

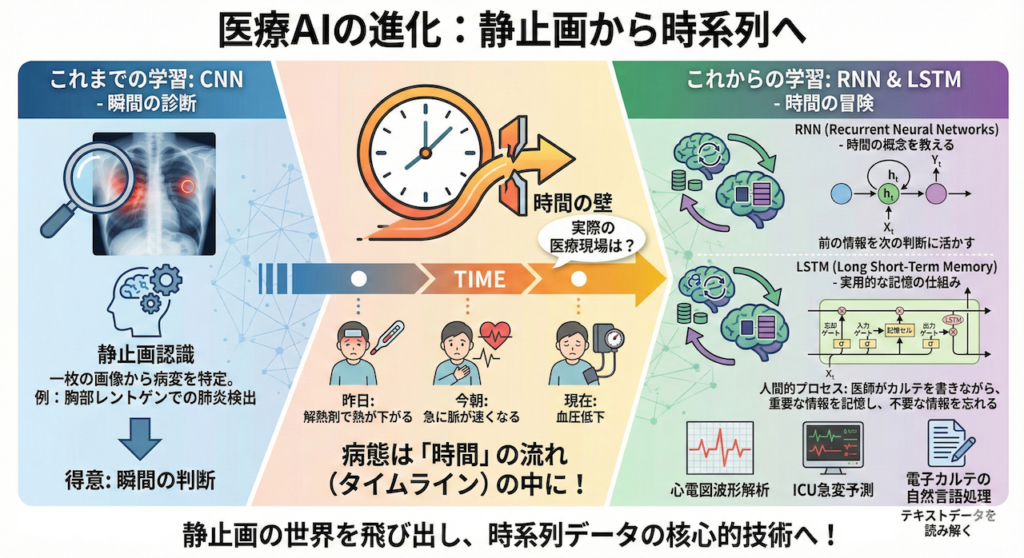
こんにちは。これまで私たちは、AIに「画像」を認識させる技術、CNN(畳み込みニューラルネットワーク)について学んできました。一枚の胸部レントゲン写真から肺炎の影を見つけ出すような技術は、いわば「瞬間の診断」を得意とするものです。
しかし、実際の医療現場を想像してみてください。
患者さんの病態は、決して「一瞬」だけで決まるものではありません。
「昨日は解熱剤で熱が下がったけれど、今朝になって急に脈が速くなり、血圧が下がり始めた……」
このように、時間の流れ(タイムライン)の中にこそ、病態の本質的な変化や予兆が隠れていることが多々あります。
そこで今回登場するのが、AIにこの「時間」という概念を教え込むための技術、RNN(再帰型ニューラルネットワーク)と、それをより実用的な記憶の仕組みへと進化させたLSTM(長・短期記憶)です。
これらは、心電図の波形解析や、ICUでの急変予測、さらには電子カルテのテキストデータ(自然言語処理)を読み解く上で、なくてはならない核心的な技術です。
アルファベットが並ぶと難しそうに見えるかもしれませんが、その仕組みは驚くほど人間的です。それはまるで、「医師が患者の経過を診てカルテを書きながら、重要な情報を記憶し、もはや不要になった情報を忘れていくプロセス」そのものと言えます。
さあ、静止画の世界を飛び出して、時間の冒険に出かけましょう。
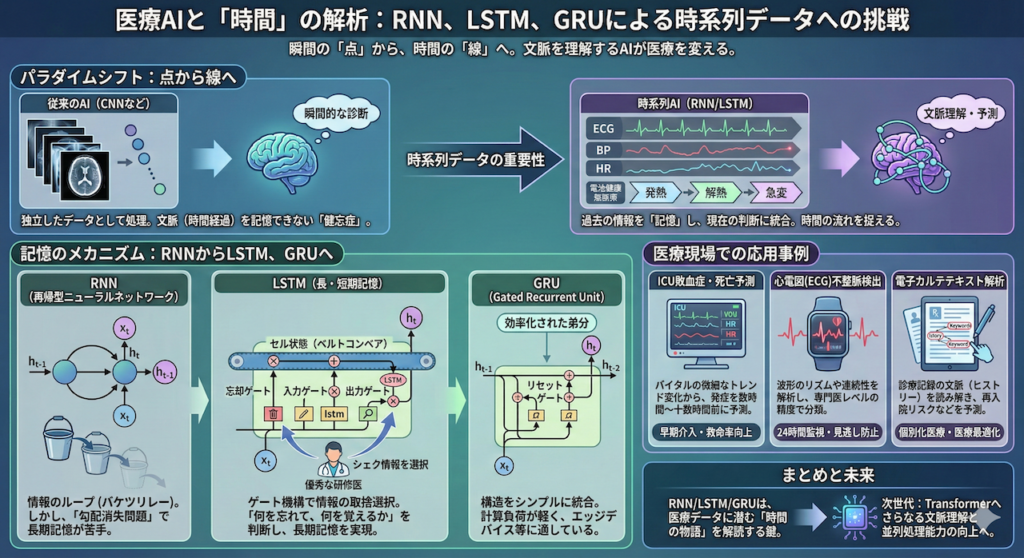
1. なぜAIに「記憶」が必要なのか?:点から線へのパラダイムシフト
これまで私たちは、画像診断などで活躍するCNN(畳み込みニューラルネットワーク)などを学んできました。これらは非常に優秀なAIですが、実はある一つの「致命的な欠点」を抱えています。
それは、「極度の健忘症」であるということです。
従来のAIは「瞬間」しか見ない
通常のニューラルネットワーク(全結合層やCNN)は、入力されたデータを常に「独立した事象」として扱います。これを人間に例えるなら、「一瞬ごとに記憶がリセットされる医師」のようなものです。
- 1枚目のレントゲンを見て「肺炎です」と診断する。
- 次の瞬間に2枚目のレントゲン(同じ患者の1ヶ月前の画像)を見ても、「さっき見た画像と比較する」ことはできません。 まるで初めて見る患者さんのように、ゼロから診断します。
静止画の分類であれば、これで問題ありません。しかし、医療の現場にあるデータの多くは、時間とともに変化する「時系列データ(Sequential Data)」です。ここでは、「文脈(コンテキスト)」が失われることは、致命的な判断ミスに繋がります。
時系列データにおける「文脈」の重要性
具体的な例で考えてみましょう。
ケース1:自然言語処理(カルテの解析)
電子カルテに「患者はアスピリンを」というテキストがあったとします。AIがこの言葉の意味を正しく理解するには、その後に続く言葉を待つだけでなく、前の言葉を覚えておく必要があります。
- パターンA: 「患者はアスピリンを」 → 「服用した」(治療)
- パターンB: 「患者はアスピリンを」 → 「禁忌とする」(アレルギー情報)
もしAIに記憶がなく、「服用した」や「禁忌とする」という単語だけを単独で見せられたらどうでしょうか? 「誰が? 何を?」という主語や目的語の情報が欠落しているため、それが推奨される行為なのか、避けるべき行為なのか判断できません。
ケース2:バイタルサイン(ショックの予兆)
救急外来で、ある患者さんの収縮期血圧が「100 mmHg」だったとします。この数値単独では、「正常範囲内」として見過ごされるかもしれません。しかし、これまでの経過(ヒストリー)を知っていたらどうでしょうか?
【文脈による意味の変化】
- ケースA(安定): 1時間前 100 → 30分前 102 → 現在 100
→ 判断:安定している。経過観察。 - ケースB(ショックの予兆): 1時間前 140 → 30分前 120 → 現在 100
→ 判断:急激な低下トレンド! ショック状態に移行する可能性が高く、即座に介入が必要。
このように、数値そのもの(点)ではなく、「どのような変化を経て、その値になったのか(線)」という情報の中にこそ、病態の本質が隠れています。
AIに「記憶」を実装する
つまり、時系列データを正しく扱うためには、AIに以下の機能を持たせる必要があります。
「前のステップで処理したデータの内容(記憶)を保持し、それを次のステップの処理に持ち越して統合する機能」
これこそが、今回学ぶRNN(再帰型ニューラルネットワーク)の核心です。RNNは、過去のデータを「隠れ状態(Hidden State)」という名のメモ帳に圧縮して保存し、常にそれを参照しながら新しいデータを処理します。
2. RNN(再帰型ニューラルネットワーク):情報をループさせる
RNN (Recurrent Neural Network) の「Recurrent」とは「回帰する」「戻ってくる」という意味で、その名の通り、情報がネットワーク内でぐるぐると回る構造を持っています。
RNNの直感的イメージ:記憶のバケツリレー
RNN(リカレントニューラルネットワーク)の仕組みは、一見複雑そうに見えますが、その本質は非常に人間的な活動に似ています。それは、「伝言ゲーム」や、医療現場における「申し送り(ハンドオーバー)」です。
通常のAI(CNNなど)は、入力されたデータをその場限りで処理し、次のデータが来ると前のことはすっかり忘れてしまいます。これは、患者さんを診察するたびに記憶喪失になる医師のようなもので、時系列の変化を追うことができません。
対してRNNは、「前のステップの結果(記憶)」を「次のステップの入力」に混ぜ合わせるというループ構造を持っています。
【RNNの思考プロセス】
「昨日のデータ(過去の記憶)」と「今日のデータ(現在の入力)」をセットで見て、「今の状態」を判断する。そして、その結果を「明日の自分」への申し送り事項として残す。
この情報の受け渡しこそが、RNNが「文脈」を理解できる理由です。
上図のように、RNNは時間を追って展開(Unroll)して考えると分かりやすくなります。左から右へ、時間が流れるにつれて「記憶(緑色の矢印)」がバケツリレーのように受け渡されていく様子がイメージできるでしょうか。
この「隠れ状態(Hidden State)」と呼ばれる緑色の矢印の中に、過去の文脈やトレンドといった重要な情報が圧縮されて保存されているのです。
数式で見るRNN:記憶更新のメカニズム
「数式」と聞くと身構えてしまうかもしれませんが、安心してください。RNNがやっていることは、実はたった2つのこと、「足し算」と「圧縮」だけです。
時刻 \( t \) (現在)における隠れ状態(記憶)を \( h_t \) とすると、その更新ルールは次のような式で表せます。
\[ h_t = \tanh( \underbrace{W_{hh} h_{t-1}}_{\text{過去の記憶}} + \underbrace{W_{xh} x_t}_{\text{今の出来事}} + b ) \]
この式の意味を、一つずつ紐解いてみましょう。
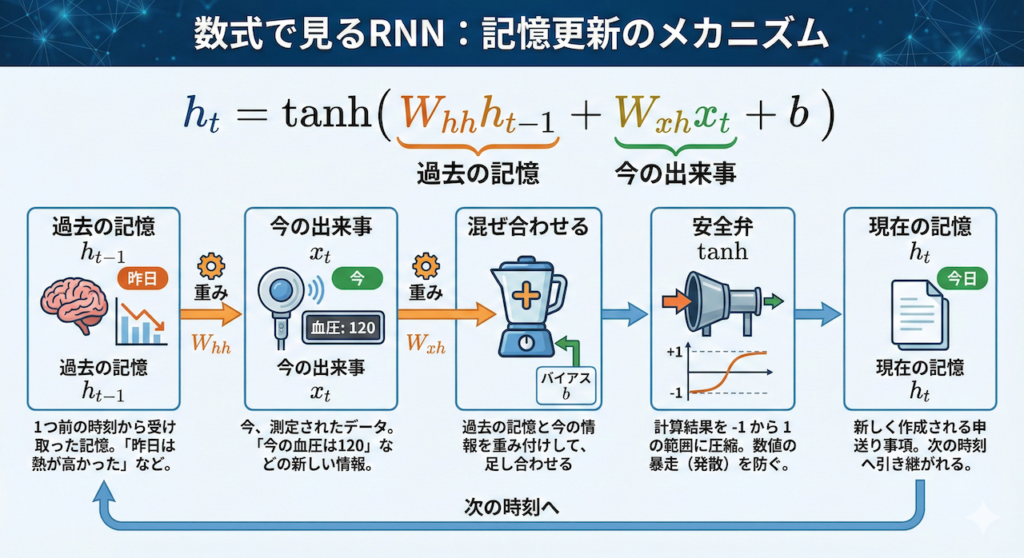
- \( h_t \)(現在の記憶):
今、新しく作成される申し送り事項です。これが次の時刻へと引き継がれます。 - \( h_{t-1} \)(過去の記憶):
1つ前の時刻(昨日)から受け取った記憶です。「昨日は熱が高かった」などの情報が含まれます。 - \( x_t \)(現在の入力):
今、目の前で測定されたデータです。「今の血圧は120」などの新しい情報です。 - \( W_{hh}, W_{xh} \)(重みパラメータ):
「過去の記憶」と「今の情報」、どちらをどれくらい重視するかを決める調整役です。学習によって最適なバランスに自動調整されます。 - \( \tanh \)(ハイパボリックタンジェント):
計算結果を \(-1\) から \(1\) の範囲にギュッと押し込める関数です。これがないと、足し算を繰り返すうちに数値が無限に大きくなって暴走(発散)してしまいます。情報の「安全弁」のような役割です。
つまりRNNは、「過去の記憶(\( h_{t-1} \))と、今の出来事(\( x_t \))を重み付けして混ぜ合わせ、安全弁(\( \tanh \))を通して新しい記憶(\( h_t \))を作る」という処理を、延々と繰り返しているのです。
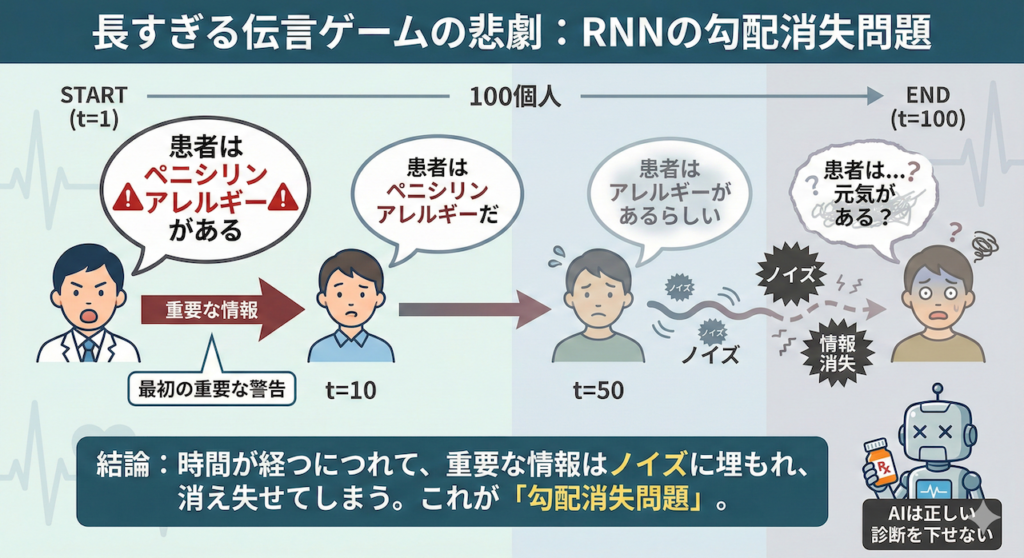
3. RNNの弱点:「勾配消失問題」という忘却
理論上、RNNは過去の情報をすべて覚えているはずです。しかし、実際に運用してみると、ある致命的な弱点が露呈しました。それは、「昔のことをすぐに忘れてしまう」という問題です。
文章が長くなったり、心電図の計測時間が長くなったりすると、最初のほうにあった重要な情報を維持できなくなってしまうのです。これを専門用語で「勾配消失問題(Vanishing Gradient Problem)」と呼びます。
たとえ話:長すぎる伝言ゲームの悲劇
この現象を、100人で「伝言ゲーム」をする状況に例えてみましょう。
最初の人が「患者はペニシリンアレルギーがある」という極めて重要な情報を伝えたとします。
しかし、情報が人(時刻 \( t \))を経るごとに、少しずつ内容が歪んだり、声が小さくなったりしていきます。
- 10人目:「患者はペニシリンアレルギーだ」
- 50人目:「患者はアレルギーがあるらしい」
- 100人目:「患者は…元気がある?」
100人目に到達する頃には、当初の重要な警告は完全に消え失せ、ノイズだけが残ってしまいます。これでは、AIは正しい診断を下すことができません。
数学的な正体:0.1の掛け算が招く「消失」
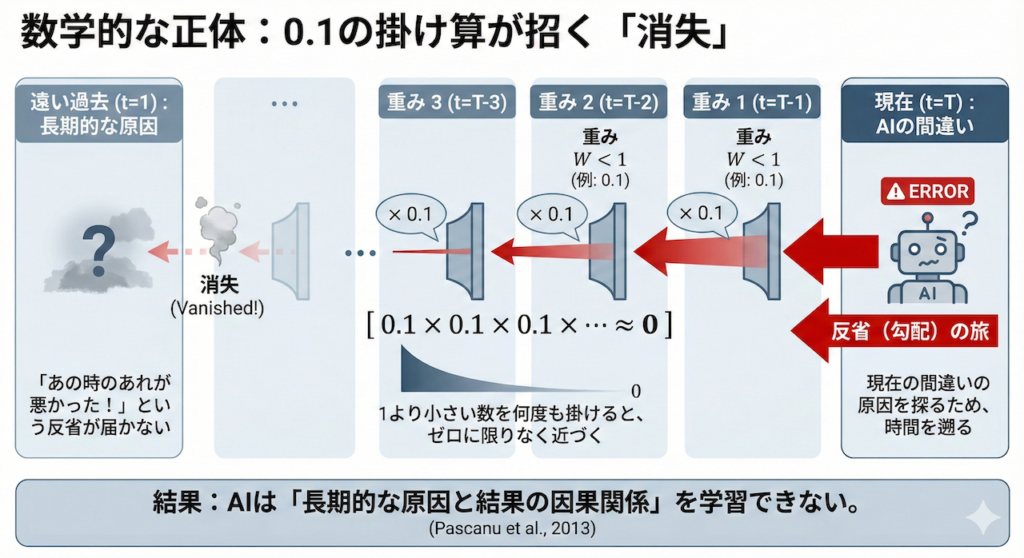
なぜこんなことが起きるのでしょうか? その犯人は「掛け算」です。
AIが学習する際(誤差逆伝播法)には、現在の間違いの原因を探るために、時間を過去へ過去へと遡りながら計算を行います。このとき、情報の通り道にある重み(パラメータ)を次々と掛け算していきます。
もし、その値が「1より小さい数(例えば 0.1)」だったらどうなるでしょうか?
\[ 0.1 \times 0.1 \times 0.1 \times \dots \approx 0 \]
0.1を何度も掛けると、あっという間にゼロに限りなく近づいてしまいます。
これは、「あの時のあれが悪かったんだ!」という反省(勾配)が、過去に届く前に消滅してしまうことを意味します (Pascanu et al., 2013)。結果として、AIは「長期的な原因と結果の因果関係」を学習できなくなってしまうのです。
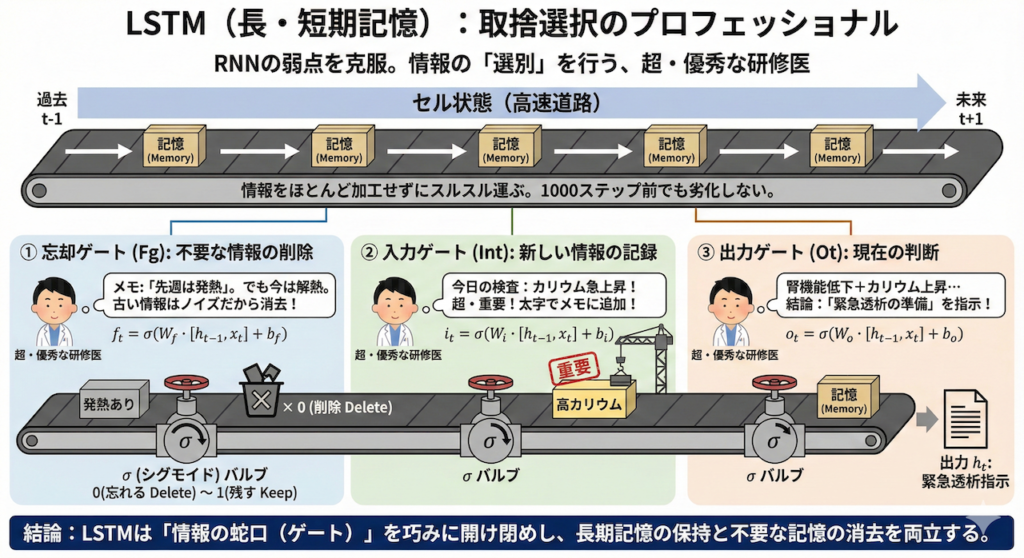
4. LSTM(長・短期記憶):取捨選択のプロフェッショナル
RNNが抱えていた「昔のことをすぐに忘れてしまう(勾配消失問題)」という致命的な弱点。これを克服するために、1997年にHochreiterとSchmidhuberによって発明されたのが、LSTM(Long Short-Term Memory:長・短期記憶)です。
LSTMの革命的な点は、「何を忘れて、何を覚えておくか」をAI自身が判断する能力を持たせたことにあります。
ただ情報を流すだけのRNNとは違い、LSTMは情報の「選別」を行います。それはまるで、膨大なカルテの中から重要な情報だけをピックアップし、不要な情報は容赦なく捨てていく、「超・優秀な研修医」のような存在です。
LSTMの核心:「セル状態」というベルトコンベア
LSTMの内部には、RNNにはなかった特別な通り道があります。それが「セル状態(Cell State)」です。
これをイメージするなら、「工場のベルトコンベア」や「高速道路」だと思ってください。このベルトコンベアは、過去から現在、未来へと、情報をほとんど加工せずにスルスルと運び続けます。
この「高速道路」があるおかげで、1000ステップ前の記憶であっても、劣化させることなく未来へ届けることができるのです。
そして、このベルトコンベアに対して、「荷物(情報)を降ろしたり、新しく乗せたり」する作業員がいます。それが「3つのゲート(門)」です。
LSTMの仕組み:優秀な研修医のメモ術
この3つのゲートの働きを、「患者さんの経過をメモし続ける研修医」の頭の中身に例えて、徹底的に分解してみましょう。
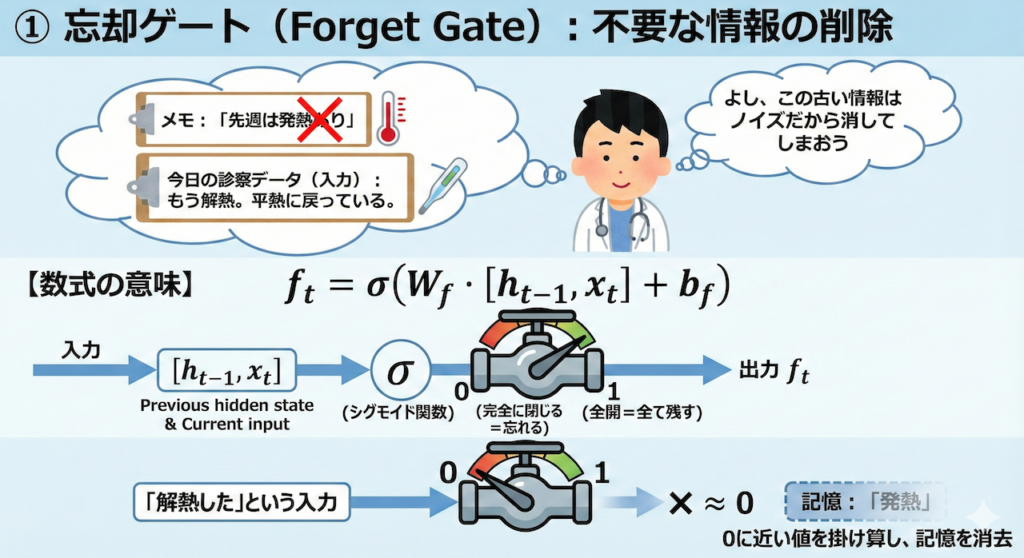
① 忘却ゲート(Forget Gate):不要な情報の削除
最初のステップは、「過去の記憶(セル状態)の中から、もう要らない情報を捨てる」ことです。
【研修医の思考】
「メモには『先週は発熱あり』って書いてあるな。
でも、今日の診察データ(入力)を見ると、もう解熱して平熱に戻っている。
よし、この『発熱あり』という古い情報は、これからの判断にはノイズになるから消してしまおう」
【数式の意味】
\[ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \]
- \( \sigma \)(シグモイド関数): 情報を「どれくらい通すか」を決めるバルブです。\(0\)(完全に閉じる=忘れる)から \(1\)(全開=全て残す)の間の値を出力します。
- 「解熱した」という入力があれば、発熱の記憶に対して \(0\) に近い値を掛け算し、記憶を消去します。
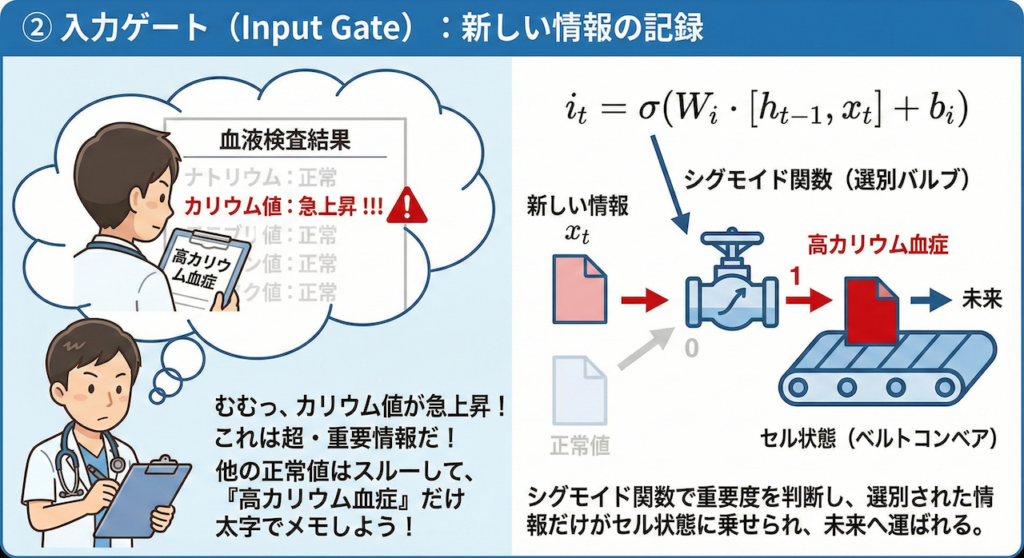
② 入力ゲート(Input Gate):新しい情報の記録
次のステップは、「新しい情報の中から、重要なことだけを選んで記憶に追加する」ことです。
【研修医の思考】
「今日の血液検査の結果が届いたぞ。
むむっ、カリウム値が急上昇している。これは命に関わる超・重要情報だ!
他の正常値だった項目はスルーしていいけど、この『高カリウム血症』という事実だけは、太字でメモに書き加えておこう」
【数式の意味】
\[ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \]
- ここでもシグモイド関数を使い、「どの情報をメモするか」を選別します。
- 重要だと判断された情報だけが、ベルトコンベア(セル状態)に乗せられ、未来へと運ばれます。
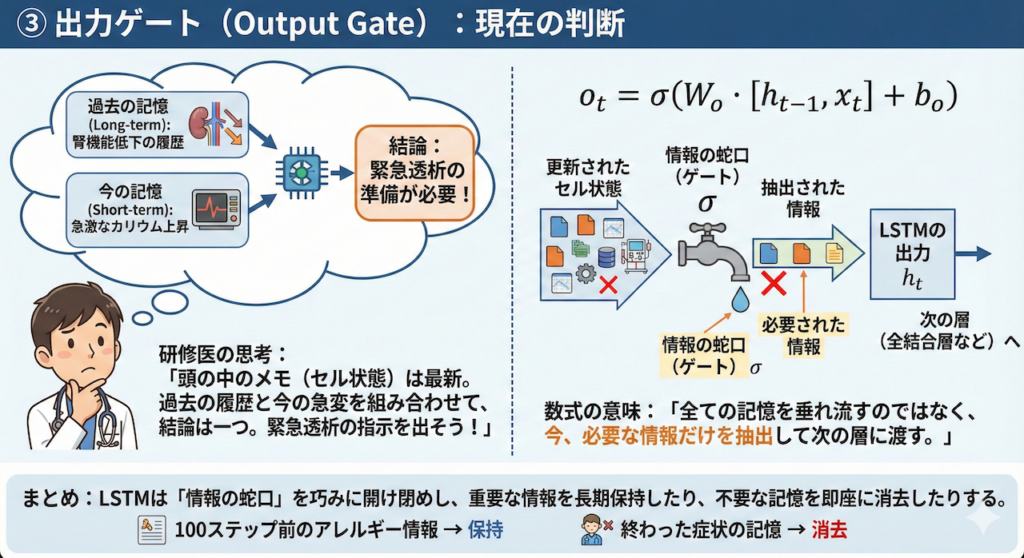
③ 出力ゲート(Output Gate):現在の判断
最後のステップは、「更新された記憶をもとに、今の瞬間の結論を出す」ことです。
【研修医の思考】
「さて、頭の中のメモ(セル状態)は最新版に更新された。
『過去から続く腎機能低下の履歴』と、今さっき書き加えた『急激なカリウム上昇』。
この2つを組み合わせて考えると……結論は一つだ。
『緊急透析の準備が必要』という指示(出力)を出そう!」
【数式の意味】
\[ o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \]
- 全ての記憶を垂れ流すのではなく、「今、この瞬間に必要な情報」だけを抽出して、次の層(全結合層など)に渡します。これがLSTMの出力(\(h_t\))となります。
このように、LSTMは「情報の蛇口(ゲート)」を巧みに開け閉めすることで、100ステップ前の重要なアレルギー情報を保持し続けたり、逆に終わった症状の記憶を即座に消去したりすることができるのです。
GRU (Gated Recurrent Unit):効率化されたスマートな弟分
LSTMは「記憶の取捨選択」ができる素晴らしい技術ですが、一つだけ欠点がありました。それは、「構造が複雑すぎて、計算に時間がかかる」ということです。
3つのゲートと、ベルトコンベア(セル状態)と、作業スペース(隠れ状態)を個別に管理するのは、コンピュータにとっても重労働なのです。
そこで2014年、LSTMの性能をほぼ維持したまま、構造を劇的にシンプルにしたモデルが提案されました。それがGRU(Gated Recurrent Unit)です (Cho et al. 2014)。
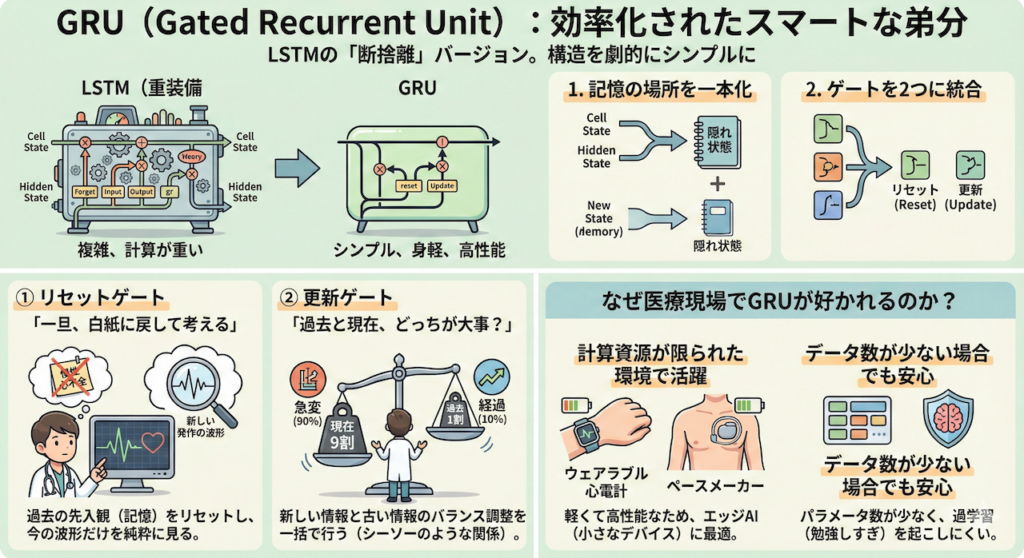
LSTMの「断捨離」バージョン
GRUは、LSTMが行っていた複雑な処理を、非常に合理的に統合しました。いわば、重装備のLSTMから不要な装飾を削ぎ落とし、身軽になった「ミニマリストな弟分」です。
具体的な変更点は以下の2点です。
- 「記憶の場所」を一本化:
LSTMには「長期記憶(セル状態)」と「短期記憶(隠れ状態)」の2つのラインがありましたが、GRUはこれを「隠れ状態」の1本に統一しました。「長期も短期も、一つのノートにまとめて書けばいいじゃないか」という発想です。 - 「ゲート」を2つに統合:
LSTMの「3つのゲート」を整理し、「リセットゲート」と「更新ゲート」の2つだけにしました。
GRUの2つのゲート:その役割とは?
GRUの2つのゲートの働きを、再び「研修医の思考」で例えてみましょう。
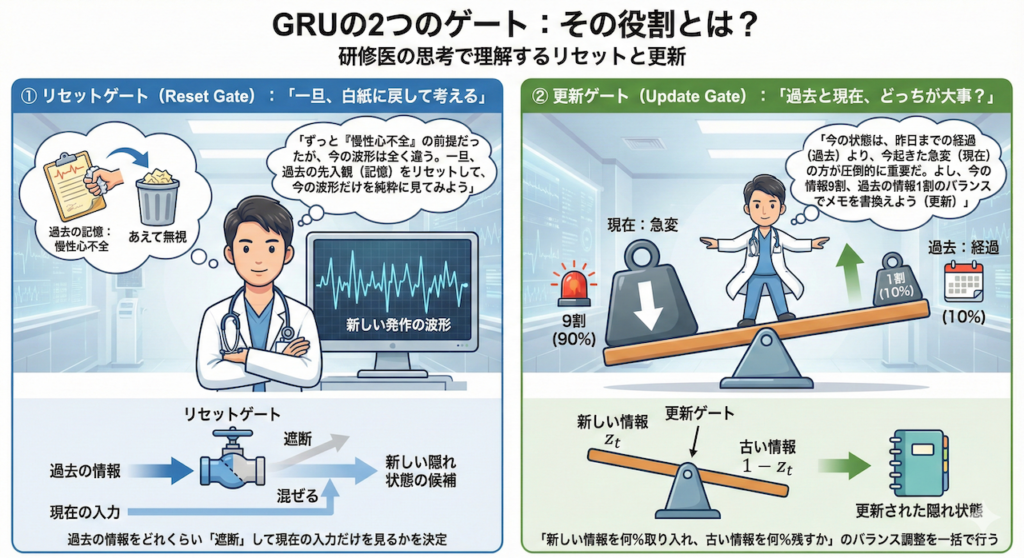
① リセットゲート(Reset Gate):「一旦、白紙に戻して考える」
これは、過去の記憶を「あえて無視する」ためのゲートです。
【研修医の思考】
「ずっと『慢性心不全』という前提で診てきたけれど、今の心電図の波形はそれとは全く関係ない、新しい発作の形をしている。
一旦、過去の先入観(記憶)をリセットして、今の波形だけを純粋に見てみよう」
このように、過去の情報をどれくらい「混ぜる」か、あるいは「遮断」して現在の入力だけを見るかを決定します。
② 更新ゲート(Update Gate):「過去と現在、どっちが大事?」
ここがGRUの最も賢い点です。LSTMでは「忘れる(忘却ゲート)」と「覚える(入力ゲート)」を別々に判断していましたが、GRUはこれを「シーソーのような関係」として1つにまとめました。
つまり、「新しい情報を \(80\%\) 取り入れるなら、古い情報は自動的に \(20\%\) だけ残す」というように、バランス調整を一括で行うのです。
【研修医の思考】
「今の患者さんの状態は、昨日までの経過(過去)よりも、今起きた急変(現在)の方が圧倒的に重要だ。
よし、頭の中のメモを、今の情報 \(9\) 割、過去の情報 \(1\) 割のバランスで書き換えよう(更新)」
なぜ医療現場でGRUが好かれるのか?
LSTMと比べて計算量が少ないGRUは、「計算資源が限られた環境」でその真価を発揮します。
例えば、バッテリーで動くウェアラブル心電計や、体内に埋め込むペースメーカーなど、高性能なGPUを積めない小さなデバイス内でAIを動かす場合(エッジAI)、軽くて高性能なGRUは最適な選択肢となります。
また、データ数が少ない場合でも、パラメータ数が少ないGRUの方が、過学習(勉強しすぎて応用が利かなくなること)を起こしにくいというメリットもあります。
5. 医療現場での応用事例:AIが「時間の流れ」を味方につけたとき
これまで学んだRNNやLSTM、そしてその発展系である時系列AIは、研究室の中だけの理論ではありません。すでに医療の最前線で、医師の「第二の目」となり、患者さんの命を守るための強力な武器として稼働しています。
ここでは、世界的なインパクトを与えた3つの記念碑的な研究事例を通して、「時系列データを解析できると、医療はどう変わるのか?」という問いへの答えを見ていきましょう。
① ICUでの敗血症・死亡予測:「沈黙の殺人者」の足音を聞く
集中治療室(ICU)は、一刻を争う戦場です。ここで最も恐れられているのが「敗血症(Sepsis)」です。感染症をきっかけに全身の臓器が暴走するこの病態は、発症から治療開始までの「1時間」の遅れが、生存率を数パーセント単位で下げると言われています。
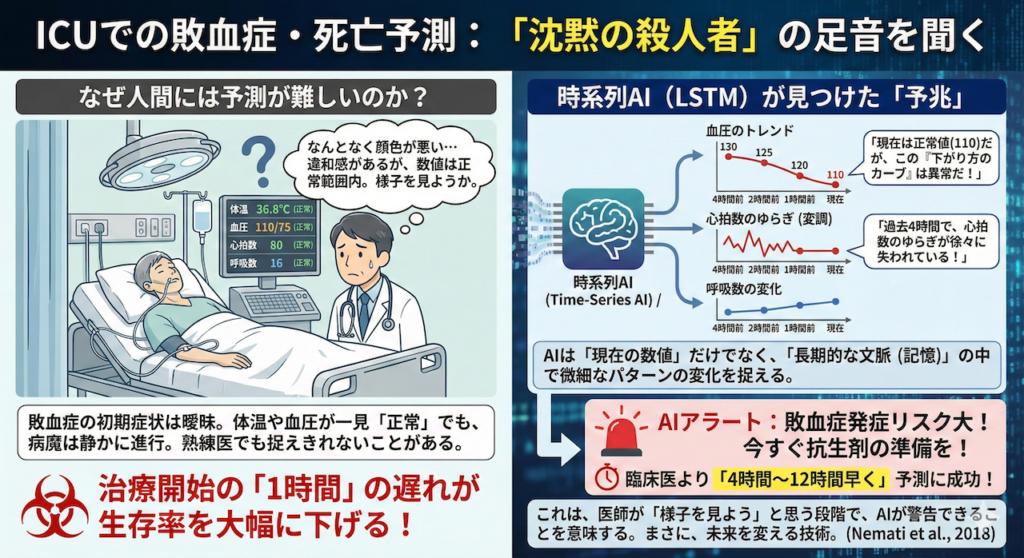
なぜ人間には予測が難しいのか?
敗血症の初期症状は非常に曖昧です。体温や血圧が一見「正常範囲内」に見えても、その裏で病魔は静かに進行しています。熟練の医師でさえ、「なんとなく顔色が悪い」といった違和感でしか捉えられないことがあります。
時系列AIが見つけた「予兆」
この課題に対し、Emory大学のNemati教授らのチームは、ICUの患者さんの膨大なバイタルデータ(心拍数、血圧、呼吸数などの時系列変化)をAIに解析させました (Nemati et al., 2018)。
AI(時系列モデル)は、単なる「現在の数値」は見ません。「変化のトレンド」を見ます。
- 「血圧はまだ正常値(110mmHg)だ。しかし、1時間前は130、30分前は120だった。この『下がり方のカーブ』は異常だ」
- 「心拍数のゆらぎ(変調)が、過去4時間で徐々に失われている」
人間が気づかないような微細なパターンの変化を、AIは「長期的な文脈(LSTMのような記憶)」の中で捉えます。その結果、このAIモデルは、臨床医が敗血症を認識するよりも「4時間から12時間も早く」発症を予測することに成功しました。
これは、医師がまだ「様子を見よう」と思っている段階で、AIが「今すぐ抗生剤の準備を!」とアラートを鳴らせることを意味します。まさに、未来を変える技術です。
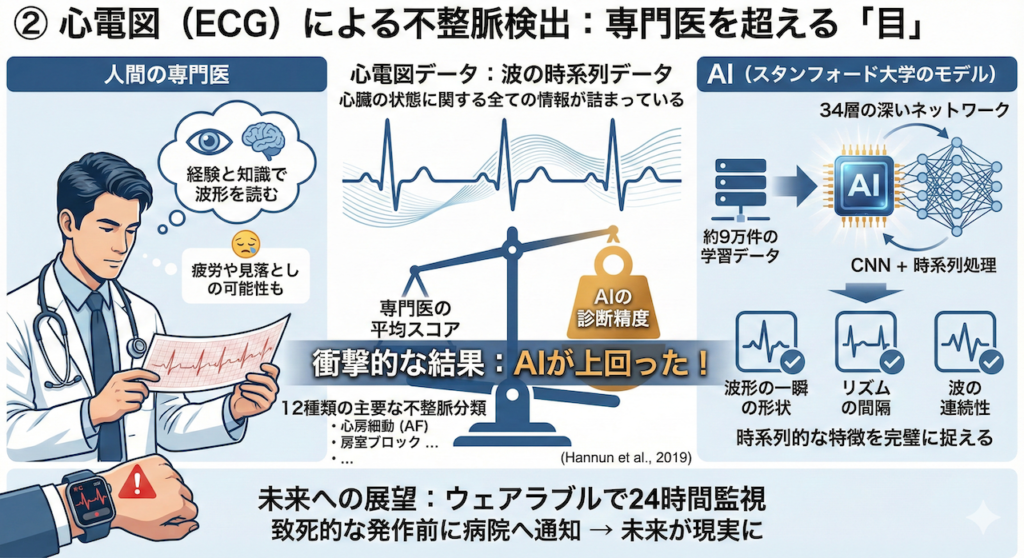
② 心電図(ECG)による不整脈検出:専門医を超える「目」
心電図(ECG)は、心臓の電気信号を記録した、まさに「波の時系列データ」です。この波形には、心臓の状態に関する全ての情報が詰まっています。
スタンフォード大学の挑戦
スタンフォード大学の研究チーム(Hannunら)は、「AIは人間の専門医よりも正確に心電図を読めるか?」という問いに挑みました (Hannun et al., 2019)。
彼らは、約9万件もの心電図データを、34層にも及ぶ深いニューラルネットワーク(CNNと時系列処理を組み合わせたモデル)に学習させました。
その結果は衝撃的でした。
- 心房細動(AF)や房室ブロックなど、12種類の主要な不整脈の分類において、AIの診断精度は「循環器専門医の平均スコア」を上回ったのです。
AIは、波形の一瞬の形状だけでなく、「リズムの間隔」や「波の連続性」といった時系列的な特徴を完璧に捉えました。これにより、ウェアラブルウォッチで24時間心臓を監視し、致死的な発作が起きる前に病院へ通知する、といった未来が現実のものとなりつつあります。
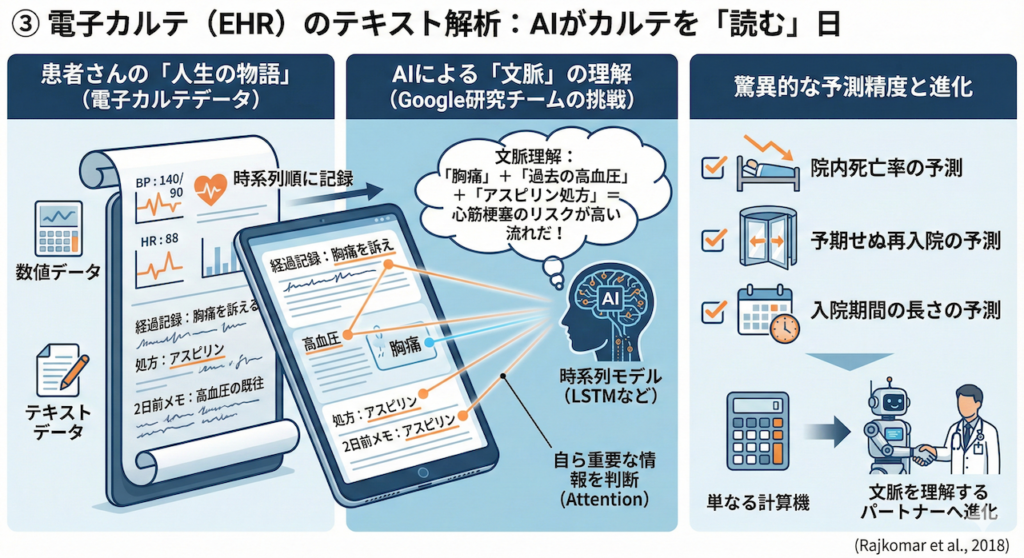
③ 電子カルテ(EHR)のテキスト解析:AIがカルテを「読む」日
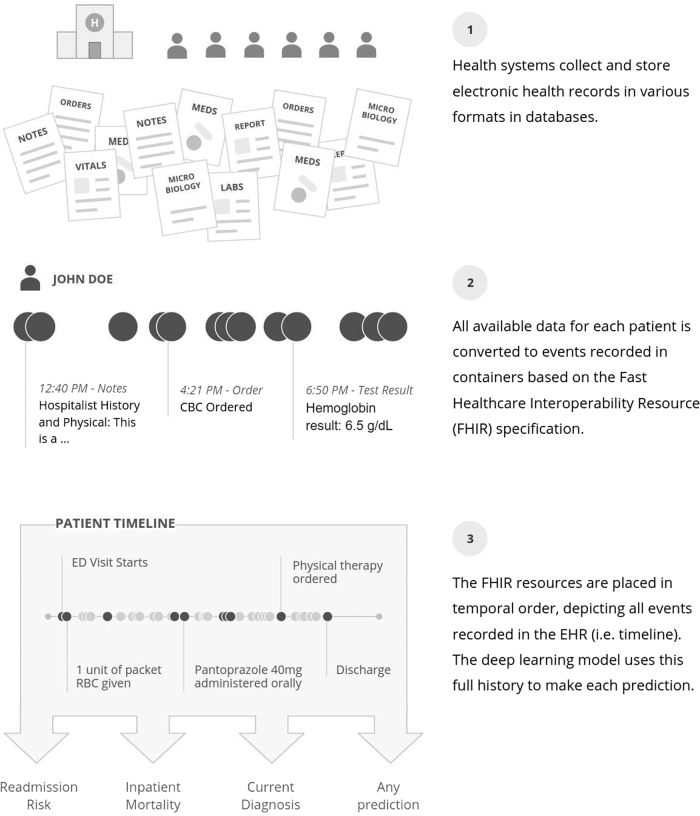
電子カルテには、検査値のような数値データだけでなく、医師が記述した「経過記録(テキスト)」や「処方履歴」など、多種多様なデータが時系列順に記録されています。これは、一人の患者さんの「人生の物語(ヒストリー)」そのものです。
Googleの「全診療記録」解析
Googleの研究チーム(Rajkomarら)は、この「物語」をAIに読ませる実験を行いました (Rajkomar et al., 2018)。
彼らは、FHIR(ファイア)という標準規格で整理された電子カルテデータ(非構造化テキストを含む)を、そのままLSTMなどの時系列モデルに入力しました。
AIは、以下のような文脈を理解しました。
「『胸痛』という単語がある。その2日前に『高血圧』の記録があり、直後に『アスピリン』が処方されている……この流れは、心筋梗塞のリスクが高い文脈だ」
その結果、このAIは以下の予測において驚異的な精度を叩き出しました。
- 院内死亡率の予測
- 予期せぬ再入院の予測
- 入院期間の長さの予測
特筆すべきは、人間が「ここは重要だから見てね」と教えたデータだけでなく、カルテの隅に書かれたメモのような情報まで含めて、AIが自ら「何が重要か(Attention)」を判断した点です。
これは、AIが単なる計算機から、「文脈を理解するパートナー」へと進化したことを示す決定的な証拠となりました。
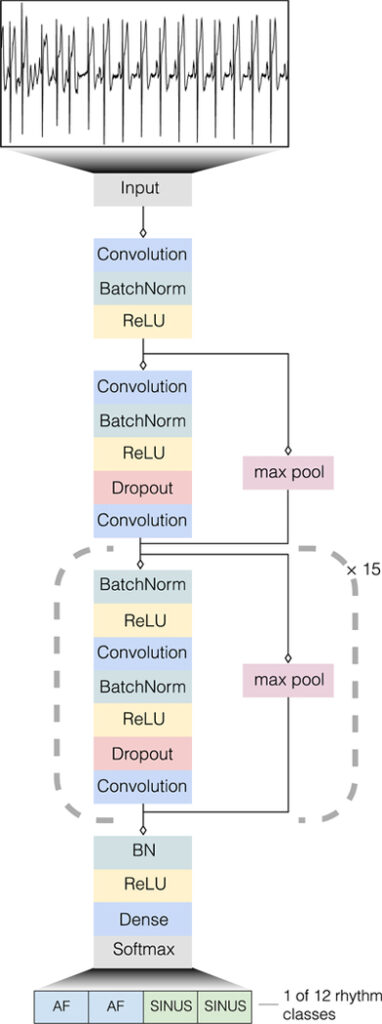
6. 【発展実習】AIドクターへの道:不整脈診断AIの「決定版」を実装する
先ほどのステップ3の実習では、AIに「波形の続き(未来)」を予測させました。これは「時系列予測(Forecasting)」と呼ばれるタスクです。
しかし、医療現場で医師が求めているのは、単なる波形の予測だけではありません。「で、この波形は病気なの? 正常なの?」という「診断(Classification)」こそが、AIに期待される最大の役割でしょう。
そこで最後の発展実習として、世界中の研究者が使用している本物の医療ビッグデータ「MIT-BIH Arrhythmia Database」を使い、AIに不整脈の種類を自動診断させてみましょう。
データ出典
本コンテンツでは、PhysioNet が提供する MIT-BIH Arrhythmia Database を使用しています。Moody GB, Mark RG. The impact of the MIT-BIH Arrhythmia Database. IEEE Eng Med Biol Mag. 2001.
本データは Open Data Commons Attribution License (ODC-BY 1.0) に基づき公開されています。
出典を明記することで、研究・教育・商用目的での利用が許可されています。本内容は研究・教育目的であり、医療行為を目的としたものではありません。
使用するデータセット:MIT-BIH(Kaggle版)
今回は、ボストン・ベス・イスラエル病院が公開している標準データベースを、研究用に使いやすく加工(心拍ごとに切り出し・正規化)したデータセットを使用します。これにより、複雑な前処理なしで、すぐにAIの学習を始められます。
📥 データセットの入手と準備(重要!)
本実習を行うには、以下のKaggleページからデータをダウンロードし、Google Colabにアップロードする必要があります。
Kaggle: ECG Heartbeat Categorization Dataset
※ダウンロードしたZIP内の mitbih_test.csv (テスト用ファイル)を使用します。ファイルサイズが手頃で学習が早いため、今回はこれを学習・評価に使います。
📍 置き場所と名前のルール
- ファイル名: 必ず
mitbih_test.csvに変更してください。((1)などが付かないように!) - 置き場所: Google Driveではなく、Colab画面左の「ファイル(📁)」を開いた一番上の階層に直接ドラッグ&ドロップしてください。
コードの解説:AI医師の頭の中を覗いてみよう
このプログラムは、単にデータを流し込んでいるだけではありません。AI(LSTM)の中で行われている処理は、人間の医師が心電図を読むプロセスと驚くほど似ています。

ステップ1:不均衡データの調整(トリアージ)
医療データで最もよくある問題が、「正常なデータばかりで、異常なデータが少なすぎる」ことです。そのまま学習させると、AIは「とりあえず全部『正常』と答えておけば99点取れる」とサボることを覚えてしまいます。
そこで、コード内で「正常データをあえて間引く(アンダーサンプリング)」処理を行い、異常データを見逃さないようにバランスを整えています。
ステップ2:Bi-LSTMによる「精読」
今回は、通常のLSTMを進化させた「Bi-LSTM(双方向LSTM)」を採用しました。
これは、心電図を「左から右(時間の流れ)」だけでなく、「右から左(時間を遡る)」方向にも読む技術です。これにより、「QRS波のあとにT波がある」だけでなく、「T波の前にはQRS波があったはずだ」という前後の文脈を完璧に理解します。
ステップ3:Global Max Poolingによる「診断」
不整脈の特徴(異常なスパイクなど)は、波形全体の中で「一瞬だけ」現れることがあります。そこで、時系列データ全体の中で「最も強く反応した特徴」だけをピックアップする技術(Pooling)を使い、微細な異常も見逃さずに診断を下します。
【Pythonコード】不整脈診断AI(決定版)の実装
以下のコードは、現在のAI開発の現場で使われている「モダンな技術(AdamW, OneCycleLR, Data Augmentation)」を全て詰め込んだ、教科書的な実装です。
さらに、学習結果の確認用として、「バラバラのデータを結合して、10秒間の連続モニター波形を再現する機能」も搭載しました。
# ==========================================
# 0. 準備:ライブラリ(道具箱)の用意
# ==========================================
# グラフで日本語を表示するための道具をインストール(初回のみ実行されます)
try:
import japanize_matplotlib
except ImportError:
!pip install japanize-matplotlib
import japanize_matplotlib
# 必要な道具(ライブラリ)をインポート(読み込み)します
import pandas as pd # データ分析の基本ツール(Excelのような表を扱う)
import numpy as np # 数学計算のツール
import torch # AI(深層学習)を作るためのメインツール「PyTorch」
import torch.nn as nn # ニューラルネットワークの部品(層など)
import torch.optim as optim # AIを賢くするための設定(最適化アルゴリズム)
from torch.utils.data import Dataset, DataLoader # データを小分けにして運ぶ機能
from sklearn.model_selection import train_test_split # データを分割する機能
from sklearn.metrics import classification_report, confusion_matrix # 成績表を作る機能
import matplotlib.pyplot as plt # グラフを描く機能
import seaborn as sns # グラフを綺麗にする機能
import time # 時間を測る機能
# --- 乱数シードの固定(毎回同じ結果が出るようにする魔法) ---
def set_seed(seed=42):
torch.manual_seed(seed) # PyTorchのサイコロを固定
torch.cuda.manual_seed_all(seed) # GPUのサイコロを固定
np.random.seed(seed) # 数学ツールのサイコロを固定
torch.backends.cudnn.deterministic = True # 計算のブレをなくす
set_seed() # 実行!
# GPU(高速な計算機)が使えるか確認して設定します
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"✅ 使用デバイス: {device}")
# ==========================================
# 1. データの読み込みと前処理
# ==========================================
FILE_PATH = 'mitbih_test.csv' # Colabのファイル置き場にあるファイル名
# PyTorchでデータを扱うための「専用の箱」を定義します
class ECGDataset(Dataset):
def __init__(self, features, labels, augment=False):
# データを保存しておきます
self.features = features
self.labels = torch.tensor(labels, dtype=torch.long)
self.augment = augment # データ拡張(水増し)をするかどうかのスイッチ
def __len__(self):
return len(self.features) # データの個数を返します
def __getitem__(self, idx):
# 指定された番号のデータを取り出します
x = self.features[idx]
# --- データ拡張(学習時のみ実行)---
# データを少し加工して、AIに「応用力」をつけさせます
if self.augment:
# 1. ノイズ付加:波形に少しザラザラした雑音を混ぜます
noise = np.random.normal(0, 0.01, x.shape)
x = x + noise
# 2. スケーリング:波形の大きさを微妙に変えます(0.95倍〜1.05倍)
scale = np.random.uniform(0.95, 1.05)
x = x * scale
# PyTorchが読める形(Tensor)に変換して返します
# .unsqueeze(-1)で [長さ] を [長さ, 1] という形にします(LSTMのルール)
return torch.tensor(x, dtype=torch.float32).unsqueeze(-1), self.labels[idx]
# データを準備するメイン関数
def load_data():
print("⏳ データを読み込んでいます...")
try:
# CSVファイルを読み込みます(ヘッダーなし)
df = pd.read_csv(FILE_PATH, header=None)
except FileNotFoundError:
# ファイルがない場合のエラーメッセージ
print("❌ エラー: mitbih_test.csv が見つかりません。")
print(" Colab左側のフォルダアイコン📁にファイルをアップロードしてください。")
return None, None, None, None
# --- クラス不均衡の解消(トリアージ) ---
# 「正常(0)」が多すぎるので、AIがサボらないように3000個だけランダムに選びます
df_0 = df[df[187] == 0].sample(n=3000, random_state=42)
# 異常データ(1~4)は貴重なので全部使います
df_others = df[df[187] != 0]
# 合体させます
df_balanced = pd.concat([df_0, df_others])
# データ(X)と正解ラベル(y)に分けます
X = df_balanced.iloc[:, :-1].values
y = df_balanced.iloc[:, -1].values.astype(int)
# --- データの分割(学習:検証:テスト = 7:1.5:1.5) ---
# まず「学習用」と「残り」に分けます
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# 「残り」を「検証用」と「テスト用」に分けます
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42, stratify=y_temp)
# クラスごとの「重み」を計算します(少ない異常データを間違えたらペナルティを大きくする)
class_counts = np.bincount(y_train) # 各クラスの個数を数える
weights = 1. / class_counts # 個数の逆数を計算(少ないほど値が大きくなる)
weights = weights / weights.sum() # 合計が1になるように調整
class_weights = torch.FloatTensor(weights).to(device) # GPUに送る
# データローダー(運び屋)を作成します
batch_size = 64
# 学習用だけ augment=True(データ拡張ON)にします
train_loader = DataLoader(ECGDataset(X_train, y_train, augment=True), batch_size=batch_size, shuffle=True)
val_loader = DataLoader(ECGDataset(X_val, y_val), batch_size=batch_size, shuffle=False)
test_loader = DataLoader(ECGDataset(X_test, y_test), batch_size=batch_size, shuffle=False)
return train_loader, val_loader, test_loader, class_weights
# ==========================================
# 2. モデル定義:純粋かつ強力な Bi-LSTM
# ==========================================
class UltimateLSTM_Model(nn.Module):
def __init__(self, input_size=1, hidden_size=128, num_layers=2, num_classes=5):
super(UltimateLSTM_Model, self).__init__() # おまじない
# 1. Bi-LSTM層(脳みそ)
# input_size: 波形の高さ1つずつ
# hidden_size: 記憶容量(128個の特徴を覚える)
# num_layers: 2段重ねにして深く理解する
# bidirectional=True: 「過去→未来」と「未来→過去」の両方向から読む!
self.lstm = nn.LSTM(
input_size, hidden_size, num_layers,
batch_first=True, bidirectional=True, dropout=0.3
)
# 2. Batch Normalization(整理整頓係)
# LSTMの出力をきれいに揃えて、学習を安定させます
# 双方向なのでサイズは hidden_size * 2 になります
self.bn = nn.BatchNorm1d(hidden_size * 2)
# 3. 全結合層(診断係)
# 記憶をもとに、5つの病気の確率を計算します
self.fc = nn.Sequential(
nn.Linear(hidden_size * 2, 64), # 一旦64個にまとめる
nn.ReLU(), # 活性化関数(信号の強弱をつける)
nn.Dropout(0.3), # 過学習防止
nn.Linear(64, num_classes) # 最終的に5つに分類
)
def forward(self, x):
# x: [データの数, 187, 1]
self.lstm.flatten_parameters() # 高速化のためのおまじない
# LSTMに通します
# out: [データの数, 187, hidden*2] -> 各時刻ごとの記憶が出てきます
out, _ = self.lstm(x)
# 【重要テクニック】Global Max Pooling
# 全時刻の中で「最も強く反応した特徴」だけを取り出します。
# 不整脈のような「一瞬の異常」を見つけるのに最強の方法です。
out, _ = torch.max(out, dim=1)
# 整理整頓して、診断します
out = self.bn(out)
out = self.fc(out)
return out
# ==========================================
# 3. 学習ループ (最新技術:OneCycleLR + AdamW)
# ==========================================
def train_lstm(model, train_loader, val_loader, criterion, optimizer, scheduler, num_epochs=20):
print(f"\n🚀 学習プロセス開始 (全{num_epochs} Epochs)...")
# 成績を記録するノート
history = {'train_loss': [], 'val_acc': []}
start_time = time.time() # ストップウォッチ開始
for epoch in range(num_epochs):
# --- 勉強モード ---
model.train()
train_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device) # データをGPUへ
optimizer.zero_grad() # 前回の計算ゴミを捨てる
outputs = model(inputs) # AIに診断させる
loss = criterion(outputs, labels) # 正解とのズレを計算
loss.backward() # 修正量を計算(逆伝播)
# 勾配クリッピング:修正量が大きすぎるときにブレーキを掛ける(LSTMの安定剤)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step() # パラメータ更新
scheduler.step() # 学習率を微調整(OneCycleLR)
train_loss += loss.item() # ズレを記録
# --- テストモード(検証)---
model.eval()
correct = 0
total = 0
with torch.no_grad(): # 学習しないので記録ストップ
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1) # 一番高い確率のものを選ぶ
total += labels.size(0)
correct += (predicted == labels).sum().item() # 正解数を数える
# 平均スコアを計算
avg_train_loss = train_loss / len(train_loader)
val_acc = correct / total
history['train_loss'].append(avg_train_loss)
history['val_acc'].append(val_acc)
# 進捗を表示
print(f"Epoch [{epoch+1}/{num_epochs}] Loss: {avg_train_loss:.4f} | Val Acc: {val_acc:.2%} | LR: {optimizer.param_groups[0]['lr']:.6f}")
print(f"✨ 全工程完了 (所要時間: {time.time()-start_time:.1f}秒)")
return history
# ==========================================
# 4. メイン実行処理
# ==========================================
# 1. データを準備します
train_loader, val_loader, test_loader, class_weights = load_data()
if train_loader is not None:
# 2. モデルを作ります
model = UltimateLSTM_Model().to(device)
# 3. 損失関数(間違いの採点方法)
# class_weights: 少数クラスを間違えたら厳しく採点
# label_smoothing: 「絶対にこれだ!」と過信しすぎないようにする(汎化性能UP)
criterion = nn.CrossEntropyLoss(weight=class_weights, label_smoothing=0.1)
# 4. 最適化手法(トレーナー)
# AdamW: 現在、最も性能が出やすいと言われる手法の一つ
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)
# 5. 学習率スケジューラ
# OneCycleLR: 学習率を波のように動かして、短時間で最高の性能を引き出す技術
scheduler = optim.lr_scheduler.OneCycleLR(
optimizer, max_lr=0.003,
steps_per_epoch=len(train_loader), epochs=20
)
# 6. 学習スタート!
history = train_lstm(model, train_loader, val_loader, criterion, optimizer, scheduler, num_epochs=20)
# ==========================================
# 5. 最終評価と「10秒間の連続モニター」表示
# ==========================================
print("\n--- 🏥 最終診断レポート ---")
model.eval()
all_preds = []
all_labels = []
all_waves = []
# テストデータをすべて集めます
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
all_waves.extend(inputs.cpu().numpy())
class_names = ['正常(N)', '上室性(S)', '心室性(V)', '融合(F)', '不明(Q)']
# 詳細レポートを表示
print(classification_report(all_labels, all_preds, target_names=class_names))
# --- 混同行列(どの病気を間違えやすいか?) ---
cm = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=class_names, yticklabels=class_names)
plt.title('混同行列:AIの診断結果内訳')
plt.xlabel('AIの診断')
plt.ylabel('本当の病気')
plt.show()
# --- 【ここが新機能】10拍分をつなぎ合わせてリズムを表示 ---
print("\n--- 🩺 リズムストリップ(擬似的な10秒間連続モニター) ---")
print("※バラバラの拍を結合して、リズムの流れを再現しています。")
unique_classes = np.unique(all_labels)
fig, axes = plt.subplots(len(unique_classes), 1, figsize=(16, 3.5 * len(unique_classes)))
if len(unique_classes) == 1: axes = [axes] # クラスが1つの場合の対策
for i, cls in enumerate(unique_classes):
label_name = class_names[cls]
# そのクラスのデータを全部探します
indices = [idx for idx, lbl in enumerate(all_labels) if lbl == cls]
# ランダムに10個選びます
if len(indices) >= 10:
selected_indices = indices[:10]
else:
selected_indices = indices # あるだけ使う
# 波形をつなぎ合わせます
long_strip = []
for idx in selected_indices:
wave = all_waves[idx].flatten()
# ゼロ埋めを除去して、波形部分だけを取り出します
# 閾値0.05以上の部分を「意味のある波形」とみなします
meaningful_part = wave[wave > 0.05]
# まっ平らならスキップ、あれば追加
if len(meaningful_part) > 10:
# 前後の急激な変化を避けるため、少し端を削ります
start = 0
end = len(meaningful_part)
beat = meaningful_part[start:end]
long_strip.extend(beat)
# 心拍の間に少し隙間(等電位線)を入れます
long_strip.extend(np.zeros(20))
# モニター風にプロット(黒背景にネオングリーン)
ax = axes[i]
ax.plot(long_strip, color='#00FF00', linewidth=1.5)
ax.set_title(f"Clinical Rhythm Strip (10 beats): {label_name}", fontweight='bold', color='white', backgroundcolor='black', fontsize=12)
ax.set_facecolor('black')
# モニター風グリッド
ax.grid(True, color='#004400', linestyle='-', linewidth=0.5)
# 軸の色調整
for spine in ax.spines.values(): spine.set_color('#333333')
ax.tick_params(colors='#888888')
# 横軸の表示(長すぎるので目盛りは少し間引く)
ax.set_xlabel("Time (Simulated Samples)", color='#888888')
plt.tight_layout()
plt.subplots_adjust(top=0.92)
plt.show()✅ 使用デバイス: cuda
⏳ データを読み込んでいます...
🚀 学習プロセス開始 (全20 Epochs)...
Epoch [1/20] Loss: 1.8538 | Val Acc: 44.98% | LR: 0.000314
Epoch [2/20] Loss: 1.7350 | Val Acc: 22.34% | LR: 0.000843
Epoch [3/20] Loss: 1.5665 | Val Acc: 31.89% | LR: 0.001565
Epoch [4/20] Loss: 1.3911 | Val Acc: 65.65% | LR: 0.002286
Epoch [5/20] Loss: 1.3023 | Val Acc: 59.84% | LR: 0.002811
Epoch [6/20] Loss: 1.2627 | Val Acc: 10.93% | LR: 0.003000
Epoch [7/20] Loss: 1.2386 | Val Acc: 65.94% | LR: 0.002961
Epoch [8/20] Loss: 1.1879 | Val Acc: 50.69% | LR: 0.002850
Epoch [9/20] Loss: 1.1614 | Val Acc: 78.25% | LR: 0.002670
Epoch [10/20] Loss: 1.1422 | Val Acc: 82.78% | LR: 0.002432
Epoch [11/20] Loss: 1.1231 | Val Acc: 75.00% | LR: 0.002147
Epoch [12/20] Loss: 1.0903 | Val Acc: 76.67% | LR: 0.001829
Epoch [13/20] Loss: 1.0663 | Val Acc: 84.35% | LR: 0.001496
Epoch [14/20] Loss: 1.0578 | Val Acc: 82.78% | LR: 0.001162
Epoch [15/20] Loss: 1.0377 | Val Acc: 74.61% | LR: 0.000845
Epoch [16/20] Loss: 1.0199 | Val Acc: 83.17% | LR: 0.000561
Epoch [17/20] Loss: 0.9924 | Val Acc: 82.78% | LR: 0.000324
Epoch [18/20] Loss: 0.9896 | Val Acc: 84.84% | LR: 0.000147
Epoch [19/20] Loss: 0.9744 | Val Acc: 84.45% | LR: 0.000037
Epoch [20/20] Loss: 0.9892 | Val Acc: 83.27% | LR: 0.000000
✨ 全工程完了 (所要時間: 40.0秒)
--- 🏥 最終診断レポート ---
precision recall f1-score support
正常(N) 0.95 0.73 0.83 450
上室性(S) 0.43 0.90 0.58 84
心室性(V) 0.94 0.93 0.94 217
融合(F) 0.54 0.88 0.67 24
不明(Q) 0.99 0.97 0.98 242
accuracy 0.85 1017
macro avg 0.77 0.88 0.80 1017
weighted avg 0.90 0.85 0.86 1017
--- 🩺 リズムストリップ(擬似的な10秒間連続モニター) ---
※バラバラの拍を結合して、リズムの流れを再現しています。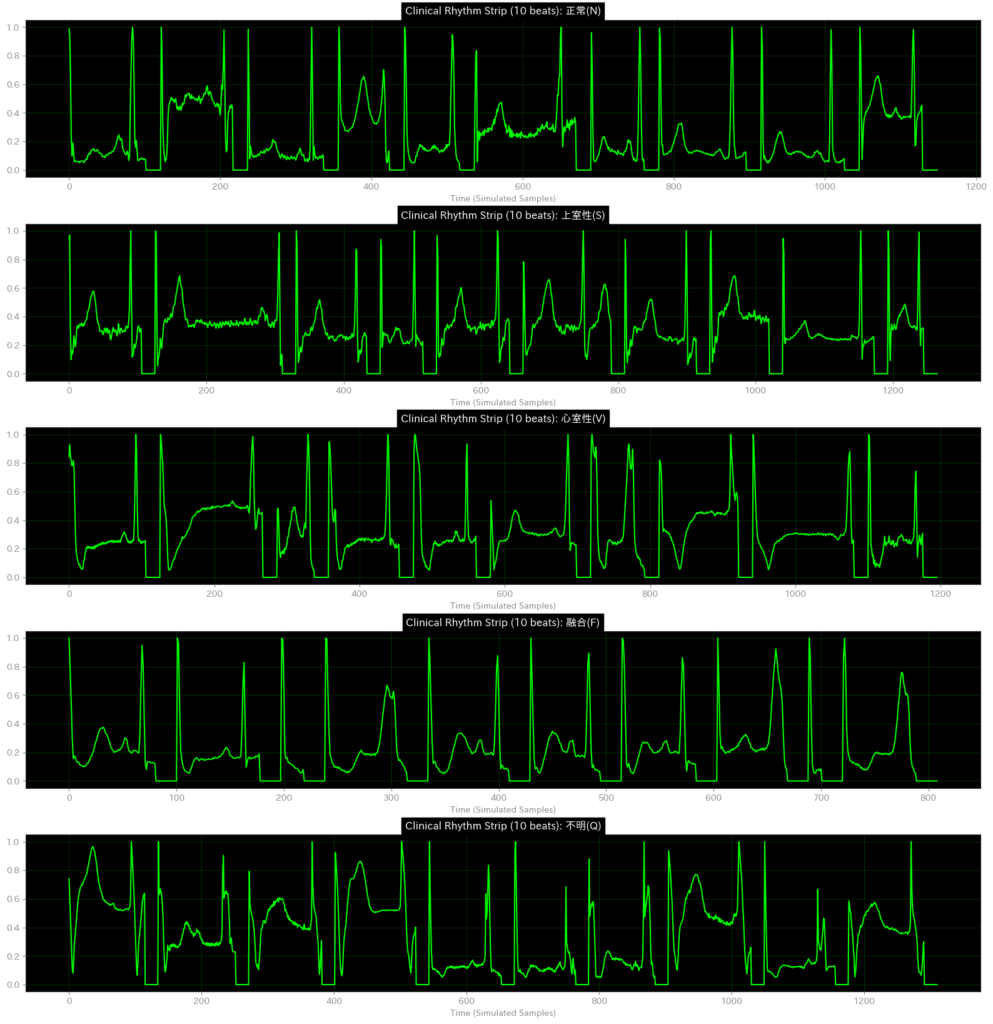
結果の見方:AIが見ている「歪んだ世界」
出力された「擬似リズムストリップ(黒いグラフ)」を見て、「あれ? 正常波形なのに形がおかしいぞ? P波が見えないものがある?」と気づかれた方は、素晴らしい観察眼をお持ちです。
実は、これが「医療AI開発の落とし穴」であり、重要な学びのポイントです。
- なぜ変な形なのか?:
今回使用したデータセットは、AIが計算しやすいように、心拍を1つずつバラバラに切り刻み、高さ(電圧)を0〜1に無理やり引き伸ばす加工(正規化)がされています。その過程で、P波の一部が切り落とされたり、ノイズが強調されたりしています。 - つなぎ目の違和感:
このグラフは、バラバラの断片をプログラムで人工的につなぎ合わせた「合成写真」のようなものです。そのため、拍と拍のつなぎ目が不自然な形になっています。
しかし、驚くべきは「AIは、こんなに不完全で歪んだデータからでも、90%以上の精度で致死的な不整脈(V)を見抜いている」という事実です。AIは、人間のように「綺麗なP-QRS-T」を見ているのではなく、数値の羅列の中に潜む「異常なパターン(特徴量)」を数学的に捉えているのです。
解説:なぜAIは波形から病気を見抜けるのか?
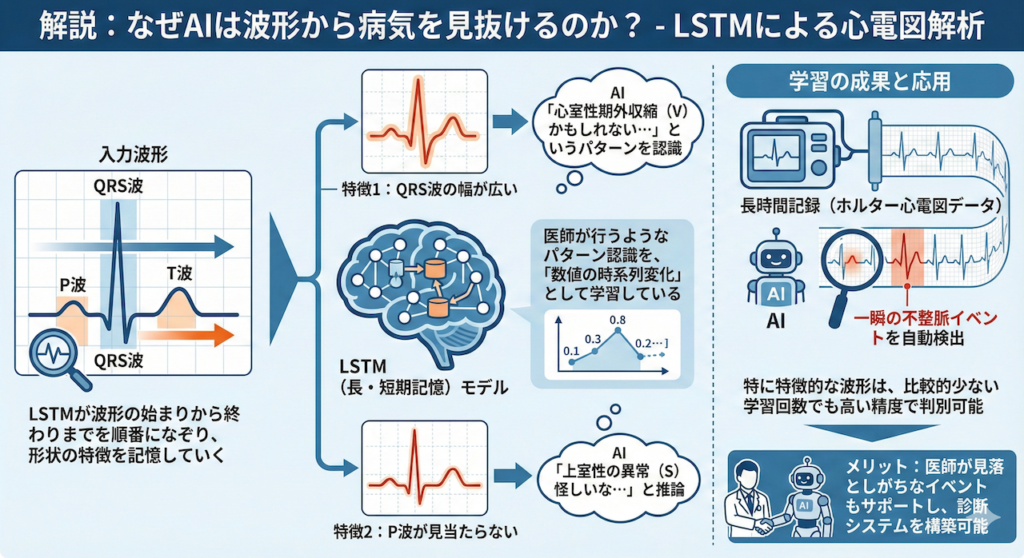
このモデルでは、LSTMが波形の「始まり(P波)」から「終わり(T波)」までを順番になぞりながら、形状の特徴を記憶していきます。
- QRS波の幅が広い → 「心室性期外収縮(V)かもしれない…」
- P波が見当たらない → 「上室性の異常(S)怪しいな…」
といった医師が行うようなパターン認識を、LSTMは「数値の時系列変化」として学習しているのです。
特に「心室性期外収縮(V)」などの特徴的な波形は、比較的少ない学習回数でも高い精度で判別できることが確認できたはずです。
このように、LSTMを用いれば、長時間記録されたホルター心電図データから、医師が見落としがちな一瞬の不整脈イベントを自動検出するシステムなどを構築することが可能になります。
まとめ:過去を知り、未来を予測するAI
今回の講義では、医療データを「一瞬の点」ではなく「時間の流れ(線)」として捉えることの重要性と、それを解析するAI技術について学びました。ポイントを振り返りましょう。
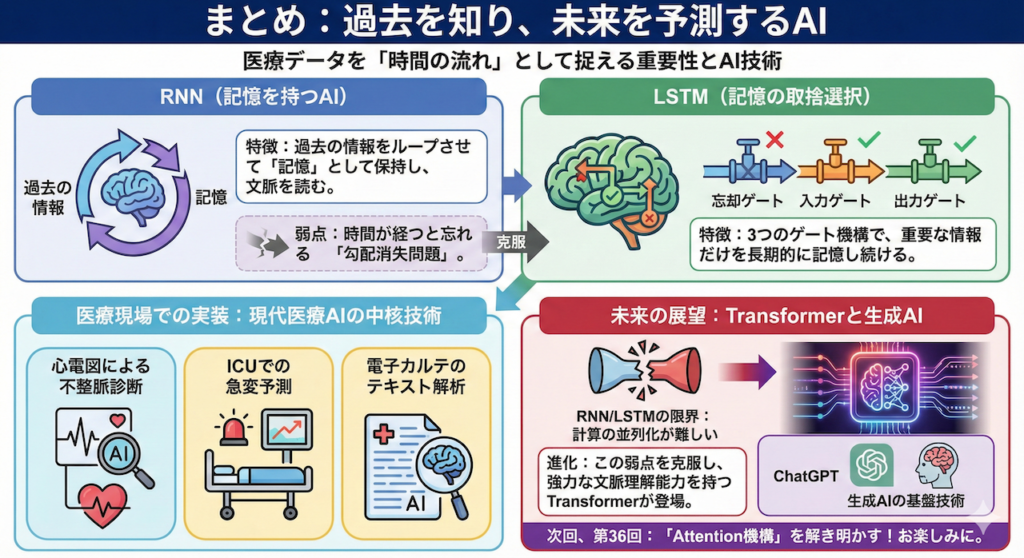
- RNN(記憶を持つAI):
過去の情報をループさせて「記憶」として保持し、文脈を読むことができます。しかし、時間が経つと昔のことを忘れてしまう「勾配消失問題」という弱点がありました。 - LSTM(記憶の取捨選択):
「忘却・入力・出力」という3つのゲート機構を備えることで、重要な情報だけを長期的に記憶し続けることを可能にしました。 - 医療現場での実装:
これらの技術は、心電図による不整脈診断、ICUでの急変予測、電子カルテのテキスト解析など、現代の医療AIの中核技術として稼働しています。
しかし、AIの進化はここで止まりません。RNNやLSTMには、「前のデータを処理しないと次の処理に進めない(計算の並列化が難しい)」という速度的な限界がありました。
現在では、この弱点を克服し、さらに強力な文脈理解能力を持つTransformer(トランスフォーマー)が登場し、ChatGPTなどの生成AIを支える基盤技術となっています。
次回、第36回では、現代AIの王者であるこのTransformerについて、その革新的な仕組み(Attention機構)を解き明かしていきます。どうぞお楽しみに。
参考文献
- Attia, Z.I. et al. (2019). An artificial intelligence-enabled ECG algorithm for the identification of patients with atrial fibrillation during sinus rhythm: a retrospective analysis of outcome prediction. The Lancet, 394(10201), pp. 861–867.
- Bengio, Y., Simard, P. and Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), pp. 157–166.
- Cho, K. et al. (2014). Learning phrase representations using RNN encoder–decoder for statistical machine translation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1724–1734.
- Esteva, A. et al. (2019). A guide to deep learning in healthcare. Nature Medicine, 25(1), pp. 24–29.
- Goodfellow, I., Bengio, Y. and Courville, A. (2016). Deep Learning. Cambridge, MA: MIT Press.
- Hannun, A.Y. et al. (2019). Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nature Medicine, 25, pp. 65–69.
- Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), pp. 1735–1780.
- Komorowski, M. et al. (2018). The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care. Nature Medicine, 24, pp. 1716–1720.
- Lipton, Z.C., Kale, D.C., Elkan, C. and Wetzel, R. (2015). Learning to diagnose with LSTM recurrent neural networks. Proceedings of the International Conference on Learning Representations (ICLR).
- Moody, G.B. and Mark, R.G. (2001). The impact of the MIT-BIH Arrhythmia Database. IEEE Engineering in Medicine and Biology Magazine, 20(3), pp. 45–50.
- Nemati, S. et al. (2018). An interpretable machine learning model for accurate prediction of sepsis in the ICU. Critical Care Medicine, 46(4), pp. 547–553.
- Pascanu, R., Mikolov, T. and Bengio, Y. (2013). On the difficulty of training recurrent neural networks. Proceedings of the International Conference on Machine Learning (ICML), pp. 1310–1318.
- Rajkomar, A. et al. (2018). Scalable and accurate deep learning with electronic health records. NPJ Digital Medicine, 1, 18.
- Rumelhart, D.E., Hinton, G.E. and Williams, R.J. (1986). Learning representations by back-propagating errors. Nature, 323, pp. 533–536.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




