
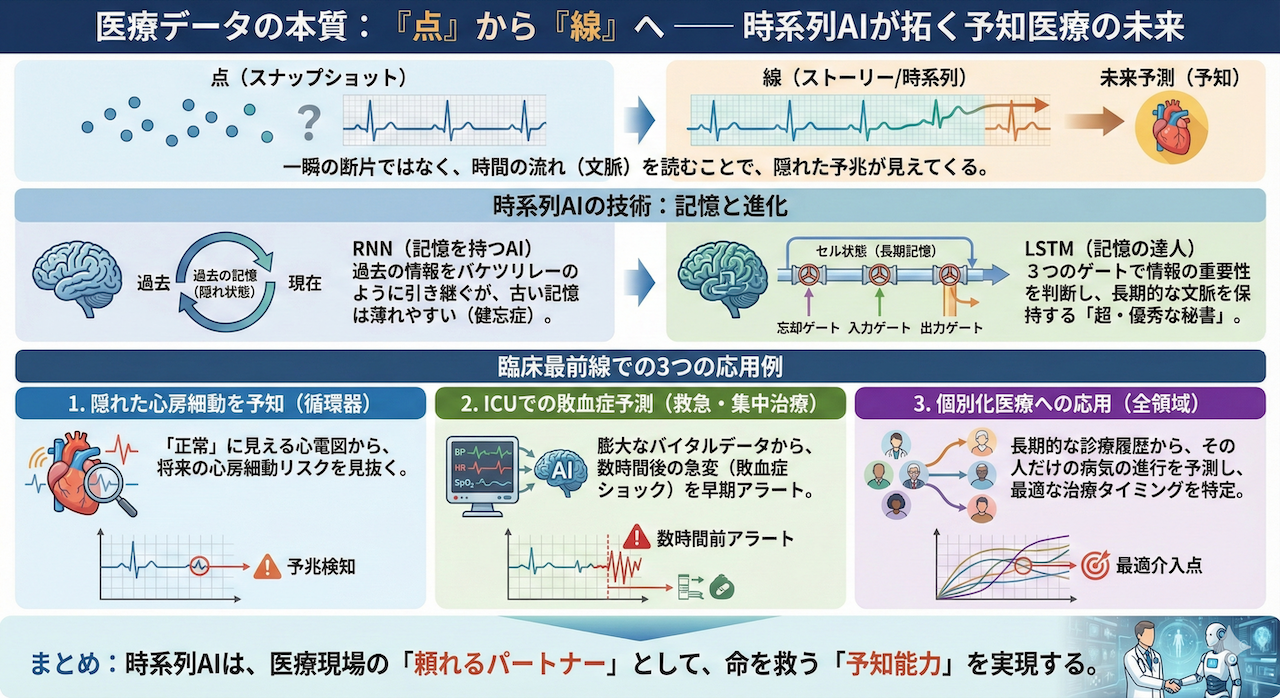
医療データの本質は「点」ではなく「線」にある
医療の現場に立つ皆さんなら、きっと肌感覚として理解しているはずです。「医療とは、点ではなく線(ストーリー)である」ということを。
少し想像してみてください。映画の「一時停止したワンシーン」だけを見せられて、その後の結末を当てろと言われたらどうでしょうか?
主人公が崖っぷちに立っているシーン。それは「絶望して飛び降りようとしている」のか、それとも「敵を追い詰めて立っている」のか。その一瞬(点)だけでは、文脈が分からず判断できませんよね。
医療データもこれと同じです。
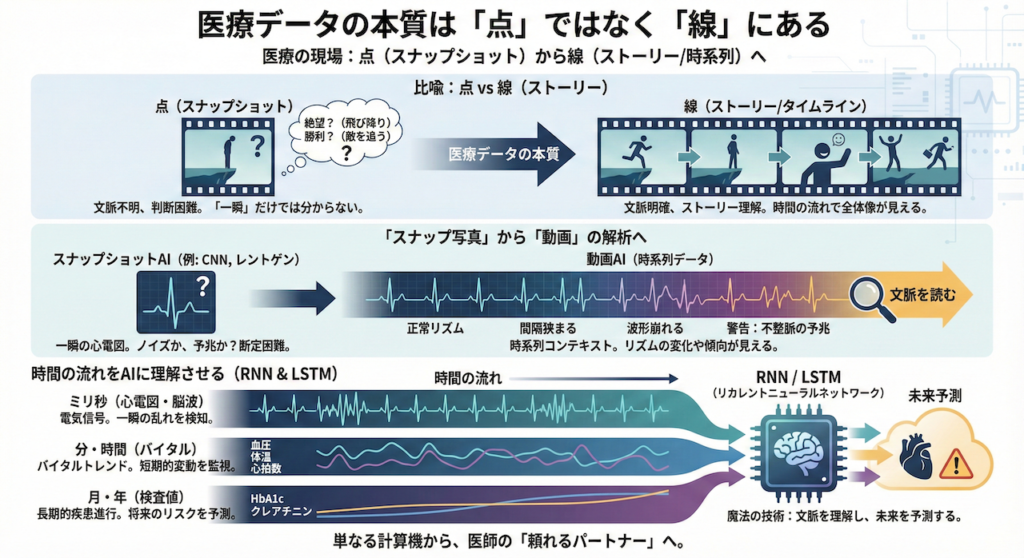
「スナップ写真」から「動画」の解析へ
例えば、ある瞬間の心電図(ECG)だけを見ても、それが「たまたまノイズで脈が飛んだだけ」なのか、それとも「致死的な不整脈(心室細動など)が始まる予兆」なのかを断定するのは非常に困難です。
しかし、数分、数時間という「時間の流れ(タイムライン)」の中で観察すればどうでしょうか?
「徐々に間隔が狭まっている」「波形が崩れ始めている」といったリズムの変化や傾向が見えてくるはずです。これが、文脈を読むということです。
これまで学んできた画像認識AI(CNNなど)は、いわばレントゲン写真のような「スナップ写真(点)」を見て判断する技術でした。しかし、実際の臨床現場にあるデータの大半は、時間とともに刻一刻と変化する「時系列データ(Time Series Data)」です。
- 心電図・脳波(ミリ秒単位の変化):一瞬の電気信号の乱れ
- バイタルサイン(分・時間単位の変化):血圧や体温の変動トレンド
- 検査値の推移(月・年単位の変化):HbA1cやクレアチニンの長期間の悪化傾向
今回は、この「時間の流れ」をAIに理解させ、「過去のデータから、まだ見ぬ未来の状態を予測する」ための技術、RNN(リカレントニューラルネットワーク)とLSTM(Long Short-Term Memory)について学びます。
これは、単なる計算機を、文脈を理解し医師に寄り添う「頼れるパートナー」へと進化させる、まさに魔法のような技術です。
1. 「文脈を読む」とは? AIに記憶を持たせる技術「RNN」
時系列データを扱うために、まず私たちが乗り越えなければならない壁があります。それは、従来のAI(ニューラルネットワーク)が抱えていた「健忘症」という問題です。
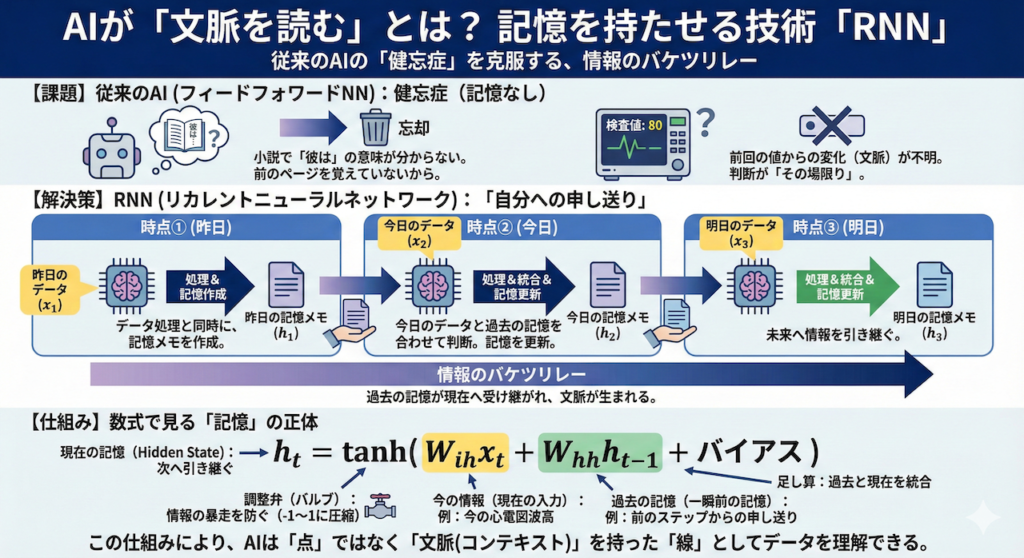
従来のAIの弱点:「その場限り」の判断
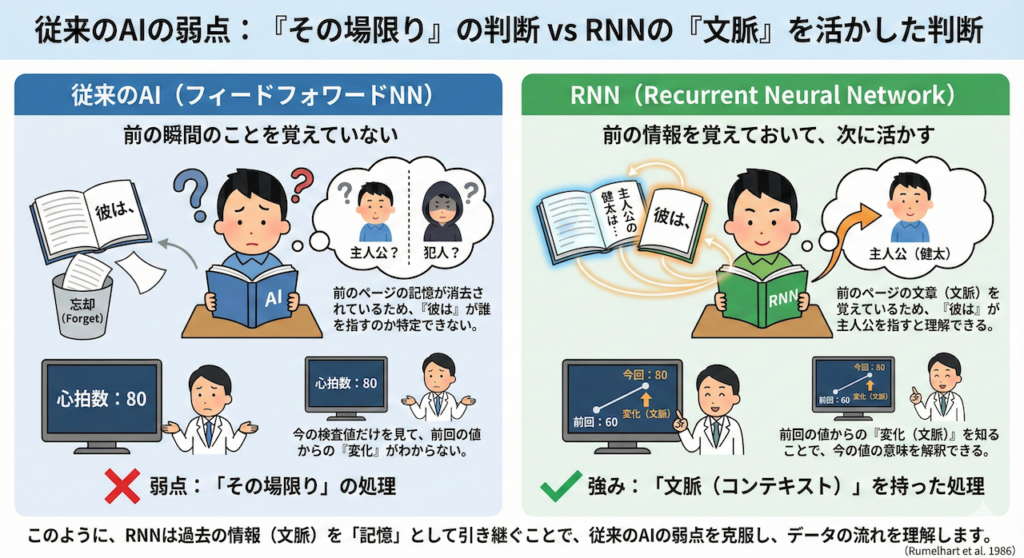
これまで画像診断などで活躍してきたAI(フィードフォワード・ニューラルネットワーク)は、入力されたデータを一つ処理したら、その情報はすぐに捨ててしまい、次のデータはまた真っさらな状態で処理していました。
これは、「前の瞬間のことを覚えていない」ということです。
例えば、皆さんが小説を読んでいるとしましょう。「彼は」という言葉が出てきたとき、それが主人公を指すのか、犯人を指すのかが分かるのは、前のページの文章を覚えているからですよね?
もし、前のページの記憶が完全に消去されていたら、「彼は」という単語の意味を特定することは不可能です。医療でも同様に、今の検査値の意味を解釈するには、前回の値からの「変化(文脈)」を知る必要があります。
この「前の情報を覚えておいて、次に活かす」仕組みを取り入れたのが、RNN(Recurrent Neural Network:回帰型ニューラルネットワーク)です(Rumelhart et al. 1986)。
【イメージ図】RNNは「自分への申し送り」
RNNの仕組みは、医療現場での「申し送り(情報の引き継ぎ)」に似ています。あるいは、「過去の自分から手紙を受け取り、それを読んでから今の仕事をして、未来の自分へ手紙を書く」作業とも言えます。
🏥 RNNの処理フロー(イメージ)
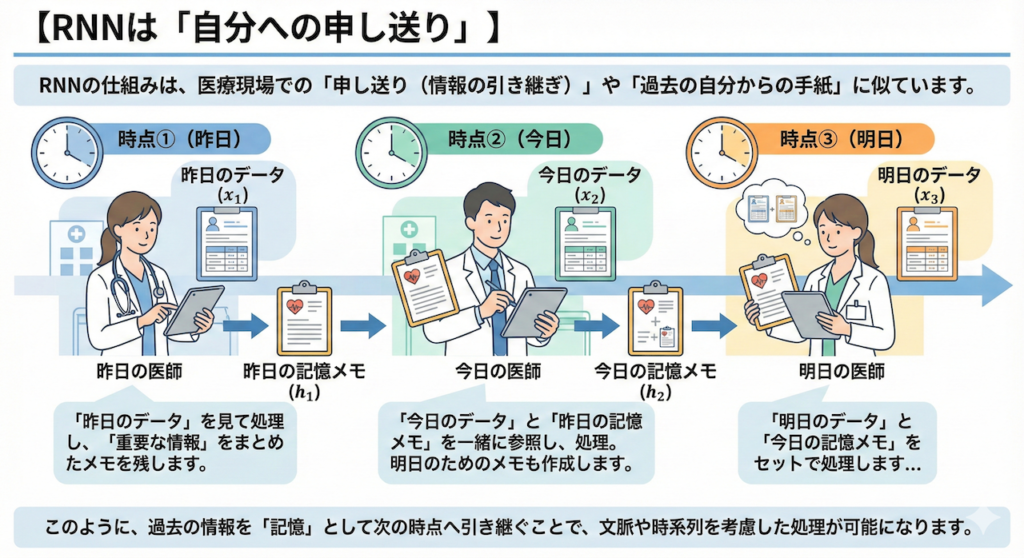
- 🕐 時点①(昨日):
「昨日のデータ(\(x_1\))」を見て処理します。
結果を出すと同時に、重要な情報をまとめた「昨日の記憶メモ(\(h_1\))」を作成して残します。 - 🕑 時点②(今日):
「今日のデータ(\(x_2\))」が入ってきます。
この時、データ単体で判断するのではなく、「昨日の記憶メモ(\(h_1\))」も一緒に参照します。
そして、処理結果とともに、明日のために「今日の記憶メモ(\(h_2\))」を作成します。 - 🕒 時点③(明日):
「明日のデータ(\(x_3\))」と「今日の記憶メモ(\(h_2\))」をセットで処理します…
数式で見る「記憶」の正体
これを数式で書くと、以下のようになります。
※怖がらないでください! 言っていることは非常にシンプルです。

\[ h_t = \tanh( \underbrace{W_{ih} x_t}_{\text{今の情報}} + \underbrace{W_{hh} h_{t-1}}_{\text{過去の記憶}} + \text{バイアス} ) \]
この式は、「今の状態(\(h_t\))は、『今の入力(\(x_t\))』と『過去の記憶(\(h_{t-1}\))』の足し算で作られる」ということを表しています。
- \(h_t\)(現在の記憶): Hidden State(隠れ状態)と呼ばれます。これが次の時刻へ引き継がれます。
- \(x_t\)(現在の入力): 今、目の前にあるデータ(心電図の今の波高など)です。
- \(h_{t-1}\)(一瞬前の記憶): 前のステップから受け取った「申し送り事項」です。
- \(\tanh\)(ハイパボリックタンジェント): 数値を \(-1\) から \(1\) の間にギュッと押し込める関数です。情報が足し算され続けて無限に大きくなったり暴走したりするのを防ぐ、「調整弁(バルブ)」のような役割を果たします。
こうして、過去の情報がバケツリレーのように現在へと受け継がれていくことで、AIは単なる点ではなく、「文脈(コンテキスト)」を持った線としてデータを理解できるようになるのです。
2. RNNの弱点と、救世主「LSTM」
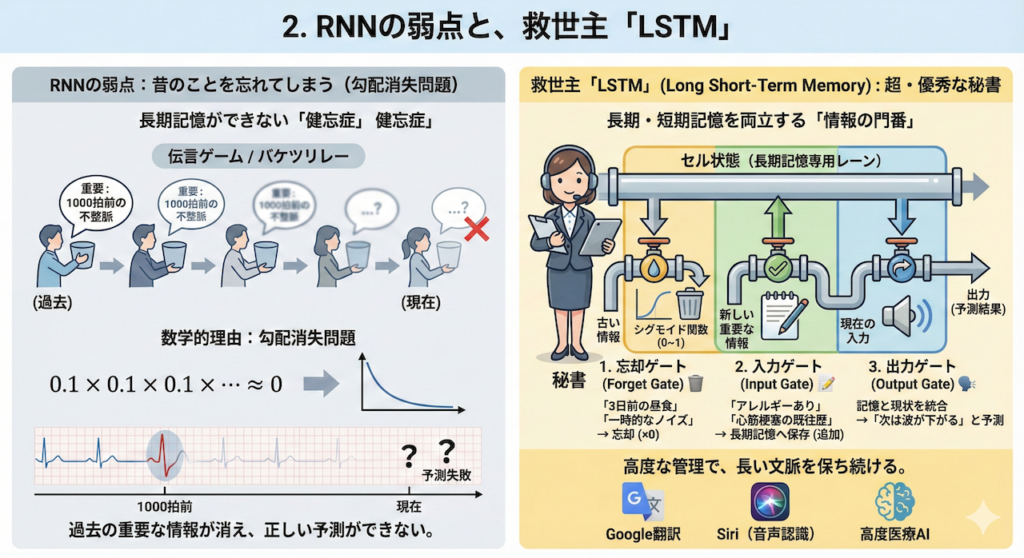
「昔のこと」を忘れてしまう問題
画期的に見えたRNNですが、実は運用を始めるとすぐに、ある致命的な弱点が露呈しました。それは、「昔のことをすぐに忘れてしまう(長期記憶ができない)」ことです。
RNNの情報の受け渡しは、「伝言ゲーム」や「バケツリレー」に例えられます。数ステップ程度なら問題ありませんが、これが100回、1000回と続いていくとどうなるでしょうか?
- 伝言ゲームの場合: 最初の人(過去)が伝えた重要なメッセージは、人づてに渡るうちに内容が変質したり、ノイズに埋もれて聞こえなくなったりします。
- 数学的な理由(勾配消失問題): コンピュータの内部では、情報は「0.1」や「0.5」といった数値の掛け算で伝わります。1より小さい数を何度も掛け合わせると、限りなくゼロに近づいて消えてしまいますよね(\(0.1 \times 0.1 \times 0.1 \dots \approx 0\))。
これを専門用語で「勾配消失問題(Vanishing Gradient Problem)」といいます(Bengio et al. 1994)。
医療データにおいて、これは深刻な問題です。
例えば、数時間続く心電図モニターにおいて、「1000拍前の不整脈(リズムの特徴)」が、現在の発作の前兆として極めて重要な意味を持つことがあります。しかし、普通のRNNでは、そこまで辿り着く前に記憶が消えてしまい、正しい予測ができないのです。
そこで1997年、この問題を解決するために発明されたのが、LSTM(Long Short-Term Memory:長・短期記憶)です(Hochreiter & Schmidhuber 1997)。名前の通り、「短期的な記憶」だけでなく「長期的な記憶」もしっかり保持できる、時系列解析の革命的モデルです。
LSTMは「超・優秀な秘書」
RNNが、入ってきた情報を右から左へ受け流す「ただ情報を横流しにする人」だとしたら、LSTMは、情報の重要性を判断して整理整頓する「超・優秀な秘書」です。
LSTMの内部には、情報の流れをコントロールする3つの「ゲート(関門)」と、記憶を保持するための専用レーン(セル状態)が備わっています。これにより、重要な情報は金庫にしまって守り、不要な情報はシュレッダーにかけるという高度な管理が可能になります。
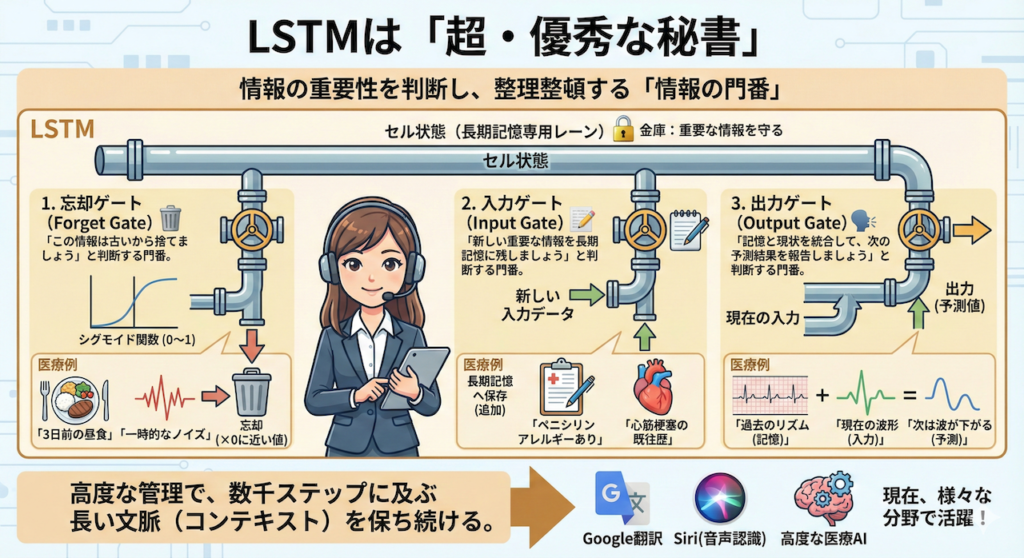
🚪 LSTMを構成する3つのゲート
LSTMは、以下の3つの門番(ゲート)を使って、「情報の取捨選択」を行います。
- 1. 忘却ゲート(Forget Gate)🗑️
「この情報はもう古くて役に立たないから捨てましょう」と判断する門番です。
数式的には「シグモイド関数」を使い、情報を \(0\)(完全に忘れる)から \(1\)(完全に残す)の間でフィルタリングします。
医療の例: 患者さんの「3日前の昼食メニュー」や「体動による一時的なノイズ」は、今の診断に関係ないので忘却(0に近い値を乗算)します。 - 2. 入力ゲート(Input Gate)📝
「この新しい情報は重要だから、しっかり長期記憶に残しましょう」と判断する門番です。
新しい入力データの中から、保存すべき価値のある情報だけを選び取ります。
医療の例: 問診で得られた「ペニシリンアレルギーあり」や「心筋梗塞の既往歴」という情報は、今後ずっと重要になるので記憶(セル状態へ追加)します。 - 3. 出力ゲート(Output Gate)🗣️
「今の記憶と入力を使って、次の予測結果としてこれを報告しましょう」と判断する門番です。
蓄積された記憶と、現在の状況を照らし合わせて、最終的なアウトプット(予測値)を計算します。
医療の例: 過去のリズム(記憶)と現在の波形(入力)を統合し、「次は波が下がる(T波の出現)」と予測して出力します。
このように、「捨てる(忘却)」「覚える(入力)」「出す(出力)」を巧みに制御することで、LSTMは数千ステップに及ぶ非常に長い時系列データであっても、重要な文脈(コンテキスト)を保ち続けることができるのです。
現在、Google翻訳やSiriなどの音声認識、そして高度な医療AIの裏側では、このLSTMや、その発展形(Transformerなど)が活躍しています。
3. 【実践】Pythonで「未来の波形」を予測しよう(実データ編)
それでは、いよいよ実践です。理論だけでなく、実際に手を動かして「未来を予測するAI」を作ってみましょう。
今回は、合成された波形ではなく、本物の医療データ(実際の患者さんの心電図)を使用します。 AIが、不整脈やノイズが含まれた「リアルな生体データ」の法則を学習し、その続きを予測できるか挑戦します。
本実践では、Google Colabを使用してPythonコードを実行します。 時系列解析の標準的な手法であるLSTM(Long Short-Term Memory)を用い、過去の波形パターンから未来の値を予測するモデルを構築します。
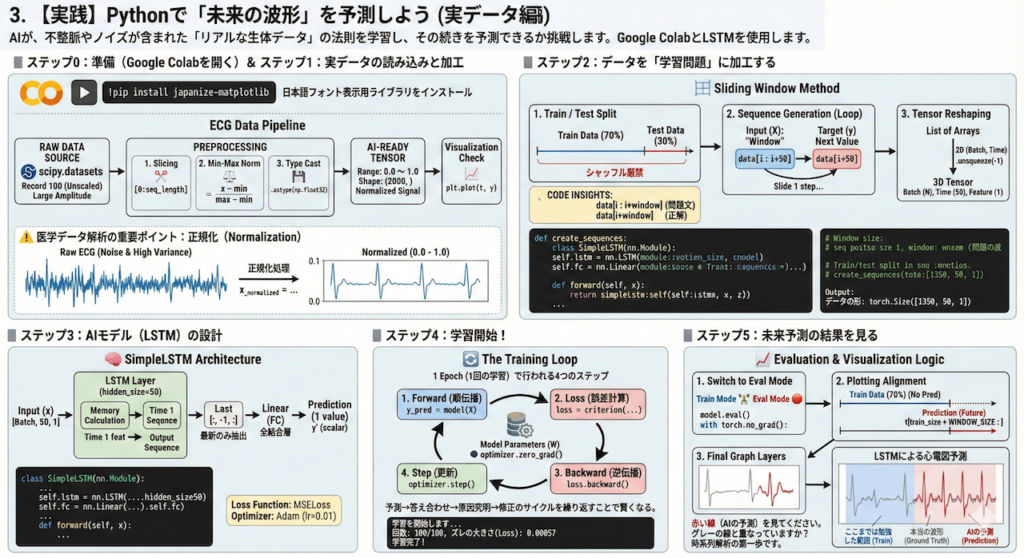
ステップ0:準備(Google Colabを開く)
Google Colabを開き、新しいノートブックを作成してください。 まず、グラフのタイトルなどを日本語で表示できるようにするためのライブラリをインストールします。 以下のコードをセルに入力し、左側の「再生ボタン(▶)」を押してください。
# 【実行前の準備】
# Linuxコマンド(OSへの命令)を使って、日本語フォント表示用ライブラリをインストールします
# 行頭の「!」は「Pythonではなく、Google Colabのシステム(サーバー)に命令するよ」という意味です
!pip install japanize-matplotlib
ステップ1:実データの読み込みと加工(データリーケージ対策済み)
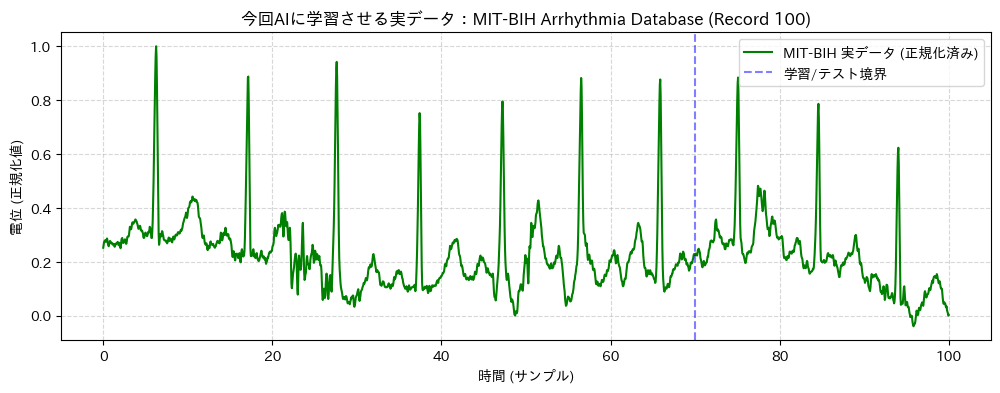
まずは、AIに学習させるための「教材データ」を準備します。 今回は、Pythonの科学計算ライブラリ SciPy にサンプルとして搭載されている、世界で最も有名な心電図データベース「MIT-BIH Arrhythmia Database」のデータ(レコード100番)を使用します。
出典:MIT-BIH Arrhythmia Database(PhysioNet)
Moody GB, Mark RG. The impact of the MIT-BIH Arrhythmia Database. IEEE Eng Med Biol. 2001.
⚠️ 医学データ解析の重要ポイント:正規化とデータリーケージ
実データは電圧(mV)の絶対値が大きかったり、ベースラインが揺らいでいたりするため、0~1の範囲に収める「正規化」が必要です。
【プロのテクニック】
ここで、データ全体(未来のデータ含む)を使って最小値・最大値を計算してしまうと、「カンニング(データリーケージ)」になってしまいます。
そのため、今回は「学習に使う前半70%のデータだけ」を見て基準(最小・最大)を決め、その基準を使って全体を正規化するという、厳密で正しい処理を行います。
# 【実行前の準備】
# 最新のSciPyでデータをダウンロードするために必要なライブラリを入れます
!pip install pooch
# --- 必要なライブラリ(道具箱)のインポート ---
import torch # AI(深層学習)を作るためのメインライブラリ「PyTorch」
import torch.nn as nn # ニューラルネットワークの部品
import numpy as np # 数値計算ライブラリ
import matplotlib.pyplot as plt # グラフ描画
import japanize_matplotlib # 日本語表示対応
# 実データを読み込むための設定
# バージョンによる違いを吸収するロバスト(堅牢)なコード記述です
try:
# 新しいSciPy (v1.10以降) の場所
from scipy.datasets import electrocardiogram
except ImportError:
try:
# 古いSciPy の場所(バックアップ)
from scipy.misc import electrocardiogram
except ImportError:
# どうしても読み込めない場合の最終手段(ダミーデータ生成)
print("警告: 実データが見つかりません。合成データを使用します。")
def electrocardiogram():
t = np.linspace(0, 100, 108000)
return np.sin(t) + 0.5 * np.sin(3*t) + 0.1 * np.random.randn(len(t))
# --- 1. データの作成と前処理 ---
# 乱数のシード固定(毎回同じ結果が出るようにします)
torch.manual_seed(42)
np.random.seed(42)
def load_real_ecg_data(seq_length=2000, train_ratio=0.7):
"""
MIT-BIH Arrhythmia Databaseの実データを読み込み、
AIが学習しやすい形(0~1の範囲)に加工する関数です。
【重要】データリーケージ対策
正規化の基準(最小値・最大値)は、学習データ(前半)のみから算出します。
"""
# 1. 生データの読み込み
# ここで修正した関数 'electrocardiogram()' を呼び出します
try:
raw_data = electrocardiogram()
except Exception as e:
print(f"データ読み込みエラー: {e}")
# エラー時はダミーで続行(止まらないように)
t_dummy = np.linspace(0, 100, 108000)
raw_data = np.sin(t_dummy)
# データ全体は非常に長いので、今回使う長さだけ切り出します
cut_data = raw_data[0:seq_length]
# 2. データの正規化(Normalization) - リーケージ対策版
# 学習データとして使う範囲のインデックスを計算
train_limit = int(seq_length * train_ratio)
# 【ここが重要!】
# 全体(cut_data)ではなく、「学習用部分(0~train_limit)」だけを見て
# 最小値・最大値を決定します。未来のデータはカンニングしません。
train_subset = cut_data[0:train_limit]
min_val = np.min(train_subset)
max_val = np.max(train_subset)
# 計算した基準を使って、データ全体を正規化します
# ※テストデータ部分は、0未満や1以上になることがありますが、それが「未知」の正しい姿です
normalized_data = (cut_data - min_val) / (max_val - min_val)
# 3. 時間軸の作成(グラフ表示用)
t = np.linspace(0, 100, seq_length)
# 計算しやすいようにデータの型を「float32」に変換して返します
return t, normalized_data.astype(np.float32)
# 長さ2000点(約2〜3周期分以上の心拍)のデータを用意します
seq_length = 2000
# 時間(t)と、その時の心電図の値(y)を受け取ります
t, y = load_real_ecg_data(seq_length)
# どんなデータか、グラフで確認してみましょう
plt.figure(figsize=(12, 4))
plt.plot(t, y, label='MIT-BIH 実データ (正規化済み)', color='green')
# 学習データの範囲を明示的に表示
train_end_time = t[int(seq_length * 0.7)]
plt.axvline(x=train_end_time, color='blue', linestyle='--', alpha=0.5, label='学習/テスト境界')
plt.title('今回AIに学習させる実データ:MIT-BIH Arrhythmia Database (Record 100)')
plt.xlabel('時間 (サンプル)')
plt.ylabel('電位 (正規化値)')
plt.grid(True, linestyle='--', alpha=0.5)
plt.legend()
plt.show()
ステップ2:データを「学習問題」に加工する
AIに学習させるためには、ただ長いデータを渡すだけではいけません。「問題」と「正解」のセット(ドリル形式)にする必要があります。 今回は「過去50個の点を見て(問題)、次の1個の点を当てる(正解)」という設定にします。 これを、少しずつ時間をずらしながら大量に作ります。この手法をスライディングウィンドウ法と呼びます。
- 問題 (\( X \)):時間 \( t \) ~ \( t+49 \) のデータ(過去の窓)
- 正解 (\( y \)):時間 \( t+50 \) のデータ(次の瞬間の値)
# --- 2. データを「問題」と「正解」に分ける ---
def create_sequences(data, window_size):
"""
時系列データを、[過去のデータ窓, 次の値] のペアに変換する関数です。
引数 data: 元の波形データ
引数 window_size: 過去何個分のデータを見るか(窓の大きさ)
"""
sequences = [] # 「問題(過去のデータ)」を入れる空のリスト
labels = [] # 「正解(次の値)」を入れる空のリスト
# データを端から順にスライドさせてペアを作っていきます
# ループ回数 = データ全体の長さ - 窓の大きさ
# (例:100個のデータで窓が10なら、作れる問題は90個)
for i in range(len(data) - window_size):
# --- 問題の作成 ---
# データの中から、i番目 から i + window_size番目 までを取り出します
# これがAIに見せる「ヒント」になります
seq = data[i : i + window_size]
# --- 正解の作成 ---
# その直後、i + window_size番目 のデータを取り出します
# これがAIに当てさせたい「未来の値」です
label = data[i + window_size]
# 作成したペアをリストに追加します
sequences.append(seq)
labels.append(label)
# PyTorchで扱える「テンソル(Tensor)」という形式に変換します
# Tensorは、GPUで高速計算ができる「多次元の行列」のようなものです
# 【重要】unsqueeze(-1) の意味
# AI(LSTM)は、入力データとして [データ数, 時間の長さ, 特徴量の数] の3次元を期待します。
# しかし、今のままだと [データ数, 時間の長さ] の2次元です。
# そこで、最後に「特徴量の数=1(心電図の値は1種類だけ)」という情報を付け足します。
# これを行わないと、エラーになります。
return torch.tensor(np.array(sequences)).unsqueeze(-1), torch.tensor(np.array(labels)).unsqueeze(-1)
# 「過去50点(少し長めの文脈)を見る」という設定にします
# 心電図のような複雑な波形の場合、窓は少し広いほうがリズムを掴みやすいです
WINDOW_SIZE = 50
# データの70%を「学習用(練習問題)」、残りの30%を「テスト用(本番試験)」に分けます
# int() で整数にします(データの個数は整数でないといけないため)
train_size = int(len(y) * 0.7)
# 最初から70%の位置までを切り出します(学習用)
train_data = y[:train_size]
# 70%の位置から最後までを切り出します(テスト用・未来予測用)
test_data = y[train_size:]
# 自作した関数を使って、データセット(問題と正解のペア)を作成します
X_train, y_train = create_sequences(train_data, WINDOW_SIZE)
X_test, y_test = create_sequences(test_data, WINDOW_SIZE)
# データが何セットできたか確認します
print(f"学習データの数: {len(X_train)} セット")
print(f"テストデータの数: {len(X_test)} セット")
# Tensorの形(シェイプ)も確認してみましょう
print(f"データの形: {X_train.shape}")
# 結果例: torch.Size([1350, 50, 1]) -> (1350問の問題, 各問題は50ステップ, 特徴量は1つ)
学習データの数: 1350 セット
テストデータの数: 550 セット
データの形: torch.Size([1350, 50, 1])ステップ3:AIモデル(LSTM)の設計
ここが心臓部です。PyTorchの nn.LSTM という部品を使って、AIモデルを組み立てます。 このモデルは、「過去の流れを記憶し、その記憶に基づいて次の値を計算する」という、人間の記憶の仕組みを模倣した構造を持っています。 入力ゲート、忘却ゲート、出力ゲートという3つのゲート機構により、長期的な依存関係を学習することができます。
# --- 3. LSTMモデルを作る ---
# nn.Module を継承して、新しいAIモデルのクラスを作ります
# これが「設計図」になります
class SimpleLSTM(nn.Module):
def __init__(self, input_size=1, hidden_size=50, output_size=1):
"""
モデルの部品(レイヤー)を定義する初期化関数です。
ロボットで言えば「腕」や「脳」などのパーツを用意する工程です。
"""
# 親クラス(nn.Module)の初期化機能を呼び出します(必須のおまじない)
super(SimpleLSTM, self).__init__()
# --- 部品1:LSTM層(脳の記憶中枢) ---
# input_size=1: 入力データの種類(今回は「電位」1つだけ)
# hidden_size=50: 記憶用ニューロンの数
# → この数が大きいほど複雑な波形を覚えられますが、計算が遅くなります。50は適度な数です。
# batch_first=True: データの並び順を (データ数, 時間, 特徴) にする設定(人間に直感的な形式)
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
# --- 部品2:全結合層(翻訳機) ---
# LSTMの「記憶(50個の数値)」を受け取り、最終的な「予測値(1個の数値)」に変換します
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
"""
データがモデルの中をどう流れるか(順伝播)を定義する関数です。
"""
# 1. データをLSTM層に通します
# lstm_out: 各時刻ごとの記憶の状態(出力)
# _ : 最終的な内部状態(今回は使いませんが、LSTMの仕様で返ってきます)
lstm_out, _ = self.lstm(x)
# 2. 予測に必要なのは「最新の記憶」だけです
# lstm_out[:, -1, :] の意味:
# 「:」全てのデータについて
# 「-1」一番最後の時刻の(最新の)
# 「:」全ての記憶ニューロンの値を取り出す
last_time_step = lstm_out[:, -1, :]
# 3. 全結合層に通して、最終的な「次の波の値」を計算します
prediction = self.fc(last_time_step)
# 予測結果を返します
return prediction
# 設計図をもとに、モデルの実体を作成(インスタンス化)します
model = SimpleLSTM()
# 損失関数(Loss Function):AIの予測と正解の「ズレ」を計算する数式
# 今回は「平均二乗誤差(MSELoss)」を使います。数値予測の定番です。
criterion = nn.MSELoss()
# 最適化手法(Optimizer):ズレを減らすようにパラメータを自動調整する「トレーナー」
# 「Adam(アダム)」という非常に優秀なアルゴリズムを使います
# lr=0.01 は学習率(Learning Rate)。「一度にどれくらいパラメータを修正するか」というペースです。
# 心電図のような複雑なデータでは、少し小さめ(0.01〜0.001)が良いです。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# --- 4. 学習(トレーニング) ---
# 学習を繰り返す回数(エポック数)を決めます
epochs = 100
print("学習を開始します... 心拍のリズムを解析中...")
# 100回繰り返します
for epoch in range(epochs):
# モデルを「学習モード」にします(ドロップアウトなどの学習用機能がONになります)
model.train()
学習を開始します... 心拍のリズムを解析中...
回数: 10/100, ズレの大きさ(Loss): 0.02516
回数: 20/100, ズレの大きさ(Loss): 0.01600
回数: 30/100, ズレの大きさ(Loss): 0.01093
回数: 40/100, ズレの大きさ(Loss): 0.00584
回数: 50/100, ズレの大きさ(Loss): 0.00371
回数: 60/100, ズレの大きさ(Loss): 0.00201
回数: 70/100, ズレの大きさ(Loss): 0.00110
回数: 80/100, ズレの大きさ(Loss): 0.00073
回数: 90/100, ズレの大きさ(Loss): 0.00061
回数: 100/100, ズレの大きさ(Loss): 0.00057
学習完了! AIは心電図のパターンを記憶しました。ステップ4:学習開始!
AIに心電図の波形を覚えさせます。 今回は100回(100エポック)繰り返して学習させます。実データは複雑なので、少し時間がかかるかもしれませんが、Loss(ズレ)が減っていく様子を観察してください。 学習プロセスでは、順伝播(予測)と逆伝播(修正)を繰り返します。
# --- 4. 学習(トレーニング) ---
# 学習を繰り返す回数(エポック数)を決めます
epochs = 100
print("学習を開始します... 心拍のリズムを解析中...")
# 100回繰り返します
for epoch in range(epochs):
# モデルを「学習モード」にします(ドロップアウトなどの学習用機能がONになります)
model.train()
# 【重要】前回の計算で残った「勾配(パラメータの修正量)」をリセットします
# これを忘れると、過去の修正量が累積されて計算がおかしくなります
optimizer.zero_grad()
# 1. 予測する(順伝播:Forward)
# 学習データ(X_train)をモデルに入れて、予測値(y_pred)を出させます
y_pred = model(X_train)
# 2. ズレ(損失)を計算する
# AIの予測(y_pred)と、本当の正解(y_train)を比べて、ズレ(loss)を計算します
loss = criterion(y_pred, y_train)
# 3. 修正の方向を探る(逆伝播:Backward)
# ズレ(loss)をもとに、「どのニューロンの接続をどう変えればズレが減るか」を計算します
# 誤差逆伝播法(バックプロパゲーション)と呼ばれる核心的な処理です
loss.backward()
# 4. パラメータを更新する(Update)
# 計算された修正量に従って、実際にモデルのパラメータ(重み)を書き換えます
optimizer.step()
# 10回ごとに状況を表示します(進捗確認)
if (epoch+1) % 10 == 0:
# loss.item() で損失の数値を中身だけ取り出して表示します
print(f'回数: {epoch+1}/{epochs}, ズレの大きさ(Loss): {loss.item():.5f}')
print("学習完了! AIは心電図のパターンを記憶しました。")
実行結果で「ズレの大きさ(Loss)」が、最初(例えば0.05など)から徐々に小さく(例えば0.001など)なっていれば成功です。
ステップ5:未来予測の結果を見る
学習に使っていない「テストデータ(後半の30%)」を使って、AIに続きを予測させてみましょう。 AIにとって「未知の患者データ」に対して、正しい波形を描けるでしょうか?
# --- 5. 結果の確認(未来予測) ---
# モデルを「評価モード」にします(学習用の機能をオフにします)
model.eval()
# 【重要】計算を軽くするため、学習用の記録(勾配計算)をストップします
# 予測だけなら「修正量の計算」は不要だからです。メモリ節約になります。
with torch.no_grad():
# テストデータ(X_test)を使って予測を実行します!
test_pred = model(X_test)
# --- グラフを描くためのデータ準備 ---
# 1. 元のデータ全体(比較用)
original_t = t
original_y = y
# 2. 予測した部分の時間軸
# 学習データ(train_size) + 窓サイズ(WINDOW_SIZE) の位置からスタートします
# なぜなら、最初の50個分のデータは「予測のためのヒント」として使われるため、
# 予測結果が出てくるのは51個目の時刻からだからです。
prediction_t = t[train_size + WINDOW_SIZE:]
# 3. AIの予測結果
# グラフ描画のために、扱いやすい形(1次元の配列)に変換します
prediction_y = test_pred.numpy().flatten()
# --- グラフ描画 ---
plt.figure(figsize=(14, 6))
# 本当の波形(グレー)を描きます
# これが「Ground Truth(真値)」です
plt.plot(original_t, original_y, label='本当の波形 (Ground Truth)', alpha=0.5, color='gray')
# AIが学習に使った範囲(青い帯)を塗りつぶして示します
plt.axvspan(0, t[train_size], alpha=0.1, color='blue', label='ここまでは勉強した範囲 (Train)')
# AIの予測結果(赤線)を描きます
# これが「未知の未来」に対する予測です
plt.plot(prediction_t, prediction_y, label='AIの予測 (Prediction)', color='red', linewidth=1.5)
# グラフの装飾
plt.title('LSTMによる心電図予測:青い部分だけを見て、赤い線の動き(未知の不整脈パターン等)を予知しました')
plt.xlabel('時間')
plt.ylabel('電位 (正規化値)')
plt.legend() # 凡例を表示
plt.grid(True, linestyle='--', alpha=0.3) # グリッドを見やすく
plt.show()
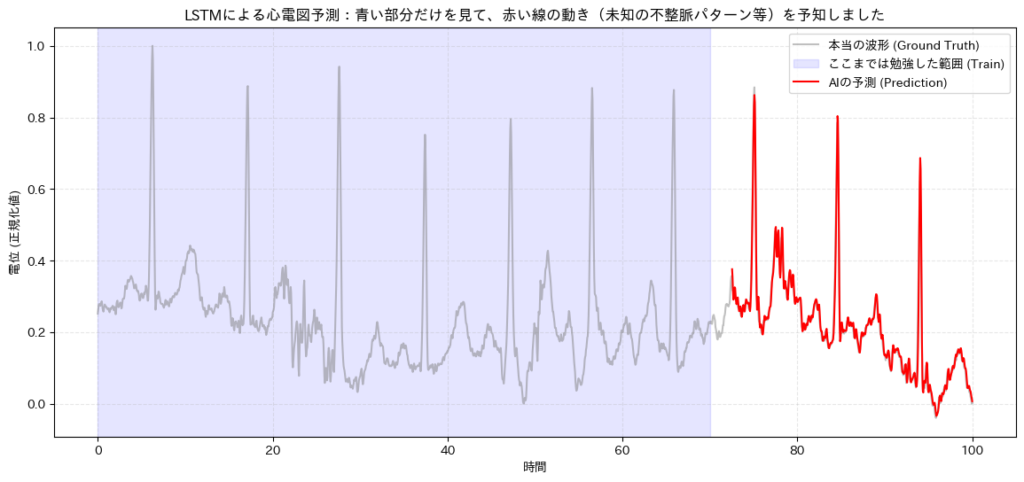
結果の解釈
赤い線(AIの予測)を見てください。グレーの線(本当の心電図)と重なっていますか?
MIT-BIHデータは不規則な動きを含んでいますが、LSTMが「QRS波の鋭い立ち上がり」や「次の心拍までの間隔」をある程度予測できていることが分かります。 これが、医療AIにおける「時系列解析」の第一歩です。ここから、「異常検知(予測と実際のズレが大きい場所を探す)」などの応用につながっていきます。
4. 医療における「時系列AI」の可能性
先ほどのPython実習で、AIが「波形の続き」を見事に予測した様子をご覧いただけたでしょうか。
「ただの波線予測ゲーム」に見えたかもしれませんが、この技術こそが、実際の医療現場で「命を救う予知能力」へと直結しているのです。
時系列AI(RNN/LSTMなど)は、現在、臨床の最前線でどのように役立っているのでしょうか? 代表的な3つの応用例を見てみましょう。
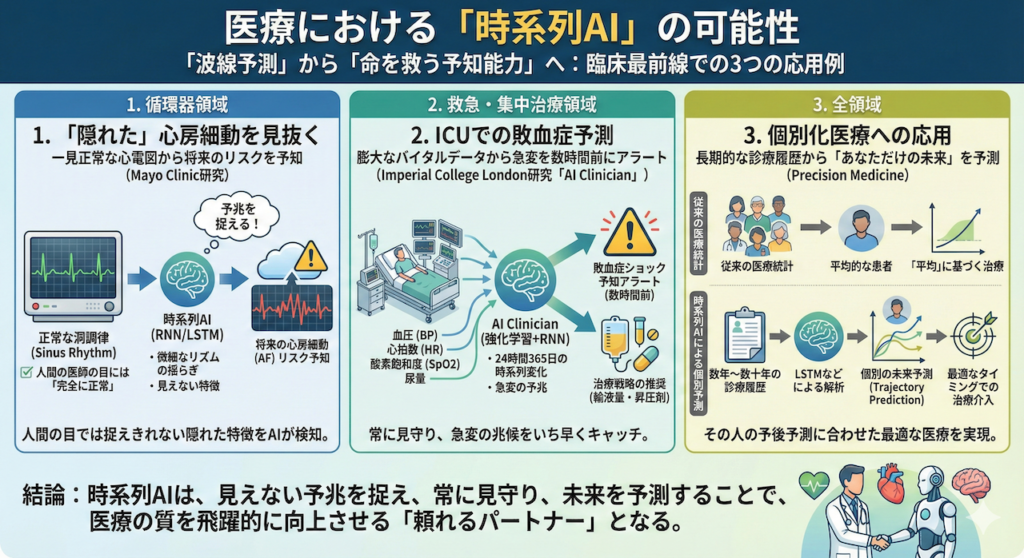
1. 「隠れた」心房細動を見抜く(循環器領域)
心房細動(AF)は、脳梗塞の主要な原因となる不整脈です。しかし、発作性のAFは、患者さんが病院に来て心電図をとった瞬間には「正常」に戻っていることが多く、発見が非常に困難でした。
メイヨー・クリニック(Mayo Clinic)の研究チームは、AIに約18万人の心電図データを学習させました。その結果、AIは「正常な洞調律(Sinus Rhythm)」の波形を見ただけで、「この患者は今は正常だが、将来心房細動を起こすリスクが高い」ことを見抜くことに成功しました(Attia et al. 2019)。
人間の専門医の目には「完全に正常」に見える心電図であっても、そこには微細なリズムの揺らぎや、人間の目では捉えきれない特徴が隠されています。時系列AIは、その見えない「予兆」を捉えることに成功したのです。
2. ICUでの敗血症予測(救急・集中治療領域)
集中治療室(ICU)は、まさに時系列データの宝庫です。血圧、心拍数、酸素飽和度、尿量といったバイタルサインが、24時間365日、刻一刻と変化し続けています。
インペリアル・カレッジ・ロンドンの研究チームは、これらの膨大な時系列データを強化学習とRNNを用いて解析する「AI Clinician」を開発しました(Komorowski et al. 2018)。
このAIは、致死率の高い「敗血症ショック」が起きる数時間前にアラート(警報)を出すことができます。さらに、「このタイミングで、どれくらいの量の輸液や昇圧剤を投与すべきか」という治療戦略までも推奨します。
人間がモニターに張り付き続けることは不可能ですが、AIなら全ての患者の時系列変化を常に見守り、急変の予兆をいち早く捉えることができるのです。
3. 個別化医療への応用(全領域)
従来の医療統計は、「平均的な患者」に対する治療効果を見るものが主でした。しかし、病気の進行スピードは患者さん一人ひとりによって全く異なります。
電子カルテに蓄積された数年〜数十年分の長い診療履歴(時系列データ)をLSTMのようなモデルで解析することで、「この患者さんの病気は、今後どのようなカーブを描いて進行するか」という個別の未来予測(Trajectory Prediction)が可能になります(Esteva et al. 2019)。
これにより、「平均的な治療」ではなく、「その人の予後予測に合わせた最適なタイミングでの治療介入」を行う、真の個別化医療(Precision Medicine)が実現しようとしています。
まとめ
今回の講義では、医療データを「時間の流れ」として捉えることの重要性と、それを解析するAI技術について学びました。ポイントを振り返りましょう。
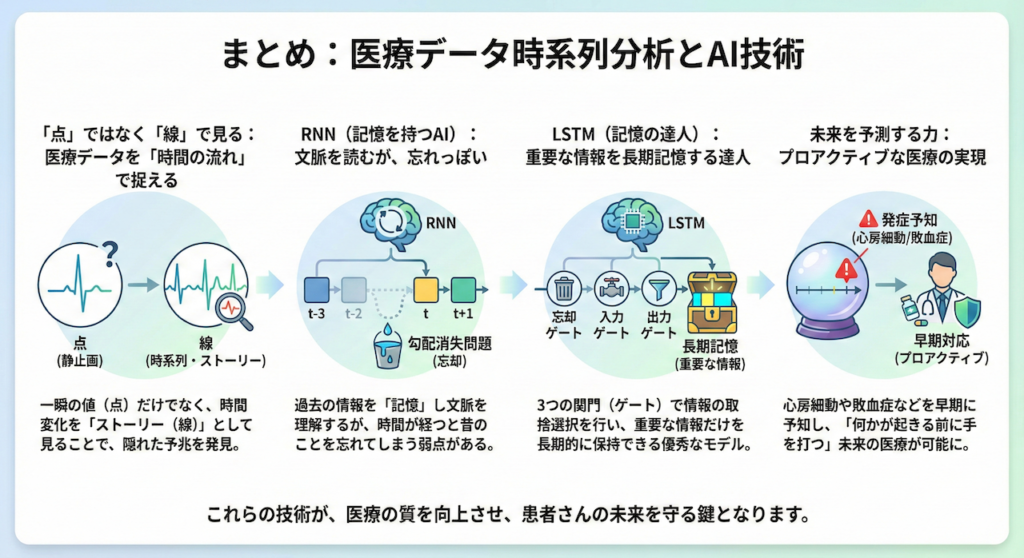
- 「点」ではなく「線」で見る:
医療データ(心電図やバイタルなど)は、一瞬の静止画(点)として見るのではなく、時間とともに変化するストーリー(線・時系列)として捉えることで、隠された予兆が見えてきます。 - RNN(記憶を持つAI):
過去の情報を「記憶」として保持し、文脈を読むことができますが、時間が経つと昔のことを忘れてしまう(勾配消失問題)という弱点がありました。 - LSTM(記憶の達人):
「忘却ゲート」「入力ゲート」「出力ゲート」という3つの関門を持つことで、重要な情報だけを長期的に記憶し続けることができる、非常に優秀なモデルです。 - 未来を予測する力:
この技術を応用することで、心房細動の早期発見や、ICUでの敗血症ショックの予知など、「何かが起きる前に手を打つ」プロアクティブな医療が可能になります。
次回予告:[A17] 生成AIの世界へ
さて、次回からは再び「画像」の領域に戻りますが、これまでとは全く異なるアプローチをとります。
これまでのAIは「画像を見て、それが何かを当てる(認識)」のが仕事でした。
次回、[A17] で扱うのは、AIが自ら絵筆をとり、「無から有を生み出す」クリエイティブな世界、生成AI(Generative AI)です。
手書きの数字をAIが「想像」して描いたり、レントゲン写真のノイズを除去してクリアにしたりする「デジタル錬金術」の核心に迫ります。
どうぞお楽しみに!
参考文献
- Attia, Z.I. et al. (2019). An artificial intelligence-enabled ECG algorithm for the identification of patients with atrial fibrillation during sinus rhythm: a retrospective analysis of outcome prediction. The Lancet, 394(10201), pp. 861–867.
- Bengio, Y., Simard, P. and Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), pp. 157–166.
- Esteva, A. et al. (2019). A guide to deep learning in healthcare. Nature Medicine, 25(1), pp. 24–29.
- Goldberger, A.L. et al. (2000). PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. Circulation, 101(23), pp. e215–e220.
- Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), pp. 1735–1780.
- Komorowski, M. et al. (2018). The Artificial Intelligence Clinician learns optimal treatment strategies for sepsis in intensive care. Nature Medicine, 24(11), pp. 1716–1720.
- Moody, G.B. and Mark, R.G. (2001). The impact of the MIT-BIH Arrhythmia Database. IEEE Engineering in Medicine and Biology Magazine, 20(3), pp. 45–50.
- Paszke, A. et al. (2019). PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems, 32, pp. 8024–8035.
- Rumelhart, D.E., Hinton, G.E. and Williams, R.J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), pp. 533–536.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




