

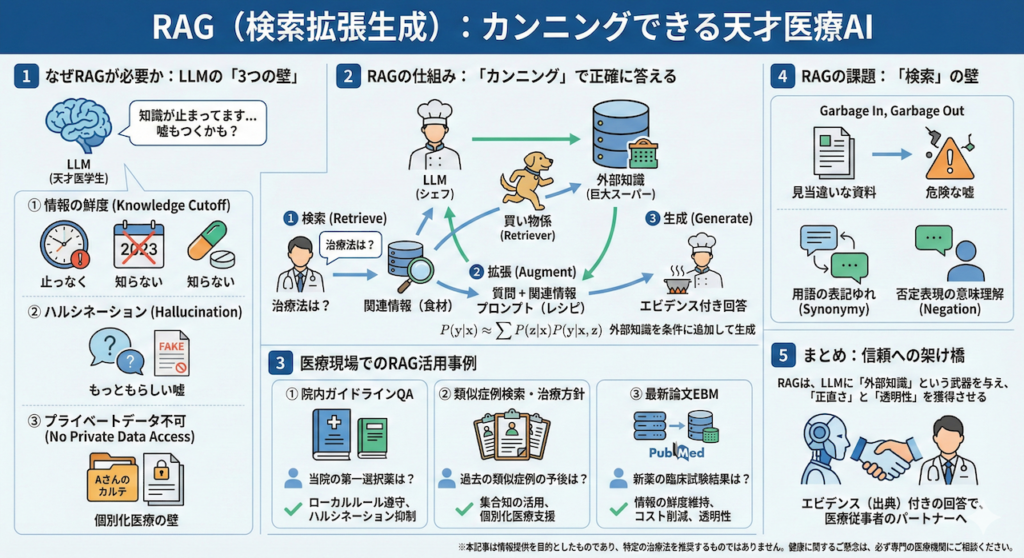
はじめに:その「優秀な医学生」は、なぜ嘘をつくのか?
少し想像してみてください。
ここに、非常に優秀な医学生が一人います。彼は医師国家試験の過去問を全て丸暗記しており、どんな難解な医学用語や病態生理についても、スラスラと流暢に答えることができます。しかし、彼には一つだけ致命的な弱点があります。それは、「最新のガイドラインや、目の前の患者さんの電子カルテを一切見ることが許されていない」という点です。
もし彼に、「今月の『The New England Journal of Medicine (NEJM)』に掲載された新しい治療法について教えて」と尋ねたらどうなるでしょうか? あるいは、「Aさんの昨日の採血データに基づくと、次の処方はどうすべき?」と臨床判断を求めたら?
彼は、自分の記憶(学習データ)の中に答えが存在しないため、確率的に「もっともらしい」言葉を繋ぎ合わせ、真顔で「嘘(ハルシネーション)」をつくかもしれません (Ji et al., 2023)。あるいは、「私の知識は2023年〇月時点で止まっています」と沈黙してしまうでしょう。
これまでのChatGPTなどの大規模言語モデル(LLM)は、まさにこの「試験会場に参考資料を一切持ち込めない(Closed-book)天才」でした。彼らは膨大な知識を持っていますが、それはあくまで過去の記憶に依存しており、外部の情報を参照する術を持たなかったのです。
今回解説するRAG(Retrieval-Augmented Generation:検索拡張生成)は、この天才に対して「教科書、最新論文、そして患者さんのカルテを試験会場に持ち込んで(Open-book)、必要に応じてカンニングしながら答えていいよ」と許可を与える技術です (Lewis et al., 2020)。
これにより、LLMは「嘘をつく確率」を劇的に減らし、常に「根拠(エビデンス)」に基づいた回答ができるようになります。医療AIの実装において、現在最も重要と言っても過言ではないこの技術の全貌を、紐解いていきましょう。
なぜRAGが必要なのか?:LLMの限界と「検索」の融合
医療現場でLLMを活用しようとした際、従来のモデル(RAGなし)では以下の3つの壁に直面します。
- 情報の鮮度(Cutoff Date): LLMの知識は学習終了時点で固定されています。日々更新される医学的知見に対応できません。
- ハルシネーション(Hallucination): 事実に基づかない情報を、あたかも事実のように生成してしまう現象です。患者の安全に関わる医療においては致命的です (Zhang et al., 2023)。
- プライベートデータへのアクセス不可: 汎用的なLLMは、特定の病院内の電子カルテ(EHR)や院内マニュアルを学習していません。
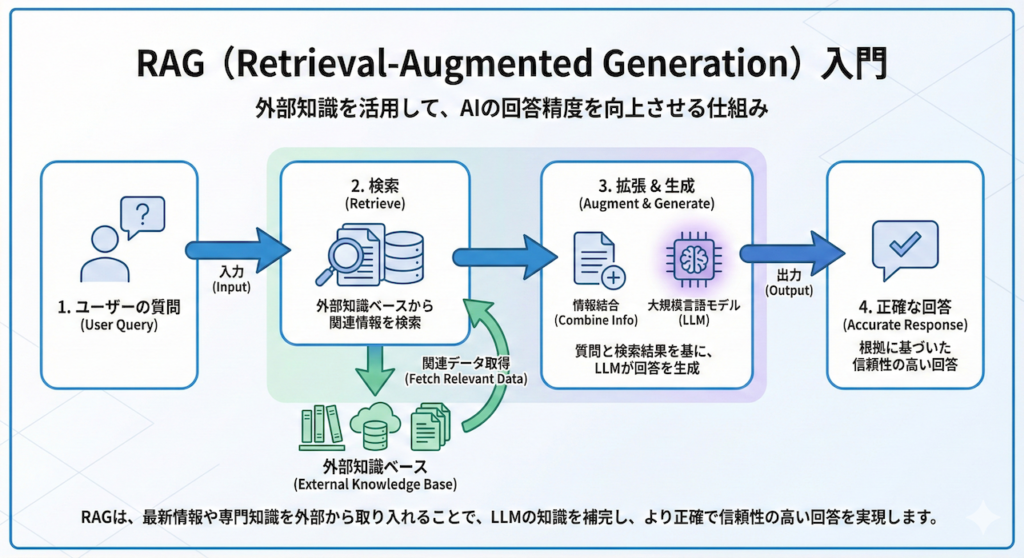
RAGは、外部のデータベース(ベクトルデータベース等)から関連情報を検索(Retrieve)し、その情報をLLMに提示して回答を生成(Generate)させることで、これらの課題を一挙に解決します。これは、医師が診療中にUpToDateやガイドラインを参照し、確実な裏付けを取ってから診断を下すプロセスと全く同じです。
RAGの概念的な仕組みを以下に示します。
1. なぜRAGが必要なのか?:LLMが抱える「3つの欠点」
大規模言語モデル(LLM)は、あたかも全知全能の百科事典のように振る舞いますが、医療現場という「正確性」と「個別性」が命の現場でそのまま使用するには、超えるべき3つの大きな壁が存在します。RAGは、これらの壁を乗り越えるための梯子(ハシゴ)となる技術です。
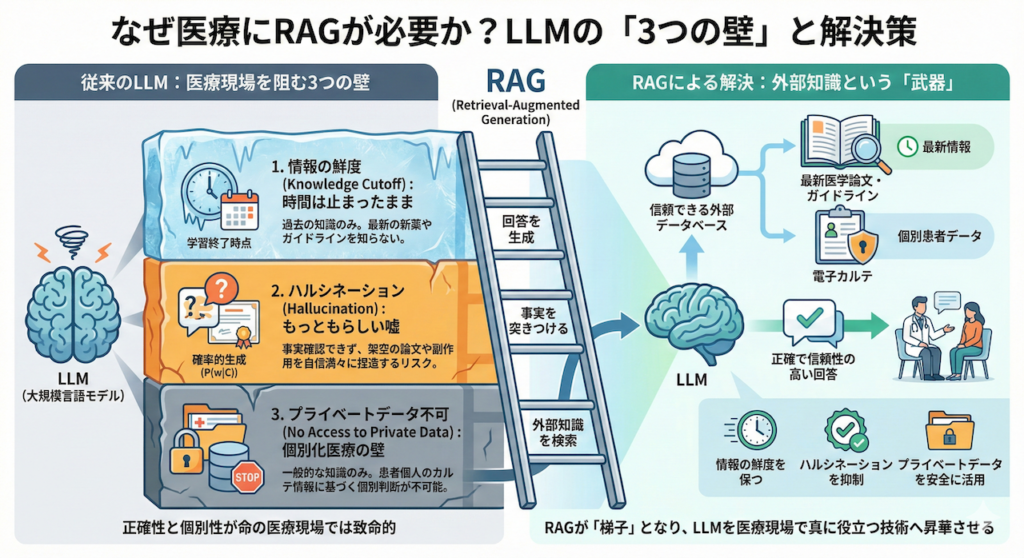
① 情報の鮮度(Cutoff Date):時間は止まったまま
LLMの知識は、AIモデルの学習(Pre-training)が終了した時点で凍結されています。これを「知識のカットオフ(Knowledge Cutoff)」と呼びます。
例えば、学習データが「2023年12月」までのものであれば、そのAIにとって「2024年1月に発表された画期的な新薬」や「先週改訂された診療ガイドライン」は、この世に存在しないことになります。臨床現場では、常に最新のエビデンスに基づいた判断が求められますが、素のLLMは「過去の知識」だけで戦おうとするため、致命的な情報の欠落が生じるのです。
② ハルシネーション(幻覚):もっともらしい嘘
これが医療応用における最大のリスク要因です。LLMの本質は「知識の検索エンジン」ではなく、「確率的な文章生成機(Next Token Predictor)」です。
数理的に言えば、LLMはこれまでの文脈 \( C \) に基づいて、次にくる単語 \( w \) の条件付き確率 \( P(w \mid C) \) を計算し、最も確率的に自然な繋がりを選んでいるに過ぎません。
\[ \hat{w} = \arg\max_{w} P(w \mid \text{Context}) \]
この仕組みゆえに、LLMは「事実かどうか(Factuality)」を検証する機能を持ちません。その結果、文脈としては自然だが事実無根である「存在しない論文の捏造」や「架空の副作用」を、自信満々に出力してしまうことがあります。これをハルシネーション(Hallucination)と呼びます (Ji et al., 2023)。
③ プライベートデータへのアクセス不可:個別化医療の壁
これが臨床において最もクリティカルな問題です。ChatGPTなどの汎用的なLLMは、インターネット上の公開データで学習されていますが、当然ながら「A病院に入院中のBさんの、昨日の血液検査データ」は学習していません。
医療とは、一般的な医学知識(教科書)を、個別の患者さんの状態(カルテ)に適用する行為です。教科書しか持っていないAIには、目の前の患者さんに最適な個別化医療(Precision Medicine)を提供することは不可能なのです。
RAGによる解決:外部知識という「武器」
RAG(Retrieval-Augmented Generation)は、これらの課題を一挙に解決します。LLMに対して、自身の記憶(学習済みパラメータ)だけに頼ることを禁止し、外部の信頼できるデータベース(最新論文や電子カルテ)から関連情報を検索(Retrieve)させます。
そして、その検索結果を「事実(Fact)」として突きつけた上で、回答を生成(Generate)させるのです。これにより、情報の鮮度を保ち、ハルシネーションを抑制し、プライベートデータを安全に活用することが可能になります (Lewis et al., 2020)。
2. RAGの仕組み:カンニングペーパーを作る技術
RAGのプロセスは、大きく分けて3つのステップで構成されています。この仕組みを理解するために、少しお腹が空くかもしれませんが、「一流レストランの厨房」に例えてみましょう。
- LLM(シェフ): 料理の腕(文章生成能力)は超一流ですが、残念ながら厨房の冷蔵庫(記憶)の中身は空っぽです。
- Vector Database(巨大スーパーマーケット): 新鮮な食材(最新の医学論文、ガイドライン、目の前の患者さんのカルテ情報)が大量に陳列されています。
- Retriever(買い物係): シェフからオーダーを受けると、スーパーへ走り、最適な食材を見つけ出してくる優秀なアシスタントです。
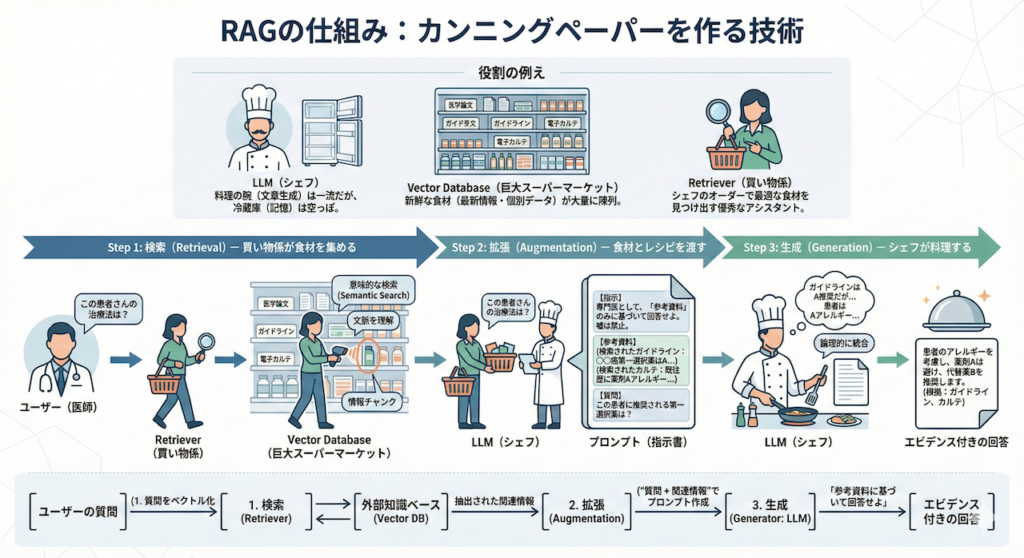
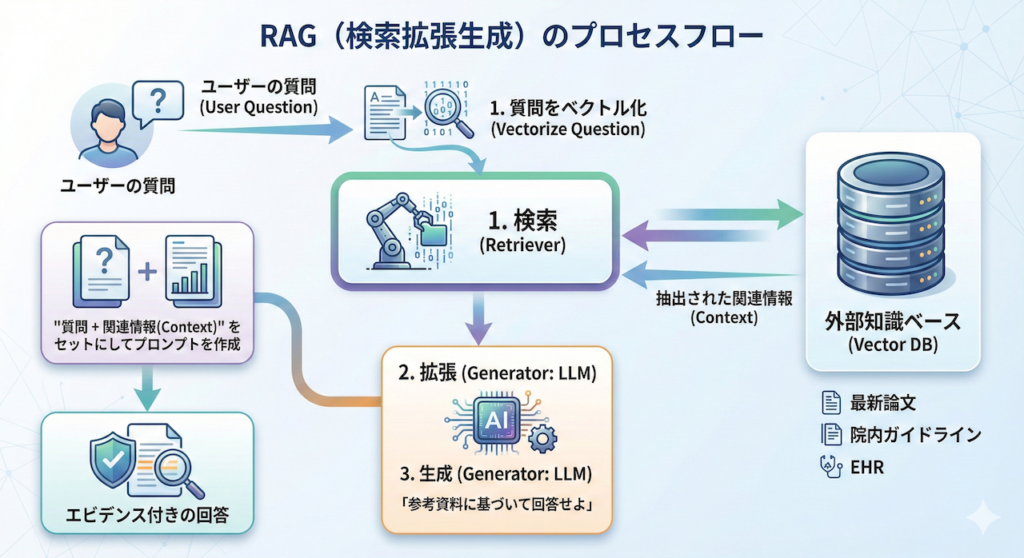
Step 1: 検索(Retrieval)— 買い物係が食材を集める
ユーザー(医師)が「この患者さんの治療法は?」と質問を投げかけたとします。
通常のチャットボットなら、シェフ(LLM)がいきなり空っぽの冷蔵庫を開けて困惑するところです。しかしRAGシステムでは、まずRetriever(買い物係)が動きます。彼は外部のデータベース(ベクトルデータベース)へ走り、質問内容と「意味的に近い」文書チャンク(情報の断片)を探し出します。
ここで重要なのは、単なるキーワード検索(”癌”という文字が含まれるか)だけでなく、文脈や意味(”悪性腫瘍”や”腫瘤”といった関連語も含めた意味的な近さ)を理解して検索する点です。
Step 2: 拡張(Augmentation)— 食材とレシピを渡す
買い物係が帰ってきました。手には、検索で見つかった「参考資料(コンテキスト)」という新鮮な食材が抱えられています。
システムは、ユーザーの元の質問に、この参考資料をくっつけます(拡張します)。具体的には、LLM(シェフ)に対して、以下のようなプロンプト(指示書)を裏側でこっそりと作成して渡すのです。
【指示】
あなたは専門医です。以下の「参考資料」**のみ**に基づいて、質問に答えてください。
もし資料の中に答えがない場合は、正直に「わかりません」と答えてください。嘘をついてはいけません。
【参考資料】
* (検索されたガイドラインの抜粋:〇〇癌の第一選択薬は薬剤Aである...)
* (検索された患者のカルテ情報:既往歴に薬剤Aへのアレルギーあり...)
【質問】
この患者に推奨される第一選択薬は?Step 3: 生成(Generation)— シェフが料理する
準備は整いました。LLM(シェフ)はこの拡張されたプロンプトを受け取ります。
「なるほど、ガイドラインでは薬剤Aが推奨されているが、この患者さんはアレルギーがあるのか」と、渡された資料(食材)を読み解きながら、論理的に整合性の取れた回答を生成(Generate)します。これがRAGによる回答生成のプロセスです。
この一連の流れを図解すると、以下のようになります。
3. 数理的な直感:条件付き確率の変化
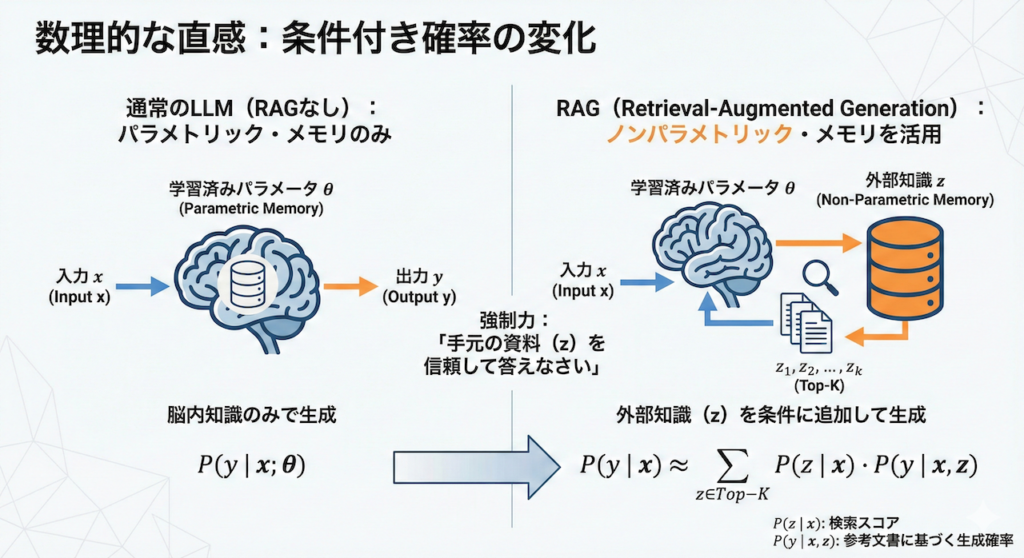
ここで少しだけ、数学的な視点を入れてみましょう。RAGがブラックボックスにならないよう、その裏側で起きている確率の変化を理解するためです。
通常のLLM(RAGなし)は、入力 \( x \) に対して、膨大な学習済みパラメータ \( \theta \)(重み)のみを使って、答え \( y \) を生成します。これは「パラメトリック・メモリ(Parametric Memory)」と呼ばれます。
\[ P(y \mid x; \theta) \]
一方、RAGは外部の知識 \( z \)(検索された文書)を利用します。これは「ノンパラメトリック・メモリ(Non-Parametric Memory)」と呼ばれ、モデルの重み(\( \theta \))を変えずに知識を追加・更新できる部分です。
RAGにおける生成確率は、検索された文書 \( z \) を条件に加えたものになります(Lewis et al., 2020)。
\[ P(y \mid x) \approx \sum_{z \in \text{Top-K}} P(z \mid x) \cdot P(y \mid x, z) \]
- \( P(z \mid x) \): 質問 \( x \) に対して、文書 \( z \) がどれくらい適切か(検索スコア)。
- \( P(y \mid x, z) \): 質問 \( x \) と参考文書 \( z \) がある状態で、答え \( y \) が生成される確率。
つまり、数式的には「自分の脳内知識(\( \theta \))だけでなく、手元の資料(\( z \))を信頼して答えなさい」という強制力が働いているわけです。
4. 医療現場でのRAG活用事例
RAGの登場により、医療AIは単なる「物知りな話し相手」から、臨床判断を支援する「信頼できるアシスタント」へと劇的な進化を遂げました。ここでは、実際に臨床現場で実装が進んでいる3つの主要なユースケースを深掘りします。
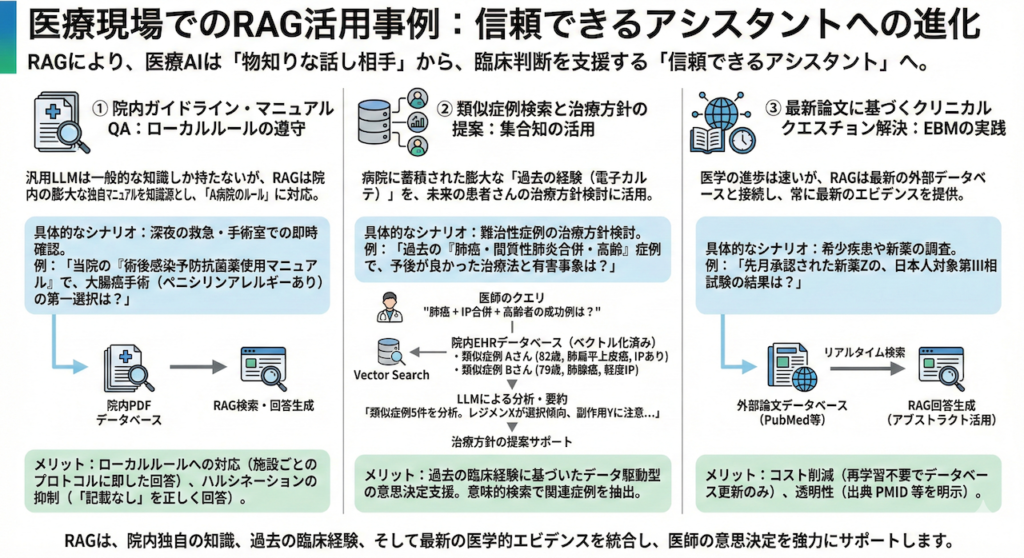
① 院内ガイドライン・マニュアルQA:ローカルルールの遵守
汎用的なLLMは、一般的な医学知識は持っていますが、「A病院のルール」は知りません。RAGは、院内の膨大なPDFマニュアルを知識源とすることで、このギャップを埋めます。
- 具体的なシナリオ: 深夜の救急外来や手術室で、医師が即座に確認したい事項が発生した場合。
「当院の『術後感染予防抗菌薬使用マニュアル』では、大腸癌手術(ペニシリンアレルギーあり)の場合の第一選択は何?」 - RAGの挙動: システムは、学習データ(一般的な教科書)ではなく、病院固有のPDFファイルを検索し、該当ページを根拠として回答します。
- メリット:
- ローカルルールへの対応: 施設ごとに異なる採用薬やプロトコル(レジメン)に即した回答が可能になります。
- ハルシネーションの抑制: 「マニュアルに記載がない場合は『記載がありません』と答える」よう制御することで、勝手な判断を防ぎます。
② 類似症例検索と治療方針の提案:集合知の活用
これは、病院に蓄積された膨大な「過去の経験(電子カルテ)」を、未来の患者さんのために活用するアプローチです。
- 具体的なシナリオ: 治療方針に悩む難治性症例。
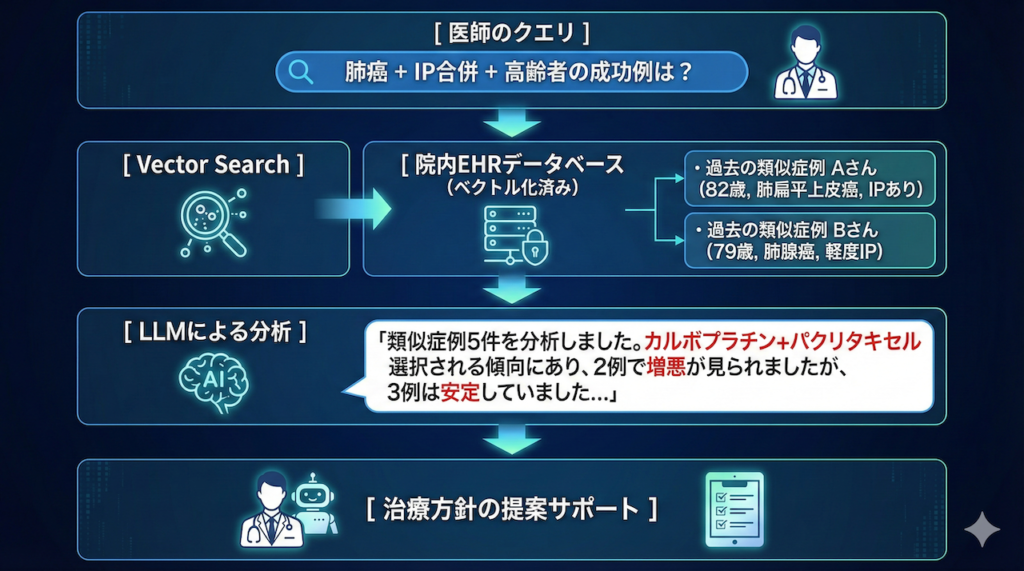
「過去に当院で治療した『肺癌・間質性肺炎合併・高齢(80歳以上)』の症例で、予後が良かった治療法(レジメン)と、発生した有害事象は?」 - プロセス:
- ベクトル化: 過去数年分の退院サマリや経過記録を、AIが読める形式(ベクトル)に変換してデータベース化しておきます。
- 意味的検索: キーワードが完全に一致しなくても、「意味的に近い」症例(同じような背景を持つ患者)を抽出します。
- 要約生成: 抽出された類似症例の治療経過をLLMが読み込み、「多くの症例でレジメンXが選択され、副作用Yに注意が必要でした」といった要約を生成します。
③ 最新論文に基づくクリニカルクエスチョン解決:EBMの実践
医学の進歩は速く、LLMの学習データはすぐに陳腐化します。RAGは、インターネット上の最新データベースと接続することで、常に最新のエビデンスを提供します。
- 具体的なシナリオ: 希少疾患や新しい治療法についての調査。
「先月承認された新薬Zの、日本人を対象とした第III相試験の結果は?」 - RAGの挙動: PubMedや医中誌などのデータベースをリアルタイム(あるいは定期更新)で検索し、該当する論文のアブストラクトを取得して回答を生成します。
- メリット:
- コスト削減: LLM自体を再学習させるには数千万円〜数億円のコストと時間がかかりますが、RAGならデータベースを更新するだけで済みます。
- 透明性: 「この回答は、2024年の〇〇という論文(PMID: 123456)に基づいています」と、必ず出典を明示させることができます。
5. RAGの課題と「検索」の重要性
RAGは、あたかもLLMの欠点を全て補う「魔法の杖」のように見えますが、実はシステム開発の現場では、「G(生成:Generation)」よりも「R(検索:Retrieval)」の方が圧倒的に難しいと言われています。
なぜなら、どれだけ優秀なシェフ(LLM)でも、腐った食材(間違った検索結果)を渡されれば、美味しい料理(正しい回答)を作ることはできないからです。
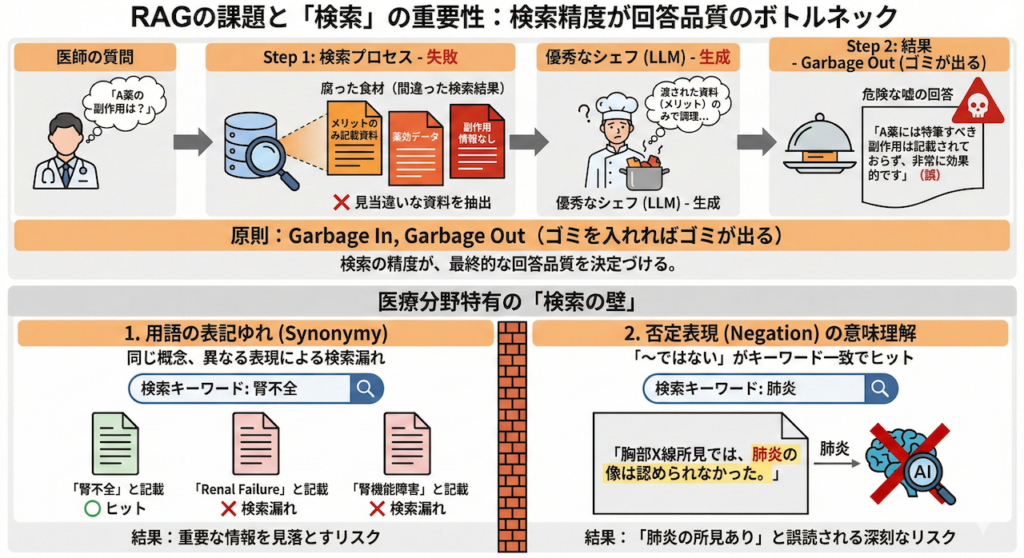
「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」の原則
もし、Step 1の検索プロセスで「見当違いな資料」を持ってきてしまったらどうなるでしょうか?
- シナリオ: 医師が「A薬の副作用」について尋ねた。
- 失敗した検索: 検索システムが誤って「A薬の薬効(メリット)」に関するページばかりを抽出してしまった。
- 結果: LLMは渡された資料(メリットのみ)に基づいて回答を作成するため、「A薬には特筆すべき副作用は記載されておらず、非常に効果的です」という、もっともらしいが危険な嘘を出力してしまいます。
このように、RAGにおいては「検索の精度」が、最終的な回答の品質(Quality of Advice)を決定づけるボトルネックとなります。
医療分野特有の「検索の壁」
特に医療テキストには、一般的なキーワード検索(単語の一致)では対応しきれない、特有の難しさがあります。
1. 用語の表記ゆれ(Synonymy)
同じ概念でも、書き手によって表現が異なります。例えば、「腎不全」の情報を探したいときに、カルテに「Renal Failure」や「腎機能障害」と書かれていれば、単純なキーワード一致では検索漏れ(False Negative)が起きてしまいます。
2. 否定表現(Negation)の意味理解
これが最も深刻です。例えば「肺炎」について検索したとき、キーワード検索では以下の文もヒットしてしまいます。
「胸部X線所見では、肺炎の像は認められなかった。」
この文は「肺炎ではない」という事実を述べていますが、単語としては「肺炎」が含まれているため、検索されてしまいます。これをそのままLLMに渡すと、「肺炎の所見があった」と誤読されるリスクがあります。
まとめ:信頼への架け橋
RAG(検索拡張生成)は、大規模言語モデル(LLM)という天才的な「試験受験者」に対して、「教科書や参考資料を持ち込んで、カンニングしながら答えてもいいよ」と許可を与える技術です。
従来のAI開発では、「いかにしてAIの脳内(パラメータ)に全ての知識を詰め込むか」が競われてきました。しかしRAGは、「知識は外部に置いておき、必要な時に参照すればいい」という逆転の発想で、AIに「正直さ」と「透明性」を獲得させました。
医療従事者がAIを受け入れるための「最低条件」
私たち医療従事者は、根拠のない意見を信用しません。「私の経験上、こう思う」という言葉よりも、「〇〇ガイドラインの推奨グレードAに基づくと、こうすべき」という言葉を信頼します。
RAGによって生成される回答には、必ず以下のような「証拠」が付随します。
「この患者には薬剤Aが推奨されます。
[出典: 日本〇〇学会 ガイドライン2024 第3版 p.45]」
このリンクをクリックすれば、元のPDFの該当ページに飛んで、自分の目で事実確認ができる。これこそが、ブラックボックスであったAIを、臨床現場でパートナーとして受け入れるための最低条件であり、RAGがもたらす最大の価値と言えるでしょう。
次回の予告:AIは「言葉」をどう理解しているのか?
さて、今回少しだけ触れた「ベクトル検索」ですが、コンピュータは一体どうやって「癌」と「悪性腫瘍」が似ている言葉だと理解しているのでしょうか?
次回「L71:ベクトルデータベースと検索」では、このRAGの心臓部である「ベクトル」の世界へ皆さんをご案内します。言葉を「数値の地図」に変える魔法のような仕組みについて、数式を交えながら直感的に深掘りしていきます。
参考文献
- Gao, Y. et al. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv preprint.
- Ji, Z. et al. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), pp. 1–38.
- Lewis, P. et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems, 33, pp. 9459–9474.
- Zhang, Y. et al. (2023). Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models. arXiv preprint.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.



