

この章では、医療AI開発の「作業台」となるJupyter Notebookの使い方を学びます。データと対話し、試行錯誤のプロセスを記録する強力なツールですが、「再現性」を保つルールと、本番開発(VS Code)との「分業」を理解することが重要です。
「コード(操作)」「実行結果(グラフ等)」「考察(文章)」を一つの文書に記録できます。これにより、試行錯誤のプロセス全体を物語として保存できます。
データを読み込み、統計量を調べ (.describe())、可視化する (.hist()) サイクルを高速で回せます。データが何を語っているかを素早く把握するのに最適です。
鉄則: 実行順序の罠を避け、「カーネルを再起動し、上から順に実行」してもエラーなく動くノートブックを維持すること。これが分析の再現性を保証します。
C30.1では、医療AIの世界でなぜPythonが「共通言語」になったのか、その全体像を掴みました。Pythonという強力な言語と、それを取り巻く道具箱(エコシステム)の存在が鍵でしたね。
さて、今回からはいよいよ、その道具箱の中でも最も重要で、研究・開発の「作業台」となるJupyter Notebook(ジュピター・ノートブック)の使い方を学びます。
医療AIの開発は、臨床研究や基礎研究と非常によく似ています。最初から完璧な答えがわかっていることは稀で、大半は「データを眺め、仮説を立て、試しに分析し、結果を見て、また考える」という地道な試行錯誤の繰り返しです。
この「試行錯誤のプロセス」を、驚くほど強力にサポートしてくれるのがJupyter Notebookなんです。これは単なるツールではなく、私たちの「思考のカルテ」あるいは「デジタルの実験ノート」そのものになります。
しかし、多くの初学者がこのツールの「本当の力」を理解しないまま使ってしまい、後で再現できなくなる「動かないコード」の山を築いてしまう…という失敗に陥りがちです。この回では、Jupyter Notebookを「科学的な実験ノート」として正しく使いこなすための、最も重要な習慣を身につけていきましょう。
最初のステップ:JupyterLabを使えるようにする(環境構築)
Jupyter Notebook(より正確には、その後継であるJupyterLab)を使うには、まずご自身のPCにPythonと関連ライブラリをインストールする「環境構築」が必要です。
プログラミングの環境構築には様々な方法がありますが、特に医療AIのように複雑な科学技術計算ライブラリ(今後学ぶPyTorchやTensorFlowなど)を扱う場合、「Conda(コンダ)」というパッケージ管理システムを使うのが最も安定的で、世界的な標準となっています。これはC30.5で詳しく学びますが、ここではまず「動かす」ための手順を紹介します。
Condaは、Python本体、JupyterLab、その他の分析ツール(Pandasなど)を、プロジェクトごとに独立した「部屋(仮想環境)」にまとめてインストールしてくれる便利なツールです。ここでは、軽量版である「Miniconda」の導入を例に進めます。
1. Minicondaのインストール
まず、お使いのOS(Windows, macOS, Linux)に合わせて、Minicondaのインストラーをダウンロードします。Anacondaの公式サイト(https://docs.conda.io/en/latest/miniconda.html)から、最新のPython 3系のインストーラーを選んでください。
2. OS別セットアップ手順
ダウンロードしたインストーラーを使って、Minicondaをインストールします。
- Windowsの場合:
- ダウンロードした
.exeファイルを実行します。 - 基本的にはすべてデフォルト設定のまま「Next」をクリックして進めます。「Install for:」は「Just Me」を推奨します。
- 「Advanced Options」では、「Register Anaconda as my default Python」にチェックを入れておくと便利です。
- インストール後、「スタートメニュー」から「Anaconda Prompt (Miniconda3)」という黒い画面(ターミナル)を起動します。
- ダウンロードした
- macOSの場合:
- ダウンロードした
.pkgファイル(または.shファイル)を実行します。.pkgファイルであれば、画面の指示に従ってインストールを進めてください。 .shファイルの場合は、「ターミナル」アプリ(/Applications/Utilities/内にあります)を開き、以下のコマンドを実行します(ファイル名はダウンロードしたものに合わせてください)。bash Miniconda3-latest-MacOSX-x86_64.sh(Apple Silicon (M1/M2/M3) の場合はarm64版をお使いください)- インストール後、一度ターミナルを完全に終了し、再起動してください。
- ダウンロードした
- Linux (Ubuntuなど) の場合:
- 「ターミナル」を開きます。
wgetコマンドなどで.shファイルをダウンロードします。- 以下のコマンドでインストールを実行します(ファイル名は適宜変更してください)。
bash Miniconda3-latest-Linux-x86_64.sh - インストール後、一度ターミナルを完全に終了し、再起動してください。
3. 仮想環境の作成とJupyterLabのインストール
ここからは、先ほど起動した「Anaconda Prompt」(Windows)または「ターミナル」(Mac/Linux)上で、OS共通のコマンドを実行します。以下のコマンドを1行ずつコピー&ペーストして実行してください。
# 1. 'clinical-ai' という名前の仮想環境を作成します
# (Pythonのバージョンは3.10を指定。-y は確認プロンプトを自動でYesにするオプション)
# この「仮想環境」についてはC30.4, C30.5で詳しく学びます
conda create -n clinical-ai python=3.10 -y
# 2. 作成した 'clinical-ai' 環境を有効化(アクティベート)します
# これ以降のコマンドは、この専用環境の中で実行されます
conda activate clinical-ai
# 3-A. Condaで主要ライブラリをインストールします
# jupyterlab: JupyterLab本体
# pandas: データ分析の必須ツール (McKinney, 2010)
# matplotlib: グラフ描画 (Hunter, 2007)
# -c conda-forge: 高品質なパッケージ配布元 (conda-forgeチャネル) を指定
conda install jupyterlab pandas matplotlib -c conda-forge -y
# 3-B. pipで日本語化ライブラリをインストールします
# (Condaチャンネルで見つからない場合があるため、pipを使います)
pip install japanize-matplotlib4. JupyterLabの起動
インストールが完了したら、同じターミナル画面で以下のコマンドを実行します。
# カレントディレクトリで JupyterLab を起動します
jupyter lab自動的にデフォルトのWebブラウザが起動し、以下のようなJupyterLabの画面(左側にファイル一覧が表示されるダッシュボード)が表示されれば、環境構築は成功です。
🚀 コラム:マジでPythonする5秒前「Google Colab」
「黒い画面(ターミナル)での設定エラーが解決できない」「職場のPCはセキュリティ制限でソフトを勝手にインストールできない」……。
環境構築は、プログラミング学習における最大の「挫折ポイント」です。しかし、現代にはそれを一瞬で飛び越える強力なクラウドサービスが存在します。それが、Google Colaboratory(通称:Colab)です。
🌐 Google Colabとは?
一言で言えば、「Googleが所有する高性能なコンピュータを、ブラウザ経由で無料で貸してもらえるサービス」です (Bisong, 2019)。
本来なら数時間かかる環境構築が不要で、Googleアカウントさえあれば、URLをクリックした5秒後にはPythonコードを書き始めることができます。
✅ 医療AI学習における3つのメリット
- 環境構築ゼロ:Jupyter Notebook環境がすでに用意されており、
pandasやmatplotlib、さらには深層学習フレームワーク(PyTorch,TensorFlow)までもが最初からインストールされています。- GPUが無料:通常、数十万円するような高性能GPU(画像解析などのAI計算に必要な部品)を、なんと無料で利用可能です(※制限あり)。
- 共有が容易:Googleドキュメントと同じ感覚で、URLを送るだけでコードを共同研究者と共有できます。
⚠️ 【最重要】医療データの取り扱いに関する鉄則
Colabは非常に便利ですが、医療従事者として必ず認識しておくべき「致命的なリスク」があります。それはデータの保存場所です。
Colab上で読み込んだデータは、一時的にGoogleのクラウドサーバー(仮想マシン)上にアップロードされます。無料版のColabは、米国の医療保険の携行性と責任に関する法律(HIPAA)に準拠する契約(BAA)の対象外であり、日本の個人情報保護法における「第三者提供」や「委託」の観点からも、十分な法的保護措置をとることが困難です (Carneiro et al., 2020; 厚生労働省, 2024)。
【鉄則】
本物の患者データ(個人情報・要配慮個人情報)は、絶対にGoogle Colab(特に無料版)にアップロードしてはいけません。本講座で使用するような「学習用の架空データ(ダミーデータ)」や「公開データセット(MIMIC-IVのデモ版など)」であれば、Colabを使っても全く問題ありません。まずはColabでPythonの操作に慣れ、機密データを扱う段階になったら、記事前半で解説した「ローカル環境(オフライン)」へ移行するという使い分けを推奨します。
Jupyter Notebookとは? ― 「思考」と「実行」の融合
もし、あなたが臨床研究のデータを分析する場面を想像してみてください。おそらく、Excelや統計ソフトでデータを読み込み、グラフを作り、その結果をWordやPowerPointに貼り付け、そこにあなたの「考察」を書き込む…といった作業をしているのではないでしょうか。
Jupyter Notebookは、これら一連の作業を「一つの文書」で完結させるためのツールです。
最大の特徴は、文書が「セル」というブロックの集まりでできていること。そして、このセルには2つの主要な種類があります。
- コードセル (Code Cell): Pythonのコード(指示)を書き込み、実行する場所。
- マークダウンセル (Markdown Cell): 文章や見出し、数式、考察などを書き留める場所。
これが何を意味するのか?
つまり、「コード(実験操作)」と「実行結果(データやグラフ)」、そして「あなたの考察(なぜそれをしたか)」を、すべて一つの時系列に沿った文書として記録できるのです。
これは、科学的プロセスにおいて革命的でした。従来の「コードは.pyファイルに、結果はWordに、考察は頭の中に…」というバラバラの状態を防ぎ、分析のプロセス全体を一つの物語として保存できるようになったのです (Kluyver et al., 2016)。
JupyterLab:あなたの「デジタル研究室デスク」
先ほど起動したのは「JupyterLab(ジュピター・ラボ)」という画面でした。Jupyter Notebookとはどう違うのでしょうか?
- Jupyter Notebook (Classic):
- 例えるなら: 「一冊のノート」を開くためのシンプルなビューア。
- 特徴: 一度に一つのノートブックファイル(
.ipynb)を開いて編集することに特化しています。
- JupyterLab:
- 例えるなら: 「研究室のデスク全体」。
- 特徴: ノートブックだけでなく、データファイル(CSVなど)、ターミナル(コマンド操作画面)、テキストエディタなどを、ブラウザのタブや画面分割で同時に開いて作業できる「統合開発環境」です。
現在(2025年時点)では、JupyterLabが標準的なインターフェースとなっており、機能も豊富です。私たちは基本的にJupyterLabを「作業デスク」として使い、その中で「実験ノート(Notebookファイル)」を開いていくイメージを持つと良いでしょう。
EDA:データと「対話」するための最強の道具
Jupyter Notebookが最も輝く瞬間、それはEDA(Exploratory Data Analysis:探索的データ解析)を行うときです。
EDAとは、統計学者のジョン・テューキーが提唱した概念で、一言でいえば「データが何を語っているか、まずはいろいろな角度から眺めてみること」です (Tukey, 1977)。これは、私たちが患者を初めて診察するとき、まずバイタルサインや視診・触診で全体像を把握しようとする行為に似ています。
JupyterLabの画面で、左上の「+」ボタンから「Python 3 (ipykernel)」を選択して新しいノートブックを作成し、以下の「対話」を試してみましょう。
【実行前の準備】先ほどの環境構築ステップで、必要なライブラリ (pandas, matplotlib, japanize-matplotlib) はインストール済みです。以下のコードをセルにコピー&ペーストし、セルの左側にある「▶」(実行)ボタンを押すか、Shift + Enterキーを押して実行してください。
# --- 0. 必要なライブラリのインポート ---
# 乱数シードを固定 (いつでも同じ架空データが作られるようにするため)
import numpy as np
np.random.seed(42)
# データ分析ライブラリ pandas を 'pd' という短い名前でインポート
import pandas as pd
# グラフ描画ライブラリ matplotlib の pyplot モジュールを 'plt' という名前でインポート
import matplotlib.pyplot as plt
# グラフの日本語表示対応ライブラリをインポート (これだけで日本語が使えるようになります)
import japanize_matplotlib# --- 1. 架空の医療データの作成 ---
# (実際にはここで pd.read_csv('your_data.csv') のように外部データを読み込みます)
# 100人分の架空の患者データを作成します
data = {
'年齢': np.random.randint(20, 80, 100),
'性別': np.random.choice(['男性', '女性'], 100),
'HbA1c': np.random.normal(6.5, 1.0, 100).round(1), # 平均6.5, 標準偏差1.0の正規分布
'BMI': np.random.normal(23, 3.0, 100).round(1) # 平均23.0, 標準偏差3.0の正規分布
}
# Pythonの辞書(data)からPandasのDataFrame(データフレーム)という表形式のデータを作成
df = pd.DataFrame(data)# --- 2. データの確認 (最初の5行) ---
# .head() メソッドでデータの先頭部分を表示し、全体像を掴みます
# print() を使うとJupyter Notebook上で綺麗に表示されます
print("--- データの先頭5行 ---")
print(df.head())【実行結果】
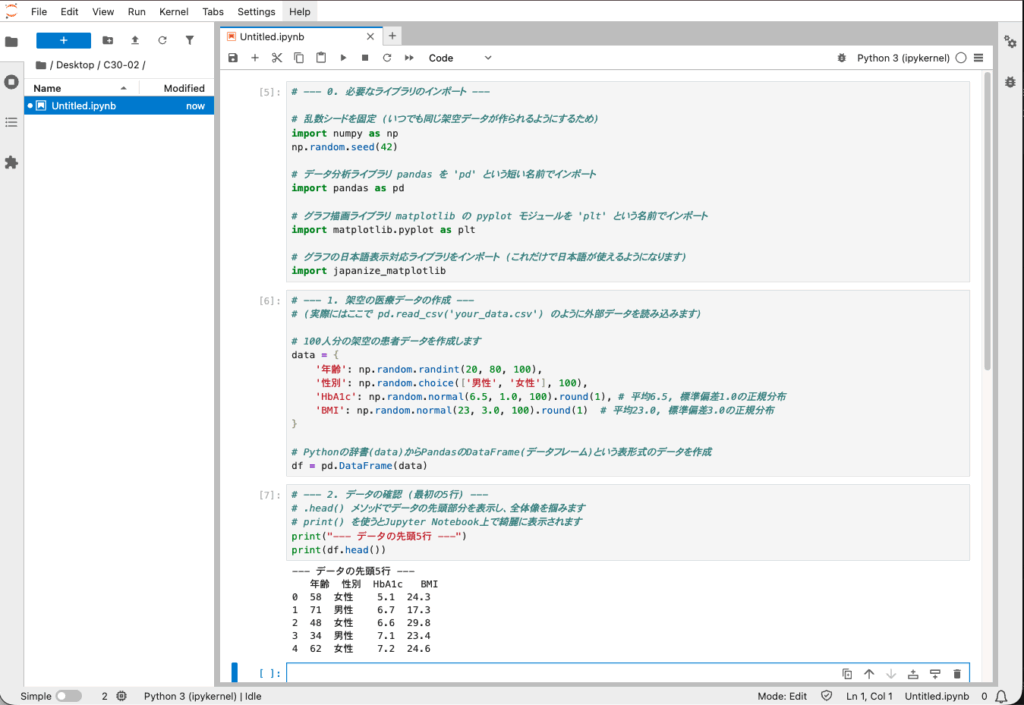
--- データの先頭5行 ---
年齢 性別 HbA1c BMI
0 78 男性 6.4 20.4
1 58 男性 6.2 22.7
2 40 男性 5.3 23.2
3 70 女性 7.6 23.1
4. 38 女性 6.0 21.3
# --- 3. データの要約統計量 ---
# .describe() メソッドで数値データ(年齢, HbA1c, BMI)の
# 基本統計量(件数, 平均, 標準偏差, 最小値, 四分位数, 最大値)を計算
print("\n--- データの要約統計量 ---")
print(df.describe())【実行結果】
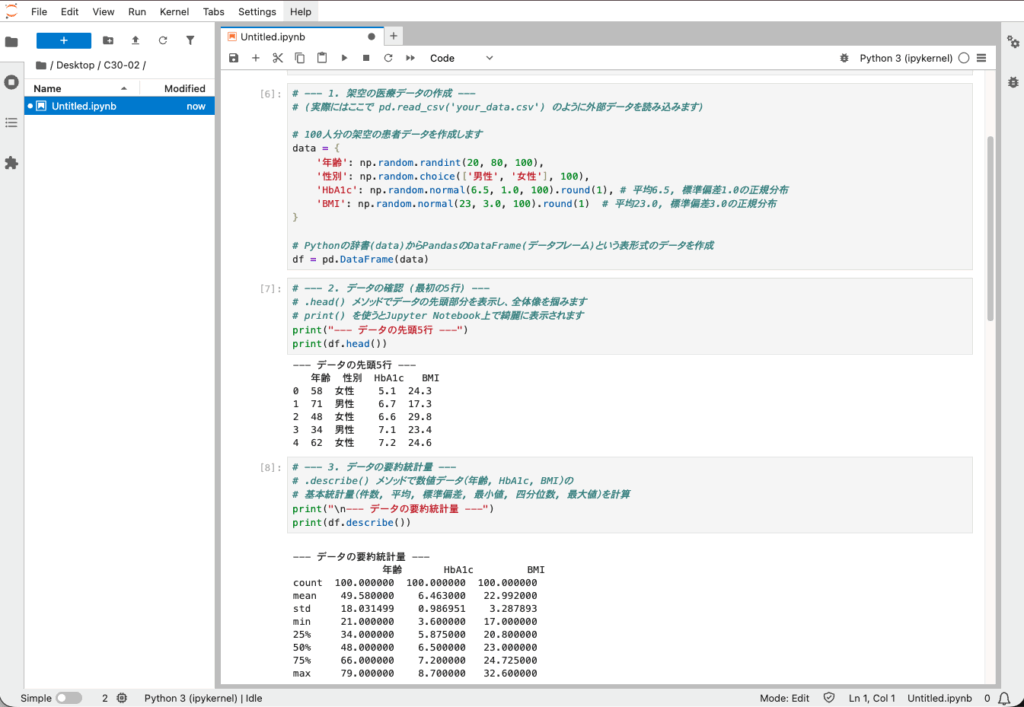
--- データの要約統計量 ---
年齢 HbA1c BMI
count 100.000000 100.000000 100.000000
mean 49.610000 6.541000 23.081000
std 17.026779 1.002018 2.993716
min 20.000000 4.100000 16.000000
25% 38.000000 5.900000 20.975000
50% 50.000000 6.600000 23.200000
75% 62.250000 7.225000 25.300000
max 79.000000 9.400000 30.800000
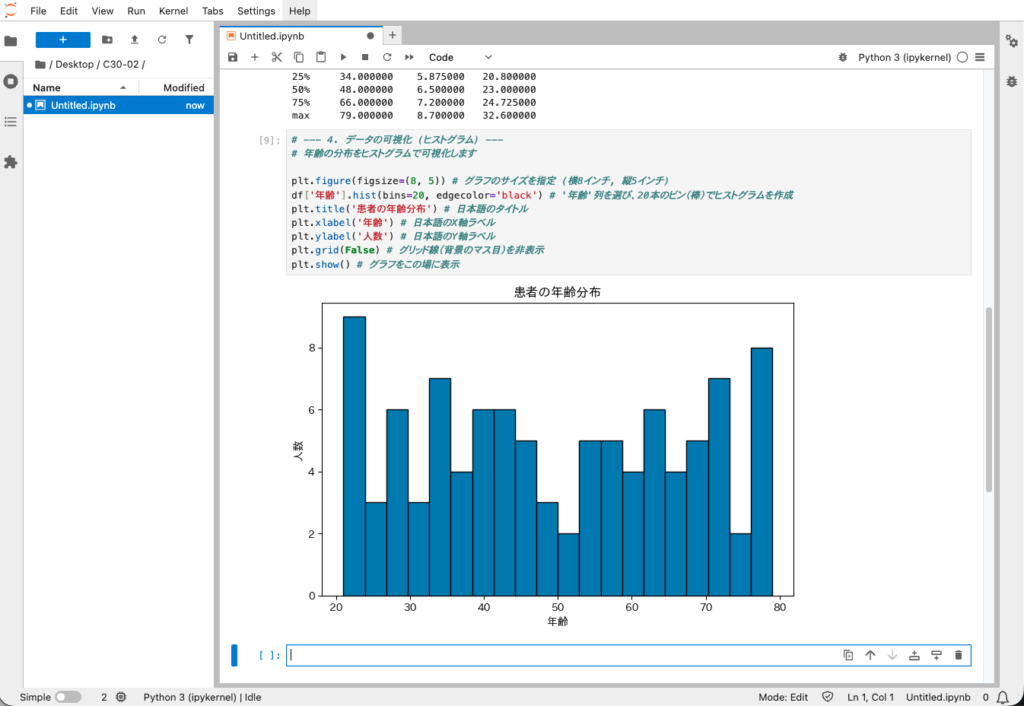
# --- 4. データの可視化 (ヒストグラム) ---
# 年齢の分布をヒストグラムで可視化します
plt.figure(figsize=(8, 5)) # グラフのサイズを指定 (横8インチ, 縦5インチ)
df['年齢'].hist(bins=20, edgecolor='black') # '年齢'列を選び、20本のビン(棒)でヒストグラムを作成
plt.title('患者の年齢分布') # 日本語のタイトル
plt.xlabel('年齢') # 日本語のX軸ラベル
plt.ylabel('人数') # 日本語のY軸ラベル
plt.grid(False) # グリッド線(背景のマス目)を非表示
plt.show() # グラフをこの場に表示【実行結果】
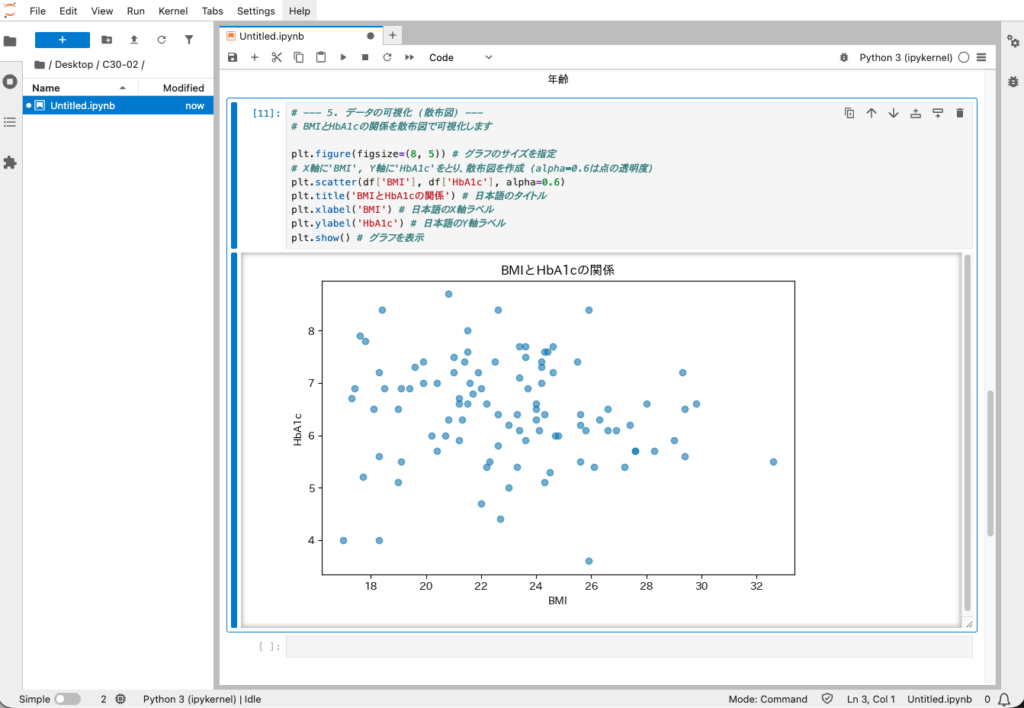
# --- 5. データの可視化 (散布図) ---
# BMIとHbA1cの関係を散布図で可視化します
plt.figure(figsize=(8, 5)) # グラフのサイズを指定
# X軸に'BMI', Y軸に'HbA1c'をとり、散布図を作成 (alpha=0.6は点の透明度)
plt.scatter(df['BMI'], df['HbA1c'], alpha=0.6)
plt.title('BMIとHbA1cの関係') # 日本語のタイトル
plt.xlabel('BMI') # 日本語のX軸ラベル
plt.ylabel('HbA1c') # 日本語のY軸ラベル
plt.show() # グラフを表示【実行結果】
このように、「コードを書き、実行し、結果(表やグラフ)を見て、考察し(Markdownセルに記録し)、次のコードを書く」というサイクルを、ページを移動することなく、猛烈なスピードで回せる。これがJupyter NotebookのEDAにおける圧倒的な強みです。
「動くSOP」にするための最重要ルール
Jupyter Notebookは非常に自由度が高く便利な反面、深刻な「落とし穴」があります。それは、「実行順序の罠」です。
Jupyterでは、セルを好きな順番で実行できます。例えば、文書の一番下のセルを先に実行し、その次に一番上のセルを実行することも可能です。これが、のちの「再現性の悪夢」に繋がります。
アンチパターン(悪い例): スパゲッティ・ノートブック
[セル 1] In [2]:
print(x * 2) <-- これを2番目に実行すると...
---
[出力]
> 20 <-- 10 * 2 = 20 が表示される
[セル 2] In [1]:
x = 10 <-- これを1番目に実行する
このノートブックは、[セル 2] → [セル 1] の順で実行すれば動きます。しかし、数日後にあなたが(あるいは共同研究者が)このノートブックを開き、いつもの習慣で「上から順に実行」したらどうなるでしょう? [セル 1] を実行した時点で「xが定義されていません」というエラーになります。
これは、手順書(SOP)が「手順5を先にやらないと手順1が実行できない」と書かれているようなもので、科学的な記録としては失格です。
そこで、私たちは「良い実験ノート」にするために、以下の鉄則を守る必要があります。
鉄則:「カーネルを再起動して、上から順にすべて実行」したときに、エラーなく最後まで通ること。
(※JupyterLabのメニューバーにある「Kernel」→「Restart Kernel and Run All Cells…」で実行できます。これは計算状態をすべてリセットし、白紙の状態からノートブックを最初から最後まで実行する操作です。)
これこそが、あなたの分析が「再現可能である」ことの最低限の保証です。この習慣を身につけることが、C30.2の最大のゴールの一つです (Rule et al., 2019)。
Jupyterの「限界」:作業台は手術室ではない
最後に、最も重要な「分業」の話をします。
Jupyter Notebookは、あくまで「研究室の作業台(仮説検証の場)」です。ここで試行錯誤し、最良の分析プロトコル(SOP)を見つけ出します。
しかし、このノートブック・ファイル(.ipynb)を、そのまま病院の電子カルテシステムに組み込んだり、Webアプリケーションとして公開したりする(=本番運用する)のは、非常に危険です。
比喩: あなたが作業台で見つけた素晴らしい術式(ロジック)を、その作業台ごと手術室に持ち込み、患者の手術(本番運用)をしようとしているようなものです。
Jupyter Notebookには以下の限界があります。
- 再現性の脆さ: 少しの実行順序の間違いで動かなくなる。
- バージョン管理の困難さ: コードの変更履歴(差分)が
git(C30.7で学習)で非常に読みにくい。 - 本番運用に不向き: 自動実行やAPIサーバーとしての動作を想定して作られていない。
では、どうすればよいのでしょうか?
答えは、「Jupyterで見つけたロジックを、本番用のコード(Pythonスクリプトファイル)として清書する」です。
この「清書」と「本番システムの構築」を行う場所こそが、次(C30.3)で学ぶVS Codeという「本格的な開発室(手術室)」の役割なのです。
Jupyter Notebookで「何をすべきか(What)」を見つけ出し、VS Codeで「それをいかに安定して動かすか(How)」を実装する。この分業の意識を、必ず持っておいてください。
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
参考文献
- Hunter, J.D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3), pp.90-95.
- Kluyver, T., Ragan-Kelley, B., Pérez, F., Granger, B.E., Bussonnier, M., Frederic, J., Kelley,K., Hamrick, J.B., Grout, J., CorLAY, S. and Ivanov, P. (2016). Jupyter Notebooks–a publishing format for reproducible computational workflows. In: ELPUB 2016, 20th International Conference on Electronic Publishing.
- McKinney, W. (2010). Data structures for statistical computing in Python. In: Proceedings of the 9th Python in Science Conference (SciPy 2010). pp. 56–61.
- Project Jupyter. (2024). JupyterLab. [Online] Available at: https://jupyter.org/ (Accessed: 16 November 2025).
- Rule, A., Birmingham, A., Zuniga, C., Altintas, I. and Voytek, B. (2019). Ten simple rules for writing and sharing computational analyses in Jupyter Notebooks. PLoS Computational Biology, 15(7), e1007007.
- Tukey, J.W. (1977). Exploratory Data Analysis. Reading, MA: Addison-Wesley.
- Anaconda Software Distribution. (2025). Miniconda. [Online] Available at: https://docs.conda.io/en/latest/miniconda.html (Accessed: 16 November 2025).
- Bisong, E. (2019). Google Colaboratory. In: Building Machine Learning and Deep Learning Models on Google Cloud Platform. Apress, Berkeley, CA. pp. 59-64.
- Carneiro, T., Da Nóbrega, R.V.M., Nepomuceno, T., Bian, G.B., De Albuquerque, V.H.C. and Reboucas Filho, P.P. (2018). Performance analysis of Google Colaboratory as a tool for accelerating deep learning applications. IEEE Access, 6, pp.61677-61685.
- 厚生労働省. (2024). 医療情報システムの安全管理に関するガイドライン 第6.0版.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




