

なぜ、今さらプログラミングなのか?
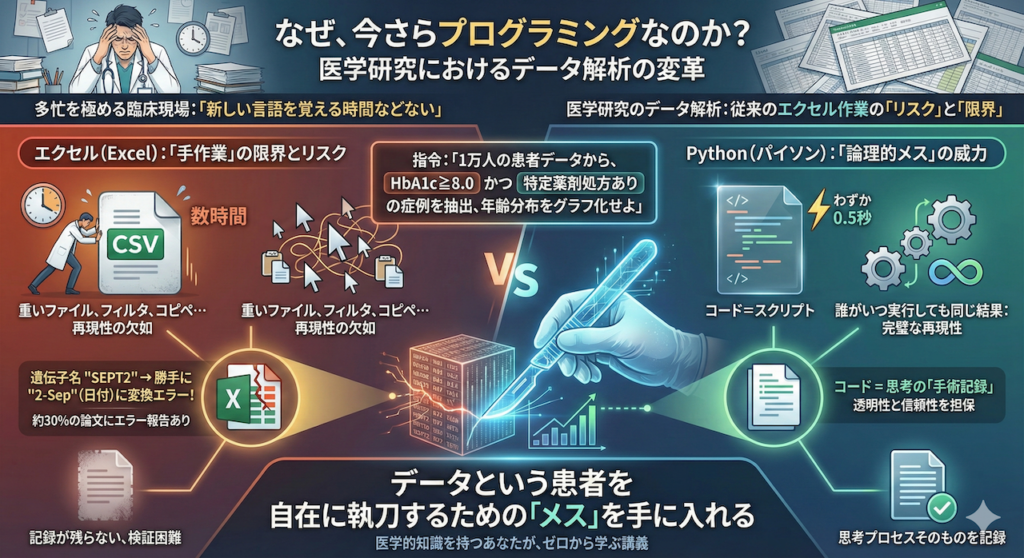
「多忙を極める臨床の現場で、新しい言語を覚える時間などない」。そう思われるのは当然です。しかし、医学研究におけるデータ解析の現場では、従来のエクセル(Excel)作業が抱える「リスク」と「限界」が浮き彫りになっています。
もしあなたが、「1万人の患者データから、HbA1cが8.0以上かつ特定の薬剤が処方されている症例を抽出し、その年齢分布をグラフ化せよ」という解析を任されたと想像してください。
エクセルという「手作業」の限界
エクセルでこれを行う場合、重たいCSVファイルを開き、フィルタをかけ、新しいシートにコピーし、マウスでグラフを描画する…という手順になります。これには数時間を要するだけでなく、「再現性の欠如」という致命的な問題があります。
ある研究によれば、エクセルで遺伝子リストを扱った論文の約30%に、オートフォーマット機能による遺伝子名の変換エラー(例:遺伝子名 “SEPT2” が日付の “2-Sep” に勝手に書き換わる等)が含まれていたことが報告されています。クリックやコピー&ペーストによる手作業は、記録が残らず、後から検証することが極めて困難です。
Pythonという「論理的メス」の威力
一方、Python(パイソン)を使えば、この作業は「指示書(コード)」を数行書くだけで完了します。実行にかかる時間はわずか0.5秒です。
さらに重要なのは、「誰がいつ実行しても、全く同じ結果が得られる」という点です。コードは、あなたの思考プロセスそのものを記録した「手術記録」のようなものであり、研究の透明性と信頼性を担保します。
この講義では、医学的知識を持つあなたが、データという患者を自在に執刀するための「メス」を手に入れる方法を、ゼロから解説します。
[Series P] 🐍 Medical AI with Python : Pythonで学ぶ人工知能の理論と実装

1. そもそも、Python(パイソン)とは何か?
Pythonは、Google検索のアルゴリズムからNASAの惑星探査データの解析、さらにはYouTubeのシステム構築まで、現代のテクノロジーを支える世界標準のプログラミング言語です。
しかし、それ以上に重要なのは、Pythonが「世界の医療AI研究における共通言語(Lingua Franca)」であるという事実です。
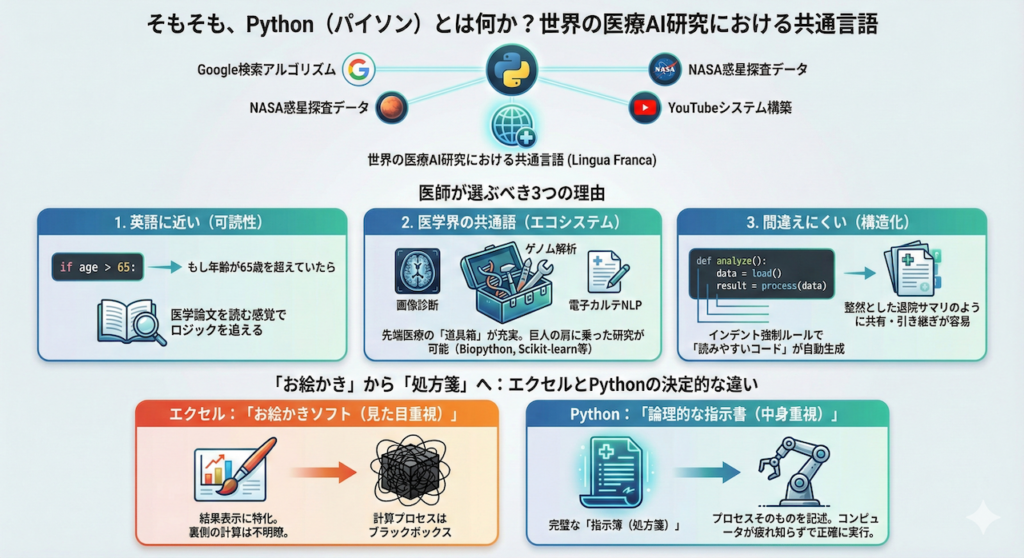
医師が選ぶべき3つの理由
他の言語(C言語やJavaなど)と比較して、Pythonには医師にとって決定的な3つの利点があります。
- 英語に近い(可読性):
Pythonは「人間が読むこと」を最優先に設計されています。例えば、if age > 65:というコードは、「もし年齢が65歳を超えていたら」という自然な英語としてそのまま読めます。複雑な記号が少なく、医学論文を読むような感覚でロジックを追うことができます (Bassett et al. 2019)。 - 医学界の共通語(エコシステム):
画像診断、ゲノム解析、電子カルテの自然言語処理など、先端医療に必要な「道具箱(ライブラリ)」が最も充実しています。世界中の研究者が作った最新の解析ツール(例:BiopythonやScikit-learn)が無料で公開されており、それらを組み合わせるだけで、巨人の肩に乗った研究が可能になります (Virtanen et al. 2020)。 - 間違えにくい(構造化):
Pythonには「インデント(字下げ)を揃えなければ動かない」という厳格なルールがあります。これにより、誰が書いても見た目が整い、論理構造が明確な「読みやすいコード」が強制的に生成されます。これは、フォーマットが統一された退院サマリのように、チームでの共有や引き継ぎを容易にします。
「お絵かき」から「処方箋」へ
エクセルとPythonの決定的な違いは、その目的にあります。
- エクセルは「お絵かきソフト(見た目重視)」: 最終的な結果をきれいに表示することに特化していますが、その裏でどのような計算が行われたかはブラックボックスになりがちです。
- Pythonは「論理的な指示書(中身重視)」: 「データをどう加工し、どう判断するか」というプロセスそのものを記述します。
Pythonでコードを書くことは、コンピュータに対して、曖昧さのない完璧な「指示簿(処方箋)」を発行する行為に他なりません。一度記述すれば、コンピュータは疲れを知らず、指示通りに何度でも正確に実行してくれます (Perkel 2018)。
2. 環境準備:最強の道具箱「Google Colab」を開く
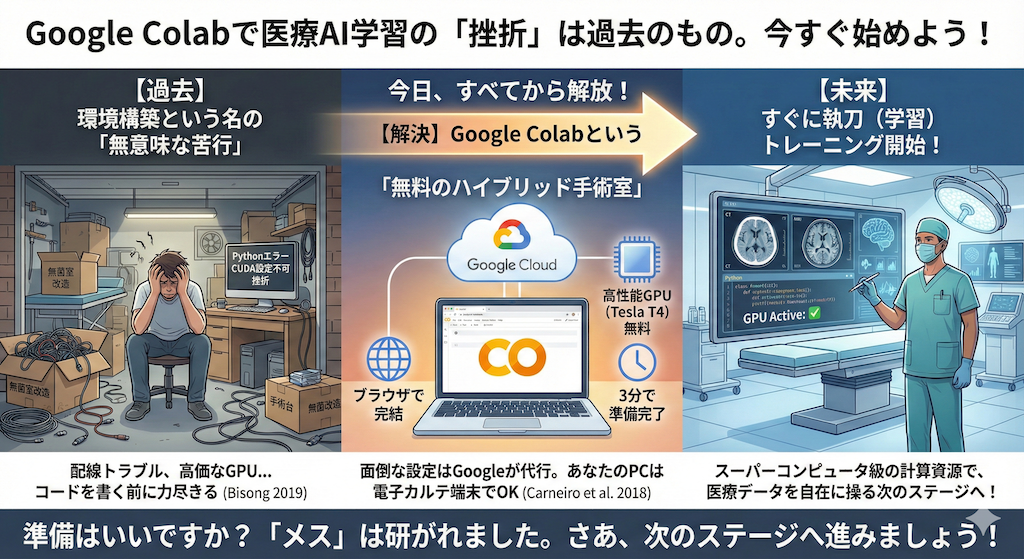
プログラミングを学ぶ際、多くの人が最初に挫折するのは「環境構築」です。自分のパソコンにソフトをインストールし、黒い画面で設定を行う…この段階で嫌になってしまうのです。
しかし、私たちはその泥臭い作業を一切行う必要はありません。なぜなら、「Google Colab(グーグル・コラボ)」があるからです。
Google Colabについては、以下の記事をご参照ください。
ブラウザ上の手術室
Google Colabは、Googleが提供する無料のクラウドサービスです。URLにアクセスするだけで、あなたのブラウザの中に「Pythonがインストール済みの高性能なコンピュータ」が即座に用意されます。
これは言わば、「自前でメスやモニターを買い揃える必要なく、IDカード一枚でフル装備の大学病院の手術室を借りられる」ようなものです。高価なGPU(画像処理装置)も無料で使用でき、院内の古いPCからでも最新のAI解析が可能になります。
最初のコード:特殊器械の取り寄せ
さあ、手術室(Colab)に入りました。基本的な器具は揃っていますが、今回は「グラフを日本語で表示する」という少し特殊な処置を行います。そのための専用器具(ライブラリ)を、SPD(物品物流センター)から取り寄せる必要があります。
以下のコードを実行してみましょう。これがあなたの「最初のオーダー」です。
# 【重要】
# 行の先頭に「#」がついている文章は「コメント」です。
# プログラム(執刀医)はこの行を読み飛ばしますが、
# 人間(助手や未来の自分)への申し送り事項として機能します。
# 日本語フォント対応ライブラリをインストールする指示
# 「japanize-matplotlib」という特殊セットを取り寄せます
!pip install japanize-matplotlib
3. 変数(Variable):データを入れる「スピッツ」
プログラミングの第一歩は、データを扱うための容器、すなわち「変数(Variable)」の理解から始まります。
採血室の業務を想像してください。患者さんから採取した血液(データ)を、そのまま机の上に放置することはありません。必ず適切な「スピッツ(採血管)」に入れ、間違いが起きないように「患者IDのラベル」を貼って管理しますよね。
Pythonの世界でも全く同じことを行います。裸のデータ(数値や文字)をそのまま扱わず、名前(ラベル)のついた箱に入れて保存します。
「=」は等号ではない
ここで最も重要なルールがあります。数学における「=」は「左と右が等しい」という意味ですが、プログラミングにおける「=」は「右のものを左の箱に入れる(代入)」という操作を指します。
sbp = 134.5
これは「sbpは134.5である」という宣言ではなく、「134.5という測定値を、’sbp’ というラベルを貼ったスピッツに入れる」という動作です。
データの種類とスピッツのキャップ
実際の医療現場で、血算用(紫)や生化学用(茶)などスピッツのキャップ色が分かれているように、データにも「型(Type)」があります。
# 数値を入れる(生化学スピッツ)
# 計算に使用できます
age = 65 # "age"というラベルの箱に 65 を入れる
sbp = 134.5 # 小数点(float)もOK
# 文字を入れる(患者ラベル)
# 文字は必ずクオーテーション(" " または ' ')で囲みます
name = "Tanaka" # "name"という箱に "Tanaka" を入れる
# 中身を確認する(print関数)
# 検査結果を画面に出力する命令(Lab Report)です
print(name)
print(age)適切にラベル(変数名)をつけることは、取り違え事故を防ぎ、研究の再現性を高めるための第一歩です (Avidan & Feitelson 2017)。
4. リストと辞書:カルテの構造化
臨床データは「1つの数値」だけではありません。「1週間分の体温変化」や「患者の基本情報セット」など、データの塊を扱います。
これらを整理するための棚が、「リスト(List)」と「辞書(Dictionary)」です。
A. リスト (List):時系列のフローシート
「入院してから退院するまでの毎日の体温」のように、順序(Sequence)が重要なデータを扱うときは「リスト」を使います。[ ](角括弧)でデータを囲み、カンマで区切って並べます。
# 過去3回分のHbA1c値(時系列)
hba1c_list = [6.2, 6.5, 6.8]
# データの取り出し
# 【最重要】Pythonは「Time 0(ベースライン)」の発想で、0から数えます!
print(hba1c_list[0]) # 最初のデータ(6.2)が表示される
# データの追加
# appendは「追記」です。カルテの最後に新しい行を足すイメージです。
hba1c_list.append(7.1) # 末尾に新しい検査結果を追加B. 辞書 (Dictionary):患者フェイスシート
「氏名、年齢、ID、診断名」のように、順序よりも「ラベル(項目名)」で管理したい情報には「辞書」を使います。{ }(波括弧)を使い、「キー(項目名): 値」のペアで記述します。
これは、現代の医療データ交換規格であるFHIR (JSON) と同じ構造です。
# 患者1名分の情報(フェイスシート)
patient = {
"id": "Pt001",
"age": 74,
"diagnosis": "Diabetes"
}
# 取り出し方:「何番目?」ではなく「項目名(キー)」で指定します
print(patient["diagnosis"]) # -> Diabetes が表示される5. ロジックの記述:トリアージと回診
データの入れ物が用意できました。ここからは「自動化」の本番です。医師の思考回路そのものをコードとして記述します。
A. 条件分岐 (If文):トリアージの自動化
医療現場は判断の連続です。「もしSpO2が90未満なら酸素投与、そうでなければ経過観察」。この臨床アルゴリズムを記述するのが「If文(条件分岐)」です。
spo2 = 88
# 条件分岐
if spo2 < 90:
# 条件を満たすとき(字下げ=インデントが必要!)
# ここが「酸素投与指示」のブロックです
print("酸素投与")
else:
# 満たさないとき
print("経過観察")【重要】字下げ(インデント):
Pythonでは、条件が満たされたときに実行する範囲を「字下げ」で表現します。これは、Pythonコードが世界中で「読みやすい」と評価される最大の理由であり、書き方の強制的なルール(PEP 8)でもあります。
B. ループ (For文):病棟回診の自動化
「リストに入っている100人の患者全員に対して、同じ検査(処理)を行う」。
人間がやると疲弊しミスが起きるこの作業こそ、コンピュータの最大の強みです。これを「For文(ループ)」と呼びます。
# 3人の体重リスト(患者リスト)
weights = [60, 70, 80]
# 一人ずつ取り出して処理する(総回診)
# "w" は、取り出した「現在の患者」を入れる仮の箱の名前です
for w in weights:
print(f"体重は {w} kgです")for w in weights: は、「weightsリストから順番にデータを取り出し、一時的に w と名付けて処理せよ」という命令です。データが1万人分あっても、コードはこの2行だけで済みます。
6. 実践:BMI自動解析プログラム
これまでの知識を統合して、「複数の患者データからBMIを計算し、肥満リスクを判定して、グラフ化する」プログラムを動かしてみましょう。
これは、手作業n=1の臨床ケアから、データ駆動型n=10,000の公衆衛生・管理医学への飛躍を意味します。
プログラムの構造(思考プロセス)
このコードは、以下の3つのステップで構成されています。
- 入力(EHR抽出): 患者データをリスト形式で準備します。実際の現場では、電子カルテからCSV出力された数万人のデータになります。
- 処理(ロジック): WHOおよび日本肥満学会の基準(BMI25以上 を肥満とする)に基づき、全員分をループ処理で計算・判定します。
- 出力(視覚化):
matplotlibというライブラリを用いて、数値の羅列を直感的なグラフに変換します。
コードの実行
以下のコードをコピーして、Google Colabに貼り付けて実行してください。
数行の指示書が、データの「加工・判定・視覚化」を一瞬で完了させる様子を体験できます。
import japanize_matplotlib # 日本語グラフ用(視覚化の専門医)
import matplotlib.pyplot as plt # グラフ描画用
# 1. 模擬データの作成(電子カルテからの抽出データを模倣)
# リストの中に辞書が入っている「入れ子構造」です
patients_list = [
{"id": 1, "height_cm": 170, "weight_kg": 65},
{"id": 2, "height_cm": 160, "weight_kg": 80},
{"id": 3, "height_cm": 175, "weight_kg": 60},
{"id": 4, "height_cm": 155, "weight_kg": 50},
{"id": 5, "height_cm": 180, "weight_kg": 110},
]
# 計算結果を入れるための空のリスト(空のカルテ用紙)
bmi_results = []
print("--- 解析開始 ---")
# 2. 全員分の回診(ループ処理)
# pt に一人分の辞書データが順番に入ります
for pt in patients_list:
# 身長をメートルに変換 (cm ÷ 100)
height_m = pt["height_cm"] / 100
# BMI計算: 体重 ÷ 身長の2乗
# Pythonで「2乗」は「** 2」と記述します
bmi = pt["weight_kg"] / (height_m ** 2)
# 小数点第1位に丸める
bmi = round(bmi, 1)
# 結果をリストに保存(追記)
bmi_results.append(bmi)
# 3. リスク判定(条件分岐)
# WHO/日本肥満学会基準:BMI 25以上を肥満と判定
if bmi >= 25:
risk = "★肥満"
elif bmi < 18.5:
risk = "低体重"
else:
risk = "標準"
# 1症例ごとの結果を出力
print(f"ID:{pt['id']} | BMI:{bmi} -> {risk}")
print("--- 解析終了 ---")
# 4. グラフ化(視覚化)
# 棒グラフを描きます
plt.figure(figsize=(8, 5))
plt.bar([f"ID:{p['id']}" for p in patients_list], bmi_results, color='skyblue')
# 基準線(BMI 25)を赤線で引く:リスクの可視化
plt.axhline(y=25, color='red', linestyle='--', label='肥満ライン (BMI 25)')
plt.title('患者別 BMI分布')
plt.xlabel('患者ID')
plt.ylabel('BMI')
plt.legend() # 凡例を表示
plt.grid(axis='y', alpha=0.5) # グリッド線を表示
plt.show()--- 解析開始 ---
ID:1 | BMI:22.5 -> 標準
ID:2 | BMI:31.2 -> ★肥満
ID:3 | BMI:19.6 -> 標準
ID:4 | BMI:20.8 -> 標準
ID:5 | BMI:34.0 -> ★肥満
--- 解析終了 ---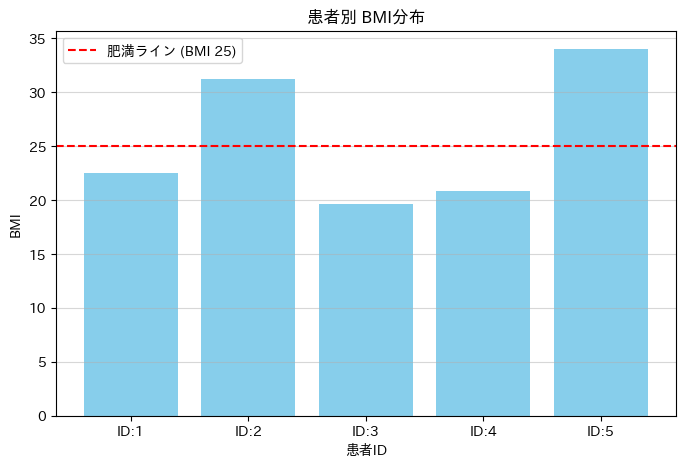
このプログラムを実行すると、計算結果のテキストログと共に、患者ごとのBMI分布を示す棒グラフが自動生成されます。手作業によるグラフ作成とは異なり、データが更新されればグラフも瞬時に、正確に再描画されます。
小まとめ:コードは「記述する医学」
いかがでしたか?
これまでの講義で、Pythonの文法が「宇宙人の言葉」ではなく、「医療現場の日常業務」そのものであることがお分かりいただけたかと思います。
- 変数 (Variable): 血液を入れる「スピッツ(採血管)」
- リスト (List): 時系列に並んだ「体温管理表」
- 辞書 (Dictionary): 患者属性をまとめた「フェイスシート」
- 条件分岐 (If): 検査値に基づく「トリアージ・診断」
- ループ (For): 全患者を診て回る「総回診」
これらは全て、あなたが普段の診療で無意識に行っている思考プロセスです。それを、コンピュータが理解できる言葉(Python)で「記述」し直したに過ぎません。
この基礎さえあれば、これから学ぶ「統計解析(検定)」も「AIモデル構築(深層学習)」も、恐れる必要はありません。すべて同じ文法、同じ論理構造で記述できます。
あなたは今、エクセルという手作業の限界を超え、医療データを自由自在に操るための「新しい言語」を手に入れました。
もっと詳しく知りたい方、さらに一歩進んだ「開発者の視点」を持ちたい方は、以下の発展編へお進みください。
発展編:医学を拡張する「専門医」と「設計図」
ここまでは、Pythonという言語の「基礎文法(変数・リスト・ループ)」を学びました。これは医学教育で言えば、医学生や研修医が「カルテの書き方(SOAP)」や「基本的な処方オーダー」を覚えた段階に相当します。個々の患者(データ)に対する基本的なアプローチはこれで十分です。
しかし、現代の高度医療がたった一人の医師で完結しないのと同様に、実用レベルの医療AI開発も、Pythonの基本機能だけでは不可能です。
そこには、高度な画像解析や統計処理を専門に行う「他科との連携(ライブラリ)」や、数万人のデータを安全かつ効率的に管理するための「病院システムの設計思想(オブジェクト指向)」が不可欠です。
この「発展編」では、次のステージ——研究室レベルのスクリプトから、臨床実装レベルのアプリケーションへ——に進むために避けては通れない3つの壁、「ライブラリ」「PyTorch」「オブジェクト指向」を、完全に医療現場のメタファーで解き明かします。
[Series P] 🐍 Medical AI with Python : Pythonで学ぶ人工知能の理論と実装
7. ライブラリ:頼れる「コンサルト先(専門医)」
Pythonが世界中で愛される最大の理由は、「他科へのコンサルト(連携)」が圧倒的に簡単だからです。
標準的なPython(インストールしたままの状態)は、優秀な「総合診療医(General Practitioner)」のようなものです。
基本的な診察や処置は何でもこなせますが、高度に専門的な手術(複雑な行列計算)や、特殊な画像診断(ディープラーニング)まで一人で行うのは非効率です。
そこで、その道のプロフェッショナルである「ライブラリ(Library)」という外部の専門家チームを呼び出します。
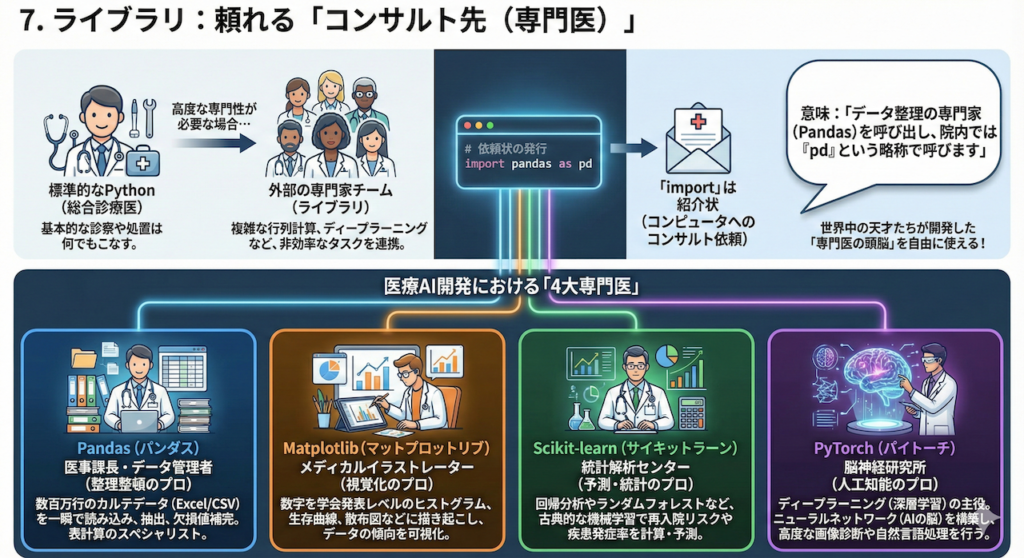
「import」は紹介状
コードの冒頭に書く import 文。これは、コンピュータに対する「他科へのコンサルト依頼(紹介状)」です。
# 依頼状の発行
import pandas as pd
# 意味:「データ整理の専門家(Pandas)を呼び出し、院内では『pd』という略称で呼びます」この一行を書くだけで、世界中の天才たちが開発した「専門医の頭脳」を、あなたのコードの中で自由に使えるようになります。
医療AI開発における「4大専門医」
医療AI開発の現場には、必ずと言っていいほど連携する「4人のスペシャリスト」がいます。
| ライブラリ名 | 医療現場での役割 | 具体的な仕事内容 |
|---|---|---|
| Pandas (パンダス) | 医事課長・データ管理者 (整理整頓のプロ) | 数百万行のカルテデータ(Excel/CSV)を一瞬で読み込み、「HbA1c 8.0以上の患者」を抽出したり、欠損値を埋めたりする表計算のスペシャリスト。 |
| Matplotlib (マットプロットリブ) | メディカルイラストレーター (視覚化のプロ) | 数字の羅列を、学会発表レベルの「ヒストグラム」「生存曲線」「散布図」などに描き起こし、データの傾向を可視化する。 |
| Scikit-learn (サイキットラーン) | 統計解析センター (予測・統計のプロ) | 回帰分析やランダムフォレストなど、古典的な機械学習を用いて「再入院リスク」や「疾患発症率」などを計算・予測する。 |
| PyTorch (パイトーチ) | 脳神経研究所 (人工知能のプロ) | ディープラーニング(深層学習)の主役。ニューラルネットワーク(AIの脳)を構築し、画像診断や自然言語処理など、高度なAI開発を行う。 |
8. PyTorch(パイトーチ):AIの「脳」を作る
数あるライブラリの中で、なぜ特にPyTorchが重要なのでしょうか?
それは、現在の医療AIブーム(ChatGPT、画像診断AI、創薬AI)のほとんどが、このPyTorch(またはTensorFlow)という基盤の上で動いているからです。
PyTorchは、Meta社(Facebook)が開発し、世界中の研究者に無償公開している「ニューラルネットワーク(脳の神経回路網)」を作るためのデジタルなブロック玩具です。
これを使えば、ゼロから複雑な数式を書くことなく、ブロックを積み上げるようにしてAIの脳を構築できます。
テンソル (Tensor):GPU専用の「特殊検体スピッツ」
PyTorchで扱うデータの単位を「テンソル (Tensor)」と呼びます。これは、ただの数字の入れ物ではありません。
- 通常の変数(リスト): 一般的な試験管。CPU(普通の手作業)で処理します。
- テンソル: 超・遠心分離機(GPU)に対応した特殊強化スピッツ。
CT画像の3次元データや、ゲノムの膨大な配列情報を、GPUというスーパーエンジンに乗せて、光の速さで並列処理するための専用コンテナです。
自動微分 (Autograd):全自動の「指導医フィードバック」
AIの学習とは、ひたすら「試行錯誤」を繰り返すことです。
「診断(予測)してみる」→「正解と比べる」→「ズレ(誤差)を修正する」というプロセスを数億回繰り返します。
このとき、「どのパラメータを、どちらに、どれだけ動かせば正解に近づくか?」を計算するのが微分(勾配計算)ですが、人間が手計算するのは不可能です。
PyTorchの「自動微分 (Autograd)」機能は、あなたの書いたコードの履歴を全て監視し、「君、ここの判断が少しズレていたから、次は右に0.01だけ修正しなさい」と、全自動で完璧なフィードバックを与え続けてくれる「神のような指導医」です。
「PyTorchを使える」ということは、「最新のAI論文のコードを自分の手元で動かせる」ということを意味します。これが、研究医にとって最強の武器になります。
9. オブジェクト指向とクラス:電子カルテの「設計図」
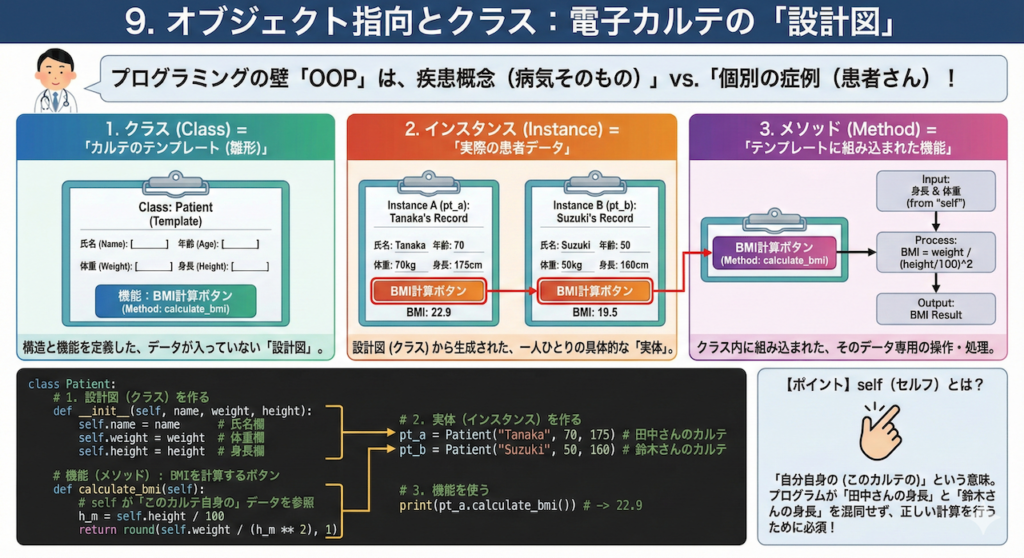
プログラミング初心者が最も挫折しやすいのが「オブジェクト指向(Object-Oriented Programming: OOP)」です。
「クラス」「インスタンス」「メソッド」……聞き慣れないカタカナ語のオンパレードに、脳が拒絶反応を起こしてしまいがちです。
しかし、恐れる必要はありません。実はこれ、皆さんが毎日使っている「電子カルテの設計思想」と全く同じ概念なのです。
もしあなたが「疾患概念(病気そのもの)」と「個別の症例(患者さん)」を区別できているなら、あなたはすでにオブジェクト指向を理解しています。
(1) クラス (Class) = 「カルテのテンプレート(雛形)」
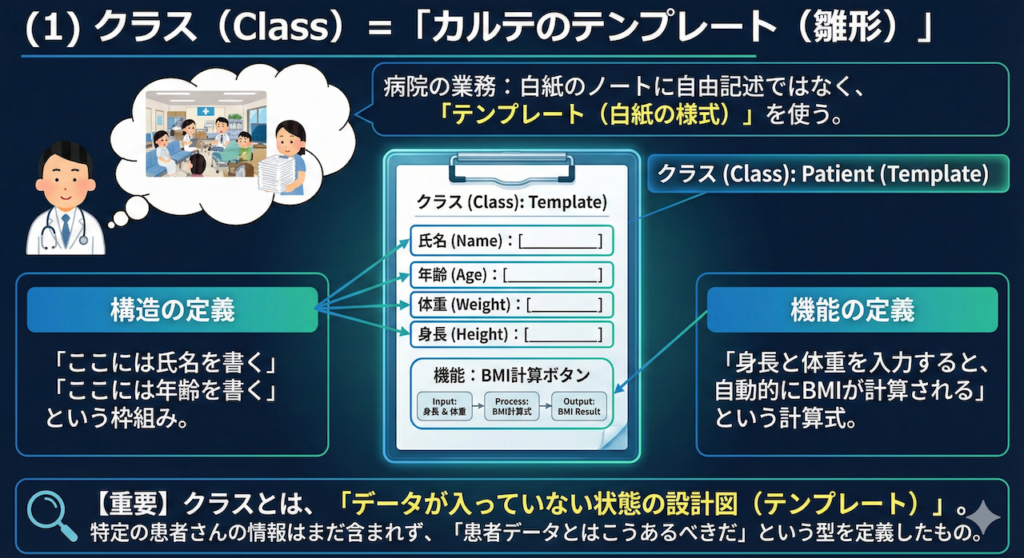
病院の業務を思い浮かべてください。「入院診療計画書」や「退院サマリ」を作成する際、いきなり白紙のノートに自由記述するわけではありませんよね?
必ず、病院ごとに定められた「テンプレート(白紙の様式)」があるはずです。
- 構造の定義: 「ここには氏名を書く」「ここには年齢を書く」という枠組み。
- 機能の定義: 「身長と体重を入力すると、自動的にBMIが計算される」という計算式。
プログラミングにおける「クラス (Class)」とは、まさにこの「データが入っていない状態の設計図(テンプレート)」のことを指します。
クラス自体には、まだ特定の患者さんの情報は含まれていません。それはあくまで、「患者データとはこうあるべきだ」という型を定義したものです。
(2) インスタンス (Instance) = 「実際の患者データ」

テンプレート(クラス)自体は、ただの「枠組み」であり、実体はありません。
そこに「田中さん」「65歳」といった具体的な情報を書き込んで初めて、それは意味のある「一人の患者のカルテ」になります。
プログラミングでは、この「設計図(クラス)を元に生成された、一人ひとりの実体」のことを「インスタンス (Instance)」または「オブジェクト」と呼びます。
- Class(クラス): 入院診療計画書の「白紙のテンプレート」
- Instance(インスタンス): 田中さんの入院診療計画書、鈴木さんの入院診療計画書…
1つのクラス(テンプレート)から、無限に異なるインスタンス(カルテ)を作ることができます。これがオブジェクト指向の最大のメリットである「再利用性」です。
(3) メソッド (Method) = 「テンプレートに組み込まれた機能」
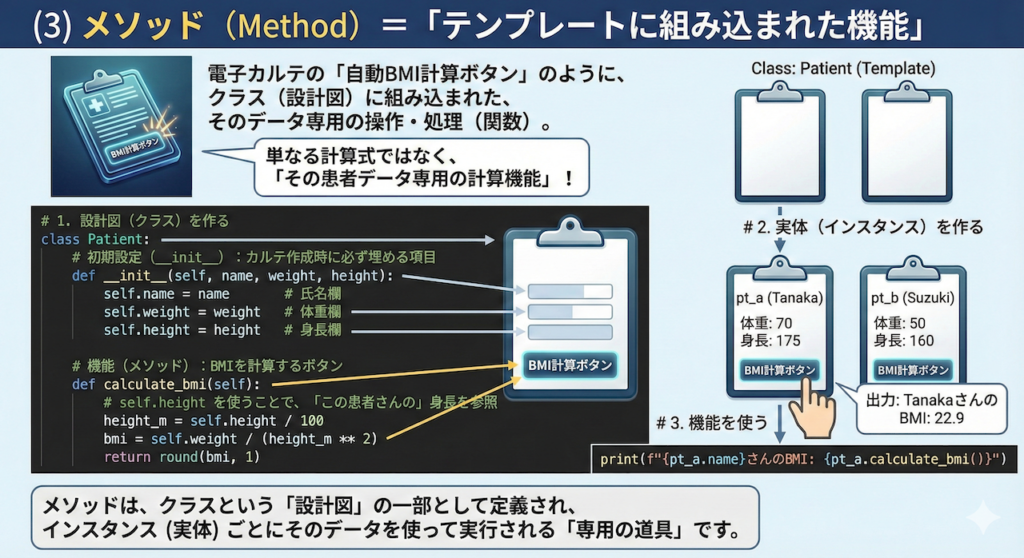
電子カルテには、データを入力するだけでなく、「身長と体重を入力すると、自動でBMIを計算してくれるボタン」がついていたりします。
このように、クラス(設計図)の中に組み込まれた、そのデータを使って行える操作や処理(関数)のことを、プログラミングでは「メソッド (Method)」と呼びます。
単なる計算式ではなく、「その患者データ専用の計算機能」です。
これをPythonコードで見ると、驚くほど直感的です。
# 1. 設計図(クラス)を作る
# 「Patient」という名前のカルテ用紙を定義します
class Patient:
# 初期設定(__init__):カルテ作成時に必ず埋める項目
# "self" は「このカルテ自身の」という意味です
def __init__(self, name, weight, height):
self.name = name # 氏名欄に書き込む
self.weight = weight # 体重欄に書き込む
self.height = height # 身長欄に書き込む
# 機能(メソッド):BMIを計算するボタン
def calculate_bmi(self):
# self.height を使うことで、「この患者さんの」身長を参照します
height_m = self.height / 100
bmi = self.weight / (height_m ** 2)
return round(bmi, 1)
# -----------------------------------
# 2. 実体(インスタンス)を作る
# 「Patient」テンプレートを使って、AさんとBさんのカルテを作成
# これで初めてメモリ上に「実体」が生まれます
pt_a = Patient("Tanaka", 70, 175)
pt_b = Patient("Suzuki", 50, 160)
# 3. 機能を使う
# Aさんのカルテにある「BMI計算ボタン」を押すイメージです
print(f"{pt_a.name}さんのBMI: {pt_a.calculate_bmi()}")
# -> 出力: TanakaさんのBMI: 22.9【ポイント】self(セルフ)とは?
コード内の self は、「自分自身の(このカルテの)」という意味です。
これがあるおかげで、プログラムは「田中さんの身長」と「鈴木さんの身長」を混同せずに、正しい計算を行うことができます。
まとめ:医師こそ、この概念を理解しやすい
「プログラミングは理系エンジニアのもの」という先入観は捨ててください。
実は、日々「病気(クラス)」という抽象的な疾患概念と、目の前の「患者さん(インスタンス)」という具体的な実体を常に行き来している医師こそ、オブジェクト指向を最も直感的に理解できる職種なのです。
臨床推論のプロセスそのものが、高度な計算論的思考(Computational Thinking)だからです。
言葉の壁を超えて
この発展編で触れた用語は、今は「聞いたことがある」レベルで十分です。
今後、AIのコードを読んだ時に「あ、これは import で専門医を呼んでいるんだな」「これは class でデータの雛形を作っているんだな」とイメージできれば、ブラックボックスはもはや恐怖の対象ではなくなります。
その瞬間、AIは得体の知れない魔法ではなく、あなたが自在に操れる「道具」に変わります。
さあ、手作業のエクセルを閉じましょう。
Pythonという広大な医療AIの海へ漕ぎ出すための羅針盤は、すでにあなたの手の中にあります。自らの手でデータを執刀し、新しい医学の知見を創造する旅へ、一緒に出かけましょう。
参考文献
- Abeysooriya, M., et al. (2021). Gene name errors: Lessons not learned. PLoS Computational Biology, 17(7), e1008984.
- Avidan, E. and Feitelson, D.G. (2017). Effects of variable names on comprehension: An empirical study. Proceedings of the IEEE 25th International Conference on Program Comprehension, 55–65.
- Banhart, F. and Lohmann, R. (2000). An object-oriented approach for structuring the electronic medical record. Studies in Health Technology and Informatics, 77, 622–626.
- Bassett, D.S., et al. (2019). Python for biologists: The code of bioinformatics. Earlham Institute.
- Bello, A. (2024). Medicine through the lens of OOP–Object-Oriented Programming. BeingWell.
- Bisong, E. (2019). Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform (pp. 59–64). Apress.
- Carver, J., et al. (2022). Jupyter Notebooks for medical education: A narrative review. Medical Teacher, 44(8), 920–925.
- Goecks, J., et al. (2010). Galaxy: A comprehensive approach for supporting accessible, reproducible, and transparent computational research in the life sciences. Genome Biology, 11(8), R86.
- He, H. (2019). The state of machine learning frameworks in 2019. The Gradient.
- Hunter, J.D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3), 90–95.
- Koundilya, A. (2021). Object-Oriented Programming teaching in English through computational fairy tales. ESPEAP.
- Kushniruk, A.W. (2001). Analysis of complex decision-making processes in health care: Cognitive approaches to health informatics. Journal of Biomedical Informatics, 34(5), 365–376.
- Mandel, J.C., et al. (2016). SMART on FHIR: A standards-based, interoperable apps platform for electronic health records. Journal of the American Medical Informatics Association, 23(5), 899–906.
- McKinney, W. (2010). Data structures for statistical computing in Python. Proceedings of the 9th Python in Science Conference, 51–56.
- Paszke, A., et al. (2019). PyTorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems, 32.
- Patel, V.L., et al. (2000). The nature of medical expertise: A critical look. Medical Education, 34(10), 852–865.
- Peng, R.D. (2011). Reproducible research in computational science. Science, 334(6060), 1226–1227.
- Perkel, J.M. (2018). Why Jupyter is data scientists’ computational notebook of choice. Nature, 563, 145–146.
- Pimentel, H., et al. (2019). A guide to reproducible code in science. Nature Ecology & Evolution, 3, 1127–1134.
- Reitz, K. (2025). Python as English: The art of readable code. Kenneth Reitz Essays.
- Severance, C. (2013). Python for informatics: Exploring information. CreateSpace Independent Publishing Platform.
- Van Rossum, G. and Drake, F.L. (2009). Python 3 reference manual. CreateSpace.
- Van Rossum, G., Warsaw, B. and Coghlan, N. (2001). PEP 8 – Style guide for Python code. Python.org.
- Virtanen, P., et al. (2020). SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nature Methods, 17, 261–272.
- Wickham, H., et al. (2019). Welcome to the Tidyverse. Journal of Open Source Software, 4(43), 1686.
- World Health Organization. (2021). Body mass index (BMI). Global Health Observatory.
- Ziemann, M., Eren, Y. and El-Osta, A. (2016). Gene name errors are widespread in the scientific literature. Genome Biology, 17, 177.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




