
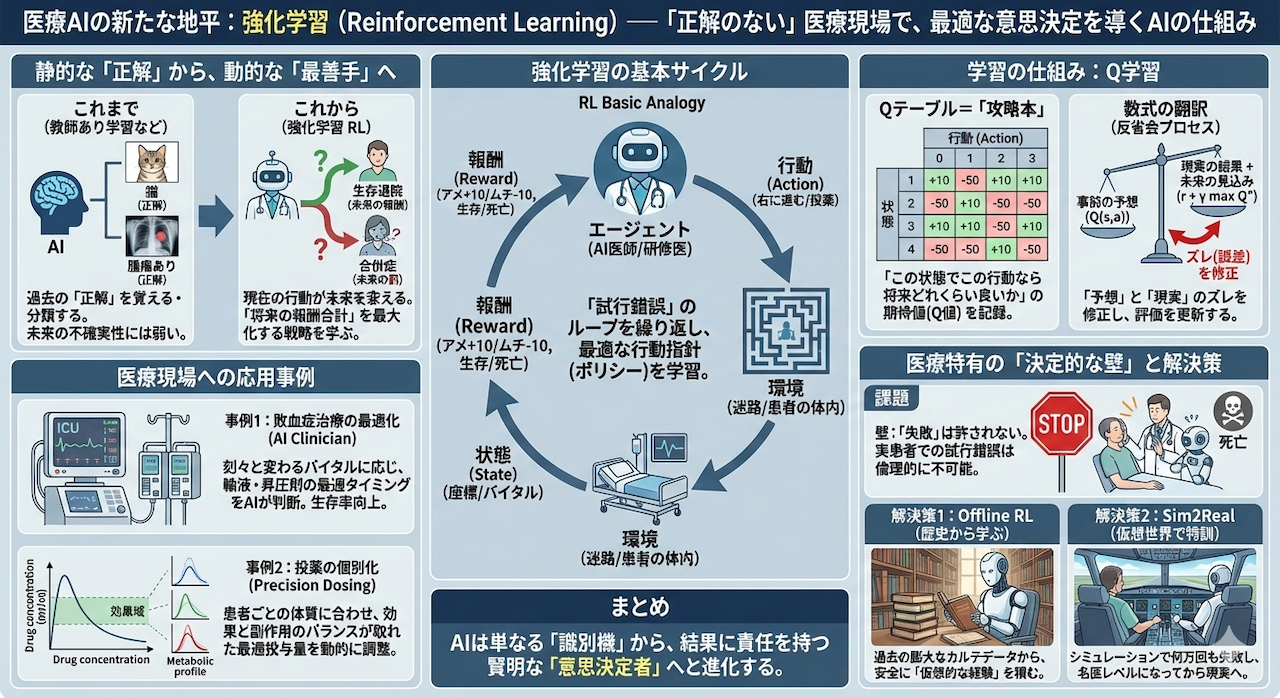
これまで私たちは、過去の正解データを覚える「教師あり学習」(例:画像診断)や、データの構造そのものを地図のように読み解く「教師なし学習」(例:患者分類)について学んできました。
しかし、医療の現場も、そして私たちの人生も、最初から「正解」のラベルが貼られているわけではありません。むしろ、正解かどうかがわかるのは、ずっと後になってからということがほとんどです。
「血圧が低下しているショック状態の患者さん。今、この瞬間に昇圧剤を投与すべきか? それとも輸液を増やすべきか?」
この問いに対する答えは、投与した直後の血圧値だけでは決まりません。その処置が数時間後の腎機能にどう影響するか、そして最終的に数日後の「生存退院」につながるかという、「未来の結果」によって初めて評価されるからです。
現在の行動が未来の状態を変え、その積み重ねが最終的な結果を左右する。このような問題を「連続意思決定問題(Sequential Decision Making)」と呼びます。
今回は、そんな複雑な意思決定を最適化するための技術、強化学習(Reinforcement Learning: RL)の世界へ足を踏み入れます。
難しい数式はいったん後回しにしましょう。まずはAIを「アメとムチ」を持った迷路探検家に例えて、その仕組みを直感的に理解することから始めます。
1. 強化学習とは?:AIを「訓練」する仕組み
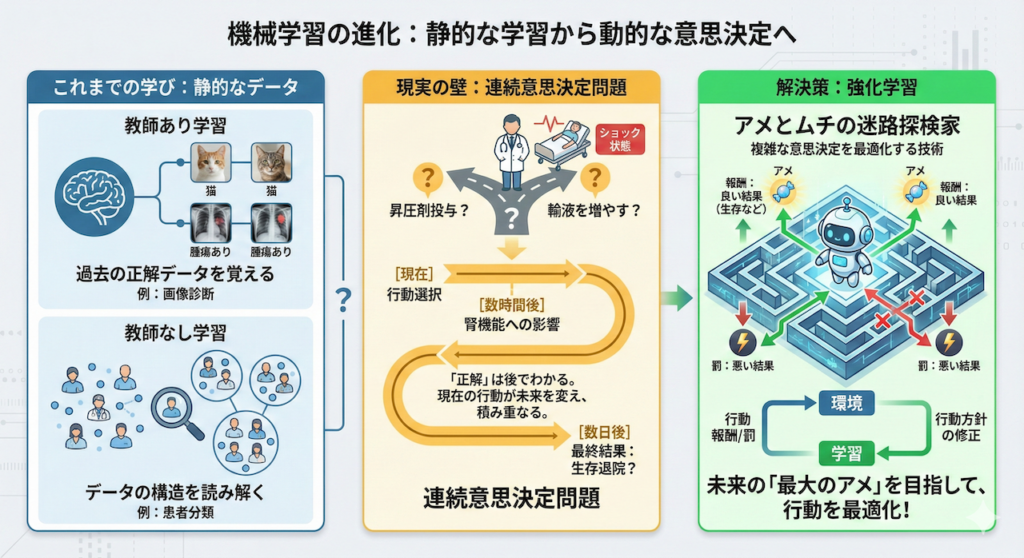
これまで学んできた「教師あり学習」は、いわば「教科書と問題集」で勉強するスタイルでした。正解があらかじめ用意されており、それを覚えることが目標です。
しかし、強化学習は全く異なります。これは「現場での経験」を通じて学ぶスタイルです。
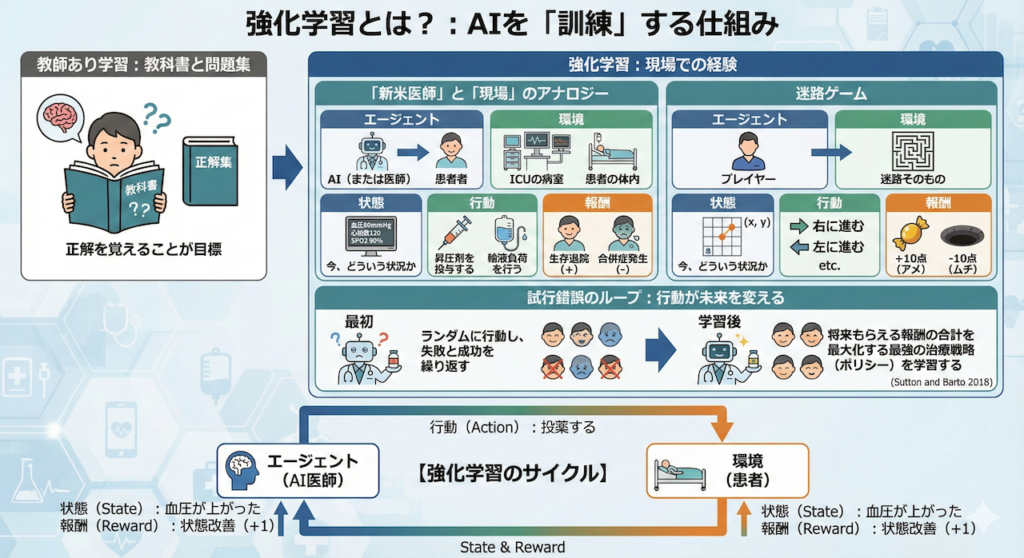
「新米医師」と「現場」のアナロジー
強化学習のイメージは、医学書を読んだだけの新しい研修医(エージェント)が、実際の臨床現場(環境)に放り込まれ、指導医からのフィードバックや患者さんの経過を見ながら、手探りで「名医」へと成長していくプロセスにそっくりです。
このプロセスを構成する5つの重要な要素を、迷路ゲームと医療現場の両方で定義してみましょう。
- エージェント(Agent):
行動する主人公。迷路では「プレイヤー」、医療では「AI(または医師)」にあたります。 - 環境(Environment):
エージェントが存在し、行動を受け入れる世界。迷路そのもの、あるいは「ICUの病室」や「患者の体内」です。 - 状態(State):
今、どういう状況か。迷路なら「座標 \((x, y)\)」、医療なら「血圧80mmHg、心拍数120、SPO2 90%」といったバイタルサインです。 - 行動(Action):
その状態で何をするか。迷路なら「右に進む」、医療なら「昇圧剤を投与する」「輸液負荷を行う」という選択肢です。 - 報酬(Reward):
行動の結果、良かったのか悪かったのかの点数。ゴールなら「+10点(アメ)」、落とし穴なら「-10点(ムチ)」、医療なら「生存退院(正の報酬)」や「合併症発生(負の報酬)」です。
試行錯誤のループ:行動が未来を変える
AIは最初、医学知識も迷路の地図も持っていないため、何が正解か全く知りません。最初はランダムに行動し、失敗(落とし穴/病状悪化)したり、成功(ゴール/回復)したりします。
「この状態で、この行動をとったら、結果的に褒められた(報酬をもらえた)」
「あそこでこの行動をとったら、後で酷い目にあった(罰を受けた)」
この「試行錯誤(Trial and Error)」を何千回、何万回と繰り返すことで、AIは「どの状態でどう動けば、将来もらえる報酬の合計(期待値)が最大になるか」という、最強の治療戦略(ポリシー)を学習していくのです (Sutton and Barto 2018)。
2. Q学習(Q-Learning):経験を「スコア表」に刻む
AIは、迷路で転んだりゴールしたりした経験を、一体どこに記憶しているのでしょうか?脳みその中にノートを持っているようなものです。
最も基本的なアルゴリズムであるQ学習(Q-Learning)では、「Qテーブル」と呼ばれるカンニングペーパー(行動価値関数)を作成し、そこに経験を書き込んでいきます。
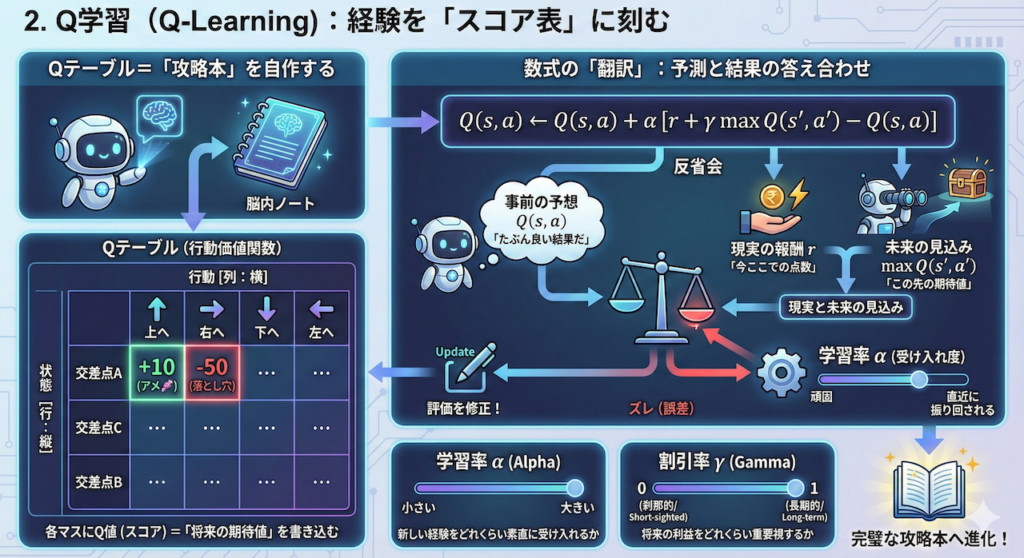
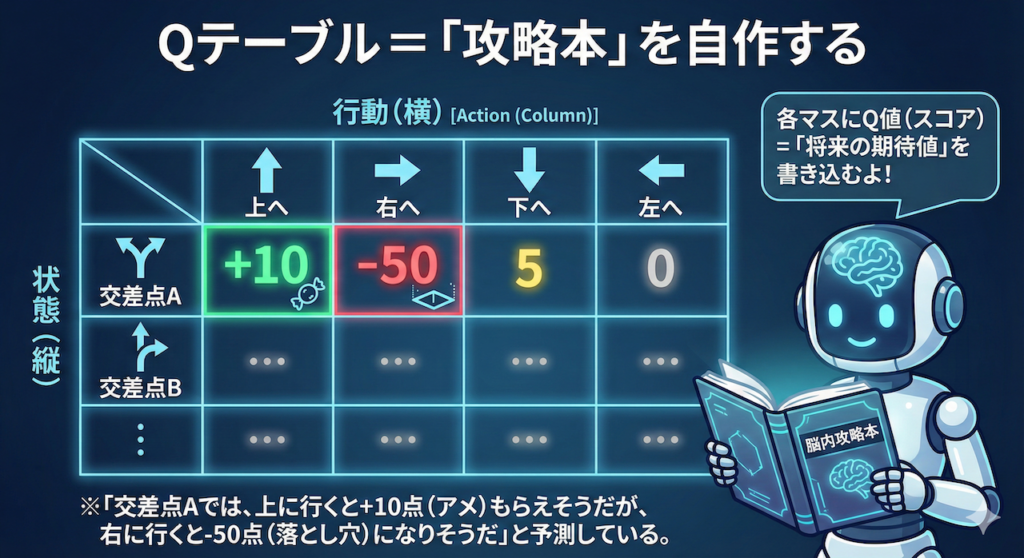
Qテーブル=「攻略本」を自作する
Qテーブルは、エクセルの表のようなものを想像してください。
- 行(縦):あらゆる「状態」(迷路の交差点、あるいは患者の病態)
- 列(横):とれる「行動」(右へ行く、あるいは投薬する)
それぞれのマス目には、Q値(Quality Value:行動の価値)というスコアが書き込まれます。これは「その状態でその行動をとったら、将来これくらい良いことがありそうだよ」というAIの期待値(予測)です。
数式の「翻訳」:予測と結果の答え合わせ
AIは行動するたびに、このQテーブルの数字を書き換えていきます。その更新ルールが以下の数式です。一見複雑に見えますが、やっていることは「反省会」です。
\[ Q(s, a) \leftarrow Q(s, a) + \alpha \left[ \underbrace{r + \gamma \max_{a’} Q(s’, a’)}_{\text{現実と未来の見込み}} – \underbrace{Q(s, a)}_{\text{事前の予想}} \right] \]
この式を日本語に翻訳すると、以下のようになります。
- \(Q(s, a)\)(事前の予想):
「たぶん、これくらい良い結果になるだろう」と思っていた古い評価。 - \(r\)(現実の報酬):
実際に行動してみたら、今ここでもらえた点数(アメやムチ)。 - \(\max Q(s’, a’)\)(未来の見込み):
移動した先から見渡してみて、「あ、この先はもっと良いことがありそうだぞ」とわかった将来の期待値。 - \(\alpha\)(学習率):
「新しい経験をどれくらい素直に受け入れるか」という係数(0〜1)。大きすぎると直近の結果に振り回され、小さすぎると頑固でなかなか学習しません。 - \(\gamma\)(割引率):
「将来の利益をどれくらい重要視するか」という係数(0〜1)。
0に近いと「今の快楽」しか見ない刹那的なAIになり、1に近いと「遠い未来の成功」のために今は耐えるAIになります。
要するに何をしているのか?
AIは、以下のようにつぶやきながらメモを修正しているのです。
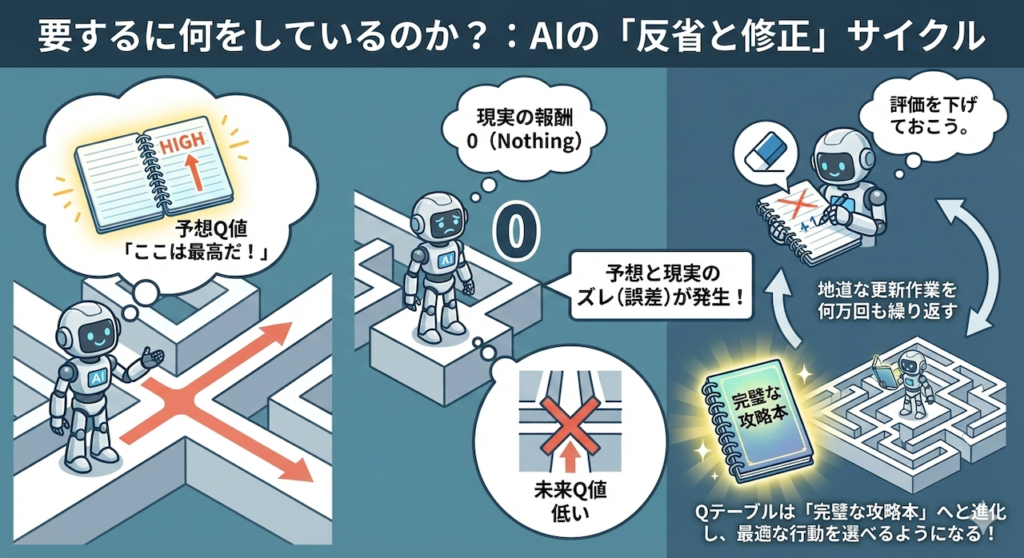
「『ここは最高だ(予想Q値)』と思ってたけど、実際に行ってみたら何もなかったし(報酬ゼロ)、その先も行き止まりだった(未来Q値も低い)。
予想と現実のズレ(誤差)の分だけ、評価を下げておこう。」
この地道な更新作業を何万回も繰り返すことで、Qテーブルは「完璧な攻略本」へと進化し、AIはどんな状況でも最適な行動を選べるようになるのです。
3. 実践ハンズオン:Pythonで迷路を攻略せよ
言葉で理論を説明されるよりも、実際に動くものを見る方が理解は早いです。「AIが賢くなる瞬間」をその目で目撃しましょう。
ここでは、複雑な外部ライブラリ(PyTorchやTensorFlowなど)は一切使わず、数値計算ライブラリの NumPy だけで、迷路環境とQ学習エージェントをゼロから実装します。「ブラックボックス」を作らず、すべての計算過程を記述することで、仕組みを完全に理解することを目指します。
シナリオ設定
3×3のシンプルな迷路です。左上(スタート)から右下(ゴール)を目指します。ただし、中央には「落とし穴」があり、落ちると大きな罰を受けます。
- スタート:左上 (座標 [0, 0])
- ゴール:右下 (座標 [2, 2]) → 報酬 +10
- 落とし穴:中央 (座標 [1, 1]) → 報酬 -10
- 移動コスト:1歩動くたびに -0.1 (最短ルートを探させるため)
【実行前の準備】
以下のコードで日本語のグラフを正しく表示させるには、あらかじめターミナルやコマンドプロンプトで以下のコマンドを実行し、ライブラリをインストールしてください。pip install japanize-matplotlib
# ==========================================
# 0. 準備:必要な道具(ライブラリ)を揃える
# ==========================================
import numpy as np # 数値計算を効率的に行うためのライブラリ
import matplotlib.pyplot as plt # グラフを描画するためのライブラリ
import japanize_matplotlib # グラフの日本語表示を可能にするライブラリ
import random # 乱数(サイコロのようなもの)を使うためのライブラリ
# 実験の結果を毎回同じにするため、乱数の「種(シード)」を固定する
np.random.seed(42)
random.seed(42)
# ==========================================
# 1. 迷路環境クラス (The World)
# AIが冒険する「世界」を定義します
# ==========================================
class SimpleMazeEnv:
def __init__(self):
# 迷路の盤面を数字の配列で定義する
# 0:道, 2:スタート, 3:ゴール, 9:落とし穴
self.grid = np.array([
[2, 0, 0], # 1行目:左上がスタート
[0, 9, 0], # 2行目:真ん中に落とし穴
[0, 0, 3] # 3行目:右下がゴール
])
# 迷路のサイズ(高さと幅)を取得しておく
self.height, self.width = self.grid.shape
# エージェントを初期位置にセットする
self.reset()
def reset(self):
"""ゲームをリセットしてエージェントをスタート地点に戻す関数"""
self.agent_pos = (0, 0) # スタート位置(左上)に設定
return self.agent_pos # 現在の位置を報告する
def step(self, action):
"""エージェントの行動を受け取り、結果(移動先、報酬、終了判定)を返す関数"""
# 行動の定義番号を、実際の移動量(縦, 横)に変換する辞書
# 0=上(-1,0), 1=右(0,1), 2=下(1,0), 3=左(0,-1)
moves = {0: (-1, 0), 1: (0, 1), 2: (1, 0), 3: (0, -1)}
# 選ばれた行動(action)に対応する移動量を取り出す
dy, dx = moves[action]
# 現在位置に移動量を足して、新しい位置(ny, nx)を計算する
ny = self.agent_pos[0] + dy
nx = self.agent_pos[1] + dx
# 【壁・枠外判定】修正箇所:
# もし新しい位置が迷路の枠内にあるなら
if 0 <= ny < self.height and 0 <= nx < self.width:
self.agent_pos = (ny, nx) # 実際に位置を更新する
else:
# 枠の外に出ようとしたら、移動せずにその場に留まる(位置更新しない)
pass
# 移動先のセルの種類(道、ゴール、穴など)を確認する
ny, nx = self.agent_pos
cell = self.grid[ny, nx]
# 報酬と終了判定の初期化
reward = 0 # 報酬はとりあえず0
done = False # ゲーム終了フラグはFalse(まだ続く)
# 【報酬のルール】
if cell == 3: # もしゴール(3)に着いたら
reward = 10 # アメを与える(+10点)
done = True # ゲーム終了
elif cell == 9: # もし落とし穴(9)に落ちたら
reward = -10 # ムチを与える(-10点)
done = True # ゲーム終了(失敗)
else: # ただの道(0)やスタート(2)なら
reward = -0.1 # わずかな罰を与える(-0.1点)
# ※これにより「ダラダラ歩かず最短ルートを目指す」動機づけになる
# 新しい位置、もらった報酬、ゲームが終わったかを報告する
return self.agent_pos, reward, done
# ==========================================
# 2. Q学習エージェントクラス (The Brain)
# 学習して賢くなる「脳」を定義します
# ==========================================
class QLearningAgent:
def __init__(self, n_states, n_actions, alpha=0.1, gamma=0.9, epsilon=0.1):
# Qテーブル(カンニングペーパー)を「状態数 x 行動数」の大きさで作る
# 最初は何も知らないので、全ての値を0にしておく
self.q_table = np.zeros((n_states, n_actions))
self.alpha = alpha # 学習率:新しい経験をどれくらい素直に受け入れるか
self.gamma = gamma # 割引率:未来の報酬をどれくらい重要視するか
self.epsilon = epsilon # 探索率:どれくらいの確率で「気まぐれ(ランダム行動)」を起こすか
self.n_actions = n_actions # 取れる行動の選択肢の数(今回は上下左右の4つ)
def get_action(self, state_idx):
"""現在の状態を見て、次の行動を決める関数(ε-Greedy法)"""
# 0〜1の乱数を振って、それがepsilon(探索率)より小さい場合
if random.random() < self.epsilon:
# 「探索」:知識に関係なく、ランダムに行動を選んでみる
return random.randint(0, self.n_actions - 1)
else:
# 「活用」:Qテーブルを見て、一番点数が高い(自信がある)行動を選ぶ
return np.argmax(self.q_table[state_idx])
def update(self, state, action, reward, next_state):
"""経験に基づいてQテーブル(記憶)を更新する関数"""
# 次の状態(移動先)で、一番良さそうな行動のQ値(最大値)を確認する
max_next_q = np.max(self.q_table[next_state])
# 現在のQ値(行動する前の予想)を取得する
current_q = self.q_table[state, action]
# 【Q学習の更新式(ベルマン方程式)】
# 「現実の報酬」+「未来の期待値」と、「事前の予想」とのズレ(誤差)を計算し
# そのズレの一部(alpha分)だけ修正して、新しいQ値とする
new_q = current_q + self.alpha * (reward + self.gamma * max_next_q - current_q)
# Qテーブルの該当箇所を新しい値に書き換える
self.q_table[state, action] = new_q
# ==========================================
# 3. 学習の実行 (Simulation)
# エージェントを環境に放り込んで訓練開始
# ==========================================
env = SimpleMazeEnv() # 迷路環境を作る
# 状態数は「縦3 x 横3」で9通り、行動は4通り
agent = QLearningAgent(n_states=9, n_actions=4, epsilon=0.1)
episodes = 500 # 500回ゲーム(エピソード)を繰り返す
rewards_history = [] # 毎回の成績(報酬の合計)を記録するリスト
for episode in range(episodes):
state = env.reset() # 毎回スタート位置に戻す
# 座標(行, 列)を、Qテーブル用の通し番号(0〜8)に変換する
# 例:(0,0)→0, (1,1)→4, (2,2)→8
state_idx = state[0] * 3 + state[1]
total_reward = 0 # 今回のエピソードの報酬合計
done = False # ゲーム終了フラグ
# ゴールするか穴に落ちるまで繰り返す(1エピソード)
while not done:
# 1. エージェントが今の状態で行動を決める
action = agent.get_action(state_idx)
# 2. 決めた行動を環境で実行し、結果を受け取る
next_state_pos, reward, done = env.step(action)
# 移動先の座標を通し番号に変換
next_state_idx = next_state_pos[0] * 3 + next_state_pos[1]
# 3. 結果(行動・報酬・次の状態)を使ってQテーブルを更新する(学習)
agent.update(state_idx, action, reward, next_state_idx)
# 4. 次のステップのために、現在の状態を更新する
state_idx = next_state_idx
# 報酬を合計に加算する
total_reward += reward
# エピソード終了後、今回の合計報酬を記録リストに追加
rewards_history.append(total_reward)
# ==========================================
# 4. 結果の可視化 (Visualization)
# ==========================================
plt.figure(figsize=(10, 5)) # グラフのサイズ設定
plt.plot(rewards_history) # 報酬の推移をプロット
plt.title('エピソードごとの獲得報酬の推移') # タイトル
plt.xlabel('エピソード数') # 横軸ラベル
plt.ylabel('獲得報酬') # 縦軸ラベル
plt.grid(True) # グリッド線を表示
plt.show() # グラフ表示
print("学習完了後のQテーブル(一部・見やすく四捨五入):")
print(agent.q_table.round(2))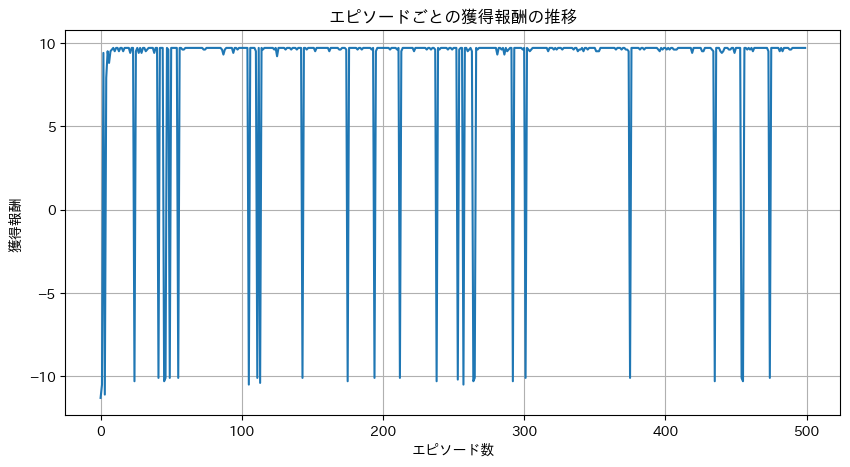
学習完了後のQテーブル(一部・見やすく四捨五入):
[[ 4.62 7.02 0.36 5.35]
[ 5.02 7.91 -8.15 4.53]
[ 5.21 6.4 8.9 6.11]
[ 1.15 -1. 1.36 -0.03]
[ 0. 0. 0. 0. ]
[ 3.92 5.45 10. -6.51]
[-0.02 3.98 -0.02 -0.02]
[-1. 7.94 0. 0. ]
[ 0. 0. 0. 0. ]]コード解説:ここがポイント!
- 環境の構築(SimpleMazeEnv):
AIが動く「世界」を作っています。ゴール(+10点)と落とし穴(-10点)だけでなく、「1歩動くごとに -0.1点」という罰を与えているのがミソです。もしこれがないと、AIは「ゴールしても点数は変わらないし」と考え、道草を食ったり、同じ場所を行ったり来たりしてしまう可能性があります。「早くゴールしたほうが点数が高くなる」ように仕向けるための工夫です。 - Epsilon-Greedy法(探索と活用):
get_actionメソッドの中にある「探索率(epsilon)」の仕組みです。AIがすでに知っている「良さそうな手(活用)」ばかり選んでいると、もっと良い未知のルートがあっても気づけません。そこで、サイコロを振ってたまに「あえてランダムな行動(探索)」をさせることで、失敗を恐れずに新しい可能性を発見させています。 - 学習の推移(グラフ):
実行すると表示されるグラフを見てください。左側(学習初期)は線が低く、ジグザグしています。これは落とし穴に落ちたり、迷ったりしている証拠です。しかし、右側(学習後半)に進むにつれて線が高い位置で安定していきます。これが、AIが「迷路の攻略法(最短ルート)」を完全に学習し、迷わなくなった瞬間です。
4. 医療現場への応用:迷路から臨床へ
「たかが迷路を解くだけのAIが、何の役に立つんだ?」
そう思われるかもしれません。しかし、侮ってはいけません。先ほど見てきた「状態(State)を見て、最適な行動(Action)を選び、結果(Reward)から学ぶ」というフレームワークは、実は現代医療が抱える最も困難な課題に対する、極めて強力なソリューションになるのです。
ここでは、実際に世界的な注目を集めた2つの画期的な研究事例を紹介します。
1. 敗血症治療の最適化 (AI Clinician)
ICU(集中治療室)における敗血症(Sepsis)の治療は、まさに時間との戦いです。刻一刻と変化する患者さんの容体に対し、医師は常に難しい判断を迫られます。
「血圧が下がってきた。血管収縮薬で締めるべきか? それとも輸液を入れて循環血液量を増やすべきか?」
2018年、インペリアル・カレッジ・ロンドンのKomorowskiらは、このジレンマに強化学習で挑んだ「AI Clinician」を発表しました (Komorowski et al. 2018)。彼らはMIMIC-IIIという巨大なICUデータベースを使い、AIに「迷路」の代わりに「敗血症治療」を学習させたのです。
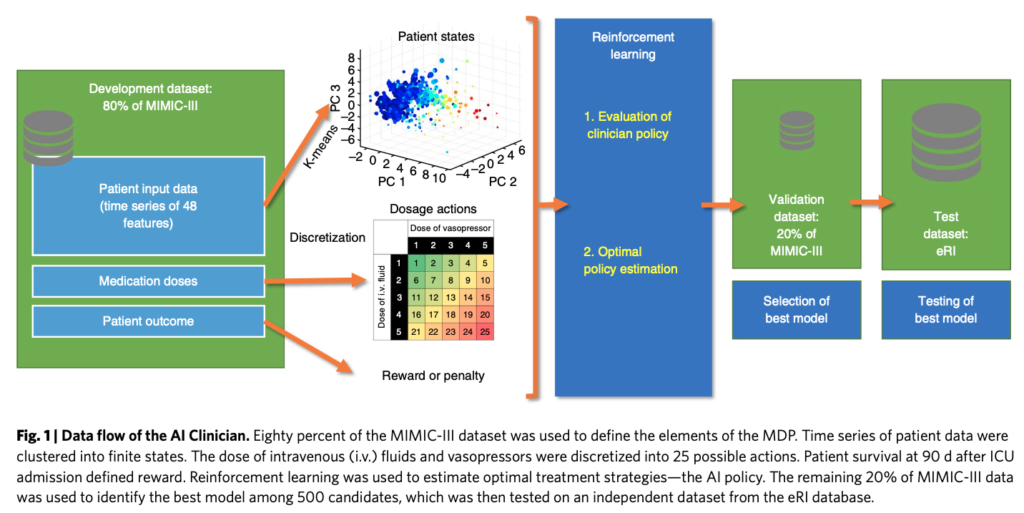
【衝撃的な結果】
学習を終えたAIは、熟練の臨床医とは異なる、独自の治療戦略を提案しました。AIの推奨する投与量と、実際の医師の投与量が一致したケースでは死亡率が低かったのに対し、大きく乖離したケースでは死亡率が高くなる傾向が見られたのです。
これは、人間が経験則や「なんとなく」の直感で行っていた微調整を、AIが「データに基づいた数理的な最適解」として再定義できる可能性を示しました。
2. 投薬スケジュールの個別化 (Precision Dosing)
薬の効き方には個人差があります。同じ量の抗がん剤や抗凝固薬(ヘパリンなど)を投与しても、ある人には効果がなく、ある人には副作用が強く出すぎることがあります。
ここで強化学習の出番です。これは「綱渡り」を制御するようなものです。
- 目的:薬物血中濃度を「効果はあるが副作用は出ない」という狭い範囲(治療域)に維持し続けること。
- AIの役割:毎回の検査結果(状態)を見て、次の投与量(行動)を微調整する。
従来の「体重だけで決める固定的なプロトコル」とは異なり、AIは「この患者さんは代謝が早いから、少し早めに追加投与しよう」といった、患者ごとの代謝や反応(Environmentの特性)に合わせた動的な個別化医療(Personalized Medicine)を実現しようとしているのです。
5. 医療における課題:「失敗できない」という決定的な壁
ここまで読んで、「すごい!すぐに現場で使おう」と思った方は、少し立ち止まってください。迷路のAIと医療現場のAIには、埋めがたい「決定的な違い」が一つあります。
それは、「失敗が許されるかどうか」です。
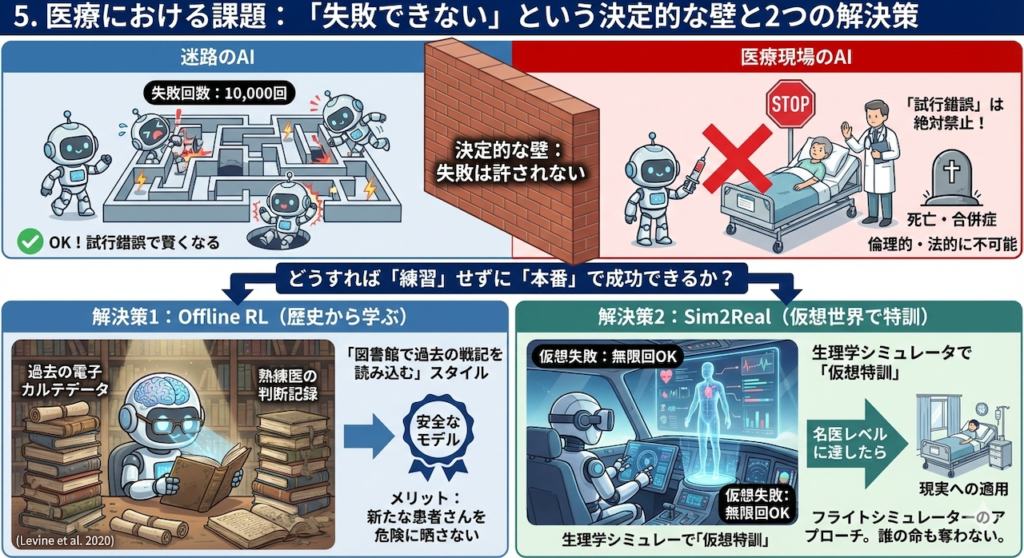
「1万回の失敗」は許されない
迷路のAIは、1万回落とし穴に落ち、壁に激突し続けることで賢くなりました。しかし、現実の患者さんで「試行錯誤(Exploration)」することは絶対に許されません。
「この患者さんで新しい薬の量を試してみよう。あ、ダメだった(死亡)。じゃあ次は減らしてみよう」
これは倫理的にも法的にも不可能です(ヒポクラテスの誓い「まずは害をなすなかれ」に反します)。
では、どうすれば「練習」せずに「本番」で成功できるのでしょうか? ここで2つの重要なアプローチが登場します。
解決策1:Offline RL(オフライン強化学習)~歴史から学ぶ~
一つ目の方法は、「過去のカルテデータ(歴史)」だけを使って学習する方法です。
オンライン強化学習(Online RL)が「走りながら学ぶ」スタイルだとすれば、オフライン強化学習(Offline RL)は「図書館で過去の戦記を読み込んで学ぶ」スタイルです (Levine et al. 2020)。
- やり方:病院に蓄積された何万人分もの電子カルテデータ(過去の医師の行動と、その結果)を用意します。
- 学習内容:「熟練医がこういう判断をした時はうまくいった」「逆にこういう判断をした時は予後が悪かった」というパターンを解析します。
- メリット:新たな患者さんを危険に晒すことなく、安全に賢いモデルを作れます。
いわば、過去の名医や失敗例から「仮想的な経験」を積むことで、現場に出る前にレベルアップしておくのです。
解決策2:Sim2Real(シミュレーションから現実へ)~仮想世界で特訓~
もう一つの方法は、「フライトシミュレーター」のアプローチです。
パイロットは最初から本物の飛行機を操縦しません。墜落しても死なないシミュレーターの中で何千回も失敗し、技術を習得してから実機に乗ります。これをAIに応用したのがSim2Real(Simulation to Reality)です。
- 生理学シミュレータ:人体の反応(薬物動態や循環動態)を模倣した「デジタルな患者(Digital Twin)」をコンピュータの中に作ります。
- 仮想特訓:AIはこのデジタル患者に対して、何万回もの治療シミュレーションを行います。ここでは何度失敗しても、誰の命も奪いません。
- 現実への適用:仮想世界で「名医」レベルに達した安全なAIモデルだけを、現実世界(Real)に連れてきます。
このように、医療AIの研究者たちは、「患者さんの命を守る」という絶対的なルールの下で、AIを賢くするための様々な工夫を凝らしているのです。
まとめ:AIは「失敗」から学び、「判断」する医師になる
今回学んだ強化学習は、AIの役割を劇的に変える技術です。
これまでのAI(教師あり学習)は、「これは癌ですか?」「はい、癌です」と答える優秀な「識別機」でした。しかし、強化学習によってAIは、「今、何をすべきか?」を自ら考え、行動の結果に責任を持つ「意思決定者」へと進化します。
「アメとムチ」を受けながら、何度も転んで、起き上がって、少しずつ迷路の歩き方を覚えていくその姿。それは、私たちが研修医時代に、先輩に怒られ、患者さんの笑顔に救われながら、教科書には載っていない「臨床の勘所」を磨いていったプロセスと驚くほど似ています。
AIも人間も、失敗から学び、経験を積み重ねることでしか到達できない「知能」の領域があるのです。
次回予告:[A20] 実装編・最終回
さて、次回はいよいよ [Series A] Season 3 の最終回です。
苦労して学習させたAIモデルも、PCの電源を切れば消えてしまいます。そこで次回は、育て上げたAIを「冷凍保存(モデルの保存)」し、いつでも呼び出して使えるようにする技術を学びます。
研究室(Google Colab)から飛び出し、実際の社会で役立つアプリケーションとして実装するための、最初の一歩を踏み出しましょう。
参考文献
- Gottesman, O., Johansson, F., Komorowski, M., Levine, S., Doshi-Velez, F., Celi, L.A. and Sontag, D. (2019). Guidelines for reinforcement learning in healthcare. Nature Medicine, 25, pp.16–29.
- Komorowski, M., Celi, L.A., Badawi, O., Gordon, A.C. and Faisal, A.A. (2018). The Artificial Intelligence Clinician learns optimal treatment strategies for sepsis in intensive care. Nature Medicine, 24, pp.1716–1720.
- Levine, S., Kumar, A., Tucker, G. and Fu, J. (2020). Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint.
- Sutton, R.S. and Barto, A.G. (2018). Reinforcement Learning: An Introduction. 2nd ed. Cambridge, MA: MIT Press.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




