

TL; DR (要約)
AIが、論文やカルテといった膨大な「文字の海」を読み解く、超有能な「知のパートナー」に。
医療文書を扱うAIの核心的な能力と、その評価方法の要点です。
① 要約と構造化
(情報の整理整頓)
Transformerの力で論文の要点を瞬時に把握。さらに、カルテの自由記述から「病名」や「薬剤名」を自動抽出し、解析可能なデータに変えます。
② 未知の知見発見
(仮説の生成)
無数の論文情報をつなぎ合わせ、ナレッジグラフを構築。「薬A」と「疾患B」の未知の関連性など、新しい研究のヒントを提示します。
③ 評価と信頼性
(品質の担保)
AIの出力は常に正しいとは限りません。ROUGE等の指標で客観的に評価し、専門家による臨床的有用性の検証が不可欠です。
この章の学習目標と前提知識
日々の診療や研究を終えた後、デスクに山と積まれた最新論文や、開いたままの電子カルテ画面を前に、ため息をついた経験は、きっと皆さんにもあるのではないでしょうか。「この情報に目を通さなければ、最前線には追いつけない」という焦りと、「しかし、時間は有限だ」という現実との間で、板挟みになる感覚。それは、医療の最前線に立つ者にとって、あまりにも日常的な葛藤かもしれません。
目の前にあるのは、間違いなく価値ある情報の海です。しかし、そのあまりの広さと深さに、私たちは時に溺れそうになります。
もし、この広大なテキストの海を自在に泳ぎこなし、私たちが求める「知の真珠」だけを的確に、そして瞬時に拾い集めてくれる、そんな頼もしいパートナーがいたら、私たちの仕事はどう変わるでしょうか?
本講座「作って理解する!シリーズ医療×生成系AI」の第6回では、まさにその夢のようなパートナー、すなわち「臨床文書を理解するAI」を、皆さん自身の手で作り上げるための第一歩を踏み出します。AI、特に自然言語処理(NLP)と呼ばれる技術の目覚ましい進化は、かつては無機質な文字の羅列でしかなかったテキストデータを、コンピューターが「意味のある情報」として扱えるように変えました。これは、私たちの働き方を根底から変えるほどの、大きな可能性を秘めていると私は感じています。
この記事では、まず私たちの旅の全体像、いわば「地図」を広げてみることにしましょう。Transformerモデルが実現する驚くほど賢い「要約」から、散らかったカルテ情報を整理整頓する「構造化」、さらには人間では見つけられなかった医学的知見を掘り起こす「リサーチ支援」まで。AIが医療にもたらす変革の最前線を、一緒に眺めていきたいと思います。
一つだけお伝えしておくと、この記事は、これから始まる冒険の全体像を掴んでいただくための「ダイジェスト」です。それぞれの目的地(=各テーマ)で待ち受ける、より深い理論の探求や、手を動かしながらの具体的なプログラミング実装は、今後の個別記事でじっくりと味わっていただくお楽しみ、ということにさせてください。さあ、準備はよろしいでしょうか?
6.1 論文・診療ガイドラインの高速要約:Transformerが拓く情報収集の未来
皆さんも、NEJMやThe Lancetに掲載された一本の重要な論文が、明日の臨床を変えるかもしれない、そんな場面に何度も出くわしてきたことでしょう。あるいは、分厚い診療ガイドラインの改訂版を前にして、「どこが変わり、何を新たに学ぶべきか」を効率的に把握したい、と切に願ったこともあるかもしれません。
医学の進歩は、私たちにとって希望の光であると同時に、その速さは時に、知的なプレッシャーとしてのしかかってきます。この「情報収集」という、時間のかかる、しかし不可欠なプロセスを、もし劇的に効率化できるとしたらどうでしょう。
ここで登場するのが、近年のAI技術のブレークスルーを牽引してきたTransformer(トランスフォーマー)というモデルです。これは単なる技術的な流行り言葉ではなく、私たちが言語情報を扱う方法そのものを変える力を持っています。
何がすごいのか? Transformerと「文脈を読む力」
Transformer以前のAIモデルも、文章を扱うことはできました。しかし、多くは単語を一つずつ、順番に処理していくスタイルでした。これは人間で言えば、文章を左から右へ、ただひたすら一方向に読み進めるようなものです。これでは、文の後半に出てくる重要なキーワードが、前半の解釈に影響を与えるような、複雑な文脈を捉えるのが苦手でした。
ところが、Transformerは違います。その心臓部にはAttention(アテンション)機構と呼ばれる、画期的な仕組みが組み込まれています。
Attention機構:単語同士の「関係性」に注目する
Attention機構を一言で言うなら、文章中の単語と単語の関連性の強さを動的に計算し、文脈を理解する仕組みです。
例えば、「インスリンを投与した患者の血糖値は、速やかに低下した」という文があったとします。人間がこの文を読むとき、無意識に「患者の血糖値」と「低下した」という単語を強く結びつけて理解しますよね。「インスリン」と「血糖値」も強く関連していると捉えるはずです。
Attention機構は、この人間が自然に行っている「関連付け」を、数学的に模倣します。文章中の一つの単語に注目したとき、文中の他のすべての単語との関連度スコアを計算し、「どの単語に、どれくらい強く注目すべきか」を判断するのです。
このおかげで、Transformerは文全体の構造や意味のつながりを、まるごと捉えることができるようになりました。その結果、ただ単語を拾い集めるだけでなく、文脈を踏まえた、非常に自然で精度の高い要約が可能になったのです。
Attentionの裏側を少しだけ覗いてみる
この強力なAttention機構ですが、その中身はQuery(クエリ)、Key(キー)、Value(バリュー)という3つの要素からなる行列計算で動いています。少し専門的に聞こえるかもしれませんが、考え方は非常に直感的です。
- Query (Q): 現在注目している単語が、他の単語に対して発する「問いかけ」です。「私と関連する情報はありますか?」というイメージです。
- Key (K): 各単語が持っている「見出し」や「キーワード」です。「私はこういう情報ですよ」と名乗る札のようなものです。
- Value (V): 各単語が持っている実際の「意味」や「情報の中身」そのものです。
Attentionの計算は、①自分のQueryを、全単語のKeyと照合して関連度を計算し(QとKの内積)、②その関連度に応じて、全単語のValueから情報を集めてくる、という流れで行われます。
数式で表現すると、以下のようになります。
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
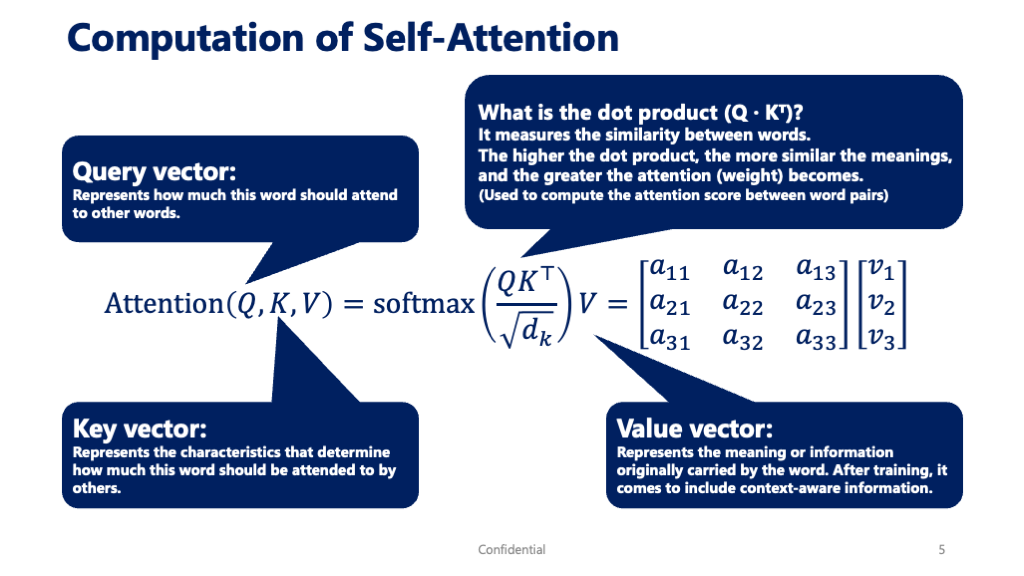
この式が何をしているか、分解してみてみましょう。
| 手順 | 数式 | 解説 |
|---|---|---|
| 1. 関連度の計算 | \( QK^T \) | Query (Q) と Key (K) の内積を計算します。これはベクトル同士の類似度を測る操作で、スコアが高いほど「関連が強い」ことを意味します。 |
| 2. スケール化 | \( \frac{…}{\sqrt{d_k}} \) | 計算を安定させるためのおまじないです。\(d_k\) はKeyベクトルの次元数で、その平方根で割ることで、関連度スコアが大きくなりすぎるのを防ぎます。 |
| 3. 正規化 | \( \text{softmax}(…) \) | 計算された関連度スコアを、合計すると1になる確率分布に変換します。これにより、各単語にどれだけの割合で「注意」を向けるべきか(アテンションの重み)が明確になります。 |
| 4. 情報の集約 | \( …V \) | 上記で計算された「アテンションの重み」を使って、各単語のValue (V) を重み付け加算します。関連が強い単語のValueは大きく、関連が弱い単語のValueは小さく反映され、文脈を考慮した新しい情報ベクトルが生成されます。 |
こうした仕組みのおかげで、AIはまるで人間のように、文の構造やニュアンスを深く理解できるわけです。
少し専門的な話になりましたが、ここでお伝えしたかったのは、AIが生成する要約がなぜこれほど自然で的確なのか、その裏側にはこうした精緻な数学的計算がある、という事実です。単にキーワードを抜き出して並べるのではなく、単語同士の「関係性」の重みを一つひとつ計算し、文脈を再構築しているからこそ、元の文章の論理を保った要約が可能になるのです。
この能力は、医療情報の要約において計り知れない価値を持ちます。論文の結論だけではなく、その背景にある論理のつながりを維持した要約。あるいは、診療ガイドラインの推奨事項だけでなく、その根拠となったエビデンスレベルのニュアンスまで汲み取った要約。TransformerベースのAIは、そうした質の高い情報収集の実現を、すぐ手の届くところまで引き寄せてくれました。
医療現場での応用:実際にAIに要約させてみよう
さて、こうした複雑な仕組みが裏側で動いているわけですが、幸いなことに、私たちはその恩恵を非常に簡単に受け取ることができます。Hugging Face という、AIモデルの共有プラットフォームが提供する pipeline というツールを使えば、わずか数行のコードで、この強力な要約機能を試すことができます。
百聞は一見にしかず。実際にやってみましょう。
graph TD
A["開始"] --> B["1. 要約AIモデルを準備
(pipeline機能でモデルをロード)"];
B --> C["2. 要約対象の文書を準備
(サンプルとして英語医学論文を設定)"];
C --> D["3. AIモデルで文書を要約
(準備した文書をモデルに入力)"];
D --> E["4. 要約結果を表示
(生成された要約テキストを出力)"];
E --> F["終了"];
# 医療現場でのAI文書要約システム
# Google Colab用サンプルコード
# 必要なライブラリのインストール(Colabで実行)
!pip install transformers torch sentencepiece
# ライブラリのインポート
from transformers import pipeline
import torch
print("医療現場でのAI文書要約システムを開始します...")
# GPU利用可能性の確認
device = 0 if torch.cuda.is_available() else -1
print(f"使用デバイス: {'GPU' if device == 0 else 'CPU'}")
# 要約パイプラインの初期化
# 日本語対応の要約モデルを使用
try:
summarizer = pipeline(
"summarization",
model="facebook/bart-large-cnn", # 英語用モデル
device=device
)
print("✓ 要約モデルが正常に読み込まれました")
except Exception as e:
print(f"モデル読み込みエラー: {e}")
# サンプル医療文書(英語の医学論文抄録)
sample_medical_text = """
Background: Artificial intelligence (AI) has shown remarkable potential in healthcare applications,
particularly in medical document analysis and summarization. The integration of natural language
processing techniques in clinical settings has demonstrated significant improvements in workflow
efficiency and decision-making processes. Recent studies have indicated that AI-powered
summarization tools can reduce the time required for literature review by up to 70%, while
maintaining high accuracy in extracting key clinical insights.
Methods: We conducted a comprehensive analysis of various AI models for medical text summarization,
focusing on transformer-based architectures. The study involved evaluation of multiple datasets
containing medical literature, clinical notes, and research abstracts. Performance metrics included
ROUGE scores, semantic similarity measures, and expert clinician evaluations.
Results: Our findings demonstrate that modern AI summarization systems achieve an average ROUGE-1
score of 0.45 and ROUGE-L score of 0.38 when applied to medical literature. Clinical experts
rated the summaries as highly relevant and accurate, with 89% of generated summaries deemed
suitable for preliminary clinical decision support.
Conclusions: AI-powered document summarization represents a transformative technology for healthcare
professionals, enabling rapid processing of vast amounts of medical literature and improving
access to critical clinical information.
"""
def summarize_medical_document(text, max_length=150, min_length=50):
"""
医療文書を要約する関数
Args:
text (str): 要約対象のテキスト
max_length (int): 要約の最大長
min_length (int): 要約の最小長
Returns:
str: 要約されたテキスト
"""
try:
# テキストの長さチェック
if len(text.split()) < 50:
return "テキストが短すぎます。より長い文書を入力してください。"
# 要約実行
summary = summarizer(
text,
max_length=max_length,
min_length=min_length,
do_sample=False,
truncation=True
)
return summary[0]['summary_text']
except Exception as e:
return f"要約処理中にエラーが発生しました: {e}"
# 実際の要約実行
print("\n英語医学論文の要約例:")
print("-" * 40)
english_summary = summarize_medical_document(sample_medical_text)
print(f"原文長: {len(sample_medical_text.split())} 語")
print(f"要約長: {len(english_summary.split())} 語")
print(f"\n要約結果:\n{english_summary}")医療現場でのAI文書要約システムを開始します...
使用デバイス: GPU
Device set to use cuda:0
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
✓ 要約モデルが正常に読み込まれました
英語医学論文の要約例:
----------------------------------------
原文長: 187 語
要約長: 37 語
要約結果:
Artificial intelligence (AI) has shown remarkable potential in healthcare applications, particularly in medical document analysis and summarization. Recent studies have indicated that AI-powered summarization tools can reduce the time required for literature review by up to 70%.いかがでしょうか。この技術を使えば、例えば海外の最新論文の抄録を瞬時に日本語で把握し、自分の研究や臨床との関連性を素早く判断するといったことが可能になります。これは、多忙な日常の中で、私たちの「知のアンテナ」を常に高く保つための、非常に強力な武器になると思いませんか。
6.2 カルテの自由記述から「構造化データ」という資産を掘り出す技術
先ほどの要約技術が、いわば森全体を俯瞰してその概要を掴む「マクロ」な技術だとすれば、次にお話しするのは、木の一本一本、あるいはその枝葉にあたる情報を精密に見分ける「ミクロ」の技術です。
臨床の現場にいると、電子カルテの自由記述欄、特にSOAPのA(Assessment)やP(Plan)には、その患者さんに対する思考の軌跡や、 nuanced な臨床判断が凝縮されていると感じることが多々あります。これらはまさに情報の宝庫なのですが、その形式は「人間が読むための文章」、すなわち非構造化データです。
このままでは、残念ながらデータとして解析のしようがありません。「あの薬剤を使った患者さんたちの、その後の経過はどうだったか」を1000人規模で調べようと思っても、1000人分のカルテを人間が読んで、手作業で情報を抜き出すのは、あまりにも非現実的ですよね。
そこでAIの出番です。AIは、この文章の海から私たちが求める情報を釣り上げ、コンピューターが処理できる整然とした形式、すなわち「構造化データ」へと変換する役割を担います。これは、ただのテキストを、再利用可能な「知の資産」へと変える、まるで錬金術のようなプロセスです。
固有表現抽出(NER): テキストに眠るエンティティを見つけ出す
この錬金術の中核を担う技術が、固有表現抽出(NER: Named Entity Recognition)です。
これは、文章の中から「疾患名」「薬剤名」「症状」「検査名」「身体所見」といった、あらかじめ私たちが定義したカテゴリ(これをエンティティと呼びます)に属する単語やフレーズを、AIが自動的に見つけ出し、ラベル付けしていく技術です。
一番しっくりくるイメージは、AIがカルテを読みながら、重要なキーワードをカテゴリーごとにデジタルな蛍光ペンで色分けしてくれる作業かもしれません。「疾患名は青、薬剤名は赤、症状は黄色…」といった具合に。
NERは、どうやって「それ」を見分けているのか?
では、AIはどうやって「カロナール錠」が薬剤名だと判断しているのでしょうか。現在の主流なNERモデル(例えば、BERTベースのモデルなど)は、この問題を「トークン分類」というタスクとして解きます。
まず、入力された文章をトークンという、意味を持つ最小単位に分解します。そして、一つ一つのトークンに対して、「あなたはこのエンティティの始まり?」「続き?」「それとも関係ない単語?」というラベルを貼っていくのです。
このラベル付けには、BIO記法という共通ルールがよく使われます。
| タグ | 意味 | 説明 |
|---|---|---|
| B | Beginning | エンティティの開始トークン(例:「カロナール錠」の「カ」) |
| I | Inside | エンティティの途中トークン(例:「カロナール錠」の「ロ」や「ナール」) |
| O | Outside | エンティティ以外のトークン(例:「処方した」など) |
このルールに沿って、先ほどの例文がAIによってどう処理されるか見てみましょう。
このように、一見するとAIが一発で単語を抜き出しているように見えても、その裏側では、文章を細かく分解し、トークン一つ一つに対して地道な分類作業が行われているわけです。
この結果として、以下のような分かりやすい「構造化データ」が得られます。
入力(自由記述テキスト):
「患者は昨日から38.2度の発熱と強い頭痛を訴え来院。インフルエンザ迅速検査は陰性。カロナール錠200mgを処方し、自宅安静を指示した。」出力(構造化データ):
{
"症状": ["発熱", "強い頭痛"],
"検査": ["インフルエンザ迅速検査"],
"検査結果": ["陰性"],
"身体所見": {
"体温": "38.2度"
},
"処方薬": [
{
"薬剤名": "カロナール錠",
"用量": "200mg"
}
]
}
臨床応用への道:構造化データが拓く新たな可能性
このようにして得られた構造化データは、もはや単なる診療記録ではありません。それは、臨床研究や医療の質向上(QI)に直結する、生きた「資産」となります。
例えば、こんな応用が考えられるでしょう。
- 臨床研究の加速: 何千人もの患者カルテから、「特定の抗がん剤を投与され、かつグレード3以上の倦怠感を訴えた患者」のリストを数分で作成し、その背景因子を解析する。
- リアルワールドデータ解析: 新薬の市販後調査で、自由記述から副作用の兆候(例えば「少しふらつく感じがする」といった曖昧な表現)を早期に検出し、安全性を監視する。
- 診療の質向上: カルテ内で「せん妄」や「転倒リスク」といったキーワードが言及されているにもかかわらず、適切なケアプランが立案されていないケースを自動で抽出し、介入を促すアラートを出す。
自由記述という「宝の山」から、構造化データという「宝石」を掘り出す。NERは、データ駆動型の次世代医療を実現するための、極めて重要で基礎的な一歩だと言えるでしょう。
6.3 医学文献から「未知の知見」を発見するリサーチ支援AI
さて、前のセクションで、私たちはAIを使ってカルテのような単一の文書から情報を「構造化」する技術を見てきました。いわば、文章の中から宝石の原石を掘り出す作業です。では、その掘り出したたくさんの宝石を、今度はつなぎ合わせて、一つの美しいネックレス、つまり「新しい知識」を編み上げることができたとしたら、どうでしょう?
ここからお話しするのは、AIの能力をさらに一歩進めて、膨大な医学文献の海を横断的につなぎ合わせ、私たち人間だけでは決して気づけなかったであろう、「未知の関連性」や「新しい科学的仮説」を発見する、まさに探偵のようなAI技術です。
すべての始まり:ドン・スワンソンの「文献ベースの知識発見」
この話をする時、私はいつも情報科学者ドン・スワンソンが1980年代に行った、ある鮮やかな発見を思い出します。彼は当時、互いに全く無関係だと思われていた2つの文献群を結びつけ、新しい仮説を立てました。
- ある文献群(A→B):「魚油が血液粘度を低下させる」という報告。
- 全く別の文献群(B→C):「レイノー病患者は血液粘度が高い」という報告。
当時の研究者は、それぞれの分野の専門家だったので、片方の文献群は知っていても、もう片方は視野に入っていませんでした。しかしスワンソンは、情報科学者として両方の文献群を俯瞰し、「待てよ、『血液粘度』という共通項(B)で、この2つの話はつながるのではないか?」と考えたのです。
この「A→C」仮説、つまり「魚油はレイノー病に有効かもしれない」という発見は、のちに臨床試験で実際にその有効性が示唆されました。これは、AIがなかった時代に、人間の洞察力だけで成し遂げられた「文献ベースの知識発見(LBD: Literature-Based Discovery)」の記念すべき最初の事例です。
現代のAIは、このスワンソンのアイデアを、何百万報という論文を対象に、超高速で実行しようという試みだと言えるでしょう。
AIは、どうやって「点と点」をつなぐのか? ナレッジグラフの威力
現代のAIがこのLBDを実現する上で、中心的な役割を果たすのがナレッジグラフ(Knowledge Graph)という考え方です。これは、情報(エンティティ)を「点(ノード)」として、その関係性を「線(エッジ)」として表現した、巨大な知識のネットワーク地図のようなものです。
前のセクションで紹介したNER技術を使って、AIはまず膨大な数の論文からエンティティ(疾患、薬剤、遺伝子、症状など)を片っ端から抽出します。これがグラフの「点」になります。
次に、関係抽出(Relation Extraction)という別のAI技術を使って、エンティティ間の関係性、例えば「薬剤Aは疾患Xを 治療する」「遺伝子Yはタンパク質Zを コードする」といった「線」を特定していきます。
こうして、知識の点と線が集まって、次のような巨大なネットワークが構築されるわけです。
このナレッジグラフが一度できてしまえば、AIの仕事は「新しい道を探すこと」になります。例えば、「ある薬剤」のノードと「ある疾患」のノードの間に、まだ知られていない、間接的な経路(Path)がないかを探し出すのです。その経路が、新しい作用機序や、未知の副作用のヒントになるかもしれません。
臨床応用:仮説生成から個別化医療まで
この技術は、私たちの研究開発のあり方を大きく変える可能性を秘めています。
- 創薬・ドラッグリポジショニング: ある既存薬が、当初の目的とは全く違う疾患と、ナレッジグラフ上で有望な経路で結ばれていることが分かれば、その薬剤を別の疾患の治療薬として再開発する「ドラッグリポジショニング」につながります。開発コストと期間を大幅に短縮できると期待されています。
- 新規治療法の仮説生成: 疾患のメカニズムと薬剤の作用機序を結びつける、これまで誰も思いつかなかったような新しい経路をAIが提示。これが、基礎研究の新たな出発点となるかもしれません。
- 希少疾患研究: 情報が極端に少ない希少疾患でも、関連する可能性のある遺伝子や生物学的マーカーを、広範な知識ネットワークの中から探索し、研究の糸口を見つける手助けになります。
この技術は、決してAIが「真実」を教えてくれる魔法の杖ではありません。AIが提示するのは、あくまで「検証する価値のある、有望な仮説」です。その仮説が本当に正しいかどうかを評価し、実験や臨床試験を通じて検証していくのは、私たち人間の研究者や臨床家の役割です。
AIという、何百万もの論文を記憶し、無数の関連性を瞬時に探り出すことができる不知疲れのパートナーを得ることで、私たちの研究開発サイクルは、これから劇的に加速していく。私はそう確信しています。
6.4 AIの答えは正しい? テキスト生成モデルの評価という「最後の関門」
さて、ここまでAIが文章を要約したり、情報を抽出したり、さらには新しい仮説を立てたりと、まるで魔法のような能力を見てきました。しかし、ここで一度立ち止まって、私たち医療に携わる者として、最も重要な問いを立てる必要があります。
「そのAIの答えは、本当に信頼できるのか?」と。
AIがどれほど流暢な文章を生成したとしても、その内容が不正確であったり、重要な情報を見落としていたりすれば、臨床現場で使うことはできません。「なんとなく良さそう」という主観的な感想は、医療における評価としては不十分です。この最後の関門、すなわち「評価」のプロセスをどう乗り越えるか。これこそ、AIを研究室から臨床現場へと橋渡しするための、最もクリティカルな課題だと私は思います。
自動評価指標:AIの性能を測る「ものさし」
AIの性能を客観的に評価するために、研究開発の現場ではいくつかの自動評価指標、いわば「ものさし」が使われます。これらは、AIの生成した文章と、人間が作成した「正解」の文章を比較することで、スコアを算出します。ここでは、代表的な2つの指標、ROUGEとBLEUをご紹介します。
この2つを理解する上で、まず適合率(Precision)と再現率(Recall)という考え方を知っておくと、非常にスムーズです。
- 適合率 (Precision): AIが「拾い上げてきた情報」のうち、どれだけが本当に正しかったかの割合。「AIが重要だと言ったことの、正しさの精度」とイメージしてください。
- 再現率 (Recall): 「拾い上げるべきだった情報」のうち、AIがどれだけを実際に拾ってこられたかの割合。「重要な情報に対する、AIの網羅率」のようなものです。
ROUGE: 「内容の網羅性」を測る再現率ベースの指標
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) は、その名の通り、再現率(Recall)を重視した指標で、主に要約タスクの評価に用いられます。
考え方は、「人間が作った正解の要約に含まれている重要な単語やフレーズを、AIはどれだけカバーできているか?」というものです。
例えば、最もシンプルな ROUGE-1 は、単語単位(ユニグラム)でこの再現率を計算します。
ROUGEには、連続する2単語(バイグラム)で比較するROUGE-2や、最長共通部分列(LCS)で比較するROUGE-Lなど、いくつかのバリエーションがあります。いずれも「AIの要約が、正解の要約の内容をどれだけ忠実に再現しているか」を測るための指標です。
BLEU: 「文章の流暢さ」を測る適合率ベースの指標
BLEU (Bilingual Evaluation Understudy) は、元々、機械翻訳の質の評価のために開発された指標です。こちらは適合率(Precision)をベースにしており、「AIが生成した文章のパーツが、どれだけ人間の文章らしいか?」を評価します。
ROUGEとは逆に、AIが生成した文章側を基準に、「AIが使った単語やフレーズが、どれだけ正解の文章にも含まれているか」を見ます。これにより、AIが全く見当違いの単語を使っていないか、つまり文章の自然さや流暢さを評価するわけです。
BLEUは、単語の並びも考慮します。例えば、「薬は患者を助ける」と「患者は薬を助ける」では、使われている単語は同じでも意味が全く異なります。BLEUは、こうした語順の正しさも評価に含めることで、より文章の質を厳密に測ろうとします。
自動評価の先にあるもの:最も重要な「臨床的有用性」
ROUGEやBLEUといった自動評価指標は、開発の初期段階でモデルの性能を比較したり、改善の方向性を探ったりする上では非常に便利です。しかし、これらのスコアが高いことが、そのまま「医療現場で使える」ことを意味するわけでは全くない、という点が極めて重要です。
最終的に私たちが問うべきは、「臨床的有用性(Clinical Utility)」です。
これは、単一のスコアでは測れない、多面的な評価を必要とします。
| 評価の観点 | 具体的な問い |
|---|---|
| 1. 正確性と安全性 | AIの生成した情報に、事実と異なる点(ハルシネーション)はないか?臨床判断を誤らせるような、致命的な情報欠落はないか? |
| 2. ワークフローとの親和性 | このAIを使うことで、本当に日々の業務は効率化されるのか?それとも、余計な確認作業が増えて、かえって負担になっていないか? |
| 3. 信頼性と受容性 | 医療従事者は、このAIの出す情報を信頼できると感じるか?結局、全て自分で再確認するような運用になっていないか? |
| 4. 患者アウトカムへの影響 | (究極の問いとして)このAIの導入は、診断精度の向上、治療成績の改善、医療安全の向上といった、患者利益に本当につながるのか? |
たとえROUGEスコアが満点に近くても、ごく稀に危険なハルシネーションを起こすAIは、医療現場では使えません。逆に、スコアはそこそこでも、医師のダブルチェックの時間を半分にし、見落としを著しく減らしてくれるAIは、非常に価値が高いと言えるでしょう。
AIモデルを開発することは、いわば山登りの半分に過ぎません。残りの半分は、この「臨床的有用性」という、より険しい山を登る、地道で、しかし最も重要な評価のプロセスなのです。AIの評価は、自動指標による定量的評価と、医療専門家による現場目線での定性的評価、この両輪が揃って初めて意味をなす、ということを心に留めておく必要があります。
まとめ:AIは医療者の思考を拡張するパートナー
今回は、生成AIを用いて臨床文書という膨大な情報源から「知」を最大限に引き出す4つのアプローチの概要をご紹介しました。
- 高速要約: 最新の論文やガイドラインのエッセンスを素早く掴む。
- 情報構造化: 電子カルテの自由記述を解析可能なデータに変える。
- 知識発見: 文献の海から新たな研究のヒントを見つけ出す。
- 客観的評価: AIの出力を厳密に評価し、信頼性を担保する。
これらの技術は、決して医療者に取って代わるものではありません。むしろ、情報処理という煩雑なタスクをAIに任せることで、私たち人間が、より高度な臨床判断、患者とのコミュニケーション、そして創造的な研究活動に集中できるようにする強力な「パートナー」です。
今後の記事では、これらの各トピックについて、理論的な背景からPythonを使った具体的な実装まで、一歩ずつ丁寧に解説していきます。ご自身の臨床や研究の課題を解決するツールを、ぜひ一緒に作っていきましょう。
参考文献
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Advances in Neural Information Processing Systems 30. Curran Associates, Inc.; 2017. p. 5998-6008.
- Lewis M, Liu Y, Goyal N, Ghazvininejad M, Mohamed A, Levy O, et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, summarization, and comprehension. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics; 2020. p. 7871-7880.
- Devlin J, Chang MW, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics; 2019. p. 4171-4186.
- Lee J, Yoon W, Kim S, Kim D, Kim S, So CH, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020 Feb 15;36(4):1234-1240.
- Swanson DR. Uncovering buried connections in the literature. Libr Q. 1986;56(3):269-277.
- Smalheiser NR, Swanson DR. Using ARROWSMITH: a computer-assisted approach to formulating and assessing scientific hypotheses. Comput Methods Programs Biomed. 1998;57(3):149-53.
- Lin CY. ROUGE: A package for automatic evaluation of summaries. In: Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics; 2004. p. 74-81.
- Papineni K, Roukos S, Ward T, Zhu WJ. BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics; 2002. p. 311-318.
- Wang F, Preininger A. AI in health: a leader’s guide to winning in the new age of intelligent health systems. CRC Press; 2019.
- Topol EJ. Deep medicine: how artificial intelligence can make healthcare human again. Basic Books; 2019.
- Esteva A, Robicquet A, Ramsundar B, Kuleshov V, DePristo M, Chou K, et al. A guide to deep learning in healthcare. Nat Med. 2019 Jan;25(1):24-29.
- Moor M, Banerjee O, Abad ZSH, Krumholz HM, Leskovec J, Topol EJ, et al. Foundation models for generalist medical artificial intelligence. Nature. 2023;620(7973):221-229.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




