

TL; DR (要約)
「正解率99%」のAIでも、実際には役に立たないことがあります。
AIの性能評価とは、単なる点数ではなく「誰を、なぜ、どう間違えたか」を深く分析する、総合的な成績表を読む作業です。
① 正しい成績の付け方
- 再現率 (Recall):
🔍 病気の人をどれだけ見逃さなかったか? (スクリーニングで重要) - 適合率 (Precision):
🎯「陽性」予測のうち、本当に陽性だったのは? (誤報を避けたい時に重要) - F1スコア:
⚖️ 再現率と適合率のバランス。 - AUC:
📈 しきい値に依らない、モデルの総合的な識別能力。
② 数字の裏側を見る
技術的に優れても、臨床で役立つとは限りません。
- エラー分析:
「なぜ」「どう」間違えたかを質的に分析。 - ユーザビリティ:
医師にとって本当に使いやすいか?ワークフローを改善するか?
③ 潜在能力を引き出す
ハイパーパラメータ最適化で、AIの「育て方」を調整し、性能を最大化します。
目的: 過学習(訓練データに特化しすぎ)と未学習(単純すぎ)の間の、最適なバランスを見つけること。
| この章の学習目標 | 1. 適切な評価指標の選択: 分類・回帰・生成といったAIモデルのタスクに応じて、適切な性能評価指標を選択できるようになる。 2. 診断AIの指標解釈: 医療診断で特に重要なROC曲線、AUC、適合率、再現率、F1スコアなどの意味を正しく解釈し、そのトレードオフを理解する。 3. 臨床的有用性の評価: 定量的なスコアだけでは測れない「臨床現場での本当の価値」を評価するための、定性的なアプローチの重要性を学ぶ。 4. ハイパーパラメータ最適化: AIモデルの性能を最大化するための、ハイパーパラメータチューニングの基本概念を理解する。 |
| 前提となる知識 | ・AIモデルの「学習(訓練)」と「検証」の基本的な流れの理解 ・(推奨)感度(Sensitivity)、特異度(Specificity)といった、臨床検査における基本的な評価用語の知識 |
はじめに:その「正解率99%」、本当に信じて大丈夫?
これまでの講座を通じて、私たちは様々なAIモデルを構築する技術を学んできました。コードを書き、試行錯誤の末にモデルの学習を終え、AIが初めてもっともらしい予測を出力してくれた瞬間。それは、開発者にとって、大きな達成感と興奮を覚える瞬間だと思います。
しかし、ここからが科学者・臨床家としての、最も重要な仕事の始まりです。そのAIの出した答えは、どれほど優れているのでしょうか?「正解率99%」という結果が出たとして、私たちはそれを手放しで喜んで良いのでしょうか?
この問いに答えるのが、モデルの性能評価です。AIの性能評価は、まるで学生の成績を評価するプロセスによく似ています。一つのテストの点数(例えば、総合正解率)だけを見て「優秀だ」と判断するのは非常に危険です。得意科目(特定のデータには強い)と不得意科目(別のデータには弱い)を見極め、どのような間違いを、なぜ犯したのかを分析し、そして、どうすればさらに成績が伸びるのか(チューニング)を考える。この一連のプロセスを経て初めて、私たちはAIの真の実力と限界を理解し、責任を持って臨床応用への道を検討できるのです。
本講座「作って理解する!シリーズ医療×生成系AI」の第15回は、このAIの「成績表」を正しく読み解き、その能力を最大限に引き出すための、性能評価とチューニングの世界を探ります。
この記事では、第15回で学ぶ4つの重要なトピックの全体像を、ダイジェストでご紹介します。なお、本記事は各トピックの概要を掴んでいただくためのサマリーです。各種評価指標の厳密な数理的定義や、ハイパーパラメータ最適化の具体的な実装手法については、15.1以降の個別記事で丁寧に解説していきますので、ご安心ください。
15.1 タスクに応じた「ものさし」の選択:適切な評価指標とは?
AIの「成績」を正しく評価するための第一歩、それは、そのAIが解いている「試験問題の種類(タスク)」を正確に理解し、それに合った「採点基準(評価指標)」を選ぶことです。国語の能力を、数学のテストで測ることができないのと同じで、AIの能力も、その目的とかけ離れたものさしで測っても、意味のある評価はできません。
私たちが医療分野でAIを応用する際、そのタスクは、大きく分けて以下の3種類に分類されることが多いです。それぞれのタスクが何を目指していて、どんな「ものさし」で測られるのかを見ていきましょう。
① 分類 (Classification):「これは、AかBか?」を判定するタスク
分類とは、与えられた入力データを、事前に定義された複数のカテゴリー(クラス)のいずれかに割り当てる、最も基本的で重要なタスクです。
医療での具体例:
- 2値分類: ある病変の画像が「良性」か「悪性」か。ある患者さんが「疾患あり」か「疾患なし」か。
- 多クラス分類: 胸部X線写真から「正常」「肺炎」「肺がん」「結核」のいずれかを判定する。
このタスクは、まさに診断行為そのものに直結するため、医療AIにおいて最も頻繁に扱われます。
② 回帰 (Regression):「その数値は、いくつになるか?」を予測するタスク
回帰とは、連続的な数値を予測するタスクです。カテゴリーに分けるのではなく、具体的な「量」を当てる問題だと考えると分かりやすいでしょう。
医療での具体例:
- 患者さんの年齢、体重、検査値から、1年後のHbA1c値を予測する。
- ICU患者のバイタルサインデータから、24時間後の死亡確率を予測する。
- 特定の抗がん剤を投与した際の、腫瘍の縮小率(%)を予測する。
③ 生成 (Generation):「新しい何かを、創り出す」タスク
生成とは、これまでの講座でも見てきたように、AIが学習したデータに基づいて、この世に存在しない新しいデータ(テキスト、画像、化合物など)を創造するタスクです。
医療での具体例:
- 電子カルテの自由記述から、退院サマリーの文章を自動生成する。
- 希少疾患のCT画像を学習し、新しいバリエーションの「合成CT画像」を生成する(データ拡張)。
- 創薬ターゲットとなるタンパク質に結合する可能性のある、新しい化合物の構造(SMILES文字列)を生成する。
これらのタスクと、それぞれを評価するための代表的な指標をまとめたのが、以下の表です。
| モデルのタスク種類 | 目的 | 主要な評価指標(ものさし)の例 |
|---|---|---|
| 分類 (Classification) | カテゴリへの割り当て | 正解率、適合率、再現率、F1スコア、AUC |
| 回帰 (Regression) | 連続値の予測 | MAE (平均絶対誤差)、RMSE (二乗平均平方根誤差) |
| 生成 (Generation) | 新規データの創造 | ROUGE, BLEU (テキスト)、FID, IS (画像) |
本記事の残りの部分、そしてこの第15回の講座全体を通じて、私たちは特に、医療AIの応用で最も頻繁に遭遇し、かつ解釈に深い洞察が求められる「分類タスク」の評価指標を、詳しく、そして実践的に掘り下げていきます。
まずは、なぜ単純な「正解率」だけでは不十分なのか、その落とし穴から見ていきましょう。
15.2 診断AIの成績を読み解く:ROC曲線と適合率・再現率の重要性
「正解率99%」という数字の魔力と、その裏側
さて、AIモデルの学習を終え、いよいよ性能評価です。テストデータで試したところ、「正解率99%」という素晴らしい結果が出たとしましょう。この数字を見ると、思わず「やった!」と声を上げてしまいたくなるかもしれません。
しかし、この「99%」という数字、本当に手放しで喜んで良いものなのでしょうか?
ここで、少し想像してみてください。あなたが開発しているのは、非常に稀な疾患(例えば、1000人に1人の有病率)を発見するための診断支援AIです。1000人分のテストデータ(うち、真の患者は1人)で評価したところ、AIは全員を「陰性(疾患なし)」と予測しました。
このAIの正解率はどうなるでしょう? 999人の健常者を正しく「陰性」と判定しているので、正解率は99.9%です。数字上は、ほぼ完璧なAIに見えます。しかし、臨床の現場ではどうでしょうか。最も見つけなければならない、たった1人の患者を見逃してしまっています。これでは、診断支援AIとしては全く役に立たない、むしろ存在しない方がマシ、とさえ言えるかもしれません。
このように、特に症例数に偏りがある(不均衡データ, Imbalanced Data)医療分野において、単純な正解率(Accuracy)は、モデルの真の性能を見誤らせる「評価の罠」となり得ます。私たちが本当に知りたいのは、AIが「何を正解し、何を間違えたのか」という、その内訳なのです。
評価の土台:混同行列(Confusion Matrix)を理解する
AIの予測結果の内訳を整理し、性能評価の土台となるのが混同行列(Confusion Matrix)です。これは、AIの予測と「真実の答え」を比較し、4つのパターンに分類する表です。いわば、AIのテスト結果を項目別に分析するための「通信簿」のようなものだと考えてください。
この4つのマスには、それぞれ非常に重要な意味があります。
- 真陽性 (True Positive, TP): 「本当に陽性」のものを、AIが正しく「陽性」と予測できたケース。AIが病変を正しく指摘できた場合など、モデルの最も望ましい成果です。
- 真陰性 (True Negative, TN): 「本当に陰性」のものを、AIが正しく「陰性」と予測できたケース。健常な人を正しく「問題なし」と判断できた場合です。
- 偽陽性 (False Positive, FP): 「本当は陰性」のものを、AIが誤って「陽性」と予測してしまったケース。「狼少年」のような誤報で、不要な精密検査や患者の不安につながる可能性があります。第一種過誤 (Type I Error)とも呼ばれます。
- 偽陰性 (False Negative, FN): 「本当は陽性」のものを、AIが誤って「陰性」と予測してしまったケース。これが臨床的に最も危険な「見逃し」であり、治療機会の損失に直結します。第二種過誤 (Type II Error)とも呼ばれます。
単純な正解率(Accuracy)は、これら4つの合計のうち、正しく予測できたTPとTNの割合(\( \frac{TP+TN}{TP+FP+FN+TN} \))に過ぎません。不均衡データの問題では、大多数を占めるTNの数が大きくなるため、FNやFPの数が見えにくくなってしまうのです。
臨床シナリオで使い分ける:適合率・再現率・F1スコア
混同行列を理解した上で、いよいよ臨床現場で本当に意味のある評価指標を見ていきましょう。特に重要なのが、適合率(Precision)と再現率(Recall)です。
再現率 (Recall / 感度 / 真陽性率): 見逃しを許さないための指標
再現率は、「本当に陽性の人たちのうち、AIがどれだけを『陽性』と正しく見つけ出せたか」の割合です。臨床検査で使われる感度(Sensitivity)と全く同じ概念です。
数式で表すと、以下のようになります。
\[ \text{再現率 (Recall)} = \frac{TP}{TP + FN} \]
分母の \( TP + FN \) は「本当に陽性だった人の総数」を意味します。この指標は、偽陰性(FN)、つまり「見逃し」をどれだけ減らせるかを示しています。
- 重視されるシナリオ: がん検診や感染症のスクリーニング検査など。
- 考え方: ここでの最優先事項は、病気の人を見逃さないことです。たとえ健康な人を誤って「陽性の疑いあり(偽陽性)」と判定してしまっても、その後の精密検査で正しく診断できます。しかし、病気の人を「問題なし(偽陰性)」と見逃してしまうと、手遅れになる可能性があります。そのため、再現率(感度)が非常に重要視されます。
適合率 (Precision / 陽性的中率): 誤報を減らすための指標
適合率は、「AIが『陽性』と予測した人たちのうち、本当に陽性だった人の割合」を示します。これは、臨床検査における陽性的中率(Positive Predictive Value, PPV)に相当します。
数式は以下の通りです。
\[ \text{適合率 (Precision)} = \frac{TP}{TP + FP} \]
分母の \( TP + FP \) は「AIが陽性と予測した人の総数」です。この指標は、偽陽性(FP)、つまり「誤報(空振り)」がどれだけ少ないかを示しています。
- 重視されるシナリオ: 侵襲的な処置(生検や手術など)を伴う確定診断の前段階。
- 考え方: AIの「陽性」という予測が、患者に大きな身体的・精神的負担を強いる治療の引き金になる場合、その予測は非常に高い確信度が求められます。「陽性」と判定したからには、本当に陽性であってほしいわけです。むやみに偽陽性を出すモデルは、臨床現場の信頼を失います。
トレードオフという現実と、F1スコア
ここで重要なのは、再現率と適合率は、多くの場合トレードオフの関係にあるという点です(3)。
- 見逃しを減らそうと(再現率↑)、AIの判定基準を甘くして「少しでも怪しければ陽性!」と判断させると、健康な人も陽性と判定しやすくなり、誤報が増えます(適合率↓)。
- 逆に、誤報を減らそうと(適合率↑)、判定基準を厳しくして「かなり確信が持てるものだけ陽性!」と判断させると、確信度が低い本当に陽性のケースを見逃しやすくなります(再現率↓)。
このトレードオフ関係にある2つの指標のバランスを取りたいときに役立つのが、F1スコア(F1-Score)です。F1スコアは、適合率と再現率の調和平均で計算されます。
\[ \text{F1スコア} = 2 \times \frac{\text{適合率} \times \text{再現率}}{\text{適合率} + \text{再現率}} \]
単純な算術平均ではなく、なぜ少し複雑な調和平均を使うのでしょうか。それは、調和平均には「片方の値が極端に低いと、全体の平均値も大きく下がる」という性質があるからです(2)。これにより、適合率と再現率が両方ともバランス良く高いモデルを評価するのに適しています。
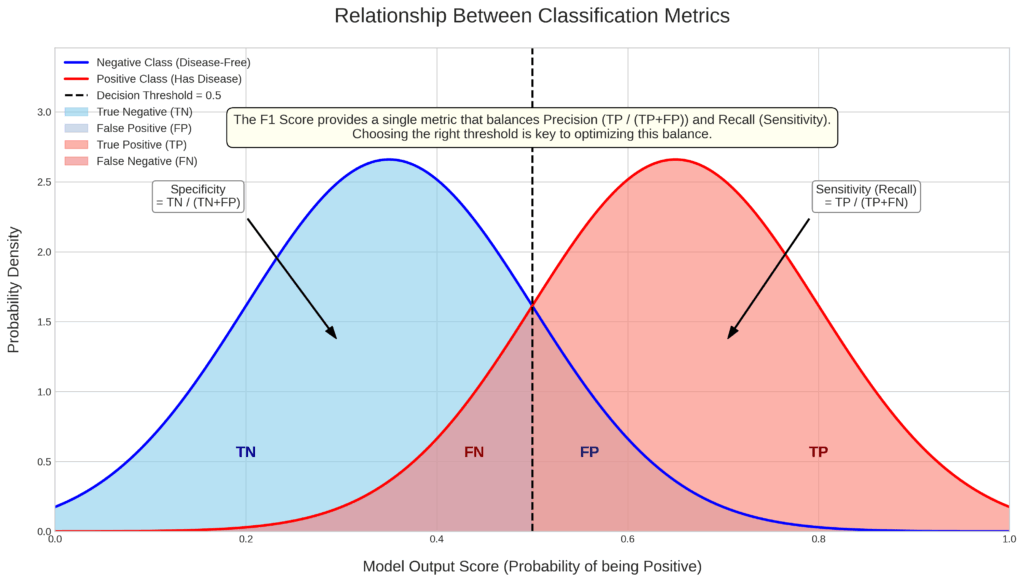
このグラフは、AIモデルが「陽性」か「陰性」かを判断する際の内部的な動きと、それが各種評価指標(感度、特異度など)にどう影響するかを視覚的に表現したものです。
1. 2つの山(分布)が示すもの
- 青い山(陰性クラスの分布): これは、本当に「疾患がない(陰性)」人たちのAIスコアの分布です。AIはこれらの人々に対して、低いスコア(例:0.1〜0.5)を出す傾向があることを示しています。
- 赤い山(陽性クラスの分布): これは、本当に「疾患がある(陽性)」人たちのAIスコアの分布です。AIはこれらの人々に対して、高いスコア(例:0.5〜0.9)を出す傾向があることを示しています。
理想的なAIとは、この青い山と赤い山をできるだけきれいに分離できる(重なりが少ない)モデルと言えます。
2. 「決定しきい値」の重要な役割
グラフの中央にある黒い破線(決定しきい値)は、AIの判断の分かれ目です。
- スコアが「しきい値」以上 → AIは「陽性」と予測
- スコアが「しきい値」未満 → AIは「陰性」と予測
このしきい値をどこに設定するかで、AIの振る舞い、特に「見逃し」と「誤報」のバランスが劇的に変化します。
3. 4つのエリアの意味(TP, FN, FP, TN)
しきい値によって分割された4つの色付きエリアは、混同行列の各要素に対応します。
- TP (真陽性): 赤い山のうち、しきい値より右側。疾患のある人を正しく「陽性」と予測できたケース。
- FN (偽陰性): 赤い山のうち、しきい値より左側。疾患のある人を誤って「陰性」と予測してしまった、最も避けたい「見逃し」ケース。
- TN (真陰性): 青い山のうち、しきい値より左側。疾患のない人を正しく「陰性」と予測できたケース。
- FP (偽陽性): 青い山のうち、しきい値より右側。疾患のない人を誤って「陽性」と予測してしまった「誤報(過剰診断)」ケース。
4. しきい値を動かすと何が起こるか?(トレードオフ)
- しきい値を下げる(左に動かす)と…
- 赤い山のFN(見逃し)エリアが減り、TPエリアが増えるため、感度(再現率)は上がります。
- しかし、青い山のFP(誤報)エリアが増えるため、特異度は下がります。
- 臨床的には「見逃しを減らすために、多少の誤報は許容する」というスクリーニング検査のような設定になります。
- しきい値を上げる(右に動かす)と…
- 青い山のFP(誤報)エリアが減るため、特異度は上がります。
- しかし、赤い山のFN(見逃し)エリアが増えるため、感度(再現率)は下がります。
- 臨床的には「誤報を絶対に避けるために、多少の見逃しリスクは許容する」という侵襲的な検査前の確認のような設定になります。
結論:F1スコアの役割
このように、感度(再現率)と特異度(または適合率)はトレードオフの関係にあります。片方を良くしようとすると、もう片方が悪化するのです。
F1スコアは、このトレードオフ関係にある「適合率」と「再現率」の両方を考慮し、そのバランスを評価するための指標です。F1スコアが高いモデルは、単にどちらか一方の性能が良いだけでなく、両方の指標がバランス良く高い、つまり「2つの山を総合的にうまく分離できているモデル」であると解釈することができます。
モデルの総合力を見る:ROC曲線とAUC
再現率と適合率のトレードオフは、AIが「陽性」と判断するしきい値(Threshold)をどこに設定するかで決まります。AIモデルの多くは、最終的に「陽性/陰性」という2値の答えを出す前に、「陽性である確率」や「信頼度」を0.0から1.0までのスコアとして出力します。例えば、スコアが0.7であれば、「70%の自信で陽性だと思う」といった具合です。
しきい値を0.5に設定すれば、スコアが0.5以上のものを陽性、未満を陰性と判断します。このしきい値を0.3に下げれば、より多くのケースを陽性と判断するため再現率は上がりますが、適合率は下がるでしょう。
では、どのしきい値が最適なのでしょうか?そして、しきい値を変えたときにモデルの性能がどう変化するのか、そのモデルが持つ潜在能力全体を評価するにはどうすれば良いのでしょうか?その答えを与えてくれるのが、ROC曲線(Receiver Operating Characteristic Curve)とAUC(Area Under the Curve)です。
ROC曲線とは何か?
ROC曲線は、この「しきい値」を0から1まで連続的に変化させたときの、縦軸:感度(再現率)と横軸:偽陽性率(\( 1 – \text{特異度} \))の関係をプロットしたグラフです(1)。
- 縦軸:真陽性率 (True Positive Rate, TPR) = 感度 = 再現率 = \( \frac{TP}{TP + FN} \)
- 横軸:偽陽性率 (False Positive Rate, FPR) = \( \frac{FP}{FP + TN} \)
- 分母の \( FP + TN \) は「本当に陰性の人の総数」なので、偽陽性率は「健康な人のうち、誤って陽性と判定された割合」を意味します。これは \( 1 – \text{特異度(Specificity)} \) と同じです(特異度 = \( \frac{TN}{FP + TN} \))。
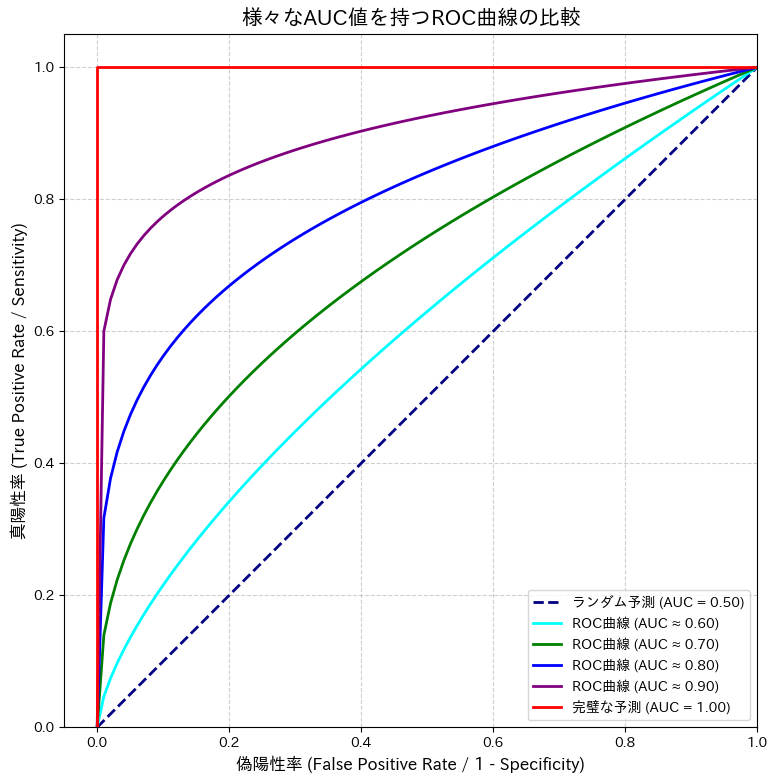
ROC曲線が左上に膨らむほど、性能の良いモデルであることを意味します。なぜなら、左上は「偽陽性率(誤報)が低く、かつ真陽性率(見逃さない率)が高い」という、最も理想的な状態を示す点だからです。
AUC (Area Under the Curve) の解釈
AUCは、文字通りROC曲線と横軸で囲まれた部分の面積を表します(4)。この値は0.5から1.0の範囲をとり、しきい値に依存しない、モデルの総合的な識別能力を示します。
- AUC = 1.0: 完璧なモデル。陽性スコアと陰性スコアが完全に分離できています。
- AUC = 0.5: 全く識別能力がないモデル。対角線(\(y=x\))の直線となり、コインを投げて決めるのと変わりません。
- AUC > 0.5: ランダムよりは良い予測ができるモデル。
AUCには、「ランダムに選んだ1人の陽性者と1人の陰性者がいた場合に、AIが陽性者の方により高いスコアを付ける確率」という、非常に直感的な解釈もあります。
臨床研究の分野では、AUCの値について以下のような大まかな目安が使われることがあります。
| AUC値 | 評価 |
|---|---|
| 0.90 – 1.00 | 非常に優れている (Excellent) |
| 0.80 – 0.90 | 優れている (Good) |
| 0.70 – 0.80 | まあまあ (Fair) |
| 0.60 – 0.70 | 劣る (Poor) |
| 0.50 – 0.60 | 価値なし (Fail) |
実践:Pythonで評価指標を計算し、可視化してみる
それでは、これまで学んできた指標を、実際にPythonコードで計算してみましょう。ここでは、scikit-learnという非常にポピュラーな機械学習ライブラリを使用します。
【実行前の準備】
以下のコードを実行する前に、お使いの環境でターミナル(またはコマンドプロンプト)を開き、pip install scikit-learn matplotlib japanize-matplotlib を実行して、必要なライブラリをインストールしておいてください。
# 必要なライブラリをインポートします
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_curve, auc
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示を有効化
# --- ダミーデータの準備 ---
# 100人分の「真のラベル」を準備します (0: 正常, 1: 疾患あり)
# 疾患あり(1)が10人(10%)、正常(0)が90人(90%)という不均衡なデータを模擬します
y_true = np.array([0]*90 + [1]*10)
# AIモデルが予測した「疾患である確率(スコア)」を模擬的に生成します
# 多くのモデルは、最終的な0/1の判断の前に、このような連続値のスコアを出力します
np.random.seed(42) # 結果を固定するためのシード値
y_scores = np.concatenate([
np.random.rand(90) * 0.45, # 正常な人たちの予測スコア (0.0〜0.45の間に分布)
np.random.rand(10) * 0.7 + 0.25 # 疾患がある人たちの予測スコア (0.25〜0.95の間に分布)
])
# 確率が0.5以上なら「陽性(1)」、未満なら「陰性(0)」とAIが最終判断したとします
# この「0.5」が「しきい値」です
threshold = 0.5
y_pred = (y_scores >= threshold).astype(int)
# --- 各種評価指標の計算 ---
# scikit-learnの関数を使い、しきい値0.5のときの各種スコアを計算します
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
# 計算結果を表示します
print(f"--- しきい値 = {threshold} の場合の評価 ---")
print(f"正解率 (Accuracy): {accuracy:.3f}")
print(f"適合率 (Precision): {precision:.3f}")
print(f"再現率 (Recall): {recall:.3f}")
print(f"F1スコア: {f1:.3f}")
print("-" * 30)
# --- ROC曲線とAUCの計算・描画 ---
# roc_curve関数は、様々な"しきい値"における偽陽性率(fpr)と真陽性率(tpr)を計算してくれます
# 入力として、真のラベル(y_true)と、AIの予測スコア(y_scores)を渡します
fpr, tpr, thresholds = roc_curve(y_true, y_scores)
# auc関数で、上で計算したfprとtprからROC曲線の下側の面積(AUC)を計算します
roc_auc = auc(fpr, tpr)
# --- グラフの描画 ---
plt.figure(figsize=(8, 8))
# ROC曲線をプロットします (lwは線の太さ)
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲線 (AUC = {roc_auc:.3f})')
# ランダムな予測の場合の線 (AUC=0.5の線) を破線でプロットします
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
# グラフの各種設定
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('偽陽性率 (1 - 特異度)', fontsize=14)
plt.ylabel('真陽性率 (感度)', fontsize=14)
plt.title('ROC曲線', fontsize=16)
plt.legend(loc="lower right", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.6)
# グラフを表示します
plt.show()--- しきい値 = 0.5 の場合の評価 ---
正解率 (Accuracy): 0.970
適合率 (Precision): 1.000
再現率 (Recall): 0.700
F1スコア: 0.824
------------------------------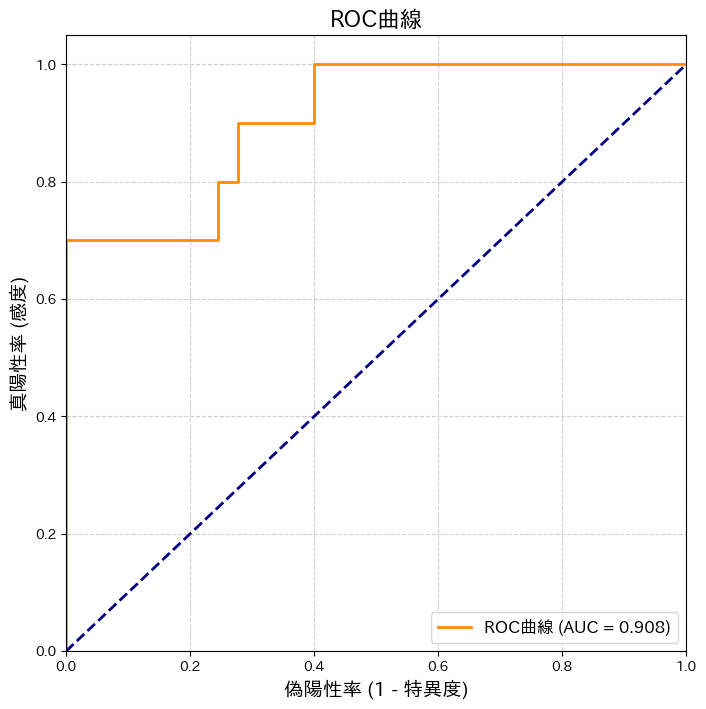
このコードを実行すると、まず各指標の計算結果が表示され、その後にROC曲線のグラフが描画されます。
表示される結果(乱数の関係で多少変動します)を見ると、正解率は約93%と高いですが、再現率は0.7程度、適合率は0.6程度かもしれません。これは「見逃し(偽陰性)が3割あり、陽性予測のうち4割は誤報(偽陽性)だった」ことを意味します。単純な正解率だけを見ていては、この重要な内訳に気づくことはできませんでした。
そして、ROC曲線とAUC(おそらく0.88-0.90程度)を見ることで、「しきい値0.5は最適ではないかもしれないが、このモデル自体は優れた識別能力を秘めている」という総合的な評価が可能になるのです。次の章で学ぶハイパーパラメータ最適化では、このAUCのような総合指標を最大化することを目指していきます。
15.3 スコアの向こう側へ:AIの「臨床的有用性」を測る定性的評価
前の章では、AUCをはじめとする定量的なスコアでAIモデルの技術的な性能を評価する方法を学びました。AUCが0.95という結果が出れば、それは間違いなく技術的に優れたモデルだと言えるでしょう。
しかし、そのAIが実際の臨床現場で「本当に役立つ」かどうかは、全く別の話です。想像してみてください。その高性能なAI、結果を一つ出すのに30分かかったとしたら? あるいは、操作が極端に複雑で、マニュアルを熟読しないと使えないとしたら? 多忙を極める臨床の現場で、そのAIが日常的に使われることは、残念ながらないでしょう。
このように、ROC曲線や適合率・再現率といった定量的なスコアだけでは、AIの「本当の価値」は測れません。そこで極めて重要になるのが、臨床的有用性(Clinical Utility)を測るための、定性的な評価です。これは、数値では表現しきれない「使いやすさ」「信頼感」「ワークフローへの適合性」といった側面から、AIを多角的に評価するアプローチです(8)。
実験室で生まれた優秀なAIを、現場で頼られるパートナーへと昇華させるために不可欠な、3つの定性的評価アプローチを詳しく見ていきましょう。
① エラー分析:AIは「なぜ、どのように」間違えるのか?
AIが予測を間違えたとき、単に「不正解」としてカウントするだけでは不十分です。「なぜ、この症例を間違えたのか?」「その間違いは、臨床的にどのような意味を持つのか?」を専門家が深く掘り下げてレビューするプロセス、それがエラー分析です。
これは、単なる間違い探しではありません。AIの「思考の癖」や「弱点」を理解するための、最も重要な手がかりとなります。
例えば、AIが肺がんの疑いがある結節を見逃した(偽陰性)とします。この一つの「間違い」にも、様々な背景が考えられます。表:エラーの質的分類の例(肺結節の見逃し)
| エラーの種類 | エラーの具体的内容 | 臨床的な許容度 | 開発へのフィードバック |
|---|---|---|---|
| A. 専門医でも判断困難なエラー | 非常に微小(3mm以下)で、淡く、血管や肋骨と重なっている結節。複数の放射線科専門医でも意見が分かれるレベル。 | 比較的高い (人間の限界に近い) | 現状のモデルの限界として認識。より高解像度のデータや異なるモダリティでの学習を検討。 |
| B. 典型的でない特徴を持つエラー | すりガラス状で境界が不明瞭な結節。典型的な円形の結節とは形状が大きく異なる。 | 中程度 (改善が望まれる) | 典型的でない症例(非典型例)のデータを追加学習させ、モデルの多様性を向上させる必要がある。 |
| C. 見逃してはならない明白なエラー | 比較的大きく(10mm以上)、典型的で明瞭な結節。人間であればまず見逃さないレベル。 | 許容不可能 (致命的な欠陥) | モデルの構造や学習プロセスに根本的な問題がある可能性。緊急の修正と再検証が必須。 |
このように、同じ「見逃し」という結果でも、その質的な意味は全く異なります。エラーAは現在の技術レベルでは仕方ない側面があるかもしれませんが、エラーCは患者に深刻な害をもたらす可能性があり、絶対にあってはならない間違いです。エラー分析を通じて、このような間違いの「質」を評価し、その原因を特定することが、信頼性の高いAIを開発する上で不可欠なのです(6)。
② ユーザビリティ評価:AIは「直感的に、心地よく」使えるか?
どんなに高精度なAIでも、使い勝手が悪ければ現場の負担を増やすだけです。そこで、AIのユーザビリティ(使いやすさ)を評価する必要があります。そのための強力な手法の一つが、思考発話法(Think-aloud Protocol)です。
これは、実際にAIを使用する可能性のある医療従事者(例えば、放射線科医や病理医)に、開発中のAIシステムを操作してもらい、その時に「頭の中で考えていること」をすべて声に出してもらうという、一見シンプルな手法です。
開発者が「きっとこう使ってくれるだろう」と想像していることと、ユーザーが実際に感じることは、しばしば大きく異なります。思考発話法は、そのギャップを浮き彫りにしてくれます。
- 「このAIの示す『確信度92%』は、どう解釈すればいいんだろう?」 → AIの出力の解釈性に課題
- 「前の画面に戻りたいのに、ボタンが見つからない…」 → UI/UXデザインに課題
- 「AIの指摘箇所を確認するために、何度もズームイン・ズームアウトするのが面倒だ」 → 操作性に課題
こうした生の声は、何百人分のログデータを分析するよりも雄弁に、改善点を教えてくれることがあります。ユーザーがどこで迷い、何に不信感を抱き、どこに価値を感じるのかを質的に分析することで、本当に「使われる」AIに近づけることができます。
③ ワークフロー評価:AIは「現場の流れ」を良くするのか?
最後に、AIを単体のツールとしてではなく、診療全体のプロセス(ワークフロー)の中に組み込んだときに、どのような影響を与えるかを評価する必要があります。
AIの導入によって、本当に全体のプロセスは効率化されたのでしょうか? それとも、意図しないボトルネックや新たな負担を生んでいないでしょうか? これを評価するのが、ワークフローへの影響評価です。
例えば、AIの導入で「画像1枚あたりの読影時間」は短縮されたとします。これは一見、素晴らしい成果です。しかし、もう少し視野を広げて見てみましょう。
- AI導入前: 読影医が10分かけてレポートを作成 → 完了
- AI導入後:
- AIが1分で解析完了(-9分)
- 読影医がAIの結果を検証・修正するのに5分(+5分)
- AIが出した「偽陽性」について、本当に問題ないか過去の検査と比較・確認するのに追加で5分(+5分)
- 結果:合計11分。かえって時間が増えてしまった。
この例は少し極端かもしれませんが、「部分最適」が「全体最適」になるとは限らない、という重要な教訓を含んでいます。評価すべきは、特定のタスクの時間だけでなく、以下のような多角的な視点です。
- 時間的側面: 診断に関わる総時間、患者の待ち時間
- 経済的側面: 不要な追加検査の増減、人件費
- 人的側面: 医療従事者の疲労度、ストレス、満足度
- 品質的側面: レポートの標準化、診断の精度、見逃しの変化
こうした定性的な評価を通じて初めて、AIが「実験室の優秀なモデル」から「臨床現場の頼れるパートナー」へと昇華できるのです。定量スコアの追求はもちろん重要ですが、それと同時に、その技術が現場の人間やプロセスにどう受け入れられるかを考える視点が、医療AI開発では不可欠と言えるでしょう(8)。
15.4 ハイパーパラメータ最適化:AIの潜在能力を解き放つ「匠の技」
さて、ここまでの章で、私たちはAIの性能を多角的に評価する方法を学んできました。AUCといった定量スコアで技術的な完成度を測り、エラー分析やユーザビリティ評価といった定性的なアプローチで臨床的な価値を探る。これらを通じて、開発したAIの「現在地」が明確になったはずです。
では、その評価結果をもとに、どうすればAIの性能をさらに高めることができるのでしょうか? その答えが、本章のテーマであるハイパーパラメータ最適化(Hyperparameter Optimization / Tuning)です。
これは、AI開発における、いわば「匠の技」が問われる領域です。最高の素材(データ)があっても、調理法が悪ければ美味しい料理が作れないように、AIもその「育て方」次第で性能が大きく変わってきます。この「育て方の秘伝のレシピ」を見つけ出すプロセスが、ハイパーパラメータ最適化なのです。
AI学習の「レシピ」と「調理法」:パラメータとハイパーパラメータの違い
ここで、多くの初学者が少し混乱するかもしれない2つの「パラメータ」という言葉を整理しておきましょう。「パラメータ」と「ハイパーパラメータ」です。この違いを理解することが、最適化の第一歩です。
先ほどの料理の比喩を続けるなら、この二つは以下のように考えることができます。
| パラメータ (Parameter) | ハイパーパラメータ (Hyperparameter) | |
|---|---|---|
| 役割 | AIモデルの「知識」そのもの。データから学習したパターン。 | AIモデルの「学習方法」や「構造」を決める設定値。 |
| 料理の比喩 | レシピの中身(材料の分量) 例:塩・コショウの量、野菜の切り方など、試行錯誤の末に決まるもの。 | 調理法・調理器具の設定 例:「強火で10分炒める」「オーブンを180℃に設定する」など、調理前に決めること。 |
| 誰が決めるか? | AIが自動で学習・更新する (訓練データを見て、誤差が小さくなるように調整される重みやバイアス) | 人間が事前に設定・調整する (開発者が試行錯誤して最適な値を探す) |
つまり、パラメータはAIがデータから自動で学ぶもの、ハイパーパラメータは私たちがAIに学習をさせる前に手動で設定してあげるもの、というわけです。この「手動設定」の良し悪しが、AIの最終的な賢さを大きく左右します。
なぜ「匠の調整」が必要なのか?過学習と未学習のジレンマ
「デフォルトの設定ではダメなの?」と思うかもしれません。もちろん、最初はそれでもある程度動きます。しかし、最高の性能を目指すには、データやタスクの特性に合わせた微調整が不可欠です。なぜなら、AIの学習には常に「過学習(Overfitting)」と「未学習(Underfitting)」というジレンマが付きまとうからです。
これも料理の比喩で考えてみましょう。
- 未学習 (Underfitting): 調理時間が短すぎたり、火加減が弱すぎたりして、具材に火が通りきっていない「生煮え」の状態。これは、AIが単純すぎて、データの中にある複雑なパターンを十分に学習できていない状態に対応します。訓練データに対する性能も、未知のデータに対する性能も、両方低いのが特徴です。
- 過学習 (Overfitting): 逆に、煮込みすぎて具材がドロドロに溶け、鍋に焦げ付いてしまった状態。これは、AIが複雑すぎるか、訓練しすぎたせいで、訓練データに「適応しすぎた」状態です。訓練データに出てきた特定の問題(ノイズまで含めて)を完璧に記憶してしまいますが、そのせいで未知のデータに対する応用力・汎化能力を失ってしまいます。訓練データでは満点を取るのに、テストでは全く歯が立たない「テストに弱い優等生」のような状態です。
ハイパーパラメータ最適化の目標は、この未学習と過学習の間の、ちょうどよい「塩梅」を見つけ出し、未知のデータ(検証用データ)に対して最も性能が高くなる点(汎化性能のピーク)を見つけ出すことにあります。
主要なハイパーパラメータ:AIの振る舞いを決める「設定ツマミ」たち
では、具体的にどのような「設定ツマミ」があるのでしょうか。代表的なものをいくつか見てみましょう。
| ハイパーパラメータ | 料理の比喩 | 役割と影響 |
|---|---|---|
| 学習率 (Learning Rate) | 火加減の強さ | パラメータを一度にどれだけ更新するかを決める。大きすぎると学習が発散し(焦げ付く)、小さすぎると学習がなかなか進まない(生煮え)。 |
| バッチサイズ (Batch Size) | 一度に鍋に入れる具材の量 | 一度の学習で、訓練データをいくつまとめてAIに見せるか。大きいと学習は安定するがメモリを多く消費し、小さいと学習は不安定になるが汎化性能が上がることがある。 |
| エポック数 (Epochs) | 煮込む時間 | 訓練データ全体を何回繰り返し学習させるか。少なすぎると未学習に、多すぎると過学習に陥りやすい。 |
| モデルの複雑さ | 調理器具の性能・複雑さ | ニューラルネットワークの層の数や、各層のノード数など。モデルが複雑なほど表現力は高まるが、過学習しやすくなる。 |
| 正則化 (Regularization) | アク取り・焦げ付き防止 | 過学習を防ぐための仕組み。モデルが複雑になりすぎることにペナルティを課す。 |
これらのツマミは互いに影響し合うため、「これをこうすれば必ず良くなる」という銀の弾丸は存在しません。だからこそ、体系的な探索が必要になるのです。
「黄金の組み合わせ」を探す旅:代表的な最適化手法
この無数にある設定値の組み合わせの中から、検証用データセットに対して最も良い性能を発揮する「黄金の組み合わせ」を、体系的に探索するプロセス。それがハイパーパラメータ最適化です。代表的な手法を3つご紹介します。
グリッドサーチ(Grid Search):しらみつぶしの総当たり戦
最もシンプルで直感的な方法です。調整したいハイパーパラメータの候補値をいくつか決め、その全ての組み合わせを試す手法です。
- 長所: 探索範囲内を網羅的に調べるため、最適な組み合わせを見逃しにくい。
- 短所: パラメータの種類や候補値が増えると、組み合わせが爆発的に増加し、計算に膨大な時間がかかる(次元の呪い)。
ランダムサーチ(Random Search):効率的な一点突破
グリッドサーチのように格子状に調べるのではなく、指定した範囲の中からランダムに組み合わせを選んで試す手法です。
一見、非効率に見えるかもしれませんが、実は多くの場合、グリッドサーチよりも効率的に良い組み合わせを見つけられることが知られています(5)。なぜなら、AIの性能に大きく影響するハイパーパラメータはごく一部で、残りはあまり影響しないことが多いからです。ランダムサーチは、様々な値の組み合わせを広く浅く探索するため、その「重要なパラメータ」の良い値に当たる確率が高くなるのです。
ベイズ最適化(Bayesian Optimization):経験から学ぶ賢者の探索
より高度な手法で、「これまでの探索結果」をもとに、「次にもっと良さそうな場所」を予測しながら探索を進める賢い方法です。
最初の数回はランダムに探索しますが、その結果(この組み合わせだとスコアが良かった/悪かった)を学習し、「このあたりを探索すれば、もっと良いスコアが出そうだ」という確率(獲得関数)を計算します。そして、その確率が最も高い点を次に試します。これを繰り返すことで、有望な領域を重点的に探索し、無駄な試行を減らすことができます。
ハイパーパラメータ最適化は、AIモデルの潜在能力を最大限に引き出すための、非常に重要で、そして奥深いプロセスです。それは単なる力仕事ではなく、どのパラメータが重要かを見極め、探索範囲を適切に設定し、計算コストと性能向上のバランスを取る、科学でありながらアートのような側面も持っています。この地道なチューニングこそが、AIを「そこそこ使えるモデル」から「真に信頼できるパートナー」へと進化させる鍵なのです。
まとめと注意事項
今回は、AIの「成績表」を正しく読み解き、その性能を評価・改善していくための基本的な考え方をご紹介しました。
- 適切な指標の選択: AIのタスク(分類、回帰、生成)に応じて、適切な評価指標(ものさし)を選ぶ。
- 臨床的指標の解釈: 医療AI、特に診断支援では、正解率だけでなく、ROC/AUCや適合率・再現率といった、臨床的な意味合いの強い指標を深く理解する。
- 定性的評価の重要性: スコアだけでは測れない「臨床的有用性」を、専門家による定性的な評価で補完する。
- チューニングによる性能向上: ハイパーパラメータを最適化することで、AIモデルの能力を最大限に引き出す。
AIモデルを構築することは、旅の始まりに過ぎません。そのモデルを客観的かつ多角的に評価し、改善を続ける、地道で科学的なプロセスこそが、信頼できる医療AIを患者さんの元へ届けるための、唯一の道なのです。
参考文献
- Fawcett, T. (2006). An introduction to ROC analysis. Pattern Recognition Letters, 27(8), 861-874.
- Powers, D. M. (2011). Evaluation: from precision, recall and F-measure to ROC, informedness, markedness & correlation.
- Davis, J., & Goadrich, M. (2006). The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd international conference on Machine learning.
- Hand, D. J. (2009). Measuring diagnostic accuracy: the case of the area under the ROC curve. Statistics in medicine, 28(1), 1-14.
- Bergstra, J., & Bengio, Y. (2012). Random search for hyper-parameter optimization. Journal of Machine Learning Research, 13(Feb), 281-305.
- Park, S. H., & Han, K. (2018). Methodologic guide for evaluating clinical performance and effect of artificial intelligence technology for medical diagnosis and prediction. Radiology, 286(3), 800-809.
- Saito, T., & Rehmsmeier, M. (2015). The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PloS one, 10(3), e0118432.
- Wiens, J., Saria, S., Sendak, M., Ghassemi, M., Liu, V. X., Doshi-Velez, F., … & Goldenberg, A. (2019). Do no harm: a roadmap for responsible machine learning for health care. Nature medicine, 25(9), 1337-1340.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




