

AIの賢さを支える「最適化」の世界を探検します。AIがどのようにして膨大な選択肢から最良の答えを見つけ出すのか、その思考のエンジンとなる基本原理と応用を学びましょう。
最適化とは「目的」「変数」「制約」の3要素を定め、目的を最大/最小化する変数の組み合わせを見つけるプロセスです。AIが自ら学習するための根幹をなす思考法です。
AIは「損失関数(地形図)」の値を最小にするため、「勾配降下法(航海術)」で膨大な「パラメータ(舵)」を自動調整します。この地道な繰り返しがAIの「学習」の正体です。
医療の「効果 vs 副作用」のような相反する目的の最適化では、「ラグランジュの未定乗数法」が活躍。限られたリソースの中で最善のバランス点を見つける強力な道具です。
医療の現場は、日々「最適解」を探し出す航海に似ていると思いませんか? 無数の治療法の中から、目の前の患者さんにとって何が最善か。この治療法は高い効果が期待できる一方、無視できない副作用のリスクを伴う。Aという薬剤とBという薬剤、エビデンスレベルは同等だが、この患者さんの背景を考えるとどちらがより適しているのか。
こうした複雑なトレードオフと不確実性に満ちた意思決定を、私たちは経験と直感、そして利用可能なエビデンスを頼りに行っています。それは非常に人間的で、尊いプロセスです。しかし、情報が爆発的に増加し、医療がより個別化・複雑化する現代において、人間の認知能力だけですべての変数を考慮し、常に最善の選択をすることは、時に困難を極めるのではないでしょうか。
もし、この複雑で知的な探求を、AIが強力にサポートしてくれるとしたらどうでしょう。世界中の膨大な医学論文や臨床データを瞬時に解析し、目の前の患者さんと類似した症例グループでの治療成績を客観的に提示してくれたら。あるいは、放射線治療計画のように、無数のビーム角度や強度の中から、腫瘍への線量を最大化しつつ正常組織へのダメージを最小化するような、人間では到底計算しきれない最適な照射パターンを提案してくれたら(Ehrgott et al., 2008)。
実は、AIがデータから学び、こうした賢い提案能力を獲得していくプロセスのまさに中心にあるのが、この「解を探し出す航海」の技術です。私たちはそれを「最適化(Optimization)」と呼んでいます。最適化とは、単なる答え探しではありません。それは、「ある制約条件の中で」「特定の評価指標を最も良くする」という明確な目的のもと、無数の選択肢の中から最良の一点を見つけ出す、論理的で体系的なアプローチです。
このコースでは、AIの思考エンジンの心臓部ともいえる「最適化」の世界を、羅針盤を一つひとつ読み解くように、一緒に探求してみましょう。
最適化とは何か?~至高のレシピを求めて~
「最適化」という言葉に、少し身構えてしまうかもしれませんね。数式やアルゴリズムが並ぶ、難解な世界を想像される方もいるかもしれません。ですが、その本質は極めて明快で、実は私たちの日常や臨床判断の中に深く根付いています。
一言でいうなら、最適化とは「定められた制約の中で、ある指標を最も望ましい状態(最大または最小)にするための変数の組み合わせを発見する、体系的なプロセス」です。
まだピンとこないかもしれませんので、少し想像を巡らせてみてください。あなたは今、糖尿病患者さんのための、美味しくて健康的なデザートレシピを開発しているとします。目標は「血糖値の上昇を最小限に抑えつつ、最高の満足度(美味しさ)を実現する」ことです。
このとき、あなたは何をするでしょうか? 手元には、砂糖の代替となる様々な甘味料(エリスリトール、ステビアなど)、食物繊維を増やすための食材(おからパウダー、サイリウムなど)、風味を豊かにするスパイス(シナモン、バニラなど)があります。
きっと、闇雲に混ぜることはしないはずです。
- 何を「良く」したいのか(目的)? → 「満足度スコア」を最大化し、「予測血糖上昇値」を最小化したい。
- 何を「調整」できるのか(変数)? → エリスリトールの量、おからパウダーの量、シナモンの量… これらが調整可能な変数です。
- 守るべき「ルール」は(制約)? → 「総カロリーは150kcal以内」「炭水化物量は10g未満」「材料費は1食200円以下」といった制約があるかもしれません。
あなたはこの3つの要素を頭に入れながら、各材料(変数)の量を精密に調整し、試作品を作っては味見をし(評価)、目標に近づくようにレシピを改良していくでしょう。「エリスリトールを増やすと甘みは増すが、後味が少し気になるな。バニラを少し加えてみようか」「おからパウダーを増やすと食物繊維は摂れるが、食感がパサつく。アーモンドミルクで水分を調整しよう」。
この「目的・変数・制約」を定義し、評価とフィードバックを繰り返しながら最良の解へと収束させていくプロセス、これこそが「最適化」の思考法なのです。
AIの学習と最適化:パラメータという名の”レシピ”調整
この「目的・変数・制約」を定義し、評価とフィードバックを通じて最良の解を探すという考え方は、AIが学習するプロセスそのものです。先ほどのレシピ開発の比喩を、AIの内部で何が起きているかに置き換えて見ていきましょう。
- スパイスの配合比率(変数)→ AIモデルのパラメータ
AIモデル、特に人間の脳神経を模したニューラルネットワークは、多数のニューロンが結合して構成されています。このニューロン間の結合の強さ(重み Weight)と、各ニューロンの発火のしやすさ(バイアス Bias)を調整可能な数値にしたものがパラメータです。この重みとバイアスの膨大な集合体こそが、AIの「知識」や「判断基準」の結晶であり、我々がレシピで調整した「スパイスの配合比率」に相当します。「どの入力情報をどれだけ重視するか(重み)」、「全体のアウトプットをどちらの方向に傾けるか(バイアス)」を、このパラメータ群が決定します。 - 料理の味(評価)→ 損失関数による評価
AIが算出した予測結果の「良し悪し」を評価するのが損失関数です。これは、作ったデザートをプロのテイスターが評価し、「理想の味と比べて甘みが強すぎる(損失:大)」「食感が理想に非常に近い(損失:小)」といった具体的なフィードバック(損失の値)を返す役割に似ています。AIはこの損失という名のたった一つの数値だけを頼りに、次にレシピをどう改良すべきか(パラメータをどう更新すべきか)の方向性を知るのです。 - レシピのルール(制約)→ 過学習を防ぐ正則化
最高のデザートを目指すあまり、特定の審査員(学習データ)の好みだけに特化した、奇抜すぎるレシピができてしまうことがあります。このレシピは、その審査員には絶賛されるかもしれませんが、一般のお客さん(未知のデータ)の口には全く合わないかもしれません。これが、AIにおける過学習(Overfitting)と呼ばれる現象です。これを防ぐために、「特定のスパイス(パラメータの値)を極端に大きくしすぎないように」「レシピはできるだけシンプルに(モデルを不必要に複雑にしないように)」といったルールを課します。このルールこそが、正則化(Regularization)と呼ばれるテクニックです。これにより、AIはより汎用性の高い、未知のデータにも強い知識を獲得しようとします。
人間が試行錯誤で調整できるレシピの材料は、せいぜい数十種類でしょう。しかし、現代のAI、特にOpen AIのGPT-5のような大規模言語モデルが持つパラメータの数は、数千億から兆の単位に達すると言われています。これは、私たちの銀河系に存在する星の数にも匹敵するスケールです。
この天文学的な数のパラメータを、人間が手動で調整することは絶対に不可能です。だからこそ、損失という名のたった一つの指標を頼りに、勾配降下法という効率的なアルゴリズムを用いて、自律的にパラメータを調整していく「最適化」のプロセスが、AIの学習において絶対不可欠なエンジンとなっているのです。
医療現場における最適化:トレードオフの海から最善手を探る
この最適化という強力なフレームワークは、まさに「アートとサイエンスの融合」と言われる医療、特にその「サイエンス」の側面を強力に下支えし、複雑な意思決定が求められる臨床現場でこそ、その真価を発揮します。医療とは、本質的にトレードオフ(trade-off)の連続だからです。効果と副作用、費用と便益、個人の利益と全体の効率。これらの相反する要素のバランスを取りながら、最善の解を見つけ出す営み、それこそが最適化に他なりません。
その典型例が、放射線治療計画です。これは、単一の目的を最大化するような単純な問題ではありません。
- 目的1: 腫瘍(標的)への照射線量を、根治に必要なレベルまで最大化する。
- 目的2: 周囲の正常組織や重要臓器(OARs: Organs at Risk)への被曝量を、許容線量以下に最小化する。
これらは完全に相反する目的であり、「あちらを立てればこちらが立たず」の関係にあります。このような、複数の相反する目的を同時に満たそうとする問題を「多目的最適化問題」と呼びます(Ehrgott et al., 2008)。
どの角度から(ビームの入射角)、どれほどの強度で(フルエンス)、何回に分けて(分割照射)ビームを照射するか。現代の強度変調放射線治療(IMRT)では、これらの変数の組み合わせは天文学的な数にのぼります。最適化アルゴリズムは、この広大な探索空間の中から、どちらの目的も「これ以上もう一方を犠牲にしなければ改善できない」ような、優れた妥協点の集合(専門的にはパレート最適フロンティア)を探索します。最終的に、その中から臨床医が患者の状態に応じて最も適切と判断する計画を選択することで、治療成績の向上と有害事象の低減という、二つの大きな目標の両立に貢献しているのです。
この最適化の思考フレームワークが活躍する領域は、枚挙にいとまがありません。
- 創薬・ドラッグデザイン: 数百万から数億にもおよぶ化合物ライブラリの中から、標的タンパク質への結合親和性を最大化し、同時に毒性や代謝安定性といった複数の指標を最適化するような分子構造を、計算化学シミュレーションを駆使して探索します。これは、新薬開発の時間とコストを劇的に削減する可能性を秘めています。
- 個別化医療・動的治療計画: 患者一人ひとりのゲノム情報や臨床データ、経時的な治療反応に基づき、治療効果を最大化する薬剤の組み合わせや投与量を、逐次的に最適化します。特に、がんや慢性疾患のように病状が変化し続ける状況で、その都度「次の一手」を最適化していくアプローチ(動的治療計画)は、強化学習などの技術と結びつき、注目を集めています。
- 病院経営・オペレーションズリサーチ: 限られたベッド数、スタッフ、手術室といった医療リソースの中で、患者の待ち時間を最小化し、医療サービスの質を最大化するような、手術スケジュールや看護師のシフトを計画します。これはオペレーションズ・リサーチ(OR)と呼ばれる数理最適化の一大分野であり、医療の質と効率をシステムレベルで向上させるために不可欠です。
これらすべてが、最適化の技術が中核を担う領域です。最適化とは、複雑で捉えどころのない現実の問題を、「目的・変数・制約」という数理モデルの言葉で構造化し、トレードオフの海の中から最も合理的な航路を見つけ出すための、強力な思考のフレームワークなのです。
AIの羅針盤、『損失関数』~予測と現実の距離を測る~
さて、至高のレシピを求める旅に出たものの、ただ闇雲にスパイスを混ぜるだけでは、いつまで経っても目的地には着けませんよね。何より重要なのは、「現在の味は、理想と比べてどれほど隔たりがあるのか?」を客観的に評価してくれる、信頼できる「味覚」、つまり評価の尺度です。この尺度があるからこそ、次にどちらの方向に進むべきか(スパイスを増やすべきか、減らすべきか)が分かります。
AIの学習において、この極めて重要な「評価の尺度」の役割を果たすのが損失関数(Loss Function)です。損失関数は、AIの学習プロセス全体をナビゲートする、いわば羅針盤のような存在です。
損失関数が担う、たった一つの重要な使命
AIの学習プロセスにおいて、損失関数が担う使命は、驚くほどシンプルでありながら、決定的に重要です。その使命とは、AIの現在の予測が「理想的な正解」からどれだけ乖離しているか、その「パフォーマンスの悪さ」を一つの数値で定量的に示すこと。これに尽きます。この数値は「損失(Loss)」や「誤差(Error)」「コスト(Cost)」などと呼ばれますが、本質は同じです。
これは、患者さんの状態を評価する臨床検査値に似ているかもしれません。例えば、血糖コントロールの状態を評価するために、私たちは「HbA1c」という指標を重視します。この数値が目標からどれだけ離れているかを見ることで、現在の治療がうまくいっているのか、それとも介入が必要なのかを客観的に判断しますよね。損失関数は、AIモデルにとっての「HbA1c」のようなもの。AIのパフォーマンスという複雑な概念を、誰もが評価できる単一の客観的な指標に落とし込んでくれるのです。
- 損失の値が大きい: AIモデルの「健康状態が悪い」というシグナルです。予測が正解から大きく外れており、治療(パラメータの調整)が急務であることを示します。
- 損失の値が小さい(ゼロに近い): AIモデルの「健康状態が良好」である証です。予測は正解に非常に近く、現在の状態が望ましいことを示しています。
AIの学習における至上命題は、この損失関数の値を最小化すること。何百万、何十億とある複雑なパラメータ調整の問題を、「この数値をひたすら小さくする」という、たった一つのシンプルな目標に変換する。この鮮やかな問題の単純化こそが、最適化の核心です。この明確な目標があるからこそ、AIは後述する勾配降下法という数学的な手続きに則って、広大なパラメータ空間を効率的に探索し、自らを改善していくことができるのです。

そして、どの「臨床検査値」を重視するかで患者さんの評価が変わるように、どの損失関数を選ぶかはAIの性格や性能を決定づける上で極めて重要です。損失関数の設計は、単なる数式選びではなく、「どのような間違いを、より深刻な問題と見なすか」という、開発者の価値判断やドメイン知識をAIに埋め込む行為に他なりません(Wang et al., 2021)。ここでは、医療AIで頻繁に登場する代表的な2つのタイプを見ていきましょう。
ケース1:数値を予測する「回帰問題」の損失関数
平均二乗誤差 (Mean Squared Error, MSE) は、連続的な数値を予測する「回帰問題」で最も広く使われる損失関数です。
例えば、患者さんの年齢、体重、HbA1cなどの臨床データから、1年後の収縮期血圧を予測するAIモデルを考えてみましょう。AIが「135 mmHg」と予測したのに対し、実際の血圧が「140 mmHg」だった場合、そのズレ(誤差)は-5 mmHgです。MSEは、こうした誤差を評価するための指標です。
数式で表すと、以下のようになります。
\[ \text{MSE} = \dfrac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 \]
一見すると難しそうですが、一つずつ分解すれば、その構造は非常にシンプルです。
- \( n \):データに含まれる患者さんの総数です。
- \( y_i \):\(i\)番目の患者さんにおける実際の収縮期血圧(正解データ)です。
- \( \hat{y}_i \)(ワイハットと読みます):AIが予測した\(i\)番目の患者さんの収縮期血圧です。
- \( (y_i – \hat{y}_i) \):予測と正解の「差」、つまり誤差(Residual)です。
- \( (\dots)^2 \):この誤差を2乗(二乗)します。これには2つの重要な意味があります。
- 符号の統一: 誤差がプラス(予測が小さすぎた)でもマイナス(予測が大きすぎた)でも、2乗することで必ず正の値になります。これにより、誤差が互いに打ち消し合うのを防ぎます。
- 大きな誤差へのペナルティ: 誤差を2乗することで、ズレが大きければ大きいほど、損失の値が指数関数的に増加します。例えば、誤差が2の場合は損失への寄与が4ですが、誤差が10の場合は100にもなります。これは「大きな外れは、小さな外れよりも遥かに問題である」という考え方を反映しており、モデルが極端に誤った予測をしないように導く効果があります。
- \( \sum_{i=1}^{n} \):全ての患者さん(1番目からn番目まで)について計算した「誤差の2乗」を、すべて足し合わせます(総和)。
- \( \dfrac{1}{n} \):最後に患者さんの総数で割り、一人当たりの「誤差の2乗」の平均値を算出します。
要するに、MSEは文字通り「誤差(Error)を二乗(Squared)した値の平均(Mean)」を計算しているのです。この値が小さくなるようにAIのパラメータを調整していくことで、予測精度は着実に向上していきます。
ケース2:カテゴリを予測する「分類問題」の損失関数
次に、胸部X線画像から「肺炎である」「肺炎でない」といったカテゴリを予測する「分類問題」を考えてみましょう。この場合、MSEはあまり適していません。なぜなら、分類問題で私たちが知りたいのは、単なる誤差ではなく、「AIがどれだけ自信を持って正解を言い当てているか」だからです。
ここで登場するのが、交差エントロピー誤差 (Cross-Entropy Error) です。これは、情報理論にルーツを持つ考え方で、AIが算出した「確率」と「正解」がどれだけ”食い違っているか”を測る指標です。
AIは、画像を入力すると「肺炎である確率: 85%、肺炎でない確率: 15%」のように、各カテゴリに属する確率を出力します。交差エントロピーは、この確率分布と、正解(例:実際は肺炎だったので、「肺炎である確率: 100%、肺炎でない確率: 0%」)とを比較します。
- AIの予測が正解に近く、かつ自信満々の場合:
- 正解: 「肺炎」
- AI予測: 「肺炎の確率99%」
- → 予測と正解の”食い違い”は非常に小さい。したがって、交差エントロピー(損失)は非常に小さくなります。
- AIの予測が不正解で、かつ自信満々の場合:
- 正解: 「肺炎」
- AI予測: 「肺炎の確率1%」(つまり「肺炎でない確率99%」)
- → これは最悪のケースです。予測と正解の”食い違い”は極めて大きい。したがって、交差エントロピー(損失)は非常に大きくなります。
このように、交差エントロピーは「自信を持って間違える」ことに対して、MSEよりも遥かに大きなペナルティを与えます。これは、誤診が重大な結果を招きうる医療現場の感覚とも合致していると言えるでしょう。例えば、がんの診断支援AIが、悪性腫瘍を99%の確率で「良性」と判断した場合、その損失は極めて大きくなるべきです。交差エントロピーは、こうした要請に応える損失関数なのです。
下の表に、2つの代表的な損失関数の違いをまとめました。
| 特徴 | 平均二乗誤差 (MSE) | 交差エントロピー誤差 (Cross-Entropy) |
|---|---|---|
| 主な用途 | 回帰問題(数値の予測) | 分類問題(カテゴリの予測) |
| 医療での例 | 血糖値予測、血圧予測、入院日数予測 | 疾患の有無の判定、画像診断(良性/悪性)、予後予測(生存/死亡) |
| 評価するもの | 予測値と正解値の「距離」 | 予測確率分布と正解分布の「隔たり」 |
| 重要な考え方 | 誤差が大きいほどペナルティを大きくする(特に外れ値に敏感) | 「自信を持って間違える」ことに非常に大きなペナルティを与える |
このように、解きたいタスクの性質を正しく理解し、それに合った損失関数(羅針盤)を選ぶことが、AI開発の成功に向けた極めて重要な第一歩となるのです。
傾斜を下り、答えを見出す『勾配降下法』
損失関数という、AIが進むべき目的地(損失の最小値)と現在地からの距離を示す、極めて精巧な「地形図」を手に入れました。しかし、この地図だけでは不十分です。次に問われるのは、「どのようにして、この広大で複雑な地形の中から、最も低い谷底へと効率的にたどり着くか?」という具体的な航海術、すなわちアルゴリズムです。
ここで登場するのが、最適化における最も基本的かつ強力なアルゴリズム、勾配降下法(Gradient Descent)です。AIの学習を支える、まさにエンジンとも呼べる存在です。
霧の中の山下り – 勾配降下法の核心的アイデア
あなたが深い霧に包まれた広大な山中にいて、最も低い谷底へ下りることを目指している、と想像してみてください。視界は極めて悪く、全体の地形を把握することはできません。しかし、幸いにも自身の足元、半径数メートルの傾斜だけは確認できます。このような状況で、最も合理的な行動は何でしょうか?
おそらく、こう考えるはずです。
「今いる場所で、地面が最も急に下っている方向はどちらか?」
そして、その最も傾斜が急な方向を見定め、そちらへ向かって慎重に一歩を踏み出す。移動した先で、再び同じ問いを繰り返し、また一歩…。この局所的な情報(足元の傾斜)だけを頼りに、最も効率的な下り方向へと進むプロセスを繰り返すことで、最終的には谷底へとたどり着けるはずです。
勾配降下法が実行しているのは、まさにこの「霧の中の山下り」という、極めて合理的で直感的な思考プロセスそのものです。AIは、このプロセスを人間には到底不可能な速度と精度で、数学的に実行していきます。そのステップを分解してみてみましょう。
- Step 1: 現在地の「傾斜」を正確に知る(勾配の計算)
まず、損失関数という広大な「地形図」の上で、AIは自身の現在地(現在のパラメータ \( \theta \) の値)を確認します。そして、その地点における勾配(gradient)を計算します。勾配とは、その地点における「坂の傾きが最も急になる方向と、その傾きの大きさ」を示す情報が詰まったベクトル(矢印)です。重要なのは、この勾配が指し示す方向は、慣例的に「最も急な上り坂」の方向であるという点です。数学的には、これは損失関数 \(L\) を各パラメータ(\(\theta_1, \theta_2, \dots\))で一つずつ偏微分することで求められます。偏微分とは、たくさんの変数がある関数について、「ある一つの変数だけを動かしたら、関数の値がどれだけ変化するか」を調べる操作です。これを全パラメータについて行うことで、全体として最も損失が増える方向がわかるのです。 - Step 2: 最も賢い「次の一歩」を踏み出す(パラメータの更新)
我々が目指すのは谷底、つまり下り方向です。「最も急な上り坂」の方向(勾配ベクトル)がわかったのですから、最も賢い下り方はその真逆の方向へ進むことですよね。そこでAIは、計算した勾配ベクトルが指し示す方向とは逆向きに、自身のパラメータをほんのわずかに更新します。この「ほんのわずか」という歩幅を決めるのが、前述した学習率 \( \eta \) です。 - Step 3: 到達した場所で、再びプロセスを繰り返す(反復)
一歩進んだ新しい地点で、AIは再びStep 1に戻ります。その場所での新たな勾配を計算し、またその逆方向へ学習率の分だけ進む。この地道なステップを何千回、何百万回、時には何億回と反復することで、損失関数の値を少しずつ、しかし着実に減少させていきます。この一歩一歩の積み重ねこそが、AIの「学習」と呼ばれるプロセスの正体であり、やがては損失が最小となる地点(またはそれに極めて近い性能の良い地点)へと収束させていくのです。
この反復的な改善のプロセスは、私たちが新しい手技を学ぶ過程にも似ています。最初はおぼつかない手つきでも、指導医からのフィードバック(損失)を受け、どこをどう直せばよいか(勾配)を考え、少しずつフォームを修正(パラメータ更新)していく。この繰り返しによって、徐々に洗練された手技が身についていくのです。
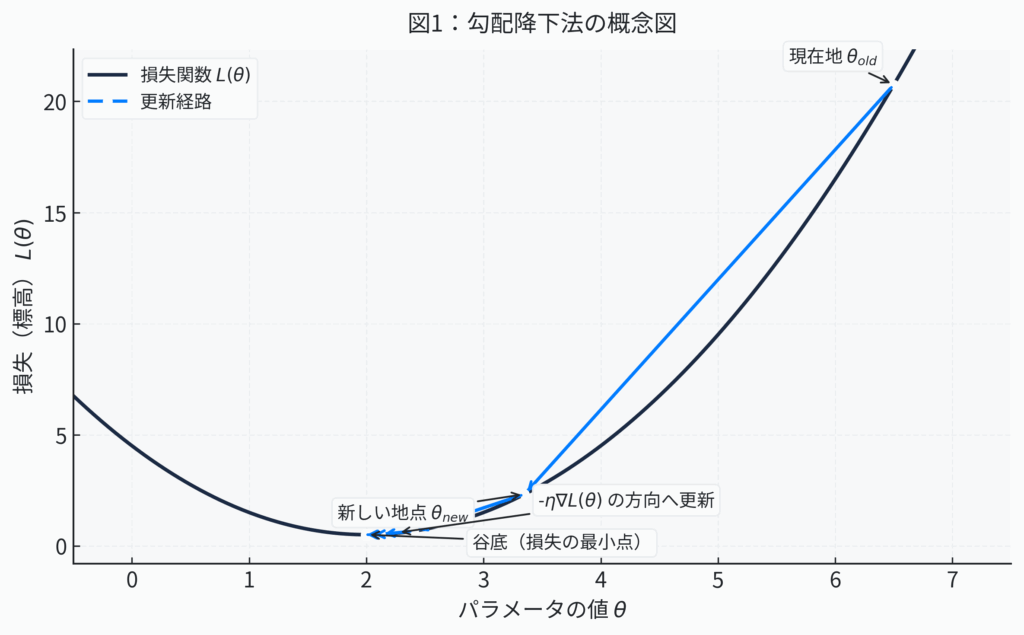
図1:勾配降下法の概念図。各地点で勾配(最も急な上り坂)を計算し、その逆方向へパラメータを更新していくことで、損失という名の谷底を目指します。一歩の大きさが学習率ηによって決まります。
パラメータ更新の数式を読み解く
このプロセスは、以下の非常にエレガントな数式で表現されます。
\[ \theta_{new} = \theta_{old} – \eta \nabla L(\theta_{old}) \]
この式はAIの学習の心臓部です。各項の意味をじっくり見ていきましょう。
- \( \theta_{old} \) と \( \theta_{new} \):それぞれ、更新前と更新後のAIモデルのパラメータです。パラメータは、AIの「知識」や「判断基準」を数値化したものであり、深層学習モデルではこれが数百万から数千億個にも及ぶベクトルとなります。この\( \theta \)を調整することこそが「学習」です。
- \( L(\theta_{old}) \):現在のパラメータ \( \theta_{old} \) における損失関数の値です。この値を最小化することが目標です。
- \( \nabla L(\theta_{old}) \):これが勾配(Gradient)です。記号 \( \nabla \)(ナブラ)は、勾配を計算することを示す演算子です。具体的には、損失関数 \( L \) を各パラメータ(\( \theta_1, \theta_2, \dots \))で偏微分したものを並べたベクトル(\( (\frac{\partial L}{\partial \theta_1}, \frac{\partial L}{\partial \theta_2}, \dots) \))です。このベクトルが指し示す方向は、「損失Lが最も急激に増加する方向」を意味します。
- \( \eta \)(イータ):学習率(Learning Rate)と呼ばれる、非常に重要なハイパーパラメータ(人間が設定する値)です。これは、山を下る際の「一歩の大きさ(ストライド)」を決定します。
- 学習率が大きすぎる場合: 一歩が大きすぎて、谷底を飛び越えて反対側の斜面に移動してしまい、かえって損失が増加することがあります。これを繰り返すと、学習は安定せず発散してしまいます(オーバーシューティング)。
- 学習率が小さすぎる場合: 一歩が小さすぎて、谷底にたどり着くまでに膨大な時間がかかってしまいます。また、後述する浅い谷(局所最適解)から抜け出しにくくなるという問題も生じます。
- \( – \)(マイナス記号):これが最も重要な点です。勾配 \( \nabla L \) が「最も急な上り坂」の方向を指すため、その逆方向、つまり「最も急な下り坂」へ進むために、マイナスを付けているのです。
より洗練された航海術へ – 勾配降下法の発展
この基本的な勾配降下法(バニラ勾配降下法とも呼ばれます)は強力ですが、いくつかの課題も抱えています。複雑な損失関数の地形では、この単純な下り方だけではうまくいかないことがあるのです。
- 局所最適解 (Local Minima) の問題: 本当の谷底(大域的最適解)よりも浅い、途中の窪み(局所最適解)にはまってしまい、そこから抜け出せなくなることがあります。
- 鞍点 (Saddle Point) の問題: ある方向から見ると谷底なのに、別の方向から見ると山頂になっているような「鞍(くら)」のような地点で、勾配がほぼゼロになってしまい、学習が停滞してしまうことがあります。高次元空間では、局所最適解よりもこの鞍点の方が遥かに多く存在し、学習を停滞させる主要な原因であると指摘されています(Dauphin et al., 2014)。
- 非効率な経路: 損失関数の谷が細長く伸びているような地形(病的な曲率を持つ地形)では、ジグザグと非効率な経路を辿ってしまい、収束に時間がかかることがあります。
これらの課題を克服し、より速く、より賢く最適解にたどり着くために、様々な勾配降下法の発展形が考案されてきました。
| 手法 | アイデアの比喩 | 特徴 |
|---|---|---|
| モーメンタム (Momentum) | 坂道を転がるボール | 慣性(勢い)を利用します。過去に進んできた方向をある程度維持することで、小さな窪みを乗り越え、谷底へ向かう動きを加速させます。ジグザグな動きを抑制する効果もあります。 |
| AdaGrad | パラメータ毎のオーダーメイドシューズ | パラメータ毎に学習率を適応的に調整します。これまであまり更新されてこなかった(勾配が小さかった)パラメータは学習率を大きく、頻繁に更新されてきたパラメータは学習率を小さくします。 |
| RMSprop | AdaGradの改良版 | AdaGradの「学習が進むと学習率が小さくなりすぎて更新が止まってしまう」という欠点を、勾配の二乗の移動平均を用いることで改善した手法です。 |
| Adam (Adaptive Moment Estimation) | 慣性付きの高性能四輪駆動車 | 現在、深層学習で最も広く使われているデファクトスタンダードです。モーメンタム(慣性)とRMSprop(適応的な学習率)の両方のアイデアを融合させた、非常に強力で安定した手法です(Kingma and Ba, 2014)。 |
これらの洗練されたアルゴリズムは、AIが複雑で高次元な損失関数の地形を効率的に探索し、より良い解を発見するための強力なツールキットとなっています。どの航海術を選択するかが、学習の速度と最終的なモデルの性能を大きく左右するのです。
解の唯一性を保証する羅針盤、『凸最適化』
これまでの航海、つまり勾配降下法による最適化の探求には、常に「遭難」のリスクが伴いました。霧深い山中で、本当の谷底だと思ってたどり着いた場所が、実はただの小さな窪み(局所最適解)で、その先にもっと深い谷(大域的最適解)が広がっていた、というケースです。一度この窪みにはまってしまうと、勾配がゼロに近くなり、そこから抜け出すのは極めて困難になります。
これは、最適化の探求における非常に悩ましく、深刻な課題です。AIモデルの性能が、パラメータの初期値という「出発点」の運次第で大きく変わってしまう可能性があることを意味するからです。これでは、安定した性能を持つ信頼性の高い医療AIを開発することはできません。
もし、地形が「迷いようのない」形だったら?
しかし、もし我々が探索する地形が、途中に紛らわしい窪みが一切存在しない、どこまでも滑らかな、きれいな「お椀」のような形状をしていたら、どうなるでしょうか?
その場合、どこから探索を開始したとしても、ただ傾斜を下っていけば、必ず唯一の最深部に到達できます。どのルートを辿っても、最終目的地は同じ。もはや「道に迷う」という概念自体が存在しません。
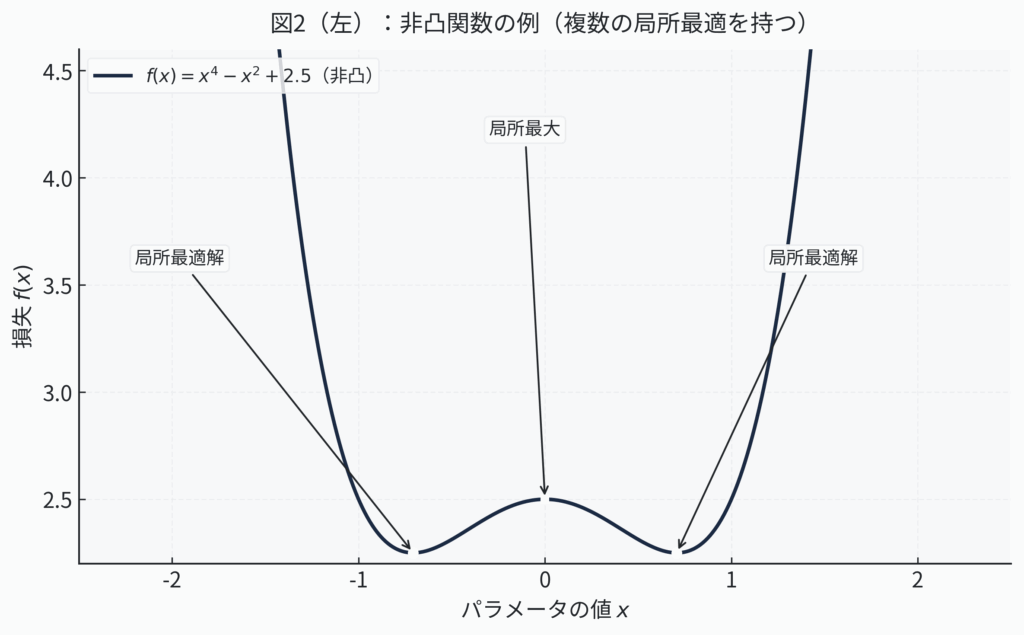

図2:非凸関数と凸関数の比較。凸関数においては、発見された最小解が全体の最小解であることが数学的に保証されます。
このような、嬉しい性質を持つ「お椀型」(あるいはその上下を反転させたドーム型)の関数を凸関数(Convex Function)と呼びます。そして、この凸関数で表される損失関数を最小化する問題を、凸最適化(Convex Optimization)と称します。
数学的には、この「お椀型」の性質は、「グラフ上の任意の2点を結んだ直線が、常にグラフそのものより上側(または線上)にある」という性質として厳密に定義されます。この性質こそが、局所最適解が存在しないことを保証してくれるのです。
なぜ「凸」であることは、それほど重要なのか?
凸最適化がもたらす最大の恩恵は、「発見された局所最適解は、必ず大域的最適解である」という、数学的に強固な保証が得られる点にあります。
これは、臨床研究や診断支援システムの開発において、計り知れない価値を持ちます。なぜなら、誰が、いつ、どのようなコンピュータで計算しても、同じデータとモデルを使えば、常に同じ「ベストな答え」にたどり着けるという再現性と安定性が保証されるからです。予測結果が計算のたびに変わるような不安定なモデルでは、安心して臨床応用することはできませんよね。
凸最適化で解ける、身近な機械学習モデル
実は、古典的でありながら今なお広く使われている機械学習アルゴリズムの多くが、この凸最適化の恩恵を受けています。
- ロジスティック回帰: 患者さんの検査値や生活習慣データから、ある疾患の罹患確率を予測する際、そのモデルの損失関数(対数尤度関数の符号反転)は凸関数です。そのため、学習によって得られる各因子の重み(パラメータ)は、常に唯一の最適解となります。
- サポートベクターマシン (SVM): 例えば、特定のがん細胞の画像を正常細胞と最も明確に分離する境界線(決定境界)を見つける問題も、凸最適化問題の一種である二次計画問題として解かれます。
これらのモデルが、比較的少ないデータでも安定した性能を発揮し、結果の解釈もしやすいのは、その数学的基盤に凸最適化という揺るぎない保証があるからなのです。
深層学習とのトレードオフ:保証を捨てて、表現力を得る
では、ここで一つの大きな疑問が浮かび上がります。「なぜ現代のAI、特に深層学習は、この強力な保証をあえて手放すのでしょうか?」
その答えは、その引き換えに得られる圧倒的な「表現力」にあります。深層学習で用いられるニューラルネットワークの損失関数は、通常、無数の山や谷、鞍点が存在する、極めて複雑で高次元な非凸(Non-convex)関数です。
この地形を最適化するのは、凸最適化に比べて遥かに困難です。最適解の保証はなく、学習率などのハイパーパラメータ設定や初期値に性能が大きく依存します。しかし、この地形の複雑さこそが、画像、言語、ゲノムといった、現実世界の複雑で多様なパターンを捉え、人間を超える精度を達成するための源泉となっているのです。
つまり、ここには明確なトレードオフが存在します。
- 凸最適化: 解の唯一性と安定性を保証するが、モデルの表現力には限界がある。
- 非凸最適化(深層学習など): 解の保証はないが、極めて高い表現力で複雑な課題を解くポテンシャルを秘めている。
この違いを理解することは、ある医療課題に対して、どのAIアプローチが最も適しているかを判断する上で、非常に重要な視点となります。
制約の中で最善を尽くす、『ラグランジュの未定乗数法』
我々の最適化を探求する航海も、いよいよ最終章です。これまでの議論では、広大な海原を何の制約もなく自由に探索し、最も低い谷底(損失の最小値)を目指してきました。しかし、現実世界の航海、とりわけ医療における意思決定は、常に「制約」という名の航路やルールに縛られています。
- 「この薬剤の1日の投与量は、安全性のため500mgを超えてはならない」(不等式制約)
- 「新しい治療法の導入に使える予算は、年間1,000万円きっかりである」(等式制約)
- 「手術室は1日に8時間しか稼働できない」(リソース制約)
こうした制約条件の下で、目標(治療効果や効率など)を最適化することこそ、我々が臨床現場で日々直面している真の課題です。このような「制約付き最適化問題」を解くための、極めて強力かつエレガントな数学的フレームワークが、ラグランジュの未定乗数法(Lagrange Multiplier)です。
制約の中で最善を尽くす、エレガントな数学的フレームワーク
現実世界の問題は、常に「予算は1,000万円」「投与量は500mgまで」といった制約に縛られます。このような「制約付き最適化問題」を解くための強力な道具が、ラグランジュの未定乗数法です。その核心は、驚くほど直感的な幾何学のアイデアにあります。
下の図解は、「周長が20の長方形の面積を最大化する」問題です。白い線 (2x + 2y = 20) が動ける範囲の制約です。背景の等高線は、面積 (f(x,y)=xy) を表します。
白い線上の点をドラッグして、面積が最大になる場所を探ってみましょう。
この「勾配ベクトルが平行になる」という幾何学的な条件 ∇f = λ∇g と、制約条件 g(x,y)=c を同時に解くために、ラグランジュ関数という巧妙な道具が作られました。
ラグランジュ関数は、「ご褒美」と「ペナルティ」を天秤にかけるバランサーとして機能します。
ご褒美
審判
反則点
この新しい関数 L を、あたかも制約がないかのように x, y, λ の3変数で最適化します。 すると、ご褒美 f を最大化しつつ、反則点 g-c をゼロにする「完璧なバランス点」が自動的に見つかります。 これにより、「制約付き」問題が「制約なし」問題へと見事に変換されるのです。
核心的アイデア:等高線が「接する」瞬間を探せ 🗺️
ラグランジュの未定乗数法は、一見すると非常に抽象的な数学の道具に思えるかもしれません。しかし、その核心にあるアイデアは、地図の等高線を読み解くような、驚くほど幾何学的で直感的なものです。
再び、簡単な例でこの手法の本質に迫りましょう。あなたは「長さが20mと決まっているロープを使い、可能な限り広い面積の長方形の土地を囲む」という、古典的ですが美しい課題に取り組んでいるとします。
- 最大化したい目標: 土地の面積 \(f(x, y) = xy\)。ここで \(x\) と \(y\) は長方形の縦と横の長さです。
- 守らなければならない制約: ロープの長さ(周長)が常に20mであること。数式で表すと \(g(x, y) = 2x + 2y = 20\) となります。
この問題を、\(x\)軸と\(y\)軸を持つ地図の上で可視化してみましょう。
- 目標は「より高い等高線」へ: 目標関数 \(f(x,y) = xy\) は、面積が同じになる地点 (\(x, y\) の組み合わせ) を結んだ「等高線」として描くことができます。例えば、面積が10になる等高線 (\(xy=10\))、面積が15になる等高線 (\(xy=15\))…というように、無数の双曲線が描かれます。私たちの目標は、この面積の値、つまり等高線の「標高」をできるだけ高くすることです。
- 移動は「決められた道の上」だけ: 一方で、制約条件 \(g(x,y) = 2x + 2y = 20\) は、私たちが移動できる範囲を限定する「一本の道」(この場合は直線)を地図上に描きます。私たちは、この道から一歩も外れることはできません。
さあ、あなたはこの「道」の上だけを歩きながら、到達可能な最も「標高の高い」等高線を探します。その最適解は、一体どこにあるでしょうか?

少し考えれば、その地点は、道(制約線)と等高線が、ちょうど「接する」唯一の点であることがわかるはずです。なぜなら、もし道と等高線が2点で交差している場合、その2点の間には、さらに標高の高い別の等高線に到達できる「道」が残されているからです。道に沿って進むことでまだ標高を上げられるうちは、そこは頂上(最大値)ではありません。これ以上進んでも標高が下がるだけ、という点、すなわち「接点」こそが求めるべき最適解なのです。
そして、幾何学的に、二つの曲線(上記の例では直線)が滑らかに「接する」点では、それぞれの曲線に対する勾配ベクトル(gradient vector)が、互いに平行になるという極めて重要な性質があります。勾配ベクトルは、その地点で最も急な上り坂の方向を示す矢印、つまり等高線に対して常に直角な方向を向いています。道と等高線が接する点では、この2つの「最も急な上り坂」の方向が、偶然にも同じ(または真逆の)方向を向くのです。
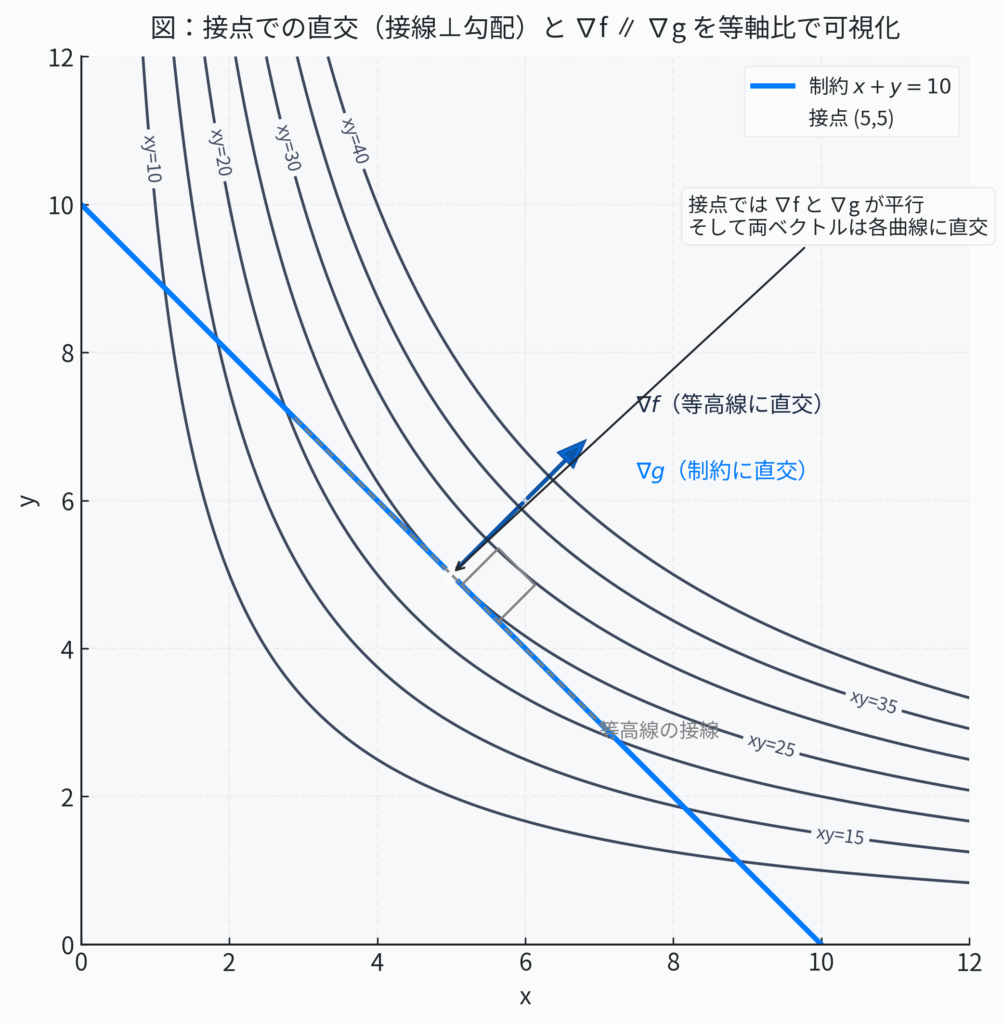
この「勾配ベクトルが平行である」という幾何学的な事実を、数式でエレガントに表現したものが、以下の式です。
\[ \nabla f(x, y) = \lambda \nabla g(x, y) \]
ここで、
- \(\nabla f\) は目標関数 \(f\) の勾配ベクトル(面積を最も効率的に増やす方向)。
- \(\nabla g\) は制約関数 \(g\) の勾配ベクトル(道に対して垂直な方向)。
- そして \(\lambda\)(ラムダ)は、二つの勾配ベクトルの向きが同じ(または真逆)で平行関係にあることを示すための、単なる比例定数(スカラー)です。ベクトルの長さは一般に異なるため、その長さを調整する役割を果たします。
この、計算を助けるためだけに導入されたように見える不思議な定数 \(\lambda\)、これこそがラグランジュ乗数なのです。この一つの式が、「制約付き最適化問題の解は、目的関数と制約関数の等高線が接する点にあり、その点では両者の勾配ベクトルが平行になる」という、美しい幾何学的洞察を凝縮しているのです。
ラグランジュ関数という名の統合ツール 🔧
さて、我々は今、「制約付き最適化の解は、目的関数と制約関数の等高線が接する点にあり、そこでは両者の勾配ベクトルが平行になる (\(\nabla f = \lambda \nabla g\))」という、美しい幾何学的な洞察を得ました。これは素晴らしい発見です。しかし、実際に問題を解こうとすると、少し困ったことになります。
というのも、私たちは今、
- 勾配が平行になる、という条件 (\(\nabla f = \lambda \nabla g\))
- そもそも道の上にいなければならない、という条件 (\(g(x,y) = c\))
という、性質の異なる2つの条件を同時に満たす点を探さなければなりません。これは、まるで2つの異なるパズルを同時に解こうとするようなもので、少し厄介ですよね。
ここからが、ラグランジュの未定乗数法の真に ingenious(巧妙)な点です。この手法は、これら2つのバラバラな条件を、たった一つの関数に統合し、しかもそれを機械的に解けるようにしたのです。
そのための鍵となる道具が、ラグランジュ関数 \(\mathcal{L}\) という、この問題のためだけに特別に仕立てられた関数です。その姿を見てみましょう。
\[ \mathcal{L}(x, y, \lambda) = f(x, y) – \lambda(g(x, y) – c) \]
この式を、単なる数式の羅列ではなく、「目標」と「ペナルティ」を天秤にかけるバランサーとして読み解いてみましょう。
- \(f(x, y)\) : メインの目標(ご褒美)
これは我々が最大化(または最小化)したい、本来の目的です。土地の面積を最大にしたい、治療効果を最大にしたい、といった「ご褒美」にあたる部分です。この値は、大きければ大きいほど嬉しいわけです。 - \((g(x, y) – c)\) : ルール違反の度合い
これは、元の制約条件 \(g(x,y)=c\) を移項して「= 0」の形にしたものです。これは、現在地 (\(x,y\)) が制約という名の「道」からどれだけ外れているかを示す「反則点」と考えることができます。もしちゃんと道の上にいれば、\(g(x,y) = c\) なので、この項はゼロになります(反則点ゼロ!)。もし道から外れていれば、ゼロ以外の値(プラスかマイナス)を取ります(反則!)。 - \(\lambda\) : ペナルティの厳しさを決める”審判”
そして、新しく登場したラグランジュ乗数 \(\lambda\) は、この「反則」に対してどれくらいの「ペナルティ」を課すかを決める、一種の”審判”の役割を果たします。この \(\lambda\) の値が大きければ大きいほど、少しのルール違反にも厳しいペナルティが課せられることになります。
つまり、ラグランジュ関数は「本来得たいご褒美 \(f\) から、(反則点 \((g-c)\) × 審判の厳しさ \(\lambda\))というペナルティを差し引いたもの」と解釈できるのです。この新しい関数 \(\mathcal{L}\) を最大化しようとすれば、AIや計算機は、ご褒美 \(f\) を大きくしつつ、同時にペナルティを受けないように \((g-c)\) をゼロに近づけようと、自動的にバランスを取ってくれるのです。
こうして、元の複雑な「制約付き」の問題が、この新しい関数 \(\mathcal{L}\) の「制約なし」の最適化問題へと見事に姿を変えるのです。
「制約なし」で解ける仕組み:三方よしの”完璧なバランス点”を探すゲーム
さて、ここからがラグランジュの未定乗数法が「巧妙だ」と言われる理由、その核心部分です。先ほど私たちは、ご褒美(目的)とペナルティ(制約)を組み合わせた、ラグランジュ関数 \(\mathcal{L}\) という特別な関数を作りましたね。
\[ \mathcal{L}(x, y, \lambda) = \underbrace{f(x, y)}_{\text{ご褒美}} – \lambda \underbrace{(g(x, y) – c)}_{\text{反則点}} \]
この手法のすごいところは、この \(\mathcal{L}\) を、あたかも何の制約もない、ただの関数として扱ってしまう点にあります。そして、この関数の「これ以上良くも悪くもならない安定した点」、つまり停留点を探すのです。なぜなら、そこではどの方向に少し動かしても、もうスコア \(\mathcal{L}\) が上がりも下がりもしない——つまり「ベストバランス」が実現しているからです。最適化の問題では、まさにこの“動かしても変わらない点”こそがゴールになります。
停留点とは、グラフで言えば、坂道の途中ではなく、山頂や谷底、あるいは峠の鞍部のような「平坦な場所」のことです。数学の世界では、ある関数が平坦になる場所を探すための鉄板の方法があります。それが、その関数を「各変数で偏微分して、イコールゼロと置く」という操作なのです。偏微分とは、各変数の方向に「ほんの少しだけ動かしたら、どちらに傾くか」を調べる操作です。もしどの方向に動かしても傾かない、つまり変化率がゼロなら、そこはまさに“坂が終わる”=停留点というわけです。
今、私たちの手元にある変数は、元の \(x, y\) だけでなく、私たちが新たに連れてきた「審判役」の \(\lambda\) も含まれています。この \(x, y, \lambda\) の3つの変数すべてにとって「三方よし」となる、完璧なバランス点を探すのが、ここでのゴールです。言わば、「\(x, y, \lambda\) の誰もが、もうこれ以上動きたくない!と満足する一点」を見つけ出すゲームだと考えてみてください。
プレイヤー1&2(\(x, y\))の視点:「ご褒美」と「ペナルティ」の甘い点を探す
ラグランジュ関数 \(\mathcal{L}\) を \(x\) と \(y\) でそれぞれ偏微分して、その値をゼロにするという操作。数式で書くとこうなりますね。
\[ \frac{\partial \mathcal{L}}{\partial x} = 0 \quad \text{と} \quad \frac{\partial \mathcal{L}}{\partial y} = 0 \]
この数学的な操作が、一体何を意味しているのか。こんなイメージで考えてみましょう。
あなたは今、広大な庭に立っています。庭のどこか一点に、あなたの大好物(ご褒美 \(f\))が置いてあります。もちろん、あなたはそのご褒美に一直線に向かいたい。この「ご褒美に向かう力」の方向と強さを示すのが、ご褒美の関数の勾配 \(\nabla f\) です。
しかし、残念なことに、あなたの体は一本の杭につながれたロープ(制約 \(g\))で繋がれています。あなたはそのロープが張る円周の上しか動けません。
さあ、あなたはこのロープに繋がれたまま、どうにかしてご褒美に一番近づける場所を探します。その「ベストポジション」はどこでしょうか?
あなたがそのベストポジションに立ったとき、あなたの体には2つの力が働いています。
- ご褒美があなたを引く力 (\(\nabla f\)):常に「ご褒美のある方向」を向いています。
- ロープがあなたを引き戻す力 (\(-\lambda \nabla g\)):常に「ロープがピンと張る方向」、つまり円周の接線に対して垂直な方向(中心とは逆の方向)を向いています。
もし、あなたがまだベストポジションにいなければ、ご褒美を求める力の一部を使って、ロープの円周に沿って少しでもご褒美に近づく方向に移動できるはずです。しかし、あなたがとうとうベストポジションに到達した瞬間、この2つの力は完全に一直線上で綱引きをしている状態になります。ご褒美の方向を向く力と、ロープが引き戻す力が、ちょうど真逆の方向を向き、ピタッと釣り合って動けなくなるのです。
この「力が釣り合って動けない」状態こそが、\(\mathcal{L}\) という(ご褒美-ペナルティ)関数が平坦になる場所、つまり偏微分がゼロになる点なのです。
この操作は、ゲームのプレイヤーである \(x\) と \(y\) の立場から見ると、「審判(\(\lambda\))が持つロープの強さがもし今のままなら、どこが一番ご褒美に近づける場所だろう?」と探す行為そのものです。
そして、この「綱引きが釣り合う」という物理的なイメージを数式に翻訳したものが、何を隠そう、先ほど地図の上で確認した「等高線が接する点での条件(\(\nabla f = \lambda \nabla g\))」と寸分違わず一致するのです!
つまり、「\(\mathcal{L}\) を \(x, y\) で偏微分してゼロと置く」という一見無味乾燥な計算は、実は「制約下で目的を最大化する点では、目的へ向かう力と制約による力が釣り合うはずだ」という、非常に直感的で物理的な原理を解いているのです。これで、解が満たすべき一つ目の重要な条件 [最適性の条件] が、見事にクリアされるというわけです。面白いですよね!
プレイヤー3(審判 \(\lambda\))の視点:そもそも「ルールが守られているか」を強制する
ここがこの仕組みのハイライトです。なぜ、私たちが勝手に導入した「審判」である \(\lambda\) でまで偏微分する必要があるのでしょうか?
\[ \frac{\partial \mathcal{L}}{\partial \lambda} = 0 \]
これは、審判 \(\lambda\) の立場から見た、「場所 (\(x, y\)) がもし今のままなら、私の厳しさをどう変えてもスコア (\(\mathcal{L}\)) に影響が出ない、そんな都合のいい状況はないだろうか?」と探す行為です。
もう一度、ラグランジュ関数の式をじっと見てみましょう。
\[ \mathcal{L} = f(x, y) – \lambda (g(x, y) – c) \]
もし、ルール違反があったら、つまり \((g(x, y) – c)\) がゼロでない値(例えば反則点が 5)だったら、どうなるでしょう。このとき、\(\mathcal{L} = f(x, y) – 5\lambda\) となります。これでは、審判 \(\lambda\) が厳しさ(\(\lambda\) の値)を上げれば上げるほど、スコア \(\mathcal{L}\) はどんどん下がってしまいます。全く安定しません。
では、審判 \(\lambda\) がいくら厳しさを変えても、スコア \(\mathcal{L}\) がピクリとも動かなくなるのは、どんな奇跡的な状況でしょうか?
それは、\(\lambda\) が掛け算されている相手、つまり「反則点」の項 \((g(x, y) – c)\) が、そもそもゼロである場合しかありえません。反則点がゼロなら、審判 \(\lambda\) がどれだけ厳しくなろうと(\(\lambda\) がどんな値を取ろうと)、ペナルティ項 \(\lambda \times 0\) は常にゼロのまま。スコア \(\mathcal{L}\) は \(f(x, y)\) の値から全く動かなくなります。
つまり、「\(\mathcal{L}\) を \(\lambda\) で偏微分してゼロになる点を探す」という操作は、遠回しな言い方をしていますが、何のことはない、「ルール違反は絶対に許さない(\((g(x, y) – c) = 0\) でなければならない)」と強制するための、非常に巧妙な仕掛けなのです。これで、解が満たすべき二つ目の条件 [制約条件] も自動的にクリアされます。
Deep Dive! なぜ「\(\mathcal{L}\) を \(\lambda\) で偏微分してゼロにする」のか
ここがラグランジュ法の肝です。 そもそも \(\lambda\) は「道から外れること(制約違反)」に対して課される ペナルティの重みを表しています。 ラグランジュ関数 \[ \mathcal{L}(x, y, \lambda) = f(x, y) – \lambda \bigl(g(x, y) – c\bigr) \] の中で、この第2項 \(-\lambda(g(x,y)-c)\) が“ルール違反への罰”を意味します。
もし、ある地点で \(g(x, y) – c \neq 0\) ならば、それは「道を外れている」ことを意味し、 ペナルティ項がスコア \(\mathcal{L}\) の値を減らします。 一方、もし \(g(x, y) – c = 0\) ならば、「ちょうど道の上」にいるので、ペナルティ項の影響はなくなります。
では、「その地点が本当に道の上にある」とは数学的にどう表現できるでしょうか? それがまさに、 \[ \frac{\partial \mathcal{L}}{\partial \lambda} = 0 \] という条件です。
\(\lambda\) で偏微分するというのは、 「ペナルティの強さをほんの少し変えても、スコア \(\mathcal{L}\) が変わらない」ことを確認する操作です。 もしまだ道を外れていれば、\(\lambda\) を少し変えるだけでスコアが動いてしまいます。 しかし、道の上に完全に戻っていれば、どんなに \(\lambda\) を変えてもスコアは変わりません。 この“変化しない状態”こそが、「もう反則点がゼロ=道の上にいる」という数学的な証拠です。
実際に偏微分すると: \[ \frac{\partial \mathcal{L}}{\partial \lambda} = – (g(x, y) – c) \] となり、これをゼロとおくことで \[ g(x, y) – c = 0 \] が自動的に復元されます。 つまり、「\(\mathcal{L}\) を \(\lambda\) で偏微分してゼロにする」とは、 “ルールが完全に守られている状態”を条件として組み込むことにほかなりません。
したがって、ラグランジュ法では
- \(x, y\) に関する偏微分:どの点が最も高いかを決める(最適化)
- \(\lambda\) に関する偏微分:その点がルールを守っていることを確認する(制約の遵守)
という二重のチェックを同時に行っているのです。
この両者がともに満たされたとき、はじめて 「ルールを破らず、これ以上登る余地のない、道の上の最高地点」―― すなわち制約付きの最適解に到達するのです。
これは本当にエレガントだと思いませんか? 私たちはただ、ご褒美とペナルティを組み合わせたラグランジュ関数という一つの統合された道具を用意し、それが全てのプレイヤー(\(x, y, \lambda\))に対して平坦になる「三方よし」の安定点を探しただけ。それだけで、元の問題が要求していた2つのバラバラな条件が、自動的に、そして同時に満たされる最適解が炙り出されるのです。
このように、ラグランジュの未定乗数法は、複雑な「制約付き」問題を、私たちがすでに解き方を知っている単純な「制約なし」問題へと見事に変換する、数学の美しさと力強さを体現した、まさに巧妙なツールなのです(Nocedal and Wright, 2006)。
医療におけるラグランジュ乗数 \(\lambda\) の真価:単なる計算道具から”意思決定の羅針盤”へ
ラグランジュの未定乗数法を学ぶ中で登場する \(\lambda\) は、一見すると、単に計算を成立させるためだけに導入された、少し謎めいた一時的な変数に見えるかもしれません。しかし、この \(\lambda\) こそが、制約付き最適化問題が単なる数学パズルに終わらず、現実世界の問題解決、特にリソースが限られる医療現場において非常に強力なツールとなる理由そのものなのです。
\(\lambda\) の正体、それはシャドウプライス(Shadow Price)、または潜在価格と呼ばれるものです。最適化された状態において、\(\lambda\) は「もし、ある制約をほんの少しだけ緩めることができたなら、目的とする値がどれだけ改善するか」という、制約の「限界的な価値」を具体的に示しています。
この性質があるからこそ、\(\lambda\) は、日々の臨床や病院経営における、こんな悩ましい「もしも」の問いに、データに基づいた答えを与えてくれるのです。
- 「もし、あと一人だけ看護師を増員できたら、病棟全体のオペレーション(例:患者の待ち時間短縮)はどれだけ改善するだろうか?」
- 「もし、この高価な新薬に使える予算がもう少しだけ増えたら、対象患者群のQOLスコアは平均してどれくらい上がるだろうか?」
\(\lambda\) は、これらの問いに対する感度(sensitivity)を、具体的な数値として示してくれる、まさに意思決定の羅針盤なのです。
なぜλは「制約の価値」を示すのか?
では、なぜこの不思議な変数 \(\lambda\) が、これほど深い意味を持つのでしょうか?その理由は、最適解が満たす「力の釣り合い」の条件に隠されています。
1. 「力の釣り合い」から考えるアナロジー ⚖️
最適化問題の解を見つけるプロセスを、物理的な力の釣り合いとしてイメージしてみましょう。
- 目的を達成したい力: あなたは、目的関数 \(f\) という名の「山」の、できるだけ高い場所へ登ろうとしています。その地点で最も急な上り坂の方向を示すのが、勾配ベクトル \(\nabla f\) です。これが「山を登ろうとする力」です。
- 制約が引き戻す力: しかし、あなたは \(g(x) = c\) という名の「フェンス」に沿ってしか動けません。このフェンスから離れようとすると、フェンスがあなたを垂直に押し返す力が働きます。この「フェンスが押し返す力」の方向が \(\nabla g\) です。
最適点、つまり、フェンスに沿って到達できる最も高い地点では、何が起きているでしょうか? その点では、これ以上フェンスに沿って動いても、高くはなれません。これは、「山を登ろうとする力」が、ちょうど「フェンスに押し返される力」と一直線上で釣り合っている状態を意味します。
この釣り合いの式が、最適解の条件でしたね。
\[ \nabla f = \lambda \nabla g \]
ここで \(\lambda\) は、二つの力の大きさを揃えるための「力の変換レート」、つまり釣り合いの強さそのものです。
さて、ここからが本題です。もし、誰かがこのフェンスを1メートルだけ外側に動かしてくれたら(制約 \(c\) を少しだけ緩めたら)、あなたはこの「山を登ろうとする力」に引かれて、どれだけ高く登れるでしょうか?
それは、まさにその瞬間の「力の釣り合いの強さ (\(\lambda\))」に依存します。
- もし \(\lambda\) が非常に大きければ: それは、あなたが非常に強い力で山を登ろうとしていたのを、フェンスが必死に押し返して釣り合っていたことを意味します。この状態でフェンスが少しでも緩めば、あなたは待ってましたとばかりに、その強い力で一気に高い場所へ移動できます。つまり、目的 \(f\) は大きく改善します。
- もし \(\lambda\) が非常に小さければ: それは、もともと弱い力でしか登ろうとしておらず、フェンスも軽く押し返すだけで釣り合っていた状態です。この状態でフェンスが少し緩んでも、あなたが登る力は弱いため、目的 \(f\) の改善はわずかです。
このように、\(\lambda\) は「その制約が、どれだけ強く目的達成の邪魔をしていたか(=どれだけ強く押し返していたか)」を示す指標なのです。だからこそ、「制約を少し緩めたら、目的がどれだけ改善するか」という、制約の限界的な価値(シャドウプライス)そのものになるのです。
2. 少しだけ数学の裏付け(包絡線定理のエッセンス)
この直感的な理解は、包絡線定理(Envelope Theorem)と呼ばれる経済学や最適化理論における美しい定理によって、数学的に裏付けられています。厳密な証明は省きますが、そのエッセンスはこうです。
ラグランジュ関数 \(\mathcal{L} = f(x) – \lambda(g(x) – c)\) を思い出してください。最適解では、この関数は \(x\) に関して平坦になっています(\(\frac{\partial \mathcal{L}}{\partial x} = 0\))。
ここで、制約 \(c\) が少しだけ \(c + \Delta c\) に変化したときの、目的関数 \(f\) の最適値の変化 \(\Delta f\) を考えてみましょう。最適点では、変数の値 \(x\) を少し動かしても、目的関数 \(f\) の値は(一次の近似では)ほとんど変化しません。なぜなら、その点はすでに山頂(または谷底)だからです。したがって、制約 \(c\) が変化したことによる \(f\) の変化は、間接的に \(x\) が動くことによる影響ではなく、ラグランジュ関数の中で \(c\) が直接含まれている項から主に生じると考えられます。
\(\mathcal{L}\) の式の中で \(c\) が直接含まれているのは、\( – \lambda(-c) = \lambda c \) の部分だけです。この項は、\(c\) が1単位増加すると、\(\mathcal{L}\) の値を \(\lambda\) だけ増加させます。そして、最適点では \(g(x) – c = 0\) なので、\(\mathcal{L} = f\) となっています。つまり、\(\mathcal{L}\) の変化は \(f\) の変化と等しくなります。
結論として、制約 \(c\) の微小な変化は、目的関数 \(f\) の値を \(\lambda\) 倍で変化させる、という関係が導かれます。これが、\(\lambda = \frac{df}{dc}\) となる理由の数学的なエッセンスです。
Case Study:病院経営における意思決定ツールとしての \(\lambda\)
ラグランジュ乗数 \(\lambda\) が単なる計算上の副産物ではないことを、より実践的なシナリオで考えてみましょう。あなたは、ある地域の中核病院の経営企画室にいるとします。今年の目標は、限られたリソースの中で、提供する医療の「価値」を最大化することです。
この「価値」を測る客観的な指標として、医療経済学で広く用いられるQALY(Quality-Adjusted Life Year: 質調整生存年)を使うことにしました。QALYは、生存年数にQOL(Quality of Life: 生活の質)の重みを掛け合わせた指標で、1 QALYは「完全に健康な状態で1年間生存すること」に相当します。病院全体の活動によって生み出される総QALYを最大化することが、今回の目的です。
しかし、病院には厳しい制約があります。
- 制約1(予算): 年間の総予算は \(c_{budget}\) 円まで。
- 制約2(人的資源): 専門看護師の総労働時間は、年間 \(c_{nurse}\) 時間まで。
この問題を最適化モデルとして定式化し、ラグランジュの未定乗数法を用いて解いたところ、以下の2つの \(\lambda\) が得られました。
- 予算制約に関するラグランジュ乗数: \(\lambda_{budget} = 0.0002\)
- 看護師の労働時間制約に関するラグランジュ乗数: \(\lambda_{nurse} = 0.01\)
さて、この2つの数字は何を意味するのでしょうか?これこそが、データに基づいた戦略的な意思決定を可能にするための羅針盤なのです。
\(\lambda\) の解釈:制約の「限界的な価値」を読み解く
これらの \(\lambda\) は、それぞれの制約が「1単位」緩和されたときに、目的である総QALYがどれだけ増加するかを示しています。
\(\lambda_{budget} = 0.0002\) の解釈:
もし年間予算を 1単位(例えば1円) 増やすことができれば、病院全体で生み出せる総QALYは 0.0002 QALY 増加する見込みがある。
\(\lambda_{nurse} = 0.01\) の解釈:
もし専門看護師の総労働時間を 1単位(1時間) 増やすことができれば、病院全体で生み出せる総QALYは 0.01 QALY 増加する見込みがある。
この時点でも、看護師の時間の価値が非常に高いことが伺えますが、単位が異なるため直接比較はできません。そこで、単位を「100万円」に揃えて比較してみましょう。仮に、専門看護師の追加雇用にかかる費用が時給5,000円だとすると、100万円の追加予算は200時間分の労働時間に相当します。
- 100万円の追加予算の効果: \(0.0002 \times 1,000,000 = 200\) QALY
- 100万円分の看護師増員(200時間)の効果: \(0.01 \times 200 = 2\) QALY
(※注:この数値は説明のための仮定です。実際には\(\lambda_{budget}\)の値はもっと小さくなります。)
おっと、この例では単純な追加予算の方が効果が大きいという結果になりました。しかし、もし看護師の \(\lambda\) がもっと大きければ、結論は逆転します。重要なのは、このように異なる種類の制約の価値を、QALYという共通の物差しで比較できる点です。
具体的なアクションへの展開:エビデンスに基づく戦略立案
この \(\lambda\) の値は、具体的な戦略的意思決定の強力な根拠となります。
- 投資対効果の評価とボトルネックの特定: 多くの国では、1 QALYを生み出すために支払ってもよいとされる金額の閾値(支払意思額)が議論されています(例えば、日本では暫定的に500万円/QALYなどが参考にされることがあります)。先ほどの例で、100万円の追加投資で200 QALYも得られるなら、これは極めて効率的な投資です。逆に、\(\lambda\) の値が非常に小さい制約は、すでにリソースが飽和しており、そこに追加投資しても効果が薄いことを示唆します。複数の \(\lambda\) を比較することで、「今、我々の病院のパフォーマンスを最も縛っているボトルネックは何か?」を特定できます。実際に、手術室のスケジューリングを最適化した米国の研究では、シャドウプライス(ラグランジュ乗数)を計算することで、最も逼迫しているリソースが麻酔科医の時間であることを特定し、そのリソースの限界的な価値を評価しています(Styrt et al., 2021)。
- 交渉と説明責任: 病院の理事会や地域の行政に対して、追加予算や人員配置を要求する際、「なぜそれが必要なのか」を客観的なデータで示すことができます。「もし専門看護師をあと2名増員できれば、年間でこれだけのQALY向上が見込まれます。これは、我々の地域における医療価値の向上に直接的に貢献します」といった具体的な説明が可能となり、説明責任を果たすことにも繋がります。
- 新しい医療技術・治療法の導入評価: 例えば、導入に多額の初期費用がかかるものの、患者の入院期間を平均2日間短縮できる新しい手術ロボットを導入すべきか、という問題も評価できます。この場合、「短縮される2日分のベッド × ベッド数 × \(\lambda_{bed}\)(ベッドの空きに関するシャドウプライス)」が、導入コストを上回る価値を生むかどうか、という定量的な議論が可能になるのです。
このように、ラグランジュ乗数 \(\lambda\) は、単なる計算過程の産物ではありません。それは、オペレーションズ・リサーチ(OR)の分野で長年培われてきた、限られたリソースをいかに賢く配分するかという問題に対する、強力な分析ツールなのです。この概念を理解することは、感覚や経験だけでなく、データに基づいた合理的な意思決定を医療現場にもたらすための、重要な一歩となるでしょう。
医療AIと機械学習における \(\lambda\) の役割:性能と頑健性の”最適”なバランスを探る
このラグランジュ乗数 \(\lambda\) が持つ「トレードオフを調整する」という核心的な性質は、単なる経営課題の解決に留まりません。むしろ、現代の医療AIや機械学習モデルのアルゴリズムの根幹に深く組み込まれ、その性能と信頼性を支える重要な役割を担っています。
1. サポートベクターマシン(SVM):「マージンの最大化」 vs 「誤分類の最小化」
サポートベクターマシン(SVM)は、古典的でありながら非常に強力で、今なお診断支援などの研究で用いられる機械学習アルゴリズムです。例えば、乳がんの超音波画像から抽出された腫瘍の形状や大きさといった複数の特徴量に基づき、それが良性か悪性かを分類するモデルを構築する場面を考えてみましょう (Akay, 2009)。
このとき、SVMは2つの相反する目標を同時に達成しようとします。
- マージンを最大化したい(安全地帯を広く取りたい): 良性のデータ群と悪性のデータ群を分離する境界線(決定境界)と、その境界線に最も近いデータ点(サポートベクター)との距離をマージンと呼びます。このマージンをできるだけ広く取ることで、少し曖昧なデータや、将来出会うであろう未知の患者データ(新しい画像)に対しても、安定して正しい判断を下せる、頑健な(robust)モデルになります。
- 誤分類を最小化したい(訓練データでの間違いを減らしたい): 当然ながら、モデルを訓練しているデータセットにおいて、良性を悪性と判断したり、その逆だったりする間違い(誤分類)は、できるだけ少なくしたいと考えます。
ここに、深刻なトレードオフが生まれます。訓練データ内の全ての点を完璧に分類しようと躍起になるあまり、非常に複雑でいびつな境界線を引いてしまうと、マージンは極めて狭くなります。このようなモデルは、訓練データには完璧に適合していますが(過学習)、新しい患者のデータに対しては、ささいなノイズに過敏に反応してしまい、誤診を連発するかもしれません。
この究極のトレードオフを調整する役割を担うのが、実はラグランジュ乗数から発展したハイパーパラメータ \(C\)(コストパラメータ) です。これは、誤分類という「制約違反」に対するペナルティの大きさを決めるもので、ラグランジュ乗数 \(\lambda\) と数学的に密接な関係にあります。
- \(C\) が大きい場合(厳格な審判): 誤分類へのペナルティが非常に重くなります。モデルは一つでも間違いを犯すことを極端に嫌い、マージンという安全地帯を犠牲にしてでも、訓練データを完璧に分類しようとします。これは、過学習に陥りやすい、柔軟性のないモデルになるリスクを孕んでいます。
- \(C\) が小さい場合(寛容な審判): 誤分類へのペナルティが軽くなります。モデルはいくつかの訓練データ(おそらくノイズや例外的な症例)を「仕方ない間違い」として許容し、その代わりに、全体としてよりシンプルで広いマージンを持つ境界線を見つけることを優先します。これにより、未知のデータに対する汎化性能が高い、より実用的なモデルになる傾向があります。
このように、SVMにおけるハイパーパラメータ \(C\) の調整は、まさにラグランジュ乗数 \(\lambda\) の思想を通じて、モデルの性能という「目的」と、誤分類という「制約」の間の最適なバランス点を探る、極めて重要なプロセスなのです(Cristianini and Shawe-Taylor, 2000)。
2. 医療画像再構成:「データ忠実度」 vs 「ノイズ抑制」
CTやMRI、PETといった現代の医療画像診断装置は、検出器で測定された生の信号データから、私たちが目にするような断層像を数学的に作り出す画像再構成というプロセスに依存しています。このプロセスにおいても、最適化は中心的な役割を果たしており、そこには常にトレードオフが存在します。
- データ忠実度(Fidelity): 再構成された画像は、検出器で物理的に測定された元の信号データと、可能な限り数学的に一致していなければなりません。これが担保されないと、画像の信頼性が失われます。
- 画像の平滑性(Regularity)/ ノイズ抑制: 画像に含まれるランダムなノイズ(例えば、X線の光子数の統計的なばらつきに起因するノイズ)をできるだけ除去し、解剖学的構造が滑らかで解釈しやすい画像にしたい、という要請があります。
これもまた、あちらを立てればこちらが立たぬトレードオフです。元データに完璧に忠実であろうとすれば、信号だけでなくノイズまで忠実に再現してしまい、ザラザラした画質になります。逆に、ノイズを強力に消そうとすれば、本来のシャープな臓器の輪郭や、微細な病変までぼやかしてしまう危険があります。
特に、被ばく量を抑えるための低線量CTや、検査時間を短縮するための高速MRI(Compressed Sensing MRIなど)では、元データが不完全であるため、この問題はより深刻になります。こうした技術では、ラグランジュ関数と全く同じ構造を持つ目的関数を最小化することで、画像を再構成します。
\[ \text{目的関数} = \underbrace{\|Ax – y\|^2}_{\text{データ忠実度項}} + \lambda \times \underbrace{R(x)}_{\text{正則化項}} \]
ここで、\(x\) は再構成したい画像、\(y\) は測定データ、\(A\) は物理モデルです。そして \(\lambda\) が、まさにラグランジュ乗数と同じ役割を果たす正則化パラメータです。この \(\lambda\) の値を調整することで、メーカーの技術者や放射線科医は、診断目的に応じて最適なバランス点を選択します。
- \(\lambda\) が小さい場合: データ忠実度を最優先します。結果として得られる画像は、ノイズは多いものの、非常にシャープで、元データが持つ情報を最大限に保持しています。微細な構造の描出に適している可能性があります。
- \(\lambda\) が大きい場合: ノイズ抑制(正則化)を強く効かせます。画像は滑らかで見た目のノイズは減りますが、過度に平滑化され、細部の情報が失われるリスクがあります。
スタンフォード大学の研究チームが開発したCompressed Sensing MRIのような技術は、この最適化問題を解くことで、従来よりも遥かに少ないデータから診断価値の高い画像を再構成することを可能にしました (Lustig et al., 2007)。この技術の核心は、\(\lambda\) を用いてデータ忠実度と正則化のバランスを巧みに制御することにあるのです。
このように、ラグランジュ乗数 \(\lambda\) の思想は、単なる数学理論に留まらず、医療AIや画像診断装置の性能を根底から支える、極めて実践的な概念です。それは、複雑な現実の問題に潜むトレードオフの構造を解き明かし、限られた情報やリソースの下での最適な意思決定を支援するための、定量的で解釈可能な羅針盤なのです。この深い意味を理解することは、数理最適化の力を医療という複雑な領域で真に活用するための鍵となります。
結論:AIの思考プロセスを理解する旅、その先へ
今回は、AIがいかにして「ベストな答え」を導き出すのか、その知的活動の根幹をなす「最適化」の世界を探求する、長い航海にお付き合いいただき、ありがとうございました。最後に、我々が手に入れた羅針盤と海図をもう一度振り返り、この旅が医療の未来にとって何を意味するのかを考えてみましょう。
我々が学んできたのは、単なる個別の技術ではありません。それは、AIが「思考」するための、一貫した論理体系です。
- 損失関数は、AIが目指すべきゴールと現在地の隔たりを示す「地形図」でした。しかしそれは同時に、「何を『良い』とするか」という価値観や哲学を、数学の言葉でAIに与える設計図でもあります。例えば、診断精度だけでなく、偽陰性を出した際のペナルティを重く設計すれば、見逃しを極端に嫌う、慎重なAIを育てることができます。
- 勾配降下法は、その地形図を頼りに谷底を目指すための「探索アルゴリズム」でした。これは、局所的な情報だけを頼りに、一歩ずつ着実に改善を重ねていくという、謙虚で力強い反復プロセスです。完全な知識がなくとも、手元の情報から最善手を探し続けるこの姿勢は、不確実な情報の中で意思決定を行う我々の臨床判断プロセスにも通じるものがあります。
- 凸最適化は、解の唯一性が保証された「理想的な問題設定」でした。これは、再現性と安定性という、科学的信頼性の礎がいかに重要であるかを我々に教えてくれます。結果が計算のたびに変わらないという保証は、医療AIが「おもちゃ」から「信頼できる医療機器」へと昇華するための必須条件です。
- ラグランジュの未定乗数法は、「制約付き」という現実的な課題を解くための「強力な道具」でした。これは、理想論だけでは解決できない現実世界の複雑なトレードオフを、数学の言葉でエレガントに記述し、その最適解を探るための洗練されたフレームワークを提供してくれます。
これらの概念は、一見すると抽象的な数式に満ちています。しかし、その根底にある思想は、私たちが日々の臨床や研究で行っているプロセスと深く共鳴しています。鑑別診断を進めるプロセスは、仮説(パラメータ)を立て、検査所見や身体所見(データ)との乖離(損失)を評価し、次の一手(勾配)を考えるという、まさに最適化の思考そのものではないでしょうか。
AIがどのように「思考」し、「学習」し、「結論を導く」のか。その中核にある最適化の論理、いわばAIの思考の”文法”を理解することは、これからの医療者にとって不可欠なリテラシーとなります。この文法を知ることで、私たちはAIを単なる不可解なブラックボックスとして扱うのではなく、その提案を鵜呑みにすることもなく、その能力と限界を正しく見極め、AIの強みと弱みを踏まえた上で、真の意味で「協働」できるようになるのです。
最適化の旅は、AIを、我々の専門性を拡張し、より複雑で個別化された医療を実現するための、強力な知的アンプリファイア(増幅器)として活用するための第一歩です。この探求が、皆様にとって、AIと共に医療の未来を切り拓くための、信頼できる羅針盤となることを願っています。
参考文献
- Boyd, S. and Vandenberghe, L. (2004). Convex Optimization. Cambridge: Cambridge University Press. doi:10.1017/CBO9780511804441.
- Goodfellow, I., Bengio, Y. and Courville, A. (2016). Deep Learning. Cambridge, MA, USA: MIT Press.
- Kingma, D. P. and Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv [cs.LG]. [Preprint] Available at: https://doi.org/10.48550/arXiv.1412.6980.
- Robbins, H. and Monro, S. (1951). A Stochastic Approximation Method. The Annals of Mathematical Statistics, 22(3), pp. 400–407. doi:10.1214/aoms/1177729586.
- Ruder, S. (2016). An overview of gradient descent optimization algorithms. arXiv [cs.LG]. [Preprint] Available at: https://doi.org/10.48550/arXiv.1609.04747.
- Wang, K., Lin, L., Zhai, H., Xu, Z., Liu, Z., and He, Z. (2021). ‘A Survey on Loss Functions for Deep Learning in Computer Vision’, IEEE Access, 9, pp. 138977–139001. doi: 10.1109/ACCESS.2021.3117942.
- Nocedal, J. and Wright, S. J. (2006). Numerical Optimization. 2nd ed. New York: Springer.
- Styrt, M. M., Elite, E., Gentry, J., Williams, K. A., and Norouzi, F. (2021). ‘An optimization model to improve operating room scheduling and surgeon assignment’, Journal of the American College of Surgeons, 233(5), pp. S107–S108. doi: 10.1016/j.jamcollsurg.2021.07.241.
- Cristianini, N. and Shawe-Taylor, J. (2000). An Introduction to Support Vector Machines and Other Kernel-based Learning Methods. Cambridge: Cambridge University Press.
- Fessler, J. A. (2020). Optimization Methods for Medical Image Reconstruction. In: A. B. El-Ghazal, ed., Machine Learning and Medical Imaging. Academic Press, pp. 29–59.
- Akay, M. F. (2009). ‘Support vector machines combined with feature selection for breast cancer diagnosis’, Expert Systems with Applications, 36(2, Part 2), pp. 3240–3247. doi: 10.1016/j.eswa.2008.01.009.
- Cristianini, N. and Shawe-Taylor, J. (2000). An Introduction to Support Vector Machines and Other Kernel-based Learning Methods. Cambridge: Cambridge University Press.
- Lustig, M., Donoho, D. and Pauly, J. M. (2007). ‘Sparse MRI: The application of compressed sensing for rapid MR imaging’, Magnetic Resonance in Medicine, 58(6), pp. 1182–1195. doi: 10.1002/mrm.21391.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




