

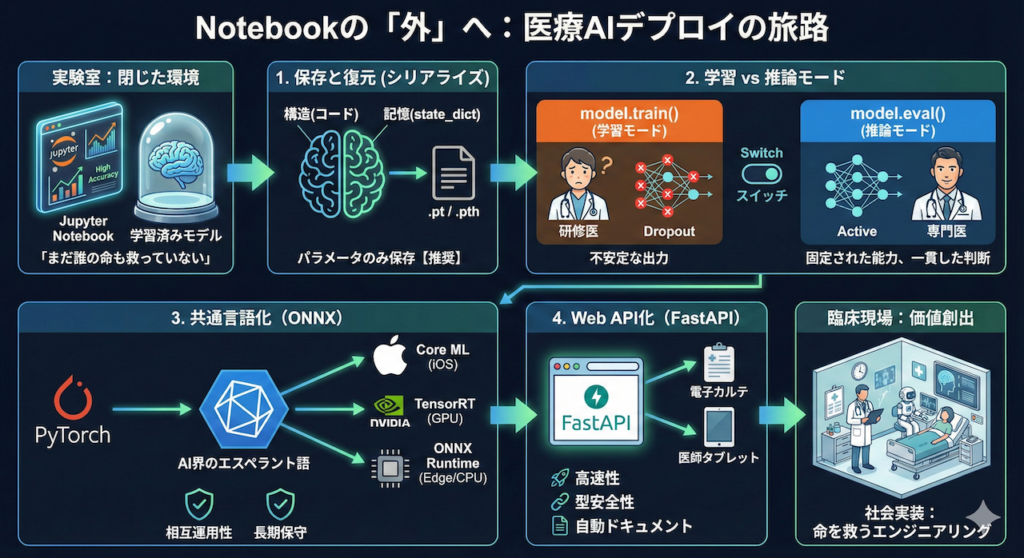
Notebookの「外」へ踏み出すとき
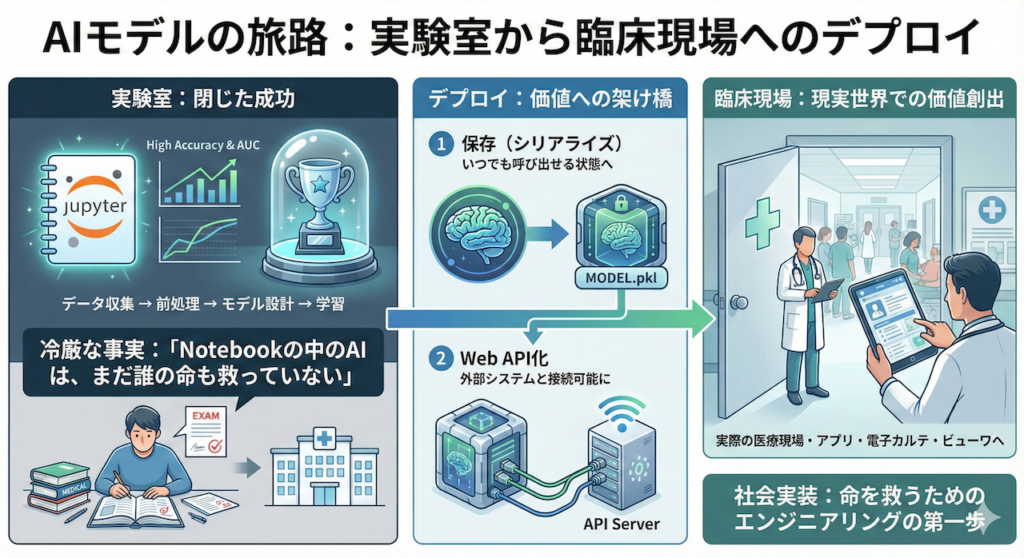
これまで私たちは、データの収集から始まり、丹念な前処理、モデルアーキテクチャの設計、そして学習という長い旅路を歩んできました。手元のJupyter Notebookの中で、あなたのモデルは高い精度(Accuracy)やAUCを叩き出し、素晴らしい性能を示しているかもしれません。画面上の数値を見て、大きな達成感を感じていることでしょう。
しかし、ここで冷厳な事実をお伝えしなければなりません。「Notebookの中にいるAIは、まだ誰の命も救っていない」ということです。
研究室や個人のPCという閉じた環境(実験室)で生まれたAIモデルを、実際の医療現場やWebアプリケーションとして使える形に変換し、設置・運用することを「デプロイ(Deployment)」と呼びます (He et al. 2019)。
これを医療者のキャリアに例えるならば、医学知識を学び(学習)、医師国家試験に合格して高いスコアを出した(高精度なモデル評価)だけの状態から、実際の病院に配属され、目の前の患者さんを診察できる状態(臨床現場への配置)になるプロセスに似ています。試験で満点を取れても、現場にいなければ患者を救えないのと同じく、AIもデプロイされなければ価値を生み出しません。
今回は、あなたが手塩にかけて育てたAIモデルを「保存(シリアライズ)」していつでも呼び出せる状態にし、さらに Web API として外部の電子カルテシステムやビューワから利用可能にするための技術的基盤を解説します。これは、研究を社会実装へと繋ぐための、エンジニアリングの第一歩です。
1. モデルの「保存」と「復元」:シリアライズの作法
AIモデルの学習には、数時間から数週間という長い時間と、大量の計算リソース(電気代やGPUパワー)が必要です。苦労して学習させた「賢いAI」も、コンピュータの電源を切ったり、プログラムを終了したりすれば、その瞬間にメモリ上から消え去ってしまいます。これは、研修医が数年かけて学んだ知識を、一晩寝たらすべて忘れてしまうようなものです。
そこで必要となるのが、学習によって最適化された膨大な数の「パラメータ(重みとバイアス)」を、永続的なファイルとして書き出す処理です。これをプログラミング用語でシリアライズ(直列化)と呼びます。シリアライズによって、AIの「記憶」を凍結保存し、必要な時にいつでも解凍して、学習を再開したり、推論(診断)に使ったりすることが可能になります。
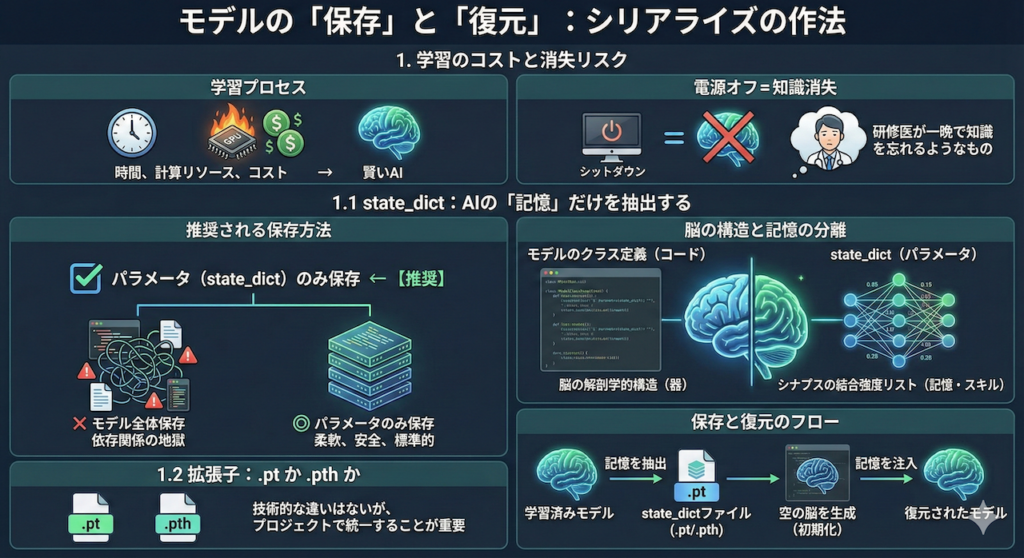
1.1 state_dict:AIの「記憶」だけを抽出する
PyTorchにおいて、モデルを保存する方法は大きく分けて2つあります。
- モデル全体(アーキテクチャ+パラメータ)を保存する
- パラメータ(
state_dict)のみを保存する ← 【推奨】
なぜ「パラメータのみ」が推奨されるのか?
公式ドキュメントや多くのエキスパートが推奨するのは、2番目の「パラメータのみ」を保存する方法です (Paszke et al. 2019)。
1番目の「モデル全体」を保存する方法(Pythonの pickle 機能を使用)は、手軽に見えますが、特定のディレクトリ構成やクラス定義に強く依存します。もし、将来的にファイル構成を変えたり、コードをリファクタリング(整理)したりすると、「モデルの読み込みができない」という致命的なエラー(依存関係の地獄)に陥るリスクが高まるからです。
脳の「構造」と「記憶」の分離
ここで、state_dict(ステート・ディクト) の概念を理解するために、脳の構造と記憶の関係に例えてみましょう。
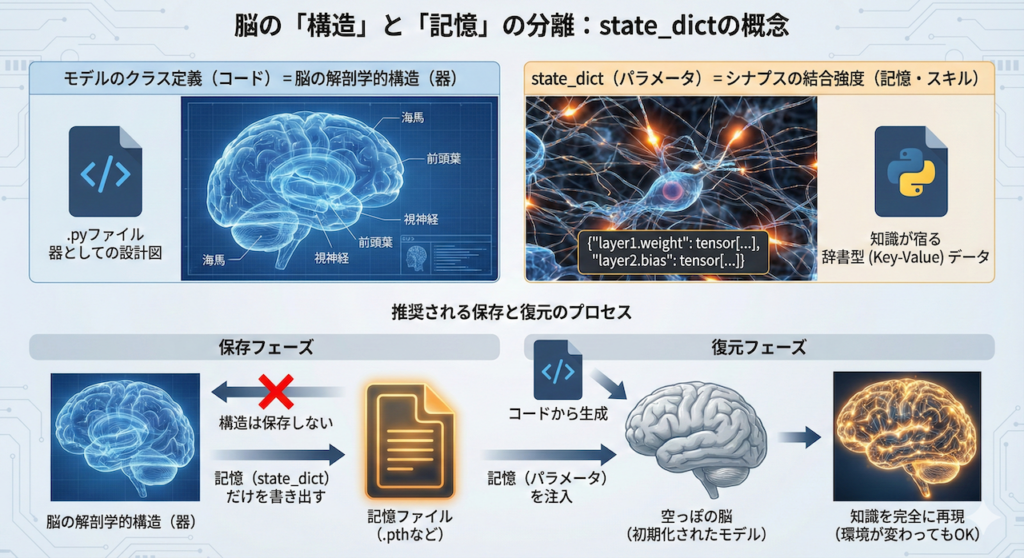
- モデルのクラス定義(コード):
これは「脳の解剖学的構造」にあたります。海馬があり、前頭葉があり、視神経がつながっている……という「器」としての設計図です。これはプログラムコード(.pyファイル)として存在します。 state_dict(パラメータ):
これは「シナプスの結合強度リスト(記憶・スキル)」にあたります。学習によって強化されたニューロン間のつながりの強さであり、ここに「知識」が宿っています。Pythonでは「層の名前」と「パラメータの数値」が対になった辞書型(Key-Value)データとして扱われます。
推奨される保存方法は、「脳の構造(コード)」は保存せず、「記憶(state_dict)」だけをファイルに書き出すやり方です。復元する際は、コードから「空っぽの脳(初期化されたモデル)」を生成し、そこにファイルから読み込んだ「記憶(パラメータ)」を注入します。これにより、環境が変わっても、同じ構造の脳さえ用意できれば、知識を完全に再現できるのです。
1.2 拡張子:.pt か .pth か
保存するファイルの拡張子には、慣習として .pt または .pth が使われます。
技術的にはどちらを使っても機能に違いはありませんが、チーム開発やプロジェクト管理の観点からは、どちらかに統一しておくことが重要です。これらは「PyTorchの重みファイルである」ことを人間が識別するためのラベルのようなものです。
2. 学習モードと推論モード:model.eval() の重要性
モデルをロードし、いざ患者さんのデータを入力して診断(推論)を行わせる際、初学者が最も陥りやすく、かつ重大な医療ミスに繋がりかねない罠があります。それは、「学習モード(Training Mode)のまま推論してしまう」ことです。
PyTorchなどのディープラーニングフレームワークでは、モデルに明確な「モード」が存在します。
model.train():学習モード(デフォルト)。訓練データを使って自分自身を更新する状態。model.eval():推論(評価)モード。学習を止め、固定された能力でテストや実運用を行う状態。
なぜわざわざ切り替える必要があるのでしょうか? 「学習を止める(勾配計算をしない)」だけなら torch.no_grad() だけで良さそうに見えます。しかし、実はニューラルネットワークの一部の層は、学習時と推論時で「挙動そのもの」が全く異なるのです。代表的なのが Dropout と Batch Normalization です (Ioffe & Szegedy 2015; Srivastava et al. 2014)。
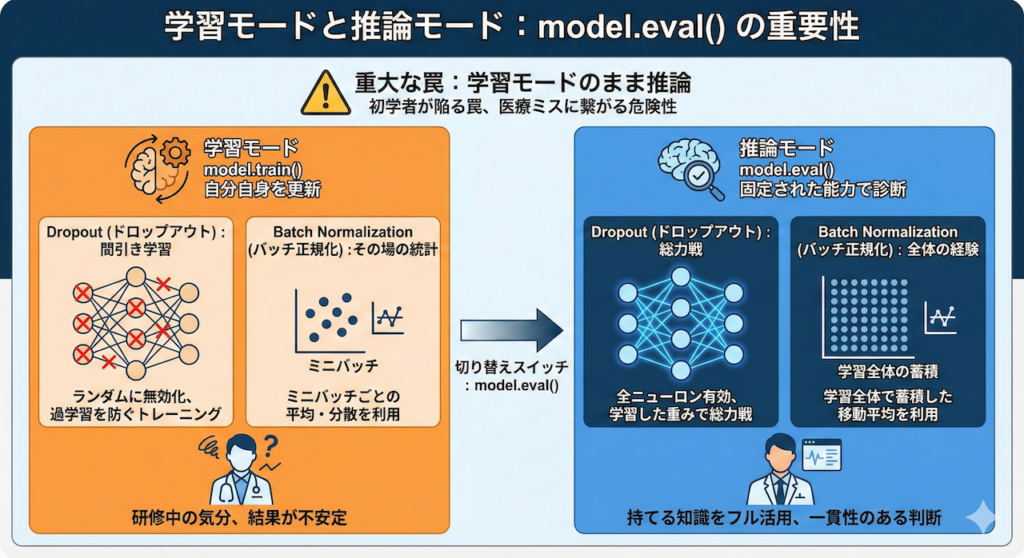
Dropout:間引き学習 vs 総力戦
- 学習時(Train):過学習を防ぐため、ランダムにニューロンを「無効化(ドロップアウト)」しながら学習します。これは、あえて一部の記憶を封じて、残りの脳細胞だけで判断させるトレーニングのようなものです。
- 推論時(Eval):すべてのニューロンを有効にし、学習した重みをスケーリングして「総力戦」で予測を行います。
もし学習モードのまま推論すると、ランダムにニューロンが休止するため、同じ画像を入力しても毎回違う診断結果が出るという恐ろしい事態になります。
Batch Normalization:その場の統計 vs 全体の経験
- 学習時(Train):入力されたミニバッチ(少数のデータ群)ごとの平均と分散を使って正規化します。
- 推論時(Eval):学習プロセス全体を通じて蓄積・計算しておいた「移動平均(Running Statistics)」を使います。
推論時はデータが1件(バッチサイズ1)で来ることもあります。そのたった1件の統計量を使って正規化してしまうと、データが極端に歪んでしまい、精度が著しく低下します。
医師に例えるなら
model.eval() を忘れることは、医師が「まだ研修中の気分のまま(答えをあてずっぽうで隠したりしながら)」患者さんを診察するようなものです。診察(推論)の現場では、持てる知識をフル活用し、一貫性のある判断を下す必要があります。そのためのスイッチが model.eval() なのです。
3. AIの共通言語:ONNXによる相互運用性
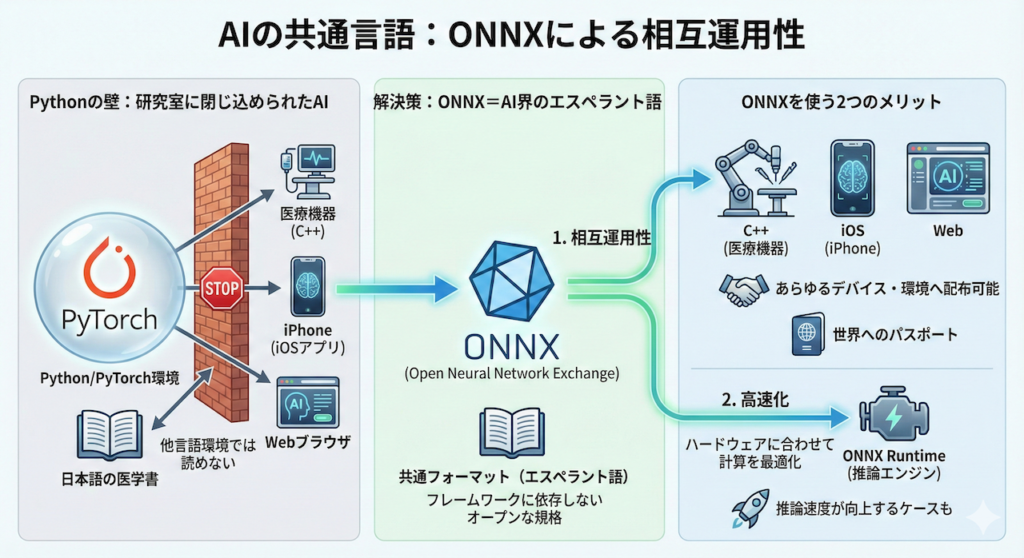
Pythonの壁を越えるには
あなたがPythonとPyTorchで開発した素晴らしいAIモデル。これを「実際の医療現場で使いたい」となったとき、大きな壁にぶつかることがあります。
例えば、手術室にある医療機器はC++で制御されているかもしれませんし、医師が回診で使うのはiPhone(iOSアプリ)かもしれません。あるいは、インストール不要なWebブラウザ上で動かしたいという要望もあるでしょう。
これらの環境すべてに、PythonやPyTorchの重厚なライブラリをインストールするのは、容量や計算リソース、セキュリティの観点から現実的ではありません。
「Python環境がないと動かない」という制約は、AIの実用化において大きな足かせとなります。
ONNX:AI界の「エスペラント語」
そこで登場するのが、ONNX(Open Neural Network Exchange:オニキス) です (Bai et al. 2019)。
ONNXは、ディープラーニングモデルを表現するための、フレームワークに依存しないオープンな共通フォーマットです。
これを言語に例えてみましょう。
- PyTorch: 日本語で書かれた医学書
- TensorFlow: 英語で書かれた医学書
- C++ / iOS / Web: 読者が住んでいる様々な国
PyTorch(日本語)で書かれたモデルを、そのままではC++(ドイツ語圏)の環境で読むことはできません。そこで、モデルを一度 ONNX(世界共通のエスペラント語) に翻訳(変換)します。
一度ONNX形式にしてしまえば、C++だろうが、iPhoneだろうが、Webブラウザだろうが、「ONNX Runtime」 という共通の翻訳機(推論エンジン)さえあれば、どこでもそのモデルを読み込んで動かせるようになるのです。
ONNXを使う2つのメリット
- 相互運用性(Interoperability):
特定のプログラミング言語やフレームワークに縛られず、モデルを広く配布・利用することが可能になります。「PyTorchで作って、iPhoneで動かす」といったクロスプラットフォームな開発が容易になります。 - 高速化(Optimization):
ONNXモデルを動かすためのエンジンである ONNX Runtime は、ハードウェア(CPU、GPUなど)に合わせて計算処理を高度に最適化してくれます。そのため、PyTorchでそのまま動かすよりも、ONNXに変換して動かしたほうが、推論速度が速くなるケースが多くあります。
このように、ONNXはあなたのモデルを「研究室のPython環境」から解き放ち、世界中のあらゆるデバイスへ届けるための「パスポート」の役割を果たします。
3.1 「どこで動かすか」で、最適解は分岐する(ONNX / Core ML / TensorRT)
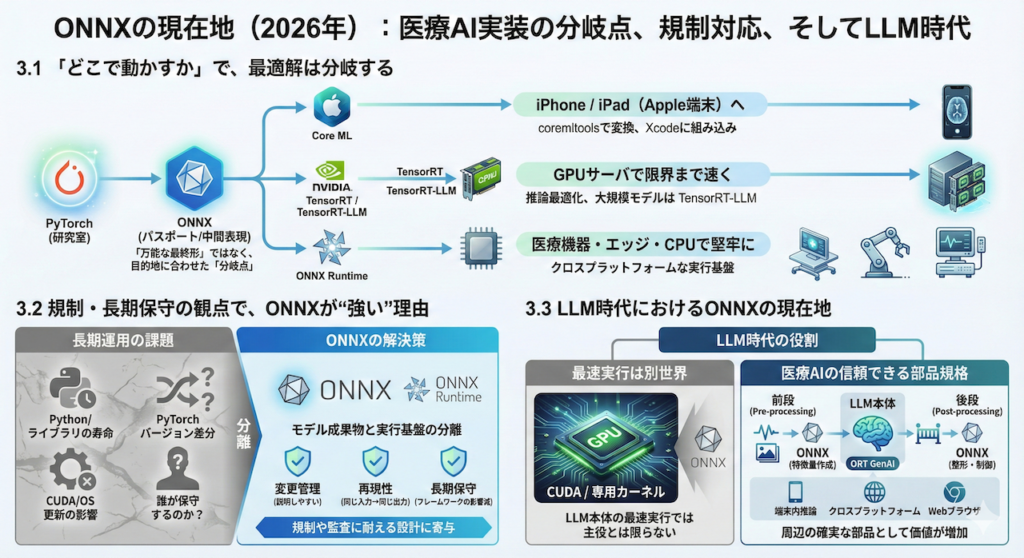
ここまでで、ONNXが「研究室のPython環境」からモデルを解き放つ“パスポート”になる話をしました。
ただし2026年の実務では、パスポート(ONNX)を取ったあとに、目的地に合わせて“最終便”を選ぶ、という考え方が一般的になっています。
- iPhone / iPad(Apple端末)に届けたいなら:Core ML
- GPUサーバで限界まで速く回したいなら:TensorRT(/ TensorRT-LLM)
- 医療機器・エッジ・CPU中心で堅牢に運用したいなら:ONNX Runtime
つまり、ONNXは「万能な最終形」ではなく、多くの現場で“分岐点(中間表現)”として機能しているのです。
- Core ML:Appleが提供する端末内推論の基盤。
coremltoolsにより学習済みモデルをCore ML形式に変換し、Xcodeに組み込むのが王道です。 - TensorRT:NVIDIA GPU上の推論最適化に特化したエンジン。特に大規模モデル推論では、LLM向けに最適化されたレイヤーである TensorRT-LLM が存在感を増しています。
3.2 規制・長期保守の観点で、ONNXが“強い”理由
医療AIは、一般のWebサービスと違い「作って終わり」になりません。
むしろ本番に入ってからが長い。5年、10年と“同じモデルを同じ振る舞いで”動かし続ける局面が普通にあります。
このとき現場で問題になるのが以下の点です。
- Python本体や依存ライブラリの寿命
- PyTorchのバージョン差分による微妙な挙動変化
- CUDAやOS更新による影響
- “誰が保守するのか問題”(開発者が異動・退職しても回る体制)
ONNX(+ONNX Runtime)を採用すると、少なくとも「研究コードの寿命問題」を切り離せます。
つまり、モデル成果物(ONNX)と実行基盤(Runtime)を分離でき、運用では「成果物としてのモデル」を中心に据えやすいのです。
加えて、ONNX Runtimeはモバイルや各種プラットフォーム向けの配布も整っており、実装・運用の現実解として採られやすい状況が続いています(例:iOS/Android要件の明示など)。
この「分離できる」という性質は、医療の文脈ではそのまま以下のようなメリットにつながり、“規制や監査に耐える設計”に寄与します。
- 変更管理(何を変えたのか説明しやすい)
- 再現性(同じ入力→同じ出力を担保しやすい)
- 長期保守(フレームワーク更新の波を受けにくい)
3.3 LLM時代におけるONNXの現在地(主役ではないが、重要度は増えている)
では、ChatGPT以降のLLM時代に、ONNXはどうなったのでしょうか?
結論から言うと以下のようになります。
- LLM“本体”の最速実行では主役とは限らない
CUDA最適化や専用カーネルが効く世界が強く、特に最新GPUの最前線ではONNX以外の選択肢が優位なケースがあります。 - 「端末内」や「クロスプラットフォーム」では強い
「端末内でLLMを動かす」「異なるOS間で同じ推論ループを回す」という要求に対し、ONNX Runtime側も生成AI向けの拡張(ORT GenAI)を前面に出しています。
さらに重要なのは、医療プロダクトの多くが “LLM単体”では完結しないことです。
- 画像・波形・検査値から特徴量を作る前段(ここはONNXが強い)
- LLMの出力を安全に整形・制御する後段(ガードレール)
- オフライン環境・院内閉域網・端末内推論などの制約
こうした「周辺の確実な部品」が増えるほど、ONNXは “医療AIの信頼できる部品規格” として価値が上がります。
また、Webブラウザ上での推論(患者説明ツール、院内端末の簡易UIなど)も現実的になってきており、ONNX Runtime WebはWebGPU実行プロバイダを公式にドキュメント化しています。
4. 世界への窓口:FastAPIによるAPI化
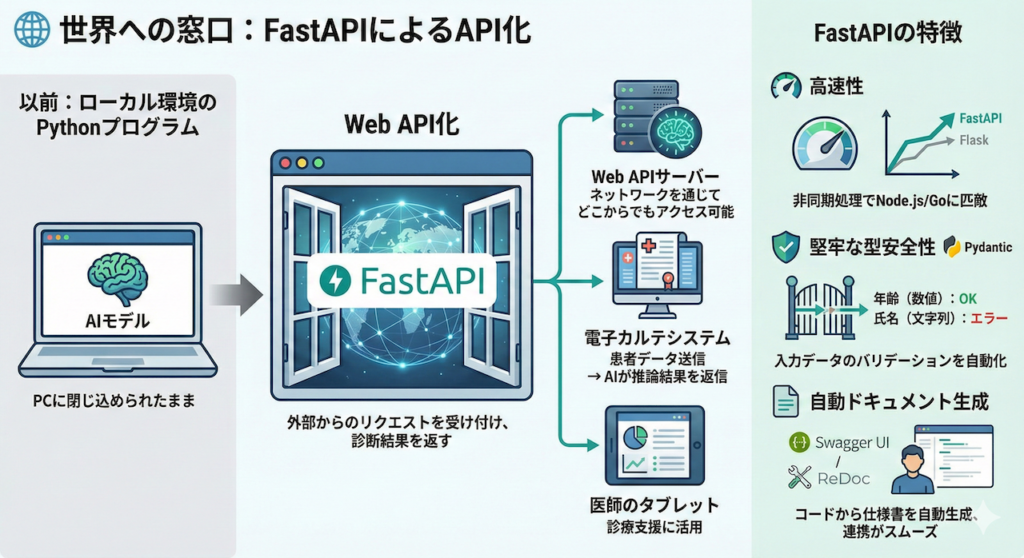
モデルを「サービス」に変える技術
モデルを保存し、推論できる準備が整いました。しかし、このままではそのAIは、あなたのPCの中に閉じ込められたままです。
これを実際の医療現場で使えるようにするには、「外部からのリクエストを受け付け、診断結果を返す」という仕組みが必要です。そのための標準的な手法が、Web API(Application Programming Interface) の構築です。
Web API化することで、あなたのモデルは「ローカル環境のPythonプログラム」から、「ネットワークを通じてどこからでもアクセスできる診断支援サーバー」へと進化します。例えば、電子カルテシステムから患者データを投げれば、瞬時にAIが推論結果を投げ返す、といった連携が可能になります。
FastAPI:現代の標準
現在、PythonでAIモデルのAPIを作る際、最も人気があり、事実上の標準として推奨されるライブラリが FastAPI です (Ramírez 2018)。
以前は Flask や Django が主流でしたが、FastAPIは以下の特徴により、AI開発の現場で急速に普及しました。
- 高速性(High Performance):
非同期処理(Asynchronous processing)をネイティブにサポートしており、Node.jsやGo言語に匹敵する非常に高いパフォーマンスを誇ります。大量のリクエストをさばく必要のある実運用環境では大きな強みとなります。 - 堅牢な型安全性(Type Safety):
Pythonの型ヒント(Type Hints)と Pydantic というライブラリを活用し、入力データのバリデーション(検証)を自動で行います。
医療データにおいて、「年齢(数値)」が入るべきところに「氏名(文字列)」が入ったり、「必須の検査値」が欠けていたりすることは許されません。FastAPIはこうした不正なデータを入り口で弾き、エラーとして報告してくれるため、堅牢なシステムを構築できます。 - 自動ドキュメント生成(Automatic Documentation):
コードを書くだけで、APIの仕様書(Swagger UI / ReDoc)が自動生成されます。これにより、フロントエンドエンジニアや他のシステム担当者との連携が劇的にスムーズになります。「どのようなデータを送ればよいか」がひと目で分かる説明書が、勝手に出来上がるのです。
FastAPIは、あなたが作ったAIという「専門医」のために、受付窓口(API)と、患者データのチェック係(バリデーション)、そして診療案内(ドキュメント)を一度に用意してくれる強力なツールと言えるでしょう。
まとめ:研究から実用への架け橋
AIモデルをファイルとして保存し、model.eval() で正しい「医師モード」に切り替え、APIを通じて外部と対話させる。これらは、あなたの作り上げた知能を、閉じた実験室から現実世界へと解き放つための不可欠な手続きです。
しかし、デプロイはゴールではありません。実運用が始まれば、モデルの精度が時間とともに劣化していないか監視したり(ドリフト検知)、セキュリティを担保したりといった MLOps(Machine Learning Operations) の課題が待っています。
次回は、より堅牢で保守性の高いコードを書くための「Pythonプロの作法」について深掘りしていきます。
参考文献
- Bai, J. et al. (2019). ONNX: Open Neural Network Exchange. GitHub.
- He, J. et al. (2019). The practical implementation of artificial intelligence technologies in medicine. Nature Medicine, 25(1), pp.30–36.
- Ioffe, S. and Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Proceedings of the 32nd International Conference on Machine Learning, 37, pp.448–456.
- Paszke, A. et al. (2019). PyTorch: An Imperative Style, High-Performance Deep Learning Library. Advances in Neural Information Processing Systems, 32.
- Ramírez, S. (2018). FastAPI. GitHub.
- Srivastava, N. et al. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research, 15, pp.1929–1958.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




