

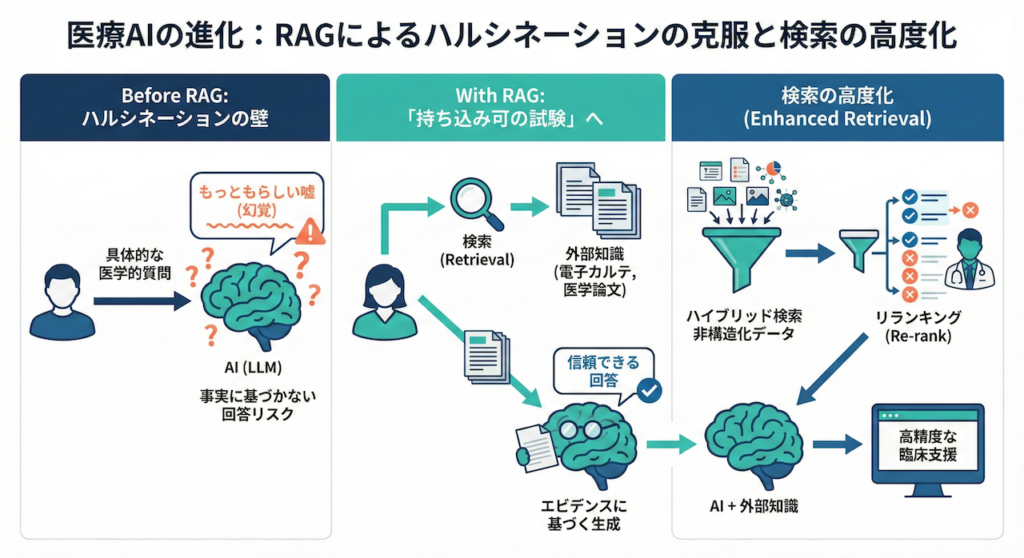
もっともらしい嘘(ハルシネーション)の壁を越える
私たちが日常的に使っているChatGPTなどの生成AIは、とても流暢に文章を作り出しますよね。しかし、医療の現場で「この患者さんの昨日の採血結果は?」「最新のガイドラインに基づく、心不全合併時のこの薬の投与量は?」といった極めて具体的な質問をしたとき、AIが堂々と嘘をつく現象に悩まされたことはないでしょうか。
この「もっともらしい嘘」はハルシネーション(幻覚)と呼ばれ、医療AIの実用化において最大の障壁となっています。実際に、大規模言語モデル(LLM)の医療応用に関する包括的なレビュー論文でも、AIが事実に基づかないもっともらしい医学的回答を生成するリスクが強く警告されており、単なる「言語能力の高さ」と「医学的正確性」は全くの別物であることが指摘されています (Thirunavukarasu et al., 2023)。
RAG:「持ち込み可」の試験に変える技術
この致命的な問題を解決するために誕生したのが、RAG(検索拡張生成:Retrieval-Augmented Generation)という技術です。RAGとは、AIに記憶の中だけで答えさせるのではなく、まず信頼できる外部の知識(自院の電子カルテや、最新の医学論文データベースなど)を読ませてから答えさせる仕組みです (Lewis et al., 2020)。
例えるなら、記憶力と文章作成能力は抜群だけれど時々勘違いをする研修医に対して、あらかじめ該当する患者のカルテと最新の診療ガイドラインを渡し、「まずはこの資料をしっかり読んでから、答えをまとめてね」と指示を出すようなものです。つまり、AIに「持ち込み可の試験」を受けさせるようなアプローチだと言えます。
本シリーズの第30回からこのRAGの基礎を学んできましたが、今回はその心臓部とも言える「いかに正しく、目的の情報を探し出してくるか(リトリーバの高度化)」というテーマに切り込んでいきます。
単一の検索では不十分な理由:2つの強力な武器
結論から言うと、本当に臨床で役立つ医療用RAGを作るには、単一の検索方法では不十分です。なぜなら、最初のステップでAIに「間違った資料」や「関係のないカルテ」を渡してしまえば、どれだけAIの文章力が高くても、間違った答えしか返ってこないからです(これを情報科学の世界では Garbage In, Garbage Out と呼びます)。
そこで本稿では、非構造化データであるテキストの山から、正確な情報を引き上げるためのアプローチを探求します。具体的には、検索精度を飛躍的に高める「ハイブリッド検索」と、見つけた情報(資料)の質を専門医のように見極める「リランキング(Re-rank)」という2つの強力な武器について、直感的にわかりやすく解説していきます。
なぜ、検索(リトリーバ)の高度化が必要なのか?
RAGシステムは、大きく分けて「検索(Retrieve)」と「生成(Generate)」という2つのステップで動きます。この仕組みは、料理に例えてみると非常にわかりやすいかもしれません。
どんなに腕の立つ一流のシェフ(優秀な言語モデル:LLM)にお願いして美しい料理(文章)を作ってもらおうとしても、最初にアシスタントが持ってきた食材(「検索」で見つけてきたカルテの記録や論文)が間違っていたり、腐っていたりすれば、完成する料理(出てくる答え)は当然間違ったものになってしまいますよね。つまり、LLMのポテンシャルを最大限に引き出すためには、いかに正しく新鮮な食材を揃えるかという「検索」の質が決定的に重要なのです。
主流となる「ベクトル検索」の魔法と仕組み
現在、RAGの検索手法として世界中で主流となっているのが「ベクトル検索」という技術です。
これは、文章が持つ「意味」や「ニュアンス」を、AIが理解できる数値の配列(ベクトル)に変換し、多次元の空間上で距離が近い(=意味が似ている)文章を探してくるという画期的なアプローチです。
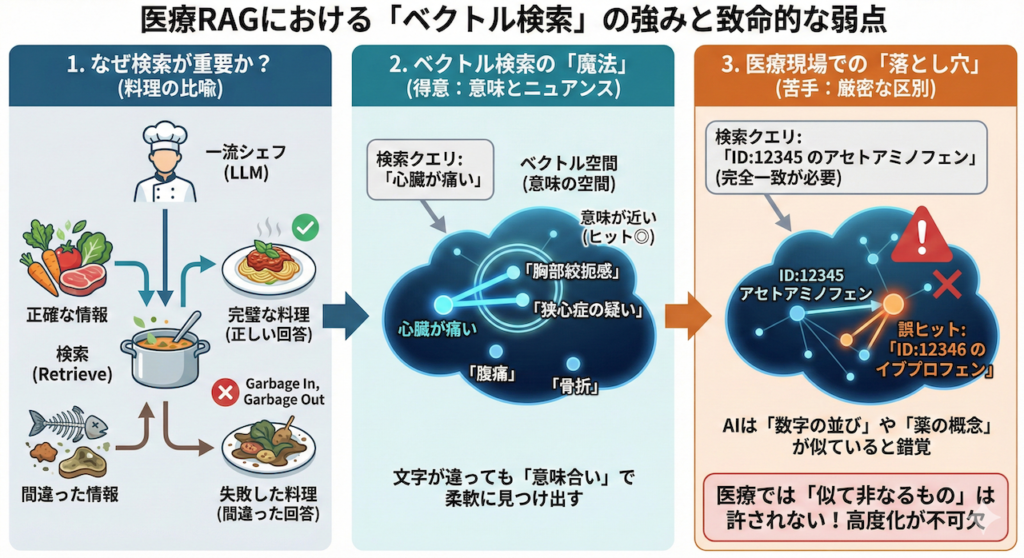
たとえば、自院のデータベースに対して「心臓が痛い」と検索したとしましょう。従来の検索システムでは「心臓」「痛い」という文字が入っていないとヒットしませんでしたが、ベクトル検索を使えば、「胸部絞扼感」や「狭心症」といった言葉を含むカルテ記録を、文字が全く一致していなくても、その「意味合い」の近さから見事に引っ張ってくることができます (Karpukhin et al., 2020)。人間が言葉の裏にある意図を汲み取るような、この柔軟性こそがベクトル検索の強みです。
医療現場における「意味検索」の致命的な弱点
しかし、医療現場において、この「意味検索」だけに頼ることは、時に致命的な弱点となります。ここがRAG構築の落とし穴なのですが、ベクトル検索は「大まかなニュアンス」を捉えるのは得意でも、「厳密な区別」がとても苦手なのです。
例えば、「患者ID: 12345 のアセトアミノフェンの処方歴」を探したい場面を想像してみてください。
ベクトル検索にこの指示を出すと、AIは良かれと思って「12346」という似た並びの別患者のIDや、「イブプロフェン」という同じ鎮痛解熱薬のカテゴリーに属する情報を上位に持ってきてしまうことが頻繁に起こります。AIの脳内(ベクトル空間)では、「12345」と「12346」はただの数字の羅列として非常に近くに配置されており、「アセトアミノフェン」と「イブプロフェン」も同じ「薬」という概念として近くにまとめられているからです。
つまり、特定の患者を間違いなく特定するための固有名詞や、絶対に間違えてはならない検査値などの「完全一致」を要求される検索は、ベクトル検索の最も苦手とする分野なのです。
医療において「似ているけれど違う薬」を処方してしまうことは絶対に許されません。だからこそ、RAGを医療現場で安全に使うためには、ベクトル検索の弱点を補う、より高度な検索の仕組み(リトリーバの高度化)が不可欠なのです。
ハイブリッド検索:意味と文字の「いいとこ取り」
ベクトル検索の弱点(固有名詞や厳密な数字の区別が苦手)を補うために、現代のRAGシステムで標準的に使われているのが「ハイブリッド検索」です。
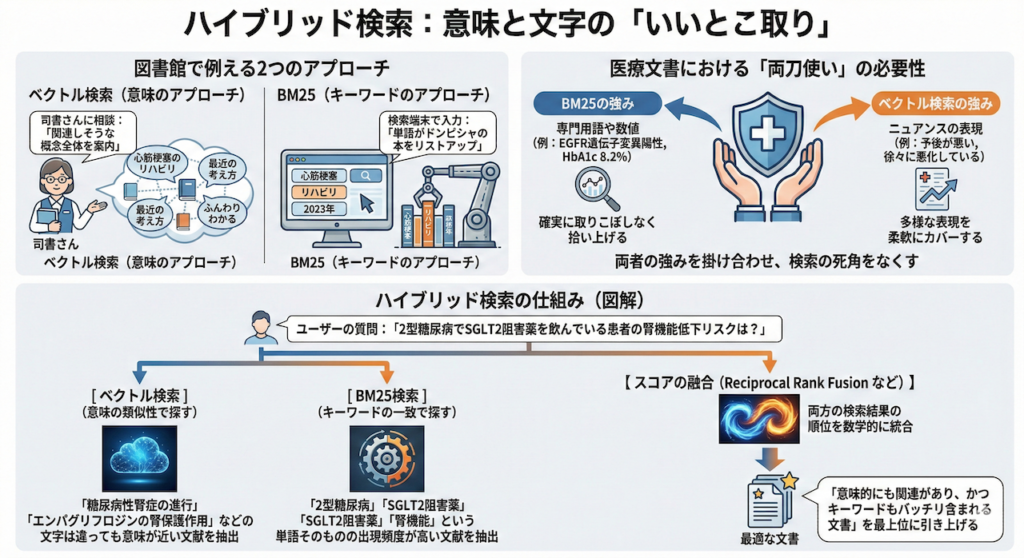
これは名前の通り、最新のAI技術である「ベクトル検索(意味合いで探す)」と、昔ながらの強力な「キーワード検索(文字の完全一致で探す)」を同時に走らせ、両方の結果の「いいとこ取り」をして融合させる手法です。
図書館で例える2つのアプローチ
キーワード検索の代表格として、現在でも広く使われているのが「BM25」と呼ばれるアルゴリズムです。これがどういうものか、図書館で本を探すときのことを想像して比較してみましょう。
- ベクトル検索(意味のアプローチ):図書館のベテラン司書さんに「なんかこう、心筋梗塞のリハビリについて、最近の考え方がふんわりわかる本ある?」と相談し、関連しそうな概念の本棚全体を案内してもらうようなイメージです。
- BM25(キーワードのアプローチ):検索端末の画面に「心筋梗塞」「リハビリ」「2023年」と打ち込み、その単語がドンピシャで目次や本文に含まれている本を機械的にリストアップするイメージです。
医療文書検索における「両刀使い」の必要性
医療文書の検索において、精度の高い回答を得るためには、この両方が絶対に必要になります。
例えば、カルテの中から情報を探すとき、「EGFR遺伝子変異陽性」や「HbA1c 8.2%」といった特定の専門用語や数値は、BM25を使って確実に取りこぼしなく拾い上げる必要があります。一方で、「予後が悪い」「徐々に悪化している」といった、医師によって書き方が多様に変化するニュアンスの表現は、ベクトル検索の柔軟性でカバーするのです。このように、両者の強みを掛け合わせることで、検索の死角をなくすことができます。
数式で見るBM25の面白さ:情報の「レア度」を測る
ここで少しだけ、キーワード検索の王様であるBM25の仕組みの裏側を覗いてみましょう。「数式はちょっと…」と思うかもしれませんが、ご安心ください。やっていることは、驚くほど「人間の感覚」に近いんです。
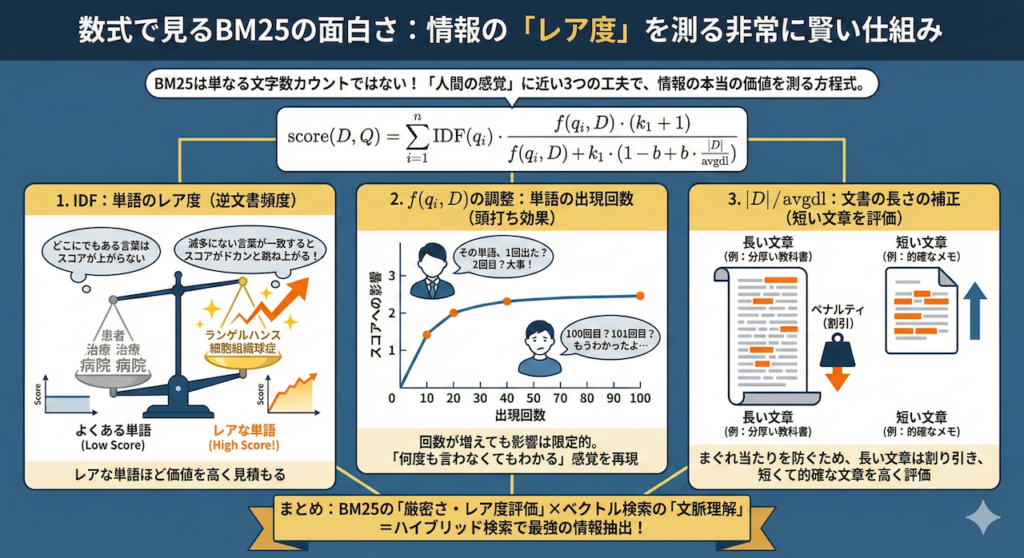
BM25は、単純に「検索した単語がたくさん入っている文章が一番エライ」という単純な文字数カウントではありません。「レアな単語が入っている文章の価値を、より高く見積もる」という、非常に賢い仕組みを持っています (Robertson et al., 2009)。
ある文書の山(コーパスと呼びます)の中から、検索キーワード \( Q \) に関連するある文書 \( D \) のスコアは、次のように計算されます。
\[ \text{score}(D, Q) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \cfrac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot \left(1 – b + b \cdot \cfrac{|D|}{\text{avgdl}}\right)} \]
数式が意味する「とても人間的な」3つの工夫
少し難しく見えるかもしれませんが、この数式は大きく3つの賢いパーツからできています。ここが面白いところなんです。
- \( \text{IDF}(q_i) \) は「単語のレア度(逆文書頻度)」です。
医療カルテの中で「患者」や「治療」という単語は、どの文書にも頻繁に出てきますよね。そういう「どこにでもある言葉」が一致しても、スコアはほとんど上がりません。逆に、「ランゲルハンス細胞組織球症」のような滅多に出現しないレアな単語が一致すれば、「これは探している情報に違いない!」と判断して、スコアがドカンと跳ね上がります。 - \( f(q_i, D) \) は「単語の出現回数(Term Frequency)」の調整です。
分母と分子の両方にこの項目があるのがミソです。これにより、「その単語が1回出たか、2回出たか」の差は大きく評価するけれど、「100回出たか、101回出たか」の差はほとんど無視するようになっています(上限が設定されている状態)。「何度も言わなくても、わかってるよ」という人間の感覚と同じですね。 - \( \cfrac{|D|}{\text{avgdl}} \) は「文書の長さの補正」です。
やたらと長い文章(例えば分厚い教科書を丸ごと1つのデータにしたもの)には、まぐれで検索キーワードが含まれてしまう確率が高くなります。そのため、長い文章はスコアを少し割り引き、逆に「短い文章なのにキーワードがピタッと含まれているもの」を、より的確な情報として高く評価します。
このように、BM25は長年培われてきた「情報の本当の価値」を測るための、洗練された方程式なのです。ハイブリッド検索では、このBM25の「厳密さ・レア度の評価」と、ベクトル検索の「文脈の理解」を掛け合わせることで、驚くほど正確な情報抽出を実現しています。
リランキング(Re-rank):集めた情報を専門医のように「目利き」して並べ替える
前回のステップである「ハイブリッド検索」によって、数百万件もの膨大なカルテや論文の海から、探したい情報が含まれている可能性が高い文書をトップ50件まで絞り込むことができました。しかし、これをそのまま言語モデル(LLM)に丸投げして答えを作らせると、医療現場で使うにはまだ少し精度が足りないことがあります。
なぜなら、最初の検索(ベクトル検索やBM25)は、とてつもない量のデータの中から「爆速で」候補を拾い上げることを最優先しているため、計算をかなり簡略化しているからです。この一次検索では、一般的にBi-Encoder(バイ・エンコーダー)と呼ばれる仕組みが使われています。
ここで、検索の総仕上げとして「リランキング(再ランキング)」という工程を行います。一度絞り込んだ少数の候補(例えば50件)に対して、今度は時間をかけてじっくりと「ユーザーの質問の意図と、見つけてきた文書の文脈が本当に噛み合っているか」を精密検査し、最適な順序に並べ替えるのです。
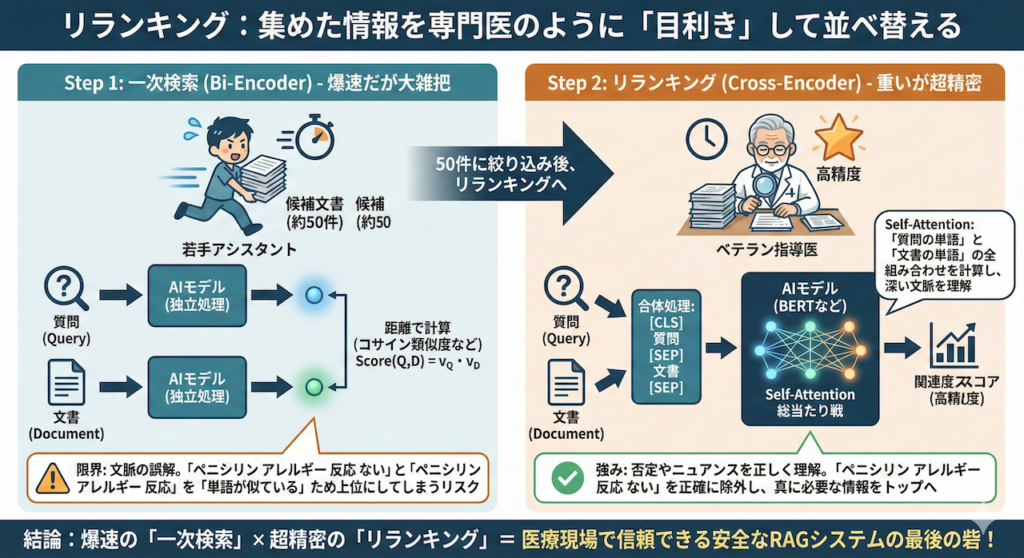
一次検索(Bi-Encoder)の限界とは?
Bi-Encoderは、質問文とデータベースの文書を「別々に」ベクトル化して、その角度の近さ(コサイン類似度や内積)だけでスコアを計算します。数式で表すと、非常にシンプルです。
\[ \text{Score}(Q, D) = \mathbf{v}_Q \cdot \mathbf{v}_D \]
ここで、\( \mathbf{v}_Q \) は質問(Query)のベクトル、\( \mathbf{v}_D \) は文書(Document)のベクトルです。あらかじめ全ての文書のベクトルを計算して保存しておけるため、検索は一瞬で終わります。
しかし、これには弱点があります。質問と文書を別々に処理するため、「質問の中の『悪化』という単語」と「文書の中の『改善』という単語」がどう関係しているかといった、複雑な文脈の絡み合いを評価できないのです。例えば、「ペニシリンによるアレルギー反応はない」というカルテ記録を、「ペニシリンのアレルギー反応」について質問した際に、「言葉の意味が近いから」と上位に持ってきてしまうリスクがあります。
Cross-Encoderによる精密な文脈理解
この限界を突破するのが、リランキングで主役となるCross-Encoder(クロス・エンコーダー)と呼ばれるディープラーニングのモデルです (Nogueira and Cho, 2019)。
これを医療現場のチーム医療に例えるなら、こんなイメージです。
- 一次検索(Bi-Encoder + BM25):若手の優秀なアシスタントが、広大な医局の書庫を全力疾走し、「先生、関連しそうなファイルを50冊持ってきました!」と机にドサッと積む作業です。とんでもなく速いですが、内容は少し大雑把です。
- リランキング(Cross-Encoder):ベテランの指導医が、その50冊のファイルを1つ1つ丁寧に開き、今回の患者さんの複雑な病歴や質問の意図とじっくり照らし合わせて、「この記録は表面的には似てるけど別の話だな」「お、この3ページ目の記述は今回の症例にドンピシャだ」と吟味し、本当に重要なトップ5冊を厳選して並べ直す作業です。
数学的に見るCross-Encoderの深さ
Cross-Encoderでは、ユーザーの「質問文 (\( Q \))」と、検索してきた「候補の文書 (\( D \))」を特殊なトークン(区切り文字)で一つの長い文章のようにつなげて、BERTなどの言語モデルに入力します。
\[ \text{Score}(Q, D) = \text{BERT}(\text{[CLS]} \, Q \, \text{[SEP]} \, D \, \text{[SEP]}) \]
- \( \text{[CLS]} \) は文全体の特徴をまとめるための特殊な記号、\( \text{[SEP]} \) は質問と文書の区切りを表す記号です。
このように合体させて入力することで、AI内部のSelf-Attention(自己注意機構)という計算が働きます。これにより、「質問の中にある『投与量』という単語」が、「文書の後半にある『5mg』という数字」と強く結びついていることを、文脈全体から数学的に割り出すことができるのです。
この総当たり戦の計算(テンソル行列の掛け算)を候補文書の数だけ繰り返すため、計算コスト(時間とコンピューターのパワー)は非常に高くなります。そのため、数百万件のデータ全てにCross-Encoderをかけることは物理的に不可能です。しかし、一次検索で50件程度に絞り込んだ後であれば、数秒でこの「目利き」を完了させることができます。
医療分野のように、否定表現、時系列の変化、微妙なニュアンスの違いが患者の命に関わる領域では、このCross-Encoderによる「圧倒的な文脈の理解度」が、安全で信頼できるRAGシステムを構築するための最後の砦となります。
医療文書の複雑な文脈を読み解く:なぜリランキングが命綱になるのか
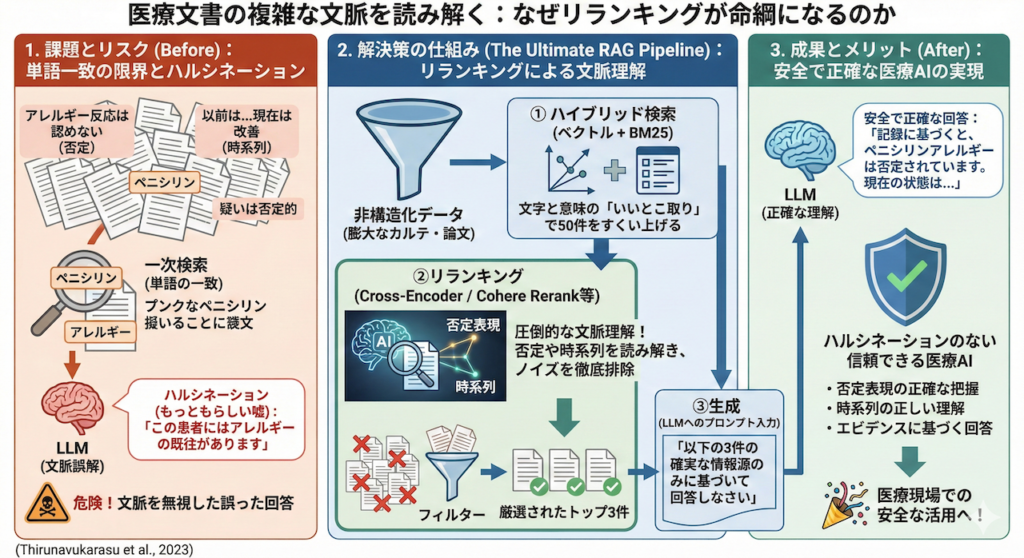
私が医療NLP(自然言語処理)に携わる中で痛感するのは、医療文書の厄介さです。一般的なニュース記事やブログとは異なり、カルテには独特の複雑さがあります。
例えば、「否定表現(〜を認めない、〜の疑いは否定的)」や「時系列の逆転(以前は〜だったが、現在は〜に改善)」といった表現です。大規模言語モデルの医療応用に関する研究においても、こうした単語の表面的な一致だけでは捉えきれない複雑な文脈が、AIを混乱させる主要な原因であることが指摘されています (Thirunavukarasu et al., 2023)。
もし、一次検索の結果だけをそのままLLMに渡してしまったらどうなるでしょう?「ペニシリン」や「アレルギー」という単語がたくさん入っているという理由だけで、「アレルギー反応は認めない」という記録を根拠に、「この患者にはアレルギーの既往があります」とLLMが知ったかぶり(ハルシネーション)をしてしまう危険性があるのです。
まとめ:正確な情報を引き上げるための「標準装備」
リランキング技術を導入することで、LLMは関係のないノイズを排除した、本当に質の高い情報(コンテキスト)だけを読み込んで回答を生成できるようになります。これは、医療安全の観点から見て、RAGの信頼性を劇的に高める決定打となります。
非構造化データであるテキストの山から、いかにして正確な情報を引き上げるか。今回解説した「ハイブリッド検索による網羅的な収集」と「リランキングによる精密な目利き」の組み合わせは、もはや医療NLPの最前線において欠かせない「標準装備」となっています。これから医療分野でRAGを構築しようと考えている方は、ぜひこの強力な武器をシステムに組み込んでみてください。
参考文献
- Nogueira, R. and Cho, K. (2019). Passage Re-ranking with BERT. arXiv preprint.
- Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D. and Yih, W.-t. (2020). Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S. and Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems, 33, 9459–9474.
- Robertson, S., Zaragoza, H. and Taylor, M. (2009). The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval, 3(4), 333–389.
- Thirunavukarasu, A. J., Ting, D. S. J., Elangovan, K., Gutierrez, L., Ting, T. F. and Ting, D. S. W. (2023). Large language models in medicine. Nature Medicine, 29(8), 1930–1940.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




