ここまで、長い旅路を本当にお疲れ様でした。
A1でAIと「握手」してその正体を知り、A11からはGoogle Colabという強力な「武器」を手に、実際にコードを書き続けてきましたね。
あなたはもう、立派なAI開発者の入り口に立っています。
さて、研究室(Google Colab)で素晴らしい精度の「肺炎診断AI」が完成したとしましょう。コード(設計図)はGoogle Driveに保存されています。
しかし、ここで一つの重大な問題が発生します。
「ブラウザを閉じてランタイムが切れると、せっかく学習させた『脳みそ(重み)』が消えてしまう」のです。
ノートブック(コード)自体は残りますが、何時間も計算して調整されたメモリ上のAIモデルは、電源を切れば消えてしまう「揮発性」の存在です。
これでは、実際の診察室に持ち運んだり、病院の電子カルテシステムに組み込んで毎日使ったりすることはできません。
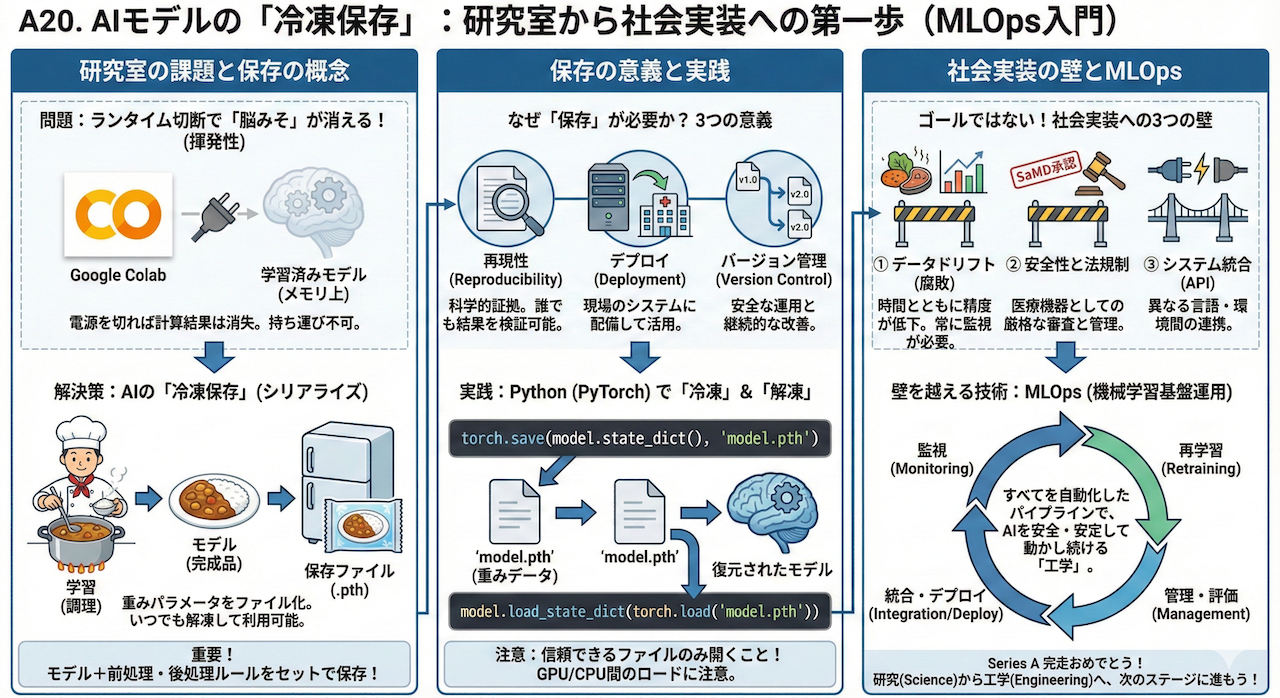
そこで必要になるのが、AIの「冷凍保存(シリアライズ)」という技術です。
今回は、苦労して育てたAIを「ファイル」としてカチカチに凍らせて保存し、必要な時にいつでもどこでも解凍して使えるようにする技術を学びます。
そしてそれは、研究室の中だけの実験から、社会で実際に役立つシステムへとAIを進化させる、MLOps(機械学習基盤運用)という広大な世界への第一歩でもあります。
1. 「料理」と「冷凍食品」:AIにおける保存の概念

AI開発のプロセスを、皆さんに馴染み深い「カレー作り」に例えて理解しましょう。
AIを作る工程と、それを使う工程は、明確に分かれています。
AI開発とカレー作りのアナロジー
- 学習(Training)=「調理」
野菜を切り、肉を炒め、スパイスを絶妙に調合して、何時間もコトコト煮込む工程です。
これには、料理人の技術(アルゴリズム)と、膨大な時間、そしてガス代や電気代(計算コスト=電気代やGPU使用料)がかかります。 - モデル(Model)=「完成したカレー」
長い時間をかけて煮込まれ、味が染み込んだ完成品です。
このカレーの中には、調理の過程で凝縮された「旨味(学習した特徴やパターン)」が詰まっています。 - 推論(Inference)=「提供(食事)」
お客さん(新しいデータ)に対して、完成したカレーを提供することです。
お客さんが「美味しい(正しい診断)!」と言うかどうかを試す段階です。
もし、レストランでお客さんが来るたびに、「いらっしゃいませ!少々お待ちください、今からタマネギの皮をむきます!」とゼロから調理を始めていたらどうなるでしょうか?
おそらく、お店は回りませんし、お客さんも怒って帰ってしまいますよね。
理想は、一度完璧に作ったカレーを「冷凍保存(Save)」しておき、注文が入ったら電子レンジで「解凍(Load)」して、一瞬で提供することです。
AIの世界でも全く同じことが行われています。一度学習が完了したAIは、ファイルとして保存しておけば、二度と学習(調理)をし直す必要はありません。
重要:保存するのは「モデル」だけじゃない!
ここで一つ、非常に重要な落とし穴をお伝えします。
実は、AIモデル(重みパラメータ)だけを保存しても、医療現場では全く役に立たないことがあります。
なぜなら、AIに入力する前の「前処理(画像のリサイズや正規化)」や、AIが出した確率を診断結果に変換する「後処理(閾値の決定など)」のルールが変わってしまうと、出力結果も変わってしまうからです。
- 前処理: リサイズ、正規化、欠損値の埋め方など
- 後処理: 「確率何%以上なら『病気』と判定するか」の閾値など
- 推論条件: 使用したライブラリのバージョンなど
これら全てがセットになって初めて、一つの「診断システム」として機能します。
カレー(モデル)だけでなく、お皿やスプーン(前後処理)までセットで保存して初めて、同じ味を提供できるのです。
シリアライズ(直列化)とは?
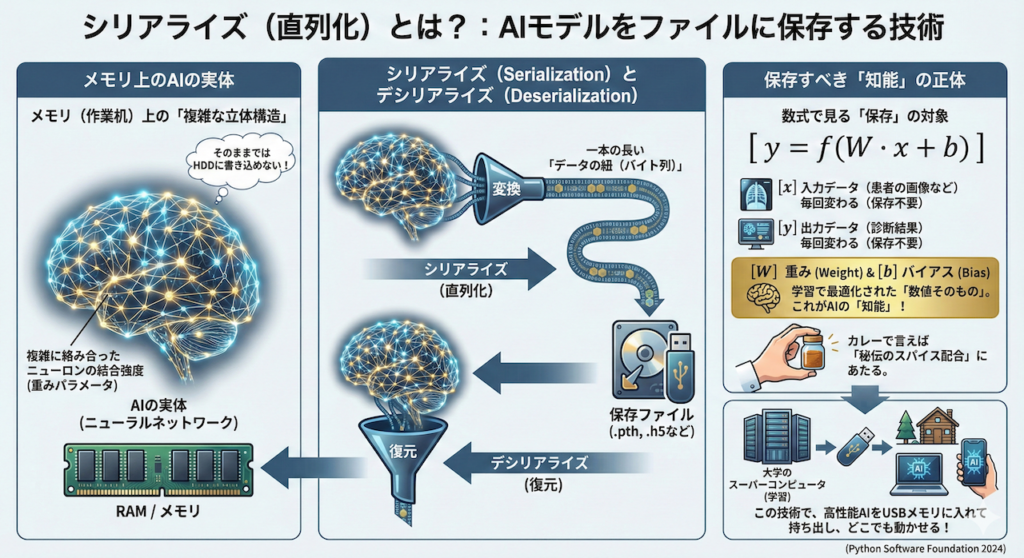
では、具体的にどうやって保存するのでしょうか?ここで登場するのが「シリアライズ(Serialization)」というコンピュータ用語です。
AIの実体は、メモリ(作業机)の上に散らばっている、複雑に絡み合ったニューロンの結合強度(重みパラメータ)です。
これをそのままでは、ハードディスクやUSBメモリに書き込むことができません。
そこで、この複雑な立体構造を、一本の長い「データの紐(バイト列)」に変換して、ファイルとして保存できる形にします。
これをシリアライズ(直列化)と呼びます (Python Software Foundation 2024)。
逆に、保存されたファイルから元の立体的なAIの形に戻すことをデシリアライズと呼びます。
数式で確認してみましょう。AIモデル、特にニューラルネットワークの実体は、巨大な行列計算の式でした。
\[ y = f(W \cdot x + b) \]
- \( x \):入力データ(患者さんの画像など)
- \( y \):出力データ(診断結果)
- \( W \):重み(Weight)
- \( b \):バイアス(Bias)
ここで「保存」すべきなのは、毎回変わる入力 \( x \) や出力 \( y \) ではありません。
何千枚もの画像を読み込んで、学習によって最適化された「重みパラメータ \( W \)」と「バイアス \( b \)」の数値そのものです。
これこそが、AIが獲得した「知能」の正体であり、カレーで言えば「秘伝のスパイス配合」に当たります。
この技術があるからこそ、大学の巨大なスーパーコンピュータで数週間かけて学習させた超高性能なAIモデルを、小さなUSBメモリに入れて持ち出し、電気もネットもない場所にあるノートPCや、スマートフォンのようなエッジデバイスの中で動かすことができるのです。
2. なぜ「保存」が社会実装の第一歩なのか?
「たかがファイルの保存でしょ?」と思われるかもしれません。
しかし、AI開発においてモデルを保存するという行為は、単に「データを消さないため」だけではありません。
それは、あなたのAIが「研究室の中だけの実験(Research)」から、社会で役立つ「製品(Product)」へとフェーズを移行させる、まさに決定的な瞬間なのです。
具体的に、保存がもたらす3つの重要な意義を見ていきましょう。
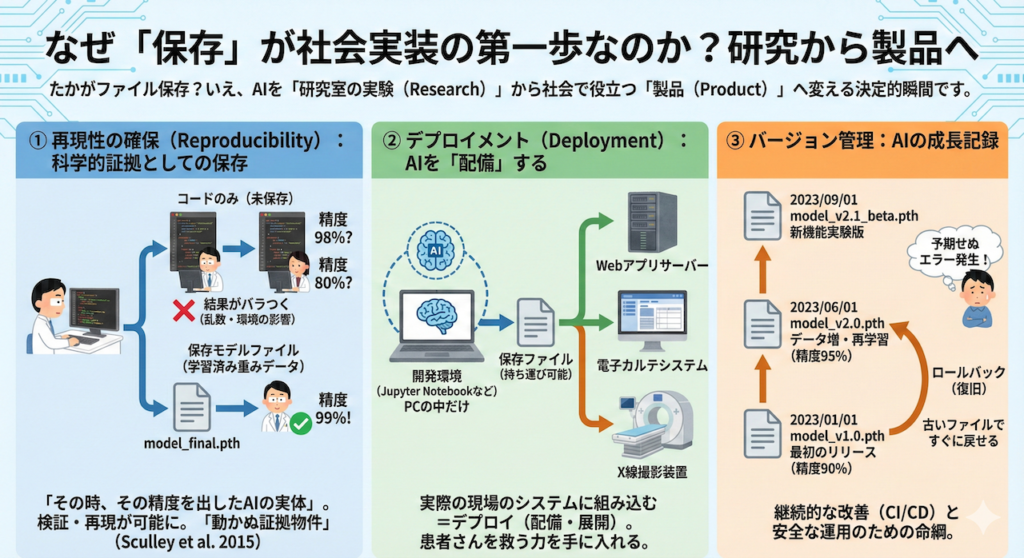
① 再現性の確保(Reproducibility):科学的証拠としての保存
例えば、あなたが「精度99%で病気を発見できるAIを作りました!」と論文で発表したとします。
しかし、もしそのAIモデル自体が保存されておらず、コードだけが残っていたらどうなるでしょうか?
他の研究者が同じコードを動かしても、乱数の影響や微妙な環境の違いで、同じ結果が出ない(精度が98%や80%になってしまう)ことは頻繁に起こります。
保存されたモデルファイル(学習済みの重みデータ)は、「その時、その精度を出したAIの実体」そのものです。
これを共有することで、誰でもあなたの実験結果を検証し、再現することが可能になります。
つまり、保存ファイルはAI研究における「動かぬ証拠物件」となるのです (Sculley et al. 2015)。
② デプロイメント(Deployment):AIを「配備」する
AIを病院で使うためには、Pythonの開発環境(Jupyter Notebookなど)からAIを取り出し、実際のシステムの中に組み込む必要があります。
例えば、Webアプリのサーバーに置いたり、電子カルテシステムの中にインストールしたり、あるいはX線撮影装置の中に埋め込んだりします。
この、AIを実際の現場で動くシステムに配置することを「デプロイ(Deployment:配備・展開)」と呼びます。
ファイルとして保存されて初めて、AIは「持ち運び可能」になり、デプロイが可能になります。
あなたのPCの中にいるだけのAIは、まだ誰の役にも立っていません。デプロイされて初めて、AIは患者さんを救う力を手に入れるのです。
③ バージョン管理:AIの成長記録
AI開発は一度で終わりではありません。新しいデータで学習させたり、構造を改良したりして、どんどん進化していきます。
この時、モデルをファイルとして保存しておくことで、以下のような管理が可能になります。
AIのバージョン管理の例
model_v1.0.pth:最初のリリース版(精度90%)model_v2.0.pth:データを増やして再学習した版(精度95%)model_v2.1_beta.pth:新しい機能を試している実験版
もし、最新のV2.0を導入したら予期せぬエラーが出たとしましょう。
古いファイル(V1.0)が残っていれば、すぐにシステムを前の状態に戻す(ロールバックする)ことができます。
このように、モデルをファイルとして管理することは、継続的な改善(CI/CD)と安全な運用のための命綱となります。
3. 【実践】PythonでAIを「冷凍」してみよう
理屈はわかりましたね。
では、実際にPython(PyTorch)を使って、AIモデルを保存し、そして復元する魔法のようなプロセスを体験してみましょう。
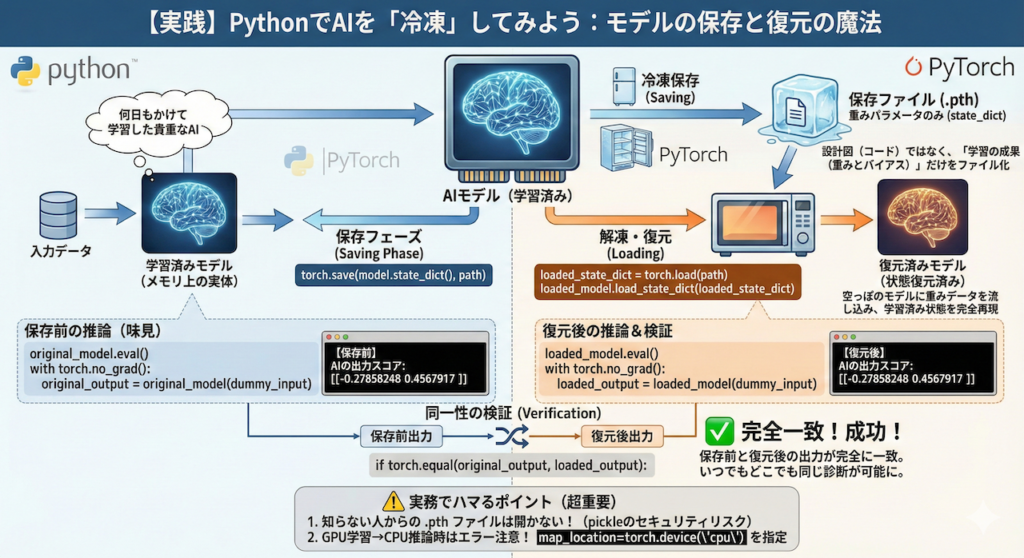
今回は、非常にシンプルなニューラルネットワークを作成します。
これを「何日もかけて学習した貴重なAI」だと仮定して、保存・読み込みの実験を行います。
実行前の準備
以下のコードで日本語のグラフを表示させるには、あらかじめターミナルやコマンドプロンプト(Google Colabではコードセル内)で pip install japanize-matplotlib を実行してライブラリをインストールしてください。
!pip install japanize-matplotlib以下は、モデルの定義から、保存、読み込み、そして「本当に同じものか?」の検証までを一気に行う完全なサンプルコードです。
各行に詳しいコメントを付けているので、読みながら実行してみてください。
import torch
import torch.nn as nn
import os
import japanize_matplotlib
import matplotlib.pyplot as plt
# ==========================================
# 1. 実行環境の固定(再現性のため)
# ==========================================
# 乱数(ランダムな数値)の種を「42」に固定します。
# これにより、いつ誰が実行しても毎回全く同じ「ランダムな」値が生成されます。
# 実験結果を再現するために非常に重要な手続きです。
torch.manual_seed(42)
# ==========================================
# 2. シンプルなAIモデル(ミニ脳)の定義
# ==========================================
# ここでAIの「設計図」を作ります。
# 今回は「10個の検査データ」から「病気あり/なし」を判定するAIを想定します。
class SimpleMedicalAI(nn.Module):
def __init__(self):
super(SimpleMedicalAI, self).__init__()
# 第1層(入力層→中間層):
# 10個の入力データを受け取り、重み計算をして5個の特徴に変換します。
self.fc1 = nn.Linear(10, 5)
# 活性化関数(ReLU):
# マイナスの値を0にして、信号の「発火」を模倣します。
self.relu = nn.ReLU()
# 第2層(中間層→出力層):
# 5個の特徴をまとめて、最終的に2個のスコア(病気なし確率、あり確率)を出します。
self.fc2 = nn.Linear(5, 2)
# データの通り道(順伝播)を定義します
def forward(self, x):
out = self.fc1(x) # 第1層を通る
out = self.relu(out) # 活性化関数を通る
out = self.fc2(out) # 第2層を通って出力
return out
# ==========================================
# 3. モデルのインスタンス化(AIの誕生)
# ==========================================
# 設計図(class)から実体(instance)を作ります。
# この時点で、重みパラメータ(W)とバイアス(b)はランダムな値で初期化されています。
original_model = SimpleMedicalAI()
# ダミーの入力データを作成します。
# 患者さん1名分の、10項目の検査データ(ランダムな数値)だと想像してください。
dummy_input = torch.randn(1, 10)
# 保存前の推論実行(味見)
# .eval()はモデルを「推論モード(学習しないモード)」に切り替えるスイッチです。
# これを忘れると、推論結果が不安定になることがあります。
original_model.eval()
# with torch.no_grad(): は「学習のための計算(勾配計算)はしないでね」という指示です。
# メモリを節約し、計算を高速化します。
with torch.no_grad():
original_output = original_model(dummy_input)
print(f"【保存前】AIの出力スコア:\n{original_output.numpy()}")
# ここで表示される数値が、このAIが出した「答え」です。
# ==========================================
# 4. モデルの「冷凍保存」(State Dictionaryの保存)
# ==========================================
# いよいよ保存です!
# 保存するファイル名を決めます。拡張子は .pth や .pt が一般的です。
save_path = "my_medical_ai_v1.pth"
# torch.save() で保存します。
# ここで重要なのは、モデル全体ではなく「state_dict()(状態辞書)」を保存している点です。
# state_dict には、学習された「重み」と「バイアス」の数値だけが詰まっています。
torch.save(original_model.state_dict(), save_path)
print(f"\n💾 モデルの重みを '{save_path}' に保存しました!")
print("これでPCの電源を切っても、このファイルさえあればAIは蘇ります。")
# ==========================================
# 5. モデルの「解凍・復元」
# ==========================================
# 復元してみましょう。まずは「空っぽのAI」を用意します。
# 設計図(クラス)は同じものを使います。
# まだ学習していない、初期状態(ランダムな重み)のモデルです。
loaded_model = SimpleMedicalAI()
# 先ほど保存したファイルから、重みデータ(state_dict)を読み込みます。
loaded_state_dict = torch.load(save_path)
# 読み込んだ重みを、空っぽのモデルに「流し込み(ロード)」ます。
# これで、学習済みの脳みそが移植されました!
loaded_model.load_state_dict(loaded_state_dict)
print("\n🧊 ファイルからモデルを復元しました!")
# ==========================================
# 6. 同一性の検証
# ==========================================
# 本当に元通りになったか確認しましょう。
# 復元したモデルを推論モードにします。
loaded_model.eval()
# 保存前と同じ入力データ(dummy_input)を入れてみます。
with torch.no_grad():
loaded_output = loaded_model(dummy_input)
print(f"【復元後】AIの出力スコア:\n{loaded_output.numpy()}")
# 保存前の結果(original_output)と、復元後の結果(loaded_output)を比較します。
# torch.equal() は、全ての数値が完全に一致しているかを判定します。
if torch.equal(original_output, loaded_output):
print("\n✅ 成功!保存前と復元後の出力が完全に一致しました。")
print("これで、いつでもどこでも同じ診断(推論)が可能になります。")
else:
print("\n❌ 失敗... 何かがおかしいようです。")
# 後始末(実験が終わったので、作ったファイルを削除しておきます)
if os.path.exists(save_path):
os.remove(save_path)
print(f"\n(検証終了のため '{save_path}' を削除しました)")
【保存前】AIの出力スコア:
[[-0.27858248 0.4567917 ]]
💾 モデルの重みを 'my_medical_ai_v1.pth' に保存しました!
これでPCの電源を切っても、このファイルさえあればAIは蘇ります。
🧊 ファイルからモデルを復元しました!
【復元後】AIの出力スコア:
[[-0.27858248 0.4567917 ]]
✅ 成功!保存前と復元後の出力が完全に一致しました。
これで、いつでもどこでも同じ診断(推論)が可能になります。
(検証終了のため 'my_medical_ai_v1.pth' を削除しました)コードの重要ポイント解説
torch.save(model.state_dict(), path):
これが「冷凍保存」の呪文です。state_dictは、モデルの中にある全てのパラメータ(重み \( W \) とバイアス \( b \))が格納された辞書(Dictionary)型のデータです。
PyTorchでは、モデルの設計図そのものではなく、この「学習の成果(パラメータの数値)」だけを保存するのが推奨される作法(マナー)です (PyTorch 2024)。設計図(コード)は別途 Git などで管理し、重みデータだけをファイルにするのです。model.load_state_dict(torch.load(path)):
これが「解凍」の呪文です。
まず、プログラム上で同じ設計図(クラス)から「空のモデル」を作ります。
そこに、torch.load()で読み込んだ重みデータをload_state_dict()で流し込むことで、学習済みの状態を完全再現します。
⚠️ 実務でハマるポイント(超重要)
研究室では上記のコードで動きますが、実務では以下の2点に注意が必要です。
1. 知らない人からもらった .pth ファイルは開かない!
torch.load() は、Pythonの pickle という仕組みを使っています。
実はこれ、悪意のあるコードが含まれていると、ファイルを読み込んだ瞬間にPCを乗っ取られるリスクがあります。
信頼できるファイル(自分で作ったものや、公式が配布しているもの)以外は、安易にロードしないでください。
2. 「GPUで作ってCPUで動かす」時のエラー
Google Colab(GPU環境)で保存したモデルを、手元のノートPC(CPU環境)でロードしようとすると、エラーになることがあります。
その場合は、ロード時に以下のように「地図(map_location)」を指定するおまじないを追加します。
# GPUで保存したモデルをCPUで強制的に読み込む場合
loaded_state_dict = torch.load(save_path, map_location=torch.device('cpu'))4. 次なる世界へ:MLOpsと社会実装の壁
おめでとうございます!あなたは今、AIを「ファイル」として保存し、持ち運ぶ技術を手に入れました。
しかし、厳しい現実をお伝えしなければなりません。
「モデルが完成した(保存できた)」というのは、ゴールではなく、新たな戦いのスタートラインに過ぎないのです。
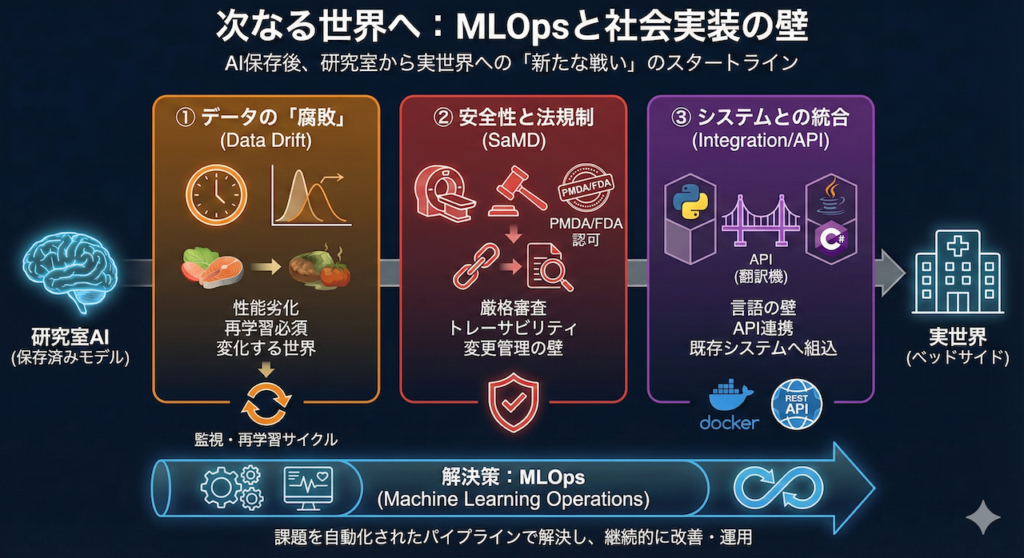
研究室のきれいなデータで「精度99%」を出したAIも、一歩外に出て実際の病院で使い始めると、途端に動かなくなったり、見当違いな診断を始めたりすることがあります。
研究室から実世界(ベッドサイド)への道のりには、乗り越えなければならない「3つの巨大な壁」が存在します。
① データの「腐敗」:Data Drift(データドリフト)
「AIは一度作れば、永遠に賢いままでいてくれる」
……残念ながら、それは幻想です。
冷凍食品にも賞味期限があるように、AIモデルも時間が経つにつれて「腐る(性能が徐々に落ちていく)」という宿命を持っています。
もちろん、保存したファイル(重みの数値)が勝手に書き換わって壊れるわけではありません。
AI自体は変わらないのに、AIを取り巻く「世界(データ)」の方が変化してしまうことで、AIの知識が「時代遅れ」になってしまうのです。
なぜAIの精度は落ちるのか?
これを専門用語で「データドリフト(Data Drift)」と呼びます。
「学習に使ったデータの分布(Training Data)」と、「実際に現場で入力されるデータの分布(Inference Data)」が、時間の経過とともにズレていく(Driftする)現象です。
具体的に、医療現場でどのような「ズレ」が起こるのか、想像してみましょう。

(A) 患者層の変化(共変量シフト)
例えば、あなたが夏に集めたデータで「風邪診断AI」を作ったとします。
このAIは、「夏風邪」の特徴は完璧に覚えました。
しかし、冬になってインフルエンザが流行し始めたらどうなるでしょう?
発熱の高さ、喉の痛み方など、患者さんの症状の傾向(分布)がガラリと変わります。
「夏風邪」しか知らないAIは、冬の患者さんを診て「これは未知の病気だ!」と混乱するか、見当違いな診断を下してしまいます。
(B) 機器や環境の変化(ドメインシフト)
もっと物理的な変化もあります。
ある日、病院がX線撮影装置(モダリティ)を、A社製からB社製の最新機種に買い替えたとしましょう。
人間が見れば「どちらも胸のレントゲン写真」ですが、AIにとっては大事件です。
画像の解像度、コントラスト、ノイズの乗り方などが微妙に変化するため、AIは「今まで見たことのない画質の画像」だと認識し、誤診を始める可能性があります。
このように、世界は常に変化し続けています。
この変化に対応するためには、AIを「一度作って終わり(売り切り)」にするのではなく、常にAIの健康状態(精度)をモニタリングし続ける必要があります。
そして、「最近、AIの正答率が落ちてきたな(ドリフトを検知)」と判断したら、すぐに最新のデータを集めてAIに勉強させ直す(再学習・ファインチューニング)仕組みが不可欠なのです (Samuel et al. 2021)。
② 安全性と法規制:SaMDとしての承認
医療AIは、人の命や健康に直接関わる技術です。
「ごめん、バグっちゃった(笑)」では済まされません。
スマホのゲームアプリならバグがあってもアップデートで直せば済みますが、医療AIの誤作動は、患者さんの治療の遅れや誤診、最悪の場合は命の危険に直結します。
そのため、AIを実際の医療現場で「診断」や「治療方針の決定」に使おうとする場合、それは単なるソフトウェアではなく、「プログラム医療機器(SaMD: Software as a Medical Device)」という法的な位置付けになります。
メスやMRI装置と同じように、法律(日本では薬機法)で厳しく規制される「医療機器」として扱われるのです。
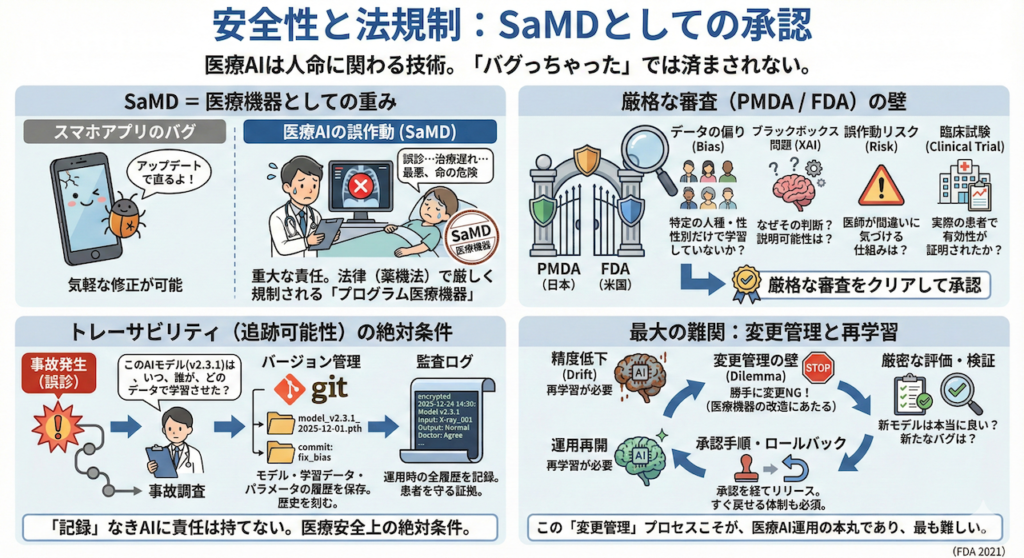
PMDA(日本)やFDA(米国)の厳しい審査
SaMDとして認められ、病院で販売・使用できるようになるためには、各国の規制当局(日本ではPMDA、米国ではFDA)による、極めて厳格な審査をクリアしなければなりません。
審査官は、コードの書き方よりも、もっと根本的な「安全性」と「有効性」を問いただします。
- データの偏りはないか?(特定の人種や性別だけで学習していないか?)
- なぜその判断をしたのか?(ブラックボックス問題への対処は?)
- 誤作動した時のリスクは?(AIが間違えた時、医師が気づける仕組みはあるか?)
- 臨床試験(治験)の結果は?(実際の患者さんで本当に役に立つと証明されたか?)
トレーサビリティ(追跡可能性)の絶対条件
そして、最も重視されるのが「トレーサビリティ(Traceability)」です。
もし将来、ある患者さんに対してAIが重大な誤診をしたとします。
その時、開発者は以下の質問に「即座に、正確に」答えられなければなりません。
事故調査で問われること
「この誤診をしたAIモデル(v2.3.1)は、いつ、誰が、どのデータセットを使って学習させ、どのパラメータ設定で作られたものですか?」
もし、「担当者が退職したのでわかりません」とか「当時のファイルは上書きして消しちゃいました」なんてことになったら、企業としての責任問題どころか、二度と医療機器を作れなくなるでしょう。
今回私たちが学んだ「モデルのファイル保存」と、ファイル名やGitを使った「バージョン管理」は、単に便利だから行うのではありません。
「いつ、どのような状態のAIが存在したか」を歴史として刻み、何かあった時に必ず原因まで遡れるようにするための、医療安全上の「絶対条件」なのです (FDA 2021)。
監査ログ:監視よりも先に「記録」せよ
トレーサビリティを確保するためには、モデルのバージョン管理だけでは不十分です。
「いつ、どのバージョンのモデルが、どのような入力データに対して、どんな出力を出し、最終的に医師はどう判断したか」
これら全ての履歴を、個人情報を保護しつつ、改ざんできない形で「監査ログ」として記録し続ける必要があります。
何かあった時、このログだけがあなたと患者さんを守る証拠になります。
最大の難関:「変更管理」と再学習
ここで一つのジレンマが生まれます。
「精度が落ちたら再学習(調理し直し)すればいい」と言いましたが、医療機器(SaMD)の世界では、学習済みモデルの中身を変えることは「医療機器の改造(変更)」にあたります。
勝手に中身を変えてはいけません。再学習した新しいモデルが、本当に前より良くなっているのか?新たなバグはないか?
これらを厳密に評価・検証し、承認手順を経てからリリースし、万が一の時はすぐに戻せる(ロールバック)体制を作る。
この「変更管理」のプロセスこそが、医療AI運用の本丸であり、最も難しい部分なのです。
③ システムとの統合:IntegrationとAPI
最後の壁は、プログラミング言語の違いによる「言葉の壁」です。
私たちがA11からずっと使ってきた言語は「Python」でしたね。
AI開発において、Pythonは圧倒的なシェアを持つ「共通言語」です。
しかし、実際の病院を見渡してみてください。
医師が毎日使っている電子カルテシステム、レントゲン画像を管理するPACS(画像保存通信システム)、受付の会計システム……。
これらは、Pythonで作られているとは限りません。むしろ、大規模な業務システムに強い「Java」や、Windowsと相性の良い「C#」といった、全く別の言語で作られていることがほとんどです。
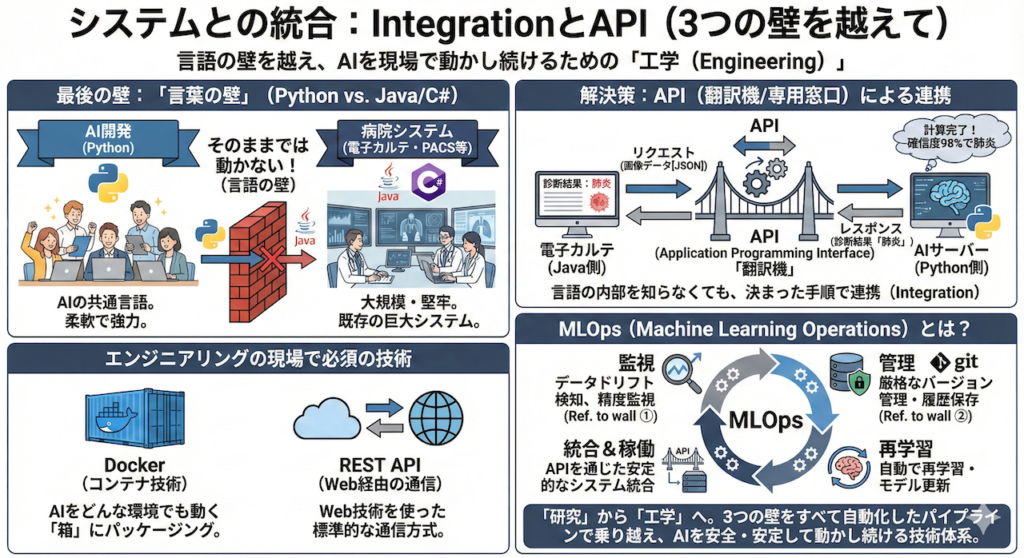
PythonのAIは、そのままでは動かない
Pythonで作ったAIプログラムを、Javaで動いている電子カルテの中に「コピペ」しても、文法が違うので絶対に動きません。
これは、日本語しか話せない外科医を、英語しか通じないアメリカの病院の手術室にいきなり放り込むようなものです。
では、どうやって連携させるのでしょうか?
ここで登場するのが、API(Application Programming Interface)という「翻訳機(専用窓口)」の技術です。
APIを使えば、お互いの内部構造や言語を知らなくても、決まった手順で「お願い(リクエスト)」と「返事(レスポンス)」を交換することができます。
具体的には、以下のような会話が行われます。
- 電子カルテ(Java側):
「おい、Python君!この画像データの診断をお願い!(画像データをJSON形式などで投げる:APIリクエスト)」 - AIサーバー(Python側):
(裏側で待機していたPythonプログラムがリクエストを受け取る)
「了解!……計算完了。確信度98%で肺炎です。(結果だけを返す:APIレスポンス)」 - 電子カルテ(Java側):
「サンキュー!(受け取った『肺炎』という文字を画面に表示する)」
このように、システム同士をAPIで緩やかにつなぐことで、言語の壁を越えてAIを現場に組み込む(Integration)ことが可能になります。
この時、AIをどんな環境でも動く「コンテナ(箱)」にパッケージングするDockerという技術や、Web経由で通信するREST APIといった技術が、エンジニアリングの現場では必須となります。
MLOps(Machine Learning Operations)とは?
ここまで見てきた「3つの壁」を思い出してください。
- データドリフト: 常に精度を監視し、腐ったら再学習させる
- 法規制・管理: 厳格なバージョン管理と履歴の保存
- システム統合: APIを通じた安定的な稼働
これら全てを、人間の手作業でやるのは不可能です。「担当者が寝ていて再学習を忘れました」では医療事故につながります。
そこで、これらのプロセスを「すべて自動化されたパイプライン(流れ作業)」として構築・運用する技術体系のこと、それをMLOps(エムエルオプス)と呼びます。
最高のAIモデルを作るのが「研究(Science)」なら、そのAIを社会の中で安全に、安定して動かし続けるのがMLOpsという「工学(Engineering)」なのです。
5. Series A 完走おめでとうございます!🚀 さあ、旅を続けましょう!

A0から始まったこの長いコースは、ここで一旦幕を閉じます。
本当にお疲れ様でした!
しかし、これは「終わり」ではありません。
あなたは今、医療AIという広大な世界の地図(全体像)を手に入れ、コンパス(Python基礎)をポケットに入れ、最初のキャンプ地(モデル保存)に到達したばかりの冒険者です。
ここから先には、より深く、より専門的で、そしてもっとワクワクする冒険が待っています。
Medical AI Nexusでは、あなたの関心や目的に合わせて、さらに深く学べる専門コースを用意しています。
興味のある扉を開いて、次のステージへ進みましょう!
私の一押しは、
[Series C] 💻 Clinical AI Coding 100 : 医療AI時代の総合プログラミング大全です!

100本ノック形式で、環境構築から最先端の画像認識、自然言語処理、そして今回の続きであるWebアプリ化まで、手を動かして実装力を「筋肉」に変えるための決定版コースです。
あなたの手元にある .pth ファイルは、まだ小さな種かもしれません。
しかしそれは、未来の医療を変え、誰かの命を救う大樹になる可能性を秘めた「希望の種」です。
どうかその種を、大切に育ててください。
また次のSeriesで、成長したあなたにお会いできることを楽しみにしています!
参考文献
- FDA (2021). Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) Action Plan. U.S. Food and Drug Administration.
- PyTorch (2024). Saving and Loading Models. PyTorch Documentation.
- Python Software Foundation (2024). pickle — Python object serialization. Python 3.12.2 Documentation.
- Samuel, S., et al. (2021). Machine Learning Operations (MLOps): Overview, definition, and architecture. arXiv preprint.
- Sculley, D., et al. (2015). Hidden technical debt in machine learning systems. Advances in Neural Information Processing Systems, 28, pp. 2503–2511.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.