

AIの学習は、何もしなければ中身が見えないブラックボックスです。このガイドでは、「学習曲線」「混同行列」「ROC/AUC」など、モデルの健康状態を診断し、その性能を客観的に評価するための4つの重要なツールを解説します。
訓練データと検証データに対する損失(エラーの大きさ)を時系列でグラフ化します。学習が順調か、あるいは過学習や学習不足に陥っていないかを一目で診断できます。
モデルが「何を何と間違えたか」を詳細に分析する表です。「正解率のワナ」を回避し、特に医療診断で重要な「見逃し(偽陰性)」などの具体的なエラーを把握します。
予測の判断基準(閾値)を様々に動かしたときの性能変化をプロットした曲線です。その面積(AUC)は、閾値に依存しないモデルの総合的な識別能力を示します。
これらの指標は、モデルの振る舞いを理解し、弱点を特定して改善サイクルを回すための「対話ツール」です。信頼性の高いAI開発に不可欠なスキルと言えます。
はじめに:AIの「学習」を、ブラックボックスで終わらせないために
皆さん、こんにちは。これまでの講義で、私たちはAIモデルの設計図を作り(クラス)、効率的にデータを供給する仕組み(DataLoader)も手に入れました。これで、いよいよモデルの「学習(訓練)」を開始する準備が整いました。
しかし、学習の実行ボタンを押した後、私たちはただ祈るように待っているだけで良いのでしょうか?モデルが正しく学んでいるのか、途中で道に迷っていないか、あるいはズルをして訓練データを丸暗記(過学習)していないか…。その学習プロセスの中身は、何もしなければブラックボックスのままです。
そこで今回は、学習というブラックボックスの中を覗き込み、モデルの状態を客観的に評価するための「診断ツール」について学びます。これは、患者さんの状態を把握するためにバイタルサインや検査値を見るのと全く同じです。私たちは、AIの「ドクター」として、モデルの健康状態を正しく診断し、より良いモデルへと導くためのスキルを身につける必要があります。
この講義では、AIモデルの「健康診断」に欠かせない、以下の4つの重要なツールに焦点を当てていきます。
- 学習曲線: 学習プロセスの「バイタルサイン」を時系列で追う。
- 正解率: 最も直感的な指標、しかしそこにはワナも。
- 混同行列: モデルの「誤診」を詳細に解剖する。
- ROC曲線とAUC: モデルの総合的な「診断能力」を評価する。
これらのツールを使いこなし、モデルと対話する術を学びましょう。
1. 学習曲線 (Learning Curve) – 学習プロセスの「バイタルサイン」
学習曲線は、学習の進行度(通常はエポック数)を横軸に、モデルの損失(間違いの大きさ)や精度を縦軸にとったグラフです。まさに、AIモデルの学習過程における「バイタルサインチャート」と言えるでしょう。このチャートを観察することで、学習が順調か、何か問題が起きていないかを一目で把握できます。
特に重要なのが、訓練データに対する損失 (Training Loss)と、モデルがまだ見ていない検証データに対する損失 (Validation Loss)の2つを同時にプロットすることです。
- 訓練損失 (Training Loss): モデルが学習に使っているデータに対する損失。これが下がるのは、モデルが「勉強」している証拠であり、基本的には下がり続けるべきです。
- 検証損失 (Validation Loss): 訓練には使っていない、モデルにとっては「未知」のデータに対する損失。これが、モデルの真の実力、すなわち般化性能を測るための重要な指標となります。
学習曲線のパターンから「診断」する
学習曲線の形状を見ることで、モデルの健康状態を診断できます。
学習曲線の3つの典型的なパターン
- 理想的な学習 (Good Fit): 訓練損失と検証損失が両方とも順調に下がり、最終的に低い値で収束している状態。モデルがうまく般化できている、健康な状態です。
- 過学習 (Overfitting): 訓練損失は下がり続ける一方で、検証損失がある時点から上昇に転じてしまう状態。モデルが訓練データを「丸暗記」し始め、未知のデータへの対応能力を失っている危険な兆候です。前回学んだ正onyl化(DropoutやL2正onyl化)などが処方箋となります。
- 学習不足 (Underfitting): 訓練損失も検証損失も、両方とも十分に下がりきらず、高い値のまま停滞している状態。モデルの表現力が単純すぎて、データからパターンを学びきれていないことを示唆します。より複雑なモデル(層を増やすなど)への変更を検討する必要があります。
2. 分類タスクの評価指標 – 「正解率」だけでは見えないワナ
損失はモデルを訓練するための指標ですが、モデルの「性能」を人間に分かりやすく伝えるには、別の指標が必要です。特に、あるデータがどのクラスに属するかを当てる分類タスクでは、いくつかの重要な指標があります。
最も直感的で分かりやすいのが正解率 (Accuracy) です。
\[ \text{正解率 (Accuracy)} = \frac{\text{正しく予測できたデータの数}}{\text{全てのデータの数}} \]
しかし、この正解率には、特に医療データのような不均衡データ (Imbalanced Data) を扱う際に、大きなワナが潜んでいます。
例えば、1000人に1人しか罹患しない非常に稀な疾患のスクリーニング検査を考えてみてください。もし、AIモデルが何も考えずに、全ての人を「陰性(疾患なし)」と予測したとします。このモデルは、999人の健康な人を正しく「陰性」と予測し、1人の患者さんだけを見逃します。このときの正解率は…
\( \frac{999}{1000} = 99.9\% \)
驚異的な正解率ですよね。しかし、このモデルは一人の患者も見つけられない、全く役に立たないモデルです。これが「正解率のパラドックス」です。
このワナを回避するために、私たちはより詳細な評価を行う必要があります。
3. 混同行列 (Confusion Matrix) – モデルの「誤診」を解剖する
混同行列は、モデルの予測結果を「どのクラスを、どのクラスと間違えたか」という観点から、詳細に分析するためのツールです。まさに、モデルの「誤診の内訳」をまとめた表と言えます。
2クラス分類における混同行列
| 予測結果 (Predicted) | |||
|---|---|---|---|
| 陽性 (Positive) | 陰性 (Negative) | ||
| 実際のクラス (Actual) | 陽性 (Positive) | TP (真陽性) 正しく陽性と予測 | FN (偽陰性) 誤って陰性と予測 |
| 陰性 (Negative) | FP (偽陽性) 誤って陽性と予測 | TN (真陰性) 正しく陰性と予測 | |
- TP (True Positive): 実際に陽性の患者さんを、正しく「陽性」と予測できたケース。
- FN (False Negative): 実際に陽性の患者さんを、誤って「陰性」と予測してしまったケース。見逃しであり、医療においては最も避けたい誤りであることが多いです。
- FP (False Positive): 実際は陰性の健康な人を、誤って「陽性」と予測してしまったケース。不要な追加検査や不安に繋がります。
- TN (True Negative): 実際に陰性の健康な人を、正しく「陰性」と予測できたケース。
この行列を見ることで、「正解率が高いけれど、実は重要な陽性ケースをたくさん見逃している(FNが多い)」といった、モデルの弱点を詳細に把握できます。
4. ROC曲線 と AUC – モデルの「診断能力」を総合評価する
混同行列は非常に有用ですが、モデルの予測が「陽性/陰性」の二択ではなく、「陽性である確率が80%」のような連続値で出力される場合、どこを「陽性」と判断するかの閾値(カットオフ値)を決めなければなりません。この閾値を厳しくすれば偽陽性(FP)は減りますが、偽陰性(FN)が増えてしまいます。逆もまた然りです。
この感度(真陽性率)と偽陽性率のトレードオフ関係を、全ての閾値にわたってプロットしたものがROC曲線 (Receiver Operating Characteristic Curve) です。
- ROC曲線: 横軸に偽陽性率 (FPR = FP / (FP+TN))、縦軸に真陽性率 (TPR = TP / (TP+FN), 感度や再現率とも呼ばれる) をとったグラフです。
- 理想的なモデル: グラフの左上隅(偽陽性率が0で、真陽性率が1)に近づくほど、性能が良いモデルと言えます。
- ランダムな予測: 対角線(原点と(1,1)を結ぶ線)は、コインを投げて予測するのと同じ、全く役に立たないモデルを示します。
そして、このROC曲線が描く曲線の下側の面積を計算したものがAUC (Area Under the Curve) です。
- AUC: 0から1までの値をとり、1に近いほど優れたモデルです(0.5はランダム予測)。このAUCは、閾値に依存しない、モデルの総合的な「識別能力」や「診断能力」を示す指標として、医学研究の論文でも頻繁に利用されます(1,2)。
Pythonコード例:ROC曲線とAUCを計算・描画する
ダミーの予測確率と正解ラベルを使って、ROC曲線とAUCを計算してみましょう。ここでは、この分野で標準的なライブラリであるscikit-learnを利用します。
# --- 1. 必要なライブラリをインポートします ---
# 数値計算のためのnumpyをインポートします。
import numpy as np
# グラフ描画のためのmatplotlib.pyplotをpltという別名でインポートします。
import matplotlib.pyplot as plt
# 日本語の文字化けを防ぐためのライブラリです(環境にインストール済の場合)。
# pip install japanize-matplotlib
import japanize_matplotlib
# --- 2. グラフの描画設定 ---
# これから描画するグラフ全体のサイズや見た目を整えます。
# figsize=(9, 9)で、縦横9インチの正方形のキャンバスを用意します。
plt.figure(figsize=(9, 9))
# --- 3. AUC=0.5 (ランダムな予測) の線をプロット ---
# これは性能が最も低い、いわば「当てずっぽう」のモデルです。
# (0,0)から(1,1)への対角線として描画されます。
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='ランダム予測 (AUC = 0.50)')
# --- 4. 様々なAUC値を持つROC曲線を描画 ---
# ここでは、特定のAUC値を持つROC曲線を数式を使って生成し、描画します。
# AUC = 1 / (p + 1) の関係から、p = (1/AUC) - 1 を使って曲線の形を決めています。
# これにより、指定したAUCに非常に近い曲線を描画できます。
# 描画したいAUCのリスト
target_aucs = [0.6, 0.7, 0.8, 0.9]
# 描画に使う色のリスト
colors = ['cyan', 'green', 'blue', 'purple']
# ループを使って、各AUCの曲線を順番に描画します。
for i, auc_val in enumerate(target_aucs):
# 曲線の「膨らみ具合」を決定するパラメータpを計算します。
p = (1 / auc_val) - 1
# 横軸となる偽陽性率(FPR)の値を0から1まで100点で生成します。
fpr = np.linspace(0, 1, 100)
# FPRの値を使って、対応する真陽性率(TPR)の値を計算します。
tpr = fpr ** p
# 計算したFPRとTPRを使ってROC曲線をプロットします。
plt.plot(fpr, tpr, color=colors[i], lw=2, label=f'ROC曲線 (AUC ≈ {auc_val:.2f})')
# --- 5. AUC=1.0 (完璧な予測) の線をプロット ---
# 完璧なモデルは、偽陽性率(FPR)が0のまま、真陽性率(TPR)が1に到達します。
# (0,0) -> (0,1) -> (1,1) と直角に曲がる線で表現されます。
plt.plot([0, 0, 1], [0, 1, 1], color='red', lw=2, linestyle='-', label='完璧な予測 (AUC = 1.00)')
# --- 6. グラフの体裁を整える ---
# 横軸の範囲を0から1に設定します。
plt.xlim([-0.05, 1.0])
# 縦軸の範囲を0から1.05に設定し、少し上に余白を持たせます。
plt.ylim([0.0, 1.05])
# 横軸にラベルを追加します。
plt.xlabel('偽陽性率 (False Positive Rate / 1 - Specificity)', fontsize=12)
# 縦軸にラベルを追加します。
plt.ylabel('真陽性率 (True Positive Rate / Sensitivity)', fontsize=12)
# グラフ全体にタイトルを追加します。
plt.title('様々なAUC値を持つROC曲線の比較', fontsize=15)
# 各曲線が何を表すかを示す凡例を表示します。
plt.legend(loc="lower right")
# 見やすいようにグリッド(補助線)を表示します。
plt.grid(True, linestyle='--', alpha=0.6)
# グラフのアスペクト比を1:1に設定し、正方形に見えるようにします。
plt.gca().set_aspect('equal', adjustable='box')
# --- 7. グラフを表示 ---
# これまでに設定した内容で、グラフを画面に表示します。
plt.show()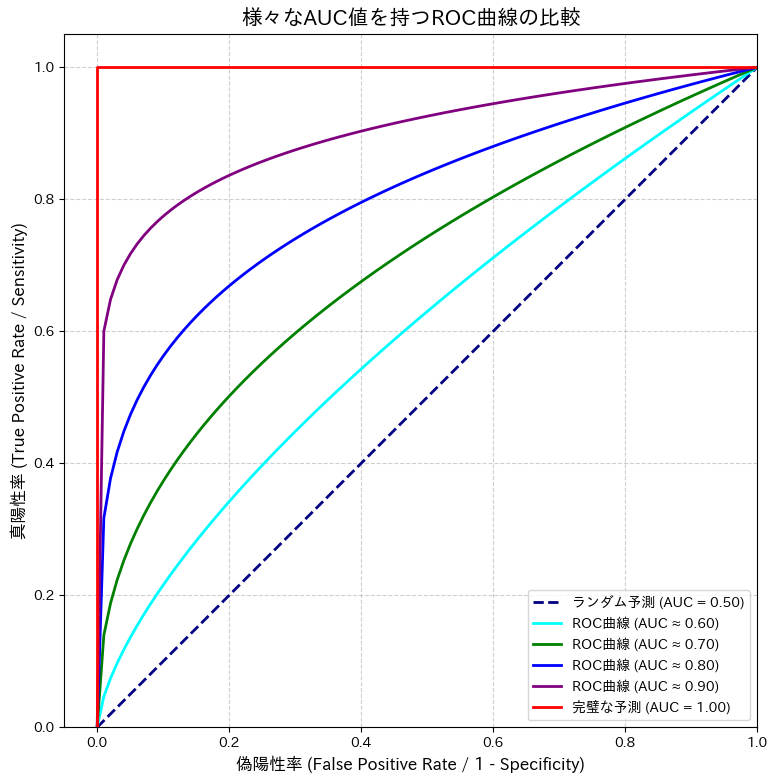
5. まとめと次のステップへ
今回は、AIモデルの学習過程と性能を評価するための「診断ツール」たちを学びました。
- 学習曲線: 学習の進行状況(順調、過学習、学習不足)をモニターするバイタルサイン。
- 正解率のワナ: 不均衡データでは、高い数値が必ずしも良いモデルを意味しないことを理解する。
- 混同行列: TP, FN, FP, TNを分析し、モデルの「誤診」の内訳を詳細に把握する。
- ROC/AUC: 閾値に依存しない、モデルの総合的な識別能力を評価する、医療分野でも標準的な指標。
これらのツールを使いこなすことで、私たちは単に「コードを実行する」段階から、モデルの振る舞いを「診断し、理解する」段階へと進むことができます。これは、信頼性の高い医療AIを構築しようとする全ての研究者にとって、極めて重要なスキルです。
さて、これでモデルを構築し、データを供給し、そしてその性能を評価する方法まで、一通りの流れを学びました。いよいよ次からは、これまでの知識を応用して、より実践的なタスクに挑戦していきます。第13回では、多層ニューラルネットを使って、より複雑なデータセットの分類問題に取り組んでみましょう。
参考文献
- Fawcett T. An introduction to ROC analysis. Pattern Recognit Lett. 2006;27(8):861-874.
- Hajian-Tilaki K. Receiver Operating Characteristic (ROC) curve analysis for medical diagnostic test evaluation. Caspian J Intern Med. 2013;4(2):627-635.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




