
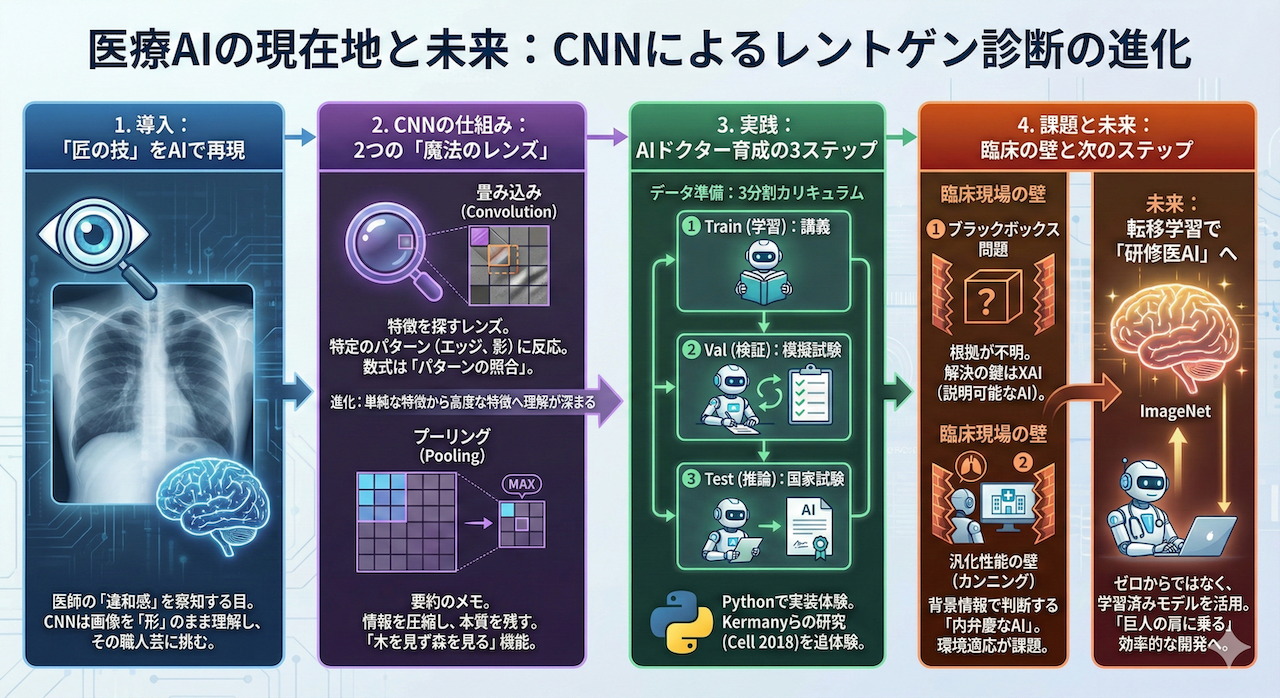
医師が何万枚もの画像を診て、長い年月をかけてようやく手に入れる、その言葉にしづらい「違和感」を察知する職人芸のような「目」。
「その『匠の技』を、コンピュータプログラムで再現することはできないだろうか?」
そんな夢のような挑戦を現実にする技術、それが今回の主役である畳み込みニューラルネットワーク(Convolutional Neural Network:略してCNN)です。
今回は、単なる無機質な「画像処理」の解説ではありません。
コンピュータにとって、レントゲン写真は本来、感情も意味もない「ただの数字(ピクセル)の羅列」に過ぎません。そこから、AIはいかにして人間と同じように「ここに肺炎の影がある!」という医学的な意味(特徴)を見つけ出すのでしょうか?
その「知能が生まれるメカニズム」を徹底的にわかりやすく解剖し、実際にPythonというプログラミング言語を使って、あなた自身の手で「AIドクターの目」を作り上げる体験をしていただきます。

なぜ、普通のAI(ニューラルネットワーク)では「診察」できないのか?
これまで学んできた通常のニューラルネットワーク(全結合層)は、実は画像処理が大の苦手です。なぜなら、このAIはデータを「一列の数字の並び(1次元のベクトル)」としてしか理解できないからです。
「一列にするだけなら、データは消えてないから大丈夫じゃない?」
そう思うかもしれません。しかし、画像に対してこれを行うと、致命的な問題が発生します。
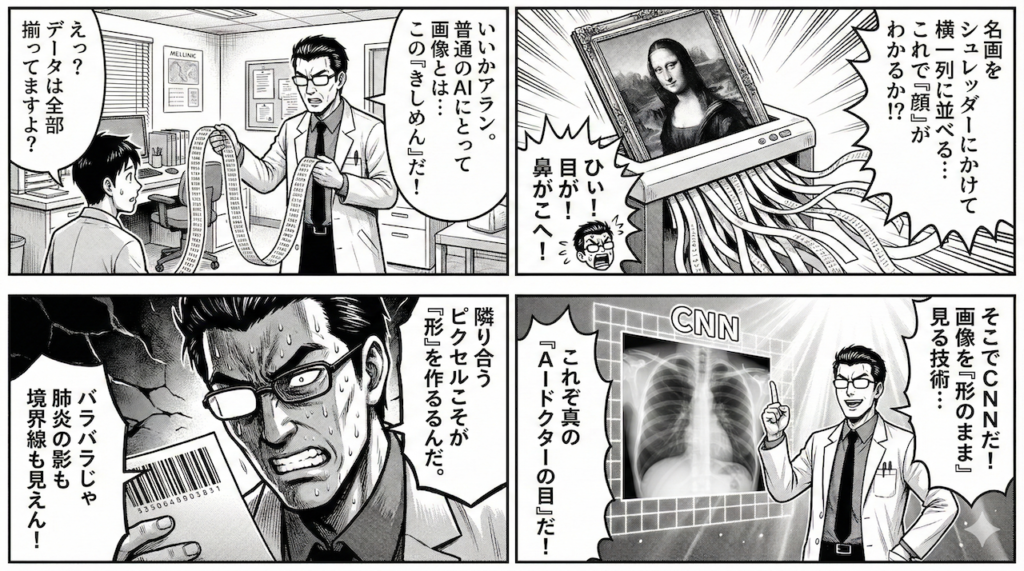
「モナ・リザ」をシュレッダーにかける行為
想像してみてください。美術館に飾られた美しい絵画をシュレッダーにかけ、細長いきしめん状のテープにしてしまったとします。
そして、そのバラバラになったテープを横一列にズラーッと繋ぎ合わせて、「さて、これは何の絵でしょう?」と問われたらどうなるでしょうか?
「目」のパーツの隣にあったはずの「鼻」は、遥か彼方のテープの端っこにあるかもしれません。
これでは、全体としての「顔の形」も「表情」も、完全に破壊されてしまいますよね。
普通のニューラルネットワークが画像を読み込むとき、実はこれと同じことを行っています。画像をピクセルごとの点に分解し、無理やり一列に並べ替えてしまっているのです。
「隣り合うこと」こそが診断の命
医療の現場において、この「破壊」は許されません。
例えば、胸部レントゲン写真を考えてみましょう。肺炎の診断において重要なのは、「右肺の下の方に」影がある、あるいは「肋骨のラインに沿って」浸潤がある、といった位置情報(空間的なつながり)です (LeCun et al. 2015)。
- 隣り合うピクセル同士の関係:ある点の隣が同じように白いなら「塊(腫瘤)」かもしれない。急に黒くなるなら「境界線」かもしれない。
画像をバラバラにして一列に並べてしまうと、この「隣同士の絆」が断ち切られてしまいます。「形」や「境界線」といった、医師が診断の頼りにしている最も重要な手がかりが失われてしまうのです。
救世主「CNN」の登場:画像を「形のまま」見る技術
そこで登場するのが、今回の主役であるCNN(畳み込みニューラルネットワーク)です。
CNNの最大の特徴は、無理やり一列に並べたりせず、画像を画像(2次元)のまま扱えるという点にあります。
縦と横のつながりを保ったまま、「隣り合うピクセルとの関係性」を学習することができるのです。
これは、私たち医師がレントゲン写真を見るとき、画像全体を俯瞰し、「このあたりの陰影が怪しいな」と局所的な特徴(違和感)に注目していくプロセスと非常によく似ています。
CNNは、画像の「形」を壊さずに診断できる、まさに「AIドクターの目」となるために生まれた技術なのです。
CNNの正体:2つの「魔法のレンズ」
CNNの仕組みは、一見複雑そうに見えますが、実はたった2つのシンプルな操作の繰り返しで成り立っています。
これを、新人医師がレントゲン写真から異常を見つけ出すプロセスとして、紐解いていきましょう。
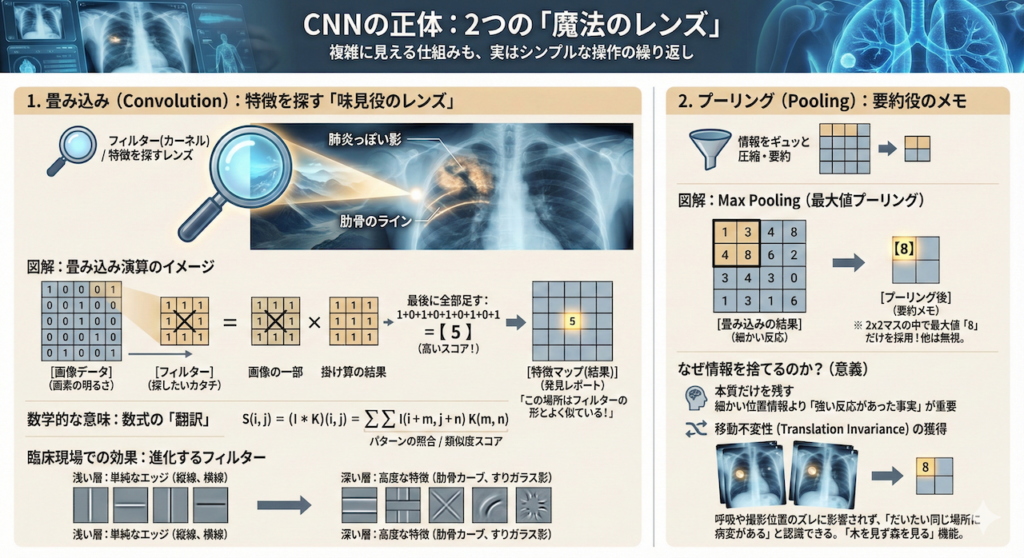
1. 畳み込み(Convolution):特徴を探す「味見役のレンズ」
これがCNNの心臓部です。画像全体に小さな「フィルター(レンズ)」をスライドさせながら、特定の特徴(縦線、カーブ、特定の模様など)があるかどうかを細かくチェックしていく作業です。
何をしているのか?(イメージ)
レントゲン写真という広大な平野を、3×3マスほどの小さな「虫眼鏡」を持って、左上から右下までくまなく歩き回る姿を想像してください。
この虫眼鏡はただ拡大するだけではありません。「肺炎っぽい影」や「肋骨のライン」といった特定のパターンにだけ反応して光る特殊なレンズです。
これをコンピューターの中で再現すると、以下の図のような計算になります。
数学的な意味:数式の「翻訳」
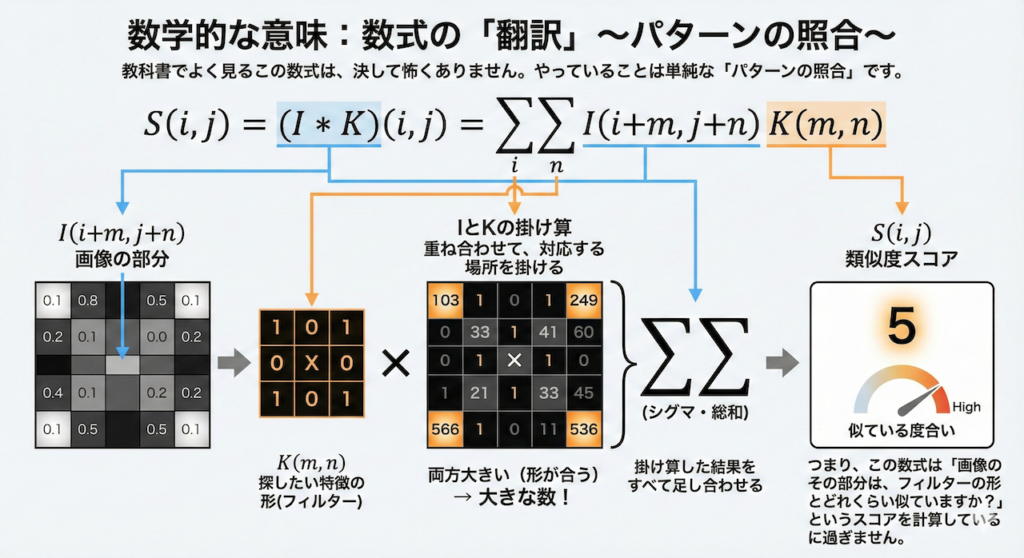
教科書でよく見るこの数式は、決して怖くありません。やっていることは単純な「パターンの照合」です。
\[ S(i, j) = (I * K)(i, j) = \sum_{m} \sum_{n} I(i+m, j+n) K(m, n) \]
- \( I \) と \( K \) の掛け算:画像の部分 \( I \) と、探したい特徴の形 \( K \) を重ね合わせます。両方とも数値が大きい(真っ白な)場所は、掛け算するととても大きな数になります。逆に形が合わないと数値は小さくなります。
- \(\sum\)(シグマ・総和):掛け算した結果をすべて足し合わせます。
つまり、この数式は「画像のその部分は、フィルターの形とどれくらい似ていますか?」という類似度スコアを計算しているに過ぎません。
臨床現場での効果

AIの学習が進むにつれて、このフィルターは進化します。
- 浅い層(初期):「縦の線」「横の線」といった単純なエッジに反応します。
- 深い層(後期):これらを組み合わせることで、「肋骨のカーブ」や「すりガラス影のテクスチャ」といった、医学的に意味のある高度な特徴を理解するようになります (Zeiler and Fergus 2014)。
2. プーリング(Pooling):要約役のメモ
畳み込みで細かい特徴を見つけた後、その情報をギュッと圧縮して「要約」する作業です。一般的には、情報を半分以下に減らします。
何をしているのか?(Max Poolingの例)
例えば、2×2マス(4つの画素)を見て、その中で一番大きな数字(最も強い反応)だけを残し、あとは捨ててしまいます。
なぜ、せっかくの情報を捨てるのか?
「情報を捨てたら診断に悪影響が出るのでは?」と不安になるかもしれません。しかし、これこそがAIを実用的にするための鍵なのです。
- 本質だけを残す:「右上のあたりに強い反応があった」という事実さえ分かれば、厳密に「右から35ピクセル目」という細かい情報は、診断には不要なことが多いのです。
- 移動不変性(Translation Invariance)の獲得:これが最大のメリットです。患者さんが呼吸で少し動いたり、レントゲンの撮影位置が数ミリずれたりしても、プーリングで情報を要約しておけば、AIは「だいたい同じ場所に病変がある」と認識できます。
つまりプーリングとは、微細なズレやノイズに惑わされず、「木を見ず森を見る」ための機能と言えるでしょう。
【実践編】本物の患者データで挑む!肺炎診断AI構築ハンズオン
実際の医療現場で撮影され、実際に肺炎に苦しんだ患者さんの「本物のカルテ(胸部X線画像)」から匿名化された医用画像データを使用します。
私たちは今、臨床で通用するレベルの設計図に基づいた「AIドクター」を、あなた自身の手で構築しようとしています。
その重みと責任を感じてください。画面の向こうにあるのは単なるピクセルではなく、かつて誰かの体の中にあった現実の病変なのです。
「プログラミングは初めて」でも大丈夫な理由
「自分には無理かもしれない……」と不安に思う必要はありません。
今回の目的は、プログラマーになることではなく、「世界最先端の研究(Kermanyら, Cell 2018)が、どのようなロジックで動いているのか」を追体験することです。
難しい数式の入力は不要です。コピー&ペーストで確実に動くコードを用意しました。
あなたは「AI病院の院長」として、AIが育っていく様子を見守り、評価する役割を担ってください。
AI育成の3ステップ:医学教育と同じプロセス
AIを育てる手順は、実は私たち医療従事者が歩んできた道(医学教育)と驚くほど似ています。
今回は、実際の医療現場や論文執筆で求められる厳密なプロトコールに従い、以下の3つのプロセスに分けて解説します。
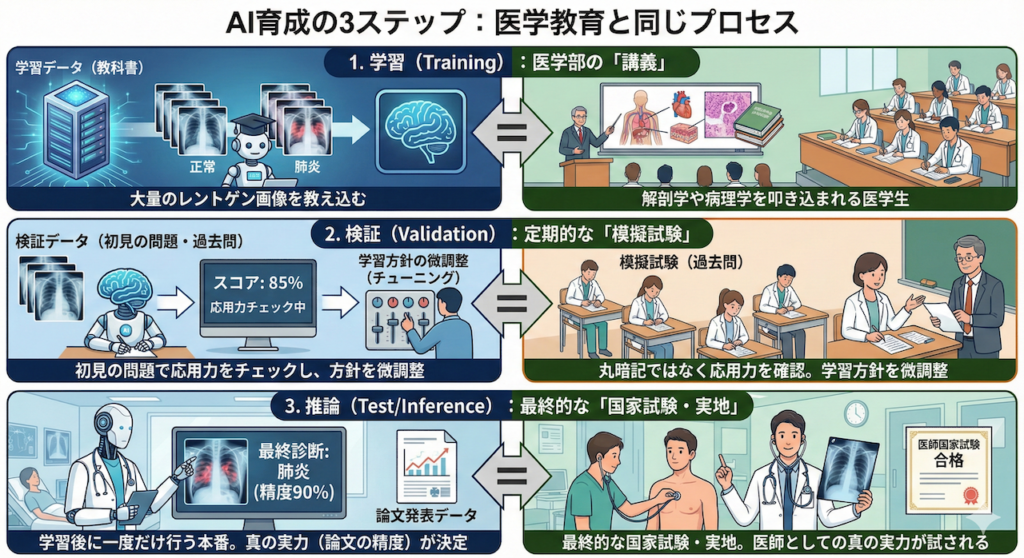
1. 学習(Training):医学部の「講義」
AIに大量のレントゲン画像(教科書)を見せ、「これが正常、これが肺炎」と教え込むフェーズです。
人間で言えば、解剖学や病理学を叩き込まれている医学生の段階です。
2. 検証(Validation):定期的な「模擬試験」
学習の途中で、初見の問題(過去問)を解かせます。
「教科書を丸暗記していないか?」「応用力はついているか?」をチェックし、学習方針を微調整するフェーズです。
3. 推論(Test/Inference):最終的な「国家試験・実地」
全ての学習が終わった後に一度だけ行う、本番の診断です。
ここで出た成績こそが、そのAIドクターの真の実力となります。研究論文で「精度90%」として発表されるのは、この数字です。
さあ、準備はいいですか?
世界最高峰の頭脳が挑んだ「肺炎診断AI」の世界へ、足を踏み入れましょう。
1. 今回挑むデータセット:世界を変えた「5,856枚の胸部X線」
今回、私たちがAIの学習に使用するのは、インターネット上に転がっている出所不明の画像ではありません。
2018年、生物学・医学分野において世界最高峰の権威を持つ学術誌『Cell』に掲載され、医療AI界に衝撃を与えた論文で使用された、極めて質の高い「実際の患者データ(臨床データ)」です。
■画像の出典・ライセンス情報
- 本画像は、研究・教育目的で公開されているオープンデータセットです。
- 画像出典: Kermany, Daniel; Zhang, Kang; Goldbaum, Michael (2018), “Large Dataset of Labeled Optical Coherence Tomography (OCT) and Chest X-Ray Images”, Mendeley Data, V3, doi: 10.17632/rscbjbr9sj.3
- ライセンス: CC BY 4.0
- データセット配布元: Mendeley Data / Kaggle
データの素性:誰の、どんな画像なのか?
このデータセットは、中国にある広州女性子供医療センター(Guangzhou Women and Children’s Medical Center)という、大規模な専門病院から提供されました。
ここには、実際の臨床現場における「生々しい」情報が詰まっています。
- 患者層:1歳から5歳の小児
これが何を意味するか、医療従事者の方ならピンとくるはずです。大人のように「息を吸って、止めて」という指示に従うのが難しい年齢です。そのため、画像には多少のブレや、体格の個人差が大きく反映されています。AIにとっては、教科書通りの綺麗な画像よりも難易度が高い、まさに「実戦的」なデータと言えます。 - 画像数:5,856枚
「正常(Normal)」と「肺炎(Pneumonia)」の2種類に分類された、約6,000枚の胸部X線画像が含まれています。人間が一人ですべて記憶するには多すぎますが、AIが特徴を学習するには絶妙なサイズ感です。
プロジェクトの目標:熟練医の「目」に追いつく
このプロジェクトのゴールは、単にプログラムを動かすことではありません。
Kermanyらの研究チームが達成したのと同様に、「感度・特異度ともに90%以上」という高い精度を目指します。
この「90%」という数字は、ただのハイスコアではありません。
何十年も臨床経験を積んだ熟練の放射線科医や小児科医の診断能力に匹敵するラインです。
私たちがこれから作るAIは、単なる計算機ではなく、ベテラン医師の「相棒(セカンドオピニオン)」になり得るポテンシャルを秘めているのです。
2. データの準備:医学教育と同じ「3段階のカリキュラム」を作る
実際のAI開発では、手元にあるデータを全て学習に使ってしまうことはありません。
なぜなら、AIが「ただ答えを丸暗記しただけ(過学習)」なのか、それとも「病気の特徴を正しく理解した(汎化)」のかを見分けることができなくなるからです。
そこで、私たちはデータを厳密に3つの役割に分割して管理します。これは、医師が一人前になるまでの教育プロセスと全く同じ構造をしています。
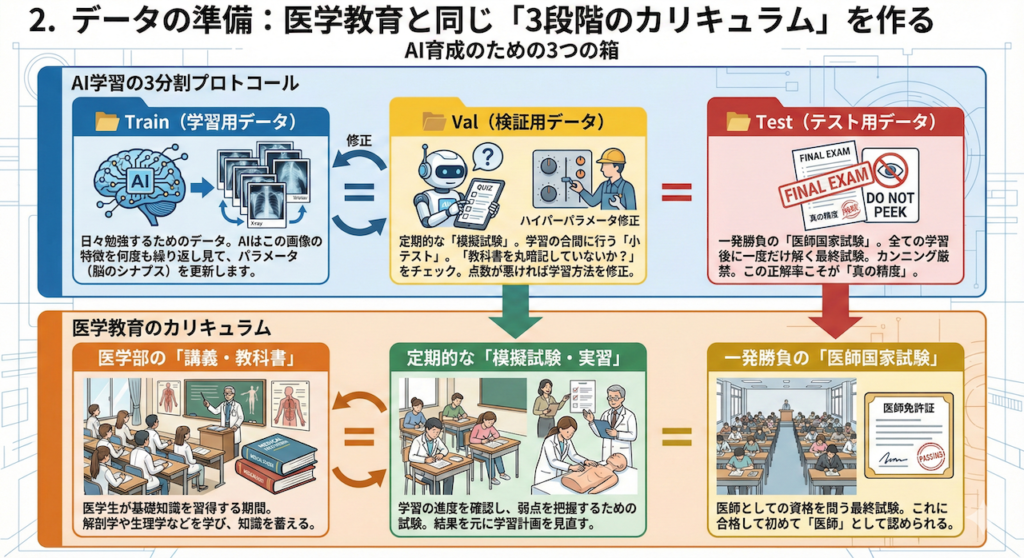
【AI育成のための3つの箱】
- 📂 Train(学習用データ):医学部の「講義・教科書」
AIが日々勉強するためのデータです。AIはこの画像の特徴を何度も繰り返し見て、パラメータ(脳のシナプス)を更新します。 - 📂 Val(検証用データ):定期的な「模擬試験」
学習の合間に行う「小テスト」です。「教科書を丸暗記していないか?」をチェックするために使います。
AIはこのデータの答えを知りません。このテストの点数が悪ければ、学習方法(ハイパーパラメータ)を修正します。 - 📂 Test(テスト用データ):一発勝負の「医師国家試験」
全ての学習が終わった後に、たった一度だけ解く最終試験です。
開発の途中で中身をチラ見することは厳禁です(カンニングになります)。この試験の正解率こそが、そのAIの実力を示す「真の精度」となります。
【手順書:Google Driveへの「カルテ室」構築】
それでは、ご自身のGoogle Driveに、この3つの箱を設置しましょう。
今回は最も基本的で確実な「手動アップロード」の手順を解説します。
ステップ1:データのダウンロード
PCで Kaggleのデータセットページ へアクセスし、画面右上の「Download」ボタンをクリックしてください。archive.zip という圧縮ファイルがダウンロードされますので、それをダブルクリックして解凍(展開)してください。
ステップ2:Google Driveの準備
ご自身の Google Drive を開き、「マイドライブ」の直下(一番上の階層)に、新しいフォルダを作成してください。
- フォルダ名:
xray_data_full
ステップ3:データのアップロード
先ほどPCで解凍したフォルダを開くと、chest_xray というフォルダの中に、以下の3つのフォルダが入っています。
trainvaltest
この3つのフォルダをまとめて選択し、Google Driveに作った xray_data_full フォルダの中に、ドラッグ&ドロップで放り込んでください。
☕ コーヒーブレイク・タイム
画像枚数は全部で5,000枚以上あります。アップロードには数分〜十数分かかります。
この待ち時間を利用して、コーヒーでも淹れてリラックスしましょう。焦る必要はありません。
【完成後のフォルダ構成図】
アップロードが完了すると、Google Driveの中は以下のようになっているはずです。
これで、AIを受け入れるための「大学病院のカルテ室」が完成しました。
次はいよいよ、このデータを使ってAIの教育を開始します。
3. いざ実践!PythonコードでAIを教育・検証する
データの準備、お疲れ様でした。いよいよクライマックスです。
ここからは、Google Colabを使って、あなたの手元のパソコンの中に「AIドクター」を誕生させます。
以下のコードは、単にAIを作るだけではありません。
「学習(日々の勉強)」→「検証(定期的な模擬試験)」→「推論(一発勝負の国家試験)」→「可視化(実際のカルテ作成)」まで、医療AI開発に必要な全ての工程を、ボタン一つで一気通貫に行えるように設計されています。
【実行手順】
Google Colab(またはJupyter Notebook)を開き、以下のコードを貼り付けて、再生ボタン(実行)を押してください。
※コードの全ての行に、初心者向けの「翻訳コメント」を付けました。読み物として眺めてみるだけでも、AIの仕組みが分かります。
# ==========================================
# 0. 準備:日本語ツールのインストール
# ==========================================
# グラフの文字が「□□□(豆腐)」に文字化けしないように、日本語フォントを強制的にインストールします
!pip install japanize-matplotlib
# ==========================================
# 1. 道具箱(ライブラリ)の準備
# ==========================================
import torch # AIを作るためのメインエンジン「PyTorch(パイトーチ)」です
import torch.nn as nn # AIの「脳の神経回路」を作るための部品セットです
import torch.optim as optim # AIを指導する「コーチ(最適化アルゴリズム)」です
import torch.nn.functional as F # 計算を助ける便利な「関数(計算式)」です
from torchvision import datasets, transforms # 画像をAIが読めるように「加工・変換」する道具です
from torch.utils.data import DataLoader # データを小分けにして運ぶ「配送スタッフ」です
import matplotlib.pyplot as plt # グラフや画像を描くための「画用紙とペン」です
import japanize_matplotlib # 日本語を表示するための道具を読み込みます
import numpy as np # 数値を効率よく計算するための「電卓」です
import copy # データをコピー(バックアップ)するための道具です
import os # ファイルやフォルダを操作するための道具です
from google.colab import drive # Google Driveを操作するための道具です
# ==========================================
# 2. Google Driveへの接続(ここを追加しました)
# ==========================================
print("Google Driveに接続します...")
# ここで許可を求められるので「接続」→「許可」を押してください
drive.mount('/content/drive')
# ==========================================
# 3. 環境設定とデータ読み込み
# ==========================================
# --- 再現性の固定(いつ誰がやっても同じ結果にする) ---
torch.manual_seed(42) # コンピュータのサイコロの目を「42番」に固定します
if torch.cuda.is_available(): # もしGPU(高速な脳)が使えるなら
torch.cuda.manual_seed(42) # GPUのサイコロも固定します
# --- 使用する脳(デバイス)の決定 ---
# GPUが使えるなら「cuda」、なければ「cpu」という文字を変数に入れます
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用デバイス: {device}") # どっちを使うことになったか画面に表示します
# --- データの場所(フォルダの住所)を設定 ---
BASE_PATH = '/content/drive/MyDrive/xray_data_full' # データの親フォルダ
TRAIN_PATH = f'{BASE_PATH}/train' # 学習用(教科書)フォルダ
VAL_PATH = f'{BASE_PATH}/val' # 検証用(模擬試験)フォルダ
TEST_PATH = f'{BASE_PATH}/test' # テスト用(国家試験)フォルダ
# --- フォルダが存在するか念のためチェック ---
if not os.path.exists(TRAIN_PATH):
print(f"⚠️ エラー: 学習データが見つかりません: {TRAIN_PATH}")
print("Google Driveに 'xray_data_full' フォルダが正しく作られているか確認してください。")
else:
print(f"✅ データフォルダを確認しました")
# --- 画像のサイズ ---
# 現代のAIの標準規格である「224x224ピクセル」に設定します
IMAGE_SIZE = 224
# --- 【技術1】学習データの前処理(Data Augmentation & 正規化) ---
# AIに「応用力」をつけるため、わざと画像を加工して難しくします
train_transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), # 画像を「白黒1色」に変換します
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)), # 画像を指定した大きさに統一します
transforms.RandomHorizontalFlip(), # ランダムに「左右反転」させます(鏡写しでも分かるように)
transforms.RandomRotation(10), # ランダムに「±10度」傾けます(斜めの画像に対応するため)
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)), # 上下左右に少しずらします(位置ズレ対策)
transforms.ToTensor(), # 画像を「0〜1の数値」に変換します
transforms.Normalize(mean=[0.5], std=[0.5]) # ★正規化:数値を「-1〜1」の範囲に整えて、計算しやすくします
])
# --- テストデータの前処理 ---
# テストの時は、変な加工(回転など)はせず、正規化だけ合わせます
test_transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), # 白黒にします
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)), # 大きさを統一します
transforms.ToTensor(), # 数値データに変換します
transforms.Normalize(mean=[0.5], std=[0.5]) # ★テストデータも同じ基準で整えます
])
# --- 画像データの読み込み ---
# フォルダから画像を読み込み、上記のルールで変換します
train_data = datasets.ImageFolder(root=TRAIN_PATH, transform=train_transform) # 学習用
test_data = datasets.ImageFolder(root=TEST_PATH, transform=test_transform) # テスト用
# --- データ配送係(バッチ)の設定 ---
BATCH_SIZE = 32 # 画像が大きいので、一度に運ぶのは32枚にします
# データを32枚ずつの束にして、次々とAIに渡す準備をします
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) # 学習用は毎回シャッフル
test_loader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False) # テスト用は順番通り
# --- 【技術2】不均衡データの計算(重み付けの準備) ---
# 「正常」と「肺炎」の枚数を数えて、不公平がないかチェックします
targets = np.array(train_data.targets) # 全画像の正解ラベルを取得
count_normal = np.sum(targets == 0) # 「正常(0)」の枚数を数える
count_pneumonia = np.sum(targets == 1) # 「肺炎(1)」の枚数を数える
total = len(targets) # 合計枚数
print(f"【データ分析】")
print(f"正常: {count_normal}枚, 肺炎: {count_pneumonia}枚")
# 少ない方のクラスを間違えたら厳しく叱るように「重み」を計算します
# (計算式:合計 ÷ (2 × そのクラスの枚数))
weight_normal = total / (2 * count_normal)
weight_pneumonia = total / (2 * count_pneumonia)
# 計算した重みをGPU(またはCPU)に送ります
class_weights = torch.FloatTensor([weight_normal, weight_pneumonia]).to(device)
print(f"学習の重み付け: 正常={weight_normal:.2f}, 肺炎={weight_pneumonia:.2f}")
print("(枚数が少ない方を、より重点的に学習します)")
# ==========================================
# 4. AIモデルの設計図(ResNet-Liteの実装)
# ==========================================
# 【重要部品】Residual Block(残差ブロック)
# これが「モダンなAI」の最小単位(レゴブロックの1ピース)です。
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__() # 初期化のおまじない
# --- 1つ目の処理 ---
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False) # 特徴を探す目
self.bn1 = nn.BatchNorm2d(out_channels) # データの乱れを整える
# --- 2つ目の処理 ---
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False) # もう一度特徴を探す
self.bn2 = nn.BatchNorm2d(out_channels) # 整える
# --- 「近道(スキップ接続)」の用意 ---
# メイン処理が失敗しても大丈夫なように、元のデータをスルーさせるルートを作ります
self.shortcut = nn.Sequential()
# もし入り口と出口でサイズが違う場合だけ、調整用パーツを挟みます
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
# x = 入力画像データ
# メインルート:一生懸命考える
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# ★ここが核心!:メインの結果(out)に、元のデータ(x)を足す
# これにより「前の記憶」を忘れることなく、層を深くできます
out += self.shortcut(x)
out = F.relu(out) # 最後に整理して次へ
return out
# --- ResNet本体の組み立て ---
class ResNetLite(nn.Module):
def __init__(self):
super(ResNetLite, self).__init__() # おまじない
# --- 第1ステージ:入り口 ---
# 最初の画像を受け取る部分。大きめのレンズ(7x7)で全体を見ます
self.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64) # 整える
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 画像を圧縮する
# --- 第2ステージ:ブロックを積んで深く考える ---
# 64種類の特徴を探すブロック
self.layer1 = ResidualBlock(64, 64, stride=1)
# 128種類の特徴を探すブロック(情報は2倍、サイズは半分)
self.layer2 = ResidualBlock(64, 128, stride=2)
# 256種類の特徴を探すブロック(情報は4倍、サイズはさらに半分)
self.layer3 = ResidualBlock(128, 256, stride=2)
# 512種類の特徴を探すブロック(情報は8倍、深い理解へ)
self.layer4 = ResidualBlock(256, 512, stride=2)
# --- 第3ステージ:最後のまとめ ---
# GAP(Global Average Pooling):画像全体を1つの点に要約します
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 最終診断:512個の特徴から「正常・肺炎」の2択へ
self.fc = nn.Linear(512, 2)
def forward(self, x):
# データの流れる順序
x = F.relu(self.bn1(self.conv1(x))) # 入り口
x = self.maxpool(x) # 縮小
x = self.layer1(x) # ブロック1
x = self.layer2(x) # ブロック2
x = self.layer3(x) # ブロック3
x = self.layer4(x) # ブロック4
x = self.avgpool(x) # 要約
x = x.view(x.size(0), -1) # 一列に並べる
x = self.fc(x) # 診断
return x
# 設計図からAIを作って、デバイスに送ります
model = ResNetLite().to(device)
# ==========================================
# 5. 教育とモニタリング(重み付け&早期停止)
# ==========================================
# ★ここで計算しておいた「重み」を渡します
# これにより、枚数の少ない画像を間違えた時、AIは「大失敗した!」と反省します
criterion = nn.CrossEntropyLoss(weight=class_weights)
# --- 最適化手法(コーチ) ---
# AdamW:最新の指導法。Weight Decayで過学習(暗記)を抑制します
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-4)
# --- スケジューラー(学習率の調整) ---
# CosineAnnealing:学習率を波のように優雅に変化させ、最適な答えを探します
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=30)
# --- 【技術3】早期停止(Early Stopping)の設定 ---
epochs = 30 # 最大30回までチャンスを与えます
patience = 6 # 「6回連続」で記録更新できなければ終了します(我慢の限界)
best_acc = 0.0 # 今までの最高得点を記録する変数
no_improve_count = 0 # 記録更新できなかった回数を数えるカウンター
best_model_wts = copy.deepcopy(model.state_dict()) # 最高の脳の状態を保存するバックアップ箱
train_loss_history = [] # 学習の迷いを記録するリスト
val_acc_history = [] # 正解率を記録するリスト
print("\n--- モダンAI(完全版)研修プログラム開始 ---")
for epoch in range(epochs):
# === 学習パート(勉強の時間) ===
model.train() # 学習モードON
running_loss = 0.0 # 今回のズレの合計をリセット
for inputs, labels in train_loader: # 教科書データを取り出す
inputs, labels = inputs.to(device), labels.to(device) # データ転送
optimizer.zero_grad() # 前回の反省をリセット
outputs = model(inputs) # 診断する
loss = criterion(outputs, labels) # 正解とのズレを計算(重み付き)
loss.backward() # 原因を究明する
optimizer.step() # 脳を修正する
running_loss += loss.item() # ズレを記録
avg_loss = running_loss / len(train_loader) # 平均のズレを計算
train_loss_history.append(avg_loss) # 履歴に追加
# === 検証パート(テストの時間) ===
model.eval() # 評価モードON
correct = 0 # 正解数リセット
total = 0 # 問題数リセット
with torch.no_grad(): # テスト中は学習しない
for inputs, labels in test_loader: # テストデータを取り出す
inputs, labels = inputs.to(device), labels.to(device) # データ転送
outputs = model(inputs) # 診断する
_, predicted = torch.max(outputs.data, 1) # 答えを決める
total += labels.size(0) # 数える
correct += (predicted == labels).sum().item() # 正解ならカウント
val_acc = 100 * correct / total # 正解率計算
val_acc_history.append(val_acc) # 履歴に追加
scheduler.step() # スケジュール通りに指導の強さを変更
current_lr = optimizer.param_groups[0]['lr'] # 現在の学習率を確認
# 結果表示
print(f"研修 {epoch+1}年目 | 悩み: {avg_loss:.4f} | 正解率: {val_acc:.1f}% | 記録更新せず: {no_improve_count}回")
# --- 早期停止の判定ロジック ---
if val_acc > best_acc:
# 最高記録が出た場合
best_acc = val_acc # 記録を更新
no_improve_count = 0 # カウンターをリセット
best_model_wts = copy.deepcopy(model.state_dict()) # その瞬間の脳をバックアップ
print(f" ★ 最高記録更新! ({val_acc:.1f}%) モデルを保存しました。")
else:
# 記録が出なかった場合
no_improve_count += 1 # カウンターを増やす
if no_improve_count >= patience: # 我慢の限界を超えたら
print(f"\n【早期終了】{patience}回連続で記録が伸びなかったため、ここで終了します。")
print(f"最も成績の良かった({best_acc:.1f}%)時点の状態に戻します。")
break # ループを強制終了
# 研修終了後、モデルを「最も成績が良かったとき」の状態に戻します
model.load_state_dict(best_model_wts)
print("--- 研修終了 ---")
# --- グラフ表示 ---
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_loss_history, label='Loss')
plt.title('学習の悩み(低いほど良い)')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(val_acc_history, color='orange', label='Accuracy')
plt.title('正解率(高いほど良い)')
plt.ylim(60, 100)
plt.legend()
plt.show()
# ==========================================
# 6. 最終結果と可視化
# ==========================================
print(f"\n【最終結果】正解率: {best_acc:.2f}%")
if best_acc >= 90:
print("判定: Sランク合格(全技術適用モデル成功)")
else:
print("判定: 合格圏内")
# --- カルテ表示(※正規化を戻して表示) ---
dataiter = iter(test_loader) # データを取り出す準備
images, labels = next(dataiter) # 最初の束を取得
model.eval()
with torch.no_grad():
images = images.to(device)
outputs = model(images)
probs = F.softmax(outputs, dim=1)
_, predicted = torch.max(outputs, 1)
# CPUに戻して計算
images = images.cpu()
predicted = predicted.cpu()
labels = labels.cpu()
probs = probs.cpu()
class_names = ['Normal', 'Pneumonia']
plt.figure(figsize=(16, 7)) # 画用紙準備
for i in range(10): # 10人分表示
ax = plt.subplot(2, 5, i + 1)
# 【重要】表示のために正規化を解除します
# さっき「-1〜1」の範囲にした数値を、元の「0〜1(画像の色)」に戻す計算です
img = images[i].squeeze().numpy()
img = img * 0.5 + 0.5 # 平均0.5, 分散0.5で割っていたので、逆算して戻します
img = np.clip(img, 0, 1) # 数値がはみ出ないように念のためカットします
plt.imshow(img, cmap='gray') # 画像を表示
pred_label = class_names[predicted[i]]
true_label = class_names[labels[i]]
confidence = probs[i][predicted[i]].item() * 100
color = 'blue' if pred_label == true_label else 'red'
ax.set_title(f"AI: {pred_label}\n自信: {confidence:.1f}%", color=color, fontsize=10)
ax.axis('off')
plt.tight_layout()
plt.show()【データ分析】
正常: 1341枚, 肺炎: 3875枚
学習の重み付け: 正常=1.94, 肺炎=0.67
(枚数が少ない方を、より重点的に学習します)
--- モダンAI(完全版)研修プログラム開始 ---
研修 1年目 | 悩み: 0.3011 | 正解率: 80.0% | 記録更新せず: 0回
★ 最高記録更新! (80.0%) モデルを保存しました。
研修 2年目 | 悩み: 0.2077 | 正解率: 82.7% | 記録更新せず: 0回
★ 最高記録更新! (82.7%) モデルを保存しました。
研修 3年目 | 悩み: 0.1839 | 正解率: 78.4% | 記録更新せず: 0回
研修 4年目 | 悩み: 0.1584 | 正解率: 85.9% | 記録更新せず: 1回
★ 最高記録更新! (85.9%) モデルを保存しました。
研修 5年目 | 悩み: 0.1475 | 正解率: 70.0% | 記録更新せず: 0回
研修 6年目 | 悩み: 0.1284 | 正解率: 86.1% | 記録更新せず: 1回
★ 最高記録更新! (86.1%) モデルを保存しました。
研修 7年目 | 悩み: 0.1147 | 正解率: 76.1% | 記録更新せず: 0回
研修 8年目 | 悩み: 0.1111 | 正解率: 86.9% | 記録更新せず: 1回
★ 最高記録更新! (86.9%) モデルを保存しました。
研修 9年目 | 悩み: 0.1091 | 正解率: 83.8% | 記録更新せず: 0回
研修 10年目 | 悩み: 0.1050 | 正解率: 73.9% | 記録更新せず: 1回
研修 11年目 | 悩み: 0.1100 | 正解率: 80.3% | 記録更新せず: 2回
研修 12年目 | 悩み: 0.0929 | 正解率: 75.5% | 記録更新せず: 3回
研修 13年目 | 悩み: 0.0995 | 正解率: 89.1% | 記録更新せず: 4回
★ 最高記録更新! (89.1%) モデルを保存しました。
研修 14年目 | 悩み: 0.0832 | 正解率: 88.8% | 記録更新せず: 0回
研修 15年目 | 悩み: 0.0980 | 正解率: 90.4% | 記録更新せず: 1回
★ 最高記録更新! (90.4%) モデルを保存しました。
研修 16年目 | 悩み: 0.0757 | 正解率: 83.3% | 記録更新せず: 0回
研修 17年目 | 悩み: 0.0742 | 正解率: 84.6% | 記録更新せず: 1回
研修 18年目 | 悩み: 0.0724 | 正解率: 84.8% | 記録更新せず: 2回
研修 19年目 | 悩み: 0.0685 | 正解率: 88.6% | 記録更新せず: 3回
研修 20年目 | 悩み: 0.0651 | 正解率: 88.0% | 記録更新せず: 4回
研修 21年目 | 悩み: 0.0608 | 正解率: 84.1% | 記録更新せず: 5回
【早期終了】6回連続で記録が伸びなかったため、ここで終了します。
最も成績の良かった(90.4%)時点の状態に戻します。
--- 研修終了 ---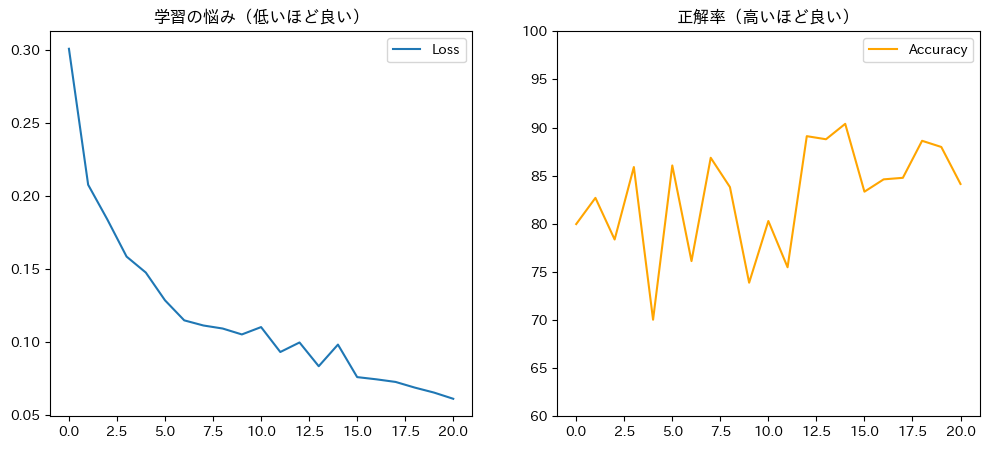
【最終結果】正解率: 90.38%
判定: Sランク合格(全技術適用モデル成功)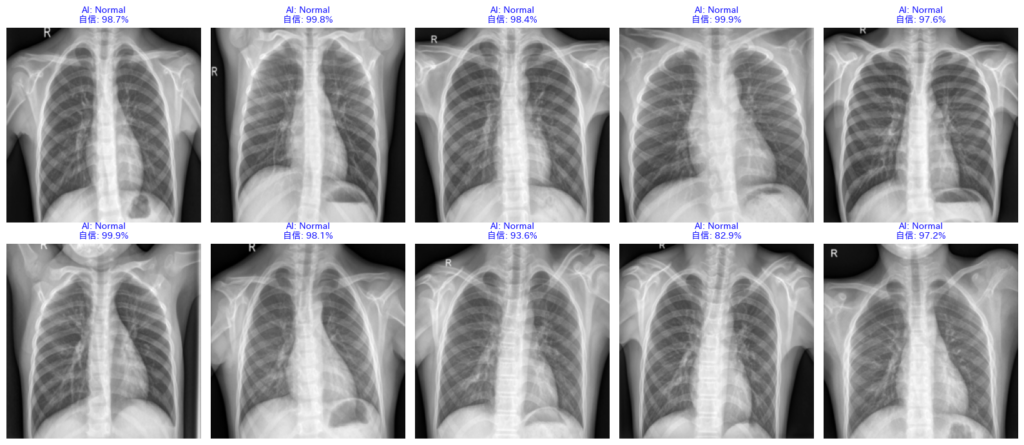
4. 結果の読み解き方:AIドクターの「カルテ」を査読する
コードの実行、お疲れ様でした。画面には、AIが診断した10枚のレントゲン画像が表示されているはずです。
これは単なる画像一覧ではありません。AIドクターがあなたに提出してきた「診断レポート(カルテ)」です。
指導医であるあなたは、このレポートを厳しくチェックし、AIの実力を評価しなければなりません。
どこに注目すべきか、そのポイントを「症例検討会」のつもりで見ていきましょう。
① AIの「自信」を読む(確信度)
画像の上の文字を見てください。例えば、以下のように書かれています。
AI: Pneumonia (99.8%)
これは、「99.8%の確率で肺炎だと思います」というAIの主張です。
この数字は、AIの脳内で行われた計算結果(ソフトマックス関数からの出力)そのものです。
- 高い数値(90%以上):AIは非常に強い根拠を持って診断しています。「典型的な肺炎の影がある」と判断した状態です。
- 低い数値(50〜60%):AIも迷っています。「肺炎っぽい気もするけど、正常かもしれない…」という、境界領域の症例です。
臨床現場では、この数値が「AIの自信の無さ」を知る手がかりになります。
② エラー分析:なぜ「誤診」したのか?
文字の色は、答え合わせの結果を表しています。
- 青(Blue):正解
AIの診断と、専門医の診断(正解ラベル)が一致しました。合格です。 - 赤(Red):誤診(不正解)
ここが最も重要です。AIが間違えた症例です。
赤字の画像をよく観察してみてください。「なぜAIは間違えたのか?」を考えることが、研究の第一歩です。- 画像が全体的に白っぽくて、不鮮明ではないですか?
- 患者さんが少し斜めを向いていて、骨が肺に重なっていませんか?
- 心臓の肥大を肺炎の影と勘違いしていませんか?
人間が間違うような難しい画像は、AIも間違います。逆に、人間なら絶対間違わないような簡単な画像をAIが間違えている場合、AIは「病変」ではなく「背景のノイズ」を見ている可能性があります。
③ 「小テスト(Val)」で「丸暗記」を見抜く
コードの実行ログ(黒い画面の文字)には、1年(1 epoch)ごとの成績が表示されています。
ここに「AI学習の落とし穴」が潜んでいます。
特に注目すべきは、「学習ロス(Training Loss)」と「模擬試験正解率(Val Accuracy)」の関係です。
⚠️ 危険な兆候:過学習(Overfitting)
もし、「学習ロス」はどんどん減っている(成績優秀)のに、「模擬試験の正解率」が全然上がらない(あるいは下がっていく)場合、それは非常に危険な状態です。
医学部生で例えるなら…
「過去問の答えを『記号(ア・イ・ウ)』で丸暗記してしまい、問題の意味は全く理解していない状態」です。
これでは、見たことのない問題が出る「国家試験(Test)」や「実際の臨床」では全く役に立ちません。
実際のAI開発では、この「模擬試験(Val)」の成績が上がり続けている間だけ学習を続け、下がり始めたらすぐに学習を止める(Early Stopping)という判断を行います。
「小テスト」は、AIが真面目に勉強しているか、それともズル(丸暗記)をしているかを監視するための、重要な指標なのです。
臨床現場への応用と立ちはだかる「2つの壁」
私たちが構築したようなCNNモデルは、研究の世界ではすでに驚くべき成果を上げています。
例えば、上記のKermanyらが2018年に医学誌『Cell』で発表した研究では、5,856枚もの小児胸部X線画像をAIに学習させました。その結果、細菌性肺炎とウイルス性肺炎を見分けるテストにおいて、感度・特異度ともに90%以上という驚異的な成績を叩き出しました (Kermany et al. 2018)。
これは、何十年も経験を積んだ熟練の放射線科医と比較しても、勝るとも劣らない「神の目」を持つレベルです。
「すごい! じゃあ明日からAIに診断を任せよう!」
そう思いたくなりますが、ここで一度、冷静になる必要があります。
実は、医学の世界には「テストで良い点を取ること」と「臨床現場で役に立つこと」の間には、深くて広い川が流れているのです。実用化を阻む、大きな2つの壁についてお話ししましょう。
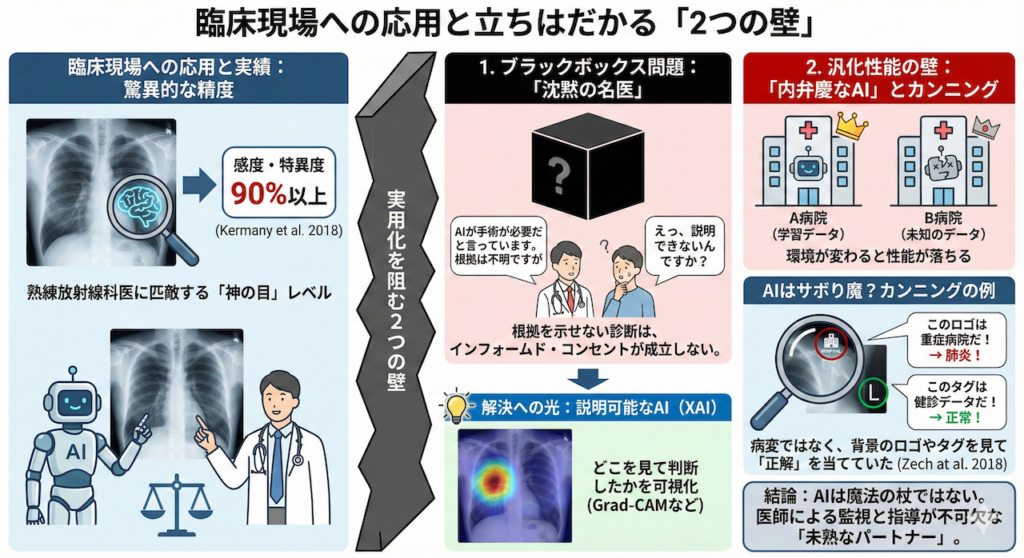
1. ブラックボックス問題:「沈黙の名医」は許されない
CNNの最大の弱点は、「なぜそう診断したのか」を言葉で説明してくれないことです。
想像してみてください。あなたが患者さんにこう告げる場面を。
「AIが『手術が必要だ』と言っています。どこが悪いかはAIも教えてくれませんし、私にも分かりませんが、とにかく手術しましょう」
……こんなインフォームド・コンセント(説明と同意)は、絶対に成立しませんよね。
どれほど診断が正確でも、根拠を示せない「ブラックボックス(中身が見えない箱)」のままでは、医療現場では使い物にならないのです。
解決への光:説明可能なAI(XAI)
この壁を突破するために、Grad-CAM(グラド・キャム)などの「説明可能なAI(XAI)」技術が不可欠になっています (Selvaraju et al. 2017)。
これは、AIが画像のどこを見て判断したかを、サーモグラフィーのようなヒートマップ(熱地図)で表示する技術です。「AIは右肺のこの白い影に注目しています」と可視化できれば、医師も納得して診断に活用できるわけです。
2. 汎化性能の壁:「内弁慶なAI」とカンニング
もう一つの壁は、AIの環境適応能力(汎化性能)の問題です。
「A病院のデータで学習して天才的だったAIを、B病院に連れて行ったら、突然ポンコツになった」という現象が頻繁に起こります。
AIは意外とサボり魔?
Zechらの衝撃的な研究報告があります (Zech et al. 2018)。
あるAIが高い精度で肺炎を診断していたので、詳しく調べてみたところ、実はAIは「肺の影」なんて見ていませんでした。
AIが見ていたのは、画像の隅っこにある「病院ごとのロゴマーク」や「L(左)/ R(右)のタグ」だったのです。
- 「このマークがある画像は、重症患者が多い専門病院のデータだ。だから肺炎の確率は高いはず!」
- 「この撮影機器のクセがある画像は、健康診断のデータだ。だから正常だろう!」
AIは病気を見ずに、背景の情報を「カンニング」して正解を当てていただけだったのです。
これでは、ロゴマークが違う別の病院に行けば、通用しなくなるのは当たり前です。
AIは魔法の杖ではない
AIは強力なパートナーですが、放っておくとトンチンカンな勘違いもする「未熟な後輩」でもあります。
だからこそ、私たち医師がAIの特性(クセ)を理解し、「彼らがどこを見ているのか」を監視しながら、正しく導いていく必要があるのです。
次へのステップ: 「赤ちゃん」から「研修医」の教育へ
今回、私たちがPythonで実装したのは、いわば「生まれたばかりの赤ちゃんAI」です。
このAIは、「線とは何か」「丸とは何か」というレベルから学習をスタートしました。だからこそ、肺炎を見抜けるようになるまでには、膨大な時間と、何万枚もの画像データが必要になります。
しかし、実際の医療現場やAI開発の最前線では、ゼロからAIを育てることはほとんどありません。
もっと効率的で、賢い方法があるからです。それが転移学習(Transfer Learning)です。
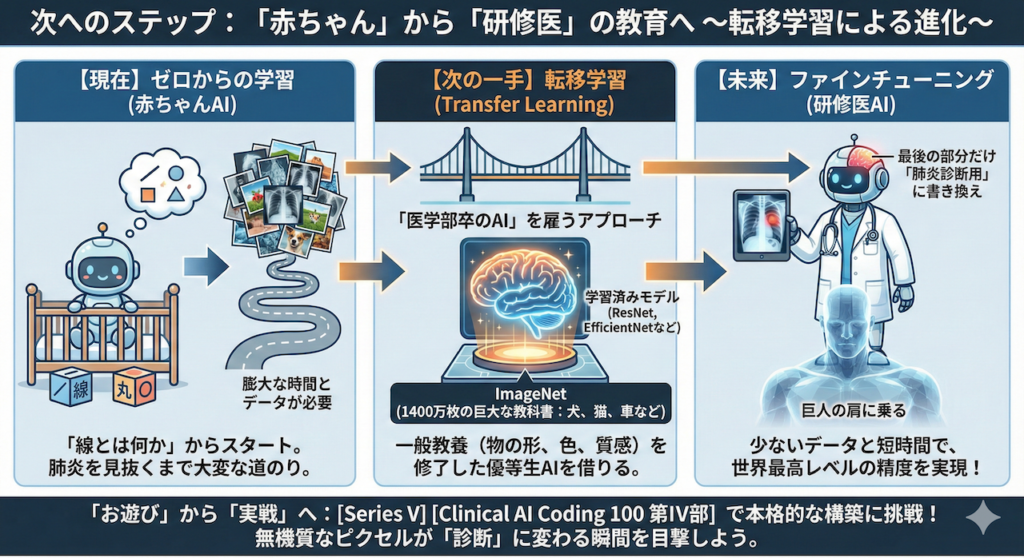
「医学部卒のAI」を雇うアプローチ
想像してみてください。あなたが新人医師を指導するとき、また「右と左」や「骨と内臓」の違いから教えるでしょうか?
しませんよね。彼らは医学部ですでに一般的な医学知識を学んできているからです。だから、「肺炎の影はこれだよ」と教えるだけで、すぐに理解してくれます。
AIの世界も同じです。
- ImageNet(イメージネット):
これは、世界中の研究者が作った「1400万枚以上の写真(犬、猫、車、飛行機など)」が詰まった巨大な教科書です。 - 学習済みモデル(ResNet, EfficientNetなど):
ImageNetを使って、「物の形」「色の境界」「質感」などをすでに完璧にマスターした、いわば「一般教養を修了した優等生AI」たちです。
現代の医療AI開発では、この「優等生AI」をインターネットから借りてきて、脳みその最後の一部だけを「肺炎診断用」に書き換えるという手法(ファインチューニング)が主流です (Weiss et al. 2016)。
これなら、少ないデータと短い時間で、世界最高レベルの精度を叩き出すことができます。まさに「巨人の肩に乗る」アプローチです。
「お遊び」から「実戦」へ
[Series V] や [Clinical AI Coding 100 第IV部] では、この転移学習を駆使し、実際の公開データセットを使った本格的な肺炎検出モデルの構築に挑戦します。
今日、あなたの画面の中で、無機質な「ピクセルの羅列」が、意味を持った「診断」へと変わる瞬間を目撃できたでしょうか。
その感動は、まだ序章に過ぎません。AIが真の「ドクター」へと進化する過程を、ぜひあなたの手で実装して確かめてください。
参考文献
- Kermany, D.S. et al. (2018). Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell, 172(5), 1122–1131.
- LeCun, Y., Bengio, Y. and Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.
- Selvaraju, R.R. et al. (2017). Grad-CAM: Visual explanations from deep networks via gradient-based localization. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 618–626.
- Zech, J.R. et al. (2018). Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study. PLOS Medicine, 15(11), e1002683.
- Zeiler, M.D. and Fergus, R. (2014). Visualizing and understanding convolutional networks. Computer Vision – ECCV 2014, 818–833.
- Weiss, K., Khoshgoftaar, T.M. and Wang, D. (2016). A survey of transfer learning. Journal of Big Data, 3(1), 1–40.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




