

偏ったデータや社会の歪みをそのまま学習すると、AIは差別構造を「正解」として再現してしまいます。
「AIは感情を持たない機械なのだから、人間のような『差別』や『忖度』とは無縁でしょう? 常にクールで、中立公平な判断をしてくれるはずだ」
もしあなたがそう信じているとしたら、その認識を少しだけアップデートする必要があるかもしれません。実は、AIほど「育った環境(学習データ)」に色濃く影響されやすく、無自覚な偏見を持ちやすい存在はいないのです。
今日は、AIが陥りやすい「偏食」という名の罠と、それが医療現場で引き起こしかねない恐ろしい「副作用」について、シミュレーションを交えながらお話しします。データという毎日の「食事」がいかにしてAIの人格(モデルの挙動)を形成してしまうのか、そのメカニズムを紐解いていきましょう。
1. AIは「何でも食べる」わけじゃない? ~データの偏食とGIGO~
まず、AI(特にディープラーニング)という存在を、真っ白なキャンバスを持った「生まれたての子供」だとイメージしてください。この子供は、人間のように誰かから「これは良いこと、これは悪いこと」と言葉で教わることはありません。ただひたすらに、与えられた「経験(データ)」だけを材料にして、世界のルールを自力で構築します。
ここで、一つ思考実験をしてみましょう。もしこの子供に、食事として毎日「リンゴ」ばかりを与え続けたら、どう育つでしょうか?
来る日も来る日も、赤くて丸いリンゴだけを見て、触れて、味わって育ちます。彼の中で「食べ物」の定義は、「赤くて、丸くて、シャリッとするもの」というルールだけで固定されます。
そんなある日、彼の目の前に真っ赤な「トマト」が出されました。彼はどう反応するでしょうか? おそらく、自信満々にこう断言するはずです。
「これは食べ物ではありません(だって、リンゴの味がしないから)」
彼にとって、学習した「リンゴのルール」こそが世界の真理であり、それ以外の味や食感は、理解不能な「異物」や「ノイズ」として切り捨てられてしまうのです。これが、AIにおける「データの偏り(Bias)」の正体です。AIは、教わっていない世界(学習データの分布外)を想像して補うことが、極めて苦手なのです。

「Garbage In, Garbage Out(ゴミが入ればゴミが出る)」
コンピュータ科学の世界には、古くから伝わる「Garbage In, Garbage Out(GIGO:ギゴ)」という鉄の掟のような格言があります。「ゴミのようなデータを入れれば、ゴミのような結果しか出てこない」という意味です。
どんなに天才的な頭脳(最新のアルゴリズム)を持っていても、食べている食事(学習データ)が偏っていたり、質が悪かったりすれば、そこから導き出される思考や判断も必ず歪みます。AIは、私たちが与えたデータという鏡に映る「社会の偏見」や「不均衡」を、そのまま、時には増幅して映し出す鏡のような存在なのです。
2. 医療現場で起きる「見えない差別」の実例
「でも、医療データなら客観的な検査数値や画像ばかりだし、人間の『偏見』なんて入り込む余地はないのでは?」
そう思われるのも無理はありません。しかし、ここにデータサイエンスにおける最大の落とし穴があります。データそのものは嘘をつきませんが、「データが社会の歪みをそのまま記録してしまっている」場合があるのです。実際の研究で明らかになった、衝撃的な事例を見てみましょう。
ケース1:重症なのに「健康」と判定された患者たち
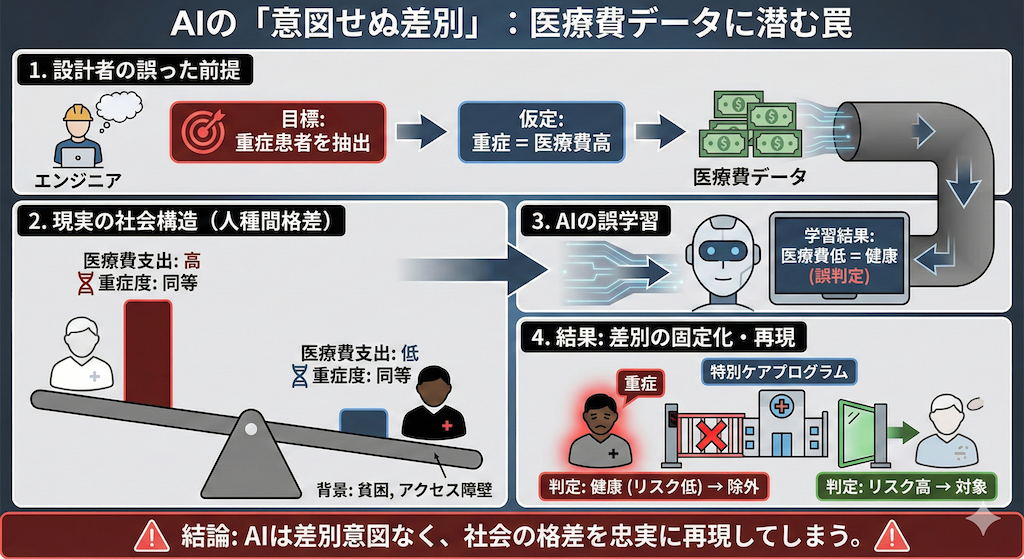
2019年に『Science』誌に掲載された研究は、医療AI界に激震を走らせました(Obermeyer et al. 2019)。米国の多くの病院で実際に運用されていた「患者のリスクを予測し、特別なケアマネジメントプログラムが必要な人を抽出するアルゴリズム」に、重大な人種バイアスが見つかったのです。
このAIは、患者の将来的な重症度を予測するために、代理指標(Proxy label)として「過去の医療費」を学習していました。開発者の理屈はこうです。
- AIへの指示(意図):「病気が重い人は、治療や入院にお金がかかっているはずだ。だから、医療費が高い人を抽出すれば、重症患者を見つけられるだろう」
一見、論理的に見えますし、医療費データは電子カルテから取得しやすい情報です。しかし、米国の社会背景として、同じ重症度(腎機能や血圧などのバイオマーカーが同じ値)であっても、黒人患者は白人患者に比べて、貧困や医療へのアクセス障壁、医療不信などの理由で「医療費の支出が大幅に少ない」という現実がありました。
その結果、AIは何を学んでしまったか。
「医療費が少ない = 重症ではない(健康である)」
この誤った学習により、AIは「白人患者よりもはるかに病状が重い黒人患者を、リスクが低い(健康)と誤判定」し、命を救うためのケアプログラムから除外してしまっていたのです。AI自体に黒人を差別する意図はありません。ただ、「人種間の格差」という社会構造が反映されたデータを忠実に学習し、それをアルゴリズムとして固定化・再現してしまっただけなのです。
ケース2:画像診断における「過小診断」の罠
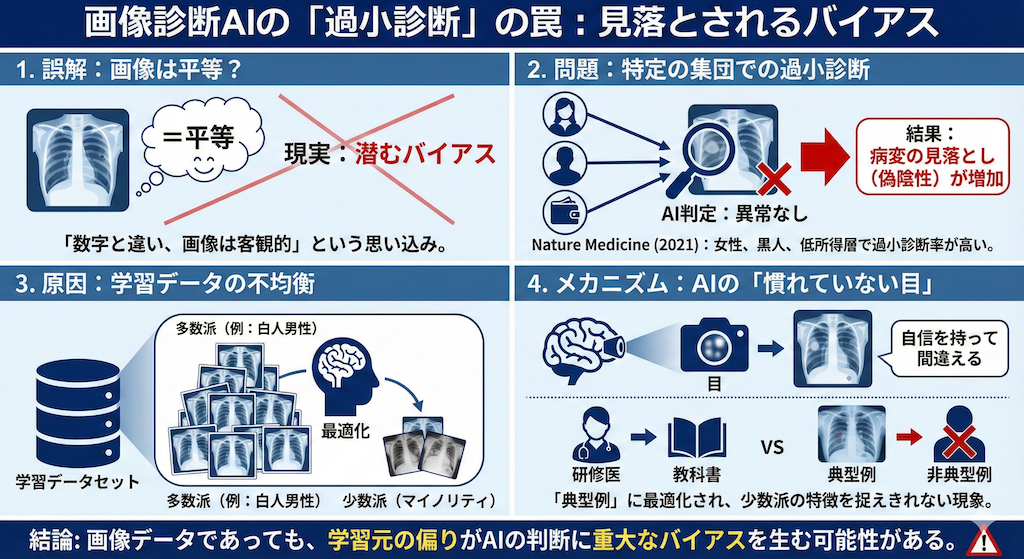
「数字(医療費)は社会の影響を受けるかもしれないが、画像(X線)なら平等だろう」と思うかもしれません。しかし、画像診断の世界でも同様の問題が報告されています。
2021年の『Nature Medicine』の研究では、最先端の深層学習モデルを用いて胸部X線から病変を検出する際、女性や黒人患者、低所得層(公的保険加入者)の患者において「過小診断(Underdiagnosis)」の率が高くなることが示されました(Seyyed-Kalantari et al. 2021)。
ここでの「過小診断」とは、本来は病気があるのに「異常なし」と判定されてしまう、いわゆる偽陰性(False Negative)のことです。なぜ、特定のグループだけ見落としが増えるのでしょうか?
原因の一つは、学習データの不均衡(Imbalance)にあります。もしAIの学習データセットにおいて、特定の属性(例えば「白人男性」)の画像が圧倒的に多かった場合、AIはその「多数派の特徴」に合わせてパラメータを最適化してしまいます。
その結果、少数派(マイノリティ)のデータに対しては、AIの「目」が十分に慣れておらず、病変の特徴を捉えきれずに「自信を持って間違える」という現象が起きるのです。これは、教科書で「典型例」ばかりを勉強した研修医が、非典型的な症状の患者さんを見落としてしまう現象によく似ています。
3. 数学的に見る「不公平」のメカニズム
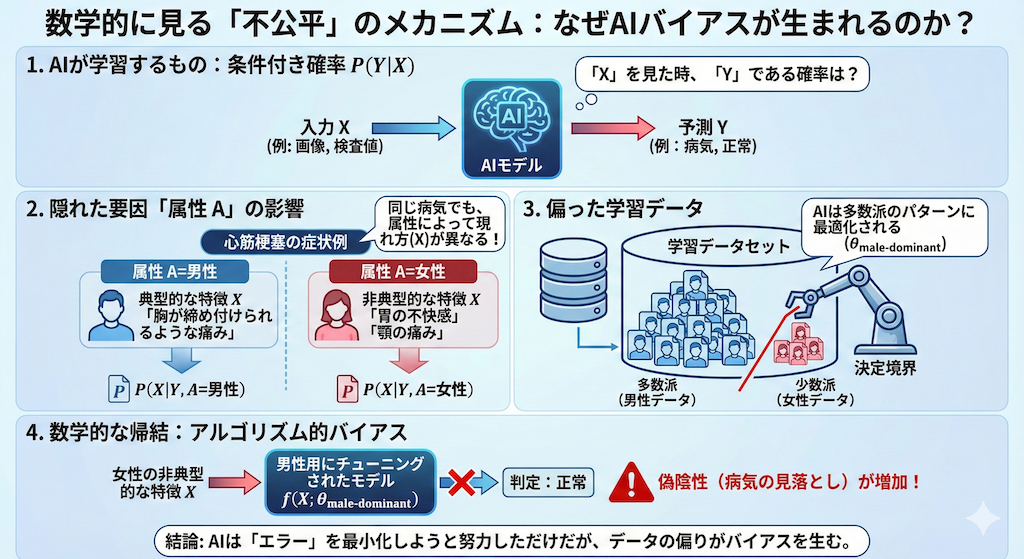
なぜこのような差別やバイアスが生まれてしまうのか。少しだけ、この現象を数理的な視点で整理してみましょう。「数学」と聞くと身構えてしまうかもしれませんが、恐れることはありません。直感的に理解できる仕組みです。
私たちがAI(機械学習モデル)を作るとき、通常は条件付き確率 \( P(Y \mid X) \) を学習させようとします。記号の意味は以下の通りです。
- \( X \):入力データ(患者さんのX線画像、血液検査値など)
- \( Y \):予測したい正解(病気である、病気ではない)
つまり、AIは「画像 \( X \) を見たときに、それが病気 \( Y \) である確率」を計算しようとしているわけです。
しかし、ここで問題になるのが、患者さんの属性 \( A \)(例:性別、人種、年齢など)です。もし学習データにおいて、属性 \( A \) ごとのデータの現れ方(分布)が大きく異なっていたらどうなるでしょうか?
例えば、心筋梗塞の症状を考えてみましょう。
- 男性の場合 \( P(X \mid Y, A=\text{男性}) \): 「胸が締め付けられるような痛み」という典型的な特徴 \( X \) が出やすい。
- 女性の場合 \( P(X \mid Y, A=\text{女性}) \): 「胃の不快感」や「顎の痛み」といった非典型的な特徴 \( X \) が出ることがある。
もし、AIに学習させるデータセットが「男性のデータ」ばかりで構成されていたら(データの偏食)、AIはどうなるでしょうか? AIが構築する決定境界(病気かどうかの線引きをする境界線)は、当然ながら「男性のデータパターン」に最適化される形で引かれます。
これを数式でイメージすると、AIの予測モデル \( f \) のパラメータ \( \theta \) は、多数派である男性データ(male-dominant)に引っ張られて固定されます。
\[ \hat{Y} = f(X; \theta_{\text{male-dominant}}) \]
この「男性用にチューニングされたモデル」を、女性の患者さんにそのまま適用したらどうなるでしょう? 女性特有の非典型的な症状 \( X \) が入力されたとき、モデルは「学習した典型的なパターン(胸痛)と違う」と判断し、本来は「病気」であるはずの領域を「正常」の領域に含めてしまうかもしれません。
これが、偽陰性(病気を見落とすこと)が増える数学的な理由であり、アルゴリズム的バイアス(Algorithmic Bias)の正体の一つです。AIは数学的に「損失(エラー)」を最小化しようと努力しただけなのですが、データの偏りによって、その努力の方向が「多数派にとっての最適化」へと歪められてしまったのです。
このメカニズムを、簡単な図でイメージしてみましょう。
4. 私たちにできること:AIの「偏食」を治す処方箋
ここまで、AIが陥りやすいバイアスの問題について見てきました。「AIは意外と不公平だ」と知って、少し怖くなったかもしれません。では、私たちはこの問題にどう立ち向かえばよいのでしょうか?
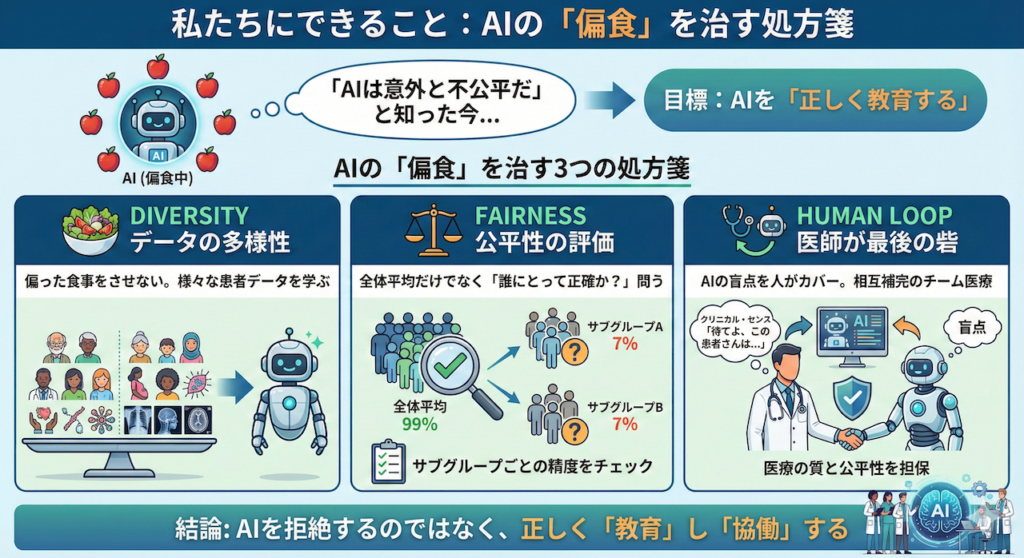
「リスクがあるからAIを使わない」というのは、根本的な解決策ではありません。AIには医療の質を飛躍的に向上させるポテンシャルがあるからです。重要なのは、AIを拒絶することではなく、AIの「偏食」を治し、「正しく教育する」ことです。
データの多様性(Diversity)を確保する
これが最も基本的かつ重要な対策です。AIに「リンゴ」だけでなく、「トマト」も「キュウリ」も食べさせるように、学習データセットの偏りを解消する必要があります。
具体的には、特定の人種、性別、年齢層だけでなく、様々な背景を持つ患者さんのデータを含んだバランスの良いデータセットを構築することが不可欠です。最近では、データの偏りを補正するための技術(データ拡張や再サンプリングなど)も研究されています。
公平性(Fairness)を評価する
AIの性能評価に対する意識を変える必要があります。単に「全体の正解率(Accuracy)が99%です!」という数字だけで満足してはいけません。
「その99%は、誰にとっての99%なのか?」と問いかける姿勢が重要です。「男性での正解率は? 女性では? 高齢者では? マイノリティでは?」と、サブグループごとの精度(Subgroup Analysis)を厳しくチェックする視点が求められます(Rajkomar et al. 2018)。もし特定のグループだけ精度が低ければ、そのAIはまだ「臨床導入には不十分」と判断すべきです。
医師が「最後の砦」となる(Human-in-the-loop)
そして、これが最も重要で、人間にしかできない役割です。それは、医師自身がAIの特性と限界を理解し、「最後の砦」となることです。
AIが出した答えに対して、盲目的に従うのではなく、「待てよ、この患者さんはAIの学習データには少ない属性(高齢者や小児など)かもしれない」「AIはこの非典型的な症状を見落としているかもしれない」と疑う直感(クリニカル・センス)を持つこと。
AIの盲点を人間がカバーし、人間の認知バイアスをAIが補う。この相互補完的な関係、いわゆる「Human-in-the-loop(人間が関与するループ)」の体制こそが、医療の質と公平性を担保する鍵となります(Char et al. 2018)。
まとめ:良質なデータが、良質なAIを育てる
AIは、魔法の杖ではありません。彼らは、私たちが提供したデータという狭い世界の中でしか生きられない、ある意味で不器用な存在です。
偏ったデータ(ジャンクフード)を与えれば、偏見に満ちた大人に育ってしまいます。しかし、多様で公平なデータ(栄養バランスの取れた食事)を与えて大切に育てれば、誰にでも優しく、頼りになる最高のパートナーに育ちます。
「AIは意外と偏食家で、頑固者だ」
まずはそう理解することから始めましょう。その上で、彼らに栄養満点のバランスの良いデータを提供し、その成長を厳しくも温かく見守る。それこそが、AIと共存するこれからの時代の医療従事者に求められる、新しいリテラシーなのかもしれません。
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
参考文献
- Obermeyer, Z., Powers, B., Vogeli, C. and Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), pp. 447–453.
- Seyyed-Kalantari, L., Zhang, H., McDermott, M.B.A., et al. (2021). Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations. Nature Medicine, 27, pp. 2176–2182.
- Rajkomar, A., Hardt, M. and Howell, M.D. (2018). Ensuring fairness in machine learning to advance health equity. Annals of Internal Medicine, 169(12), pp. 866–872.
- Char, D.S., Shah, N.H. and Magnus, D. (2018). Implementing machine learning in health care — addressing ethical challenges. The New England Journal of Medicine, 378(11), pp. 981–983.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




