まかな方向性を見つけるのを助けます。そして、進むべき方向が定まり、学習が安定してきたところで、徐々に歩幅を広げていく。この丁寧なスタートが、その後の学習プロセス全体を安定させ、結果的により速く、より良い解にたどり着くための鍵となるのです。特に、私たちが今後扱っていくTransformerのような巨大で複雑なモデルを学習させる際には、もはや必須のテクニックの一つと言えるかもしれません(1)。
2. コサインアニーリング (Cosine Annealing) – 優雅に減速し、最適解に着地
ウォームアップで安定したスタートダッシュを決めた後、学習はいよいよ中盤から終盤へと向かいます。マラソンで言えば、競技場のトラックが見えてきて、ゴールに向けて最後の調整に入る段階ですね。ここでは、学習率を徐々に下げて、最適解の谷底へと繊細に着地させていくフェーズに入ります。
その「減速」の方法にも様々な戦略がありますが、近年非常に人気があり、多くの場面で素晴らしい結果をもたらしてくれるのが、今回ご紹介するコサインアニーリング (Cosine Annealing) なんです(2)。
コサインアニーリングとは?
これは、その名の通り、学習率を三角関数のコサインカーブに沿って、滑らかに減少させていく手法です。指定した学習サイクル(エポック数)の中で、学習率が最大値から最小値(通常は0に近い値)まで、コサイン関数の半周期を描くように、優雅に減速していきます。
この動きを理解するための最高のイメージは、「宇宙船の月面着陸」です。宇宙船は、月面に近づくにつれて、いきなりブレーキをかけるのではなく、逆噴射を滑らかに制御し、徐々に速度を落としていきます。そして、地表(最適解)に激突(オーバーシュート)することなく、ふわりと優雅に着陸しますよね。コサイン関数は、この非常に滑らかで、初めはゆっくり、中間は速めに、そして最後はまた非常にゆっくりと減速していく、理想的なカーブを描くのに最適な関数なのです。
なぜコサインカーブが良いのか?
では、なぜ、ただ直線的に下げたり(線形減衰)、階段状に下げたり(ステップ減衰)するよりも、コサインカーブが良いのでしょうか?他の手法と比べてみましょう。
様々な学習率減衰スケジュールの比較
階段状に学習率を落とすステップ減衰では、学習率が「ガクン」と下がった直後に、まだ最適解の谷底の探索が終わっていないのに、次の大きな下落までの間、比較的高めの学習率で探索を続けてしまう可能性があります。一方、コサインカーブは、学習の終盤になればなるほど、より緩やかに、そして滑らかに学習率をゼロに近づけていきます。この「最後の粘り」が、最適解の谷底の最も良い地点を、じっくりと見つけ出すための時間を与えてくれる、と考えられているのです。
数式で表現すると、ある時刻 \(t\) における学習率 \(\eta_t\) は、以下のように計算されます。
\[ \eta_t = \eta_{\min} + \frac{1}{2}(\eta_{\max} – \eta_{\min}) \left( 1 + \cos\left(\frac{T_{\text{cur}}}{T_{\max}}\pi\right) \right) \]
- \(\eta_t\): 時刻 \(t\) での学習率
- \(\eta_{\min}\), \(\eta_{\max}\): 学習率の最小値と最大値
- \(T_{\text{cur}}\): 現在の学習ステップ数(またはエポック数)
- \(T_{\max}\): 学習率が1サイクルするまでの総ステップ数(または総エポック数)
数式を見ると少し難しく感じるかもしれませんが、要は \(\cos\) の中身が0から\(\pi\)(180度)まで変化するにつれて、学習率が \(\eta_{\max}\) から \(\eta_{\min}\) まで滑らかに減少していく、ということを表しているだけです。美しい仕組みですよね。
(発展)ウォームリスタート (Warm Restarts)
さらに、このコサインアニーリングを何度も繰り返す「ウォームリスタート付き確率的勾配降下法(SGDR)」という発展的な手法もあります(2)。これは、学習率が最小値に達したら、再び大きな学習率にリセット(ウォームリスタート)し、またコサインカーブで下げていく、というサイクルを繰り返すものです。
もし学習が良くない谷底(局所的最適解)にハマってしまっても、学習率を強制的にリセットすることで、そこから脱出し、より良い解を探しに行くチャンスを与えてくれる、という利点があります。
3. 実装:Warmup付きコサインアニーリングを可視化する 〜理論をグラフで見て、深く理解する〜
さて、ここまでウォームアップとコサインアニーリングという、二つの強力な戦略を別々に見てきました。理論はなんとなく分かったけれど、実際に組み合わせるとどんな学習率の推移になるのか、目で見てみたくなりますよね。
ここでは、PyTorchとMatplotlibを使って、この「ウォームアップ付きコサインアニーリング」の学習率スケジュールをシミュレーションし、その美しい軌跡をグラフとして可視化してみましょう。理論が形になる瞬間を、ぜひ体験してください。
【実行前の準備】
以下のコードで日本語のグラフを表示させるには、あらかじめターミナルやコマンドプロンプトで pip install japanize-matplotlib を実行してライブラリをインストールしてください。
Pythonコード例:学習率スケジュールの可視化
graph TD
A["開始"] --> B["1. 学習率スケジュールを定義
(ウォームアップ期間やコサインカーブ等のルールを設定)"];
B --> C["2. 学習率の推移をシミュレーション
(全エポックをループし、各時点の学習率を計算・記録)"];
C --> D["3. 結果をグラフで可視化
(計算した学習率の推移をプロットして表示)"];
D --> E["終了"];
# --- 1. 必要なライブラリをインポート ---
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示のため
import numpy as np
# --- 2. ダミーのモデルとオプティマイザを準備 ---
# 学習率スケジューラは、どのオプティマイザの学習率を調整するのかを知る必要があるため、
# まず土台となるオプティマイザを準備します。モデル自体はダミーで構いません。
model = torch.nn.Sequential(torch.nn.Linear(10, 1))
# 最適化手法としてAdamを、ウォームアップ「後」に到達したい最大学習率(lr=0.001)で設定します。
optimizer = optim.Adam(model.parameters(), lr=0.001)
# --- 3. 学習スケジュールのパラメータを設定 ---
# 全体の学習サイクル(エポック)数
total_epochs = 100
# ウォームアップを行うエポック数
warmup_epochs = 10
# ウォームアップ後の最大学習率(オプティマイザに設定した値と同じ)
max_lr = 0.001
# ウォームアップ開始時の学習率(非常に小さい値から始める)
initial_lr = 1e-6
# --- 4. コサインアニーリング用のスケジューラを作成 ---
# これは、ウォームアップ「後」の学習率の推移を計算するためのスケジューラです。
# T_max: 学習率が最大値から最小値になるまでのエポック数を指定します。
# ウォームアップ期間を除くので total_epochs - warmup_epochs となります。
# eta_min: 学習率の最小値。ここでは0に設定します。
cosine_scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=total_epochs - warmup_epochs,
eta_min=0
)
# --- 5. 学習率の推移をシミュレーション ---
# 各エポックでの学習率を記録するための空のリストを用意します。
lr_history = []
# 全エポックにわたってループを実行し、学習率の変化をシミュレートします。
for epoch in range(total_epochs):
# ウォームアップ期間中の処理 (最初の10エポック)
if epoch < warmup_epochs:
# 現在のエポック数に応じて、学習率を線形に(直線的に)増加させます。
# (epoch / warmup_epochs) は、ウォームアップの進捗度(0から1)を示します。
lr = initial_lr + (max_lr - initial_lr) * (epoch / warmup_epochs)
# オプティマイザが持つ学習率の値を、計算した値で直接上書きします。
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# ウォームアップ期間終了後の処理
else:
# コサインアニーリングのスケジューラを使って、学習率を1ステップ進めます。
# これにより、コサインカーブに従って学習率が自動的に更新されます。
cosine_scheduler.step()
# 現在の学習率を履歴に記録します。
# optimizer.param_groups[0]['lr'] で現在の学習率を取得できます。
lr_history.append(optimizer.param_groups[0]['lr'])
# --- 6. 学習率の推移をグラフにプロット ---
print("--- 学習率スケジュールの推移をプロットします ---")
# グラフのキャンバスを用意します。
plt.figure(figsize=(10, 6))
# 横軸をエポック数、縦軸を学習率として、履歴をプロットします。
plt.plot(range(total_epochs), lr_history)
# グラフにタイトルやラベルを追加して、分かりやすくします。
plt.title('Warmup付きコサインアニーリングの学習率スケジュール', fontsize=15)
plt.xlabel('エポック数 (Epochs)')
plt.ylabel('学習率 (Learning Rate)')
# ウォームアップ期間を分かりやすく示すために、縦の破線を描画します。
plt.axvline(x=warmup_epochs, color='gray', linestyle='--', label=f'Warmup終了 ({warmup_epochs}エポック)')
plt.grid(True, linestyle='--', alpha=0.6) # グリッド線
plt.legend() # 凡例を表示
# これまでに設定した内容で、グラフを画面に表示します。
plt.show()
# === ここから下が上記のprint文による実際の出力 ===
# --- 学習率スケジュールの推移をプロットします ---
# (学習率の推移を示すグラフウィンドウが表示される)
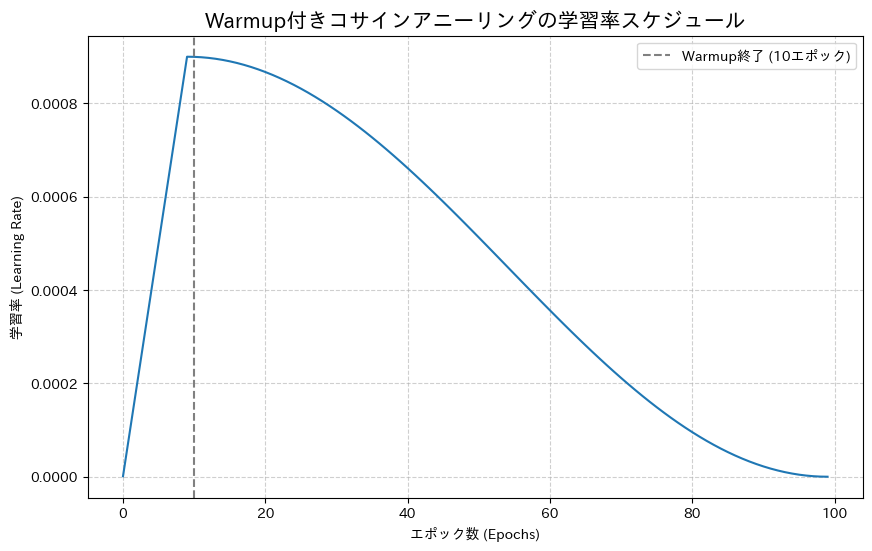
グラフの解釈と考察
このコードを実行すると、一枚の美しいグラフが表示されたはずです。まさに、私たちが議論してきた学習の「ペース配分」そのものですよね。
- ウォームアップ期 (最初の10エポック): グラフの左端を見ると、学習率がほぼゼロから始まり、目標の最大学習率
0.001に向かって、直線的に上昇しているのが分かります。これが「助走」の期間です。モデルはここで安定したスタートを切ります。 - コサインアニーリング期 (11エポック以降): ウォームアップが終わると、学習率はコサインカーブを描きながら、滑らかに減衰していきます。学習の最終盤(100エポック目)に近づくにつれて、非常に緩やかに、限りなくゼロに近づいていく様子が見て取れます。この優雅な「軟着陸」が、モデルを最適解の谷底にそっと導いてくれるのです。
このように、学習率スケジューリングを可視化してみることは、自分のモデルがどのようなペースで学習を進めているのかを直感的に理解し、デバッグする上で非常に役立ちます。ぜひ、ご自身の研究でも試してみてください。
実際の訓練ループへの組み込み方
先ほどのコードでは、スケジュールの「形」を見るために、学習率の値をシミュレーションしました。では、これを実際の訓練ループに組み込むには、どうすれば良いのでしょうか?実は、やることは非常にシンプルです。
基本的な流れは、「1エポック分の訓練がすべて終わった後、オプティマイザの学習率をスケジューラで更新する」というものです。具体的には、訓練のforループの最後に scheduler.step() を呼び出すだけです(ウォームアップ部分は手動で実装します)。
以下のコードは、ダミーのデータとモデルを使って、この学習率スケジューラを組み込んだ訓練ループの全体像を示しています。先ほどの可視化コードのロジックが、実際の学習プロセスの中でどう活かされるのか、その繋がりを見ていきましょう。
Pythonコード例:訓練ループに学習率スケジューラを組み込む
# --- 1. 必要なライブラリをインポート ---
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示のため
# --- 2. ダミーのデータとDataLoaderを準備 ---
# (バッチサイズ, 入力特徴数) のダミー訓練データを作成します。
X_train = torch.randn(128, 10)
# ダミーの正解ラベルを作成します。
y_train = torch.randint(0, 2, (128,))
# DatasetとDataLoaderを作成します。
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=32)
# --- 3. ダミーのモデル、損失関数、オプティマイザを準備 ---
# 入力10、出力2(クラス数)の単純なモデルです。
model = nn.Sequential(nn.Linear(10, 2))
# 損失関数
criterion = nn.CrossEntropyLoss()
# 最適化手法としてAdamを使います。学習率(lr)はウォームアップ後の最大値を設定します。
optimizer = optim.Adam(model.parameters(), lr=0.001)
# --- 4. 学習スケジュールのパラメータとスケジューラを設定 ---
total_epochs = 100
warmup_epochs = 10
max_lr = 0.001
initial_lr = 1e-6
# コサインアニーリング用のスケジューラを作成します。
cosine_scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=total_epochs - warmup_epochs,
eta_min=0
)
# --- 5. 訓練ループとスケジューラの適用 ---
print("--- Warmup付きCosineAnnealingスケジューラを適用した訓練ループ開始 ---")
# 実際に訓練で適用された学習率の推移を記録します。
actual_lr_history = []
# 全エポックにわたってループを実行します。
for epoch in range(total_epochs):
# モデルを訓練モードにします。
model.train()
# ミニバッチループ (この中での処理は簡略化しています)
for inputs, labels in train_loader:
# 実際の訓練では、ここで勾配リセット、順伝播、損失計算、
# 逆伝播、パラメータ更新の一連の処理を行います。
# optimizer.zero_grad()
# outputs = model(inputs)
# loss = criterion(outputs, labels)
# loss.backward()
# optimizer.step()
pass # 今回はスケジューラの動きを見るため、訓練処理自体は省略します。
# --- ここからがスケジューラの適用部分 ---
# 1エポックの訓練がすべて終わった後、学習率を更新します。
# ウォームアップ期間中の処理
if epoch < warmup_epochs:
# 現在のエポック数に応じて、学習率を線形に増加させます。
lr = initial_lr + (max_lr - initial_lr) * (epoch / warmup_epochs)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# ウォームアップ期間終了後の処理
else:
# 定義したコサインアニーリングのスケジューラの状態を1ステップ進めます。
cosine_scheduler.step()
# 現在の学習率を履歴に記録します。
current_lr = optimizer.param_groups[0]['lr']
actual_lr_history.append(current_lr)
# 10エポックごとに、現在のエポック数と学習率を表示します。
if (epoch + 1) % 10 == 0:
print(f"エポック [{epoch+1}/{total_epochs}], 現在の学習率: {current_lr:.6f}")
print("--- 訓練ループ完了 ---")
# --- 6. 実際に適用された学習率の推移をプロット ---
# 訓練ループ内で記録した学習率の履歴を可視化し、
# 意図したスケジュール通りに動作したかを確認します。
plt.figure(figsize=(10, 6))
plt.plot(actual_lr_history)
plt.title('訓練ループで実際に適用された学習率の推移', fontsize=15)
plt.xlabel('エポック数 (Epochs)')
plt.ylabel('学習率 (Learning Rate)')
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()
--- Warmup付きCosineAnnealingスケジューラを適用した訓練ループ開始 ---
エポック [10/100], 現在の学習率: 0.000900
エポック [20/100], 現在の学習率: 0.000873
/usr/local/lib/python3.11/dist-packages/torch/optim/lr_scheduler.py:227: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn(
エポック [30/100], 現在の学習率: 0.000795
エポック [40/100], 現在の学習率: 0.000675
エポック [50/100], 現在の学習率: 0.000528
エポック [60/100], 現在の学習率: 0.000372
エポック [70/100], 現在の学習率: 0.000225
エポック [80/100], 現在の学習率: 0.000105
エポック [90/100], 現在の学習率: 0.000027
エポック [100/100], 現在の学習率: 0.000000
--- 訓練ループ完了 ---
このように、オプティマイザを定義した後にスケジューラを紐付け、エポックごとのループの最後にスケジューラの状態を更新(scheduler.step())するのが基本的な使い方です(ウォームアップ部分は目的に応じて手動で実装することが多いです)。これにより、学習は私たちが設計した「理想的なペース配分」に沿って、自動的に進んでいきます。とても簡単ですよね。
4. まとめと次のステップへ
今回は、学習のペース配分を自動で最適化する学習率スケジューリング、特に現代的な手法であるウォームアップとコサインアニーリングについて学びました。
- 学習率スケジューリング: 学習を安定的かつ効率的に進めるために、学習率を動的に変化させるテクニック。
- ウォームアップ: 学習初期の不安定さを解消するための「準備運動」。
- コサインアニーリング: 学習終盤で最適解に滑らかに収束するための「軟着陸」戦略。
固定の学習率で試行錯誤するよりも、こうした洗練されたスケジューリング手法を用いることで、多くの場合、より速く、より良い性能のモデルを得ることができます。
さて、ResNetで「深さ」を、そして学習率スケジューリングで「訓練の巧みさ」を手に入れた私たちは、いよいよ現代のAIを語る上で欠かせない、最も重要なアーキテクチャに挑む準備が整いました。
次回の第22回では、自然言語処理の世界に革命を起こし、今や画像認識や医療AIの分野でも主流となりつつある、Transformerモデルを徹底的に解剖していきます。
参考文献
- He K, Girshick R, Dollár P. Rethinking imagenet pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. 2019. p. 4918-4927. (Warmupの有効性について言及)
- Loshchilov I, Hutter F. SGDR: Stochastic gradient descent with warm restarts. In: International Conference on Learning Representations. 2017.
- PyTorch Documentation.
torch.optim.lr_scheduler. [Internet]. [cited 2025 Jun 12]. Available from: https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




