

医療時系列データ分析におけるAIモデルの進化を解説。従来のRNN/LSTMが持つ課題を、Transformerの革新的な「Attention機構」がどう解決するのか、そしてPyTorchによる実装から倫理的課題までを学びます。
RNNやLSTMはデータを順番に処理するため、時系列が長くなると初期の重要情報が薄れてしまいます。カルテを1ページ目から読み進めるうちに、最初のページの重要所見を忘れてしまうような状態でした。
データ全体を一度に見渡し、関連の強い部分にだけ「注目」します。経験豊富な専門医がカルテ全体を瞬時に俯瞰し、数年前の記録と現在の症状の関連を一瞬で見抜くような、効率的で強力な情報処理を実現しました。
PyTorchでの実装は、データ準備 → モデル定義 → 学習 → 評価という流れで行います。この強力な技術を医療に応用する際は、プライバシーや公平性、解釈可能性といった倫理的課題と向き合うことが不可欠です。
はじめに
日々の臨床や研究の現場で、私たちは心電図(ECG)や持続血糖モニター(CGM)のデータなど、膨大な「時間の流れを持つデータ」に常に触れていますよね。これらの医療時系列データは、患者さんの状態のわずかな変化を捉える宝の山であり、これらをAI、特にPyTorchのようなツールで解析し、疾患の早期発見や進行予測に繋げる時系列解析は、間違いなく次世代医療の鍵を握る技術の一つだと思います。
これまで、こうした連続的なデータの分析には、RNN(再帰型ニューラルネットワーク)や、その発展形であるLSTM(Long Short-Term Memory)が主役でした。これらは情報を記憶しながら、データを時系列に沿って一つずつ順番に処理していくのが得意です。例えるなら、カルテを1ページ目から丁寧に読み進める、真面目な研修医のようなイメージでしょうか。しかし、この「順番に」という性質が、時として弱点にもなります。非常に長い時系列データ、例えば数週間にわたるバイタルデータを扱う場合、初期の重要な情報が最後まで伝わりにくくなる「長期依存性の問題」を抱えていました。実はこの点、LSTMが1997年に提案された当初から認識されていた古典的な課題でもあるのです (Hochreiter and Schmidhuber, 1997)。
そんな中、2017年にGoogleの研究者らが発表した論文『Attention Is All You Need』(Vaswani et al., 2017)をきっかけに、Transformer(トランスフォーマー)というモデルが自然言語処理の世界に文字通り革命を起こしました。そして今、その波が医療AIの分野にも押し寄せています。
Transformerの最大の武器は、Attention(アテンション)機構と呼ばれる仕組みです。これは、データを順番に処理するのではなく、系列全体のどこに重要な情報があるかを一度に見渡し、関連性の強い部分にだけ「注目」を割り当てます。先ほどの例で言えば、患者さんのカルテ全体を瞬時に俯瞰し、現在の症状と数年前の既往歴との関連性を一瞬で見抜く、経験豊富な専門医のような働き方です。このおかげで、Transformerは時間の壁を越えて、遠く離れた過去のデータが持つ意味を的確に捉えることができるのです。
この記事は、AIプログラミングが初めてという医療従事者や研究者の方々に向けて、このTransformerの魅力とその使い方をお伝えするために執筆しました。この学習の旅では、一緒に以下のステップを歩んでいきます。
- なぜ今、医療AIの世界でTransformerが注目されているのか? その背景と可能性を、臨床現場の視点から探ります。
- Transformerの心臓部、「Attention」とは何か? その仕組みを、難しい数式は一旦脇に置いて、直感的なイメージで理解します。
- 実際にモデルを動かしてみよう! PyTorchを使い、医療データを模した時系列データで簡単な予測モデルを構築します。コードは一行ずつ丁寧に解説しますので、ご安心ください。
このコースを通じて、皆さんがTransformerという強力なツールを深く理解し、ご自身の研究や臨床現場の課題解決に応用するための、確かな一歩を踏み出すお手伝いができれば、これほど嬉しいことはありません。AIという「新しい聴診器」を手に、未来の医療を切り拓く準備を一緒に始めましょう。
1. なぜ医療時系列データにTransformerが有効なのか?
医療現場で私たちが日々向き合っている時系列データは、想像以上に複雑な物語を秘めていますよね。例えば、集中治療室(ICU)で患者さんの容態急変を予測するシナリオを考えてみましょう。この時、直前の数時間のバイタルサインだけを見ていては、全体像を見誤ってしまうかもしれません。もしかすると、3日前に投与したフロセミド(利尿薬)が今日の呼吸数悪化に間接的に影響しているかもしれませんし、1週間前の検査データに重要な予兆が隠れている可能性だってあります。
このように、原因と結果が時間的に大きく離れているケースは、医療データでは決して珍しくありません。この「時間の壁」をどう乗り越えるかが、予測AIの精度を左右する大きな鍵となります。
従来のモデル(RNN/LSTM)が抱えていた壁
こうした課題に対して、以前の主役であったRNNやLSTMは少し苦戦していました。これらのモデルは情報を記憶しながら、時系列に沿って一歩一歩、順を追ってデータを処理していきます。これはまるで、長いカルテを最初のページから順番に読み進め、重要な情報に付箋を貼りながら進んでいくようなものです。
とても丁寧な方法ですが、カルテが何十ページにも及ぶとどうなるでしょうか。ページをめくるごとに、前のページの情報を要約して新しい付箋に書き写していくような作業を繰り返すため、最終ページにたどり着く頃には、最初の頃に発見したはずの重要な所見が「要約の要約の…」となってしまい、元の繊細なニュアンスが失われがちです。これが、技術的に「長期依存性の問題」と呼ばれる、彼らが抱えていた構造的な壁でした。
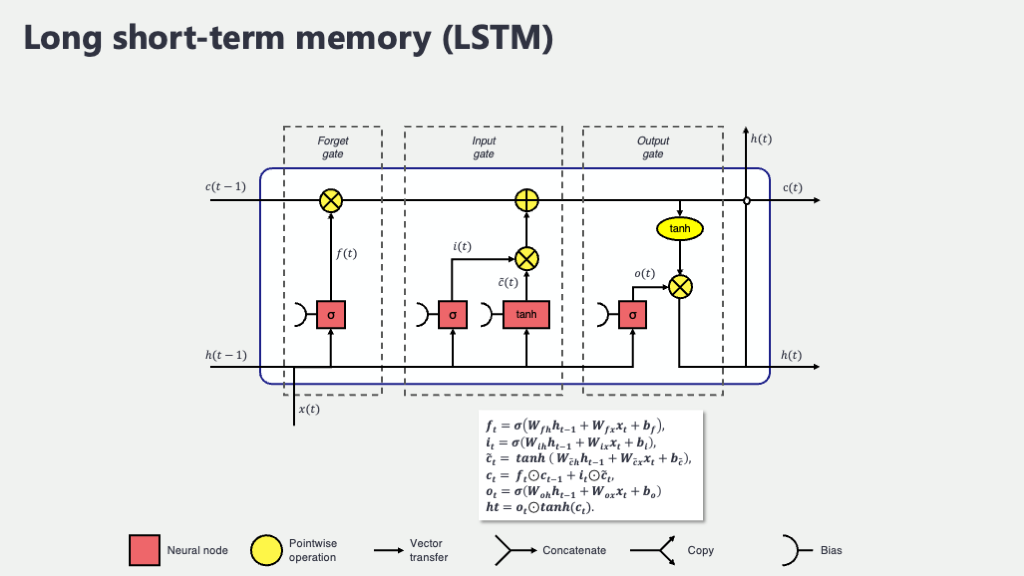
TransformerとAttention機構によるブレークスルー
ここで登場するのがTransformerです。私がこの仕組みを初めて学んだとき、まるで魔法のように感じました。その最大の特徴は、Self-Attention(自己注意機構)という、まさに革新的なメカニズムにあります。
Transformerは、時系列データを一歩ずつたどるのではなく、分析したい期間のすべてのデータポイントを一度に、大きな視野で見渡します。そして、「現在の状態を予測するために、過去のどの時点の情報が最も重要か?」を自ら判断し、関連性の強いデータポイントにだけ強く「注目(アテンション)」するのです。
先ほどのカルテの比喩を続けるなら、Transformerは経験豊富な専門医が最新の電子カルテシステムを使っているイメージに近いかもしれません。重要なキーワードで検索をかけると、関連する過去の記録が(たとえ数年前のものであっても)瞬時にリストアップされ、しかも、現在の疑問に対して最も関連が深い順にハイライト表示してくれる。そんな包括的かつ効率的な情報処理を得意としています。

この処理方法の違いを、もう一度、簡単な図で見てみましょう。
この図から、RNN/LSTMの情報伝達が一本道なのに対し、Transformerからは予測したいポイントを起点に、過去のあらゆる時点へ無数のアンテナが直接伸びているのがお分かりいただけるかと思います。この一本一本のアンテナが「アテンション」であり、どの情報にどれだけ注目すべきかを測るためのものです。
この特性のおかげで、Transformerは時間的な隔たりが大きいデータ間の複雑な関係性を捉えるのが非常に得意なのです。
実際、この分野の研究を大きく前進させたのは、ジョージア工科大学のZerveasらの研究(2021)でした。彼らがTransformerベースのフレームワークを提案したことで、これまで自然言語処理が主戦場だったこの技術を、多様なセンサーデータやバイタルサインといった医療時系列データに応用するための道筋が示されたのです。
こうした背景から、複雑なストーリーが隠された医療時系列データの分析において、Transformerは非常に強力なツールとして期待されている、というわけです。
では、この魔法のような「全体を一度に見渡す」仕組みは、一体どのように実現されているのでしょうか?次の章で、いよいよその心臓部であるAttention機構の内部を、もう少し詳しく覗いてみることにしましょう。
2. Transformerの心臓部:Attention機構を覗いてみよう
さて、前の章でTransformerが「全体を一度に見渡す」という魔法のような働きをするとお話ししましたが、その魔法の正体こそ、今回解説するAttention(アテンション)機構です。この概念を腹落ちさせて理解することが、Transformerを使いこなす上で最も重要なステップだと私は思います。
ここでは、複雑な数式はいったん脇に置き、私たちが普段行っている情報収集のプロセスに例えながら、その本質に迫っていきましょう。
Attentionを「医療文献検索」のプロセスで理解する
Attention機構の働きは、私たちが臨床上の疑問を解決するためにPubMedなどで文献を検索し、情報を統合するプロセスに驚くほど似ています。このメカニズムには、主に3つの登場人物がいます。それがQuery(クエリ)、Key(キー)、Value(バリュー)です。
Query (Q): あなたの「知りたいこと」
これは、あなたが今まさに解決したい臨床的な疑問や、AIが予測を行うための「問いかけ」そのものです。
(例:「この患者の次の時点での血圧を予測するために、過去のどのバイタルサインが最も重要か?」という問い)
Key (K): 各データの「見出し・キーワード」
これは、データベースにある膨大な文献の見出しや、過去の各データポイントが持っている「インデックス」や「名札」のようなものです。AIは、このKeyを見て、そのデータが何についての情報なのかを判断します。
(例:過去の各データポイントが持つ「1時間前の心拍数」「3日前の投薬履歴」といったタグ)
Value (V): 各データの「本文・中身」
これは、Keyに紐づく具体的な情報そのものです。文献の抄録であったり、実際のバイタルサインの測定値だったりします。
(例:「心拍数: 85 bpm」「ラシックス20mg投与」という実際の記録)
あなたが文献検索をするとき、まず自分の疑問(Query)を検索窓に入力しますよね。するとシステムは、そのQueryと関連性の高そうなキーワード(Key)を持つ文献をリストアップします。そしてあなたは、その中から最も関連が深いと思われる文献の本文(Value)を重点的に読み、情報を統合して疑問の答えを導き出すはずです。
Attention機構は、この一連の知的作業を、コンピュータが扱える数値(ベクトル)の世界で、超高速に、そして客観的に行っているものだと考えてみてください。
Attention計算の具体的な4ステップ
では、このQ, K, Vを使って、具体的にどのような計算が行われるのでしょうか。このプロセスは、大きく4つのステップに分けられます。
ステップ1:関連度(アテンション・スコア)の計算
まず、現在の予測のためのQuery (Q)と、過去のすべてのデータポイントのKey (K)を一つひとつ総当たりで照合し、どれだけ関連があるか(似ているか)を数値化します。これがアテンション・スコアです。専門的には「内積」という計算がよく使われますが、これは2つのベクトル(情報の塊)がどれだけ同じ方向を向いているかを測るようなもので、スコアが高いほど「関連性が強い」と判断されます。
ステップ2:スコアの正規化(重みへの変換)
次に、計算したアテンション・スコアをSoftmax(ソフトマックス)という便利な関数に通します。これは、各スコアを「注目すべき度合い」を示す重みに変換するプロセスです。Softmaxの優れた点は、バラバラだったスコアの合計がちょうど「1」(=100%)になるように自動で調整してくれることです。これにより、限られた「注目のリソース」を、関連度に応じて各データポイントに何%ずつ配分するかが客観的に決まります。
ステップ3:Valueとの加重平均
そして、ステップ2で計算した「重み」を使って、すべてのValue (V)の加重平均を計算します。これは、注目すべき度合い(重み)が大きいValue(重要な情報)は計算結果に強く反映させ、逆に関連度が低いと判断されたValue(ノイズの可能性が高い情報)の影響は限りなくゼロに近づける、という操作です。重要な情報だけを選んでブレンドするようなイメージですね。
ステップ4:文脈を反映した情報の生成
この加重平均によって得られた最終的なアウトプットが、「現在のQueryにとって、過去の情報を賢く要約・統合した、文脈を考慮した新しい情報表現」となります。AIは、この情報を基に、次の予測を行うのです。
順序という概念を教える「Positional Encoding」
最後に、一つだけ重要な補足があります。ここまで説明したAttention機構だけでは、実はデータの「順序」が全く考慮されません。「3日前のデータ」と「1時間前のデータ」が、区別なくごちゃ混ぜに扱われてしまうのです。これでは時系列分析はできませんよね。
そこでTransformerでは、Positional Encoding(位置エンコーディング)という、非常に巧妙な仕掛けが用意されています。これは、各データポイントの入力ベクトルに、「あなたは何番目の位置にいますよ」というユニークな住所情報(数値ベクトル)を、あらかじめ足し込んであげる処理です。
具体的には、周期の異なるsin(サイン)波とcos(サイン)波を組み合わせて、各位置ごとに固有の「波形パターン」を作り出します。これは、各データに固有のタイムスタンプを刻印するようなものです。このおかげで、モデルはAttentionの計算の中で、データの値そのものだけでなく、そのデータが時系列上のどの位置にあるのかも同時に考慮できるようになり、時間的な前後関係を学習することが可能になるのです。 cleverなトリックだと思いませんか?
3. 実践!PyTorchでTransformerモデルを構築する
さて、理論を学んだら、次は実践あるのみです!ここからは実際にPyTorchを使い、Transformerモデルをゼロから構築していくプロセスを体験してみましょう。理論とコードが結びついたとき、きっと理解がぐっと深まるはずです。
今回は、実際の患者さんのデータを使う前に、まずはモデル構築の全体像を掴むことを目指します。そのため、「過去のバイタルサイン(血圧、心拍数)の時系列データから、次の時点の血圧を予測する」という、臨床現場を想定したタスクを設定し、そのためのリアルな疑似データを生成するところから始めます。準備はいいですか?一緒に手を動かしていきましょう。
3.1. 開発環境の準備とデータ生成
まずは、AIモデルを動かすための準備運動です。必要なライブラリをインポートし、学習に使うための疑似的な医療時系列データを作成します。
なぜわざわざ疑似データを作るのか、と思われるかもしれませんね。実際の医療データは、欠損値があったり、ノイズが多かったり、そして何より個人情報保護の観点から取り扱いに細心の注意が必要です。そこで今回は、まずはTransformerの仕組みそのものに集中するために、周期的変動やノイズといった、いかにもバイタルデータらしい特徴を持った「お手本データ」を自作するわけです。
【実行前の準備】以下のコードで日本語のグラフを表示させるには、あらかじめターミナルやコマンドプロンプトで pip install japanize-matplotlib を実行してライブラリをインストールしてください。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示ライブラリのインポート
import math
# デバイスの設定 (GPUが利用可能ならGPUを使用)
# AIの計算は非常に重いので、もしPCにNVIDIA製のGPUが搭載されていれば、
# それを優先的に使うように設定します。なければCPUで計算します。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 疑似医療時系列データの生成
def create_dataset(num_samples=1000):
# まず、時間の流れを表す等間隔の点を1000個生成します
time = np.linspace(0, 200, num_samples)
# 血圧(SBP)のベースラインをsin波とcos波の組み合わせで生成します。
# これは、日内変動のような周期的な動きを模倣するためです。
sbp = 120 + 10 * np.sin(time * 0.1) + 5 * np.cos(time * 0.5)
# 心拍数(HR)も同様にコサイン波で生成します。血圧と少し連動しているように見せます。
hr = 70 + 8 * np.cos(time * 0.1 - np.pi / 4)
# 現実のデータは決して綺麗ではないので、正規分布に従うランダムなノイズを加えます。
sbp += np.random.normal(0, 2, num_samples)
hr += np.random.normal(0, 3, num_samples)
# 血圧と心拍数のデータを一つのNumPy配列にまとめます。
# shape: (サンプル数, 特徴量数) -> (1000, 2)
data = np.vstack([sbp, hr]).T
return data
# 上記の関数を使って、実際にデータセットを作成します
data = create_dataset()
# 生成したデータがどんなものか、グラフで見てみましょう
plt.figure(figsize=(12, 6))
plt.plot(data[:, 0], label='収縮期血圧 (SBP)')
plt.plot(data[:, 1], label='心拍数 (HR)')
plt.title('生成された疑似医療時系列データ')
plt.xlabel('時間ステップ')
plt.ylabel('値')
plt.legend()
plt.grid(True)
plt.show()

どうでしょうか。このグラフを見ると、いかにも実際のバイタルデータにありそうな、大きな周期と細かな変動が組み合わさったリアルな波形になっているのがわかりますね。これで、モデルを学習させるための準備が一つ整いました。
3.2. データの前処理:モデルが学習しやすい形へ
次に、生成したデータをAIモデルが「食べて」学習できる形式に加工していきます。この前処理は、美味しい料理を作るための下ごしらえのようなもので、非常に重要なステップです。ここでは大きく2つの作業を行います。
- 正規化: 特徴量ごとの数値のスケール(大きさの範囲)を揃えます。
- シーケンス化: 時系列データを「問題(入力)」と「答え(正解ラベル)」のペアに切り分けます。
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader, TensorDataset
# --- 1. 正規化 ---
# 血圧(120前後)と心拍数(70前後)では数値のスケールが全く違います。
# このままモデルに入れると、数値の大きい血圧の方にばかり注目してしまい、
# 公平な学習ができません。そこで、すべてのデータを-1から1の範囲に揃えます。
scaler = MinMaxScaler(feature_range=(-1, 1))
data_normalized = scaler.fit_transform(data)
# --- 2. シーケンス化 ---
# これは、モデルに「問題集」を作ってあげるような作業です。
# 過去`tw`個のデータを見て、次の1個を予測する、という問題と答えのセットを
# データを1ステップずつずらしながら大量に作成します(スライディング・ウィンドウ)。
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
# データセットの端からウィンドウをスライドさせていくループ
for i in range(L - tw):
# tw期間のデータ(血圧, 心拍数)を入力(X)とする
train_seq = input_data[i:i + tw]
# その次のステップの血圧(最初の特徴量)を正解ラベル(y)とする
train_label = input_data[i + tw:i + tw + 1, 0]
inout_seq.append((train_seq, train_label))
return inout_seq
# ハイパーパラメータ:モデルの挙動を決める重要な設定値
input_window = 20 # 入力として過去20ステップ分のデータを使用
# 上記の関数で問題集(シーケンスデータ)を作成
sequences = create_inout_sequences(data_normalized, input_window)
# 作成した問題集を、モデルの訓練用と性能評価用のテスト用に分割します (80% : 20%)
train_size = int(len(sequences) * 0.8)
train_sequences = sequences[:train_size]
test_sequences = sequences[train_size:]
# PyTorchのDataLoaderを作成する関数
# これは、データを小さな束(ミニバッチ)にまとめて、モデルに少しずつ効率よく
# 「食べさせてあげる」ための便利な道具です。
def create_dataloader(sequences, batch_size):
# 入力(X)とラベル(y)をそれぞれリストにまとめる
X = [s[0] for s in sequences]
y = [s[1] for s in sequences]
# AIが扱えるtorch.Tensorという形式に変換し、DataLoaderを準備
return DataLoader(
TensorDataset(torch.FloatTensor(X), torch.FloatTensor(y)),
batch_size=batch_size,
shuffle=False # 時系列データなので、時間の順序を保つためシャッフルはしない
)
batch_size = 32 # 32問ずつまとめてモデルに見せる
train_loader = create_dataloader(train_sequences, batch_size)
test_loader = create_dataloader(test_sequences, batch_size)
print(f"訓練データ ローダー数: {len(train_loader)}")
print(f"テストデータ ローダー数: {len(test_loader)}")
訓練データ ローダー数: 25
テストデータ ローダー数: 7
/tmp/ipython-input-18655127.py:47: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at /pytorch/torch/csrc/utils/tensor_new.cpp:253.)
TensorDataset(torch.FloatTensor(X), torch.FloatTensor(y)),これで、モデルに入力するためのデータ準備は万端です。
3.3. Transformerモデルの定義:AIの設計図を描く
ここが本日のメインディッシュです!前の章で学んだ理論を基に、PyTorchを使ってTransformerモデルの設計図をコードで記述していきます。一見すると複雑に見えるかもしれませんが、データのたどる道のりを一つずつ追っていけば、必ず理解できます。
# --- 位置エンコーディング (Positional Encoding) の実装 ---
# 前の章で学んだ、Transformerに「順序」を教えるための重要な部品です。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 位置エンコーディング用の行列(pe)をゼロで初期化
pe = torch.zeros(max_len, d_model)
# 位置(0, 1, 2, ...)のテンソルを作成
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# sin/cos関数に入れるための除算項を計算 (数式通り)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 偶数番目の次元にはsinを、奇数番目の次元にはcosを適用
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
# register_buffer: peをモデルのパラメータとしては扱わないが、状態として保存する
self.register_buffer('pe', pe)
def forward(self, x):
# 入力テンソル x に、計算済みの位置エンコーディングを加算する
return x + self.pe[:x.size(0), :]
# --- Transformerモデル本体の定義 ---
class TransformerModel(nn.Module):
def __init__(self, input_dim=2, d_model=64, nhead=4, num_encoder_layers=2, dim_feedforward=256, dropout=0.1):
super(TransformerModel, self).__init__()
self.model_type = 'Transformer'
# --- ここから、モデルの中をデータが旅する順に部品を定義 ---
# 1. 入力層 (Embedding層)
# 入力データ(血圧,心拍数の2次元)を、モデルが内部で扱いやすい、より豊かな表現(d_model次元)に変換します。
self.encoder = nn.Linear(input_dim, d_model)
# 2. 位置エンコーディング層
# 上で定義したPositionalEncodingクラスのインスタンスです。
self.pos_encoder = PositionalEncoding(d_model)
# 3. Transformerエンコーダ層
# PyTorchには便利なことに、Transformerの主要部品があらかじめ用意されています。
# ここで、Self-Attentionによる計算が実行されます。
encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_encoder_layers)
# 4. 出力層 (Decoder/Linear層)
# Transformerが抽出した文脈情報(d_model次元)を、私たちが欲しい答え(次の血圧という1次元の数値)に変換します。
self.decoder = nn.Linear(d_model, 1)
self.init_weights()
def init_weights(self):
# モデルのパラメータ(重み)を適切な初期値に設定します。学習を安定させるためのおまじないです。
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
# --- データの流れ(forward pass)を定義 ---
def forward(self, src):
# 1. 入力srcをEmbedding層に通す
src = self.encoder(src) # shape: (バッチサイズ, 系列長, 2) -> (バッチサイズ, 系列長, 64)
# 2. 位置情報を付与する
src = self.pos_encoder(src)
# 3. Transformerエンコーダで文脈情報を抽出する
output = self.transformer_encoder(src)
# 4. 最後のタイムステップの情報だけを取り出し、出力層に通して最終予測値を得る
output = self.decoder(output[:, -1, :]) # shape: (バッチサイズ, 64) -> (バッチサイズ, 1)
return output
# モデルの設計図から、実際のモデル(インスタンス)を作成し、デバイスに送る
model = TransformerModel().to(device)
3.4. モデルの学習:AIに問題集を解かせる
設計図を基にモデルを組み立てたら、次はいよいよ学習のフェーズです。
モデルを「訓練」するとは、一言で言えば「問題集(訓練データ)を解かせて、間違えたら答えを教え、正解に近づくようにAIの脳内パラメータ(重み)を少しずつ修正させる」作業の繰り返しです。
このプロセスには、2人の重要な役割を持つ登場人物がいます。
- 損失関数(Loss Function): モデルの予測がどれだけ正解から外れているかを評価する「採点官」です。今回は予測値と正解値の差(誤差)を測る平均二乗誤差(MSE)を使います。
- 最適化アルゴリズム(Optimizer): 採点結果を見て、誤差が小さくなる方向にパラメータを修正する「修正ペン」の役割を担います。今回はAdamという非常に賢いアルゴリズムを使います。
# 「採点官」を定義
loss_function = nn.MSELoss()
# 「修正ペン」を定義
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 学習ループ
epochs = 20 # 問題集を20周させる
model.train() # モデルを「訓練モード」に切り替える(Dropoutなどを有効にする)
for epoch in range(epochs):
total_loss = 0
# DataLoaderからミニバッチ単位で問題と答えを取り出すループ
for seq, labels in train_loader:
# データを計算用のデバイスに転送
seq, labels = seq.to(device), labels.to(device)
# --- 訓練の5ステップ ---
# 1. 勾配をリセット (前の問題の採点結果を消す)
optimizer.zero_grad()
# 2. モデルによる予測 (問題を解かせる)
y_pred = model(seq)
# 3. 損失の計算 (答え合わせをして点数をつける)
single_loss = loss_function(y_pred, labels)
# 4. 誤差逆伝播 (どこをどう間違えたのかを逆算する)
single_loss.backward()
# 5. パラメータの更新 (修正ペンで脳内パラメータを書き換える)
optimizer.step()
total_loss += single_loss.item()
# 1周終わるごとに、平均の損失(間違い具合)を表示
if (epoch+1) % 5 == 0:
print(f'epoch: {epoch+1:3} loss: {total_loss/len(train_loader):10.8f}')
epoch: 5 loss: 0.20935502
epoch: 10 loss: 0.04691626
epoch: 15 loss: 0.03411845
epoch: 20 loss: 0.029760083.5. 評価と結果の可視化:AIの実力テスト
訓練が終わったら、モデルが未知の問題(テストデータ)をどれだけ解けるか、実力を試してみましょう。そして、その結果をグラフにして、私たちの目で直接確かめてみます。
# モデルを「評価モード」に切り替える
# これはモデルに「本番モードだよ」と伝えるおまじないのようなもので、
# 訓練時だけ使う機能(Dropoutなど)をオフにして、予測に集中させます。
model.eval()
test_predictions = []
actual_values = []
# 勾配計算を無効にすることで、計算を高速化し、メモリを節約します
with torch.no_grad():
for seq, labels in test_loader:
# データをデバイスに転送
seq, labels = seq.to(device), labels.to(device)
# 予測
y_pred = model(seq)
# 予測結果と実際の値をリストに保存 (あとでグラフ化するため)
test_predictions.extend(y_pred.cpu().numpy())
actual_values.extend(labels.cpu().numpy())
# --- 結果を元のスケールに戻す ---
# モデルは正規化された-1から1のデータで学習したので、予測結果もそのスケールで出てきます。
# これを私たちが理解できる元の血圧のスケールに戻してあげる必要があります。
# 少しテクニカルですが、元のscalerを使って逆変換します。
dummy_hr = np.zeros((len(test_predictions), 1))
predictions_rescaled = scaler.inverse_transform(np.hstack([np.array(test_predictions), dummy_hr]))[:, 0]
actuals_rescaled = scaler.inverse_transform(np.hstack([np.array(actual_values), dummy_hr]))[:, 0]
# --- 結果のプロット ---
plt.figure(figsize=(15, 7))
plt.plot(actuals_rescaled, label='実際の収縮期血圧', color='blue', linewidth=2)
plt.plot(predictions_rescaled, label='予測された収縮期血圧', color='red', linestyle='--', linewidth=2)
plt.title('Transformerモデルによる血圧予測の結果')
plt.xlabel('時間ステップ (テストデータ)')
plt.ylabel('収縮期血圧 (SBP)')
plt.legend()
plt.grid(True)
plt.show()
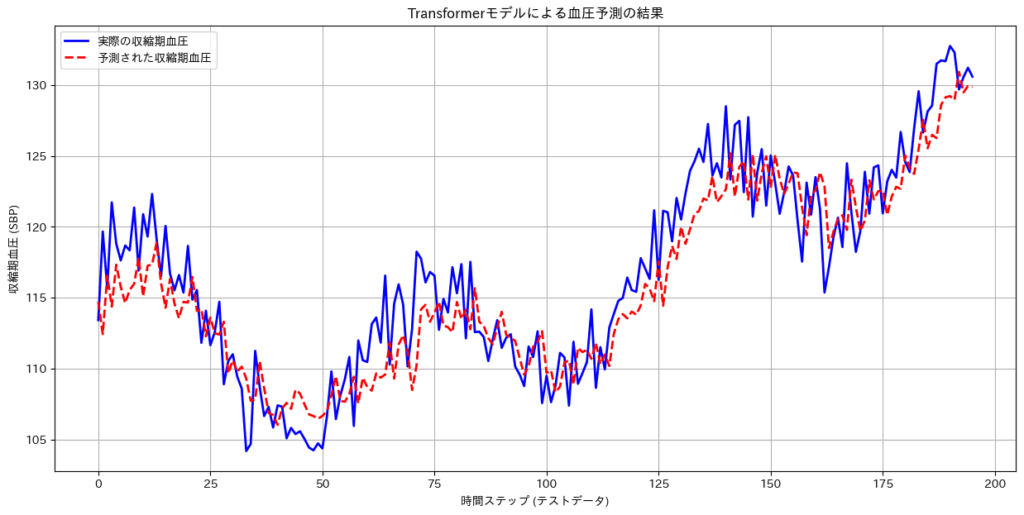
どうでしょうか?グラフを見ると、赤色の予測線が、青色の実際の値をかなり滑らかに追いかけているのがわかりますね。もちろんこれは完璧ではありませんが、たった20エポックという短い学習時間で、モデルがデータの大まかな周期性や変動パターンをしっかりと学習できたことが見て取れます。
これが、PyTorchでTransformerモデルを構築し、学習させ、評価するまでの一連の流れです。一つひとつのステップは地道ですが、こうして理論が動く形になるのは、とてもエキサイティングだと思いませんか?
4. 医療応用への展望と、私たちが向き合うべき課題
さて、モデルを構築する技術を学んだ今、最後に少しだけ視座を上げ、この技術が拓く未来の医療と、その光が強ければ強いほど濃くなる影、つまり私たちが向き合うべき倫理的・社会的な課題について一緒に考えてみましょう。
今回私たちが作ったのは、あくまで疑似データを使ったシンプルなモデルですが、これは未来の医療に向けた大きな可能性を秘めた「種」のようなものです。この種が育った先には、どのような景色が広がっているのでしょうか。
Transformerが拓く医療応用の可能性
現在、世界中の研究者がTransformerの力を医療に応用しようと、様々な研究に取り組んでいます。ここでは、その中でも特にエキサイティングな領域をいくつかご紹介します。
ICUでの超早期警告システム:
複数のバイタルサインや電子カルテ情報、ときにはベッドサイドの映像情報までを統合し、敗血症や急性腎障害といった危険な状態に陥るリスクを、人間が気づくよりも数時間早く予測する研究が進められています。医学雑誌『Nature Medicine』で発表されたShashikumarらの研究(2021)もその一つです。これが実現すれば、医療は「起きてから対応する」リアクティブなものから、「起きる前に介入する」プロアクティブなものへと、質的な大転換を遂げるかもしれません。
個別化された慢性疾患管理:
糖尿病患者さんの持続血糖モニター(CGM)データを用いて、数時間後の低血糖や高血糖イベントを事前に予測する。そんな研究も報告されています (Perez-Gandia et al., 2010)。予測に基づき、インスリン量の微調整や補食を促すアラートを出すことができれば、患者さん自身が日々の生活の中で自分の状態をより良く管理できるようになる、自己管理支援の強力なツールになる可能性があります。
客観データに基づく精神疾患モニタリング:
スマートフォンやウェアラブルデバイスから得られる活動量、睡眠パターン、さらにはSNSのテキストデータといったデジタルな足跡(デジタルフェノタイプ)から、精神状態の変化を検知するアプローチも研究されています (Mohr, Zhang, and Lattie, 2017)。これまで主観的な問診に頼ることが多かった領域に、客観的なデータという新しい光を当てる試みです。
AIという「賢い道具」とどう向き合うか:5つの重要な論点
このように大きな可能性を秘めた技術だからこそ、私たちはその使い方について、誰よりも深く、そして慎重に考えなくてはなりません。AIは万能の魔法ではなく、あくまで「賢い道具」です。この道具とどう向き合うべきか、ここでは5つの重要な論点を提示したいと思います。
データのプライバシーとセキュリティ:
言うまでもありませんが、AIの学習に用いる医療データは、最も機微な個人情報です。個人情報保護法などの法令遵守はもちろんのこと、匿名化技術や堅牢なセキュリティ体制の構築は、研究開発の大前提となります。これは単なる法律遵守の問題ではなく、患者さんとの信頼関係の根幹に関わる問題です。
モデルの公平性とバイアス:
AIは、学習したデータという「過去」を映し出す鏡です。もしそのデータに社会的な偏り(特定の性別や人種、地域のデータが少ないなど)が含まれていれば、AIはその偏見を学習し、増幅して「未来」の予測に投影してしまいかねません。Parikhらが指摘するように(2019)、AIによる健康格差の拡大を防ぐため、常にバイアスを評価し、公平性を担保する仕組みが不可欠です。
相関関係と因果関係の峻別:
これは科学者・研究者として、特に心に刻むべき点です。AIが見つけ出すのは、あくまで「Aが起きるとBが起きやすい」という相関関係です。それが「AがBを引き起こす」という因果関係を直接証明するものではありません。この違いを混同することは、誤った治療介入に繋がる極めて重大なリスクをはらんでいます。AIの提示する関連性は、あくまで「仮説」の源泉として捉え、その検証は私たち人間の仕事です。
判断根拠の解釈可能性(XAI):
もしAIが「この患者は6時間後に危険な状態に陥る確率90%」と警告したとして、その「なぜ?」に答えられなければ、私たちはその情報を基に自信を持って次のアクションを起こすことはできません。Transformerのような複雑なモデルは「ブラックボックス」になりがちですが、その判断根拠を人間が理解できるようにする説明可能なAI(XAI)の研究は、AIを臨床現場で信頼できるパートナーにするための鍵となります。
最終的な責任の所在:
そして最も重要なことは、最終的な診断を下し、治療方針を決定し、患者さんと向き合い、その人生に責任を持つのは、アルゴリズムではなく、血の通った私たち医療者である、という原則です。AIは、私たちの知性と経験を拡張してくれる最も強力なツールの一つですが、その使い方を判断し、全責任を負うのは、常に私たち人間であるべきです。
AIという新しい道具を手に、医療をより良い方向へ進めるためには、技術的なスキルだけでなく、こうした倫理観や社会的な視座を併せ持つことが、これからの時代の医療者・研究者には求められていくのだと、私は強く信じています。
まとめ:AIという「新しい聴診器」を手に
ここまで、本当にお疲れ様でした。
この記事では、Transformerという、一見すると複雑なAIモデルの理論的な心臓部であるAttention機構の直感的な理解から始まり、実際にPyTorchでコードを一行ずつ書きながら、時系列予測モデルを動かすところまで、一緒に旅をしてきました。
私たちが実装したAttention機構が、データ全体の文脈を一度に見渡す力を持つこと、そしてそれが、複雑なストーリーが絡み合う医療データの分析において、従来のモデルを超える大きな可能性を秘めていることを、肌で感じていただけたのではないでしょうか。
今日学んだことは、広大な医療AIの世界への、ほんの第一歩に過ぎません。しかし、この一歩は、あなたがAIを単なる「使う側」から、自らの手で「創り出し、その意味を問いかける側」へと変わるための、決定的に重要な一歩です。
私たちが手にしたAIという「新しい聴診器」は、ただ患者さんの今の状態を聴くだけでなく、膨大なデータの中に眠る「過去の響き」と「未来の予兆」を聴き取ることを可能にしてくれるポータルを秘めています。
最終的に未来の医療を形作るのは、AIそのものではなく、AIという強力なツールを手にした、皆さんのような深い専門知識と温かい心を持った医療者・研究者です。本稿が、そのためのささやかな一助となれたのであれば、これに勝る喜びはありません。
ぜひ、ご自身のフィールドでこの新しい聴診器をどう活かすか、その可能性を探求し続けてください。皆さんの挑戦を、心から応援しています。
参考文献
- Hochreiter, S. and Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), pp.1735–1780.
- Mohr, D.C., Zhang, M. and Lattie, E.G. (2017). The future of digital mental health. JAMA Psychiatry, 74(6), pp.551-552.
- Parikh, R.B., Teeple, S. and Navathe, A.S. (2019). Addressing Bias in Artificial Intelligence in Health Care. JAMA, 322(24), pp.2377–2378.
- Perez-Gandia, C., Facchinetti, A., Sparacino, G., Cobelli, C., Gómez, E.J., Rigla, M., de Leiva, A. and Hernando, M.E. (2010). Artificial neural network algorithm for online glucose prediction from continuous glucose monitoring. Diabetes Technology & Therapeutics, 12(1), pp.81–88.
- Shashikumar, S.P., Wardi, G., Malhotra, A., Nemati, S. and Holder, A. (2021). A transformer-based model for early prediction of acute kidney injury in the intensive care unit. Nature Medicine, 27(12), pp.2131–2133.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I. (2017). Attention Is All You Need. In: Advances in Neural Information Processing Systems 30 (NIPS 2017).
- Zerveas, G., Jayaraman, S., Doshi, D., Kale, D. and Boning, A. (2021). A Transformer-based Framework for Multivariate Time Series Representation Learning. In: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. pp.2114–2124.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




