

Transformerが文脈を巧みに読み解く力の源泉は、情報の関連性に応じて「注目」するAttention機構にあります。Query(問いかけ)、Key(索引)、Value(情報)という三役者が、どの情報が重要かを動的に判断し、リッチな文脈表現を生み出します。
Query(Q): 情報を探す「問いかけ」。
Key(K): 情報の特性を示す「索引」。
Value(V): 実際の「情報の中身」。
QとKの関連度でVを重み付けし、文脈を捉えます。
①QとKの内積で関連度スコアを算出。②スケーリングで安定化。③Softmax関数で「注目度(確率)」に変換。④その注目度でVを加重和し、文脈を反映した出力を得ます。
Multi-Head: 複数の視点(ヘッド)で同時に注目し、多角的な情報を抽出します。
Causal Mask: 文章生成時に未来の情報を隠し、モデルの「カンニング」を防ぐ重要な仕組みです。
さて、この連載「Transformerモデルを徹底的に理解する!」も、いよいよ深部へと分け入ってきました。皆さんと一緒に、現代AIの代表格であるTransformerの、その興味深い仕組みと応用の可能性を探る旅を続けています。
前回(22.2 Transformerの全体構造と中身)では、Transformerがいったいどんな部品から成り立っているのか、その全体像、いわば設計図を眺めましたね。Self-Attention、Multi-Head Attention、FFN(フィードフォワードネットワーク)、残差接続、LayerNorm(層正規化)、そしてPositional Encoding(位置エンコーディング)といった、ちょっと難しそうな名前のコンポーネントたちが、それぞれパズルのピースのように組み合わさって、一つの大きな知能を形作っている様子を掴んでいただけたのではないでしょうか。
そして今回、私たちはその中でも特にTransformerの「心臓部」とも言えるAttention機構、とりわけSelf-Attentionという仕組みにグッと焦点を当てていきます。「Transformerはどうしてあんなに巧みに文章のニュアンスを読み取ったり、自然な受け答えができたりするんだろう?」――そんな疑問の核心に迫るのが、今回のテーマです。AIがまるで人間のように、文脈の中から「いま、ここが重要だ!」と見抜く力の源泉を、一緒に探求していきましょう。
具体的にどんなお話をするかというと、まずはAttentionの基本となる3つのキープレイヤー、Query (Q)、Key (K)、Value (V) というベクトルたちが、それぞれどんな役割を担っているのかをご紹介します。これらのベクトルが、どのようにしてお互いの関連性を見つけ出し(これを「スコア計算」と呼びます)、重要な情報に「注目」する重みを生み出すのか、その舞台裏を丁寧に見ていきます。さらに、AIが実際に「何を見ているのか?」、その注目度を可視化するテクニックや、文章を生成する際に未来の情報をカンニングしないようにするための巧妙な仕掛けであるCausal Mask(意味的マスク、あるいはコーザルマスク)についても、分かりやすく解説するつもりです。
このセクションを読み終える頃には、Transformerがどのようにして複雑な情報の中から大切なポイントを抽出し、文脈を理解しているのか、その魔法のようなメカニズムの一端を、きっと肌で感じていただけると思います。そして、この理解こそが、皆さんがこの強力なAI技術をご自身の研究や日々の臨床現場で「なるほど、こう使えそうだ!」と具体的な応用を思い描き、実際に役立てていくための、とても大切な一歩になるはずだと、私は信じています。さあ、準備はよろしいでしょうか?一緒にAttentionの世界へ踏み出しましょう。
1. Attention機構とは? – 「関連性」に注目する仕組み
さて、前回まではTransformerモデル全体の構造を眺めてきましたが、ここからはその中でも特に重要な部品の一つ、「Attention機構」についてじっくり見ていくことにしましょう。このAttention機構、一体どんな働きをするのでしょうか? もし一言で言い表すなら、「入力されたたくさんの情報の中から、今まさに処理しようとしていることにとって、最も関連が深い部分にグッと焦点を合わせる仕組み」と言えるかもしれません。

ちょっと私たちの日常を思い浮かべてみてください。例えば、皆さんが何か調べ物をしていて、たくさんの資料や論文を読んでいるとします。その時、一字一句すべて同じ集中力で読み進める、ということは少ないのではないでしょうか? きっと、探している情報に関連するキーワードや重要な記述を見つけると、自然とそこに意識が集中し、それ以外の部分は少しペースを上げて読み進めたりしますよね。
医療の現場でも似たようなことがあるかもしれません。患者さんが様々な症状や経過を話される中で、その全てが診断に直結するわけではなく、ある特定の言葉、症状が現れたタイミング、その持続時間といった情報が、診断を下す上で非常に重要な手がかりになることがあります。経験豊富な医師ほど、こうした重要なポイントを巧みに拾い上げ、それらを頭の中で関連付けて診断を進めていくものです。Attention機構は、AIにこれと非常によく似た「情報の取捨選択と集中の能力」を与える、まさに画期的なアイデアなんです。
では、なぜこのような「注目」の仕組みが、AIにとってこれほどまでに大切なのでしょうか? その理由を理解するために、少しだけ時計の針を戻して、Attention機構が登場する前に主流だったニューラルネットワークモデル、特にRNN(Recurrent Neural Network:再帰型ニューラルネットワーク)のことを思い出してみましょう。
RNNは、例えば文章を読むときのように、情報を一つずつ順番に処理していくのが得意なモデルでした。これは人間が文章を読むプロセスと似ていて直感的ではあるのですが、一つ、悩ましい特性を抱えていたのです。それは、「系列が長くなればなるほど、初期に入力された重要な情報の影響力が、だんだん薄れていってしまう」という点。これは「長期依存性の問題(Long-term dependency problem)」として知られています。
ちょっと図でイメージしてみましょうか。
上の図で示したように、RNNが情報をまるで伝言ゲームのように順番にバケツリレーしていくと想像してみてください。リレーの距離が長くなればなるほど、最初のメッセージはだんだん曖昧になったり、一部が抜け落ちてしまったりすることがありますよね。これと同じで、非常に長い患者さんのカルテをRNNで処理しようとすると、カルテの冒頭に書かれていたはずの決定的に重要な既往歴の情報が、最後の診断予測の段階ではすっかり「忘れられて」しまっている…なんてことが起こり得たわけです。これは困りますよね。
そこで救世主のように登場したのが、今回主役のAttention機構なんです! Attention機構の本当に素晴らしいところは、入力された情報のどの部分に対しても、まるで手元にある強力なサーチライトで照らし出すかのように、あるいは文書内のどこへでも一瞬でジャンプできるブックマーク機能のように、直接的かつ動的に「注目」できる点にあります。
順番に情報をたどっていく必要がないため、どんなに長い文章(系列)であっても、あるいは重要な情報が文の最初の方にあっても、現在の処理に必要な情報であれば、それを見つけ出してくることができる。これにより、AIは以前よりもずっと長い文脈をしっかりと踏まえた上で、より賢い判断を下せるようになった、というわけなんです。これは大きな進歩だと思いませんか?
このAttention機構の能力が、医療の分野でどのように活かせるか、少し具体的に想像してみましょう。例えば、何ページにもわたる一人の患者さんの電子カルテがあるとします。そこには、日々のバイタルサイン、検査結果の推移、投薬の記録、医師や看護師による詳細な記述など、膨大な情報が時系列に沿って記録されていますよね。Attention機構を搭載したAIならば、その膨大な記録の海の中から、「今回の患者さんの状態を理解する上で最も重要なのは、半年前に行われたあの特定の検査データと、3日前のカルテに書かれたこの自覚症状の記述、そして1年前にあったあのアレルギー反応の記録だ!」といった具合に、まるで経験豊かな専門医が注目するポイントを見つけ出すかのように、関連性の高い情報群にピンポイントで光を当て、私たちに提示してくれるかもしれません。
まさに、AIがベテランの医師の思考プロセスの一部を肩代わりしてくれるかのように、膨大な情報の中から診断や治療方針の決定に必要な「今、注目すべき情報」を的確に選び出し、その判断をサポートしてくれる。そんな未来が、Attention機構によってグッと近づいてきたと言えるでしょう。
2. Attentionの心臓部:Query, Key, Value (QKV) モデル
さて、前のセクションではAttention機構が「入力された情報の中から、関連性の高い部分にグッと焦点を合わせる仕組み」だというお話をしましたね。では、その「焦点合わせ」つまり「注目」というのは、一体AIの中でどのようにして実現されているのでしょうか? そのからくりの核心を握っているのが、今回ご紹介する3つの重要な要素、Query (クエリ)、Key (キー)、Value (バリュー) です。それぞれの頭文字を取って、愛情を込めて「QKVモデル」なんて呼ばれたりもします。
これらQ、K、Vは、入力された文章中の一つ一つの単語(より専門的には「トークン」と呼びます。例えば「私」「は」「昨日」「病院」「へ」「行きました」「。」のように区切られたものですね)から、それぞれ作り出されるベクトル情報です。同じ単語から生まれたにも関わらず、Q、K、Vはそれぞれ異なる「顔」と「役割」を持っていて、三位一体となってAttentionの魔法を生み出します。なんだか、一つの劇団に所属する3人の役者が、それぞれ異なる役を演じ分けるようなイメージに近いかもしれません。
では、それぞれの役者の役割を、もう少し詳しく見ていきましょう。
Query (Q):「何を探しているの?」と問いかける探求者
まずQuery(クエリ)ですが、これは「現在注目している単語が、他のどの単語と関連が深い情報を持っているだろうか?」と積極的に情報を探しに行く「問いかけ」や「検索クエリ」そのものだと考えてみてください。皆さんがインターネットで何か調べ物をするとき、検索窓にキーワードを打ち込みますよね? あのキーワードが、まさにQueryのイメージです。
例えば、文章中の一つの単語が「私は今、この文脈でどういう意味で使われているんだろう?他の単語との関係性を知りたい!」と考えたとき、その単語から生成されたQueryベクトルが、文中の他の単語たちに対して「ねえ、君は私とどんな関係があるの?何か情報ちょうだい!」と積極的に働きかけるわけです。まるで好奇心旺盛な探求者が、周囲に質問を投げかけて情報を集めるような感じですね。

Key (K):「私はこんな情報を持っていますよ」と示す名札
次にKey(キー)です。これは、入力系列中の各単語が持っている「特性」や「属性」を表すベクトルで、「この単語はこんな情報(例えば、意味的なカテゴリー、文法的な役割など)を持っていますよ」と示す、いわば単語の「名札」や「索引キーワード」のようなものです。
Queryが「こんな情報を探しているんだけど!」と問いかけてきたとき、各単語は自分のKeyベクトルを提示して「私、その情報と関連があるかもしれません!」と応答する準備をしています。Queryと、他の単語のKeyがどれだけ似ているか(専門的にはベクトル間の類似度が高いか)を比べることで、「お、この単語のKeyは、今のQueryとピッタリ合う(または、よく似ている)ぞ!」となれば、その単語は「注目すべき候補」として浮上してくるわけです。なんだか、探偵が手がかり(Query)をもとに、容疑者リスト(各単語のKey)を照合していく作業にも似ていますね。
Value (V):「関連があるなら、この情報をどうぞ」と差し出す実体
そして最後にValue(バリュー)です。これは、入力系列中の各単語が実際に持っている「具体的な情報の中身」や「内容そのもの」を表すベクトルです。KeyがQueryとの関連性を示唆する「名札」だとすれば、Valueはその名札の持ち主が実際に提供できる「価値ある情報」と言えるでしょう。

QueryとKeyの照合の結果、「この単語は重要そうだ!」と判断された場合、その単語に紐づけられたValueベクトルが実際に取り出され、重視されます。つまり、Attention機構の最終的な出力(ある単語が周囲の情報を加味して得られる新しい表現)は、このValueベクトルたちを、QueryとKeyの関連度(注目度)に応じて重み付けし、それらを賢くブレンドして作られるんです。関連性が高いと判断された単語のValueほど、その「声」が大きくなるイメージですね。
ここまでのQ、K、Vの役割を、図書館の例えでまとめてみましょうか。
| 要素 | 主な役割 | 図書館での例え | もっと身近な例え |
|---|---|---|---|
| Query (Q) | 情報を探し出すための「問いかけ」 | 司書さんに伝える「こんな本を探しています」というリクエストや、検索システムに入力する「キーワード」 | レストランで店員さんに「おすすめのパスタは何ですか?」と尋ねる時の「質問」 |
| Key (K) | 各情報が持つ「索引」や「属性」 | 本棚に並んだ本の「背表紙のタイトル」や「ジャンル分類ラベル」 | メニューに書かれたパスタの「名前」や「簡単な説明書き(トマトベース、オイル系など)」 |
| Value (V) | 実際に参照・利用される「情報の中身」 | 司書さんが探し出してくれた本の「本文」や、キーワードでヒットした文献の「具体的な内容」 | 店員さんが教えてくれた、あるいはメニューから選んだパスタの「実際の料理そのもの」 |
どうでしょう、少しはQKVトリオの活躍ぶりがイメージできたでしょうか?
Q, K, V ベクトルはどうやって生まれるの? – 重み行列による変換
さて、ここまでQ、K、Vがそれぞれ重要な役割を担っていることを見てきましたが、「そもそも、これらのベクトルはどうやって作られるの?」という疑問が湧いてきますよね。実は、これらは入力された各単語(トークン)が元々持っている数値表現(これを「単語埋め込みベクトル」や「トークンエンベディング」と呼びます。連載22.2で触れた、単語の位置情報を加味したPositional Encodingがここにも関わってきます)をベースにして、それぞれ専用の「変換装置」とも言える数学的な処理を経て生成されます。
この「変換装置」の正体は、学習を通じて最適化される重み行列 (Weight Matrix) と呼ばれるものです。具体的には、Queryを生成するための重み行列 \(W^Q\)、Keyを生成するための重み行列 \(W^K\)、そしてValueを生成するための重み行列 \(W^V\) という、3種類の異なる行列がモデル内に用意されています。
入力系列のある単語 \(i\) の埋め込みベクトル(Positional Encoding込み)を \(x_i\) としましょう。この \(x_i\) から、その単語 \(i\) 専用のクエリベクトル \(q_i\)、キーベクトル \(k_i\)、バリューベクトル \(v_i\) が、それぞれ次のように行列乗算によって計算されます。
\[ q_i = x_i W^Q \]
\[ k_i = x_i W^K \]
\[ v_i = x_i W^V \]
ここで、\(x_i\) は例えば \(d_{model}\) 次元のベクトルだと考えてみてください(\(d_{model}\) はTransformerモデルが扱う情報の基本次元数で、例えば512次元だったりします)。それに対して、重み行列 \(W^Q\) や \(W^K\) は通常、\(d_{model} \times d_k\) という形状をしており、\(W^V\) は \(d_{model} \times d_v\) という形状をしています。ここで \(d_k\) はキーとクエリの次元数(例えば64次元)、\(d_v\) はバリューの次元数(これも例えば64次元が多いですが、\(d_k\) と異なる場合もあります)を表します。
この計算を図でイメージしてみましょう。入力単語のベクトル \(x_i\) が、まるで粘土のように、異なる型(重み行列)にはめ込まれることで、それぞれQ、K、Vという異なる形のベクトルに変身する様子を想像してみてください。
この図が示しているのは、元の単語 \(i\) の情報(\(x_i\))が、それぞれ異なる「専門家チーム」(重み行列 \(W^Q, W^K, W^V\))によって分析・変換され、Query向きの特性、Key向きの特性、Value向きの特性をそれぞれ持った新しいベクトル \(q_i, k_i, v_i\) へと射影(プロジェクト)される、というイメージです。「射影」という言葉が少し難しく聞こえるかもしれませんが、これは元の情報を別の視点や空間で表現し直す、というような意味合いです。例えば、私たちの顔も正面から見るのと横から見るのでは印象が異なりますよね? それと同じように、元の単語の情報を「問い合わせ用」「索引付け用」「内容表現用」という異なる角度から見た特徴ベクトルとして取り出している、と考えても良いかもしれません。
そして何より大切なのは、これらの重み行列 \(W^Q, W^K, W^V\) の中身(つまり、具体的な数値)は、最初から決まっているわけではなく、Transformerモデルが大量の学習データを使って「どうすればこのタスク(例えば翻訳や質問応答)をうまくこなせるか」を学ぶ過程で、徐々に最適化されていく、という点です。つまり、モデル自身がデータの中から「賢いQ、K、Vの作り方」を学習していくんですね。これは本当に興味深いプロセスだと思います。
医療データでのQKVモデルの活躍イメージ
では、このQKVモデルが医療データ、特に電子カルテのようなテキスト情報を扱う際に、どのように機能するのか、具体的な例でさらにイメージを深めてみましょう。
例えば、ある患者さんの電子カルテにこんな一文があったとします:「昨日から38度の発熱と咳があり、呼吸苦も伴う」
今、AI(Transformerモデル)がこの文中の「呼吸苦」という単語(トークン)に注目し、その意味を深く理解しようとしているとしましょう。この時、何が起こるかというと…
- まず、「呼吸苦」という単語から、専用のQueryベクトル \(q_{呼吸苦}\) が生成されます。この \(q_{呼吸苦}\) は、「この“呼吸苦”という症状は、この文脈において他のどんな情報と関連が強いんだろう?」という問いかけを内に秘めています。
- それと同時に、文中のすべての単語(「昨日から」「38度」「発熱」「と」「咳」「あり」「呼吸苦」「も」「伴う」)それぞれについて、Keyベクトル \(k\) とValueベクトル \(v\) が生成されます。
- 「呼吸苦」のQuery \(q_{呼吸苦}\) は、自分自身を含む文中の全単語のKeyベクトルたち(\(k_{昨日から}, k_{38度}, k_{発熱}, \dots, k_{伴う}\))と、一つ一つ照合されます。これは、\(q_{呼吸苦}\) と各 \(k\) との関連度(類似度)を計算するステップで、詳細は次のセクションで触れますね。
- この照合の結果、例えば「発熱」のKey \(k_{発熱}\) や「咳」のKey \(k_{咳}\) は、「呼吸苦」のQuery \(q_{呼吸苦}\) との関連性が高い、と判断される可能性が高いでしょう。なぜなら、これらの症状は医学的にも関連が深いですからね。AIも学習を通じて、そういった関連性を捉えられるようになっているはずです。一方で、「昨日から」というKey \(k_{昨日から}\) も時間的な関連情報として重要ですし、「38度」のKey \(k_{38度}\) も発熱の程度を示す情報として関連するかもしれません。
- そして、この関連性の度合いに応じて、それぞれの単語のValueベクトル(\(v_{昨日から}, v_{38度}, v_{発熱}, v_{咳}\) など)が重み付けされて集められ、「呼吸苦」という単語の最終的な文脈を考慮した表現が作られます。つまり、「呼吸苦」という言葉が単独で存在するのではなく、「昨日からの38度の発熱と咳を伴う呼吸苦」という、よりリッチな意味合いを持った情報としてAIに認識されるようになるわけです。
なんだか、AIが私たちと同じように、あるいはそれ以上に、言葉と言葉の間の見えない繋がりを読み解いているみたいで、ワクワクしませんか? このQKVモデルこそが、Transformerが複雑な文脈を理解するための、まさに心臓部と言えるのです。
3. Attentionスコアの計算:関連性の度合いを数値化する
さて、前のセクションでQuery、Key、Valueという、Attention機構を支える3人の頼もしい役者たちが登場しましたね。それぞれの役割もなんとなく掴めてきたところで、いよいよ彼らがどのように連携し、「注目すべき情報」すなわち「関連性の度合い」を数値化していくのか、その計算の舞台裏、いわゆる「Attentionスコア」の計算プロセスに足を踏み入れてみましょう。
Transformerモデルの世界で最も広く使われているのは、「Scaled Dot-Product Attention」という名前の計算方法です。名前だけ聞くと「なんだか難しそう…」と感じるかもしれませんが、ご安心ください。一つ一つのステップを丁寧に分解して見ていけば、そのロジックはきっと「なるほど!」と納得できるはずです。全体の流れは、まるで美味しい料理を作るための精密なレシピのよう。では、そのステップを順番に追いかけていきましょう。
ステップ1:QueryとKeyの「心の距離」を測る – 内積によるスコア計算
最初のステップは、ある単語の「知りたい!」という気持ちを表すQueryベクトルと、文中のすべての単語(自分自身も含む、ここがSelf-Attentionの「Self」たる所以ですね)が持つ「私はこんな情報です」というKeyベクトルとの間で、「どれくらい心が通じ合っているか」つまり「関連度」を測ることです。
この「関連度」、実は数学でお馴染みの「内積(Dot Product)」という計算を使って求めます。ベクトル同士の内積を計算すると、二つのベクトルがどれだけ同じ方向を向いているか、そしてそれぞれのベクトルの「強さ(大きさ)」がどれくらいかを総合的に評価した数値が出てきます。ざっくり言うと、向きが似ていて、お互いに「個性が強い」ベクトル同士ほど、内積の値は大きくなる傾向があるんです。これが基本的な「関連度スコア」の素になります。
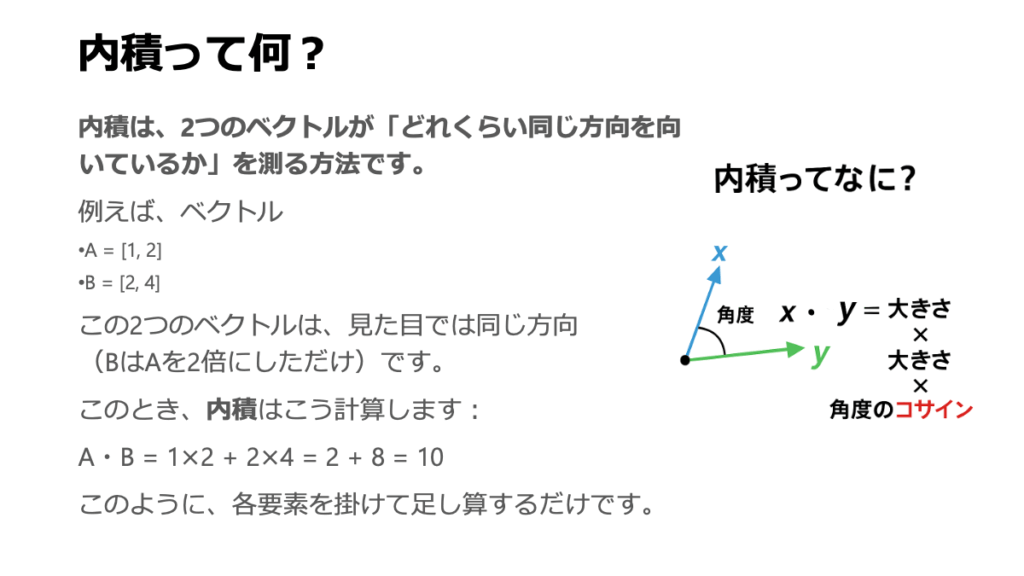
ここでは、多くの場合、入力文全体のQueryをまとめた行列 \(Q\) と、Keyをまとめた行列 \(K\) の「転置」\(K^T\) とを掛け合わせる(行列乗算する)という形で計算が進められます。「行列で考えるのはちょっと…」と抵抗を感じる方もいるかもしれませんが、本質的には、各行のQueryベクトルが、全ての列のKeyベクトル(\(K^T\) になっているので元のK行列の行ベクトルが列になっている状態)と、一つ一つ総当たりで内積を取っている、とイメージしていただくと分かりやすいかもしれません。
この計算を数式で表すと、こうなります:
\[ \text{Scores} = Q K^T \]
ここで、\(Q\) はQueryベクトルの集まり(行列)、\(K^T\) はKeyベクトルの集まり(の転置行列)です。もう少し具体的に、行列の「形」(次元)も一緒に見てみましょう。
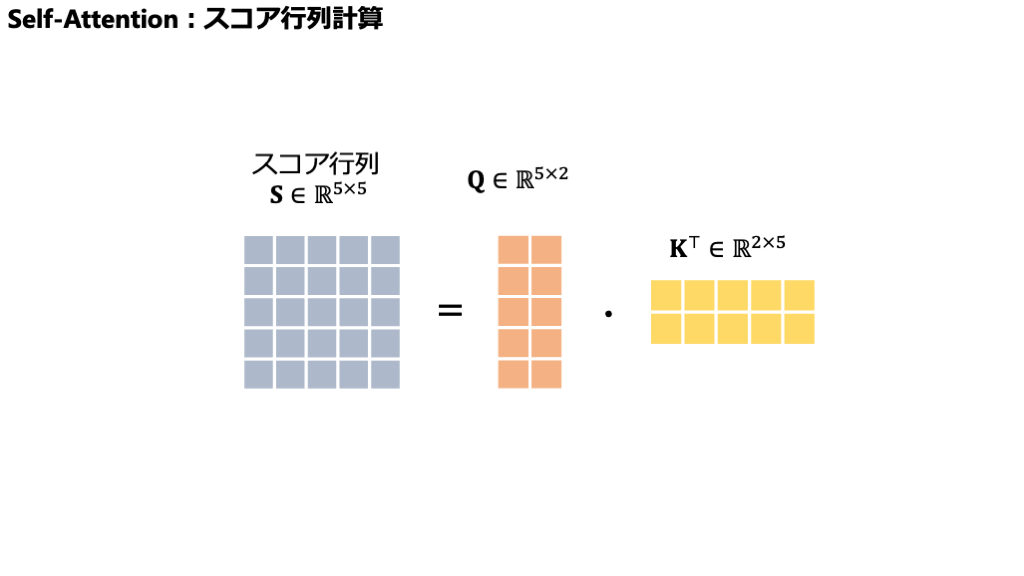
仮に、入力された文章の長さ(トークン数)を \(L\) とし、KeyやQueryベクトルの次元数を \(d_k\) とします(例えば、\(L=10\)単語、\(d_k=64\)次元など)。すると、
- \(Q\) の形状は \((L \times d_k)\) : \(L\) 個のQueryベクトルがそれぞれ \(d_k\) 次元。
- \(K\) の形状は \((L \times d_k)\) : \(L\) 個のKeyベクトルがそれぞれ \(d_k\) 次元。
- なので、\(K^T\)(\(K\) の転置)の形状は \((d_k \times L)\) となります。
この行列同士を掛け算すると、どんな形の行列が出てくるでしょうか?
上の図のように、結果として得られる \(\text{Scores}\) 行列は、\((L \times L)\) という正方行列になります。この行列の \(i\) 行 \(j\) 列目の要素 \(s_{ij}\) が、まさしく \(i\) 番目の単語のQuery (\(q_i\)) と \(j\) 番目の単語のKey (\(k_j\)) との内積、つまり生の「関連度スコア」を表しているのです。このスコアが高いほど、「ふむふむ、この \(i\) 番目の単語は、\(j\) 番目の単語と何やら深いつながりがありそうだぞ!」とAIが感じ取っている証拠、というわけです。
ステップ2:スコアの「熱気」を調整する – スケーリング
さて、ステップ1で計算された生のスコアは、時として「熱くなりすぎる」ことがあります。特に、Keyベクトルの次元数 \(d_k\) が大きい場合、内積の値が非常に大きくなったり、逆に非常に小さくなったりして、数値のばらつきが大きくなる傾向があるんです。もしスコアが極端な値ばかりだと、次のステップで登場するSoftmax関数(後ほど説明しますね)がうまく機能しづらくなり、学習が不安定になってしまうことがあります。具体的には、勾配(学習の手がかりになる数値)がほとんど0に近い「平坦な領域」に入ってしまい、モデルが賢くなるための道筋を見失ってしまうんですね。
そこで、この「熱気」を適度に冷ましてあげるために、計算されたスコアをある数値で「割る」というスケーリング処理を施します。これは、モデルの学習をスムーズに進めるための、いわば「縁の下の力持ち」的な工夫だと考えてください。
具体的には、各スコアをKeyベクトルの次元数 \(d_k\) の平方根、つまり \(\sqrt{d_k}\) で割ります。
\[ \text{ScaledScores} = \frac{QK^T}{\sqrt{d_k}} \]

なぜ平方根で割るのか?というのは少し専門的な議論になりますが、これは入力ベクトルの各要素が平均0、分散1に従うと仮定したときに、内積の分散が \(d_k\) に比例することから来ています。それを \(\sqrt{d_k}\) で割ることで、スケーリング後のスコアの分散を1に近づけ、値のばらつきを抑えようという狙いがあるんですね。この一手間が、モデルの学習を安定させ、より良い性能を引き出すのに貢献している、というわけです。
ステップ3:(オプション)「見てはいけない情報」を隠す – マスキング
計算の途中で、特定の情報、例えば「未来の単語の情報」などを意図的にAttentionの計算から隠したい(無視させたい)場合があります。そのような場合には、「マスキング」という処理がこのスケーリングの後(あるいはSoftmaxの前)に挟まることがあります。これについては、後の「22.3.4 Causal Mask (意味的マスク):未来の情報を見せない工夫」というセクションで詳しくお話ししますので、ここでは「特定の文脈では、注目すべき範囲を制限するテクニックもあるんだな」という程度に覚えておいていただければ大丈夫です。
ステップ4:「注目度合い」を確率に変換 – Softmax関数
スケーリングによって調整されたスコアは、まだ「このQueryとこのKeyは、相対的にどれくらい関連が強そうか」という大小関係を示しているに過ぎません。これを、より解釈しやすく、かつ計算にも使いやすい「各Keyに対する注目の度合い(重み)」へと変換するために、ここで「Softmax関数」という、ちょっとした魔法のような関数が登場します。
Softmax関数は、入力された数値のリスト(この場合は、ある一つのQuery \(q_i\) に対する、全てのKey \(k_j\) とのスケーリング済みスコアの集まり、つまり \(\text{ScaledScores}\) 行列の各行)を受け取ると、それぞれの数値を0から1の間の値に変換し、かつ、変換後の全ての値を合計するとちょうど1になるような「確率分布」の形にして出力してくれます。
あるスコアのリスト \((z_1, z_2, \dots, z_L)\) に対して、\(i\) 番目の要素のSoftmax値は、以下の式で計算されます(\(e\) はネイピア数、つまり自然対数の底で、約2.718です)。
\[ \text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{L} e^{z_j}} \]
この式が何をしているかというと、まず各スコア \(z_j\) を \(e\) の肩に乗せて指数(\(e^{z_j}\))を取ることで、必ず正の値に変換します(しかも、元のスコアの大小関係は保たれ、差はより強調されます)。そして、それらを全て合計したもので、個々の \(e^{z_i}\) を割ることで、全体に対する割合(確率)を算出しているのです。直感的には、より大きなスコアはより大きな確率値(注目度)に、より小さなスコアはより小さな確率値に変換され、全体で合計1の「注目のパイ」を分け合うようなイメージですね。
このSoftmax関数をスケーリング済みスコア行列の各行に適用することで得られた行列が、ついに「Attentionの重み (Attention Weights)」と呼ばれるものになります!この行列(ここでは \(A\) としましょう)の \(i\) 行 \(j\) 列目の要素 \(a_{ij}\) は、「\(i\) 番目の単語のQueryが、\(j\) 番目の単語のKey(ひいてはその単語自身)に、どれだけの割合で注目すべきか」を示しています。この値が大きいほど、その単語が現在のQueryにとって「超重要!」と判断された証拠です。
\[ A = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) \]
\(A\) の形状も、元のスコア行列と同じく \((L \times L)\) で、各行の要素を合計すると1になります。

ステップ5:Value情報を「重み」で集める – 加重和
さあ、長旅でしたが、いよいよ最終目的地が見えてきました!ステップ4で、各QueryがどのKeyにどれだけの「愛(Attentionの重み)」を注ぐべきかが決まりましたね。
この愛情の度合い(重み)を使って、今度は各単語が持っている「実質的な情報」であるValueベクトルたちを、賢く「いいとこ取り」していきます。具体的には、計算されたAttentionの重み \(a_{ij}\) を、対応する \(j\) 番目の単語のValueベクトル \(v_j\) に掛け合わせ、それらを \(j\) について全て足し合わせるのです。この操作を「加重和 (Weighted Sum)」と呼びます。
これはつまり、注目度が高い(重みが大きい)と判断された単語のValueベクトルは、その情報が強く最終結果に反映され、逆に注目度が低い(重みが小さい)単語のValueベクトルは、その影響力が小さくなる、という形で情報が集約・統合されることを意味します。各Query \(q_i\) に対する出力ベクトル \(z_i\) は、以下のように計算されます。
\[ z_i = \sum_{j=1}^{L} a_{ij} v_j \]
これを全てのQuery \(q_i\)(\(i=1, \dots, L\))について行うと、最終的なAttention機構の出力である行列 \(Z\) が得られます。行列で書くと、ステップ4で得たAttentionの重み行列 \(A\) と、Valueベクトルの集まりである行列 \(V\)(形状は \((L \times d_v)\)、\(d_v\) はValueベクトルの次元数)との行列乗算として一気に計算できます。
\[ Z = A V \]

この出力行列 \(Z\)(形状は \((L \times d_v)\))の各行 \(z_i\) が、対応する入力単語 \(x_i\) が文脈全体からの情報(特に注目すべき他の単語の情報)を巧みに取り込み、よりリッチで文脈に即した新しい表現へと生まれ変わった姿なのです!
Attention計算の全体像
ここまでの5つのステップを一つの流れるような数式にまとめると、冒頭で少しだけ顔を出した、あの美しいScaled Dot-Product Attentionの式が再び姿を現します。
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
Query (\(Q\))、Key (\(K\))、Value (\(V\)) という3つの入力情報から、これらのステップを経て、文脈をしっかりと捉えた新しい情報 (\(Z\)) が生み出される…。この一連のプロセス、なんとなくその流れを掴んでいただけたでしょうか? まるでオーケストラで、指揮者(Query)が各楽器(Keys)の音色(Values)に注意を払いながら、全体の調和(最終的な出力)を生み出していくかのようですね。
Multi-Head Attention:複数の「目」で多角的に情報を捉える
さて、3.6までで私たちは、一つのAttention機構(単一ヘッドのScaled Dot-Product Attention)が、どのようにしてQuery、Key、Valueを駆使し、関連性スコアを計算して文脈を捉えた情報を抽出するのか、その詳細なプロセスを見てきました。これは確かに強力な仕組みですが、ここで一つ、欲張りな疑問が湧いてくるかもしれません。「一つの『注目』の仕方だけで、複雑な情報のあらゆる側面を捉えきれるのだろうか?」と。
例えるなら、非常に複雑な絵画を鑑賞する時、一点だけを凝視するよりも、少し視点を変えたり、絵の異なる部分に注目したりすることで、その絵画の全体像や作者の意図、隠されたディテールがより深く理解できることがありますよね。あるいは、一人の患者さんを診断する際に、一人の専門医の視点だけでなく、複数の異なる専門分野の医師たちがそれぞれの視点から意見を出し合うことで、より包括的で的確な診断に至ることがあるのと似ています。
Transformerの設計者たちも、まさにこのように考えました。そして、「一つの大きな強力な目で見る」代わりに、「複数の、それぞれ異なる得意分野を持つ小さな目で同時に、多角的に見る」というアプローチ、すなわちMulti-Head Attention (MHA) という仕組みを考案したのです。このMHAこそが、Transformerが人間のように柔軟で豊かな情報処理を可能にするための、もう一つの重要な鍵となっています。
なぜ「一つの視点」だけでは足りないのか? – Multi-Head Attentionの動機と利点
単一のAttentionヘッド(これまで学んできたScaled Dot-Product Attention)は、学習を通じて獲得した一組の重み行列 \(W^Q, W^K, W^V\) を使って、Q, K, Vベクトルを生成し、特定の方法で「注目」のパターンを学習します。これは、いわば「ある特定の種類の関連性」を見つけ出す専門家のようなものです。しかし、私たちが扱う情報、特に人間の言語や複雑な医療データには、実に多様な種類の関連性が潜んでいます。
例えば、文章を理解する際には、
- 単語と単語の文法的なつながり(例:主語と述語の関係)
- 意味的に近い単語同士の関連(例:「医師」と「看護師」)
- 少し離れた場所にある単語同士の照応関係(例:「その患者は…彼(その患者)は…」)
- あるいは、もっと抽象的なテーマやトピックレベルでの関連性
など、様々なレベル・種類の「注目」が必要になることがあります。単一のAttentionヘッドにこれら全てを完璧に捉えさせるのは、少々荷が重いかもしれません。一つのヘッドが全ての種類の関連性をバランス良く学習しようとすると、結果的にどの関連性も中途半半端にしか捉えられない「器用貧乏」になってしまう可能性も考えられます。
そこでMulti-Head Attentionの出番です。その主な動機と利点は以下の通りです。
- 多様な特徴空間からの情報抽出: MHAは、入力情報を複数の異なる「部分空間(subspace)」に射影し、それぞれの部分空間で独立にAttention計算を行います。これは、まるで同じデータに対して、異なるフィルターや異なる角度から光を当てて、それぞれ異なる特徴を浮かび上がらせるようなものです。各ヘッドが異なる種類の情報や関連性に特化して注目することを学習しやすくなります。
- 表現力の向上: 複数のヘッドからの情報を統合することで、単一のヘッドよりもずっと豊かで、多角的な情報を捉えた表現を獲得できます。これにより、モデル全体の表現力と汎化能力が向上すると期待されます。
- 学習の安定化: 場合によっては、複数のヘッドが異なる側面を学習することで、学習プロセス全体がより安定し、局所最適解に陥りにくくなる効果も報告されています。
例えるなら、一人の万能選手を育てるよりも、それぞれ異なるポジションで高い専門性を持つ選手たちを集めて強力なチームを作る、という戦略に近いかもしれませんね。各ヘッドがそれぞれの得意な「注目」の仕方を学習し、その結果を統合することで、より高度で柔軟な情報処理が実現できるのです。
Multi-Head Attentionの仕組み:並列する「専門家の目」たち
では、このMulti-Head Attentionは、具体的にどのような仕組みで動いているのでしょうか? その名の通り、複数のAttention「ヘッド」が並列して動作し、それぞれの結果を最後に統合するというのが基本的なアイデアです。
Multi-Head Attentionの処理フローは、大きく以下の3つのステップに分けられます。
- 各ヘッドにおけるQ, K, Vの独自生成(入力情報の分割と射影): まず、入力として与えられたQuery (\(Q\))、Key (\(K\))、Value (\(V\)) の行列(あるいは、これらを生成する元となる単語埋め込み行列 \(X\))を、\(h\) 個のヘッド(例えば、Transformer Baseモデルでは \(h=8\) が一般的です)に「分配」します。 ただし、単純に分割するのではなく、各ヘッド \(i\)(\(i=1, \dots, h\))は、それぞれ独自の学習可能な線形射影行列(重み行列)\(W^Q_i, W^K_i, W^V_i\) を持ちます。これらの行列を使って、元のQ, K, V(または\(X\))から、そのヘッド専用の小さなQuery (\(Q_i\))、Key (\(K_i\))、Value (\(V_i\)) を作り出します。 \[ Q_i = Q W^Q_i \quad (\text{または } X W^Q_i) \] \[ K_i = K W^K_i \quad (\text{または } X W^K_i) \] \[ V_i = V W^V_i \quad (\text{または } X W^V_i) \] この操作により、各ヘッドは入力情報をそれぞれ異なる「視点」や「部分空間」で捉え直すことになります。まるで、同じ一枚のレントゲン写真を、放射線科医、呼吸器内科医、腫瘍内科医が、それぞれ自身の専門知識に基づいて異なるポイントに着目して読影するのに似ていますね。
- 各ヘッドでの並列Attention計算: 次に、各ヘッド \(i\) は、ステップ1で生成された自分専用の \(Q_i, K_i, V_i\) を使って、私たちが3.1から3.5で学んだScaled Dot-Product Attentionを独立かつ並列に実行します。 \[ \text{head}_i = \text{Attention}(Q_i, K_i, V_i) = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k’}}\right)V_i \] ここで \(d_k’\) は、各ヘッド内部で使われるKey(およびQuery)ベクトルの次元数です。この計算は \(h\) 個のヘッド全てで同時に行われます。つまり、\(h\) 人の「Attention専門家」が、それぞれ異なる観点から情報を分析し、注目すべきポイントを見つけ出しているイメージです。
- 複数ヘッド出力の結合と最終調整: 最後に、\(h\) 個のヘッドからそれぞれ出力されたAttentionの結果(\(\text{head}_1, \text{head}_2, \dots, \text{head}_h\))を、文字通り連結(Concatenate)して一つの大きなベクトルにします。 そして、この連結されたベクトルに対して、さらに学習可能な線形射影行列 \(W^O\) を適用し、最終的なMulti-Head Attentionの出力を得ます。この最後の線形変換は、各ヘッドが得た多様な情報をうまく統合し、後続の層(例えばFFN)が扱いやすい形に整える役割を果たします。
この一連の処理を図で示すと、以下のようになります。
テキストベースの図
入力 (Q, K, V または X)
│
├── ヘッド1: QW_1^Q, KW_1^K, VW_1^V → ScaledDotProdAttention → head_1
│
├── ヘッド2: QW_2^Q, KW_2^K, VW_2^V → ScaledDotProdAttention → head_2
│
┊ ... (h個のヘッドが並列に処理) ...
│
└── ヘッドh: QW_h^Q, KW_h^K, VW_h^V → ScaledDotProdAttention → head_h
│ │ │
└──────┼─────Concat─────┼────────┘
│ (head_1, head_2, ..., head_h を連結)
▼
┌────────────────┐
│ 線形変換 (W^O) │
└────────────────┘
│
▼
Multi-Head Attention 出力
このように、Multi-Head Attentionは、複数の専門家の意見を統合して、より包括的で信頼性の高い結論を導き出すプロセスと考えることができるでしょう。

Multi-Head Attentionの数式表現と次元の工夫
Multi-Head Attentionの全体の処理を一つの数式でまとめると、以下のようになります。
\[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \dots, \text{head}_h)W^O \]
ここで、各ヘッド \(\text{head}_i\) は、以下のように定義されます。
\[ \text{head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i) \]
そして、\(\text{Attention}(\cdot)\) の部分は、Scaled Dot-Product Attentionの計算、すなわち \(\text{softmax}\left(\frac{Q’ K’^T}{\sqrt{d_k’}}\right)V’\) を表します(ここで \(Q’, K’, V’\) は各ヘッドの入力)。
ここで一つ、非常に巧妙な「次元の工夫」について触れておきましょう。もし、各ヘッドが元の入力と同じ次元数 \(d_{model}\) でAttention計算を行い、その結果を \(h\) 個連結すると、出力の次元数が \(h \times d_{model}\) となってしまい、計算コストやパラメータ数が非常に大きくなってしまいます。そこで、オリジナルのTransformer論文 [1] では、各ヘッドで扱うベクトルの次元を、ヘッドの数 \(h\) で割った値に設定するという工夫がなされています。
具体的には、
- 各ヘッド \(i\) に入力されるQuery、Key、Valueを生成するための射影行列の出力次元を、それぞれ \(d_k’ = d_{model}/h\)、\(d_k’ = d_{model}/h\)、\(d_v’ = d_{model}/h\) とします。(簡単のため、ここでは \(d_k = d_v = d_{model}\) としています。オリジナルの論文では、QueryとKeyの次元 \(d_k\) とValueの次元 \(d_v\) は必ずしも \(d_{model}\) と同じである必要はありませんが、ここでは話を単純化しています。重要なのは、各ヘッドの出力次元が \(d_{model}/h\) 程度になるように射影されるという点です。)
- つまり、射影行列は、\(W^Q_i \in \mathbb{R}^{d_{model} \times (d_{model}/h)}\)、\(W^K_i \in \mathbb{R}^{d_{model} \times (d_{model}/h)}\)、\(W^V_i \in \mathbb{R}^{d_{model} \times (d_{model}/h)}\) のような形状になります。
- その結果、各ヘッド \(\text{head}_i\) の出力ベクトルの次元も \(d_{model}/h\) となります。
- これらの \(h\) 個のヘッド出力を連結(Concat)すると、全体の次元は \(h \times (d_{model}/h) = d_{model}\) となり、元の入力ベクトルの次元数と同じになります。
- そして最後に、この連結された \(d_{model}\) 次元のベクトルに対して、最終調整のための線形射影行列 \(W^O \in \mathbb{R}^{d_{model} \times d_{model}}\) を適用します。
この次元設計により、Multi-Head Attention全体の計算量は、巨大な単一ヘッドAttentionとほぼ同等に保たれつつ、複数の異なる「表現部分空間」からの情報を同時に捉えるという恩恵を享受できるのです。これは、Transformerの設計における非常にエレガントな解決策の一つと言えるでしょう。
行列の形状(次元)のイメージを掴むために、簡単な例を見てみましょう。 入力 \(X\) が \((L \times d_{model})\) の形状(\(L\)はシーケンス長)だとします。

テキストベースの図
入力 X (L × d_model)
│
▼ (各ヘッドi (1...h) に対して)
┌───────────────────────────────────────────────┐
│ W_i^Q (d_model × d_model/h) │
│ W_i^K (d_model × d_model/h) │
│ W_i^V (d_model × d_model/h) │
└───────────────────────────────────────────────┘
│
▼
Q_i (L × d_model/h), K_i (L × d_model/h), V_i (L × d_model/h)
│
▼ (Scaled Dot-Product Attention)
head_i (L × d_model/h)
↓ (h個のhead_iを連結)
Concat(head_1, ..., head_h) (形状: L × (h * d_model/h) = L × d_model)
│
▼
W^O (d_model × d_model)
│
▼
最終出力 Z (形状: L × d_model)
このように、各ヘッドはより低い次元で情報を処理し、それらを最後に統合することで、効率性と表現力のバランスを取っているのです。
医療AIにおけるMulti-Head Attentionの示唆
このMulti-Head Attentionの能力は、複雑で多面的な情報を扱う必要がある医療AIの分野において、どのような可能性を示唆してくれるのでしょうか?
- 電子カルテの高度な読解: 患者さんの電子カルテには、症状の記述、検査結果、治療歴、生活背景など、様々な種類の情報が混在しています。Multi-Head Attentionを用いることで、AIはこれらの情報をより多角的に捉えることができるようになるかもしれません。 例えば、
- あるヘッドは、患者さんが訴える複数の症状間の短期的な関連性(例:「発熱」と「悪寒」の同時出現)に注目する。
- 別のヘッドは、数年前の既往歴と現在の症状との長期的な関連性(例:過去の「間質性肺炎」と現在の「呼吸困難」)に注目する。
- さらに別のヘッドは、特定の投薬情報と、その後の検査値の変動パターンとの関連性(例:「ステロイド投与」と「血糖値上昇」)に注目する。
- また、あるヘッドは否定的な表現(例:「胸痛なし」)を正確に捉え、別のヘッドは家族歴(例:「母親が大腸がん」)の重要性に注目する。
- 医学論文の多角的解析: 医学論文を読む際にも、その内容の理解には様々な側面からのアプローチが必要です。Multi-Head Attentionは、
- あるヘッドが論文の「方法論」の妥当性に注目し、
- 別のヘッドが「結果」の統計的有意性や臨床的重要性に注目し、
- さらに別のヘッドが「考察」で述べられている既存の知見との関連性や限界点に注目する、
- 創薬における複雑な相互作用の理解: 新薬候補の化合物とターゲットとなる生体分子(タンパク質など)との相互作用を予測する際にも、Multi-Head Attentionが役立つ可能性があります。化合物の異なる部分構造や、タンパク質の異なるアミノ酸領域が、それぞれ異なる種類の力(静電的相互作用、疎水性相互作用、水素結合など)で相互作用するかもしれません。複数のヘッドがこれらの異なる相互作用パターンや、結合に関与する特徴的な「モチーフ」に注目することで、より精度の高い結合予測や、新しい薬物設計のヒントが得られるかもしれません。
Multi-Head Attentionは、AIが複雑な医療情報を「浅く広く」ではなく、「深く多角的に」理解するための強力なツールであり、その応用範囲は今後ますます広がっていくことでしょう。
医療分野でのAttention(単一ヘッド・マルチヘッド共通)の注目例
さて、これまでAttention機構の仕組み、特に単一のScaled Dot-Product Attentionと、それを複数組み合わせたMulti-Head Attentionについて詳しく見てきました。これらの技術が、実際に医療の現場でどのように「注目」の力を発揮し得るのか、具体的なシナリオを通してさらにイメージを深めていきましょう。AIが医療データ、特にテキストで書かれたカルテ情報を読み解く際に、どこに注目しているのかを想像することは、AIの可能性と限界を理解する上で非常に重要です。
シナリオ1:糖尿病患者のカルテ読解と合併症リスク評価
以前、単一Attentionの例で「糖尿病」というQueryで情報を探す話をしましたね。Multi-Head Attentionを用いると、このプロセスはさらに高度になります。
ある糖尿病患者さんの長期的なカルテ情報があるとします。そこには、血糖値やHbA1cの推移、体重変化、血圧、脂質データ、投薬履歴(インスリンの種類や量、経口血糖降下薬など)、そして自覚症状(例:「最近、足が痺れる」「視力が落ちてきた気がする」)や医師の所見(例:「眼底検査で軽度の網膜症を認める」「尿中アルブミン微増」)などが記録されています。
このカルテ情報をTransformerに入力した際、Multi-Head Attentionの各ヘッドは、例えば以下のような異なる側面に注目するかもしれません。
- ヘッドA(血糖コントロール指標への注目): 「HbA1c」や「血糖値」といった直接的なコントロール指標と、「糖尿病」というキーワードとの強い関連性に注目し、これらの数値の長期的な変動パターンを追う。
- ヘッドB(合併症関連記述への注目): 「網膜症」「足の痺れ(神経障害の可能性)」「尿中アルブミン(腎症の可能性)」といった、糖尿病の代表的な合併症を示唆する記述や検査結果に注目する。
- ヘッドC(治療介入と効果への注目): 「インスリン」「食事療法」「運動指導」といった治療介入に関する記述と、その後の血糖値やHbA1cの変化との関連性に注目し、治療効果を評価する。
- ヘッドD(時間的経過への注目): 「最近」「昨日から」「半年前」といった時間を示す表現と、症状や検査値の変化を結びつけ、病状の進行度合いや急変の兆候に注目する。
これらの複数のヘッドからの情報が統合されることで、AIは単に「糖尿病」という診断名だけでなく、「長年のコントロール不良により、初期の腎症と網膜症が疑われ、神経障害も進行しつつある可能性のある糖尿病患者」といった、より詳細で、リスク層別化にも繋がるような深いレベルでの患者像の理解に至るかもしれません。そして、この「注目」のパターンを可視化することで、AIがなぜそのようなリスク評価に至ったのか、その根拠を医師が確認する手がかりにもなり得ます。
シナリオ2:救急外来での迅速なトリアージ支援
救急外来では、限られた時間と情報の中で、迅速かつ的確な判断が求められます。患者さんの短い訴えや、救急隊からの限られた情報(これもテキストデータとして入力されるとします)から、緊急度を判断するトリアージの一助としてAIが活用される未来を考えてみましょう。
例えば、「65歳男性、突然の激しい胸痛と冷や汗、呼吸困難あり。既往に高血圧。」という情報が入力されたとします。
Multi-Head Attentionは、
- あるヘッドが「突然の」「激しい胸痛」という症状の性質に強く注目し、
- 別のヘッドが「呼吸困難」「冷や汗」といった随伴症状との組み合わせに注目し、
- さらに別のヘッドが「65歳男性」「既往に高血圧」という患者背景(リスクファクター)に注目する、
といった形で、緊急性の高い疾患(例えば急性心筋梗塞や大動脈解離など)を示唆するパターンを多角的に捉えようとするでしょう。そして、これらの情報から総合的に「注目すべきは、生命を脅かす可能性のある循環器系の救急疾患の兆候である」という内部表現を生成し、トリアージレベルの判断を支援する情報を提示するかもしれません。
これらの例はまだ概念的なものですが、Attention機構、特にMulti-Head Attentionが持つ「多角的な注目」の能力は、複雑な医療情報の中から重要なシグナルを抽出し、医師の臨床判断をサポートするための強力な武器となる可能性を秘めていることを示唆しています。もちろん、その解釈や最終判断は常に医療専門家が行うべきですが、AIが膨大な情報の中から「ここに注目してみてはどうでしょうか?」と的確なヒントを与えてくれる未来は、そう遠くないのかもしれませんね。
💡 Deep Dive!:Multi-Head Attentionの“視点”は誰が決めるのか?
本文では、Multi-Head Attentionが複数の専門医のように、それぞれ異なる視点から情報を捉えると学びました。しかし、ここでこんな疑問が浮かぶかもしれません。「それぞれの専門分野(視点)は、一体どうやって決まるのだろう?」「専門家チームが、全員同じことを見てしまう可能性はないの?」
このコラムでは、そんな疑問に答えていきます。
Q1. 各ヘッドの「視点」は、どうやって決まるの?
A. モデルが「学習」を通じて、自律的に獲得します。
各ヘッドの視点(何に注目するか)は、ランダムや確率で決まるわけではありません。モデルが大量のデータを学習する過程で、タスクの精度が最も高くなるように、各ヘッドが持つ固有の重み行列 (\(W^Q_i, W^K_i, W^V_i\)) が自動で調整されていきます。
その結果、あるヘッドは文法的な関係を見つけるのが得意になり、別のヘッドは単語の意味的な関連性を見つけるのが得意になるなど、学習の成果として専門性が生まれるのです。これは、人間が事前に設計するのではなく、モデル自身がデータから見つけ出す、Transformerの非常に強力な特徴です。
Q2. 全員が同じような「視点」を持ってしまうことはないの?
A. はい、あり得ます。これは「ヘッドの冗長性」と呼ばれます。
理想的には、全てのヘッドが異なる有益な視点を学習することが期待されます。しかし、実際には複数のヘッドがほぼ同じような役割(例えば「すぐ隣の単語に注目する」など)を学習してしまったり、特定のヘッドがほとんど重要な役割を果たさなかったりすることがあります。
これはMulti-Head Attentionの「多様な視点から捉える」という利点を少し損なう可能性がありますが、それでも多くの場合、複数のヘッドを持つことはモデル全体の性能向上に貢献します。
Q3. 私たちが「このヘッドは文法担当」のように役割を指定できる?
A. いいえ、標準的なTransformerではできません。
これが自己注意(Self-Attention)機構の核心部分です。Transformerの強みは、人間が「この情報に着目せよ」というルールを細かく与えるのではなく、データの中から重要な関連性を自動で発見できる点にあります。
私たちが設定できるのは、専門家チームの人数にあたるヘッドの数 (\(h\)) や、それぞれの専門家が扱う情報の次元数 (\(d’_k\)) といった、モデルの「構造」に関するハイパーパラメータのみです。具体的な視点や役割分担は、すべてモデルの学習に委ねられています。
4. Attentionの重みの可視化:AIは何に注目しているのか?
さて、これまでのセクションで、Attention機構がQuery、Key、Valueという要素を使って、どのように「注目度」にあたるスコアを計算し、情報を取捨選択しているのか、その仕組みを追いかけてきましたね。実は、このAttention機構には、もう一つ非常に興味深く、そして実用上も大切な特徴があるんです。それは、AIが計算した「注目度」、つまりAttentionの重みを、私たちの目で見える形に「可視化」できるということです!
AI、特にディープラーニングのモデルは、その複雑さゆえに判断プロセスが「ブラックボックス」だと揶揄されることもあります。しかし、Attentionの重みを可視化することは、まるでそのブラックボックスに小さな窓を開けて、AIの「頭の中」で何が起こっているのか、その一端をこっそり覗き見るような、そんなワクワクする体験を私たちに与えてくれます。
具体的には、前のセクションのステップ4で登場したSoftmax関数によって計算されたAttentionの重み行列 \(A\) (覚えていらっしゃいますか? \( A = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) \) でしたね)。この行列の各要素 \(a_{ij}\) は、「\(i\) 番目の単語(Query)が \(j\) 番目の単語(Key)にどれだけ注目しているか」を示す直接的な指標となっています。この数値の大小を色の濃淡で表現するヒートマップなどの形でグラフにすることで、モデルが入力された情報のどの部分を特に重視し、どの部分をあまり見ていないのかが、一目瞭然になるのです。
「見える化」で何がわかる? – 可視化の3つの大きな意義
では、このAttentionの重みを「見える化」することには、どんな良いことがあるのでしょうか? 主に3つの大きな意義があると考えられています。
- モデルの「気持ち」を理解する(解釈性の向上): AIがなぜそのような判断を下したのか(例えば、なぜこの診断候補を挙げたのか、なぜこのような翻訳文を生成したのか)、その根拠の一端を私たち人間が理解する上で、非常に強力な手がかりを与えてくれます。「なるほど、AI君は入力テキストのこの部分とこの部分を強く関連付けて、この結論に至ったんだな」というように、AIの思考プロセスに少しだけ寄り添えるようになるのです。これは、AIの出す結果を盲目的に信じるのではなく、批判的に吟味し、最終的にAIを信頼して活用する上で、とても大切なことだと思いませんか?
- モデルの「クセ」や「弱点」を見抜く(デバッグと改善): 開発したAIモデルが、期待した通りに賢く振る舞ってくれない…そんな時、Attentionの可視化は問題解決の糸口を示してくれることがあります。例えば、「おっと、このAIは重要なキーワードではなく、句読点やありふれた接続詞にばかり注目してしまっているぞ」とか、「この症状とこの検査所見を結びつけて考えてほしいのに、全然違う無関係な箇所に注目が散漫になっているな」といった、モデルの「勘違い」や「見当違い」のパターンを発見できるかもしれません。こうした弱点を発見できれば、モデルの構造を見直したり、学習データに追加の工夫をしたりと、より賢いAIへと改善していくための具体的なアクションに繋げられます。
- モデルに潜む「偏見」に気づく(バイアスの発見と公平性の確保): 時には、AIモデルが特定の言葉遣いや表現に対して、意図せず不適切な形で過度に注目してしまったり、逆に無視してしまったりすることがあります。これは、学習に使用したデータセットに何らかの偏り(バイアス)が含まれていたり、モデルの構造自体が特定のパターンを不均衡に学習しやすかったりすることが原因で起こり得ます。例えば、医療AIが特定の性別や年齢層に関する記述にのみ過剰に反応するようなAttentionのパターンを示した場合、それは潜在的なバイアスの存在を示唆しているかもしれません。Attentionのパターンを注意深く分析することで、こうした社会的な公平性に関わる問題に早期に気づき、より信頼性の高い、誰にとっても公平なAIシステムを構築するための一歩を踏み出すことができるのです。
このように、Attentionの重みを可視化することは、AIをただ使うだけでなく、その挙動を深く理解し、より良く育てていく上で、非常にパワフルなツールと言えるでしょう。
さあ、実際に見てみよう!Pythonで簡単ビジュアライゼーション
百聞は一見に如かず、です! ここでは、非常に簡単な日本語のサンプル文を使って、ダミーの(=本物ではない、お試し用の)Attentionの重みを人工的に作り出し、それをヒートマップとして可視化するPythonコードをご紹介します。実際のTransformerモデルでは、これらの重みはモデルが学習データから一生懸命に、そして自動的に獲得するものですが、今回はまず「どうすればAttentionの重みを見える形にできるのか」という、その手法自体に焦点を当ててみましょう。
コードを実行する前に、もし皆さんの環境に必要なライブラリが入っていなければ、先にインストールしておきましょう。コマンドプロンプトやターミナルで以下のコマンドを実行してみてください。
pip install torch numpy matplotlib japanize-matplotlibjapanize-matplotlibは、グラフ中の日本語が文字化けしないようにするためのおまじないです。
では、Pythonコードを見ていきましょう。Pythonのコードと聞くと少し身構えてしまうかもしれませんが、一つ一つ何をしているかコメントを付けていますので、ゆっくり追っていけば大丈夫ですよ。
import torch # PyTorchライブラリ。ディープラーニングの計算、特にテンソル操作で大活躍
import numpy as np # NumPyライブラリ。数値計算、特に多次元配列(行列など)の扱いに強い味方
import matplotlib.pyplot as plt # Matplotlibのpyplotモジュール。グラフ描画の定番ライブラリ
import japanize_matplotlib # Matplotlibで日本語を美しく表示するためのサポーター(インポートするだけでOK)
# 1. サンプルとなる日本語のテキストデータ(今回はあらかじめ単語リスト=トークン列として準備)
# 実際のAIプロジェクトでは、まず文章を単語や意味のある単位(トークン)に区切る「トークナイズ」という前処理が必須です。
# それには、MeCab(めかぶ)やJanome(じゃのめ)、SudachiPy(すだちパイ)、あるいはspaCy(すぺいしー)の日本語モデルGiNZA(ぎんざ)といった、
# いわゆる形態素解析ライブラリと呼ばれるツールが役立ちます。
# 今回は、その処理は済んでいるものとして、直接トークンのリストを使いますね。
tokens = ["彼", "は", "昨日", "から", "38度", "の", "発熱", "と", "咳", "が", "あり", "ます"]
num_tokens = len(tokens) # トークンの総数を数えておきます (この例では12個)
# 2. ダミーのAttention重み行列を作成します (num_tokens × num_tokens の正方行列)
# これは、あくまで「お試し用」の重みです。実際のモデルでは学習によって賢い重みが決まります。
# ここでは、i番目のトークン(Query側)が、j番目のトークン(Key側)にどれくらい注目するか、という値を
# ランダムに生成してみましょう。
np.random.seed(42) # いつ実行しても同じランダム値が出るように、乱数の種を固定(再現性のため)
attention_weights_np = np.random.rand(num_tokens, num_tokens) # 0から1の間の乱数で (12 × 12) の行列を生成
# Attentionの重みは、通常、各行(あるQueryに対する各Keyへの注目度)の合計が1になるように正規化されます
# (Softmax関数の出力がそうなっていますね)。ここではそれを擬似的に再現します。
# 各行の要素を、その行の合計値で割ることで、行和を1にします。
attention_weights_np = attention_weights_np / np.sum(attention_weights_np, axis=1, keepdims=True)
# axis=1 は行ごとの合計を意味します。keepdims=True は計算後の次元数を維持し、ブロードキャストをうまくやるためのテクニックです。
# NumPy配列からPyTorchテンソルに変換します (実際のモデルはPyTorchなどのフレームワーク上で動くことが多いので)。
attention_weights = torch.from_numpy(attention_weights_np)
# 3. Matplotlibを使って、Attentionの重みをヒートマップで可視化!
fig, ax = plt.subplots(figsize=(10, 8)) # グラフを描くための「キャンバス(fig)」と「描画領域(ax)」を用意。サイズも指定。
# ax.imshow()関数がヒートマップ描画の主役です。
# attention_weights.numpy() でPyTorchテンソルをNumPy配列に戻してから渡します。
# cmap='viridis' は色の種類(カラースキーム)を指定。他にも色々ありますよ。
cax = ax.imshow(attention_weights.numpy(), cmap='viridis')
# グラフの体裁を整えていきましょう。
# X軸とY軸に、それぞれどの単語に対応するかのラベルを付けます。
ax.set_xticks(np.arange(num_tokens)) # X軸の目盛りの位置を設定
ax.set_yticks(np.arange(num_tokens)) # Y軸の目盛りの位置を設定
ax.set_xticklabels(tokens, rotation=90) # X軸の目盛りラベルをトークン文字列にし、90度回転して見やすく
ax.set_yticklabels(tokens) # Y軸の目盛りラベルもトークン文字列に
# カラーバー(色の濃淡がどの数値に対応するかを示す凡例)を追加します。
fig.colorbar(cax, label="Attentionの重み") # labelでカラーバー自体の説明も付けられます
# 軸のタイトルとグラフ全体のタイトルも設定しましょう。
ax.set_xlabel("注目される単語 (Key側)") # X軸は「注目される側」
ax.set_ylabel("注目する単語 (Query側)") # Y軸は「注目する側」
ax.set_title("Attentionの重みの可視化(ダミーデータによる例)")
plt.tight_layout() # ラベルなどが重ならないように、レイアウトをよしなに調整してくれる便利機能
plt.show() # これでグラフが表示されます!
コードのポイント解説(一部再掲になりますが、お付き合いください):
- ライブラリの役割:
torch: ディープラーニング計算のフレームワーク。ここでは主にテンソル(多次元配列)を扱うために使っています。numpy: Pythonでの数値計算、特に配列や行列の操作を効率的に行うためのライブラリ。matplotlib.pyplot: Pythonでグラフを描画するための標準的なライブラリ。多彩な表現が可能です。japanize_matplotlib: これをインポートしておくだけで、Matplotlibが日本語フォントを認識し、文字化けを防いでくれます。ありがたいですね。
- トークンリスト (
tokens): これは、AIが処理する単位に分割された単語のリストです。実際の応用では、この分割(トークナイゼーション)自体が非常に重要なステップとなります。 - ダミーの重み (
attention_weights_np):np.random.rand()で生成しているのは、0から1の間のランダムな数値です。これを二次元配列(行列)にしています。そして、各行の合計が1になるように正規化することで、Softmax関数の出力であるAttentionの重みの「雰囲気」を再現しています。本物のモデルでは、この重みは学習によって意味のある値に調整されます。 - ヒートマップ描画 (
ax.imshow()): この関数が、数値の行列を色の濃淡で表現された画像(ヒートマップ)に変換してくれます。cmap引数で色のテーマを変えられるので、色々試してみるのも面白いですよ(例えば'hot','coolwarm','Blues'など)。 - 軸ラベルとタイトル: グラフは何を表しているのか、軸は何を意味するのかを明記することは、情報を正確に伝えるために非常に大切です。特にAttentionのヒートマップでは、Query側とKey側をしっかり区別しましょう。
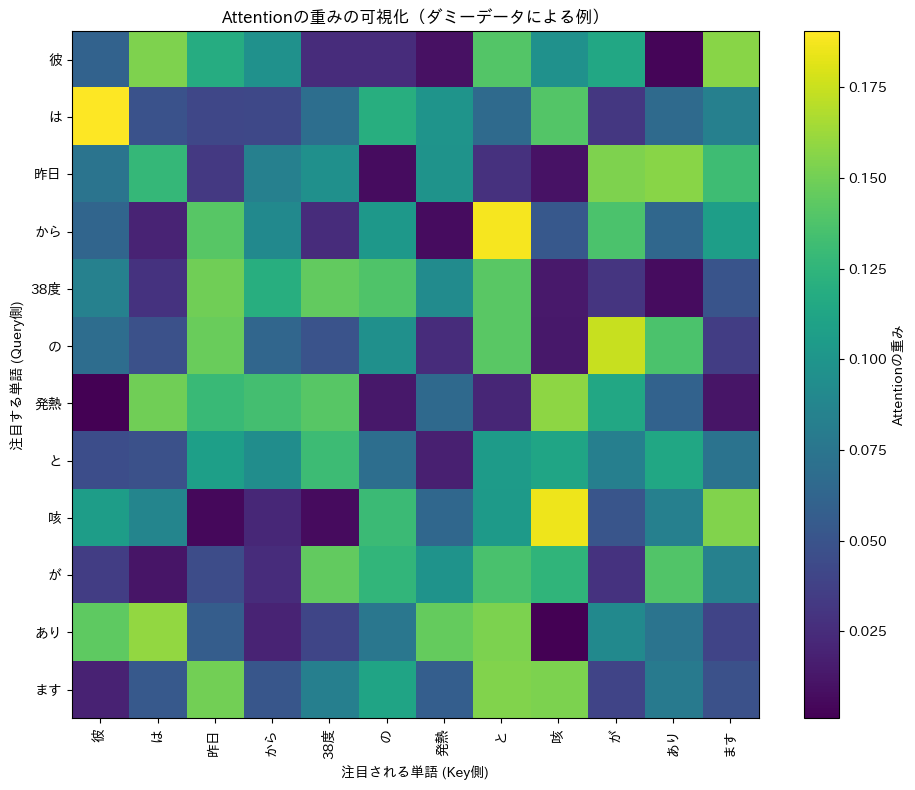
さて、このコードを実行すると、カラフルな正方形の図(ヒートマップ)が表示されたことと思います。この図の読み解き方ですが、まず、Y軸(縦軸)が「注目する側」の単語(Queryトークン)、そしてX軸(横軸)が「注目される側」の単語(Keyトークン)を表しています。そして、各マス目の色が、Y軸の単語がX軸の単語にどれだけ注目しているか(つまり、Attentionの重みの大きさ)を示しています。右側にある凡例(カラーバー)を見て、色が明るい(または特定の色スケールで値が高いことを示す色。今回の'viridis'という配色では黄色に近いほど)ほど、注目度が高い、という意味になります。
例えば、もし「発熱」の行(Y軸)と「咳」の列(X軸)が交差するマス目が非常に明るい黄色になっていたとしたら、それはモデルが「発熱」という単語の意味を解釈したり、次の単語を予測したりする際に、「咳」という単語の情報を強く参考にしている、と読み解くことができるわけです。「なるほど、AI君はここでこの二つを結びつけて考えているんだな!」と、AIの思考の一端に触れたような気持ちになれるかもしれませんね。
医療現場での応用を夢想する:AIの「視線」から何が見える?
では、このAttentionの可視化というテクニックが、医療の現場で具体的にどんな風に役立つ可能性があるのでしょうか? 少し想像を膨らませてみましょう。
例えば、患者さんがご自身の言葉で記述した問診票のテキストデータや、日々の体調変化を記録した日記のような文章をTransformerベースのAIに入力して、AIに重要な愁訴や状態の変化点を抽出させる、といったタスクを考えてみます。仮に、ある患者さんの記録にこんな一文があったとしましょう:「2日前からズキズキする頭痛が続いていて、吐き気も少しあります。以前もらった痛み止めを飲んでみたのですが、あまり効いている感じがしませんでした。」
この文章からAIが「頭痛」というキーワードを認識したとして、その「頭痛」という単語を処理(理解)する際に、AIが文中のどの部分に注目しているかを可視化できたとしたら…。もしかしたら、「2日前から」や「ズキズキする」といった症状の具体的な性質や期間を表す言葉や、「吐き気」といった併発症状の記述に、ちゃんと強いAttentionが向いているかもしれません。また、「以前もらった痛み止め」や「あまり効いている感じがしませんでした」といった、既往の治療やその効果に関する部分への注目度も目で見て確認できるでしょう。
もし、AIが「痛み止め」という薬剤名には非常に強く注目しているのに、肝心の「ズキズキする」といった症状の具体的な描写への注目が相対的に薄い、なんてことがヒートマップから読み取れたとしたらどうでしょう? 「ふむ、このAIモデルは、薬剤の名前には敏感に反応するけれど、症状の質的な情報への配慮が少し足りないのかもしれないな。もう少し症状の機微を捉えられるように、学習データやモデルの設計を見直す必要があるかもしれない」といった、AIをより賢く、そしてより信頼できるパートナーへと育てていくための貴重なヒントや改善点が見えてくるかもしれません。
このように、AIが「どこを見ているのか」を理解することは、AIの診断支援結果や要約文生成などのアウトプットを鵜呑みにせず、その背景にあるAIの「思考のクセ」のようなものまで含めて評価し、最終的に医療の質向上に繋げていく上で、とても大切な視点を与えてくれるのではないでしょうか。
5. Causal Mask (意味的マスク):未来の情報を見せない工夫
さて、これまでの話で、Transformerが文中の単語同士の関連性を見つけ出す「Attention」という仕組みについて見てきました。Transformerは、まるで文章全体を一度に見渡して、どこに注目すべきかを判断しているかのようでしたね。しかし、時としてAIには「見てはいけないもの」、つまり「未来の情報」を意図的に隠す必要がある場面が出てきます。特に、Transformerが文章を新しく生成したり、次に来る単語を予測したりするようなタスクでは、この「未来の情報をカンニングさせない」という工夫が非常に重要になります。そのための賢い仕掛けが、今回ご紹介するCausal Mask(コーザルマスク、因果マスク)、別名Look-ahead Mask(先読み防止マスク)と呼ばれるものです。
このCausal Maskは、主にTransformerのDecoderと呼ばれる部分(連載の後半で詳しく触れますが、主に文章生成などのタスクを担当します)で活躍します。「Causal」とは「因果関係の」という意味。つまり、原因となる過去の情報だけを見て、結果となる未来の情報を予測させる、という考え方に基づいているんですね。
目的:「ネタバレ禁止!」AIに未来を予知させないためのルール
では、なぜAIにわざわざ「未来を見るな」と指示する必要があるのでしょうか? その最大の目的は、モデルが学習や予測の際に、ズルをして未来の正解情報を見てしまうのを防ぐためです。
少し想像してみてください。皆さんがAIに「今日の天気は」という書き出しに続く言葉を予測させたいとします。もしこの時、AIがこっそり辞書の続きのページをめくって「晴れ」という「正解」の単語を事前に知っていたとしたら…。それはもう「予測」ではなく、ただの「答えの丸写し」ですよね。これでは、AIが本当に文脈を理解して言葉を紡ぎ出す能力を鍛えることはできませんし、実用的な予測モデルも作れません。
AIが文章を一つずつ生成していく場合、多くは自己回帰的(Autoregressive)な方法を取ります。これは、「①まず最初の単語を生成 → ②次に、生成した最初の単語を使って2番目の単語を生成 → ③さらに、生成した1番目と2番目の単語を使って3番目の単語を生成…」というように、直前の自身の出力を次の入力の一部として使いながら、雪だるま式に情報を紡いでいくやり方です。このとき、各ステップで「まだ生成していない未来の単語」の情報は、AIの視界から完全に遮断されていなければなりません。Causal Maskは、この「未来のネタバレは絶対禁止!」という厳格なルールをAIに守らせるための、いわば魔法の目隠しのような役割を担っているのです。
仕組み:未来のスコアを「ほぼゼロ」にする巧妙な仕掛け
では、具体的にどのようにして「未来を見えなくする」という魔法を実現しているのでしょうか? Causal Maskは、Attentionスコアを計算するプロセスの、まさにクライマックス直前、つまりSoftmax関数を適用する直前(前のセクションのステップ3で「マスキング」として少し触れましたね!)という絶妙なタイミングで登場し、その力を発揮します。
その手法は意外とシンプルかつ強力です。あるQueryトークン(例えば、今まさに次の単語を予測しようとしている位置のトークン)に対して、それよりも「未来」の位置にある全てのKeyトークンに対応するAttentionスコアに、意図的にとてつもなく小さな値(実質的に負の無限大に近い値。プログラムコードではよく -1e9 や -float('inf') といった非常に大きな負の数で代用されます)を足し算するのです。
ここで思い出してほしいのが、Softmax関数の性質です。Softmax関数は、入力されたスコアを \(e\)(ネイピア数)の肩に乗せて指数を取り、その後で正規化するのでしたね。もし \(e\) の肩に、例えば \(-1000000000\) のような非常に小さな負の数が乗ったらどうなるでしょう? \(e^{-1000000000} \approx 0\) というのは、限りなく0に近い、とてもとても小さな値になります。その結果、Softmax関数を通過した後では、未来のトークンに対応する部分のAttentionの重み(つまり注目度)が、実質的にほぼ0になってしまうのです!
例えば、あるQueryに対するスケーリング済みスコア(Softmax適用前)が、トークン1から4に対してそれぞれ [2.0, 1.5, 3.0, 0.5] だったとしましょう。もし今、AIがトークン1(例えば「今日」)の次に続くトークン2(例えば「の」)を予測しようとしているとします。この時、AIはトークン1の情報は見ても良いですが、トークン2、3、4(「の」「天気」「は」など、まだ予測していない未来の情報)は絶対に見ることはできません。そこでCausal Maskを適用すると、トークン1が参照できるスコアは、例えば [2.0, -1e9, -1e9, -1e9] のように加工されます。これをSoftmax関数にかけると、-1e9 に対応する未来のトークンへの注目度はほぼ0%になり、結果的にAIは自分自身や過去のトークンにしか注目できなくなる、という寸法です。まさに、未来への扉を固く閉ざすような処理ですね。
このCausal Maskの働きを、以前にも少しお見せした下のような図で再確認してみましょう。この図は、Attentionスコア行列(Softmax適用前)のどの部分が計算に使われ(OK)、どの部分がマスクされるか(MASK)を示しています。
Key: トークン1 トークン2 トークン3 トークン4 (注目される側)
Query (注目する側)
トークン1 OK MASK MASK MASK (トークン1はトークン1しか見れない)
トークン2 OK OK MASK MASK (トークン2はトークン1,2を見れる)
トークン3 OK OK OK MASK (トークン3はトークン1,2,3を見れる)
トークン4 OK OK OK OK (トークン4はトークン1,2,3,4を見れる)
(OK: Attentionスコアをそのまま計算, MASK: スコアを負の無限大に設定し、実質的に注目度を0にする)
この図で「MASK」と書かれている右上三角の領域が、未来のトークンに対応する部分です。これらの部分のスコアが負の無限大(あるいはそれに近い非常に小さい値)に設定されるため、Softmax関数を通過した後のAttentionの重み(注目度)はほぼ0になります。その結果、各Queryトークンは、自分自身の位置、および自分よりも過去の(すでに出現・生成済みの)Keyトークンには注目できますが(図の「OK」の部分)、未来のKeyトークンには注目できなくなる、というわけです。
Pythonコードで見るCausal Maskの実装(概念)
では、この「未来への窓を閉じる」Causal Maskを、PythonとPyTorchライブラリを使ってどのように実装できるのか、簡単な概念実証コードで見ていきましょう。実際にコードを追いかけ、手を動かしてみることで、「なるほど、こうやって未来の情報を隠しているのか!」という実感も湧きやすいと思いますよ。
import torch # PyTorchライブラリ。ディープラーニングでお馴染みですね
import torch.nn.functional as F # PyTorchの便利な関数群(Softmax関数もここに入っています)
# 仮のシーケンス長(文章のトークン数)を設定
seq_len = 5 # 例えば5つのトークンからなるシーケンスを考えます
# 1. ダミーのAttentionスコア(Softmax適用前)を準備
# 本来は QK^T/√d_k の計算結果ですが、ここではランダムな数値で代用します。
# 形状は (Queryトークン数, Keyトークン数) を想定。ここでは (5, 5) ですね。
attention_scores = torch.randn(seq_len, seq_len)
print("--- 元のAttentionスコア (Softmax前) ---")
print(attention_scores)
# 2. Causal Mask(未来を見えなくするマスク)を作成
# マスクは、Trueの部分が「隠したい未来の箇所」を示すブール型(True/False)の行列です。
# Queryの位置を i、Keyの位置を j とすると、j > i となる部分(つまり未来)をマスクします。
# torch.triu(input, diagonal) は、行列の上三角部分を取り出す関数です。
# diagonal=0 なら主対角線を含み、diagonal=1 なら主対角線を含まない(主対角線より1つ「上」の)対角線から上を取り出します。
# これがまさに、未来のトークンに対応する位置関係ですね!
mask_matrix = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
# torch.ones(seq_len, seq_len) で全ての要素が1の (5x5) 行列を作成
# これに torch.triu を適用すると、未来部分が1、過去と現在は0の行列ができます。
# 最後に .bool() で、0をFalse、1をTrueのブール型に変換します。
# この True の部分が、後でスコアを極小値で埋める対象となります。
print("\n--- Causal Mask (Trueの部分が未来なのでマスク対象) ---")
print(mask_matrix)
# 3. マスクの適用:未来のスコアを「ほぼ負の無限大」に
# attention_scores の中で、mask_matrix が True の位置にある要素を、
# 非常に小さい値(例: -1e9 や float('-inf'))で置き換えます。
# これにより、Softmaxを通った後の確率がほぼ0になります。
masked_attention_scores = attention_scores.masked_fill(mask_matrix, -1e9) # -1e9 は -1 × 10^9 のこと
print("\n--- マスク適用後のAttentionスコア (Softmax前) ---")
print(masked_attention_scores)
# 4. Softmax関数を適用して、最終的なAttentionの重み(確率)を得る
# dim=-1 は、行列の各行ごとにSoftmaxを適用することを意味します(つまり、各QueryについてKeyへの注目度を計算)。
attention_weights = F.softmax(masked_attention_scores, dim=-1)
print("\n--- Causal Mask適用後のAttentionの重み (Softmax後) ---")
print(attention_weights)
# 確認してみましょう!
# 出力された attention_weights を見ると、確かに対角線よりも右上(未来に対応する部分)の重みが
# ほぼ0になっているはずです。
# 例えば、1行目(最初のQueryトークン)の重みは、1列目(自分自身)には比較的大きな値がありますが、
# 2列目以降(未来のKeyトークン)への重みは、ほぼ0になっていることが見て取れるでしょう。
# これで、各Queryは自分より未来の情報をカンニングできなくなりましたね!
コードのポイント解説(こちらも一部再掲になりますが、お付き合いを):
seq_len: これは処理する文章(トークン列)の長さを表します。この例では5としています。attention_scores: これは \(QK^T/\sqrt{d_k}\) を計算し、スケーリングまで終えた後の「生の」Attentionスコアだと考えてください(Softmaxを適用する前の段階です)。各行が特定のQueryトークン、各列が特定のKeyトークンに対応し、その要素が両者の関連度を示しています。mask_matrix = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool(): この一行がCausal Mask作りの核心です。torch.ones(seq_len, seq_len): まず、全ての要素が1で満たされた正方行列(この例では5×5)を作ります。torch.triu(..., diagonal=1): 次に、この行列の「上三角部分(Upper Triangle)」だけを取り出します。diagonal=1という指定が重要で、これは「主対角線そのものは含まず、主対角線の一つ右上の要素から上側の部分」を意味します。この部分が、まさしく各Queryトークンにとって「未来」にあたるKeyトークンの位置に対応します。この処理で、未来の部分は1、それ以外の部分(現在と過去)は0という行列ができます。.bool(): 最後に、この0と1からなる行列をブール型(True/False)に変換します。1だった部分(未来の位置)がTrue、0だった部分(現在と過去の位置)がFalseとなります。このmask_matrixでTrueになっている箇所が、次にスコアを極小値で置き換える対象となるわけです。
masked_attention_scores = attention_scores.masked_fill(mask_matrix, -1e9): このmasked_fill関数が、魔法の一手を実行します。attention_scores行列の中で、mask_matrixがTrue(つまり未来の位置)になっている要素の値を、ごっそりと-1e9(マイナス10億という、実質的に負の無限大として機能する非常に小さな数値)で置き換えてしまうのです。attention_weights = F.softmax(masked_attention_scores, dim=-1): マスク処理によって未来の情報が隠蔽されたスコア行列に対して、通常通りSoftmax関数を適用(dim=-1で行ごと、つまり各Queryごとに)し、最終的なAttentionの重みを計算します。
--- 元のAttentionスコア (Softmax前) ---
tensor([[-0.5122, 0.2897, -1.4887, 0.4464, -1.1653],
[ 0.8328, -1.1301, -0.5856, 0.4115, 0.6017],
[-2.3316, -1.5581, 0.0733, -0.9280, 0.6568],
[ 0.3562, 1.1784, 0.4851, 0.9921, 0.5696],
[ 1.9154, -0.2012, -1.5073, 1.0429, -0.0519]])
--- Causal Mask (Trueの部分が未来なのでマスク対象) ---
tensor([[False, True, True, True, True],
[False, False, True, True, True],
[False, False, False, True, True],
[False, False, False, False, True],
[False, False, False, False, False]])
--- マスク適用後のAttentionスコア (Softmax前) ---
tensor([[-5.1225e-01, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09],
[ 8.3280e-01, -1.1301e+00, -1.0000e+09, -1.0000e+09, -1.0000e+09],
[-2.3316e+00, -1.5581e+00, 7.3322e-02, -1.0000e+09, -1.0000e+09],
[ 3.5620e-01, 1.1784e+00, 4.8509e-01, 9.9214e-01, -1.0000e+09],
[ 1.9154e+00, -2.0115e-01, -1.5073e+00, 1.0429e+00, -5.1889e-02]])
--- Causal Mask適用後のAttentionの重み (Softmax後) ---
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.8768, 0.1232, 0.0000, 0.0000, 0.0000],
[0.0702, 0.1521, 0.7776, 0.0000, 0.0000],
[0.1587, 0.3611, 0.1805, 0.2997, 0.0000],
[0.5845, 0.0704, 0.0191, 0.2443, 0.0817]])このコードを実行した結果、最後の「Causal Mask適用後のAttentionの重み (Softmax後)」の部分を見てみてください。行列の対角線よりも右上側の要素(つまり、各Queryにとって未来にあたるKeyへの注目度)が、ほぼ0に近い値になっていることが確認できるはずです。例えば、1行目(最初のQueryトークン)の重みを見ると、1列目(自分自身への注目)にはそれなりに値がありますが、2列目以降(未来のKeyトークンへの注目)はほぼ0になっているでしょう。これで、AIは未来の情報をカンニングすることなく、現在までの情報に基づいて次の判断を下すことができるようになったわけです!
医療分野での意義:AIに「水晶玉」ではなく「正確な過去分析」を
さて、この一見地味かもしれないCausal Maskですが、医療AI、特に時系列データを扱う多くの場面において、モデルの信頼性を担保する上で非常に重要な役割を果たします。
例えば、患者さんの症状が時間とともにどのように変化していくか(症状進行予測)をAIで予測する研究を考えてみましょう。今日の検査値やカルテの記述までを入力として、明日の患者さんの状態を予測させたいとします。もしこの時、学習中のAIが、こっそり明後日や一週間後のカルテデータまで「先読み」して学習してしまったらどうなるでしょう? もちろん、訓練データに対する予測精度は驚くほど高くなるかもしれません。しかし、それは未来の「答え」を知っている上での結果であり、真の予測能力ではありません。そんな「カンニングAI」は、実際の臨床現場で未知のデータに対して正確な予測をすることは期待できませんよね。Causal Maskは、まさにこのような事態を防ぎ、AIがちゃんと「過去と現在の情報だけ」に基づいて、純粋な未来予測を行うように強制する役割を果たします。
あるいは、ある新しい治療法を開始した後、その効果が時間経過と共にどのように現れてくるか(治療効果の時系列モデリング)を予測するような研究でも、Causal Maskの考え方は不可欠です。各時点での治療効果の予測は、それ以前のデータ、つまり「その時点までに判明している情報」のみに基づいて行われなければ、その治療法の真のポテンシャルや、効果が現れるまでの時間的パターンなどを正しく評価することはできません。
このように、Causal Maskは、Transformerが時間的な順序や因果関係が決定的に重要なデータを正しく学習し、現実世界に即した信頼性の高い予測や文章生成などを行うために、なくてはならない「縁の下の力持ち」と言えるでしょう。AIに怪しげな「水晶玉(未来を見る魔法の玉)」を持たせるのではなく、あくまで「過去のデータに基づいた堅実な推論能力」を身につけさせるための、研究者たちの知恵と工夫が詰まった技術の一つなのです。
6. 医療分野におけるAttention機構の応用と可能性
さて、これまでAttention機構の内部構造や計算の仕組みといった、いわば「からくり」の部分を詳しく見てきましたね。では、この情報を巧みに取捨選択し、重要なポイントに「注目」する能力は、私たちの生活に深く関わる医療というフィールドで、一体どんな未来を拓いてくれるのでしょうか? 実は、Transformerモデル、特にその心臓部とも言えるSelf-Attentionの登場は、医療AIの分野に静かな、しかし着実で大きな変革の波をもたらしつつあるんです。
それはまるで、経験豊かな専門医が長年の知識と鋭い直感で、複雑な情報の中から診断や治療の鍵となる重要な手がかりを瞬時に見つけ出すように、AIが膨大な医療データの中から本質的なパターンを捉え、私たち医療者を力強くサポートしてくれる…そんな未来が、もうすぐそこまで近づいてきているのかもしれません。具体的にどんな応用が考えられているのか、一緒に見ていきましょう。
電子カルテ・医療記録の解析:眠れる「情報の巨人」を呼び覚ます
日々の診療で蓄積されていく電子カルテや様々な医療記録は、まさに情報の宝庫。しかし、その膨大さゆえに、必要な情報へ迅速にアクセスすることが難しい場合もありますよね。Attention機構は、この「情報の巨人」から価値ある知見を引き出すのに役立ちます。
- 診断の頼れるアシスタント(診断支援): 患者さんの現在の症状、これまでの長い病歴、山のような検査結果…。これらの情報の中から、特定の疾患を示唆するクリティカルな記述や数値のパターンをAIが「注目」し、ハイライトして提示してくれたらどうでしょう? Attentionは、例えば「この患者さんの訴える倦怠感と微熱、そして3ヶ月前のこの血液検査の結果は、もしかしたら〇〇病の初期症状と関連があるかもしれない」といったように、診断の精度向上や見落とし防止に貢献する可能性を秘めています。[1, 2]
- 長文記録も一瞬で要点整理(臨床文書の自動要約): 退院時サマリーや他の専門医への紹介状など、医療現場ではしばしば詳細な長文の記録が作成されます。Attentionを活用すれば、これらの文書から本当に伝えるべき核心部分、つまり「この患者さんの経過で最も重要なポイントは何か?」をAIが的確に捉え、簡潔な要約を自動で生成する手助けができます。これにより、医療者間の情報共有がよりスムーズになり、何よりも貴重な時間を他の業務に充てられるようになるかもしれませんね。
- 「あの時のあの患者さん」をすぐに見つけ出す(情報検索・類似症例検索): 「以前、これとよく似た症状や検査値の推移を示した患者さんがいたはずなんだけど、すぐには思い出せない…」そんな経験はありませんか? 現在の患者さんの特徴(これをAIへのQueryと考えます)と、過去の膨大な症例データベース(これがKeyとValueの集まりですね)とを照合し、治療方針の決定や予後予測の参考になる類似症例をAIが瞬時に探し出してくれる。そんな未来も、Attention機構のおかげで現実味を帯びてきています。
医科学論文・文献情報の処理:広大な「知の海」を航海する羅針盤
新しい治療法や診断技術は、世界中の研究者による日々の論文発表によって、その知識が積み重ねられています。しかし、その量はまさに広大な海。Attentionは、この「知の海」を効率よく航海するための羅針盤となってくれるかもしれません。
- 最新知識をあなたの手に(知識抽出): 毎日、世界中で発表される膨大な数の医学論文。そのすべてに目を通し、重要な情報を見つけ出すのは、どんなに熱心な研究者や臨床家にとっても至難の業です。Attentionは、これらの文献から、例えば「特定の遺伝子とある疾患との新たな関連性」や「新薬の予期せぬ副作用情報」、「最新の治療ガイドラインの変更点」といった重要な知見をAIが自動的に抽出し、データベース化するのを助けてくれます。[3] これにより、私たちは必要な情報により早く、より正確にたどり着けるようになるでしょう。
- 研究を加速するスマート検索(文献検索エンジンの高度化): ご自身の研究テーマに関連する論文を探す際、従来のキーワード検索だけではノイズが多く、本当に価値のある情報を見つけるのに苦労することも少なくありません。AttentionベースのAIは、検索クエリの意図や文脈を深く理解し、より本質的で関連性の高い論文を的確に推薦してくれるようになるかもしれません。研究の効率が格段に向上し、新しい発見への道のりが少しでも短縮されると嬉しいですよね。
創薬・薬剤開発:まだ見ぬ治療法への「近道」を探る
新しい薬を一つ開発するには、莫大な時間と費用、そして多くの失敗が伴うと言われています。Attention機構は、この困難な道のりを少しでも効率化し、新しい治療法をより早く患者さんの元へ届けるための「近道」を探る手助けとなる可能性を秘めています。
- 分子の「相性」を見抜く(化合物とタンパク質の相互作用予測): 新薬の開発プロセスにおいて、薬の候補となる化合物が、体内の標的となるタンパク質(例えば、病気の原因となる酵素や受容体など)とどのように結合し、作用するのかを予測することは極めて重要です。Attentionは、化合物の分子構造やタンパク質のアミノ酸配列の中で、どの部分(原子や官能基、特定の配列パターンなど)が両者の結合に特に重要なのか、その「注目すべき部位」を解析することで、より効果的で副作用の少ない薬の設計を支援します。[4]
- 「もしも」を賢く予測する(副作用予測): 既存の医薬品に関する膨大なデータ(構造、薬理作用、既知の副作用など)をAIに学習させることで、開発中の新しい薬の候補が、どのような副作用を引き起こす可能性があるのかを、初期段階で予測しようという試みも進んでいます。Attentionは、どの構造的特徴が特定の副作用と関連しているかに「注目」することで、この予測精度を高めるのに貢献するかもしれません。
医療画像診断支援:AIの「もう一つの眼」で微細なサインを捉える
レントゲン写真、CTスキャン、MRI画像、病理画像…。医療画像は、現代医療における診断に不可欠な情報源ですが、その読影には高度な専門知識と豊富な経験が求められます。Attention機構は、AIに「もう一つの熟練した眼」を与える可能性を秘めています。
- 見えないサインを捉え、判断根拠を示す(病変検出と位置特定): 特に最近注目されているのが、画像認識の分野にTransformerのアーキテクチャを応用した「Vision Transformer (ViT)」と呼ばれるモデル群です。これらのモデルにAttention機構を組み込むことで、AIがX線写真やCT画像の中から、例えば初期の小さな肺がんの結節影、微細な骨折線、あるいは気づきにくい脳出血のサインといった病変を検出する際に、画像のどの領域に「注目」してその判断に至ったのかを、ヒートマップのような形で可視化できるようになってきました。[5] これは、単にAIが「病変あり」と結果を出すだけでなく、その判断根拠を医師が目で見て確認し、AIの判断を信頼したり、あるいは疑問を持ったりする上で、非常に大きな意味を持ちます。医師とAIによるダブルチェック体制が、より精度の高い診断を実現するかもしれません。
ゲノム・プロテオーム解析:壮大な「生命の設計図」を読み解く
私たちの体を形作り、生命活動を司る遺伝情報(ゲノム)やタンパク質(プロテオーム)は、まさに壮大な生命の設計図です。この複雑な設計図を読み解き、病気のメカニズム解明や個別化医療へと繋げる研究にも、Attention機構が応用され始めています。
- 遺伝子の未知なる「役割」を探る(遺伝子配列の機能予測): ヒトゲノムには約30億もの塩基対があり、その中で遺伝子として機能する領域や、遺伝子の働きを調節する領域(プロモーターやエンハンサーなど)が複雑に配置されています。Attentionは、この非常に長いDNAやRNAの配列の中で、どの部分のパターンが特定の機能(例えば、あるタンパク質を作り出す指示や、遺伝子のスイッチのオンオフなど)にとって重要なのか、その「注目すべき配列モチーフ」を見つけ出し、生命の謎を解き明かす手助けをします。[6]
- 病気の「隠れた犯人」を特定する(疾患関連遺伝子の特定): 特定の病気を持つ患者さんたちの集団と、健康な方々の集団のゲノム情報をAIで比較解析する際に、Attention機構は、両群間で顕著な違いが見られる遺伝子領域や、疾患の発症に強く関わっている可能性のある未知の遺伝子変異のパターンに「注目」することができます。これにより、病気の根本原因の解明や、新しい治療ターゲットの発見、さらには個々人の遺伝的背景に基づいた「オーダーメイド医療(個別化医療)」への道が、また一歩大きく開けるかもしれませんね。
光と影:Attentionの輝かしい可能性と、乗り越えるべき倫理的課題
ここまで見てきたように、Attention機構を搭載したAIは、医療の様々な場面で、まるでSF映画で描かれた未来が現実になったかのような、計り知れない恩恵をもたらす大きな可能性を秘めています。診断の精度向上、治療法の開発加速、医療従事者の負担軽減、そして最終的にはより多くの患者さんの救命やQOL(生活の質)の向上…。考えるだけでワクワクしてきますね。
しかし、その輝かしい未来を実現するためには、私たちが真摯に向き合い、賢明に乗り越えていかなければならないいくつかの重要な課題や倫理的な問題も、光と影のように存在しています。それはまるで、新しく開発された非常に強力な医薬品が、その素晴らしい効果と共に、未知の副作用のリスクや適切な使用法を慎重に検討しなければならないのと似ているかもしれません。
- 患者情報の守護神であれ(データのプライバシーとセキュリティの確保): 言うまでもありませんが、患者さんのカルテ情報やゲノムデータは、個人の最もデリケートでプライベートな情報です。これらの情報をAIの学習や実際の運用で利用する際には、外部への漏洩や不正アクセス、目的外利用といった事態が絶対に起こらないよう、技術的な対策(例えば、データの匿名化、暗号化、安全なサーバー管理など)はもちろんのこと、法制度や組織内の厳格な倫理規定、そして何よりも扱う人々の高い倫理観に基づく、鉄壁のセキュリティ体制が不可欠です。技術の進歩と個人の尊厳の保護は、常に車の両輪として進められなければなりません。
- 「公平な目」を持つAIを育てる(モデルのバイアスとその影響の低減): AIは、まるで子供が親から学ぶように、学習に使われたデータから物事を判断するパターンを学び取ります。もし、その学習データに、特定の性別、人種、年齢層、居住地域、あるいは社会経済的背景などに関する何らかの偏り(バイアス)が含まれていれば、AIもまたその偏見を無邪気に学習してしまい、結果として特定のグループに対して不利益となるような、不公平な診断や治療の推奨をしてしまう危険性があります。例えば、ある疾患が特定の人種に多いという過去のデータだけでAIを学習させてしまうと、それ以外の人種で発生した同じ疾患の初期症状を見逃しやすくなるかもしれません。Attentionの可視化は、時としてこうしたモデル内部のバイアスの存在を示唆してくれることもありますが、根本的な解決のためには、開発の初期段階からデータの多様性に最大限配慮し、質の高いバイアスの少ないデータを注意深く収集・整備すること、そしてモデルの性能評価においても公平性の観点からの検証を怠らないことが、何よりも重要です。
- AIの「思考プロセス」を説明できるか(解釈性と説明責任の確立): 特に人の命や健康に直接関わる医療の現場では、「AIがこう判断しました」という結果だけでは、多くの医師や患者さんは納得できませんし、安心してその判断を受け入れることも難しいでしょう。なぜAIがそのような結論に至ったのか、その判断の根拠やプロセスを、人間が理解できる形で説明できる能力(解釈性または説明可能性と言います)が、医療AIには強く求められます。Attentionの可視化は、その「なぜ?」に答えるための一助となりますが、それだけでAIの複雑な判断プロセス全てを完全に説明できるわけではありません。AIの判断プロセスをより透明化し、万が一、AIの判断によって不利益が生じた場合に、その責任の所在をどのように考えるのか(説明責任)といった点についても、社会全体での深い議論とルール作りを進めていく必要があります。
- あくまで「賢い道具」として使いこなす(過信と誤用の防止): どんなに優れたAIが登場したとしても、それは万能の魔法の杖ではありません。AIによる診断支援や治療提案は、医療従事者にとって非常に強力な「ツール」となり得ますが、その結果を鵜呑みにしたり、過度に依存したりするのではなく、あくまで最終的な診断や治療方針の決定は、十分な知識と経験、そして倫理観を持った医療専門家が、AIからの情報も参考にしつつ、総合的に判断を下すという姿勢が不可欠です。AIの強みと限界を正しく理解し、人間の医師とAIが互いの能力を最大限に活かし合うような「協調」と「共進化」の関係こそが、私たちが目指すべき姿ではないでしょうか。
これらの課題は決して簡単なものではありませんが、技術を開発する側の私たち研究者やエンジニア、実際にAIを医療現場で活用する医療専門家の皆さん、倫理や法律の専門家、そして何よりも社会全体が密接に連携し、それぞれの立場から知恵を出し合い、建設的な対話を重ねていくことで、きっと一つ一つ乗り越えていけると信じています。Attentionという素晴らしい技術の恩恵を、全ての人が安全にかつ公平に享受できるような未来を目指して、私たち自身も常に学び、考え続ける姿勢が求められていますね。
7. まとめと今後の展望:Attentionの旅、そして次なるステージへ
さて、今回の「22.3 Attentionは「何を見ているのか?」を読み解く」という旅も、いよいよ終着点が見えてきました。Transformerモデルのまさに「心臓部」とも言えるAttention機構、特にSelf-Attentionの奥深い世界を、皆さんと一緒に探検できたことを大変嬉しく思います。
今回の冒険を振り返ってみましょう。まず、まるで名探偵の助手のように働くQuery (Q)、Key (K)、Value (V) という3つの重要なベクトルたちが、どのようにして情報をやり取りし、関連性を見つけ出すのか、その基本的な役割と仕組みを学びましたね。次に、これらのベクトルを使って、AIが「どの情報にどれだけ注目すべきか」というAttentionスコアを計算する具体的なステップ(内積計算、スケーリング、Softmax関数による正規化、そしてValueとの加重和)を、数式も交えながら丁寧に追いかけました。さらに、AIの「頭の中」、つまりAttentionの重みをヒートマップとして可視化することで、モデルの判断根拠を探る方法を体験し、最後に、AIに「未来の情報をカンニングさせない」ための巧妙な仕掛けであるCausal Maskの重要性についても理解を深めました。
これらの知識の一つ一つが、Transformerベースの生成AI、例えば大規模言語モデル(LLM)などが、どうしてあんなにも自然な文章を生成したり、複雑な質問に的確に答えたり、あるいは膨大な医療文献から重要な知見を抽出したりできるのか、その魔法のような能力の秘密を解き明かすための、大切な鍵となるはずです。特に、医療の現場でAIの力を活用したい、あるいはご自身の研究でAIを用いた新しい応用を切り拓きたいと考えていらっしゃる皆さんにとって、このAttention機構の理解は、AIの挙動を深く洞察し、その可能性と限界を見極め、そして最終的にはご自身の手でAIを「使いこなし」、さらには「創り出す」ための、確かな土台となることを心から願っています。
Attention機構は、入力されたデータの中から「今、この瞬間に、どこに注目すべきか」を動的かつ柔軟に学習する、本当にパワフルなメカニズムです。しかし、物語はここで終わりではありません。実は、Attentionが集めてきた「宝物のような情報」、つまり文脈を豊かに含んだ各トークンの表現も、それだけでは最終的なタスク(例えば、病名を分類する、治療効果を予測する、あるいは患者さんへの説明文を自動生成するなど)を完璧にこなすためには、もうひと手間、力強い仲間によるさらなる「磨き上げ」が必要になることが多いのです。
Attentionによって選び抜かれ、周囲の重要な情報が適切に重み付けされた各トークンの表現。これらを、今度は一つ一つ個別に、より深く、そしてより抽象的なレベルで処理し、最終的なタスク解決に本当に役立つ特徴へと変換していく役割を担うのが、次回(22.4 FFNはなぜ必要か?意味の深化を担う非線形変換の役割)で詳しく解説するFFN(Feed-Forward Network)、日本語では順伝播型ニューラルネットワークと呼ばれるコンポーネントです。
ここで、本講座22.3で学んだAttention機構が、Transformer全体の情報処理の流れの中でどのような位置づけにあり、次に学ぶFFNとどう繋がっていくのか、簡単な図でイメージを共有しておきましょう。
flowchart TD
A["入力情報
(例: 患者さんのカルテテキスト)"] --> B["1. トークン化・単語埋め込み
(Positional Encodingも含む)"];
B --> C["2. 各トークンの初期ベクトル表現"];
subgraph sg1["本講座 22.3 の主要テーマ"]
C --> SA["Attention機構 (Self-Attention)
- Query, Key, Value の生成
- Attentionスコアの計算 (QK^T, スケーリング, Softmax)
- Causal Mask (必要な場合)"];
SA --> Z_out["文脈を考慮したトークン表現
(Attentionの出力Z)"];
end
subgraph sg2["次回の講座 22.4 のテーマ"]
Z_out --> FFN["FFN (Feed-Forward Network)
- 各トークン表現を個別により深く処理 (非線形変換)"];
FFN --> Refined_Z["さらに洗練されたトークン表現"];
end
Refined_Z --> Loop_Desc["(残差接続や正規化を経て、
これらのブロックが何層も繰り返される)"];
Loop_Desc --> Output["最終的な出力
(例: 診断候補、テキスト生成、リスクスコアなど)"];
テキストベースの図
【Transformer内部の情報処理フロー(AttentionとFFNの連携イメージ)】
[入力情報 (例: 患者さんのカルテテキスト)]
↓
[1. トークン化・単語埋め込み (Positional Encodingも含む)]
↓
[2. 各トークンの初期ベクトル表現]
│
┝━━ (本講座 22.3 の主要テーマ) ━━━
│ ↓
│ [Attention機構 (Self-Attention)]
│ │ - Query, Key, Value の生成
│ │ - Attentionスコアの計算 (QK^T, スケーリング, Softmax)
│ │ - Causal Mask (必要な場合)
│ ↓
│ [文脈を考慮したトークン表現 (Attentionの出力Z)]
│
┝━━ (次回の講座 22.4 のテーマ) ━━
│ ↓
│ [FFN (Feed-Forward Network)]
│ │ - 各トークン表現を個別により深く処理 (非線形変換)
│ ↓
│ [さらに洗練されたトークン表現]
│
↓ (残差接続や正規化を経て、これらのブロックが何層も繰り返される)
↓
[最終的な出力 (例: 診断候補、テキスト生成、リスクスコアなど)]
この図のように、Attentionが「文脈の中で、どの情報が特に重要か」を見つけ出し、それに基づいて情報を集約する役割(いわば、情報の「どこに注目するか」を決める役割)を担うのに対し、FFNはその集約された情報を各トークンごとに、より深く掘り下げて分析・変換する役割(いわば、「注目して得た情報をどう解釈し、意味を深めるか」を担う役割)を果たします。この二つは、まるで優れた探偵(Attention)と、その探偵が集めてきた証拠を元に鋭い分析を加えるプロファイラー(FFN)のような、強力なタッグを組んでいるのです。次回は、このFFNがどのようにして「意味の深化」を実現しているのか、その秘密に迫りますので、どうぞご期待ください!
最後に、医療AIの未来に目を向けてみましょう。Attention機構は、その誕生以来、驚くべき速さで進化を続けています。より少ない計算資源で、より長い医療記録やゲノム配列といった系列データを扱えるように改良された効率的なAttentionの亜種(例えば、LongformerやReformerといったモデルは、本コースの最終回22.7で少し触れるかもしれません)が次々と提案されています。また、Attentionの重みが本当にモデルの「解釈」として信頼できるのか、その意味するところをより深く探求する研究も活発に行われています。
これらの技術的進歩は、より複雑で多様な医療データ(テキスト、画像、センサーデータ、遺伝情報など)を統合的に解析し、個々の患者さんに最適化された「オーダーメイド医療(個別化医療)」の精度を飛躍的に高めたり、これまで人間の目では見過ごされてきた微細な病気の兆候や、新しい治療法・診断マーカーの手がかりを発見したり…。そんな、今日ではまだ夢物語に聞こえるかもしれない未来の医療を現実のものとするための、強力なエンジンとして、Attention機構は今後ますますその重要性を増していくことでしょう。
本日の「Attentionは「何を見ているのか?」を読み解く」という内容が、皆さんの知的好奇心を少しでも刺激し、AIという強力なツール、そしてその奥にある美しい原理への理解を深める一助となれば、これに勝る喜びはありません。Attentionの世界の探求に最後までお付き合いいただき、本当にありがとうございました!
8. 参考文献
- Choi E, Bahadori MT, Kulas JA, Schuetz A, Stewart WF, Sun J. RETAIN: An interpretable predictive model for healthcare using reverse time attention mechanism. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc.; 2016. p. 3512–3520.
- Sha Y, Wang MD. Interpretable deep learning for healthcare: A comparative study of attention mechanisms. Artif Intell Med. 2021;117:102099.
- Beltagy I, Lo K, Cohan A. SciBERT: A pretrained language model for scientific text. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics; 2019. p. 3615–3620.
- Karpov P, Godin G, Tetko IV. Transformer-CPI: improving compound–protein interaction prediction by sequence-based deep learning with attention mechanism. J Cheminform. 2020;12(1):15.
- Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16×16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations (ICLR) 2021. Available from: https://openreview.net/forum?id=YicbFdNTTy
- Ji Y, Zhou Z, Liu H, Davuluri RV. DNABERT: pre-trained Bidirectional Encoder Representations from Transformers model for DNA-language in genome. Bioinformatics. 2021;37(15):2112–2120.
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc.; 2017. p. 6000–6010.
- Lee J, Yoon W, Kim S, Kim D, Kim S, So CH, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020;36(4):1234–1240.
- Rasmy L, Xiang Y, Xie Z, Tao C, Zhi D. Med-BERT: pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction. NPJ Digit Med. 2021;4(1):86.
- Alsentzer E, Murphy JR, Boag W, Weng WH, Jindi D, Naumann T, et al. Publicly available clinical BERT embeddings. In: Proceedings of the 2nd Clinical Natural Language Processing Workshop. Minneapolis, Minnesota, USA: Association for Computational Linguistics; 2019. p. 72–78.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




