
ChatGPTに複雑な症例経過を入力したとき、まるで人間のように文脈の裏側まで理解しているような返答が来て、背筋が凍るような感覚を覚えたことはありませんか?
日々の診療でAIを活用されている医師の皆様なら、一度はその「不気味なほどの賢さ」に驚かされた経験があるのではないでしょうか。
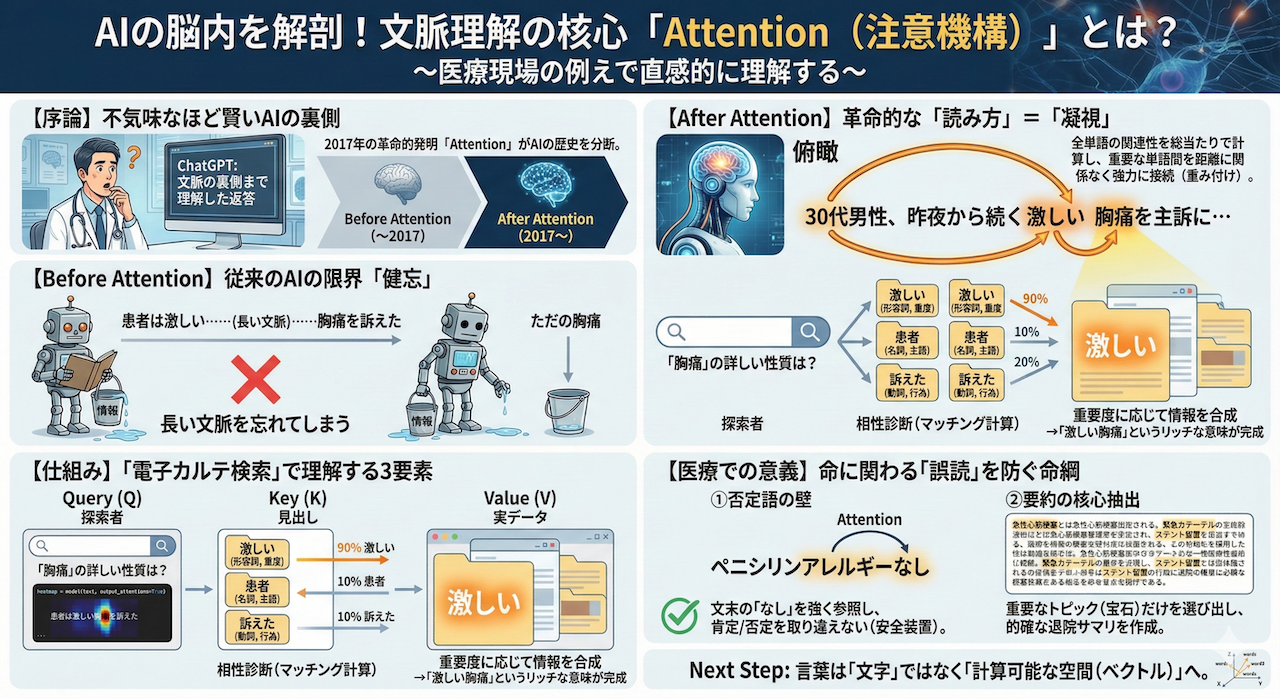
実は、近年のAIがこれほど劇的な進化を遂げた背景には、たった一つの「革命的な発明」が存在します。それが、2017年にGoogleの研究チームが発表した論文『Attention Is All You Need』で提唱された、「Attention(アテンション/注意機構)」という仕組みです (Vaswani et al. 2017)。
この技術の登場は、医学史で言えば「麻酔」や「抗菌薬」の発見に匹敵するパラダイムシフトでした。それまでのAIがどうしても克服できなかった「長い文脈を覚える」という壁を突破し、AIの歴史を「Before Attention」と「After Attention」に分断してしまったのです。
今回は、普段は巨大な計算機の中でブラックボックスとして隠蔽されている「AIの脳内」を、Pythonという名のメスを使って切り開き、その思考回路を解剖します。
難しい数式の話は、一旦後回しにしましょう。
まずは、AIがカルテや論文を読むとき、一体どの単語を凝視し、どのように意味を繋げているのか――その「視線」を実際に覗き見して、知能が生まれる瞬間を追体験する旅に出かけましょう。

1. AIは「流し読み」しない。大事な単語を「凝視」する
まず、AIの頭の中を覗く前に、私たち自身の脳がどのように言葉を理解しているのか、その驚くべきメカニズムを再確認してみましょう。
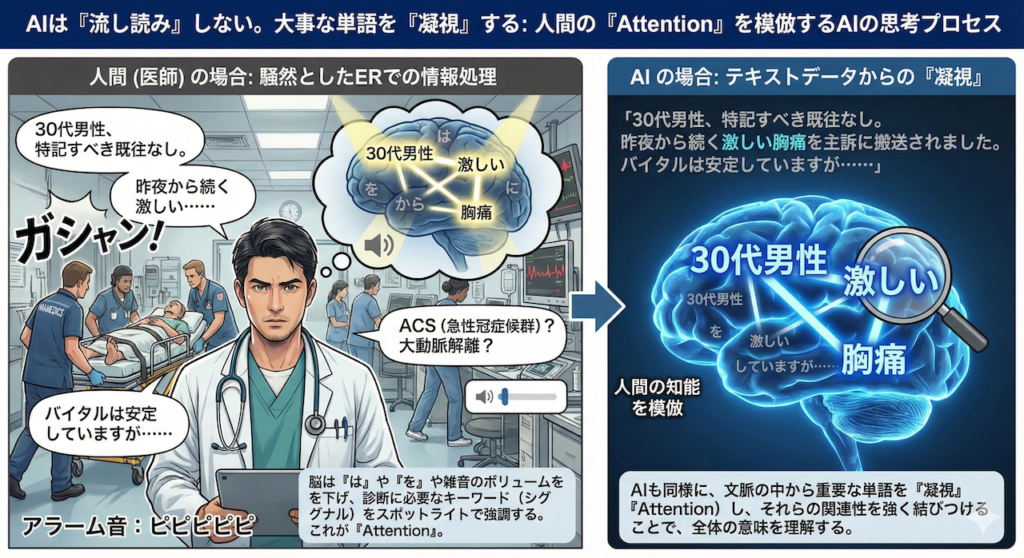
想像してみてください。あなたは今、モニターのアラーム音やスタッフの叫び声が飛び交う、騒然とした救急外来(ER)にいます。そんな中、搬送してきた救急隊員が早口で申し送りを始めました。
「30代男性、特記すべき既往なし。昨夜から続く激しい……(ここでストレッチャーがぶつかる大きな音)……胸痛を主訴に搬送されました。バイタルは安定していますが……」
この一瞬、あなたの脳内では高度な情報処理が行われています。
「30代男性」「特記なし」「昨夜から」といった情報は、淡々と短期記憶の棚に並べられます。しかし、「胸痛」という単語が耳に飛び込んできた瞬間、脳のスイッチが切り替わったはずです。
あなたは無意識のうちに、数秒前に聞き流しかけた「激しい」という形容詞を記憶の底から急いで引っ張り出し、「胸痛」と強力に結びつけたのではないでしょうか?
さらに、「30代」という年齢情報とも照らし合わせ、「若年者の激しい胸痛? ACS(急性冠症候群)か? それとも大動脈解離か?」と、瞬時に鑑別診断のネットワークを広げたはずです。
このとき、脳は「は」や「を」といった助詞や、周囲の雑音(ノイズ)のボリュームを下げ、診断に必要なキーワード(シグナル)だけをスポットライトで照らすように強調しています。これこそが、人間の知能の根幹をなす機能、「Attention(注意機構)」です。
なぜ、昔のAIは「文脈」が読めなかったのか?
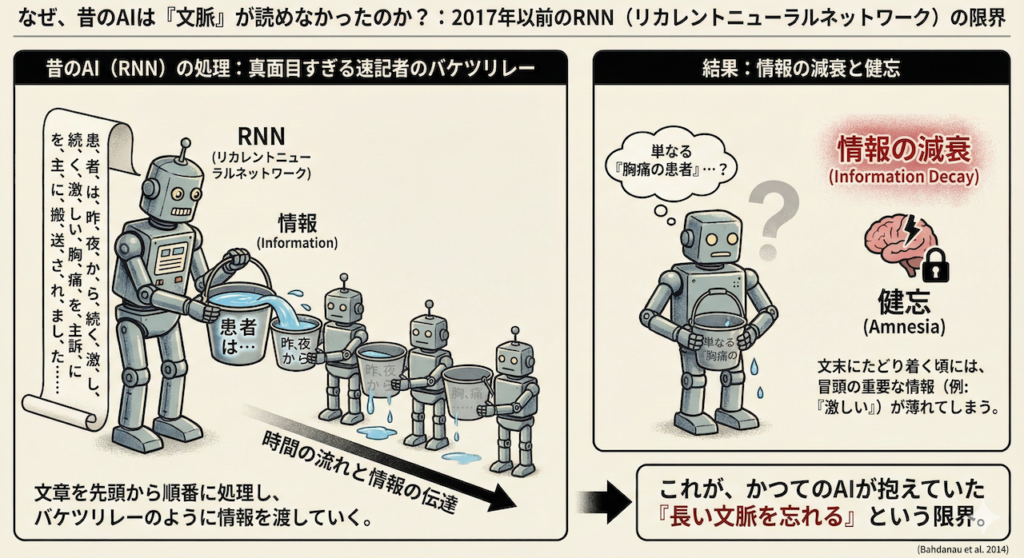
実は、2017年以前のAI(主にRNN:リカレントニューラルネットワークと呼ばれるタイプ)にとって、この「当たり前」の作業が絶望的に困難でした。
彼らは、真面目すぎる速記者のようなものでした。文章を先頭から一文字ずつ、順番に読んで記憶していくことしかできなかったのです。
「患、者、は、昨、夜、か、ら……」と順番に処理してバケツリレーのように情報を渡していくため、文章が長くなればなるほど、最初の方にあった情報の「水」はこぼれ落ちてしまいます。
その結果、文末の「搬送されました」にたどり着く頃には、冒頭にあった「激しい」という重要な修飾語の印象が薄れてしまい(情報の減衰)、単なる「胸痛の患者」として処理してしまう――。いわば、重度の「健忘」症状を抱えていたのが、かつてのAIの限界でした (Bahdanau et al. 2014)。
Attentionが起こした「読み方」の革命
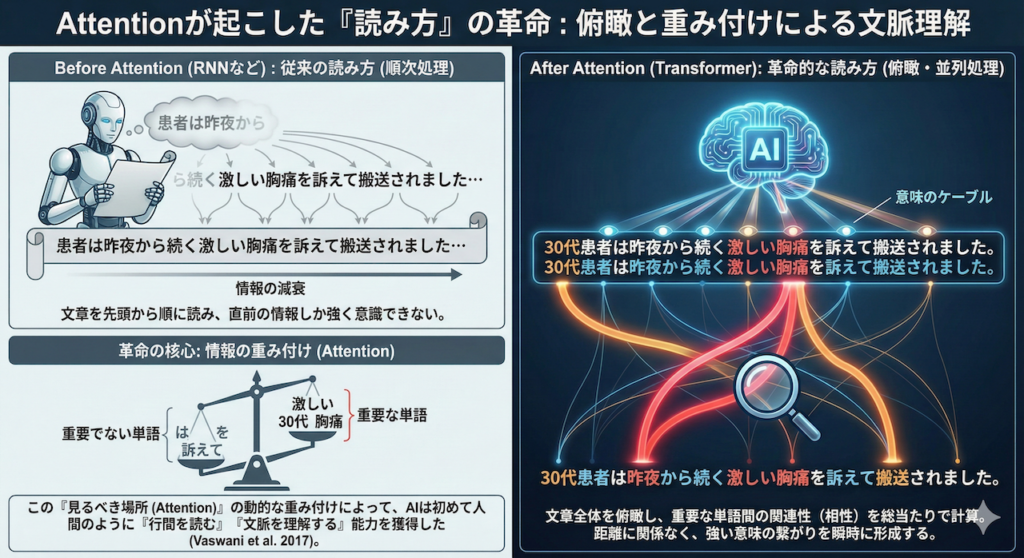
しかし、Attentionを搭載した最新のAI(Transformerモデル)は、読み方の次元が違います。
彼らは文章を「左から右へ」順に読むことをやめました。
代わりに、文章全体を「上空から一気に俯瞰(ふかん)」します。そして、文章の中に存在する全ての単語同士の相性(関連性)を、総当たりで計算し始めるのです。
「『胸痛』という言葉の意味を正しく定義するには、隣にある『を』や『訴えて』は重要ではない。ずっと前にある『激しい』と、冒頭の『30代』という情報こそを、強く参照しなければならない!」
AIはそう判断すると、距離の壁を飛び越えて、重要な単語と単語の間に太くて強い「意味のケーブル(関連性)」を瞬時に接続します。逆に、重要でない単語との接続は細く弱くします。
このように、単なる文字の羅列の中から、文脈に応じて動的に「見るべき場所(Attention)」を変え、情報の重み付けを行うこと。これによってAIは初めて、人間と同じように「行間を読む」あるいは「文脈を理解する」という能力を手に入れたのです (Vaswani et al. 2017)。
2. 仕組みの正体:「カルテ検索」で理解するQuery, Key, Value
では、AIの脳内では具体的にどのような計算が行われて、この「注目の強さ(Attention Weight)」が決まるのでしょうか?
専門書を開くと、「QueryベクトルとKeyベクトルの内積を取り、Softmax関数で正規化し……」といった呪文のような説明が並び、多くの初学者がここで脱落します。
しかし、恐れることはありません。この仕組みは、私たちが日常的に行っている「電子カルテの検索システム」と全く同じ構造をしているのです。
Attentionメカニズムの内部には、以下の「3人の登場人物」がいます。
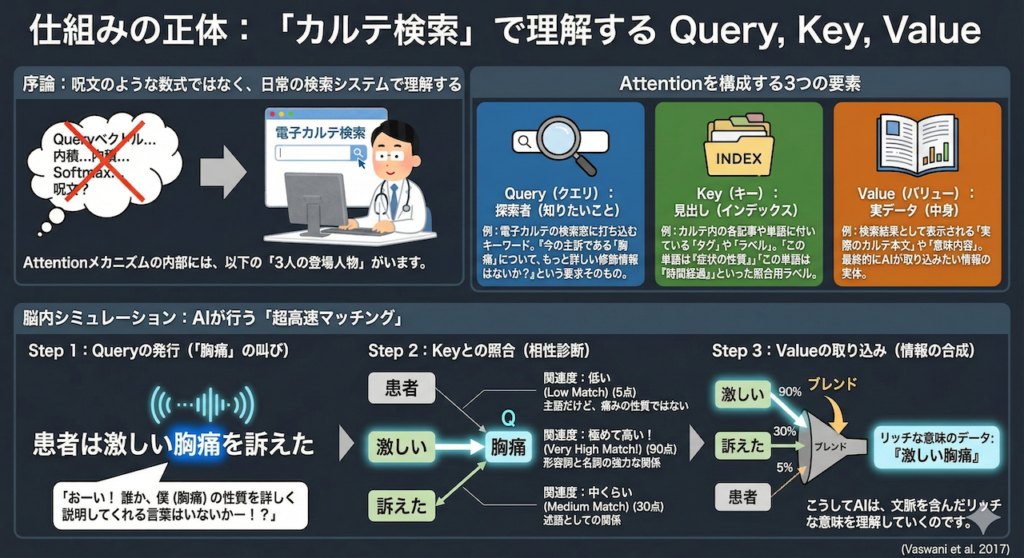
Attentionを構成する3つの要素

- Query(クエリ): 「探索者(知りたいこと)」
例:あなたが電子カルテの検索窓に打ち込むキーワード。
「今の主訴である『胸痛』について、もっと詳しい修飾情報はないか?」という要求そのものです。 - Key(キー): 「見出し(インデックス)」
例:カルテ内の各記事や単語に付いている「タグ」や「ラベル」。
検索システムが、「この単語は『症状の性質』を表している」「この単語は『時間経過』を表している」といった照合用ラベルを持っています。 - Value(バリュー): 「実データ(中身)」
例:検索結果として表示される「実際のカルテ本文」や「意味内容」。
最終的にAIが取り込みたい情報の実体です。
脳内シミュレーション:AIが行う「超高速マッチング」
AIが「患者は激しい胸痛を訴えた」という文章を処理する際、脳内では以下のようなマッチング処理が瞬時に行われています。
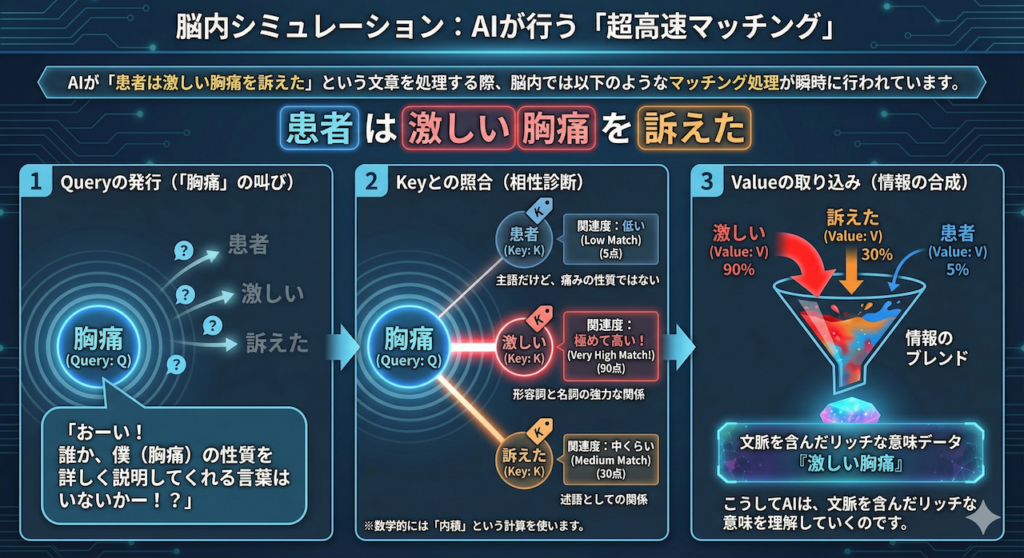
Step 1:Queryの発行(「胸痛」の叫び)
まず、「胸痛」という単語がQuery(Q)として立ち上がり、文章中の他のすべての単語に向かって問いかけます。
「おーい! 誰か、僕(胸痛)の性質を詳しく説明してくれる言葉はいないかー!?」
Step 2:Keyとの照合(相性診断)
この呼びかけに対して、文章中の他の単語たちが自分のKey(K)を提示します。
AIは、Query(胸痛)と、それぞれのKeyとの「関連度(マッチ度)」を計算します(※数学的には「内積」という計算を使います)。
- 「患者」のKey vs 「胸痛」のQuery → 関連度:低い(主語だけど、痛みの性質ではない)
- 「激しい」のKey vs 「胸痛」のQuery → 関連度:極めて高い!(形容詞と名詞の強力な関係)
- 「訴えた」のKey vs 「胸痛」のQuery → 関連度:中くらい(述語としての関係)
Step 3:Valueの取り込み(情報の合成)
マッチングの結果、「激しい」という単語が90点、「訴えた」が30点、「患者」が5点……といったスコアが出たとします。
AIは、このスコアに応じて、各単語が持っているValue(中身の情報)をブレンドして取り込みます。
「『激しい』の意味を90%、『訴えた』の意味を30%混ぜ合わせて……よし、これで『ただの胸痛』ではなく『激しい胸痛』という意味のデータが完成だ!」
こうしてAIは、文脈を含んだリッチな意味を理解していくのです。
数式の「翻訳」:怖がる必要はありません

この一連の流れを、論文『Attention Is All You Need』では以下の数式で表現しています。
一見難しそうに見えますが、今までの物語をそのまま記号にしただけです。
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
この数式を「医療現場語」に翻訳してみましょう。
- \(QK^T\): 「胸痛(Query)」と他の全単語(Key)との相性チェック(マッチング計算)です。
- \(\text{softmax}(\dots)\): 計算されたスコアを「合計が100%になるようなパーセンテージ」に変換する魔法です。「激しい:0.9」「訴えた:0.05」……といった確率分布に直します。
- \(\dots V\): 最後に、そのパーセンテージ(重み)を使って、各単語のValue(情報の中身)を回収・合成します。
つまり、この数式全体が言っていることは、「検索して(QとK)、重要度を計算し(Softmax)、必要な情報だけを集めてくる(V)」という、私たちが調べ物をするプロセスそのものなのです。
3. 実装:AIの「視線」をヒートマップで可視化しよう
「百聞は一見にしかず」です。
理屈は一旦置いておき、実際にPythonを使って、AIの脳内を「fMRI(機能的磁気共鳴画像法)」のように撮影してみましょう。
ターゲットにする文章は、先ほどの例と同じ「患者は激しい胸痛を訴えた」です。
AIがこの文章を読むとき、脳内の神経回路(ニューロン)がどのように発火し、どの単語とどの単語をつなげているのか。それを色鮮やかな「ヒートマップ」として可視化します。
【実行前の準備:AIの「手術道具」を揃える】
Google Colabなどのクラウド環境で実行する場合、日本語のグラフを表示したり、最新のAIモデルを動かすための「道具箱(ライブラリ)」をインストールする必要があります。最初に以下のコマンドを実行して、環境を整えてください。
!pip install transformers fugashi ipadic japanize-matplotlib unidic_lite準備ができたら、いよいよ本番です。以下のコードを実行してみてください。
東北大学が開発した「日本語BERTモデル」の思考回路(Attention)をのぞき見るプログラムです。
※単純に出力すると、文末の記号([SEP])などに視線が集中して肝心の中身が見えにくくなるため、重要な単語部分だけを拡大(トリミング)して表示する工夫をコードに組み込んでいます。
import torch
from transformers import BertJapaneseTokenizer, BertModel
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib # グラフの日本語文字化けを防ぐ「おまじない」
import numpy as np
# -------------------------------------------------------
# 1. AIモデル(脳)の準備
# -------------------------------------------------------
# 東北大学が公開している、日本語学習済みの「BERT」モデルを使用します
MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
# トークナイザー:文章をAIが読める単位(トークン)に切り分ける「メス」
tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME)
# モデル本体:AIの脳みそ(output_attentions=Trueで思考過程を出力)
model = BertModel.from_pretrained(MODEL_NAME, output_attentions=True)
def visualize_attention(text):
"""
指定されたテキストに対するAIのAttention(注目度)を可視化する関数
"""
print(f"解析中の文章: {text}")
# -------------------------------------------------------
# 2. 文章をAIが読める形式に変換(前処理)
# -------------------------------------------------------
inputs = tokenizer(text, return_tensors='pt')
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
# -------------------------------------------------------
# 3. AIに読ませる(推論実行)
# -------------------------------------------------------
with torch.no_grad():
outputs = model(**inputs)
# -------------------------------------------------------
# 4. Attention(脳波データ)を取り出す
# -------------------------------------------------------
# 最後の層(最も高度な理解をしている層)のAttentionを取得
last_layer_attention = outputs.attentions[-1]
# 複数の視点(Head)の平均を取り、全体的な傾向を見ます
attention_matrix = torch.mean(last_layer_attention, dim=1)[0].numpy()
# -------------------------------------------------------
# 【重要】見やすくするためのトリミング加工
# -------------------------------------------------------
# 文頭の[CLS]や文末の[SEP]といった記号を除外し、
# 意味のある単語同士のつながりを拡大表示します。
attention_matrix = attention_matrix[1:-1, 1:-1]
tokens = tokens[1:-1]
# -------------------------------------------------------
# 5. ヒートマップ(サーモグラフィ)で描画
# -------------------------------------------------------
plt.figure(figsize=(10, 8))
sns.heatmap(attention_matrix,
xticklabels=tokens,
yticklabels=tokens,
cmap='Blues', # 色使い(青色ベース)
annot=False, # 数字は表示しない
square=True, # 正方形に整える
cbar_kws={'label': 'Attention Score (注目の強さ)'})
plt.title(f"AIの視線:『{text}』のつながり", fontsize=16)
plt.xlabel("見られている単語 (Key: 情報源)", fontsize=12)
plt.ylabel("見ている単語 (Query: 起点)", fontsize=12)
plt.xticks(rotation=45)
plt.yticks(rotation=0)
plt.show()
# --- 実行してみよう ---
target_text = "患者は激しい胸痛を訴えた"
visualize_attention(target_text)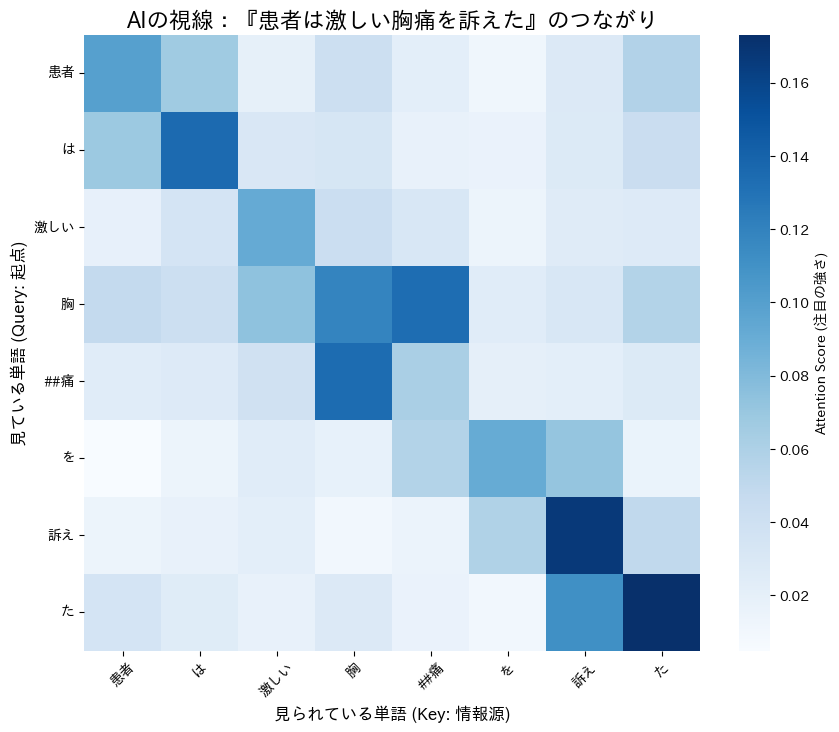
4. 結果の見方:AIの思考を解読する
実行すると、青いモザイク模様(ヒートマップ)が表示されます。これが「AIの視線の記録」です。
レントゲン写真のように、この図を詳しく読影してみましょう。
① 「胸痛」が2つに割れている!?
まず軸のラベルを見て驚くかもしれません。「胸痛」という単語が、「胸」と「##痛」(##は『前の単語に続く』という意味の記号)の2つに分割されています。
これはAIが未知の言葉に対応するために、単語を細かいパーツ(サブワード)に分解して理解しようとしている証拠です。
実際に、縦軸の「胸」の行を見てください。最も濃い青色(強い視線)が向けられている先は、右隣の「##痛」ではないでしょうか?
「『胸』という文字だけじゃ意味が狭すぎる。後ろの『痛』とくっついて初めて『Chest Pain』になるんだ!」
AIはまず何よりも先に、バラバラになった単語パーツを結合し、意味のあるカタマリを再構築することに全力を注いでいるのです。
② 文脈をつなぐ「中くらいの青」
次に、縦軸の「激しい」という行を見て、横軸の「胸」や「##痛」との交差点を見てみてください。
真っ青ではないものの、薄っすらと青く色づいているのが分かるはずです。
これこそが「文脈の理解」です。
AIは単語の再構築(胸+痛)を行いながらも、同時に「激しい」という修飾語とも緩やかなネットワークを結んでいます。
「一番大事なのは『胸』と『痛』がくっつくこと(濃い青)。でも、それが『激しい』ものであるという情報も、忘れずにリンクしておこう(中くらいの青)」
このように、AIの脳内では「単語の組み立て」と「文脈のリンク」が、濃淡の異なる青色として同時に処理されているのです。
5. なぜ医療にこれが必要なのか?
「単語と単語のつながりが見えたからといって、それが臨床の現場で何の役に立つの?」
そう思われる方もいるかもしれません。
しかし、医療現場において、このAttention(注意機構)の能力は、単なる便利機能ではありません。それは、致命的な医療過誤を防ぐための「命綱」そのものなのです。
① 否定語の取り違えを防ぐ(「Not」の壁)
医療テキストの解析において、最も恐ろしく、かつ絶対に避けなければならないミス。それは「肯定と否定の取り違え」です。
例えば、以下の2つの文を見てください。
- 「ペニシリンアレルギーあり」
- 「ペニシリンアレルギーなし」
文字の並びとしては9割以上が同じです。しかし、その意味は天と地ほど違います。もしAIがここを読み間違えれば、アナフィラキシーショックによる医療事故に直結しかねません。
かつてのAI(RNNなどAttentionを持たないモデル)は、文章を左から右へと一文字ずつ流し読みしていました。そのため、文脈が長くなったり、「……という所見は認められなかった」のように否定語が文末に離れて置かれたりすると、その効力がどこまで及ぶのかを判断できず、「アレルギー」という単語の強い印象だけに引きずられて「陽性」と誤認することがありました。
しかし、Attentionメカニズムを持つ最新のAIは違います。
実際にヒートマップで解析すると、彼らが「アレルギー」という単語を処理する際、文末にある「なし」や「認めず」といった否定語に向かって、強烈なAttention(視線)を向けていることが確認されています (Khandelwal and Sawant 2020)。
「この『アレルギー』という単語は、後ろにある『なし』という言葉とセットで読み込まないと、意味が180度変わってしまう!」
AIは計算の中でこのように強く関連付けることで、「これはアレルギーが存在するという意味ではなく、否定されている情報(Negative)だ」と正確に認識します。
この「文脈をまたぐ強力な結びつき」こそが、AIによる読解ミスを減らし、誤薬や誤診のリスクを劇的に下げる安全装置となっているのです (Jiang et al. 2023)。

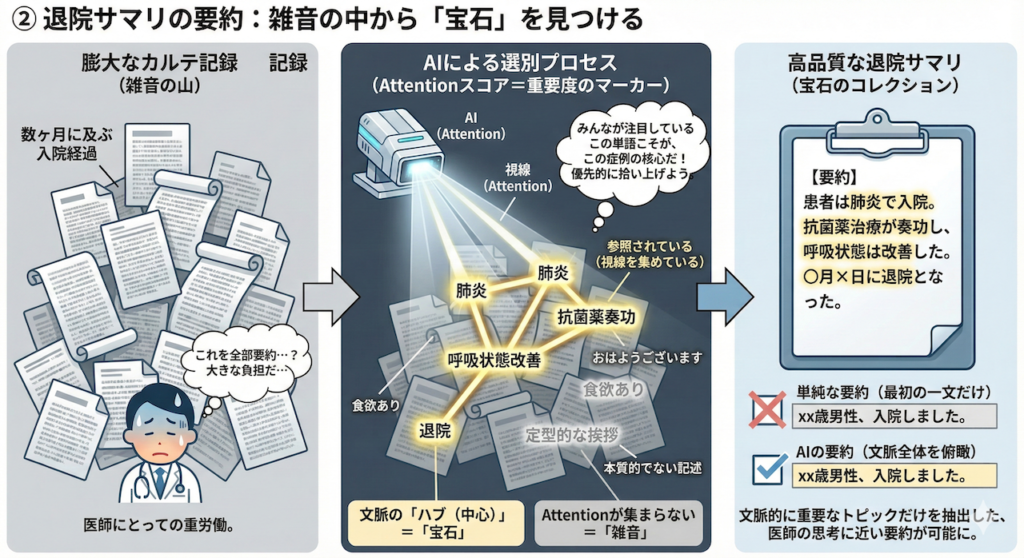
② 退院サマリの要約:雑音の中から「宝石」を見つける
数ヶ月に及ぶ入院経過が記された、膨大なカルテ記録。これを要約して退院サマリを作る作業は、医師にとって大きな負担です。
AIに要約を任せるとき、Attentionスコアは「重要度のマーカー」として機能します。
文章の中で、他のたくさんの単語から「参照されている(視線を集めている)」単語は、それだけ文脈上の「ハブ(中心)」であることを意味します。
逆に、定型的な挨拶や、本質的でない記述には、あまりAttentionが集まりません。
AIはこのスコアを見て、「みんなが注目しているこの単語こそが、この症例の核心(宝石)だ」と判断し、優先的に拾い上げます。
これにより、「最初の一文だけを切り抜く」ような単純な要約ではなく、文章全体を見渡して「文脈的に重要なトピック」だけを抽出した、医師の思考に近い要約が可能になるのです。
Next Step:言葉の意味は「空間」にある
今回の旅では、ヒートマップを使って「AIがどの単語に注目し、どう文脈をつないでいるか」という「思考のプロセス(Attention)」を可視化しました。
しかし、ここで一つ、根本的な疑問が浮かびませんか?
「そもそもAIは、『胸痛』や『激しい』という日本語を、どうやって計算機の中で扱っているの?」
実は、AIの脳内には「文字」は一文字も存在しません。
そこにあるのは、すべて「数字の羅列(ベクトル)」だけです。
AIにとって、言葉とは辞書にある定義ではなく、広大な数学的空間の中に浮かぶ「座標(点)」なのです。
以下の回でも直感的なイメージを掴むための解説しましたが、[Series L]では、今回学んだAttentionによって選び出されたこれらの数字たちが、どのようにして「意味の空間(ベクトル空間)」を構築していくのか。その深淵に迫ります。

言葉を足したり引いたりできる不思議な幾何学の世界。
AIが言葉を「理解」するのではなく、「計算」しているという魔法の裏側へ、さらに深く潜っていきましょう。
参考文献
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30.
- Bahdanau, D., Cho, K. and Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. Proceedings of the International Conference on Learning Representations (ICLR).
- Jiang, L.Y., et al. (2023). Health system-scale language models are all-purpose prediction engines. Nature, 619, pp. 24–30.
- Khandelwal, A. and Sawant, S. (2020). NegBERT: A Transfer Learning Approach for Negation Detection and Scope Resolution. Proceedings of the 12th Language Resources and Evaluation Conference, pp. 5739–5748.
- Chapman, W.W., Bridewell, W., Hanbury, P., Cooper, G.F. and Buchanan, B.G. (2001). A simple algorithm for identifying negated findings and diseases in discharge summaries. Journal of Biomedical Informatics, 34(5), pp. 301–310.
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




