

TL; DR (要約)
AI開発は料理と同じ。良い食材(データ)を正しく下ごしらえし、レシピ通りに調理し、最後に味見(評価)する。
この総合演習では、心疾患予測をテーマに、AI開発のフルコースレシピを最初から最後まで体験します。
① データの下ごしらえ
(EDA & Preprocessing)
pandasでデータを観察し、欠損値を処理。scikit-learnで学習・検証・テスト用に公正に分割し、特徴量をスケーリングします。
② モデルの調理
(Design & Training)
PyTorchでモデル構造を設計し、データをDataLoaderで効率的に供給。訓練と検証のサイクルを回し、モデルを学習させます。
③ 最終的な味見
(Evaluation)
学習曲線で過学習をチェックし、未知のテストデータで最終性能を評価。混同行列やROC曲線で多角的に分析します。
この章の学習目標と前提知識
はじめに:点と線が繋がり、一つの「プロジェクト」になる日
皆さん、こんにちは!ここまで12回の講義、本当にお疲れ様でした。もし、この講座が料理教室だとしたら、皆さんは今、包丁の使い方(Pythonの基本)をマスターし、新鮮な食材の選び方(データ構造)を知り、火加減の調整(制御構文)を覚え、さらには調理器具一式(関数やクラス)まで手に入れた状態です。素晴らしいですよね。
しかし、これらの素晴らしい道具や知識も、まだ皆さんの厨房の棚に、一つ一つバラバラの状態で置かれているかもしれません。
そこで今回は、いよいよ集大成です。これまで学んだ全ての知識とスキルを総動員して、前菜(データの準備)からメインディッシュ(モデルの訓練)、そしてデザート(性能評価)まで、一つのフルコース料理(AI開発プロジェクト)を、最初から最後まで一気通貫で作り上げてみる、初めての総合演習に挑戦します。
本日挑戦するお題(レシピ)は、「いくつかの臨床検査値から、その人が心疾患を持つかどうかを予測する」という、非常に実践的で重要な二値分類問題です。この演習を通じて、これまで学んだ点と点が繋がり、一つの線、そして一つの意味のある「プロジェクト」として形になる、あの「アハ!」体験を、ぜひ皆さんに味わっていただきたいと思います。
この講義で私たちが辿るステップは、まさに医療AI開発の「王道のレシピ」そのものです。
- ステップ1:データの準備と理解 (まずは「患者さん」という食材を深く知ることから)
- ステップ2:データ前処理 (AIが食べやすいように食材を「下ごしらえ」する)
- ステップ3:訓練・検証・テスト用データの分割 (モデルを公正に評価するための「味見」の準備)
- ステップ4:モデルの設計と学習 (これまでの知識を結集して「メインディッシュ」を調理する)
- ステップ5:結果の評価 (完成した料理の「最終的な味」を客観的に評価する)
さあ、エプロンを締めて、手を洗いましょう。AI開発という、知的でエキサイティングな「厨房」での、初めての本格的な調理実習の始まりです!
1. データの準備と理解 (EDA: Exploratory Data Analysis) 〜まずは「患者さん(データ)」を深く知ることから〜
どんな名医も、患者さんを治療する前には、まず問診、視診、聴診、そして検査を通して、その人の状態を深く理解しようとしますよね。データ分析やAIモデル開発も、それと全く同じです。本格的な分析に入る前に、まずデータそのものを多角的に観察し、その「個性」や「健康状態」を把握するプロセスを、探索的データ分析(Exploratory Data Analysis, EDA)と呼びます。
今回は、その練習台として、機械学習の世界で古くから使われている、信頼性の高い「UCI心疾患データセット」の一部を利用してみましょう(1)。私たちの目標は、年齢や血圧といった13個の臨床特徴量から、心疾患の有無(targetが1なら有り、0なら無し)を予測するモデルを作ることです。
UCI心疾患データセットとは?
AIや機械学習を学び始めた人が最初に触れることの多い、定番の医療データです。カリフォルニア大学アーバイン校が提供する公開データで、特に「心疾患があるかどうか」を予測するために使われます。
このデータセットには、年齢や性別、血圧、コレステロール、胸痛の種類、運動時の異常の有無など、合計14の特徴量が含まれており、そこから「心疾患あり・なし(0 or 1)」を分類するのが目的です。サイズも手頃(約300人分)で、さまざまなタイプのデータ(数値・カテゴリ)が混ざっているため、データ前処理からモデル評価まで、一連の機械学習の流れを練習するには最適です。
ただし、注意点もあります。まずデータが古く(1988年収集)、現代の医療とは異なる部分があること。また、生データには列名がついておらず、欠損値も含まれているため、自分で整える必要があります。そして何より、これは特定の集団から得られたデータなので、他の患者集団にそのまま使うと精度が落ちることも。
それでもこのデータセットは、AIの勉強を始めるうえで、非常にわかりやすく、実践的な第一歩となってくれるでしょう。
さあ、最初の「問診」を始めましょう。
1.1 データの読み込みと最初の観察
まずは、このデータセットを私たちの「診察室」(Python環境)に招き入れ、カルテの最初のページを開いてみることにしましょう。ここでは、第1.7回で学んだPandasが早速大活躍します。
【実行前の準備】
以下のコードで日本語のグラフを表示させるには、あらかじめターミナルやコマンドプロンプトで pip install japanize-matplotlib を実行してライブラリをインストールしてください。
# --- 1. 必要なライブラリをインポート ---
# これから使う道具一式を、まず作業台の上に準備します。
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, roc_curve, auc
import matplotlib.pyplot as plt
import japanize_matplotlib # グラフの日本語文字化けを防ぐおまじない
# --- 2. データの読み込みと確認 ---
# データセットをURLから直接PandasのDataFrameとして読み込みます。
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data'
# このデータには元々カラム名(列名)が付いていないため、仕様書を元に手動で設定します。
column_names = ['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'thal', 'target']
# na_values='?' は、データの中にある'?'という文字列を「欠損値」として正しく認識させるための、重要なおまじないです。
df = pd.read_csv(url, header=None, names=column_names, na_values='?')
# --- 3. 簡単なデータ探索 (EDA) ---
print("--- データの最初の5行 ---")
# .head() は、データフレームの最初の数行を表示し、データの中身を素早く「つまみ食い」するのに非常に便利です。
print(df.head())
--- データの最初の5行 ---
age sex cp trestbps chol fbs restecg thalach exang oldpeak \
0 63.0 1.0 1.0 145.0 233.0 1.0 2.0 150.0 0.0 2.3
1 67.0 1.0 4.0 160.0 286.0 0.0 2.0 108.0 1.0 1.5
2 67.0 1.0 4.0 120.0 229.0 0.0 2.0 129.0 1.0 2.6
3 37.0 1.0 3.0 130.0 250.0 0.0 0.0 187.0 0.0 3.5
4 41.0 0.0 2.0 130.0 204.0 0.0 2.0 172.0 0.0 1.4
slope ca thal target
0 3.0 0.0 6.0 0
1 2.0 3.0 3.0 2
2 2.0 2.0 7.0 1
3 3.0 0.0 3.0 0
4 1.0 0.0 3.0 0 1.2 データの「健康診断」と前処理
データを読み込んだら、次にそのデータに抜け漏れ(欠損値)がないか、各項目がどんな種類のデータとして記録されているか、といった基本的な「健康診断」を行います。もし問題が見つかれば、AIが食べやすいように「調理(前処理)」してあげる必要があります。
# --- 3-1. データの基本情報を表示 (.info()) ---
print("\n--- データの基本情報 ---")
# .info()は、データフレームの「健康診断書」のようなものです。
# 各列のデータ型(Dtype)や、欠損していない値の数(Non-Null Count)などを一覧で表示してくれます。
df.info()
# --- 3-2. 欠損値の数を具体的に確認 ---
# .isnull().sum() を使うと、各列に欠損値が具体的に何個あるかを数えることができます。
print("\n--- 各列の欠損値の数 ---")
print(df.isnull().sum())
# --- 3-3. 欠損値の処理 ---
# info()とisnull().sum()の結果から、'ca'と'thal'に少数の欠損値があることが分かりました。
# AIモデルはデータに欠損があると計算ができないため、何らかの対処が必要です。
# 今回は簡単のため、これらの欠損値を含む行をまるごと削除します。
# 実際の大規模な研究では、データは非常に貴重なため、安易に削除するのではなく、
# 平均値や中央値で補完する(Imputation)といった、より慎重なアプローチが求められることも多いです。
df = df.dropna()
print("\n--- 欠損値処理後のデータ形状 ---")
# .shape で、データが (行数, 列数) のどんな形をしているか確認します。
print(df.shape)
# --- 3-4. ターゲット変数の変換 ---
# 私たちが予測したい「目的」であるtarget列を見てみます。
# 元のデータでは、targetが0(健康)と1,2,3,4(何らかの疾患あり)になっています。
# これを、0(健康)と1(疾患あり)の、シンプルな「二値分類問題」に変換しましょう。
# (df['target'] > 0) は、0より大きい値の箇所をTrue、そうでない箇所をFalseに変換します。
# さらに.astype(int)で、Trueを1に、Falseを0に変換しています。
df['target'] = (df['target'] > 0).astype(int)
print("\n--- 変換後のtarget列の値の種類と数 ---")
print(df['target'].value_counts())
# === info()の出力例 ===
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 303 entries, 0 to 302
# Data columns (total 14 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 age 303 non-null float64
# 1 sex 303 non-null float64
# ... (中略) ...
# 11 ca 299 non-null object <-- 欠損値あり(303-299=4) & 数値でない
# 12 thal 301 non-null object <-- 欠損値あり(303-301=2) & 数値でない
# 13 target 303 non-null int64
# dtypes: float64(5), int64(6), object(3)
# memory usage: 33.3+ KB
--- データの基本情報 ---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 303 entries, 0 to 302
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 303 non-null float64
1 sex 303 non-null float64
2 cp 303 non-null float64
3 trestbps 303 non-null float64
4 chol 303 non-null float64
5 fbs 303 non-null float64
6 restecg 303 non-null float64
7 thalach 303 non-null float64
8 exang 303 non-null float64
9 oldpeak 303 non-null float64
10 slope 303 non-null float64
11 ca 299 non-null float64
12 thal 301 non-null float64
13 target 303 non-null int64
dtypes: float64(13), int64(1)
memory usage: 33.3 KB
--- 各列の欠損値の数 ---
age 0
sex 0
cp 0
trestbps 0
chol 0
fbs 0
restecg 0
thalach 0
exang 0
oldpeak 0
slope 0
ca 4
thal 2
target 0
dtype: int64
--- 欠損値処理後のデータ形状 ---
(297, 14)
--- 変換後のtarget列の値の種類と数 ---
target
0 160
1 137
Name: count, dtype: int64
<ipython-input-3-3401568345>:29: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['target'] = (df['target'] > 0).astype(int)1.3 データの可視化 〜百聞は一見にしかず〜
最後に、データの中身をより直感的に理解するために、グラフを描いてみましょう。まずは患者さんの年齢分布から見てみます。ここではMatplotlibの出番ですね。
# --- 3-5. データの可視化 ---
print("\n--- 患者の年齢分布をヒストグラムで表示します ---")
# グラフを描画するための新しい「図」を用意します。figsizeでプロットエリアのサイズをインチ単位で指定できます。
plt.figure(figsize=(8, 5))
# patient_dfの'age'列のデータを使ってヒストグラムを作成します。
# binsは、データをいくつの区間(棒)に分けるかを指定します。
plt.hist(df['age'], bins=20, edgecolor='black', alpha=0.7)
# グラフにタイトルや軸ラベルを追加して、論文やレポートに使えるような、分かりやすい見た目にします。
plt.title('患者の年齢分布')
plt.xlabel('年齢 (歳)')
plt.ylabel('人数')
plt.grid(True, linestyle='--', alpha=0.6) # 見やすいようにグリッド線を追加
# これまでに設定した内容で、グラフを画面に表示します。
plt.show()
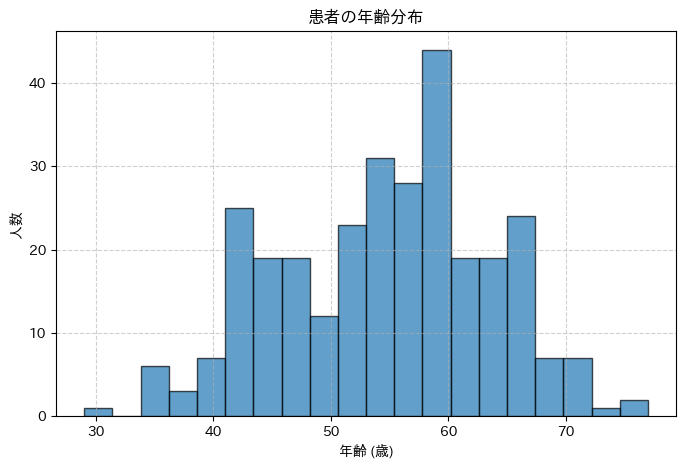
このコードを実行すると、横軸が年齢、縦軸が人数となるヒストグラム(棒グラフ)が表示されるはずです。これにより、「このデータセットには、どの年齢層の患者さんが多いのか」といった分布の偏りなどを一目で確認できます。こうした視覚的な確認は、データセットの特性を掴む上で非常に重要です。
いかがでしたでしょうか。このように、本格的なモデル構築に入る前に、まずはデータをじっくりと観察し、欠損値やデータ型を確認し、必要に応じて修正・変換し、そして可視化を通じてその全体像を掴む。この一連のEDAのプロセスが、信頼性の高いAIモデル開発の、揺るぎない土台となるのです。
2. データ前処理と分割 – AIが食べやすい形に調理し、公正に評価する準備
前のステップでデータの中身をじっくり観察し、その個性や健康状態を把握しましたね。さて、次はいよいよ、このデータをAIモデルが学習しやすいように「調理」する、前処理 (Preprocessing) のステップに進みます。生の食材をそのまま鍋に入れるのではなく、きちんと下ごしらえをするのと同じで、このひと手間が、後の学習の質を大きく左右するんですよ。
ここでは、特に重要な二つの「下ごしらえ」、つまりデータ分割と特徴量のスケーリングについて学んでいきます。
2.1 データ分割 – 公正な「実力テスト」の準備
AIモデルの性能を公正に評価するためには、絶対に守らなければならないルールがあります。それは、「モデルの学習に使ったデータで、そのモデルの最終的な性能を評価してはいけない」というものです。これは、答えを知っている問題で自分をテストするようなもので、本当の実力は測れませんよね。
そこで、私たちは手元にあるデータ全体を、目的の異なる3つのセットに分割します。これは、受験勉強のプロセスによく似ています。
データ分割の概念図
graph TD
%% --- ノードの定義 ---
all_data["全データセット (100%)"]
train_val_set["訓練・検証用 (80%)"]
test_set["テスト用 (20%)
(本番の試験)
(最後まで見ない)"]
train_set["訓練用 (64%)
(教科書)"]
validation_set["検証用 (16%)
(模擬試験)"]
%% --- 分岐処理を示すための透明ノード ---
split1("分割
(例: 80% / 20%)")
split2("分割
(例: 80% / 20%)")
%% --- ノード間の関係を定義 ---
all_data --> split1
split1 --> train_val_set
split1 --> test_set
train_val_set --> split2
split2 --> train_set
split2 --> validation_set
%% --- 分岐ノードのスタイルを透明に設定 ---
style split1 fill:none, stroke:none, color:#000
style split2 fill:none, stroke:none, color:#000
- 訓練用データ (Training Set): モデルが学習するために使う、いわば「教科書」や「問題集」です。モデルはこのデータを何度も見て、パターンを学びます。
- 検証用データ (Validation Set): 学習の途中で、モデルがどのくらい賢くなったかを確認するための「模擬試験」です。この模擬試験の結果を見て、私たちは「もう少し学習を続けるべきか?」とか「ハイパーパラメータ(学習の進め方の設定)を調整しようか?」といった判断を下します。
- テスト用データ (Test Set): 全ての学習と調整が終わった後、モデルの最終的な、そして真の実力を測るための「本番の入学試験」です。このデータは、モデルにとっては完全に初見の問題でなければならず、学習の過程では絶対に覗き見してはいけません。
2.2 特徴量のスケーリング – 全ての特徴量を「同じ土俵」に乗せる
次に、もう一つの重要な下ごしらえ、スケーリングです。私たちのデータには、「年齢」(29〜77)のように比較的範囲の狭い特徴量と、「血圧」(94〜200)や「コレステロール」(126〜564)のように範囲の広い特徴量が混在しています。もし、このままのスケールで学習を始めると、数値の範囲が大きい特徴量(例えばコレステロール)の勾配が、範囲の小さい特徴量(例えば年齢)の勾配よりも不当に大きくなってしまい、学習がうまく進まないことがあるんです。
例えるなら、色々な専門分野の委員がいる会議で、声の大きい人(スケールの大きい特徴量)の意見ばかりが通ってしまい、声は小さいけれど重要な意見(スケールの小さい特徴量)がかき消されてしまうようなものです。
そこで、全ての数値的な特徴量を、平均が0、標準偏差が1になるように変換して、同じ土俵で比べられるようにしてあげます。この手法を標準化 (Standardization) と呼びます。これにより、勾配降下法がよりスムーズに、そして効率的に最適解へと向かうことができるようになります。
【最重要ポイント】データのカンニング(リーク)を防ぐ
ここで非常に重要な注意点があります。この標準化に使う平均値と標準偏差は、必ず訓練用データからのみ計算します。そして、その計算された値を使って、訓練用、検証用、テスト用の全てのデータを変換します。もし検証用やテスト用のデータも含めて平均・標準偏差を計算してしまうと、それは「未来の模擬試験や本番試験の問題をこっそり覗き見る」という、データのカンニング(データリーケージ)になってしまい、モデルの性能を公正に評価できなくなってしまいます。
Pythonコード例:データの前処理と分割
では、これらのデータ分割とスケーリングを、Pythonのscikit-learnという、もう一つの非常に強力なライブラリを使って実践してみましょう。scikit-learnは、こうした機械学習の前処理を、数行のコードで簡単かつ安全に実行できるようにしてくれます。
# --- 1. 特徴量(X)とターゲット(y)に分割 ---
# 'target'列が私たちが予測したい対象(正解ラベル)なので、それをyとします。
# .values を付けることで、PandasのSeriesからNumPy配列に変換します。
y = df['target'].values
# 'target'列を削除(drop)した残りの全ての列が、予測に使う特徴量Xです。
X = df.drop('target', axis=1).values
# --- 2. 訓練用+検証用 と テスト用に分割 ---
# まず、データを訓練・検証用(80%)と、最終評価用のテスト用(20%)に分けます。
# test_size=0.2 は、全体の20%をテストデータに割り当てるという意味です。
# random_state=42 は、分割のランダム性を固定し、誰が実行しても同じ結果になるようにするためのおまじないです。
# stratify=y とすることで、元のデータの0と1の比率(クラスの比率)を保ったまま分割してくれます。不均衡データでは特に重要です。
X_train_val, X_test, y_train_val, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y)
# --- 3. 訓練用と検証用にさらに分割 ---
# 次に、先ほど分けた訓練・検証用データ(X_train_val)を、さらに訓練用と検証用に分けます。
# test_size=0.2 は、X_train_valの20%を検証用データに割り当てるという意味です (つまり、元データ全体の 80% * 20% = 16%分)。
X_train, X_val, y_train, y_val = train_test_split(
X_train_val, y_train_val, test_size=0.2, random_state=42, stratify=y_train_val)
# --- 4. 特徴量のスケーリング(標準化) ---
# scikit-learnから、標準化を行うためのスケーラーを準備します。
scaler = StandardScaler()
# 【重要】スケーラーは「訓練データ(X_train)のみ」を使ってフィットさせます。
# これにより、訓練データの平均値と標準偏差が計算され、スケーラー内部に記憶されます。
scaler.fit(X_train)
# フィットさせたスケーラーを使って、全てのデータを変換します。
# 訓練データだけでなく、検証データとテストデータも「同じ基準」で変換することが重要です。
X_train_scaled = scaler.transform(X_train)
X_val_scaled = scaler.transform(X_val)
X_test_scaled = scaler.transform(X_test)
# --- 5. 分割後のデータ形状を確認 ---
print("--- データ分割後の形状 ---")
print(f"訓練データ: {X_train_scaled.shape}")
print(f"検証データ: {X_val_scaled.shape}")
print(f"テストデータ: {X_test_scaled.shape}")
# === ここから下が上記のprint文による実際の出力の例 ===
# --- データ分割後の形状 ---
# 訓練データ: (193, 13)
# 検証データ: (49, 13)
# テストデータ: (60, 13)
--- データ分割後の形状 ---
訓練データ: (189, 13)
検証データ: (48, 13)
テストデータ: (60, 13)これで、私たちのデータは「訓練用」「検証用」「テスト用」に公正に分割され、かつ各特徴量が同じ土俵で評価されるようにスケーリングされました。最高の「下ごしらえ」が完了したと言えるでしょう!
3. PyTorchのパイプライン構築 (Dataset と DataLoader) 〜調理済みの食材を、学習の「ベルトコンベア」に乗せる〜
さて、データの下ごしらえが完了し、私たちの手元には、きれいにスケーリングされた訓練用、検証用、そしてテスト用のNumPy配列が準備できました。これでAIの「厨房」に、最高の食材が揃ったわけです。
しかし、この食材(データ配列)を、どうやって効率的に、そして学習に適した形でAIモデルという「調理場」に供給すれば良いのでしょうか?ここで、第11回で学んだ、PyTorchのデータ供給パイプライン、DatasetとDataLoaderのコンビがいよいよ本領を発揮します。彼らは、下ごしらえ済みの食材を、学習という名の「ベルトコンベア」に、適切な量(ミニバッチ)ずつ、適切なタイミングで乗せてくれる、非常に重要な役割を担っているんですよ。
Pythonコード例:カスタムDatasetとDataLoaderの作成
今回は、前処理済みのNumPy配列を扱うので、Datasetの定義は非常にシンプルになります。見ていきましょう。
# --- 1. カスタムDatasetクラスの定義 ---
# PyTorchが提供する `Dataset` クラスを継承して、
# 今回の心疾患データ専用の「データのカタログ」を設計します。
class HeartDiseaseDataset(Dataset):
# このクラスが作られる(インスタンス化される)際の初期設定を行います。
# ここでは、前処理済みの特徴量(features)とラベル(labels)をNumPy配列として受け取ります。
def __init__(self, features, labels):
# 受け取ったNumPy配列を、あらかじめPyTorchのテンソルに変換しておきます。
# こうすることで、後でデータを取り出す __getitem__ の処理が高速になります。
# 特徴量は浮動小数点数型(torch.float32)にするのが一般的です。
self.features = torch.tensor(features, dtype=torch.float32)
# 分類の正解ラベルは整数型(torch.long)にするのがPyTorchの標準的なお作法です。
self.labels = torch.tensor(labels, dtype=torch.long)
# このデータセットに含まれるデータの総数を返す、お決まりのメソッドです。
def __len__(self):
# 特徴量テンソルの最初の次元の大きさが、そのままデータ数になります。
return len(self.features)
# 指定された番号(idx)のデータを1つ取り出して返す、心臓部のメソッドです。
def __getitem__(self, idx):
# DataLoaderは、このメソッドを繰り返し呼び出してミニバッチを作成します。
# idx番目の特徴量と、それに対応するidx番目のラベルをペアで返します。
return self.features[idx], self.labels[idx]
# --- 2. 各データセットのインスタンスを作成 ---
# 上で定義した設計図(HeartDiseaseDataset)を使って、
# 訓練用、検証用、テスト用の3つのデータセットの実体を作ります。
train_dataset = HeartDiseaseDataset(X_train_scaled, y_train)
val_dataset = HeartDiseaseDataset(X_val_scaled, y_val)
test_dataset = HeartDiseaseDataset(X_test_scaled, y_test)
# --- 3. DataLoaderのインスタンスを作成 ---
# 次に、これらのデータセットからミニバッチを生成する「配送トラック」を用意します。
# バッチサイズを32に設定します。これは一度に32件のデータを処理することを意味します。
# この値は、利用するマシンのメモリに応じて調整が必要なハイパーパラメータです。
batch_size = 32
# 訓練データ用のDataLoaderを作成します。
# 訓練データは、学習の各サイクル(エポック)で異なる順番でモデルに見せることで、
# モデルがデータの順序を覚えてしまうのを防ぎ、般化性能を高める効果が期待できます。
# そのため、shuffle=True は非常に重要な設定です。
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 検証用とテスト用のDataLoaderも作成します。
# こちらは、毎回同じ条件でモデルの性能を評価したいため、シャッフルは行いません(shuffle=False)。
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# --- 4. 準備完了の確認 ---
print("\n--- DataLoaderの準備完了 ---")
# ミニバッチのサイズと、訓練データのバッチ数を表示してみましょう。
# バッチ数 = (訓練データの総数) / (バッチサイズ) で、切り上げた値になります。
print(f"ミニバッチのサイズ: {batch_size}")
print(f"訓練データのバッチ数: {len(train_loader)}")
# === ここから下が上記のprint文による実際の出力の例 ===
# --- DataLoaderの準備完了 ---
# ミニバッチのサイズ: 32
# 訓練データのバッチ数: 7
--- DataLoaderの準備完了 ---
ミニバッチのサイズ: 32
訓練データのバッチ数: 6どうでしょう?ほんの少しのコードで、私たちのNumPy配列データが、PyTorchの学習ループに投入できる、洗練されたデータパイプラインに姿を変えました。これで、モデルにデータを供給する準備は万端です。
食材の下ごしらえが終わり、ベルトコンベアにも乗りました。次はいよいよ、メインディッシュの調理、つまりAIモデルそのものを設計し、学習させていくステップに進みます!
4. モデルの設計と学習ループの実装 〜知識を結集し、AIの「脳」を育てる〜
いよいよ、この総合演習のクライマックスです。これまでに準備してきた全ての材料と道具(データ、DataLoaderなど)を使い、AIモデルという「メインディッシュ」を調理し、じっくりと時間をかけて「火入れ(学習)」をしていきます。ここが、AI開発で最もエキサイティングで、そして最も試行錯誤が求められる部分かもしれません。
4.1 モデルの設計 〜AIの「脳」のアーキテクチャを決める〜
まず、AIの脳みそとなるニューラルネットワークの構造(アーキテクチャ)を設計します。今回は、複数の層を重ねた多層ニューラルネット(Multi-Layer Perceptron, MLP)を使います。第1.6回で学んだnn.Moduleクラスを継承して、私たちだけのカスタムモデルHeartDiseasePredictorを定義しましょう。
今回設計するモデルの構造図
graph TD
A["[入力 (13特徴)]"]
B["Linear(13 -> 64)"]
C["ReLU"]
D["Dropout"]
E["Linear(64 -> 32)"]
F["ReLU"]
G["Linear(32 -> 2)"]
H["[出力 (2クラスのスコア)]"]
A --> B --> C --> D --> E --> F --> G --> H
Pythonコード例:モデルの定義
# --- 1. モデルの設計 (多層ニューラルネット) ---
# nn.ModuleというPyTorchの設計図を継承して、私たちだけのモデルクラスを作ります。
class HeartDiseasePredictor(nn.Module):
# (A) __init__メソッド: モデルで使う「部品(層)」をここで定義します。
def __init__(self, input_features):
# まずは、おまじないとして親クラスの__init__を呼び出します。
super(HeartDiseasePredictor, self).__init__()
# 3層のニューラルネットワークを定義します。
# nn.Linearは、線形変換(重みを掛けてバイアスを足す)を行う層です。
# 第1層: 入力特徴の数(input_features)を受け取り、64個のノードを持つ隠れ層に出力します。
self.layer1 = nn.Linear(input_features, 64)
# 第2層: 64個のノードを受け取り、32個のノードを持つ隠れ層に出力します。
self.layer2 = nn.Linear(64, 32)
# 第3層(出力層): 32個のノードを受け取り、最終的な2つのクラスのスコアを出力します。
self.layer3 = nn.Linear(32, 2)
# モデルで使う「機能」もここで定義しておきます。
# 活性化関数ReLU (第10回で学びました)
self.relu = nn.ReLU()
# 正則化のためのDropout (第10回で学びました)。20%のニューロンをランダムに無効化します。
self.dropout = nn.Dropout(p=0.2)
# (B) forwardメソッド: データがモデル内をどう流れるか(順伝播)を定義します。
def forward(self, x):
# 入力xが、定義した層を順番に通っていきます。
x = self.relu(self.layer1(x)) # layer1を通して、ReLUで活性化
x = self.dropout(x) # Dropoutを適用して過学習を防ぐ
x = self.relu(self.layer2(x)) # layer2を通して、ReLUで活性化
x = self.layer3(x) # 最後の出力層を通す
# 注: 最後の層の後には活性化関数(Softmaxなど)を入れません。
# なぜなら、後で使う損失関数 nn.CrossEntropyLoss が内部でSoftmaxの計算を含んでいるためです。
return x
4.2 学習の準備 〜損失関数と最適化手法の選択〜
モデルの設計図ができたら、次は「学習のルール」を決めていきます。具体的には、「間違いをどう測るか(損失関数)」と「どうやって賢く修正していくか(最適化手法)」の二つです。
Pythonコード例:学習のセットアップ
# --- 2. モデル、損失関数、オプティマイザの準備 ---
# モデルをインスタンス化します。入力特徴の数は、訓練データの列数(13)です。
# X_train_scaled.shape[1] で列数を取得できます。
model = HeartDiseasePredictor(input_features=X_train_scaled.shape[1])
# 損失関数を定義します。
# nn.CrossEntropyLossは、複数クラス分類問題で最も一般的に使われる損失関数です。
# モデルの出力(ロジット)と正解ラベルを受け取り、両者の「ズレ」を計算します。
criterion = nn.CrossEntropyLoss()
# 最適化アルゴリズムを定義します。
# Adamは、非常に性能が良く、多くの場面で安定した結果をもたらす人気の最適化手法です。
# model.parameters()で、モデル内の全ての学習可能な重みをAdamに渡します。
# lr=0.001 は学習率(learning rate)で、重みを一度にどれだけ更新するかのステップ幅です。
# weight_decay=1e-5 で、L2正則化を適用し、過学習を抑制します。
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5)
4.3 学習ループの実装 〜訓練と検証のサイクルを回す〜
いよいよ学習ループです。これは、AI開発の「真髄」とも言える部分。AIに「問題集(訓練データ)を解かせては、答え合わせをして反省させる」というサイクルを、何度も何度も繰り返します。この「問題集を1周すること」を1 エポック (epoch) と呼びます。
1エポックの中では、大きく分けて訓練フェーズと検証フェーズの二つを行います。
学習ループの概念図
AIの学習プロセスでは、「訓練用データはミニバッチで、検証用データはデータ全体で」と使い分けています。この違いがなぜ生まれるのか、それぞれの「目的」から考えると、とてもスッキリ理解できると思います。
アナロジーで理解する:教科書の「章末問題」と「模擬試験」
AIの学習を、ある一冊の分厚い「教科書」で勉強するプロセスだと想像してみてください。
訓練フェーズ:教科書を数ページずつ読み進める
訓練フェーズは、モデルが教科書(訓練データ)を読んで、知識を吸収する時間です。しかし、分厚い教科書を丸ごと一気に頭に入れるのは大変ですよね。
そこで、数ページずつ(ミニバッチ)区切って読み、「なるほど、ここはこうなっているのか」と少しずつ理解を深めて(パラメータを更新して)いきます。一気に全部読むより、少しずつ読み進めて、その都度理解度を更新していく方が、効率的に学習が進むからです。これが、訓練をミニバッチで行う理由です。
検証フェーズ:章末ごとの「実力テスト」
検証フェーズは、例えば教科書の一章分の勉強が終わった後に、その章末問題を解いてみる「実力テスト」のようなものです。
このテストの目的は、「今の自分の理解度を正確に測ること」ですよね。もし、テスト問題の中からランダムに数問だけ選んで解いていたら、たまたま簡単な問題ばかりだったり、逆に難しい問題ばかりだったりして、本当の実力は測れません。
全ての章末問題(検証データ全体)を毎回解くことで初めて、その時点での正確な理解度(モデルの性能)を、ブレなく、公正に評価できるのです。
実装上の補足:検証データも「バッチ処理」はするが…
ここで一つ、「おや?」と思うかもしれません。「検証用データも大きい場合、メモリに乗らないのでは?」と。その通りなんです!
そのため、実際のプログラムでは、検証フェーズでもデータローダーを使ってデータをバッチに分けてモデルに入力します。
しかし、訓練フェーズと決定的に違うのは、損失や正解率をバッチごとに計算し、それらを全て合計・平均して、最終的に検証データセット『全体』としてのスコアを算出する点です。パラメータの更新は、この全体のスコアが出るまで一切行いません(そもそも検証フェーズでは重みを更新しません)。
まとめ:目的による使い分け
この違いを表にまとめると、以下のようになります。
| フェーズ (Phase) | 目的 (Purpose) | データの使い方 (How Data is Used) | パラメータ更新 |
|---|---|---|---|
| 訓練 (Training) | モデルのパラメータを学習・更新させること | ミニバッチに分割し、1バッチごとにパラメータを更新 | 行う |
| 検証 (Validation) | 学習中のモデルの現在の性能を公正に評価すること | データセット全体で評価する(計算上はバッチ処理でも、最終スコアは全体で算出) | 行わない |
この「訓練は少しずつ、評価は全体で」という使い分けは、AIモデルを正しく育て、その実力を正確に測るための、非常に基本的なお作法なんですね。
Pythonコード例:学習ループ
# --- 3. 学習ループの実装 ---
# 学習を100サイクル(エポック)行います。
num_epochs = 100
# 各エポックでの損失と正解率の履歴を保存するためのリストを用意します。
# 後で学習曲線をプロットするのに使います。
train_losses, val_losses = [], []
train_accuracies, val_accuracies = [], []
print("\n--- 学習開始! ---")
# 指定したエポック数だけ、学習サイクルを繰り返します。
for epoch in range(num_epochs):
# --- 訓練フェーズ ---
model.train() # モデルを訓練モードに設定します。Dropoutなどが有効になります。
running_loss = 0.0
correct_train = 0
total_train = 0
# 訓練データローダーから、ミニバッチを一つずつ取り出して処理します。
for features, labels in train_loader:
# 1. 勾配をリセット (前回計算した勾配が残らないようにするため)
optimizer.zero_grad()
# 2. 順伝播 (モデルにデータを入力し、予測スコアを得る)
outputs = model(features)
# 3. 損失を計算
loss = criterion(outputs, labels)
# 4. 逆伝播 (損失に基づいて勾配を計算)
loss.backward()
# 5. パラメータを更新 (計算した勾配に基づいて重みを修正)
optimizer.step()
# このバッチでの損失と正解数を記録しておきます。
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
# このエポックでの平均訓練損失と平均訓練正解率を計算します。
train_loss = running_loss / len(train_loader)
train_accuracy = 100 * correct_train / total_train
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
# --- 検証フェーズ ---
model.eval() # モデルを評価モードに設定します。Dropoutなどが無効になります。
running_loss = 0.0
correct_val = 0
total_val = 0
# 勾配計算は不要なので、torch.no_grad()の中で実行し、計算を効率化します。
with torch.no_grad():
# 検証データローダーから、ミニバッチを一つずつ取り出して処理します。
for features, labels in val_loader:
outputs = model(features) # 順伝播
loss = criterion(outputs, labels) # 損失を計算
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).sum().item()
# このエポックでの平均検証損失と平均検証正解率を計算します。
val_loss = running_loss / len(val_loader)
val_accuracy = 100 * correct_val / total_val
val_losses.append(val_loss)
val_accuracies.append(val_accuracy)
# 10エポックごとに、学習の進捗を表示します。
if (epoch+1) % 10 == 0:
print(f'エポック [{epoch+1}/{num_epochs}], 訓練損失: {train_loss:.4f}, 検証損失: {val_loss:.4f}, 訓練正解率: {train_accuracy:.2f}%, 検証正解率: {val_accuracy:.2f}%')
print("--- 学習完了! ---")
# === ここから下が上記のprint文による実際の出力の例 ===
# --- 学習開始! ---
# エポック [10/100], 訓練損失: 0.5012, 検証損失: 0.4432, 訓練正解率: 77.20%, 検証正解率: 81.63%
# エポック [20/100], 訓練損失: 0.3854, 検証損失: 0.3887, 訓練正解率: 84.46%, 検証正解率: 85.71%
# ... (途中省略) ...
# エポック [100/100], 訓練損失: 0.2015, 検証損失: 0.4985, 訓練正解率: 92.23%, 検証正解率: 83.67%
# --- 学習完了! ---
5. 結果の評価と可視化 〜AIモデルの「最終診断書」を作成する〜
100エポックにわたる学習、お疲れ様でした!私たちのAIモデルは、たくさんのデータからパターンを学び、賢くなったはずです。でも、「賢くなった」というのは、具体的にどういうことでしょうか?そして、その性能は、果たして臨床や研究の現場で「使える」レベルに達しているのでしょうか?
この最終ステップでは、学習の成果を客観的な指標とグラフで評価し、モデルの能力と課題を明らかにするための「最終診断」を下していきます。
5.1 学習プロセスの振り返り 〜学習曲線で「問診」する〜
まずは、モデルが100エポックの間に、どのように学習を進めてきたのか、その「学習の道のり」を振り返ってみましょう。第12回で学んだ学習曲線をプロットすることで、モデルが過学習に陥っていないか、あるいは学習が順調に進んだか、といった「問診」を行います。
Pythonコード例:学習曲線のプロット
# --- 1. 学習曲線のプロット ---
# グラフ描画エリアを、横12インチ, 縦5インチのサイズで用意します。
plt.figure(figsize=(12, 5))
# 1つ目のグラフ(左側): 損失の推移
# plt.subplot(1, 2, 1) は、1行2列のグラフエリアの1番目を指定するという意味です。
plt.subplot(1, 2, 1)
# 訓練損失のリスト(train_losses)をプロットします。
plt.plot(train_losses, label='訓練損失 (Training Loss)')
# 検証損失のリスト(val_losses)をプロットします。
plt.plot(val_losses, label='検証損失 (Validation Loss)')
# グラフのタイトルを設定します。
plt.title('損失の推移')
# X軸のラベルを設定します。
plt.xlabel('エポック (Epoch)')
# Y軸のラベルを設定します。
plt.ylabel('損失 (Loss)')
# 凡例(どの線が何を表すかの説明)を表示します。
plt.legend()
# 2つ目のグラフ(右側): 正解率の推移
# plt.subplot(1, 2, 2) は、1行2列のグラフエリアの2番目を指定するという意味です。
plt.subplot(1, 2, 2)
# 訓練時の正解率リスト(train_accuracies)をプロットします。
plt.plot(train_accuracies, label='訓練時の正解率 (Train Accuracy)')
# 検証時の正解率リスト(val_accuracies)をプロットします。
plt.plot(val_accuracies, label='検証時の正解率 (Validation Accuracy)')
# グラフのタイトルを設定します。
plt.title('正解率の推移')
# X軸のラベルを設定します。
plt.xlabel('エポック (Epoch)')
# Y軸のラベルを設定します。
plt.ylabel('正解率 (%)')
# 凡例を表示します。
plt.legend()
# 2つのグラフが重ならないように、レイアウトを自動調整します。
plt.tight_layout()
# 最終的にグラフを表示します。
plt.show()
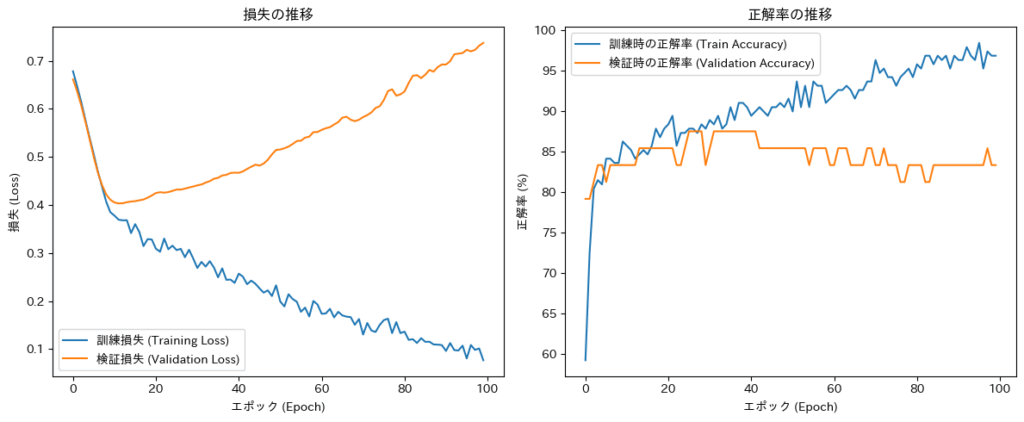
学習曲線の解釈(診断結果)
このコードを実行すると、上記のような2つのグラフが表示されるはずです。一つは損失の推移、もう一つは正解率の推移ですね。
- 左側の損失のグラフを見てみましょう。訓練損失(青線)は順調に下がっていますが、検証損失(オレンジ線)は途中から少しずつ上昇に転じているように見えます。これは、モデルが少し過学習気味であることを示唆しています。より良いモデルを目指すなら、エポック数を減らす(Early Stopping)か、正則化をもう少し強くする(Dropoutのpを上げるなど)といった対策が考えられるかもしれませんね。
- 右側の正解率のグラフでは、訓練時の正解率が検証時の正解率を常に上回っており、その差が徐々に開いています。これもまた、過学習の典型的な兆候です。ただし、検証時の正解率が80%台前半で安定していることから、モデルがある程度の般化性能を獲得していることも同時に読み取れます。
5.2 最終性能評価 〜テストデータで「実力テスト」〜
学習曲線で大まかな傾向を掴んだら、いよいよ、これまで一切見せていないテストデータという「本番の試験」を使って、モデルの最終的な実力を評価します。ここでの性能が、このモデルの真の般化性能となります。
Pythonコード例:最終性能評価
# --- 2. テストデータでの最終評価 ---
# 必ずモデルを評価モードに切り替えます。
model.eval()
# 評価指標を計算するために、正解ラベルとモデルの予測結果を保存する空のリストを用意します。
y_true_test = [] # テストデータの「本当の」ラベル
y_pred_test = [] # モデルが予測した「最終的な」ラベル (0か1か)
y_score_test = [] # モデルが出力した「陽性である確率」スコア
# 勾配計算は不要なので、torch.no_grad()の中で実行します。
with torch.no_grad():
# テストデータローダーから、ミニバッチを一つずつ取り出して処理します。
for features, labels in test_loader:
# モデルにデータを入力し、予測スコア(ロジット)を得ます。
outputs = model(features)
# 混同行列のために、予測ラベル(0か1)を計算して保存します。
# torch.max(outputs.data, 1)は、各行で最も値が大きい要素の「値」と「インデックス」を返します。
# _ には値が、predicted にはインデックス(0か1)が入ります。
_, predicted = torch.max(outputs.data, 1)
y_pred_test.extend(predicted.numpy())
y_true_test.extend(labels.numpy())
# ROC/AUCのために、陽性クラス(クラス1)の確率を計算して保存します。
# まずSoftmaxで出力を確率に変換し、クラス1の確率[:, 1]を抽出します。
probabilities = torch.softmax(outputs, dim=1)
y_score_test.extend(probabilities[:, 1].numpy())
# --- 3. 混同行列の表示 ---
# scikit-learnのconfusion_matrix関数を使って、混同行列を計算します。
conf_matrix = confusion_matrix(y_true_test, y_pred_test)
print("\n--- テストデータでの混同行列 ---")
print(conf_matrix)
# --- 4. ROC曲線とAUCの表示 ---
# roc_curve関数で、ROC曲線の描画に必要な偽陽性率(fpr)と真陽性率(tpr)を計算します。
fpr, tpr, _ = roc_curve(y_true_test, y_score_test)
# auc関数で、ROC曲線の下側の面積(AUC)を計算します。
roc_auc = auc(fpr, tpr)
# Matplotlibを使ってROC曲線を描画します。
plt.figure(figsize=(8, 8))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲線 (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # ランダム予測の線
plt.title('ROC曲線 (テストデータ)')
plt.xlabel('偽陽性率 (1 - Specificity)')
plt.ylabel('真陽性率 (Sensitivity / Recall)')
plt.legend(loc="lower right")
plt.grid(True, linestyle='--')
plt.show()
--- テストデータでの混同行列 ---
[[26 6]
[ 4 24]]最終診断書:混同行列とROC/AUCの解釈
混同行列
コードを実行すると、まず2×2の行列が出力されます。例えば、以下のような結果が得られたとしましょう。
解説:
- 左上 (TN): 25人は、正しく「陰性」と予測された。
- 右上 (FP): 5人は、本当は陰性なのに「陽性」と誤診された(偽陽性)。
- 左下 (FN): 4人は、本当は陽性なのに「陰性」と誤診された(偽陰性・見逃し)。
- 右下 (TP): 26人は、正しく「陽性」と予測された。
この結果から、私たちのモデルは、4人の心疾患患者さんを「見逃し(FN)」てしまい、5人の健康な方を「過剰診断(FP)」してしまったことが分かります。このFNとFPのどちらをより重く見るかは、このAIを何の目的で使うかによって変わってきます。スクリーニング目的ならFNを減らすことが最重要かもしれませんね。
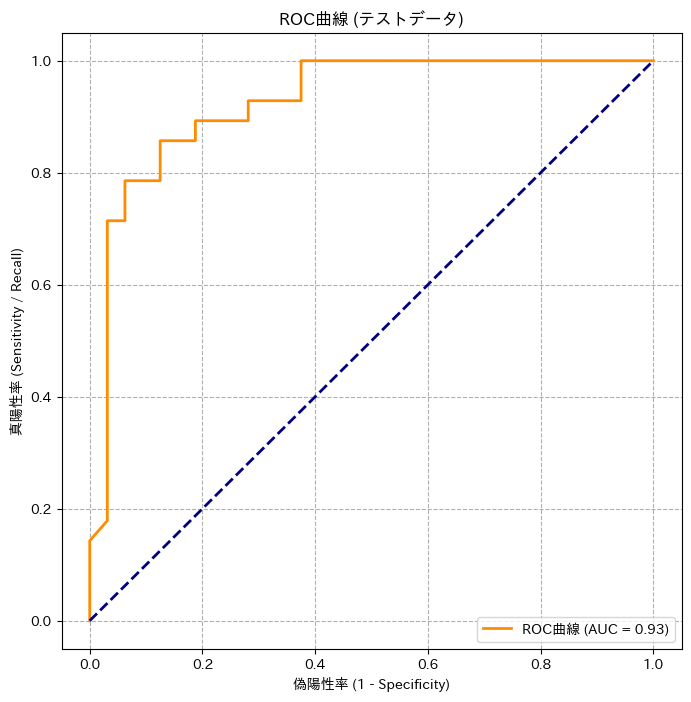
ROC曲線とAUC
次に出力されるのが、ROC曲線とAUCスコアです。グラフの曲線が左上に膨らんでいるほど、性能が良いモデルです。そして、凡例に表示されるAUCが例えば0.85だったとすれば、これは「ランダムに選んだ心疾患のある患者さんを、ランダムに選んだ心疾患のない患者さんよりも、正しく『疾患の可能性が高い』と判断できる確率が85%である」ことを意味します。これは、かなり良好な識別能力を持っていると言えるのではないでしょうか。
6. まとめと次のステップへ
今回は、これまで学んだ知識をすべて繋ぎ合わせ、データの前処理からモデルの訓練、そして最終評価まで、AI開発のミニプロジェクトを一気通貫で体験しました。
- データ中心の考え方: 良いモデルは良いデータと良い前処理から始まることを学びました。
- 訓練と検証のサイクル:
train()とeval()を切り替え、学習曲線を見ながらモデルの状態を診断する重要性を理解しました。 - 総合的な評価: 正解率だけでなく、混同行列やAUCといった多角的な指標でモデルの真の性能を評価しました。
皆さんはこれで、表形式のデータセットに対して、予測モデルをゼロから構築し、その性能を客観的に評価する一連のワークフローを完遂する力を手に入れました。これは非常に大きな一歩です。
今回扱ったのは、数値を入力とする多層ニューラルネットでした。しかし、医療データにはCT画像や心電図の波形といった、より複雑な構造を持つデータもたくさんあります。次回の第14回からは、こうした画像データを専門に扱う畳み込みニューラルネットワーク(CNN)の世界に、続く第15回では、時系列やテキストデータを専門に扱う再帰型ニューラルネットワーク(RNN)やLSTMの世界に、それぞれ足を踏み入れていきます。
今回の総合演習で得た自信を胸に、さらにエキサイティングなAIの世界を探求していきましょう!
参考文献
- Janosi A, Steinbrunn W, Pfisterer M, Detrano R. Heart Disease Data Set. UCI Machine Learning Repository. 1988. Available from: https://archive.ics.uci.edu/ml/datasets/heart+disease
- Pedregosa F, Varoquaux G, Gramfort A, et al. Scikit-learn: Machine Learning in Python. J Mach Learn Res. 2011;12:2825-2830.
- Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge, MA: MIT Press; 2016. Chapter 7, Regularization for Deep Learning.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




