

TL; DR (要約)
AIに「時間」や「順序」の概念を教える系列モデルのまとめです。
心電図の波形やカルテの文章など、流れを持つデータを分析する技術の核心を掴みましょう。
RNN 【基本の記憶モデル】
過去の情報を次のステップに伝えるループ構造が特徴。ただし、遠い過去の記憶は薄れがちです(短期記憶は得意)。
LSTM 【賢い高機能モデル】
「忘却・入力・出力」の3つのゲートで情報を取捨選択。必要な情報を忘れず、長期記憶を可能にします。
GRU 【効率的な改良モデル】
LSTMを簡略化し、計算効率と性能のバランスを両立。LSTMの優秀な弟分のような存在です。
医療AIでの応用例
📈 時系列解析
心電図(ECG)の波形から不整脈の兆候を検出し、ICUのバイタルサインから患者の急変を予測します。
📄 自然言語処理 (NLP)
電子カルテの文章から「症状」や「薬剤名」を自動で抽出し、データを研究に活用しやすくします。
はじめに:過去を記憶し、未来を予測するAI
皆さん、こんにちは!「応用モデルと実践トレーニング」編へようこそ。
前回の講義では、CNNという強力な武器を手に入れ、画像の「空間」的なパターンを読み解く方法を学びましたね。しかし、私たちが日々向き合う医療データには、もう一つ、決して無視できない重要な軸が存在します。それが、「時間」です。
例えば、数秒間にわたる心電図の波形、数日間のバイタルサインの推移、あるいは電子カルテに綴られた診察の記録…。これらは全て、記録された「順序」そのものに決定的な意味がある、系列データ(Sequence Data)です。静的な一点の情報ではなく、「流れ」の中で初めて意味をなすデータと言えるでしょう。
ここで、これまで学んできたMLPやCNNの限界が見えてきます。これらのモデルは、入力されたデータをそれぞれ独立した「一点もの」として扱います。そのため、例えば一枚のX線写真から肺炎のパターンを見つけるのは得意でも、「数時間前のバイタルサインの悪化を踏まえて、現在の状態を評価する」といった、過去の情報を「記憶」しながら、現在のデータを解釈することが、構造的にできないのです。
例えるなら、彼らは非常に優秀だけれど、「記憶力が10秒しかもたない名探偵」のようなものです。目の前の証拠(現在の入力)から鋭い推論はできても、数分前に聞いた証言(過去の入力)を忘れてしまうため、時間的な繋がりが重要な謎は解けません。
この「時間」という概念をAIに教え、過去を記憶しながら未来を予測させるために生まれたのが、再帰型ニューラルネットワーク(Recurrent Neural Network, RNN)です。RNNは、ネットワークの内部に情報を「記憶」し続けるための特殊なループ構造を持っており、時々刻々と変化するデータを処理することに特化しています。
この記事では、この系列データ分析の世界への第一歩として、その基礎から、RNN、そしてその弱点を克服した発展形であるLSTMやGRUの核心的なアイデア、さらに医療分野での具体的な応用例まで、その全体像をダイジェスト形式で一気に探求していきます。なお、それぞれのモデルのより詳細な理論や、PyTorchを用いた具体的な実装については、今後の個別記事(15.1〜15.9)でじっくりと掘り下げていく予定です。今回はまず、この新しいAIの「考え方」に触れ、その可能性を感じていただくことを目標にしましょう!
15.1 系列データの基礎とPyTorchでの準備 〜「時間」と「順序」を、AIの言葉に翻訳する〜
さて、系列モデルの世界に飛び込む前に、まずはその主役である系列データ(Sequence Data)とは、一体どんなものなのか、その正体を見極めましょう。系列データとは、その名の通り、要素の「順序」が決定的に重要な意味を持つデータのことです。データの並びをシャッフルしてしまうと、全く意味が変わってしまう、あるいは意味をなさなくなってしまう。それが系列データの特徴です。
医療分野には、こうした系列データが溢れています。
| データの種類 | 具体例 | 特徴 |
|---|---|---|
| 時系列データ | 心電図(ECG)、脳波(EEG)、連続血糖モニタ(CGM)の波形、ICUでの1時間ごとのバイタルサイン記録など | 時間の経過と共に、連続的な数値が記録される。 |
| 自然言語データ | 電子カルテの自由記述、看護サマリー、医学論文、患者さんとのチャット履歴など | 単語や文字が、特定の文法や意味構造に従って並んでいる。 |
埋め込み(Embedding)とは? 〜単語を「意味のある住所」にマッピングする〜
では、こうした系列データを、AIモデルはどうやって「入力」として受け取るのでしょうか?「10時、心拍数80」という情報や、「糖尿病」という単語を、そのままニューラルネットワークに入れることはできません。AIが理解できるのは、あくまで数値、特にベクトルの集まりだけです。
この、カテゴリカルな情報(単語など)や、系列の各時点の要素を、密な数値ベクトルに変換するプロセスが、埋め込み(Embedding)と呼ばれる、非常に重要な前処理です。
埋め込みは、各単語に、その意味や文脈的な役割を反映した、多次元空間上の「住所」を割り当てる作業に似ています。
- 例えば、「アスピリン」と「イブプロフェン」は、どちらも「解熱鎮痛薬」という似た役割を持つので、この空間上では非常に「近い」住所が割り当てられます。
- 一方で、「アスピリン」と「心電図」は、全く異なる概念なので、「遠い」住所が割り当てられるでしょう。
単語の埋め込み(Word Embedding)の概念図
PyTorchでは、nn.Embeddingという層がこの役割を担います。事前に、データセットに出てくる全ての単語で「辞書」を作っておき、各単語にユニークなIDを割り振ります。そして、nn.Embedding層に単語のIDを入力すると、対応する学習済みのベクトルを出力してくれる、という非常に便利な仕組みです。このベクトルの値自体も、モデルの学習を通じて、より良い表現へと最適化されていきます。
このようにして、様々な系列データを、ニューラルネットワークが処理できる「ベクトルの系列」という統一された形式に変換する。これが、系列データ分析における、最も重要で、そして最初のステップなのです。
15.2 再帰型ニューラルネットワーク(RNN)の理論 —「記憶」を持つネットワーク
系列データを扱う上で、「過去の情報をどうやって記憶するか」が鍵だというお話をしました。この課題を、非常に独創的な構造で解決したのが、再帰型ニューラルネットワーク(Recurrent Neural Network, RNN)です。
RNNの最大の特徴は、その名の通り、ネットワークの計算結果が、再び自分自身への入力として「再帰(Recurrent)」する、つまりループ構造を持つ点にあります。このループこそが、AIに「短期記憶」を与える魔法の仕組みなんです。
隠れ状態 (Hidden State) 〜RNNの「ワーキングメモリ」〜
このRNNの「記憶」の正体は、隠れ状態(Hidden State)、\(h_t\) と呼ばれるベクトルです。これは、ある時点 \(t\) までの系列の情報を要約した「ワーキングメモリ」のようなものだと考えてください。
これは、医師が患者さんの長い経過カルテを読み進めるのに似ています。医師は、カルテの最初から読み進め、頭の中で「ふむふむ、3日前に熱が出て、2日前に解熱剤を使い、昨日はCRPが少し下がったな…」と、重要な情報を要約しながら、常に記憶を更新していきますよね。この、ある時点までの「要約された記憶」こそが、隠れ状態 \(h_t\) なのです。
RNNセルと呼ばれる計算ブロックは、以下の2つの情報を受け取って、新しい記憶である現在の隠れ状態 \(h_t\) を作り出します。
- 現在の入力 \(x_t\) (例: 今日のバイタルサイン)
- 一つ前の時点の記憶 \(h_{t-1}\) (例: 昨日までの経過サマリー)
この計算は、数式で書くと以下のようになります。
\[ h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b_h) \]
- \(h_t\): 新しい記憶(現在の隠れ状態)
- \(x_t\): 現在の入力
- \(h_{t-1}\): 一つ前の記憶
- \(W_{hh}\): 過去の記憶に掛ける重み(記憶をどれだけ重視するか)
- \(W_{xh}\): 現在の入力に掛ける重み(今の入力をどれだけ重視するか)
- \(b_h\): バイアス項
- \(\tanh\): 活性化関数(計算結果を-1から1の間に収める)
この同じ計算(同じ重み \(W_{hh}\) と \(W_{xh}\))が、系列の各時点で繰り返し使われることで、情報が次々と伝播していくのです。
RNNの構造(時間展開したイメージ)
シンプルなRNNの限界:遠い過去の「勾配消失」
このシンプルなRNNの構造は非常にエレガントですが、一つ大きな弱点を抱えていました。それは、逆伝播で勾配を計算する際に、何度も同じ重み行列 \(W_{hh}\) が掛け合わされるため、系列が長くなると(つまり、遠い過去に遡るほど)、勾配が指数関数的に小さくなる(または大きくなる)、勾配消失・爆発問題が非常に起こりやすいのです。
結果として、シンプルなRNNは、直前の数ステップの記憶は保持できても、何十、何百ステップも前の「遠い過去」の情報を、うまく現在の判断に活かすことができませんでした。いわば、「長期記憶」が苦手だったわけですね。
この、RNNの「長期記憶障害」を克服するために、より洗練された「記憶のゲート」を持つ、LSTMやGRUといったモデルが考案されることになります。
15.5 & 15.8 LSTMとGRU —「賢い記憶」を実現するゲート機構 〜情報の取捨選択を学ぶ、洗練された記憶システム〜
さて、シンプルなRNNは、過去の情報を次の時点に伝える「記憶」の仕組みを持っていましたが、遠い過去の情報は、伝言ゲームのように、どんどん薄れていってしまう(勾配消失)という大きな弱点がありました。これでは、「長期記憶」が苦手な、少し物覚えの悪いAIになってしまいます。
このRNNの「長期記憶障害」を、非常に独創的なアイデアで克服したのが、LSTM (Long Short-Term Memory) なんです(1)。その名の通り、短期記憶だけでなく、長期的な記憶も扱えるように設計されています。
LSTMの核心:2つの「記憶」と3つの「ゲート」
LSTMの仕組みは、優秀な秘書が行う、洗練された情報管理術に似ています。LSTMは、RNNが持っていた短期的な記憶(隠れ状態)に加えて、「細胞状態(Cell State)」という、もう一つの長期的な記憶の流れを持っています。
- 細胞状態 (\(c_t\)): 重要な情報を長期的に保持するための、いわば「メインの記憶ディスク」です。このディスク上の情報は、基本的にそのまま次の時点に引き継がれ、「情報の高速道路」のような役割を果たします。
- 隠れ状態 (\(h_t\)): その時点で実際に出力として使われる、いわば「ワーキングメモリ」や「作業用のメモ」です。
そして、この二つの記憶の流れを巧みにコントロールするのが、「ゲート(Gate)」と呼ばれる3人の賢い門番(秘書)です。彼らは、どの情報を長期記憶に加え、どの情報を忘れ、どの情報を短期記憶としてアウトプットするかを、学習を通じて判断します。
LSTMセルの概念図
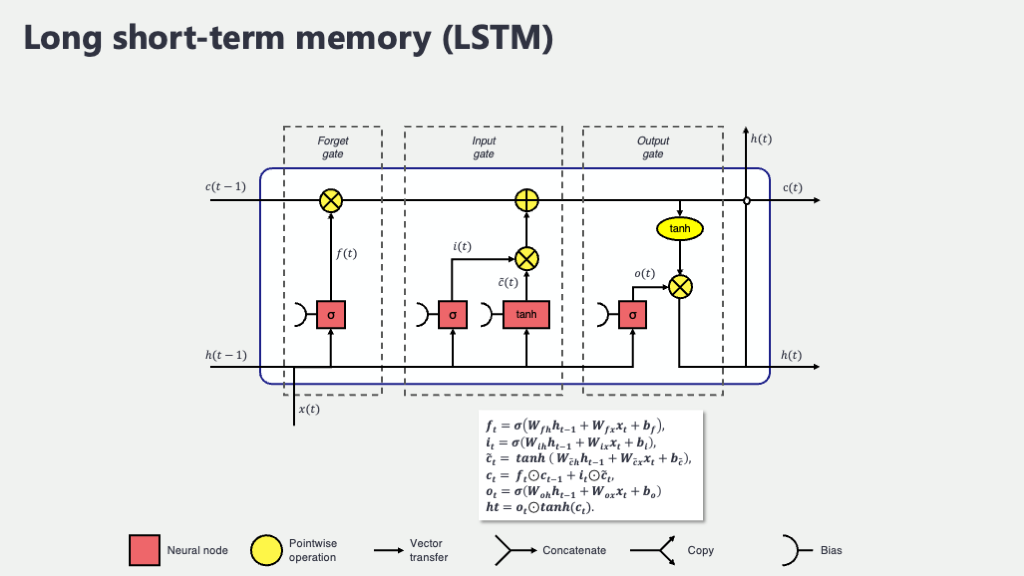
- 忘却ゲート (Forget Gate): 「この古い情報は、もう今の予測には関係ないから、メインの記憶ディスクから削除しましょう」と判断します。
- 入力ゲート (Input Gate): 「この新しい情報は、非常に重要なので、メインの記憶ディスクにしっかり書き込んでおきましょう」と判断します。
- 出力ゲート (Output Gate): 「今のタスクには、メインの記憶ディスクの中から、この部分の情報だけを取り出して、作業用のメモに書き写して使いましょう」と判断します。
この情報の取捨選択を行うゲート機構のおかげで、LSTMは勾配消失問題を回避し、長期的な依存関係を学習できるようになったのです。
直感的なイメージ
GRU (Gated Recurrent Unit):「記憶」と「出力」を統合した効率的な弟分
LSTMは非常に強力ですが、その分、構造が複雑で計算コストも高めです。そこで、LSTMの基本的な考え方を継承しつつ、構造を少しシンプルにしたのがGRU (Gated Recurrent Unit) です(2)。
GRUは、LSTMが持っていた「細胞状態」と「隠れ状態」を、一つの「隠れ状態」に統合し、ゲートの数も2つ(更新ゲートとリセットゲート)に減らしています。いわば、より効率的に働くように最適化された、LSTMの「弟分」のような存在ですね。多くの場合、LSTMと同等の性能を、より少ない計算コストで実現できるため、こちらも非常に人気があります。
幸い、PyTorchでは、これらの内部構造が複雑なモデルも、RNNとほとんど同じように、ライブラリから一行で呼び出すことができます。本当に便利ですよね。
# 必要なライブラリをインポート
import torch.nn as nn
# --- パラメータの解説 ---
# input_size: 各時点での入力ベクトルの次元数
# hidden_size: 隠れ状態(記憶)ベクトルの次元数
# batch_first=True: テンソルの最初の次元をバッチサイズにする、というお決まりの設定
# シンプルなRNN
rnn = nn.RNN(input_size=10, hidden_size=20, batch_first=True)
# LSTM
lstm = nn.LSTM(input_size=10, hidden_size=20, batch_first=True)
# GRU
gru = nn.GRU(input_size=10, hidden_size=20, batch_first=True)
このゲート付きRNN(LSTMやGRU)の登場により、AIは、文章中の遠く離れた単語の関連性や、時系列データの長期的なトレンドといった、複雑な時間的依存関係を、ようやく効果的に学習できるようになったのです。
15.3, 15.4, 15.6, 15.7 医療AIでの応用:時系列解析と自然言語処理への扉
さて、RNNやLSTMといった、系列データを扱うための強力なツールを手に入れたところで、いよいよ、これらが実際の医療現場でどのように活躍しているのか、その応用例を見ていきましょう。系列モデルは、大きく分けて「医療時系列データ」と「医療自然言語処理」という、二つの領域でその真価を発揮します。
医療時系列データ編:波形や数値の「流れ」から未来を読む
私たちの体は、時々刻々と変化する情報の宝庫です。心電図の微細な揺らぎ、ICUでのバイタルサインの連続的な変化…。系列モデルは、これらの数値の「流れ」そのものから、人間の目では捉えきれない複雑なパターンを学習し、未来のリスクを予測したり、異常を検知したりすることを得意とします。
時系列データ解析のイメージ(心電図からの異常検知)
- 不整脈や心疾患の早期発見 心電図(ECG)の長い波形データを入力として、致死性不整脈に繋がりかねない危険なパターンや、心不全の兆候などを自動で検出します。これは、24時間ホルター心電図の解析を自動化・高度化する上で、大きな力となります。
- ICUにおける急変イベント予測 呼吸数、心拍数、血圧、SpO2といった、多変量のバイタルサインの数時間〜数日間の推移を学習し、「数時間後に敗血症性ショックを発症するリスク」を予測します。これにより、医療スタッフはより早期の介入が可能になるかもしれません(3)。
- 血糖値の変動予測 連続血糖モニタリング(CGM)のデータを元に、数十分後、数時間後の血糖値を予測し、低血糖や高血糖のリスクを患者さんに事前に通知するような、個別化医療への応用も期待されています。
医療自然言語処理(NLP)編:カルテの「物語」をAIが読み解く
もう一つの大きな応用分野が、電子カルテの自由記述や看護記録、医学論文といった、膨大なテキストデータ、すなわち「言葉の系列」を扱う医療自然言語処理です。
自然言語処理のイメージ(カルテからの情報抽出)
- 情報の構造化(系列ラベリング) 医師が記載した自由診療録の中から、「疾患名」「薬剤名」「症状」といった重要な情報をAIが自動で抽出し、タグ付け(ラベリング)します。これにより、非構造化データであるテキストを、後でデータベースとして解析可能な構造化データへと変換できます。これを系列ラベリングや固有表現抽出(Named Entity Recognition, NER)と呼びます。
- サマリーの自動生成 長い入院経過や、大量の論文をAIが読み込み、その要点を数行にまとめたサマリーを自動生成します。これにより、医師や研究者は、情報収集の時間を大幅に短縮できます。
- 文章生成(カルテ草稿など) 診察時の医師と患者の会話を音声認識し、その内容を元に、AIがカルテの所見欄の「草稿」を自動で生成する、といった応用も研究されています。
このように、系列モデルは、医療現場に存在する多様な「流れを持つデータ」に対して、非常に強力な分析手段を提供してくれます。皆さんの研究や日常業務の中でも、「これは系列データとして扱えるかもしれない」と考えてみると、新しいAI活用のアイデアが生まれてくるかもしれませんね。
まとめと次のステップへ
今回は、AIに「時間」の概念を教えるための系列モデルの世界を概観しました。
- 医療現場には、心電図やカルテなど、順序が重要な系列データが溢れていること。
- RNNは、ループ構造によって過去の情報を記憶する仕組みを持つこと。
- LSTMやGRUは、ゲート機構によって、長期的な依存関係をより賢く学習できること。
これらのモデルは、時系列解析や自然言語処理といった、医療AIの重要な領域で活躍する基盤技術です。
さて、MLP、CNN、RNN/LSTMと、様々な強力なアーキテクチャを学んできました。しかし、モデルが複雑になればなるほど、常に私たちを悩ませる問題があります。それが「過学習」です。
次回の第16回では、この過学習をいかにして検出し、対策を講じるかという、極めて実践的なテーマに改めて深く向き合います。
参考文献
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9(8):1735-1780.
- Cho K, van Merrienboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. 2014. p. 1724-1734.
- Rajkomar A, Oren E, Chen K, et al. Scalable and accurate deep learning with electronic health records. NPJ Digit Med. 2018;1:18.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




