

難易度:★★★☆☆
こんにちは!前回は「生成系AIの概要と医療への応用可能性」を概観しましたが、今回は実際にコードを書くための環境構築と、Python + PyTorchの基本について学びます。
医療分野で生成AIを活用するときには欠かせない“土台”なので、しっかり押さえましょう。まずはGoogle Colabを使って手軽に試す方法を紹介し、その後、WindowsとMacでVS Codeを使うローカル開発環境の作り方を詳しく解説します。
💡本シリーズ(第2回)は、生成系AIを医療に活かすための実践力を身につけるべく、いくつかの章に分けて解説します。
この第1章では、Python + PyTorchを使った開発環境の構築と、プログラミングの基本操作に焦点を当て、実装に入る前の「土台づくり」を行います。
次回の第2章では、いよいよディープラーニングの心臓部とも言える誤差逆伝播と自動微分の仕組みに迫っていきます。
1. まずはGoogle Colabで動かしてみよう!
1-1. Google Colabとは?
- Google Colab(以下Colab)は、ブラウザだけでPyTorchなどを動かせる無料サービスです。
- Googleアカウントがあればすぐに利用可能。
- GPU/TPUの無料枠があり、ディープラーニングの実験に便利(使用時間やセッション切断等の制限あり)。
1-2. ColabでPyTorchを使う準備
- Google Colab にアクセスし、Googleアカウントでログイン。(以下の図)
- 「新しいノートブックを作成」等をクリックして、Python 3 のノートブックを開きます。
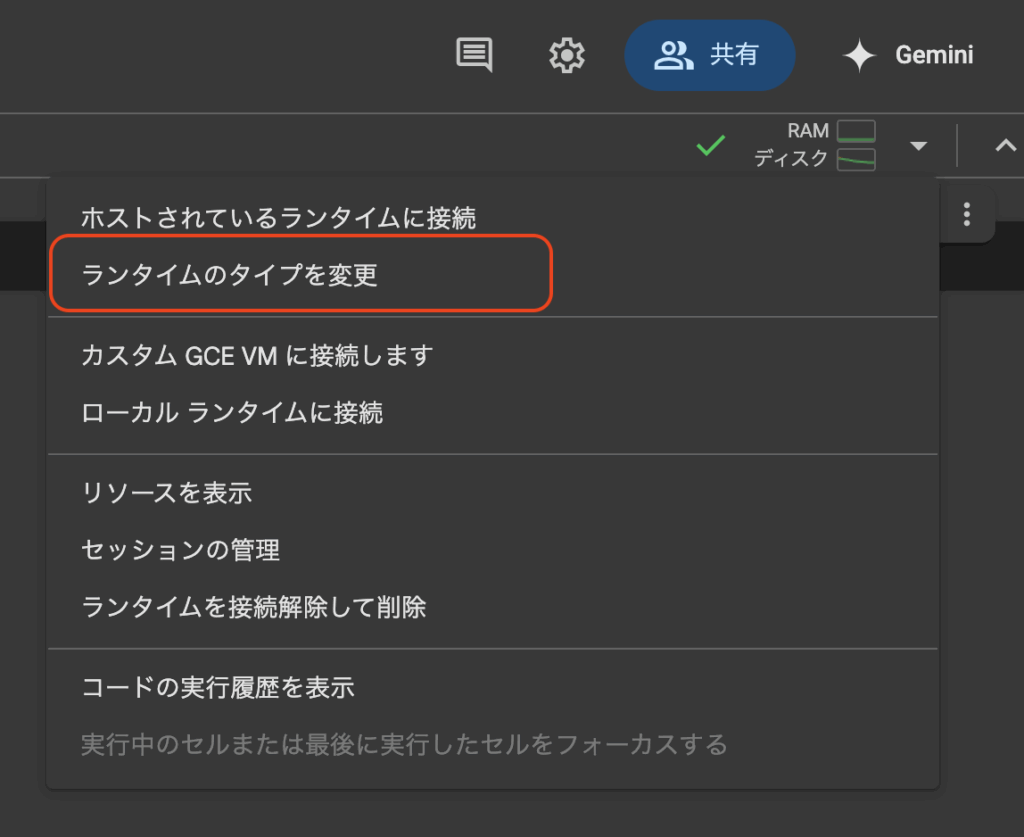
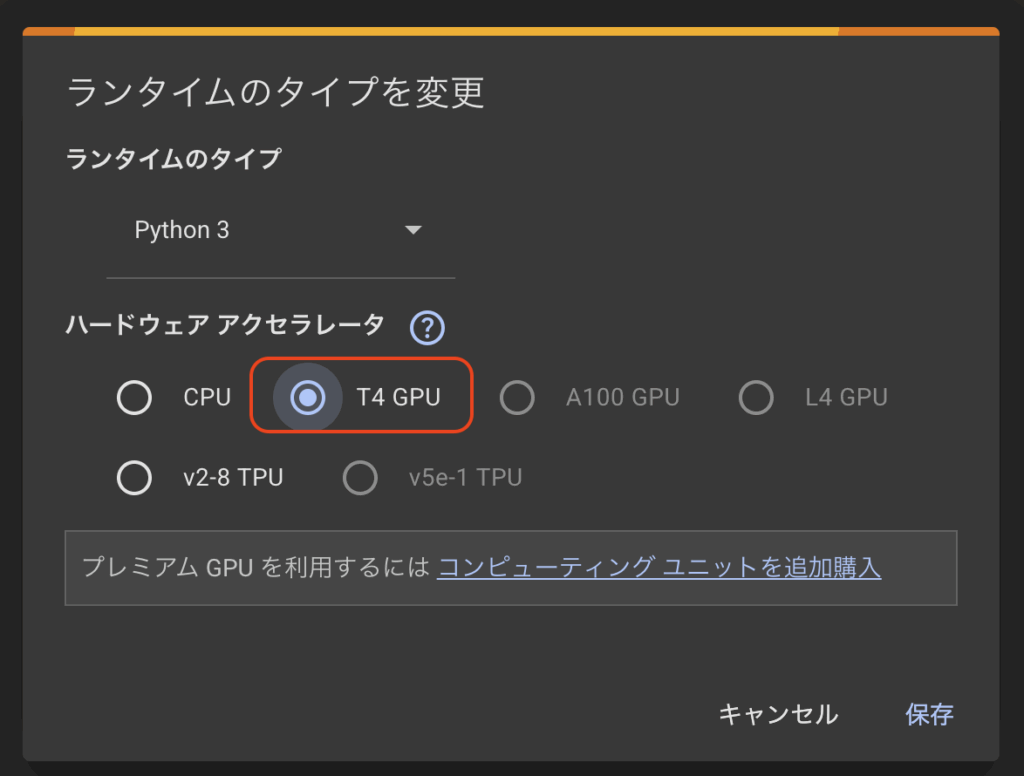
- 上部メニューの「ランタイム」 → 「ランタイムのタイプを変更」を選択し、ハードウェアアクセラレータをGPUに変更(必要であれば)。
- ノートブックのセルに下記のPyTorch動作確認コードを貼り付けて実行。
# -*- coding: utf-8 -*-
import torch
print("PyTorchバージョン:", torch.__version__)
if torch.cuda.is_available():
print("GPUが利用できます!")
else:
print("GPUは利用できません。")
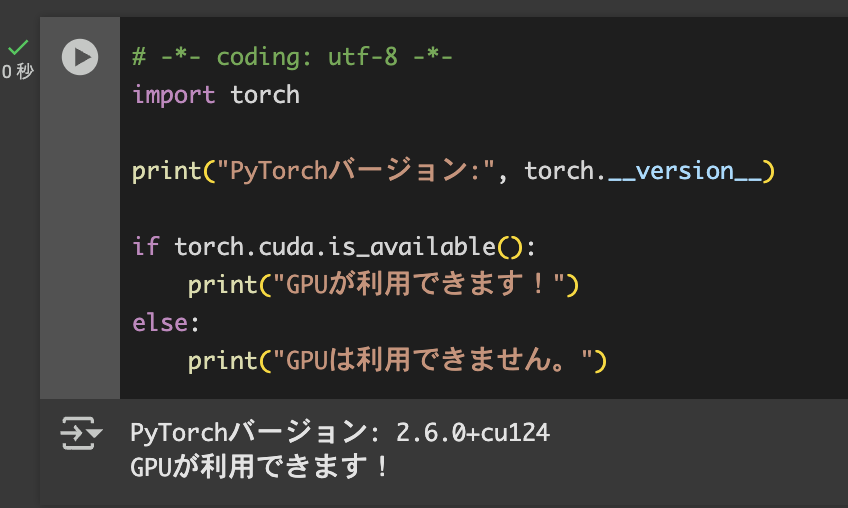
エラーが出ずに「GPUが利用できます!」と表示されればOKです。GPUを使わずCPUのみでも動かせます。
医療データをColabにアップロードする際の注意
- 患者データなど個人情報を含む場合、クラウド上にアップロードして良いか所属機関や法令を必ず確認してください。
- 匿名化された研究用データなら手軽に試しやすいですが、セキュリティやプライバシー保護が十分に担保されているか注意が必要です。
2. ローカル環境で開発する(Windows / Mac + VS Code)
「Colabで感触はつかめたが、機密データを扱うのでクラウドはNG」「VS Codeの便利な機能を使いながら開発したい」という方は、ローカル環境を構築しましょう。ここではWindowsとMacそれぞれでVisual Studio Code(VS Code)を使う方法を順を追って解説します。
2-1. VS Codeのインストール
(A) Windowsでのインストール
- VS Code公式サイトにアクセスし、Windows向けのインストーラをダウンロード。
- ダウンロードした
.exeファイルを実行し、インストールウィザードに従います。- 「PATHに追加する」「ショートカットを作成する」などのオプションが出ますが、基本的にはデフォルト設定でOK。
- インストール完了後、スタートメニューなどからVisual Studio Codeを起動します。
(B) Macでのインストール
- VS Code公式サイト にアクセスし、Mac向けの
.zip(または.dmg)をダウンロード。 - ダウンロードしたファイルを解凍し、「Visual Studio Code.app」をアプリケーションフォルダに移動します。
- LaunchpadやFinderからVisual Studio Codeを起動します。
(C) 拡張機能のインストール
- VS Codeを起動したら、左側のメニューにある「拡張機能」(四つのブロック状アイコン)をクリック。
- 検索窓に「Python」や「Jupyter」などを入力し、Microsoft公式の拡張機能をインストールしておくと、Pythonの補完やNotebook実行が楽になります。
2-2. Anaconda / Miniconda (conda) でPython環境を構築
condaは、Python以外のCUDAライブラリやC/C++製ライブラリもまとめて管理できるため、GPU対応のAI開発で特に便利です。
2-2-1. Windowsでのconda環境構築
- Anaconda公式サイトからWindows版のAnaconda、または軽量版のMinicondaをダウンロード。
- ダウンロードした
.exeを実行し、インストーラの案内に従ってインストールします。- 「Add Anaconda to my PATH environment variable」というオプションがある場合、チェックしておくと後でコマンドが使いやすくなりますが、推奨/非推奨がバージョンによって異なるので注意。
- VS Codeを起動し、「ターミナル」メニュー → 「新しいターミナル」 をクリックして、VS Codeの統合ターミナルを開きます。(以下参照)
- デフォルトではPowerShellやCommand Promptが立ち上がります。
- ターミナルで以下のコマンドを実行し、仮想環境
myenvを作成します。- ❗️Windowsで
condaが使えない時は、下の対処法を試してください。
- ❗️Windowsで
# (1) "myenv" という名前の仮想環境 + Python3.9をインストール
conda create -n myenv python=3.9 -y
# (2) 仮想環境をアクティベート
conda activate myenv
# (3) PyTorch, TorchVision, TorchAudio, CUDAツールキットをまとめてインストール
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -y
# (4) Notebookを使いたい場合
conda install jupyter
- VS Code下部(ステータスバー)に「Python: *」と表示されている場合、そこをクリックしてPythonインタープリタ**を
myenvに変更します。- これでVS CodeからPythonを実行するときに、
myenvのライブラリが使われます。
- これでVS CodeからPythonを実行するときに、
- インストール完了後に、以下のコマンドでNotebookを起動します。ブラウザが立ち上がり、以下のような画面になります。:
または VS Code の左上「実行」→「新しいJupyterノートブック」でも起動可能です。
jupyter notebook
はい、同じような問題はWindowsでも起こりえます。以下のようなケースで conda が「認識されない」または「command not found / is not recognized as an internal or external command」になることがあります。
❗️Windowsで conda が使えない主な原因と対処法
✅ ① Anaconda/Miniconda をインストールしていない
まず基本として、conda を使いたいなら Anaconda または Miniconda をインストールしておく必要があります。
✅ ② システムの「環境変数」に conda のパスが通っていない
Windowsでは、コマンドライン(cmd または PowerShell)で conda を実行するには、Anaconda/Miniconda のインストール時に以下のフォルダへのパスが「環境変数(Path)」に追加されている必要があります:
C:\Users\YourName\anaconda3C:\Users\YourName\anaconda3\ScriptsC:\Users\YourName\anaconda3\Library\bin
⚠️ インストール時に「Add Anaconda to my PATH environment variable」にチェックを入れなかった場合は、追加されていない可能性があります。
対処法:手動でPathに追加する方法
- 「スタート」→「環境変数」と検索 → 「システム環境変数の編集」を開く
- 「環境変数」ボタン → 「Path」→「編集」
- 上記3つのパスを 追加 して「OK」
✅ ③ Anaconda Prompt を使えばすぐ解決する場合も
Anacondaをインストールしていれば、「スタートメニュー」にある Anaconda Prompt(専用ターミナル)を使えば、最初から conda が通っている状態で起動します。
conda --version
が通るか、まずここで確認するのもおすすめです。
✅ 補足:VS Codeで conda activate がうまくいかないとき
VS Codeのターミナルでは conda activate がそのまま使えない場合があります。以下の対策が有効です:
# conda 環境を初期化
conda init powershell
# または cmd 用に
conda init cmd.exe
その後、VS Codeを再起動してください。
2-2-2. Macでのconda環境構築
- Anaconda公式サイトからMac版のAnacondaまたはMinicondaをダウンロード。
- ダウンロードした
.pkg(または.sh) を実行し、インストーラに従ってインストールします。 - VS Codeを起動し、「ターミナル」メニュー → 「新しいターミナル」 をクリック。(上記参照)
- デフォルトではzshやbashが立ち上がるはずです。
- 下記コマンドを入力します(手順はWindowsと同様です)。
- ❗️
conda: command not foundと表示された場合は、下の対処法を試してください。
- ❗️
# (1) "myenv" という名前の仮想環境 + Python3.9をインストール
conda create -n myenv python=3.9 -y
# (2) 仮想環境をアクティベート
conda activate myenv
# (3) PyTorch, TorchVision, TorchAudio, CUDAツールキットのインストール
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -y
# (4) Jupyter Notebookも必要なら
conda install jupyter
- VS Code下部(ステータスバー)でインタープリタを
myenvに切り替えます。- 「Python: ***」をクリックし、
myenvが表示されていれば選択してください。
- 「Python: ***」をクリックし、
- インストール完了後に、以下のコマンドでNotebookを起動します。ブラウザが立ち上がり、以下のような画面になります。:
または VS Code の左上「実行」→「新しいJupyterノートブック」でも起動可能です。
jupyter notebook以下は、WordPressに貼り付けられるよう整えた形式(コードブロック含む)でのまとめです:
❗️conda: command not found と表示された場合の対処法
ターミナルで conda を実行しても「command not found」などと表示される場合、以下の原因が考えられます:
✅ ① Anaconda/Miniconda が未インストールの場合
上記のリンクから Anaconda または Miniconda をダウンロード・インストールしてください。
✅ ② インストール済だが PATH が通っていない場合
conda の場所が環境変数 PATH に登録されていないことが原因です。
# conda の場所を確認
which conda何も表示されない場合は、~/.zshrc(または ~/.bash_profile)に以下を追記してください:
export PATH="$HOME/miniconda3/bin:$PATH"そして、設定を反映させます:
source ~/.zshrc✅ ③ 初期化が済んでいない場合
シェルに conda を認識させるため、次の初期化コマンドを実行します:
conda init zshその後、ターミナルを再起動するか、以下のコマンドで反映させます:
source ~/.zshrc✅ 確認
以下のコマンドを実行し、バージョン情報が表示されればセットアップは完了です:
conda --version注意(Windows/Mac共通)
- GPU(CUDA)が使えるかどうかは、PCのハードウェア(対応GPU)とドライバ状況によります。
- Anaconda/Minicondaをインストール後にVS Codeを起動して、ターミナルに
condaコマンドが認識されるようにしてください。もし認識されない場合は、Anaconda PromptやTerminalでインストールパスを手動で設定する必要があります。
2-3. Python標準の venv で環境を構築
venvはPythonに標準搭載の仮想環境ツールです。軽量ですが、GPU周りなどを自力でセットアップする必要があります。
2-3-1. Windows
- Python公式サイトなどからPython3.xをインストール(Anacondaを使わない場合)。
- VS Codeを起動し、「ターミナル」→「新しいターミナル」 でPowerShellやCmdを開く。
- 下記コマンドを入力。
# (1) 'myvenv' という名前の仮想環境を作成
python -m venv myvenv
# (2) 仮想環境をアクティベート
# (Windowsの場合)
myvenv\Scripts\activate
# (macOS/Linuxの場合)
# source myvenv/bin/activate
# (3) PyTorch本体と関連ライブラリをインストール
pip install torch torchvision torchaudio
# (4) Jupyter Notebookの実行環境をインストール
pip install jupyter
# (5) AI開発に役立つ便利ライブラリも追加インストール
pip install matplotlib seaborn pandas scikit-learn
pip install tqdm opencv-python
pip install transformers datasets
# (必要に応じて)
# pip install numpy scipy Pillow
# pip install tensorboard wandb # 実験ログ管理に便利
- VS Code下部の「Pythonインタープリタを選択」から
myvenvを選択します。
2-3-2. Mac
- Mac標準のPython3か、python.orgもしくはHomebrew(
brew install python)などでPython3.xを導入。 - VS Codeの「ターミナル」を開き、bashやzsh上で下記コマンドを入力。
# (1) 'myvenv' という名前の仮想環境を作成
python -m venv myvenv
# (2) 仮想環境をアクティベート
# (Windowsの場合)
# myvenv\Scripts\activate
# (macOS/Linuxの場合)
source myvenv/bin/activate
# (3) PyTorch本体と関連ライブラリをインストール
pip install torch torchvision torchaudio
# (4) Jupyter Notebookの実行環境をインストール
pip install jupyter
# (5) AI開発に役立つ便利ライブラリも追加インストール
pip install matplotlib seaborn pandas scikit-learn
pip install tqdm opencv-python
pip install transformers datasets
# (必要に応じて)
# pip install numpy scipy Pillow
# pip install tensorboard wandb # 実験ログ管理に便利
- VS Code下部のインタープリタを
myvenvに切り替えます。
GPU対応について
- venvでは、NVIDIA公式のCUDA Toolkitを手動でインストールし、PyTorchを対応バージョンで
pipインストールする必要があり、ややハードルが高いです。- GPUを楽に使うなら、conda環境がおすすめです。
3. Pythonの基礎文法:ざっくりおさらい(辞書がわりにどうぞ)
ここでは、Pythonで深層学習やデータ分析を始めるにあたって最低限知っておきたい基本的な文法や書き方を、なるべく丁寧に解説します。初歩的な部分に見えるかもしれませんが、後々のプログラミング効率や可読性に大きく関わってくるので、ぜひ一度ざっと目を通してみてください。
3-1. Pythonコードのはじめかた
# -*- coding: utf-8 -*-
# ↑ この宣言は、ソースコード内で日本語などのマルチバイト文字を扱う際に
# エンコーディングを明示しておくためのものです。Python3では必須ではありませんが、
# 文字化けを防ぐため念のため入れておくと安全です。
- Python 3 以降、ファイル冒頭のエンコーディング宣言がなくても基本的にUTF-8として解釈されますが、環境によっては文字化けを起こすケースがあるため、明示しておくと安心です。
3-2. 変数と型
x = 10
y = 3.14
x = 10: Pythonでは整数を表すとき、型を明示する必要はありません。y = 3.14: 浮動小数点数(float)も同様に、そのままy = 3.14と書くだけでOK。- Pythonは動的型付け言語のため、
xやyの型は実行時に決まります。宣言式のようなものはありません。
ポイント
- 他の言語(C, Java等)のように「int x;」と書く必要がないので、初めての方にも比較的始めやすい反面、「思わぬ型の変化」が起こりうる点には注意。
- 大きなプロジェクトになるほど、Pythonの型ヒント(type hints)を併用することで可読性や保守性を高めることが多い。
3-3. リストと辞書
リスト (List)
fruits = ["apple", "banana", "orange"]
["apple", "banana", "orange"]はリストと呼ばれるシーケンス型。- 要素の追加や削除、順番の入れ替えなどが簡単にできます。
fruits.append("grape") # リストの末尾に"grape"を追加
print(fruits) # => ["apple", "banana", "orange", "grape"]
- リストの要素にはどんな型でも入れられる(文字列、数値、他のリストなど)。
- インデックスは0から始まります。
fruits[0]は"apple"、fruits[1]は"banana"になります。
辞書 (Dictionary)
info = {"name": "Alice", "age": 30}
{"name": "Alice", "age": 30}は辞書型。- キーと値のペアを複数持つことができます。
print(info["name"]) # => Alice
info["job"] = "Doctor" # 新しいキー "job" を追加
print(info) # => {'name': 'Alice', 'age': 30, 'job': 'Doctor'}
- 辞書のキーは文字列以外にも数値やタプルを使用できます(ただしリストは不可)。
- 医療分野の例では、
{"patient_id": "AB123", "height": 170, "weight": 65}のように患者情報をまとめるのにも便利です。
3-4. 制御構文:forループとif文
forループ
for i in range(3):
print(i)
range(3)は[0,1,2]相当のイテレーション用オブジェクトを返します。- ブロックはインデント(字下げ) で表現します。Pythonでは
{}を使わないので注意しましょう。 - リストの要素を直接ループで取り出すことも可能です。
fruits = ["apple", "banana", "orange"]
for fruit in fruits:
print(fruit)
# => apple
# banana
# orange
if文
x = 10
if x > 5:
print("xは5より大きい")
elif x == 5:
print("xは5と等しい")
else:
print("xは5より小さい")
if/elif/elseの末尾にコロン「:」を付け、次の行をインデントします。==は「等しいかどうか」を判定する演算子、=は代入演算子なので混同に注意してください。
3-5. 関数の定義
def greet(name):
return f"Hello, {name}!"
def 関数名(引数):で関数を定義。- 関数も本体はインデントでスコープを表します。
- Python 3.6以降では、
f"Hello, {name}!"のようにf-stringを使うと可読性の高い文字列フォーマットができます。
message = greet("Bob")
print(message) # => "Hello, Bob!"
- 一度定義した関数を何度でも呼び出せるため、コードを整理しやすくなります。
- 大規模開発では、関数・クラスをモジュールとして分割管理するのが一般的です。
3-6. f-string(フォーマット文字列)について
- Python 3.6以降で導入された、変数埋め込みが簡単に書ける構文です。
name = "Alice"
age = 30
print(f"{name} is {age} years old.")
# => Alice is 30 years old.
- 以前は
format()や%演算子がよく使われていましたが、f-stringはより直感的です。 - 医療分野の例:
patient_id = "ABC123"
height = 170
weight = 65
print(f"Patient {patient_id} has height {height} cm and weight {weight} kg.")
- => “Patient ABC123 has height 170 cm and weight 65 kg.”
3-7. Pythonの便利機能:リスト内包表記
nums = [1, 2, 3, 4, 5]
squares = [n**2 for n in nums]
print(squares) # => [1, 4, 9, 16, 25]
- リスト内包表記 (List Comprehension)と呼ばれる書き方で、ループを書かずにリスト変換が行えます。
- さらにif文を加えることも可能です。
nums = [1, 2, 3, 4, 5]
even_squares = [n**2 for n in nums if n % 2 == 0]
print(even_squares) # => [4, 16]
3-8. インデントとコロンに注意
- Pythonはインデント(行頭のスペースやタブの数)でブロックを区切ります。
if,for,defの行末にはコロン:を書き、その次の行をインデントでまとめます。
if x > 0:
print("positive")
else:
print("non-positive")
- インデントの深さを間違えたり、スペースとタブを混在させるとエラーの原因になるので気をつけてください。
- チーム開発では PEP 8(Pythonのコードスタイルガイド)に合わせ、スペース4つでインデントを統一するのが一般的です。
3-9. Pythonの強み:可読性の高さ
- ここまで見てきたように、Pythonはコードが直感的に読めるようにデザインされています。
- AIやデータ分析コミュニティでは、コードの可読性を重視する文化があり、Pythonの文法がその考え方と親和性が高いと言えます。
3-10. クラスとオブジェクト指向:コードを「モノ(オブジェクト)」で整理する考え方
Pythonでは「オブジェクト指向プログラミング(OOP)」という考え方が使えます。
これは、データとその操作をひとまとまりにして、現実のモノ(オブジェクト)を模した設計をするスタイルです。
💡クラス(class)とは?
クラスは、設計図のようなもの。
たとえば「患者」という概念をクラスで定義すると、名前、年齢、身長、体重などの情報(データ)や、BMIを計算する機能(メソッド)を持たせることができます。
class Patient:
def __init__(self, name, height, weight):
self.name = name
self.height = height # 単位:cm
self.weight = weight # 単位:kg
def calculate_bmi(self):
height_m = self.height / 100
return self.weight / (height_m ** 2)
💡オブジェクト(インスタンス)を作って使う
クラスから具体的な「実体(オブジェクト)」を作ることを インスタンス化 と言います。
p1 = Patient("Alice", 170, 65)
print(p1.name) # => Alice
print(p1.calculate_bmi()) # => 22.491...
__init__は「コンストラクタ」と呼ばれ、インスタンスが作られるときに呼ばれます。selfは「そのオブジェクト自身」を指す特別なキーワードです。self.変数名で各オブジェクトのデータを管理できます。
医療の現場での例え
もし、複数の患者データを管理したい場合、辞書やリストで持つよりも、例えば、Patient クラスを使った方がコードの見通しが良くなります。
patients = [
Patient("Bob", 180, 80),
Patient("Carol", 160, 50)
]
for p in patients:
print(f"{p.name} のBMIは {p.calculate_bmi():.2f}")
なぜ使うのか?
- データと処理を「ひとまとめ」にできる
- コードの再利用性・保守性が上がる
- 大規模なアプリや医療AIなどでは、クラスを使った設計が基本になる
✅補足:関数(関数型) vs クラス(オブジェクト指向)
| 特徴 | 関数だけで書く | クラスを使う |
|---|---|---|
| 小さなスクリプト向き | ◎ | △ |
| データと処理の整理 | △ | ◎ |
| 再利用や拡張性 | △ | ◎ |
| 初心者へのおすすめ | ◎ | ◯(基本を覚えてから) |
この「クラスとオブジェクト指向」の考え方は、後でニューラルネットワークをクラスで定義するとき(nn.Moduleの継承など)にも活かされます。
3-11. モジュールと import 文:コードの再利用と整理術
Pythonでは、よく使う関数やクラスを別ファイルにまとめておくことで、必要なときに「読み込む」ことができます。これをモジュール化と呼びます。
💡基本の import 文
import math
print(math.sqrt(16)) # => 4.0
import モジュール名でモジュール全体を読み込みます。math.sqrt()のように、モジュール名をつけて関数を呼び出します。
💡特定の関数だけ読み込む(from … import …)
from math import sqrt
print(sqrt(25)) # => 5.0
math.sqrt()のようにモジュール名をつけなくていいので、コードがスッキリします。
💡自作モジュールを使う
たとえば、utils.py というファイルに以下の関数を定義したとします:
# utils.py
def greet(name):
return f"Hello, {name}!"
別ファイルからこれを使うには:
# main.py
from utils import greet
print(greet("Alice"))
✅ モジュール化のメリット
- 何度も使う処理をまとめておける
- チーム開発で役割ごとにコードを分担しやすい
- コードが短く、見やすく、再利用しやすくなる
ディープラーニングやデータ分析では、モデル定義・前処理・評価などをファイルで分けるのが一般的です。
3-12. Pythonでよく使う標準ライブラリ(初心者向け厳選)
Pythonには、最初から使える便利なモジュールがたくさんあります。ここではよく使うものを紹介します。
| モジュール名 | 用途 | 例 |
|---|---|---|
math | 数学関数 | math.sqrt(16)(平方根) |
random | 乱数生成 | random.randint(1, 6)(サイコロ) |
datetime | 日付・時間の操作 | datetime.datetime.now() |
os | ファイル操作、パス操作 | os.listdir() でフォルダ内を確認 |
sys | Pythonの実行環境に関する情報 | sys.argv でコマンドライン引数取得 |
re | 正規表現(文字列検索) | re.search() で文字列マッチ |
json | JSON形式のデータを扱う | Web APIとの連携などに便利 |
🔎 医療分野での使い方の例
import datetime
today = datetime.date.today()
print(f"今日の日付: {today}") # => 今日の日付: 2025-04-23
import random
patient_id = f"PT{random.randint(1000, 9999)}"
print(f"新規患者ID: {patient_id}") # => 新規患者ID: PT4821
3-13. NumPy・Pandasなどの外部ライブラリの導入
Pythonには、最初から使える「標準ライブラリ」に加えて、インストールして使う外部ライブラリ(サードパーティライブラリ)があります。
その中でも、特にデータ分析・AI分野で必須なのが:
- NumPy(ナムパイ):高速な数値計算(行列、ベクトルなど)
- Pandas(パンダス):表形式のデータ(Excelのような表)を効率よく操作
💡 これらを使うには、まずインストール
ターミナル(またはColabのセル)で以下を実行します:
pip install numpy pandasGoogle Colabでは最初から入っているため、すぐに使えます。
NumPy:数値計算の基盤ライブラリ
NumPyは、配列(array)を使った高速な数値処理を提供します。
リストよりも計算が速く、数学的な処理に強いです。
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(a + b) # => [5 7 9]
# 医療データ例:身長と体重の配列を使ったBMI一括計算
heights = np.array([160, 170, 180])
weights = np.array([55, 65, 75])
bmi = weights / (heights / 100) ** 2
print(bmi) # => [21.48 22.49 23.15]
NumPyが便利な理由:
- for文を書かずにベクトル演算できる(=「ブロードキャスト」)
- 線形代数(行列計算)や統計にも対応
- PyTorchなどのライブラリもNumPyを土台にしている
Pandas:データ分析のための表操作ライブラリ
Pandasは、表(行と列)形式のデータ=「データフレーム」を扱えるライブラリです。
import pandas as pd
data = {
"patient_id": ["P001", "P002", "P003"],
"height": [160, 170, 180],
"weight": [55, 65, 75]
}
df = pd.DataFrame(data)
print(df)
# BMI列を追加
df["bmi"] = df["weight"] / (df["height"] / 100) ** 2
print(df)
出力:
patient_id height weight bmi
0 P001 160 55 21.484375
1 P002 170 65 22.491349
2 P003 180 75 23.148148
Pandasが便利な理由:
- CSVファイルやExcelの読み書きが簡単
- 欠損値(NaN)の処理や統計分析も可能
- 医療データの前処理に非常に強い(電子カルテデータなど)
よく使う外部ライブラリ(おまけ)
| ライブラリ名 | 用途 |
|---|---|
matplotlib / seaborn | グラフ描画(可視化) |
scikit-learn | 機械学習モデルの構築と評価 |
PyTorch / TensorFlow | ディープラーニング |
3-14. まとめ
- 変数: 宣言不要、代入するだけでOK(動的型付け)。
- リスト・辞書: さまざまな構造のデータを柔軟に扱う。
- 制御構文:
forやifはインデントによってブロックを構成。 - 関数定義:
def 関数名(引数):、インデントでスコープを示す。 - f-string: 文字列の中に変数を埋め込むのが簡単。
- リスト内包表記: 簡潔な書き方でリストを生成可能。
- インデントとコロンが文法の重要な要素(波括弧
{}を使わない)。 - クラスとオブジェクト指向:データと機能をひとまとまりにして、現実の構造に近い形でコードを設計できる。大規模プロジェクトやディープラーニングのモデル定義では欠かせない考え方。
- import 文で他人や自分が書いた便利な機能を呼び出せる。
- 標準ライブラリを使えば、追加インストールなしで多くの処理が可能。
- 自作モジュールに処理をまとめておくと、後から再利用・保守しやすくなる。
- NumPy:高速なベクトル計算や統計処理
- Pandas:表形式データの読み書き・加工に最適
- pip install で自由に追加・拡張できるのがPythonの強み
これらを把握していれば、PyTorchや他のライブラリを使ったコードも理解しやすくなるはずです。次のステップでは、これらの基礎文法を活かしてディープラーニング用のテンソル操作やニューラルネットワークの構築に取り組んでいきましょう。次回の第2章では、いよいよディープラーニングの心臓部とも言える誤差逆伝播と自動微分の仕組みに迫っていきます。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




