

「Garbage In, Danger Out」を防ぐため、欠損メカニズム(MCAR/MAR/MNAR)の分類に基づいた適切な代入法(MICE)と、医学的妥当性を考慮した外れ値処理の手法を習得します。
欠損が「完全にランダム」か、「他の変数で説明可能」か、それとも「隠れた重症度など」に依存するかを分類します。これにより、削除して良いか、高度な代入が必要かを判断します。
単純な平均値代入は分散を過小評価します。MICEは予測値に乱数(ノイズ)を加えて複数回代入を行うことで、データの持つ本来の不確実性と相関関係を維持します。
極端な値が「入力ミス(ノイズ)」なのか、「致死的な重症例(シグナル)」なのかを見極めます。統計的な検知と医学的判断を組み合わせるハイブリッド手法が不可欠です。
1. はじめに:なぜ「前処理」がAIの診断能力を左右するのか
医療AI開発のプロジェクトにおいて、私たちはしばしば、華やかな「モデル構築」よりも、地味で泥臭い「データ前処理」に開発期間の大半を費やします。なぜ、そこまで徹底してデータを磨き上げる必要があるのでしょうか?それは、前処理の質こそが、最終的なAIモデルの臨床的妥当性(Clinical Validity)を決定づけるからです。
私たちが扱う電子カルテ(EHR)やレセプトデータなどのリアルワールドデータ(RWD)は、本来「目の前の患者さんを診療するため」、あるいは「保険請求を行うため」に記録されたものであり、AIに学習させるための「研究用データ」として整えられたものではありません。そのため、そこには必然的に、欠損、入力ミス、単位の不統一、あるいは施設ごとの入力ルールの違いといった「汚れ」が含まれています (Ghassemi et al. 2020)。
「ゴミ」が招くのは、エラーではなく「危険」
データサイエンスの世界には、昔から「Garbage In, Garbage Out(ゴミを入れればゴミが出てくる)」という有名な格言があります。質の悪いデータを学習させれば、質の悪いAIができる、という意味です。しかし、人の命を預かる医療の現場においては、この言葉を次のように言い換えるべきでしょう。
「Garbage In, Danger Out(ゴミを入れれば危険が出てくる)」
もし前処理が不十分であれば、その後どれほど最新鋭の深層学習アルゴリズムを用いたとしても、AIは偏ったデータから偏った「真実」を学習してしまいます。最悪の場合、特定の患者集団(例えば、特定の年齢層や重症度の患者)に対してのみ診断精度が著しく低下するようなバイアスを生み出し、臨床現場に混乱や不利益をもたらすリスクすらあります (Chen et al. 2021)。
2. 欠損データのメカニズム:医学的な「理由」を分類する
データが欠損しているとき、そこには必ず理由があります。あるいは、「データの空白そのものが、一つの情報である」と言ってもよいでしょう。
統計学の権威であるLittleとRubinは、欠損が生じるメカニズムを以下の3つに分類しました (Little and Rubin 2019)。この分類を見極めることこそが、誤ったバイアスを避け、適切な対処法(代入法など)を選択するための最初の一歩となります。
まずは、この3つの違いを整理した概念図を見てみましょう。
2.1. MCAR (Missing Completely At Random:完全にランダムな欠損)
これは、データが欠損するかどうかが、観測データにも、欠損している真の値にも全く依存しない状態です。数式で表現すると、欠損変数 \( R \)(欠損なら1、観測なら0)の確率は定数となります。
\[ P(R | Y_{obs}, Y_{mis}) = P(R) \]
- 医療の例:検体の入った試験管が、検査室での事故でたまたま破損し、検査値が得られなかった場合。
- 対処と解釈:この場合、欠損データは「単に運悪く消えた」だけなので、残ったデータは母集団の偏りのない縮図です。したがって、リストワイズ削除(欠損を含む行を削除)を行っても、推定結果にバイアス(偏り)は生じません。しかし、単純にデータ数が減るため、統計的な検出力(Power)が低下するというデメリットがあります。
※注意:現実のリアルワールドデータ(RWD)において、純粋なMCARが成立することは極めて稀です。
2.2. MAR (Missing At Random:ランダムな欠損)
ここが最も誤解されやすく、かつ重要な概念です。「ランダム」という名前ですが、決して「でたらめ」という意味ではありません。これは、「観測されている他のデータ(\( Y_{obs} \))があれば、欠損の発生を説明できる」状態を指します。
\[ P(R | Y_{obs}, Y_{mis}) = P(R | Y_{obs}) \]
- 医療の例:例えば、「若年の健康な患者(年齢=観測データ)では、定期的なHbA1c測定(欠損データ)が行われない傾向がある」というケースを想像してください。
全体を見れば、HbA1cの欠損は健康な若者に多いため、単純に平均値を取ると「病気の高齢者」のデータばかりが残り、実際の平均より数値が悪く見えてしまいます。しかし、「同じ年齢層(例:20代)の中だけで見れば、検査の有無はランダムである」と仮定できる場合、これをMARと呼びます。 - 対処:MARの条件下では、観測データ(年齢など)を使って欠損値(HbA1c)を予測することが可能です。このため、後述する多重代入法(MICE)などの統計的補完手法が最も有効に機能し、バイアスのない推定が可能になります。
2.3. MNAR (Missing Not At Random:ランダムでない欠損)
最も厄介なのがこのMNARです。欠損の発生が、「欠損している値そのもの(=未知の真値 \( Y_{mis} \)」に関連している状態です。「見えないからこそ、そこに意味がある」ケースです。
\[ P(R | Y_{obs}, Y_{mis}) \text{ は } Y_{mis} \text{ に依存する} \]
- 医療の例:
- うつ病の質問票:重度のうつ状態にある患者(真のスコアが高い)ほど、気力が低下して回答を拒否する(欠損になる)傾向がある場合。
- 臨床検査:医師が患者の様子を見て「重症かもしれない」と感じた(がカルテには明記されていない)場合にのみ、特定の腫瘍マーカーをオーダーする場合。
- 対処:この場合、欠損値を補完しようにも、手がかりとなる情報はデータセットの外(真の値そのもの)にあります。通常の代入法を用いるとバイアスが生じてしまうため、欠損のメカニズム自体をモデル化する高度な手法や、ドメイン知識に基づいた慎重な取り扱いが必要です (Sterne et al. 2009)。
実務上のポイント:感度分析(Sensitivity Analysis)の重要性
多くの臨床研究やAI開発の現場では、「とりあえずMARを仮定して多重代入を行う」という運用になりがちです。しかし、実際の欠損にはMARとMNARが混在していることも少なくありません。
そのため、メインの解析ではMARを仮定しつつ、「もし、重症例ほど検査が行われない(MNAR)という最悪のシナリオだった場合、結果はどの程度変わるか?」といった感度分析を組み合わせて報告することが、科学的な誠実さ(Scientific Integrity)として推奨されます (Sterne et al. 2009)。
2.4. RWDにおける公平性とバイアス
最後に、欠損データの問題を「AIの公平性」という視点でも捉えておきましょう。
とりわけRWDでは、社会経済的背景、居住地域、あるいは人種や性別によって、「そもそも誰のデータが詳しく記録され、誰のデータが欠損しやすいか」という構造的な偏りが存在します。例えば、高額な検査は経済的に余裕のある患者に偏るかもしれません。
これを考慮せずに機械的に処理してしまうと、AIは「データの多い(恵まれた)集団」に対しては高精度でも、「データの少ない(脆弱な)集団」に対しては精度が低いモデルになってしまう恐れがあります。前処理の段階から、こうした構造的バイアスの存在を意識することが重要です (Chen et al. 2021)。
3. 代入法の選択:単純代入の危険性と多重代入(MICE)
欠損データへの対処として、最も安易な方法は「欠損行を削除する(リストワイズ削除)」ことですが、これは貴重なデータを捨てることになり、バイアスの原因となります。そこで、欠損箇所を何らかの推定値で埋める「代入法(Imputation)」が選択されます。
代入法には、大きく分けて平均値などで一度だけ埋める「単純代入法」と、統計モデルを用いて複数回埋める「多重代入法(MICE)」があります。結論から言えば、医療データ解析において、現在最も広く推奨されている標準的なアプローチは後者です。
3.1. 単純代入法(Simple Imputation)の罪
「平均値代入(Mean Imputation)」は、欠損している部分に、その変数の平均値を一律に埋める手法です。計算は非常に簡単ですが、医学統計においては「やってはいけない禁じ手」に近い扱いを受けることがあります。なぜでしょうか?
それは、データが本来持っている「ばらつき(分散)」と「関係性(相関)」を破壊してしまうからです。
1. 分散の過小評価(Variance Underestimation)
全員を「平均的な患者」として扱うため、データのばらつきが実際よりも小さくなります。数式でイメージしてみましょう。真の分散を \( \sigma^2 \) とすると、平均値を埋めた後の分散 \( \hat{\sigma}^2 \) は以下のようになります。
\[ \hat{\sigma}^2 < \sigma^2 \]
分散が小さくなると、標準誤差(SE)も不当に小さくなります。その結果、信頼区間が狭くなりすぎ、本来は差がないはずの比較で「有意差あり」と誤判定してしまう第1種の過誤(偽陽性)のリスクが劇的に高まります (Sterne et al. 2009)。
2. 相関関係の破壊
生体データには、「年齢が上がれば腎機能(eGFR)が下がる」といった相関関係があります。しかし、年齢に関わらず一律にeGFRの平均値を埋めてしまうと、この医学的な関係性がデータから消滅してしまいます。これでは、多変量解析を行っても正しい係数を得ることはできません。
3.2. 多重代入法(Multiple Imputation by Chained Equations: MICE)
そこで登場するのが、MICE(マイス)と呼ばれる多重代入法です。これは、欠損値を「ただ埋める」のではなく、「予測された値にゆらぎ(不確実性)を持たせて、何通りものパターンで埋める」というアプローチです (Van Buuren 2018)。
MICEのアルゴリズムは、以下の3つのステップで進行します。
なぜ「乱数」を加えるのか?
MICEの肝は、予測値にあえてノイズ(乱数)を加える点にあります。例えば、年齢とBMIからHbA1cを予測する場合、回帰直線上ピッタリの値で埋めてしまうと、それは「予測が100%正しい」と過信していることになります。
実際には、予測しきれない個人差(誤差)があるはずです。MICEでは、この誤差項に相当する乱数を加えることで、「この値はあくまで推定であり、不確実なものである」という事実をデータの分散として保持します。これにより、単純代入法で問題となった「分散の過小評価」を防ぎ、統計的に妥当なP値や信頼区間を得ることができるのです。
ただし、多重代入法は万能魔法ではありません。この手法が統計的に正当化されるのは、欠損メカニズムがMAR(Missing At Random)であると仮定できる場合に限られる点に留意が必要です。
4. 外れ値(Outlier)検知:エラーか、重症か?
リアルワールドデータ(RWD)の分布を見ると、しばしば私たちの常識を逸脱した「極端な値」に遭遇します。しかし、データサイエンスの教科書通りに「外れ値=ノイズ」と決めつけて、これらを機械的に削除してはいけません。
医療データにおける外れ値には、全く異なる2つの性質があるからです。
- データエラー(削除・修正すべき):
生物学的にあり得ない値です。例えば「身長 300cm」「収縮期血圧 3000mmHg」といった入力ミスや、単位の間違い(gとmgの取り違え)などが該当します。これらはノイズであり、モデルの学習を妨げるため、削除や修正が必要です。 - 医学的異常値(削除してはいけない):
生物学的には稀ですが、実際に起こりうる重篤な状態です。例えば、CK(クレアチンキナーゼ)という酵素の値が、基準値(数百程度)を遥かに超えて数万単位に上昇している場合、それは入力ミスではなく「横紋筋融解症」という致死的な病態を示している可能性があります。
もし、統計的な基準だけでこれを「外れ値」として削除してしまえば、私たちは「最も重症な患者」のデータを自ら捨て去ることになります。その結果、軽症例には強いが、本当に救うべき重症例を予測できないAIが生まれてしまうのです (Aggarwal 2017)。
4.1. アルゴリズムと専門家の協働
では、どのようにしてエラーと重症例を見分ければよいのでしょうか? ここで必要になるのが、統計的手法とドメイン知識(医学的知見)のハイブリッド・アプローチです。
ステップ1:統計的手法による「候補」のリストアップ
まず、Isolation Forestや、四分位範囲(IQR)を用いた手法で、外れ値の「候補」を機械的に抽出します。例えばIQR法では、以下の数式に基づいて正常範囲を定義します。
\[ \begin{aligned} \text{Lower Limit} &= Q1 – 1.5 \times \text{IQR} \\ \text{Upper Limit} &= Q3 + 1.5 \times \text{IQR} \end{aligned} \]
ここで、\( Q1 \) は第1四分位数、\( Q3 \) は第3四分位数、\( \text{IQR} = Q3 – Q1 \) です。この範囲を逸脱したデータを「外れ値候補」としてフラグ付けします。
ステップ2:専門家による医学的判断
ここからが重要です。アルゴリズムが抽出したレコードについて、医師やデータマネージャーが介入し、カルテや検査レポートの原データを確認する二段階プロセスを行います。
- 「この患者は外傷で搬送されているから、CK 50,000 は妥当だ(重症例として残す)」
- 「この血圧値は、バイタルサインの他の項目(脈拍など)と矛盾しているから、入力ミスだろう(欠損にするか修正する)」
外れ値検知アルゴリズムは、あくまで「人間がチェックすべきデータ」を教えてくれるアラート機能に過ぎません。最終的な審判を下すのは、常に医学的な文脈を理解する専門家であるべきです (Aggarwal 2017)。
5. Pythonによる実装:MICEと外れ値検知
理論を学んだところで、実際にPythonを使って手を動かしてみましょう。ここでは、あえて「正解(真の値)」がわかっている架空の医療データを作成し、それを意図的に汚(欠損・外れ値化)してから修復することで、MICEやIsolation Forestがどのように機能するかを目の当たりにします。
5.1. 実行環境の準備
以下のコードは、Python環境(Jupyter NotebookやGoogle Colabなど)でそのまま実行可能です。グラフの日本語表示のために japanize-matplotlib ライブラリを使用します。
# ターミナルまたはコマンドプロンプトで以下を実行してください
pip install pandas numpy matplotlib seaborn scikit-learn japanize-matplotlib
5.2. サンプルコード:データ生成から補完、可視化まで
このスクリプトは、以下のストーリーをシミュレーションします。
- 真の世界:糖尿病リスクに関連するデータ(年齢、BMI、HbA1c、血圧)が存在する。
- 現実の壁:健康そうな人ほど検査を受けない(MAR欠損)、入力ミスが発生する(外れ値)。
- データ救出:Isolation Forestでミスを見つけ、MICEで欠損を科学的に埋める。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib # 日本語表示用
from sklearn.experimental import enable_iterative_imputer # MICE用
from sklearn.impute import IterativeImputer
from sklearn.ensemble import IsolationForest
# 再現性のためのシード固定
np.random.seed(42)
# ==========================================
# 1. 疑似医療データの生成 (RWDを模倣)
# ==========================================
# ※注意: これは乱数による架空データであり、実在の患者情報ではありません。
n_samples = 1000
data = pd.DataFrame({
'Age': np.random.normal(60, 10, n_samples).astype(int), # 年齢
'BMI': np.random.normal(25, 4, n_samples), # BMI
'SBP': np.random.normal(130, 15, n_samples) # 収縮期血圧
})
# HbA1cは他の変数と相関を持たせて生成 (相関構造を作る)
# 「年齢が高いほど、BMIが高いほどHbA1cが高くなる」という医学的相関を埋め込む
data['HbA1c'] = (
0.02 * data['Age'] +
0.1 * data['BMI'] +
np.random.normal(3, 0.5, n_samples)
)
# データをコピーして欠損生成用にする(ここからデータを汚していきます)
data_missing = data.copy()
# ==========================================
# 2. 欠損の導入 (MARメカニズムのシミュレーション)
# ==========================================
# シナリオ: 「BMIが低い(健康そうな)人はHbA1c検査を受けないことが多い」
# これは観測値(BMI)依存の欠損なので MAR (Missing At Random) とみなせます
# BMI < 22 の人のうち、約60%のHbA1cデータを削除
mask_mar = (data_missing['BMI'] < 22) & (np.random.rand(n_samples) < 0.6)
data_missing.loc[mask_mar, 'HbA1c'] = np.nan
print(f"生成された欠損数: {data_missing['HbA1c'].isnull().sum()} / {n_samples}")
# ==========================================
# 3. 外れ値の混入 (データ入力ミスの模倣)
# ==========================================
# 誤ってBMI 250 (おそらく25.0の入力ミス) を1件だけ混入させます
data_missing.loc[0, 'BMI'] = 250.0
# ==========================================
# 4. 外れ値の検知と処理
# ==========================================
# Isolation Forestによる外れ値検知(候補の抽出)
# contamination=0.01 は「データ全体の1%程度が外れ値だろう」という仮定
clf = IsolationForest(contamination=0.01, random_state=42)
data_missing['Outlier_Score'] = clf.fit_predict(data_missing[['Age', 'BMI', 'SBP']])
# 外れ値 (スコア -1) を特定
outliers = data_missing[data_missing['Outlier_Score'] == -1]
print("\n【検知された外れ値候補】")
print(outliers[['Age', 'BMI', 'SBP', 'HbA1c']].head())
# 医学的妥当性チェック:
# 実務ではここでカルテ確認を行いますが、今回はBMI > 100 を明らかな入力エラーとみなしてNaNに置換します
data_missing.loc[data_missing['BMI'] > 100, 'BMI'] = np.nan
# 作業用カラム削除
data_missing.drop('Outlier_Score', axis=1, inplace=True)
# ==========================================
# 5. 多重代入法 (MICE) の実行
# ==========================================
# IterativeImputerを使用 (デフォルトはBayesianRidge回帰による予測)
# sample_posterior=True が重要!予測値に「ゆらぎ」を加え、本来の分散を復元します
mice_imputer = IterativeImputer(max_iter=10, random_state=42, sample_posterior=True)
data_mice = pd.DataFrame(mice_imputer.fit_transform(data_missing), columns=data_missing.columns)
# ==========================================
# 6. 結果の可視化と評価
# ==========================================
plt.figure(figsize=(12, 6))
# オリジナル(真値)の分布
sns.kdeplot(data['HbA1c'], label='オリジナル (真値)', color='green', linestyle='--', linewidth=2)
# 欠損ありデータの分布 (欠損除去 / リストワイズ削除)
sns.kdeplot(data_missing['HbA1c'].dropna(), label='欠損あり (削除法)', color='red', linestyle=':')
# MICE補完後の分布
sns.kdeplot(data_mice['HbA1c'], label='MICE補完後', color='blue', linewidth=2)
plt.title('HbA1c分布の比較: MICEによるバイアス補正効果')
plt.xlabel('HbA1c (%)')
plt.ylabel('密度')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()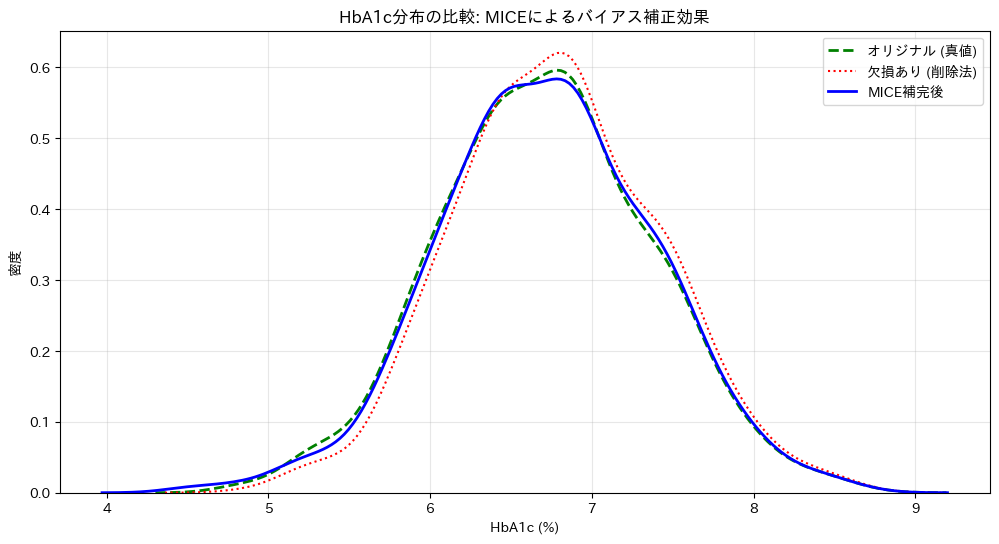
コード解説:何が起きているのか?
- データの相関構造の埋め込み
コード前半でdata['HbA1c'] = ...としている部分にご注目ください。ここで「年齢やBMIが高いほど、HbA1cも高くなる」という医学的な相関関係を数式としてデータに埋め込んでいます。これがMICE成功の鍵となります。 - MAR(バイアス)の再現
「BMIが低い(健康な)人は検査を受けない」というシナリオで欠損を作りました。これにより、残ったデータは「BMIが高い(不健康な)人」に偏ります。 - グラフの読み方(結果の解釈)
出力されるグラフを見てみましょう。- 赤の点線(削除法):分布が全体的に右(高値)へズレています。これは、健康な人のデータが消え、不健康な人のデータばかりが残ったため、平均値が高く歪んでしまったことを示しています(バイアス)。
- 青の実線(MICE補完後):赤の点線から修正され、緑の破線(オリジナル真値)にピタリと重なっているのがわかります。
これが統計学の力です。MICEは、残された「年齢」や「BMI」の情報から「この患者は若くて痩せているから、きっとHbA1cも低いはずだ」と推測し、失われた情報を科学的に復元したのです。
6. 結論:データへの敬意
長きにわたる前処理の解説も、ようやく終わりです。最後に、私が最も大切にしている考え方をお伝えして、この章を締めくくりたいと思います。
それは、「前処理とは、不都合なデータを消し去ることではなく、得られたデータから最大限の情報を科学的に救い出すプロセスである」ということです。
リアルワールドデータ(RWD)の背後には、必ず一人の患者さんの人生があり、医療現場の苦闘があります。欠損値一つをとっても、そこには「なぜ検査ができなかったのか」「なぜ入力されなかったのか」という物語(メカニズム)が存在します。 MCAR/MAR/MNARというメカニズムを深く考察し、安易な単純代入ではなくMICEのような多変量アプローチを採用すること。それは、データに対する統計学的なアプローチであると同時に、データを提供してくれた患者さんへの誠実な態度(Integrity)でもあります。
こうして「汚れ」を「情報」へと昇華させることで初めて、私たちは偏りのない、臨床的に信頼できるAIモデルの構築に挑戦する資格を得るのです。
次回の講義では、いよいよこれらの前処理を経た「きれいなデータ」を用いて、実際に病気を予測するモデルを選択し、構築するプロセス(決定木から、現代最強のアルゴリズムGBDTまで)へと進みます。どうぞお楽しみに。
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
参考文献
- Aggarwal, C.C. (2017). Outlier Analysis. 2nd edn. Springer Cham.
- Chen, I.Y., Pierson, E., Rose, S., Joshi, S., Ferryman, K. & Ghassemi, M. (2021). Ethical Machine Learning in Healthcare. Annual Review of Biomedical Data Science, 4, pp.81–105.
- Ghassemi, M., Naumann, T., Schulam, P., Beam, A.L., Chen, I.Y. & Ranganath, R. (2020). A review of challenges and opportunities in machine learning for health. AMIA Joint Summits on Translational Science proceedings, 2020, pp.191–200.
- Little, R.J.A. & Rubin, D.B. (2019). Statistical Analysis with Missing Data. 3rd edn. Wiley Series in Probability and Statistics.
- Sterne, J.A.C., White, I.R., Carlin, J.B., Spratt, M., Royston, P., Kenward, M.G. et al. (2009). Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls. BMJ, 338, b2393.
- Van Buuren, S. (2018). Flexible Imputation of Missing Data. 2nd edn. Chapman and Hall/CRC.
- 経済産業省. (2023). AI原則実践のためのガバナンス・ガイドライン ver. 1.1.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




