

Jupyterは「実験ノート」として優秀ですが、再現性に課題があります。VS Codeは「コードの手術室」として、インテリジェンス機能、厳格なフォルダ分け(ゾーニング)、デバッグ機能により、Jupyterで見つけたアイデアを「再現可能な本番コード(資産)」に昇格させます。
単なるエディタではなく、コード補完やエラーチェックで「医療過誤(バグ)」を未然に防ぐ高機能な開発環境(IDE)です。
「実験用 (notebooks/)」と「本番用 (src/)」を明確に分離。この「清潔野」の区別が、再現性の鍵です。
Jupyterで試したロジックを、VS Codeで「再利用可能な関数(部品)」として src/ フォルダに清書。これがプロのワークフローです。
C30.2では、Jupyter Notebookという素晴らしい「デジタルの実験ノート」を学びました。データを対話的に探索し、コードと考察を一つの文書に残すEDA(探索的データ解析)の強力な相棒でしたね。
しかし、Jupyter Notebookを「手書きの実験ノート」だとすると、一つの重大な問題が残ります。それは、「そのノート、他の人が読んでも100%同じ実験を再現できますか?」という問題です。
実行順序に依存したり、途中で変数名を変更したことを忘れていたり…。Jupyter Notebookは「試行錯誤」には最適ですが、その自由さゆえに「属人的」になりやすく、厳密な「再現性」を担保するのが難しいのです。
もし、あなたがJupyterで見つけたロジック(例えば、敗血症の早期予測モデル)を、病院の電子カルテシステムに組み込む「本番環境」で使おうとしたらどうでしょう?
「その日、その人のPCでだけ動く」ような実験コードは、医療現場では絶対に受け入れられません。必要なのは、いつ、誰が、どのサーバーで実行しても、寸分違わず同じ結果を出す、堅牢で再現可能な「本番用の手順書(コード)」です。プログラミングの世界では、これをSOP(Standard Operating Procedures)と呼ぶことがありますが、要するに「信頼できる、何度でも使える部品」のことです。
この回で学ぶ Visual Studio Code (VS Code) は、その「本番用の手順書」を作成し、管理するための、いわば「コードの手術室」です。Jupyterという「作業台」で見つけた素晴らしいアイデアを、「本番の臨床現場」で安全に使えるレベルに昇格させるための、プロフェッショナルな開発環境なのです。
VS Codeとは?:「コードの手術室」と呼べる理由
VS Codeは、Microsoftが開発・提供する、世界で最も人気のある「コードエディタ」の一つです (Stack Overflow, 2023)。
「コードエディタ」と聞くと、Windowsの「メモ帳」やMacの「テキストエディット」のような、単なる文字入力ソフトを想像するかもしれません。しかし、VS Codeはそれらとは全く異なります。これは「統合開発環境(IDE)」と呼ばれる、非常にインテリジェントなツールです。
この違いを、医療現場のアナロジーで考えてみましょう。
- メモ帳 / テキストエディット:
- 例えるなら: 「まっさらな手書きカルテ用紙」。
- 機能: 文字を書くことしかできません。薬剤名を間違えても、あり得ない用法用量を書いても、何も警告してくれません。
- Jupyter Notebook (C30.2):
- 例えるなら: 「優秀な研究者の個人ノート」。
- 機能: 実行と記録はできますが、管理は本人次第。他の人がそのノートを正確に解読できるかは保証されません。
- VS Code:
- 例えるなら: 「オーダリングシステムと連携した高機能電子カルテ」。
- 機能: ただの記録(コード記述)だけでなく、以下のような強力な支援機能(インテリジェンス)が満載です。
VS Codeのインテリジェンス(支援機能)
- シンタックスハイライト: コードの種類(関数、変数、文字列など)を色分けし、構造を読みやすくします。
- コード補完(IntelliSense): あなたが使おうとしている関数や変数を予測し、候補を表示します。「この薬剤(関数)には、この引数(用法用量)が必要ですよ」と教えてくれるイメージです。
- リアルタイム・エラーチェック(Linting): コードを書きながら、文法的な間違いや「推奨されない書き方(危険な用法)」をリアルタイムで下線で警告してくれます (Linters, 2024)。
- デバッグ機能: これが最強の機能です。コードの実行を一時停止し、内部の状態を詳細に観察できます。後ほど詳しく解説します。
Jupyterが「自由に仮説を試す診察室」だとしたら、VS Codeは「エラー(医療過誤)を未然に防ぎ、標準化された手順(本番コード)を確実に実行するための、アシスタント付きの手術室」なのです。
セットアップと「必須装備(拡張機能)」
VS Codeは無料で、Windows, macOS, Linuxのすべてで動作します。まずは公式サイト(https://code.visualstudio.com/)からダウンロードし、インストールしてください。
インストールした直後のVS Codeは、まだ「空の手術室」のようなものです。ここに、Python開発に必要な「専門機器」を持ち込む必要があります。それが拡張機能(Extensions)です。
VS Codeの左側にあるテトリスのようなアイコンをクリックし、以下の2つの拡張機能は必ずインストールしてください。
- Python (Microsoft):
- 役割: Python言語の「通訳・アシスタント」。
- 機能: これを入れることで、先ほど説明したコード補完、エラーチェック(Linting)、デバッグ機能など、Python開発に必要なほぼ全ての支援機能が有効になります。
- Jupyter (Microsoft):
- 役割: 「手術室から実験ノートを覗く窓」。
- 機能: なんと、VS Codeの中でJupyter Notebook(
.ipynbファイル)を直接開いて編集、実行できるようになります。これにより、「Jupyterで試行錯誤し、固まったロジックをVS Codeの.pyファイルに清書する」という作業が、一つのソフト内でシームレスに行えます。
本番プロジェクトの「ゾーニング(区画分け)」
VS Codeを使った本番開発では、Jupyterのように「とりあえずファイルを作る」ことはしません。最初に「プロジェクト」という単位で全体の「設計図(フォルダ構成)」を決めます。
これは、医療現場で「清潔野」と「不潔野」を厳密に分ける「ゾーニング」の思想と全く同じです。「どこに何があるか」を明確にし、意図しない汚染(コードの衝突やデータの破壊)を防ぎ、医療安全(開発の安全性)を確保するためです。
Jupyterでありがちな「ノートブックも、CSVデータも、書き出した画像も、全部同じフォルダにぐちゃぐちゃ」という状態は、最も避けなければならない「不潔」な状態です。
プロの現場では、以下のような「清潔」な区画分けが標準的です。
このゾーニングの核心は、notebooks/(実験)と src/(本番コード)を完全に分離することです。
JupyterからVS Codeへの「リファクタリング(清書)」実践
では、いよいよ実践です。C30.2の「実験ノート(Jupyter)」で試行錯誤した「架空の患者データを作成し、グラフを描画する」という一連のプロセスを、今度は「本番用の手順書」として「手術室(VS Code)」に清書(リファクタリング)してみましょう (Fowler, 2018)。
この「清書」こそが、Jupyterのアイデアを「再現可能な資産」に変える、最も重要なステップです。
【実行前の環境確認】
この記事のコードは、C30.2で構築した私たちの「清潔な器具庫」である clinical-ai というConda環境 が存在することを前提としています。作業を始める前に、必ずターミナル(WindowsならAnaconda Prompt、Mac/Linuxならターミナル)を開き、以下のコマンドで環境を有効化(アクティベート)してください。
# ターミナルでこのコマンドを実行し、
# プロンプト(行頭)が (base) から (clinical-ai) に変わることを確認します
conda activate clinical-aiまた、この環境に必要な「器具(ライブラリ)」が揃っているか確認します。C30.2のセットアップで pandas, matplotlib, japanize-matplotlib はインストール済みのはずですが、数値計算の基礎となる numpy が必要になるため、以下のコマンドで追加インストールしておくと万全です。(すでにあれば “Requirement already satisfied” と表示されます)
# (clinical-ai) 環境が有効な状態で実行します
pip install numpy【プロジェクトフォルダの準備】
次に、VS Codeの操作に移ります。ここで、Jupyterとは異なる「プロジェクト」としてのファイルの作り方を学びます。
- プロジェクトフォルダを開く: VS Codeを起動します(この時点では空のウィンドウかもしれません)。
- メニューバーから「ファイル」(File)を選び、「フォルダを開く…」(Open Folder…)をクリックします。
- ファイルダイアログが表示されたら、私たちが設計したプロジェクトフォルダ(例:
my_sepsis_project)を選択して「開く」ボタンを押します。
- フォルダの作成と確認: フォルダが開くと、VS Codeの左側に「エクスプローラー」パネルが表示され、
my_sepsis_projectフォルダが示されます(最初は中身が空かもしれません)。- まず、
my_sepsis_projectフォルダ名(エクスプローラーの最上位)のあたりで右クリックし、「新しいフォルダー…」(New Folder…)を選択します。 dataと入力してEnterキーを押し、dataフォルダを作成します。- 同じ操作を繰り返して、
notebooksフォルダとsrcフォルダも作成してください。 - これで、
data/,notebooks/,src/という3つのサブフォルダがツリー状に表示されます。
- まず、
- 本番用コードファイル (
analysis.py) の作成:- 左のエクスプローラーパネルで、「本番コード・部品置き場」である
srcフォルダにマウスカーソルを合わせます。(クリックはしないでください) srcの右側に、小さなアイコンがいくつか表示されます。一番左の「新しいファイル…」(New File…)アイコン(紙にプラスマークが付いたようなアイコン)をクリックします。srcフォルダのすぐ下にテキストボックスが表示されるので、analysis.pyと入力し、Enterキーを押します。- これで、
srcフォルダ内にanalysis.pyという空のファイルが作成され、画面右側のメインエディタ領域にそのタブが開きます。ここが、私たちが再利用可能な「関数(部品)」を書き込む場所です。
- 左のエクスプローラーパネルで、「本番コード・部品置き場」である
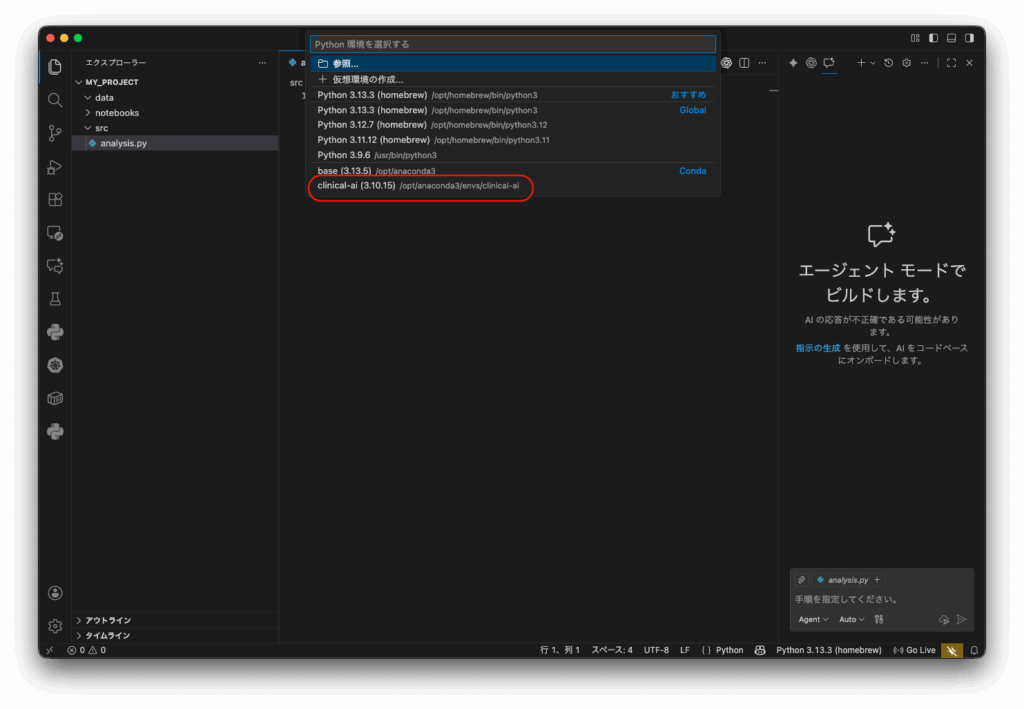
- 【最重要】Python環境の接続: 最後に、この「手術室(VS Code)」で、先ほど有効化した「清潔な器具庫(
clinical-ai環境)」を使えるように接続します。- VS Codeウィンドウの右下(または左下)にあるステータスバーを見てください。「Python 3.x.x …」のようにバージョンが表示されている部分があるはずです。
- そこをクリックします。(もし何も表示されていなければ、
analysis.pyが開いていることを確認し、Cmd+Shift+P(Mac) /Ctrl+Shift+P(Win) でコマンドパレットを開き、「Python: Select Interpreter」と入力します) - 画面上部に「Pythonインタプリタを選択」というリストが表示されます。その中から、
'clinical-ai': Condaと書かれた項目(.../envs/clinical-ai/bin/pythonのようなパスが示されているはず)を選びます。 - これで、VS Codeは
clinical-ai環境にインストールされているpandasやnumpyを正しく認識できるようになりました。コード補完(IntelliSense)やエラーチェックが、この環境を基準に動作し始めます。
これで準備は完了です。次の「作業1」で、この analysis.py にコードを書き込んでいきましょう。
作業1:再利用可能な「関数(部品)」の作成 (src/analysis.py)
Jupyterではセルにベタ書きしていたロジックを、src/analysis.py ファイルの中に、再利用可能な「関数」として清書します。「関数」とは、特定の作業(例: データ作成)を実行する、名前の付いたコードのまとまりのことです。一度作れば、他のファイルから何度でも呼び出すことができます。
# -----------------------------------------------------
# ファイル名: src/analysis.py
# 役割:再利用可能な分析関数(部品)を定義する場所
# -----------------------------------------------------
# --- 必要なライブラリのインポート ---
import numpy as np # 数値計算のためのライブラリ (as np で 'np' という名前で使う)
import pandas as pd # データ分析のためのライブラリ (as pd で 'pd' という名前で使う)
import matplotlib.pyplot as plt # グラフ描画のためのライブラリ
import japanize_matplotlib # グラフの日本語表示対応
# --- 関数1:架空データを作成する部品 ---
def create_dummy_patient_data(num_patients=100, seed=42):
"""
指定された人数と乱数シードに基づき、架空の患者データ(DataFrame)を作成する関数。
Args:
num_patients (int): 作成する患者数(デフォルトは100)。
seed (int): 乱数シード(デフォルトは42)。シードを固定することで、何度実行しても同じデータが生成される(再現性の担保)。
Returns:
pd.DataFrame: 患者データ(カラム: 年齢, 性別, HbA1c, BMI)。
"""
# 乱数シードを固定(再現性の確保)
np.random.seed(seed)
# Pythonの辞書(dict)形式でデータを定義
data = {
'年齢': np.random.randint(20, 80, num_patients), # 20歳から79歳までの整数をランダムに生成
'性別': np.random.choice(['男性', '女性'], num_patients), # '男性'または'女性'をランダムに選択
'HbA1c': np.random.normal(6.5, 1.0, num_patients).round(1), # 平均6.5, 標準偏差1.0の正規分布で生成し、小数第1位で丸める
'BMI': np.random.normal(23, 3.0, num_patients).round(1) # 平均23.0, 標準偏差3.0の正規分布で生成し、小数第1位で丸める
}
# 辞書からPandas DataFrame(表)を作成
df = pd.DataFrame(data)
# 作成したDataFrameを関数の結果として返す
return df
# --- 関数2:年齢分布グラフを作成・保存する部品 ---
def plot_age_distribution(df, save_path):
"""
患者データのDataFrameを受け取り、年齢分布のヒストグラムをPNGファイルとして保存する関数。
Args:
df (pd.DataFrame): 患者データ('年齢'カラムを含む必要がある)。
save_path (str): グラフを保存するファイルパス(例: 'age_distribution.png')。
"""
# グラフの描画領域(Figure)とサイズ(figsize)を指定
plt.figure(figsize=(8, 5))
# データフレーム(df)の'年齢'列(column)を使ってヒストグラムを作成
# bins=20: 棒の数を20本に指定, edgecolor='black': 棒の枠線を黒に
df['年齢'].hist(bins=20, edgecolor='black')
# グラフのタイトル(日本語)
plt.title('患者の年齢分布')
# X軸のラベル(日本語)
plt.xlabel('年齢')
# Y軸のラベル(日本語)
plt.ylabel('人数')
# 背景のグリッド線(マス目)を非表示に
plt.grid(False)
# 指定されたファイルパス(save_path)にグラフを画像として保存
plt.savefig(save_path)
# メモリを解放するために、描画領域を閉じる
plt.close()
# コンソール(ターミナル)に保存完了のメッセージを表示
print(f"グラフを {save_path} に保存しました。")これで、「データを作る部品」と「グラフを描く部品」が完成しました。Jupyter Notebookと違い、コードが「関数(def ...:)」という単位で整理されているのが特徴です。
作業2:分析フローを実行する「メインファイル」の作成 (run_analysis.py)
次に、先ほど作った「部品(関数)」を呼び出して、実際の分析フロー(①データを作り、②グラフを描く)を実行するための、メインのスクリプトファイルを作成します。
VS Codeのエクスプローラーで、今度はプロジェクトのルートフォルダ(my_sepsis_project/)を直接クリックし、「新しいファイル…」アイコンから run_analysis.py というファイルを作成します。
# -----------------------------------------------------
# ファイル名: run_analysis.py
# 役割:srcフォルダに定義した「部品(関数)」を呼び出し、
# 実際の分析ワークフローを実行するファイル。
# -----------------------------------------------------
# --- 必要な「部品(関数)」のインポート ---
# 「src/analysis.py」ファイルから、先ほど定義した2つの関数をインポート
# これにより、このファイル内で create_dummy_patient_data や plot_age_distribution が使えるようになる
from src.analysis import create_dummy_patient_data, plot_age_distribution
# --- メイン実行ブロック ---
# (Pythonスクリプトのお作法:このファイルが直接実行された時だけ、以下の処理を行う)
if __name__ == "__main__":
# 1. ログ(実行開始のメッセージ)を表示
print("分析プロセスを開始します...")
# 2. 「データ作成部品」を呼び出し、150人分のデータを作成
# 結果は patient_df という変数に格納される
patient_df = create_dummy_patient_data(num_patients=150, seed=123)
# 3. グラフを保存するファイルパスを定義
# 'results' というフォルダ(別途作成しておく)に保存する想定
output_filepath = "results/age_distribution_plot.png"
# 4. 「グラフ描画部品」を呼び出し
# (patient_df と output_filepath を引数として渡す)
plot_age_distribution(df=patient_df, save_path=output_filepath)
# 5. ログ(実行完了のメッセージ)を表示
print("分析プロセスが正常に完了しました。")作業3:VS Codeのターミナルから実行する
VS Codeには「統合ターミナル」という、コマンドを実行するための画面が内蔵されています(メニューの「ターミナル」 > 「新しいターミナル」で開けます)。
(あらかじめ mkdir results コマンド(またはエクスプローラーで右クリック→「新しいフォルダー」)で results フォルダを作成しておいてください)
ターミナルで、Conda環境が (clinical-ai) になっていることを確認し、以下のコマンドを実行します。
(clinical-ai) % python run_analysis.py
【実行結果(ターミナル)】
分析プロセスを開始します...
グラフを results/age_distribution_plot.png に保存しました。
分析プロセスが正常に完了しました。
results フォルダを見ると、age_distribution_plot.png というグラフファイルが生成されているはずです。

これが「本番コード」の動き方です。Jupyterのようにセルを順に実行するのではなく、python run_analysis.py というコマンド一つで、定義された手順書が上から順に自動実行されます。これこそが「再現性」です。
VS Codeの最強機能「デバッガ」:コードの内部診断
VS Codeが「手術室」である最大の理由が、この「デバッガ」機能です。
JupyterやRでコードが動かない時、私たちは print() 関数をコードのあちこちに挿入し、変数の途中経過を表示させてエラーの原因を探します。これは、原因がわからないまま「とりあえず採血してみる」という対症療法に似ています。
一方、VS Codeのデバッガは「コードのCT/MRI」あるいは「動作中のコードの内部を覗く内視鏡」です。
run_analysis.py を開いた状態で、VS Codeの左側にある「実行とデバッグ」(虫のアイコン)タブを開き、以下の操作をします。
- ブレークポイント (Breakpoint) の設定:
run_analysis.pyのpatient_df = ...という行の左側(行番号のあたり)をクリックして、赤い丸(ブレークポイント)を付けます。 - デバッグの開始: 「実行とデバッグ」ボタン(緑の三角)を押します。
すると、プログラムの実行が赤い丸を付けた行で「一時停止」します。
この状態で、以下のことができます。
- ステップ実行 (Step Over/Into): 一時停止した状態で、コードを1行ずつ、あるいは関数の中(
create_dummy_patient_dataの中身)に入り込みながら実行を進められます。 - 変数モニタ: 画面左側の「変数」ウィンドウに、その時点でのすべての変数の値がリアルタイムで表示されます。
patient_dfが作成された直後に止めれば、その中身(DataFrame)をドリルダウンして確認できます。
つまり、「症状(エラーメッセージ)」から原因を推測するのではなく、コードの実行プロセス(血流)を一時停止させ、内部の状態(血液検査データや画像所見)をリアルタイムで詳細に観察し、エラーの「根本原因」を診断できるのです。
付録:VS Codeデバッガ 基本ショートカット (安全版)
- F5 デバッグの開始 / 続行
- F9 ブレークポイントの設定/解除
- F10 ステップオーバー (1行実行)
- F11 ステップイン (関数の中に入る)
- Shift + F11 ステップアウト (関数の外に出る)
- Shift + F5 デバッグの停止
環境の接続(C30.2とC30.4をつなぐ)
(このセクションは【プロジェクトフォルダの準備】の「Python環境の接続」ステップで既に詳細に解説済みですが、念のため再掲します)
VS Codeという「手術室」に、C30.2(またはC30.5)で作った clinical-ai 環境という「清潔な薬剤・器具セット」を持ち込む必要があります。
VS Codeは、PC内に複数のPython環境(標準のPython、Conda環境など)があっても、プロジェクトごとに「どの環境(インタプリタ)を使うか」を選択できます。VS Codeの右下(または左下)に表示されているPythonのバージョンをクリックし、リストから clinical-ai を選ぶだけで接続は完了です。
これにより、VS Codeは clinical-ai 環境にインストールしたライブラリ(Pandasなど)を正しく認識し、コード補完やデバッグを実行できるようになります。
まとめ:VS Codeで「資産」を作る
Jupyter Notebookが「試行錯誤(Experiment)」の場であるなら、VS Codeは「再現可能な資産(Assets)」を作る場です。
この「ゾーニング(src/)」と「リファクタリング(清書)」、そして「デバッガ(内部診断)」の習慣を身につけることが、あなたの書くコードを「その場限りのメモ」から「チームで共有し、臨床現場で安全に運用できるAI」へと昇格させる、最も重要な第一歩となります。
参考文献
- Ampcome. (2025). Top 7 AI Agent Frameworks in 2025 — Ultimate Guide. [Online] Available at: https://www.ampcome.com/post/top-7-ai-agent-frameworks-in-2025 (Accessed: 16 November 2025).
- Binadox. (2025). Best Local LLMs for Cost-Effective AI Development in 2025. [Online] Available at: https://www.google.com/search?q=https://www.binadox.com/blog/best-local-llms-for-cost-effective-ai-development-in-2025 (Accessed: 16 November 2025).
- Fowler, M. (2018). Refactoring: Improving the Design of Existing Code (2nd Edition). Addison-Wesley Professional.
- GitHub Blog. (2025). GitHub Copilot in Visual Studio — August update. [Online] Available at: https://github.blog/changelog/2025-08-28-github-copilot-in-visual-studio-august-update/ (Accessed: 16 November 2025).
- Hunter, J.D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3), pp.90-95.
- Linters (2024). Marketplace for Visual Studio Code. [Online] Available at: https://marketplace.visualstudio.com/search?target=VSCode&category=Linters (Accessed: 16 November 2025).
- McKinney, W. (2010). Data structures for statistical computing in Python. In: Proceedings of the 9th Python in Science Conference (SciPy 2010). pp. 56–61.
- Medium. (2025). Top 5 Local LLM Tools and Models to Use in 2025. [Online] Available at: https://medium.com/@bishakhghosh0/top-5-local-llm-tools-and-models-to-use-in-2025-57b0c3088520 (Accessed: 16 November 2025).
- Microsoft (2024). Python in Visual Studio Code. [Online] Available at: https://code.visualstudio.com/docs/languages/python (Accessed: 16 November 2025).
- Nut Studio. (2025). [2025] Best LLMs for Coding Ranked: Free, Local, Open Models. [Online] Available at: https://nutstudio.imyfone.com/llm-tips/best-llm-for-coding/ (Accessed: 16 November 2025).
- Pinggy. (2025). Top 5 Local LLM Tools and Models in 2025. [Online] Available at: https://pinggy.io/blog/top_5_local_llm_tools_and_models_2025/ (Accessed: 16 November 2025).
- Sider. (2025). 10 Best Agentic AI Frameworks for Developers in 2025. [Online] Available at: https://sider.ai/blog/ai-tools/best-agentic-ai-frameworks-for-developers-in-2025-what-to-build-with-and-why (Accessed: 16 November 2025).
- Stack Overflow (2023). 2023 Developer Survey: Integrated development environment. [Online] Available at: https://survey.stackoverflow.co/2023/#integrated-development-environment (Accessed: 16 November 2025).
- Towards AI. (2025). AI Agents Design Patterns: Complete Guide to Agentic AI Models in 2025. [Online] Available at: https://pub.towardsai.net/ai-agents-design-patterns-complete-guide-to-agentic-ai-models-in-2025-b0fe49cd02d7 (Accessed: 16 November 2025).
- Visual Studio Code. (2025). Open Source AI Editor: Second Milestone. [Online] Available at: https://code.visualstudio.com/blogs/2025/11/04/openSourceAIEditorSecondMilestone (Accessed: 16 November 2025).
- Visual Studio Code (2024). Download Visual Studio Code. [Online] Available at: https://code.visualstudio.com/ (Accessed: 16 November 2025).
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




