

TL; DR (要約)
創薬が、無数の「鍵」から正解を探す時代から、AIで「鍵穴」を理解し、最適な「鍵」を設計する時代へ。
AI創薬とゲノム医療の最前線を4つのステップでまとめます。
① 新しい「鍵」の設計
生成AIが、薬の候補となる全く新しい化合物の構造(鍵)を、ゼロから合理的に「創造」します。
② 「鍵穴」のカタログ化
AlphaFoldが、薬の標的となるタンパク質(鍵穴)の3D構造を正確に予測。創薬の「設計図」が手に入ります。
③ 最適なペアのマッチング
AIが患者個人のゲノムを解析し、その人だけの「鍵穴」に最も効果的な「鍵」(薬剤)を提案する、個別化医療を実現します。
④ 臨床試験の効率化
AIが薬の効きやすい患者を事前に予測することで、莫大なコストと時間がかかる臨床試験の成功率を高めます。
| この回の学習目標 | 1. 新規化合物デザイン: 生成AI(VAE, GANs)が新しい薬の候補を「創造」する基本原理を理解する。 2. タンパク質構造予測: AlphaFoldなどが創薬プロセスをどう変革したかを理解する。 3. 個別化医療: ゲノム情報とAIを組み合わせたプレシジョン・メディシンの概念を掴む。 4. 臨床試験の効率化: AIが臨床開発のボトルネックをいかに解消しうるかを学ぶ。 |
| 前提となる知識 | ・AI、機械学習、深層学習に関する基本的な概念の理解 ・Pythonプログラミングの初歩的な知識(変数、関数、クラスの概要) ・(推奨)高校レベルの生物学・化学の基礎知識 |
はじめに:創薬の常識が変わる日
「一つの新薬が承認される確率はおよそ3万分の1。研究開始から市場に出るまでには、10年以上の歳月と1000億円を超える費用が必要になる(1)。」
これは、私たち医療に関わる者であれば一度は耳にしたことがある、創薬という世界の厳しさを示す数字ではないでしょうか。これまで、新しい薬を生み出すプロセスは、標的となる体内のタンパク質(鍵穴)に対し、膨大な化合物ライブラリ(無数の鍵)の中から、適合するものをひたすら探し続ける、という途方もない試行錯誤の連続でした。それはまさに、暗く広大な倉庫の中で、たった一本の正しい鍵を手探りで探し当てるような、長く困難な旅だったと言えるかもしれません。
しかし今、AI、特に生成AI(Generative AI)が、この創薬の常識を根底から覆そうとしています。AIはもはや、暗闇の中で闇雲に鍵を試す探索者ではありません。標的となる鍵穴の三次元構造を原子レベルで精密に解析し、さらには「この鍵穴には、こんな形の鍵こそが最適だろう」と、全く新しい鍵のデザインそのものを合理的に「設計」できる、強力なパートナーになりつつあるのです。
本講座「作って理解する!シリーズ医療×生成系AI」の第9回は、この最もエキサイティングな領域、AI創薬とゲノム医療の世界に焦点を当てます。AIがいかにして新しい薬を「創造」し、一人ひとりの遺伝情報に合わせた「個別化医療」を実現していくのか、その最前線を見ていきましょう。
この記事では、「第9回: AI創薬とゲノム医療へのインパクト」で学ぶ4つの主要なトピックの全体像を、ダイジェストでご紹介します。
なお、本記事は各トピックの概要を掴んでいただくためのサマリーです。各技術の背景にある生成モデルの数理や、AlphaFoldのアルゴリズム、具体的なプログラミング実装、そして利用するライブラリといった詳細については、9.1以降の個別記事で丁寧に解説します。ご安心ください。
9.1 生成AIによる新規候補化合物のデザイン
イントロダクションで、私たちはAIを「全く新しい鍵を設計するパートナー」と表現しました。このセクションでは、その核心に迫ります。AIは、一体どのようにして、この世にまだ存在しない、それでいて薬として有望な特性を持つ可能性を秘めた化合物を「創造」するのでしょうか。
このプロセスの第一歩は、創薬化学者が長年の経験と深い洞察、そして時には幸運な閃きによって行ってきた、創造的なステップです。ここに生成AIが加わることで、私たちはその探索空間を、かつてない規模と速度で広げることができるようになります。
化合物を「言葉」として扱うSMILES記法
AIが化合物の構造を学習し、生成するためには、まずその複雑な三次元の形を、コンピューターが処理できる形式に変換しなくてはなりません。そのための「共通言語」として、現在広く使われているのがSMILES(Simplified Molecular-Input Line-Entry System)という表記法です。
これは、分子構造を一定のルールに従って一行の文字列(String)に変換するもので、まさに「化学構造のアルファベット」と呼べるかもしれません。
C,O,N: それぞれ炭素、酸素、窒素原子を表す。=,#: それぞれ二重結合、三重結合を表す。(): 分岐を表す。1,2, …: 環の開始点と終了点を示す番号。
例えば、解熱鎮痛薬としてよく知られるアスピリン(アセチルサリチル酸)の構造は、SMILESではO=C(C)Oc1ccccc1C(=O)Oという一行のテキストとして表現されます。この「構造のテキスト化」こそが、自然言語処理で絶大な力を発揮するAIモデルを、化学の世界に応用するための重要な鍵なのです。
新しい化合物を「創造」するAI:VAEとGANs
AIは、既存の数百万種類もの化合物データベースをこのSMILES形式で学習し、分子構造における「文法」や「デザインパターン」を習得します。そして、その知識を元に、全く新しいSMILES文字列、すなわち新しい化合物を「生成」します。この「創造」を実現する代表的な生成AIモデルが、VAEとGANsです。
| モデル | アナロジー(直感的なイメージ) | 仕組みの概要 |
|---|---|---|
| VAE (変分オートエンコーダ) | 「分子のコンセプトデザイナー」 | 既存の多種多様な分子構造を学習し、それらの「設計思想」や「概念」を、潜在空間(Latent Space)と呼ばれる多次元の地図上に配置します。この地図上では、似た特性を持つ分子は近くに位置します。新しい分子を創りたい時、私たちはこの地図上の未知の座標(まだ分子が存在しない場所)を指定します。すると、VAEはその座標が持つであろう「概念」を解釈し、対応する新しい分子構造を生成してくれるのです。 |
| GANs (敵対的生成ネットワーク) | 「贋作画家と鑑定士の真剣勝負」 | 2つのAIが互いに競い合う、ユニークな学習方法です。一方は「新しい化合物を生成するAI(生成器/贋作画家)」、もう一方は「その化合物が本物らしいか(既知の薬物様化合物に近いか)を見破るAI(識別器/鑑定士)」です。贋作画家は鑑定士を騙そうと、より精巧な贋作(新しい化合物)を作り、鑑定士はそれを見破ろうと鑑定眼を磨きます。この競争の果てに、鑑定士でも見破れないほど「本物らしい」、有望な化合物が生まれるのです。 |
ハンズオン:SMILESという「言葉」を「形」にする
生成AIが新しいSMILES文字列を提案してくれても、それがただの文字の羅列では、私たち化学や医学の専門家にはピンときません。その「言葉」を、私たちが慣れ親しんだ「形」、つまり分子構造図に翻訳してくれるツールが必要です。その代表格が、化学情報学の世界で広く使われているrdkitというPythonライブラリです。
実際に、SMILES文字列から分子のイメージを生成してみましょう。
【実行前の準備】以下のコードは、化合物の構造を描画するためにrdkitというライブラリを使用します。実行前にGoogle Colabのセルで !pip install japanize_matplotlib rdkit-pypi を実行してください。(rdkitはBSD-3-Clause Licenseで提供されています。)
graph TD
A["開始"] --> B["1. SMILES文字列を準備
(化学構造をテキストで表現)"];
B --> C["2. 文字列を分子オブジェクトに変換
(コンピュータが扱えるデータ形式へ)"];
C --> D["3. 分子オブジェクトを画像として描画
(構造式をグリッド形式で)"];
D --> E["4. 生成された画像を表示"];
E --> F["終了"];
# RDKitという化学情報学ライブラリから必要な機能をインポートします
from rdkit import Chem
from rdkit.Chem import Draw
from rdkit.Chem.Draw import IPythonConsole # IPython環境(Colabなど)で画像を表示する機能
import matplotlib.pyplot as plt # グラフ描画ライブラリ
import japanize_matplotlib # 日本語表示を有効化
# --- SMILES文字列から分子構造への変換 ---
# アスピリンとイブプロフェンのSMILES文字列を定義します
smiles_aspirin = 'O=C(C)Oc1ccccc1C(=O)O'
smiles_ibuprofen = 'CC(C)Cc1ccc(C(C)C(=O)O)cc1'
# Chem.MolFromSmiles関数で、SMILES文字列をRDKitが扱える分子オブジェクトに変換します
mol_aspirin = Chem.MolFromSmiles(smiles_aspirin)
mol_ibuprofen = Chem.MolFromSmiles(smiles_ibuprofen)
# --- 分子構造の可視化 ---
# 2つの分子をリストにまとめます
mols = [mol_aspirin, mol_ibuprofen]
# 分子名もリストにまとめます
legends = ['アスピリン (Aspirin)', 'イブプロフェン (Ibuprofen)']
# Draw.MolsToGridImage関数で、複数の分子構造をグリッド形式の画像として描画します
# molsPerRow=2 は、1行に2つの分子を描画する設定です
# subImgSize=(300, 300) は、各画像のサイズを指定します
# legends=legends は、各画像の下に表示する凡例(分子名)を指定します
img = Draw.MolsToGridImage(mols, molsPerRow=2, subImgSize=(300, 300), legends=legends)
# --- 生成された画像の表示 ---
# Google ColabなどのJupyter Notebook環境でこのコードを実行すると、
# 最後の行に変数`img`を置くことで、生成された分子構造の画像がセルに表示されます。
# このコードブロック自体が生成AIではありませんが、
# AIが生成したSMILES文字列をこのように可視化して評価する、という流れを理解するためのものです。
img
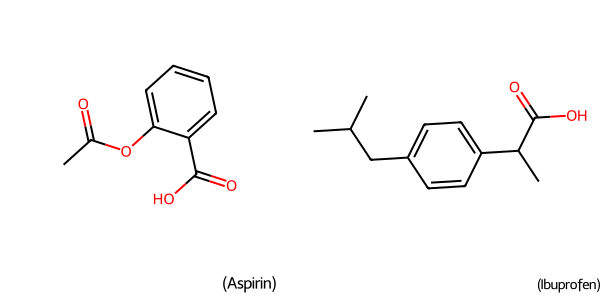
このように、生成AIは有望な化合物の「設計図(SMILES)」を提案し、私たちはrdkitのようなツールを使ってその設計図を「可視化」し、創薬化学者としての知見を加えて評価していく、という協働作業が、新しい創薬の姿となりつつあります。
9.2 タンパク質立体構造予測と創薬への応用
前のセクションでは、生成AIが新しい「鍵」、つまり薬の候補となる化合物をデザインする様子を見てきました。しかし、どれほど優れた鍵を無数に作り出しても、それが差し込まれるべき「鍵穴」、すなわち創薬ターゲットとなるタンパク質の正確な形が分からなければ、文字通り話になりません。
薬は、体内の特定のタンパク質に結合し、その働きを調節することで効果を発揮します。そのため、合理的で効率的な創薬の第一歩は、この鍵穴の三次元構造を原子レベルで正確に把握することなのです。
生命科学における50年来の難問:「タンパク質折り畳み問題」
タンパク質は、アミノ酸が長く一本につながった鎖(ポリペプチド鎖)からできています。しかし、生命活動を担うとき、タンパク質は単なる紐状では機能しません。細胞内で合成されたその瞬間、この長い鎖は、物理法則に従って自発的に、極めて精密で複雑な、固有の立体構造へと一瞬で「折り畳まれ(フォールディング)」ます。
この「アミノ酸配列という一次元の文字列情報から、機能を持つ三次元の立体構造を予測する」という課題が、タンパク質折り畳み問題(Protein Folding Problem)です。
タンパク質を構成するアミノ酸の組み合わせは天文学的な数にのぼり、取りうる立体構造のパターンも膨大であるため、力任せの計算では到底解くことができませんでした。この問題は、実に50年以上にわたり、生命科学における「グランドチャレンジ」とされてきました。
AlphaFoldの衝撃:AIが生命科学の常識を塗り替えた日
この長年の難問に、驚異的なブレークスルーをもたらしたのが、2020年にGoogle傘下のDeepMind社が発表したAIモデル、AlphaFoldです(3)。
2年に一度開催されるタンパク質構造予測の精度を競う国際コンテスト(CASP)において、AlphaFold2は他の追随を許さない圧倒的な精度を叩き出し、専門家たちに「この問題は、基本的に解決された」と言わしめるほどの衝撃を与えました。
では、AlphaFoldは何が違ったのでしょうか。その核心には、私たちがこれまでのレッスンで学んできたTransformerとAttention機構の応用があります。
AlphaFoldの仕組み(概念的な理解):
AlphaFoldは、単一の巨大なネットワークではなく、複数のAIが連携する洗練されたシステムです。そのアイデアの根幹は、以下のように理解できるかもしれません。
- 共進化情報の抽出: まず、AIは既存の膨大なタンパク質データベースを検索し、異なる生物種間で、あるアミノ酸のペアが進化の過程でどのように一緒に変化してきたか(共進化)を解析します。もし、配列上は遠く離れた2つのアミノ酸が、常にペアで変異しているなら、それらは立体構造上では近くに位置しているはずです。AIは、この情報から「どのアミノ酸とどのアミノ酸が近くにありそうか」という距離の制約マップを作成します。
- Attention機構による構造の推論: 次に、Transformerベースのネットワークが、この距離マップと元のアミノ酸配列の両方に「注意(Attention)」を向けます。そして、「このアミノ酸とこのアミノ酸の距離関係が、全体の構造にとって最も重要だ」といったように、構造全体を形成する上で重要な相互作用を見つけ出し、最も確からしい三次元座標を予測していくのです。
創薬におけるインパクト:「鍵穴カタログ」の時代へ
AlphaFoldの登場は、創薬の世界にパラダイムシフトをもたらしました。DeepMind社と欧州バイオインフォマティクス研究所(EMBL-EBI)は、AlphaFoldによって予測された、ヒトのほぼ全てのタンパク質を含む、数億種類ものタンパク質の立体構造を「AlphaFold Protein Structure Database」として無償で公開したのです(4)。
これは、世界中の研究者が、いつでも自由に参照できる、生命の「鍵穴カタログ」が手に入ったことを意味します。
| 観点 | Before AlphaFold | After AlphaFold |
|---|---|---|
| 構造決定の手法 | X線結晶構造解析、クライオ電子顕微鏡など、多大な労力とコストを要する実験的手法が主。 | アミノ酸配列を入力するだけで、高精度な立体構造を計算によって予測可能に。 |
| 時間とコスト | 一つの構造決定に数ヶ月〜数年、数千万円以上のコスト。 | 数分〜数時間、極めて低コスト(あるいはデータベースから無料で入手)。 |
| 利用可能な構造数 | 実験的に決定されたものに限られ、全体の数%に過ぎなかった。 | ほぼ全ての既知タンパク質を網羅する、数億の構造が利用可能。 |
この「鍵穴カタログ」の登場により、私たちはもはや闇雲に鍵を探す必要はありません。標的とするタンパク質の正確な三次元構造(鍵穴の形)を前提として、そこにぴったりとはまる化合物をコンピュータ上で合理的に設計・探索する合理的創薬(Structure-Based Drug Design, SBDD)が、飛躍的に加速されることになりました。
これで、9.1で見た「新しい鍵をデザインするAI」と、このセクションで手に入れた「ほぼ全ての鍵穴のカタログ」が揃いました。この二つを組み合わせることで、創薬は次のステージへと進むのです。
9.3 ゲノム情報解析と個別化医療(Precision Medicine)
9.1で「鍵」となる化合物を、9.2で「鍵穴」であるタンパク質を見てきました。しかしここで、最も重要な登場人物が、まだ舞台に上がっていません。それは、私たち医療者が向き合う、唯一無二の存在——「患者さん」です。
同じ「非小細胞肺がん」という診断名であっても、ある患者さんの病態を駆動している「鍵穴」はEGFR遺伝子の変異によって形が変わり、また別の患者さんの「鍵穴」はALK遺伝子の融合によって歪んでいるかもしれません。この「鍵穴」の違いを無視して、すべての人に同じ「鍵(薬剤)」を渡しても、効果が出ないどころか、有害事象につながる可能性さえあります。
個別化医療(Precision Medicine)とは、まさにこの一人ひとりの遺伝情報(ゲノム)や生活習慣、環境要因といった個々人の違いを深く理解し、その人に最も効果が期待でき、かつ副作用が少ない治療法を「狙い撃ち」で選択する、次世代の医療アプローチです。
| 観点 | 従来の医療 (One-size-fits-all) | 個別化医療 (Precision Medicine) |
|---|---|---|
| 診断 | 臓器や組織型に基づく(例:肺がん、乳がん) | 遺伝子変異など、分子レベルの原因に基づく(例:EGFR変異陽性肺がん) |
| 治療 | 標準化されたプロトコルを、多くの患者に適用する。 | 特定の分子標的に対して設計された薬剤を、該当する患者にのみ投与する。 |
| 根拠 | 大規模な集団での平均的な治療効果。 | 個人のゲノム情報やバイオマーカー。 |
AIが駆動する個別化医療のワークフロー
この個別化医療を実現するためには、患者さん一人の細胞に含まれる30億塩基対もの膨大なゲノム情報を読み解き、その中から病気の原因となっている、たった一つの重要な変異を見つけ出す必要があります。これは人間だけで行うにはあまりに膨大で複雑な作業であり、AIの力が不可欠となります。
AIが担う具体的な役割
上記のフローの中で、AIは特に以下の重要な役割を担います。
- ゲノム解析の精度向上: 次世代シーケンサから出力されるデータには、多くのノイズやエラーが含まれます。深層学習を用いたAIモデルは、これらのノイズから真の遺伝子変異を高精度に識別することに貢献します。また、TCGA (The Cancer Genome Atlas) のような巨大な公開ゲノムデータベースを学習し、特定された変異が病的意義を持つものか(Pathogenic)、あるいは良性の多型なのか(Benign)を予測します。
- 治療薬のマッチングと提案: 特定されたドライバー変異に対し、AIは既存の薬剤データベースや最新の論文情報を瞬時に検索し、最適な分子標的薬やコンパニオン診断薬の候補を提示します。これは、多忙な臨床医が常に最新の知識を維持するための、強力な意思決定支援となります。
- 究極の個別化創薬(N-of-1創薬)へ: もし、その患者さんだけが持つ非常に稀な変異で、既存薬がなければどうでしょう。その時こそ、本章で学んできた技術の集大成です。9.2のAlphaFoldでその患者さん特有の変異タンパク質の「鍵穴」の形を予測し、9.1の生成AIでその特殊な鍵穴にだけ結合する「鍵」をゼロから設計する。一人の患者さんのために、一つの薬を創り出す——そんな「N-of-1(エヌオブワン)創薬」も、理論上は視野に入ってくるのです。
もちろん、これはまだ未来のビジョンであり、倫理的・技術的な課題も山積みです。しかし、AIとゲノム科学の融合が、医療を「疾患を治療する」時代から「個々の患者を治療する」時代へと、確実に押し進めている。その大きな潮流を感じていただければ幸いです。
9.4 臨床試験の効率化:AIは「死の谷」を越えるための羅針盤となるか
これまでのセクションで、私たちはAIを駆使して新しい「鍵」を設計し(9.1)、精密な「鍵穴」のカタログを手に入れ(9.2)、さらにはゲノム情報に基づいて最適な「鍵と鍵穴のペア」を患者さんごとに見つける(9.3)、という夢のようなプロセスを見てきました。
しかし、ここからが創薬における最も長く、険しい道のり、「臨床試験」です。実験室で有望だった候補化合物が、ヒトでの安全性と有効性を証明できずに開発中止となる確率は極めて高く、この非臨床から臨床への移行フェーズは、しばしば「死の谷(Valley of Death)」とも呼ばれます。実際、臨床試験の各フェーズの成功率は、第I相から承認までをトータルすると10%にも満たないという報告もあります(9)。
この「死の谷」を越え、有望な薬をより確実に患者さんの元へ届けるために、AIは強力な羅針盤となり得ます。
なぜ臨床試験は失敗するのか? 「患者の不均一性」という壁
伝統的な臨床試験が困難を極める最大の理由の一つが、患者の不均一性(Patient Heterogeneity)です。例えば、ある新薬が、実際には特定のバイオマーカーを持つ15%の患者さんには劇的に効くとしても、残りの85%には効果がない場合、集団全体として統計的な有意差が示されず、試験は「失敗」と結論づけられてしまいます。宝物のような薬が、その他大勢のデータの中に埋もれて見過ごされてしまうのです。
AIは、この不均一性という壁を打ち破るための、新しいアプローチを可能にします。
AIの役割①:最適な被験者選定(患者層別化)
AIの最も直接的な貢献は、「その薬が最も効く可能性が高い患者さん」を、臨床試験の開始前に高精度で見つけ出すことです。これを患者層別化(Patient Stratification)と呼びます。
AIモデルは、電子カルテ、ゲノム情報、画像データ、さらにはウェアラブルデバイスから得られるデータまで、多種多様な情報を統合的に解析します。そして、過去の臨床試験データなどを基に、「どのような特徴を持つ患者が治療に良好な反応を示したか」というパターンを学習します。
このアプローチにより、臨床試験は、本当に薬が効く可能性の高い集団を対象に、より小規模で、より短期間に、そしてより高い成功確率で実施することが可能になります。
AIの役割②:開発の「GO/NO-GO」を支援する成功確率予測
製薬企業にとって、どの候補化合物の開発を進め、どれを中止するかという判断は、経営を左右する極めて重要な意思決定です。AIは、この意思決定をデータに基づいて支援します。
AIモデルは、化合物の物理化学的特性、非臨床試験の結果、ターゲットとするタンパク質の生物学的情報、そしてClinicalTrials.govのようなデータベースに蓄積された何万もの過去の臨床試験の成否データなどを学習します。そして、新しい候補化合物が、第I相、第II相、第III相をそれぞれ突破できる確率 \(P(\text{success})\) を予測します。この客観的な予測スコアが、莫大な投資を行うかどうかの判断(GO/NO-GO判断)における、重要な材料の一つとなるのです。
臨床試験の未来像:In Silico試験とデジタルツイン
さらに未来を見据えれば、AIは臨床試験のあり方そのものを変えるかもしれません。その鍵となるのが、デジタルツインとIn Silico(イン・シリコ)臨床試験です。
- デジタルツイン: ある患者さん一人の詳細なゲノム、臨床、生活習慣データを統合し、その人の生理機能や病態をコンピュータ上に再現した「デジタルの双子」。
- In Silico 試験: 新薬を、まずこの無数のデジタルツインに対してコンピュータ上で投与し、その有効性や副作用をシミュレーションする。
これにより、実際にヒトに投与する前に、どのような患者に効果があり、どのような副作用が懸念されるかを大規模に予測することが可能になります。もちろん、最終的には実際の人間での試験が必要ですが、その前段階の安全性と有効性のスクリーニングを、AIが肩代わりしてくれる未来がすぐそこまで来ています。
| AIの役割 | 解決する問い | 使われる主な技術 | インパクト |
|---|---|---|---|
| 患者層別化 | 「誰に」この薬は効くのか? | 教師あり学習、クラスタリング | 試験の小規模化・短期化・成功率向上 |
| 成功確率予測 | この薬の開発は「進めるべきか」? | 予測モデリング、過去のデータ解析 | R&D投資の最適化、意思決定支援 |
| In Silico 試験 | 「もし投与したら」どうなるか? | デジタルツイン、生成AI、シミュレーション | 開発初期での安全性・有効性スクリーニング、倫理的配慮 |
AIは、創薬という長く困難な旅の、あらゆる段階で羅針盤となり、私たちを導いてくれます。それは、これまで多くの理由で開発を断念せざるを得なかった、希少疾患の治療薬などにも、新たな光を当てるものに他ならないのです。
まとめ:創薬を「発見の科学」から「設計の科学」へ
今回は、AIが創薬とゲノム医療の最前線でどのようなインパクトを与えているか、その概要をご紹介しました。
- 新規化合物デザイン: 生成AIが、薬の候補となる全く新しい化学構造を「創造」する。
- タンパク質構造予測: AlphaFoldが、薬の標的となる「鍵穴」の形を正確に解き明かす。
- 個別化医療: ゲノム解析とAIを組み合わせ、患者一人ひとりに最適な治療を目指す。
- 臨床試験の効率化: AIが、最も成功する可能性の高い試験計画を支援する。
AIの登場により、創薬は、偶然の発見(セレンディピティ)に頼る部分が大きかった「発見の科学」から、データと理論に基づいて合理的に薬を設計していく「設計の科学」へと、その姿を大きく変えようとしています。これは、より多くの患者さんへ、より早く、より効果的な治療を届けるための、大きな希望と言えるでしょう。
参考文献
- Gómez-Bombarelli R, Wei JN, Duvenaud D, Hernández-Lobato JM, Sánchez-Lengeling B, Ekins S, et al. Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules. ACS Cent Sci. 2018 May 23;4(5):268-276.
- Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Advances in Neural Information Processing Systems 27. Curran Associates, Inc.; 2014. p. 2672-2680.
- Jumper J, Evans R, Pritzel A, Green T, Figurnov M, Ronneberger O, et al. Highly accurate protein structure prediction with AlphaFold. Nature. 2021 Aug;596(7873):583-589.
- Varadi M, Anyango S, Deshpande M, Nair S, Natassia C, Yordanova G, et al. AlphaFold Protein Structure Database: massively expanding the structural coverage of protein-sequence space with high-accuracy models. Nucleic Acids Res. 2022 Jan 7;50(D1):D439-D444.
- Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nat Med. 2019 Jan;25(1):44-56.
- Liu Y, Jain A, Eng C, Way DH, Lee K, Bui P, et al. A deep learning system for differential diagnosis of skin diseases. Nat Med. 2020 Jun;26(6):900-908.
- Esteva A, Robicquet A, Ramsundar B, Kuleshov V, DePristo M, Chou K, et al. A guide to deep learning in healthcare. Nat Med. 2019 Jan;25(1):24-29.
- Ching T, Himmelstein DS, Beaulieu-Jones BK, Kalinin AA, Do BT, Way GP, et al. Opportunities and obstacles for deep learning in biology and medicine. J R Soc Interface. 2018 Apr;15(141):20170387.
- Vamathevan J, Clark D, Czodrowski P, Dunham I, Ferran E, Lee G, et al. Applications of machine learning in drug discovery and development. Nat Rev Drug Discov. 2019 Jul;18(6):463-477.
- The Lancet. Artificial intelligence in drug discovery: a new wolf in a flock of sheep? Lancet. 2019 May 18;393(10185):2011.
- Fleming N. How artificial intelligence is changing drug discovery. Nature. 2018 May;557(7707):S55-S57.
- van der Schaar M, Alaa AM, Floto A, et al. How AI is transforming the future of healthcare. A report from the Royal Society. London: The Royal Society; 2019.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




