

「AIが絵を描き、小説を綴り、あるいは新しいタンパク質構造さえもデザインする」——。
ほんの数年前まで、これはSF映画の中だけの出来事でした。しかし今、私たちはその「未来」に生きています。ここで、冷静な実務家の視点で、ふと疑問が湧きませんか?
「計算機(Computer)であるはずの機械が、なぜ『創造(Creation)』という、最も人間らしい営みができるのか?」 と。
結論から言いましょう。生成AI(Generative AI)は、無から有を生み出す魔法使いでもなければ、魂を持った芸術家でもありません。
その正体は、膨大な過去のデータを徹底的に学習し、そこから「確率という名のサイコロ」を振って、もっともらしい「正解のようなもの」を紡ぎ出す、極めて優秀な「統計学の職人」なのです。
計算機が夢を見るメカニズムとは、一体どうなっているのでしょうか?
今回は、この一見難解な「創造の仕組み」を、数式という設計図と、少しユニークな「ものまね芸人」のたとえ話を使って、直感的に解き明かしていきましょう。

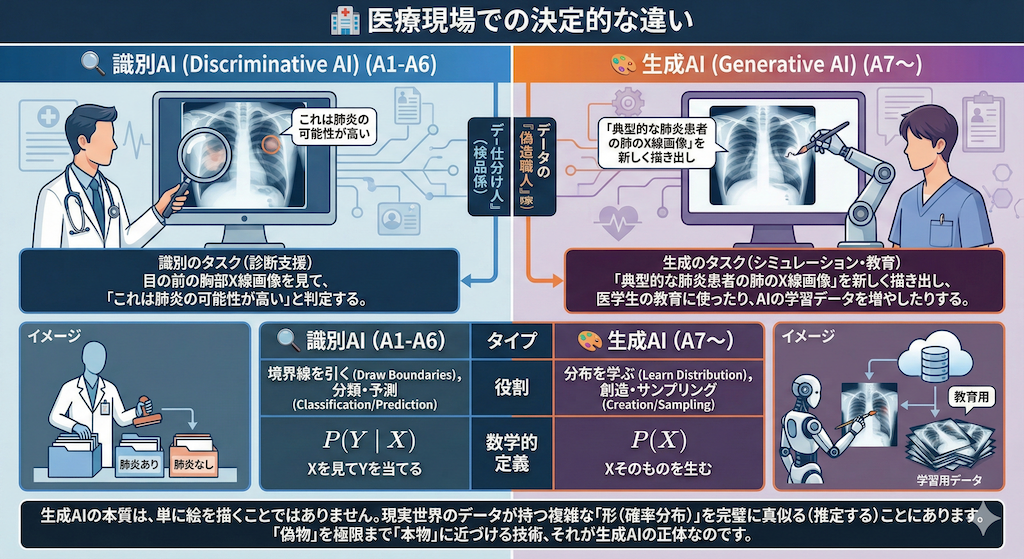
1. 「識別」と「生成」:似て非なる2つの能力
まず、これまでの講義(A1〜A6)で扱ってきたAIと、今回から学ぶ生成AI(A7以降)との決定的な違いを整理しておきましょう。AIの世界には、大きく分けて2つの「職人」がいます。
🔍 識別モデル(Discriminative Model):データの「仕分け人」
これは、「与えられたデータが何であるか」を判定する能力です。
例えば、「この画像は猫ですか? 犬ですか?」と聞かれたときに、その特徴を見て境界線を引く作業です。前回の講義で学んだ「回帰」や「分類」がこれに当たります。
数学的には、「データ \( X \)(レントゲン画像など)を見たときに、正解ラベル \( Y \)(肺炎あり/なし)になる確率」、すなわち条件付き確率を計算しています。
\[ P(Y \mid X) \]
🎨 生成モデル(Generative Model):データの「偽造職人」
一方で生成モデルは、「新しいデータそのもの」を作り出す能力です。
「新しい猫の画像を一枚描いてください」と言われたときに、学習したデータの特徴を捉えて、この世に存在しないオリジナルの猫を生み出します。
こちらは、「データ \( X \) そのものが、どのくらいの確率で存在しそうか」という、データ自体の確率分布を学習します。
\[ P(X) \]
🏥 医療現場での決定的な違い
これを医療の現場に置き換えてみると、その役割の違いがより鮮明になります。
- 識別のタスク(診断支援):
目の前の胸部X線画像を見て、「これは肺炎の可能性が高い」と判定する。 - 生成のタスク(シミュレーション・教育):
「典型的な肺炎患者の肺のX線画像」を新しく描き出し、医学生の教育に使ったり、AIの学習データを増やしたりする。
| タイプ | 役割 | 数学的定義 | イメージ |
|---|---|---|---|
| 🔍 識別AI (A1-A6) | 境界線を引く 分類・予測 | \( P(Y \mid X) \) Xを見てYを当てる | データの「仕分け人」 (検品係) |
| 🎨 生成AI (A7〜) | 分布を学ぶ 創造・サンプリング | \( P(X) \) Xそのものを生む | データの「偽造職人」 (贋作画家) |
生成AIの本質は、単に絵を描くことではありません。現実世界のデータが持つ複雑な「形(確率分布)」を完璧に真似る(推定する)ことにあります。「偽物」を極限まで「本物」に近づける技術、それが生成AIの正体なのです。
2. データの「影」を捉える:確率分布という設計図
では、先ほど述べた「データの形(分布)を真似る」とは、具体的にどういうことでしょうか?
ここで、テレビで活躍する優秀な「ものまね芸人」を想像してみてください。
彼らが有名人のモノマネを習得するとき、その人の発言を一言一句丸暗記しているわけではありません。「声の高さ」「独特の口癖」「間の取り方」といった、その人をその人たらしめている「特徴の偏り(クセ)」を徹底的に分析し、再現しています。
「あの人なら、こういう場面でこう言いそうだ」というパターンを掴んでいるからこそ、本人が一度も言ったことのないセリフでも、まるで本人のように話すことができるのです(これが「生成」です)。
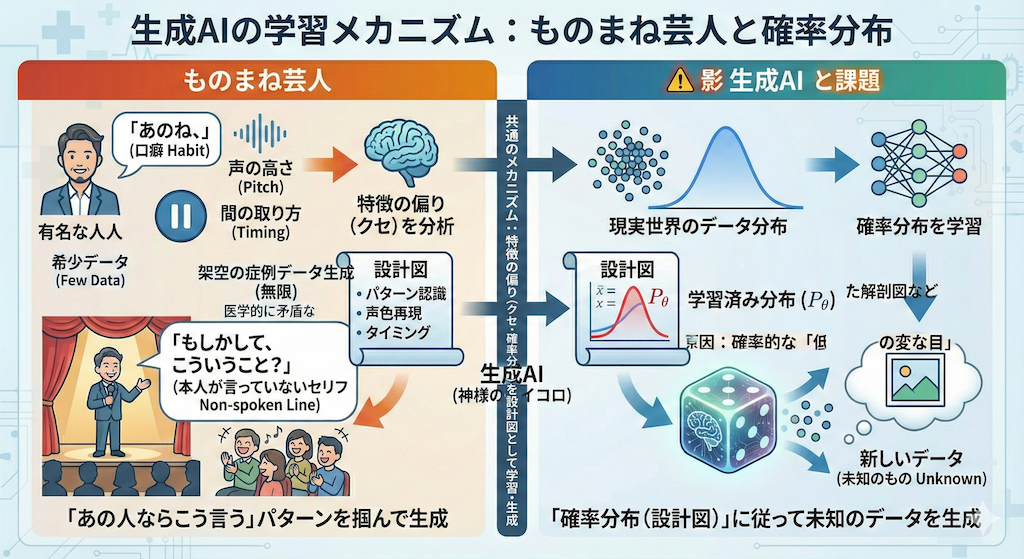
AIもこれと全く同じことを行っています。
数値の「山」を見つける
例えば、「健康な日本人の血液検査データ(赤血球数など)」を大量にAIに学習させるとしましょう。
AIは、「Aさんは450万、Bさんは480万…」と個別の数値を暗記するような非効率なことはしません。その代わりに、「どのくらいの数値が出る確率が高いか」というデータの集まり具合(分布の形状)を学習します。
- 450万〜500万付近:非常に多い(山の頂上)
- 300万以下や600万以上:めったにいない(山の裾野)
このようにデータには必ず「偏り」があり、これをグラフにすると「山のような形」になります。この山の形のことを、数学用語で確率密度関数(Probability Density Function)と呼びます。
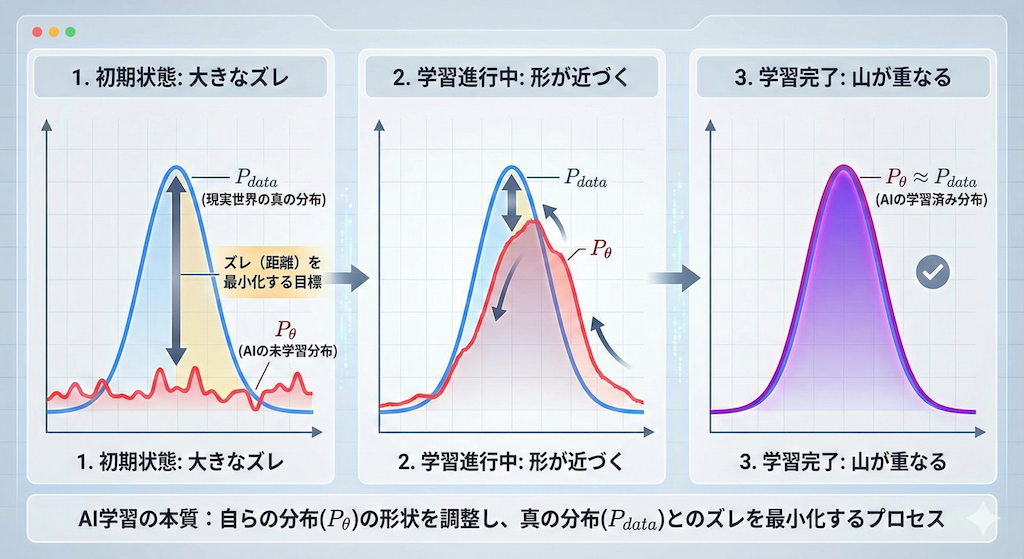
学習とは「山の形」を合わせること
生成AIの学習目標は、数式で書くと非常にシンプルです。
現実世界の真のデータ分布 \( P_{\text{data}}(x) \) に、AIが自分の中に作り上げた「真似」の分布 \( P_{\text{model}}(x) \) を限りなく近づけることです。
\[ P_{\text{model}}(x) \approx P_{\text{data}}(x) \]
最初はAIの分布はデタラメな形をしていますが、学習を進めるにつれて、その形状は現実のデータ分布とぴったり重なるようになっていきます。
この「2つの山のズレ(距離)」を最小化する作業こそが、AIの学習(パラメータ調整)の本質なのです。
3. 神様のサイコロ:ランダム性が「創造」を生む
さて、データの「山の形(分布)」を完璧に真似できたとします。しかし、それだけではまだデータは生まれません。
分布図をただ眺めていても、新しい絵や文章は出てこないからです。ここで必要になるのが、この分布の中から具体的なデータを一つ取り出す作業、すなわち「サンプリング(Sampling)」です。
これを一言で言えば、「確率という名のサイコロを振る」行為に他なりません。
なぜAIの答えは毎回違うのか?
ChatGPTに同じ質問をしても、毎回少しずつ表現の違う答えが返ってくることに気づいていますか?
あるいは、画像生成AIに「犬」と入力するたびに、ある時は柴犬、ある時はトイプードルと、毎回違う種類の犬が出てきますよね。
これはAIの気まぐれではありません。AIは、学習した巨大な確率分布の中から、サイコロの出目(確率)に従って、ランダムに一点を選び出している(サンプリングしている)からなのです。
- 山の高い部分(確率が高い):
サイコロの目がここに出る確率は高いです。ここからサンプリングされると、「誰もが納得する、典型的で王道の答え(ありふれたデータ)」が生成されます。 - 山の裾野(確率が低い):
確率は低いですが、たまにここに目が当たることがあります。すると、「珍しいけれど、確かに存在するユニークな答え(個性的なデータ)」が生成されます。
「ゆらぎ」こそが創造の源泉
もし、このランダム性(確率的要素)が全くなかったらどうなるでしょうか?
AIは毎回、確率が最も高い「平均的で無難な答え」を一つだけ返し続ける、単なる「検索エンジン」や「辞書」になってしまいます。
適度な「ノイズ(ゆらぎ)」を加えてサイコロを振るからこそ、AIは毎回異なる結果を出力でき、それが人間には「無限のバリエーション」や「創造性」のように映るのです。
計算機の中に「神様のサイコロ」を持ち込むこと。これこそが、機械に創造性を宿らせるための魔法の種なのです。
4. 潜在空間の操作:レシピを書き換える錬金術
ここまで、AIが「サイコロを振ってデータを生み出す」ことを見てきました。しかし、ただの運任せではありません。さらに面白いのは、この生成プロセスを私たちが意図的にコントロールできるという点です。
これを理解するために、生成AIにおける最も重要で美しい概念、「潜在空間(Latent Space)」についてお話ししましょう。

データ裏側の「レシピ」を見抜く
複雑なデータを、もっとシンプルな要素に分解して考えてみます。これを料理(カレー)に例えてみましょう。
目の前に完成した「カレー(目に見えるデータ \( x \))」があります。その背後には、必ずそれを作ったときの「レシピ(目に見えない要因 \( z \))」が存在します。
- スパイスの量:3.5
- 煮込み時間:120分
- 辛さレベル:5
生成AI(特にVAEやGANといったモデル)の凄さは、複雑な画像や文章データをそのまま丸暗記するのではなく、一度このシンプルな「レシピ(数値の羅列)」に圧縮して理解しようとする点にあります。この圧縮されたレシピの保管場所を、数学用語で「潜在空間」と呼びます。
レシピを書き換えて、現実を改変する
数式で見ると、生成のプロセスは次のような2段階になります。
\[ z \sim P(z) \]
まず、潜在空間からレシピ(潜在変数 \( z \))を一つ選びます(サイコロを振って決めます)。
\[ x = \text{Generator}(z) \]
次に、そのレシピ \( z \) を「生成器(Generator)」という調理マシンに渡して、具体的なデータ \( x \) を生成させます。
ここからが錬金術の真骨頂です。私たちは、サイコロ任せにするだけでなく、このレシピ \( z \) の数値を手動で少し書き換えることができるのです。
「辛さ」の数値を少し上げれば「激辛カレー」ができるように、AI内部の数値を操作することで、「笑顔の女性の画像を、少し怒った顔に変える」ことや、医療であれば「正常な肺のレントゲン画像に、指定した大きさの影(病変)を追加する」といった操作が自在に可能になります。
生成AIとは、単に画像を出すだけでなく、現実世界の裏側にある「構成要素(レシピ)」を自由に操ることができるツールなのです。
5. 医療現場への応用と「ハルシネーション」のリスク
さて、この「神様のサイコロ(生成AI)」は、私たちの医療現場で具体的にどのように役立つのでしょうか? また、どのような危険が潜んでいるのでしょうか? 光と影の両面を見ていきましょう。
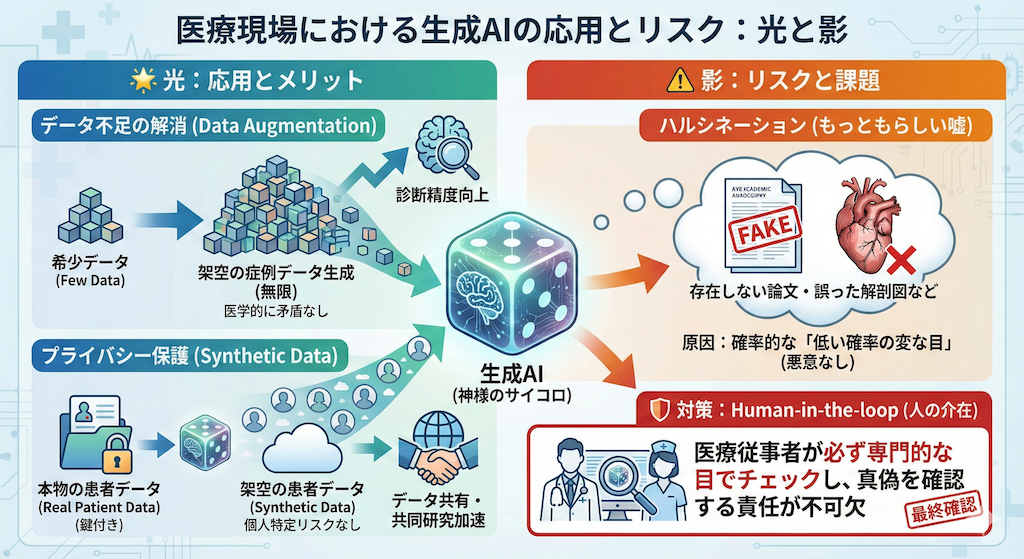
🌟 光:データ不足の解消(Data Augmentation)
医療AI開発の最大の壁は「データの少なさ」です。特に希少疾患の症例データは集めるのが難しく、AIの学習には不十分なことがよくあります。
そこで生成AIの出番です。AIに少数のデータを学習させ、その分布(特徴のルール)を捉えさせることで、「実在はしないが、医学的に矛盾のない架空の症例データ」を無限に作り出すことができます。
これを学習データに混ぜて「水増し」することで、AIの診断精度を向上させる技術が盛んに研究されています (Thirunavukarasu et al., 2023)。
🛡️ 光:プライバシー保護(Synthetic Data)
本物の患者データを病院の外に出すことは、プライバシー保護の観点から非常に困難です。
しかし、患者データの統計的特徴(分布)だけを学習したAIに、全く新しい「架空の患者データ(Synthetic Data)」を生成させればどうでしょうか?
このデータは実在する誰のものでもないため、個人のプライバシーを侵害するリスクがありません。これにより、施設間でのデータ共有や共同研究が劇的に加速すると期待されています (Chen et al., 2021)。
⚠️ 影:ハルシネーション(もっともらしい嘘)
しかし、決して忘れてはならない重大なリスクがあります。それがハルシネーション(Hallucination:幻覚)です。
ここまで見てきた通り、生成AIは「事実」を語っているのではなく、あくまで「確率的にありそうなもの」をサイコロを振って作っているに過ぎません。
そのため、時として「存在しない架空の論文をでっち上げる」「医学的にあり得ない誤った解剖図をもっともらしく描く」といった現象が起こります。
私たち人間から見れば「嘘」ですが、AIにとっては悪意などなく、単に「確率のサイコロでたまたま、低い確率の変な目が出ただけ」なのです。
だからこそ、AIを臨床で使う際には、私たち医療従事者が「Human-in-the-loop(人の介在)」として、AIの出力した内容を必ず専門的な目でチェックし、真偽を確認する責任が不可欠なのです。
まとめ:創造とは、確率の海を航海すること
今回は、生成AIが持つ「創造」の正体について解き明かしてきました。
それは決して魔法や魂の所業ではなく、膨大なデータの海原から、「確率」というコンパスを使って、まだ誰も見たことのない新しい座標(データ)を見つけ出す、数学的な航海の旅のようなものです。
AIはサイコロを振り続け、私たちの想像を超える景色を見せてくれます。しかし、その羅針盤が狂えば(ハルシネーション)、私たちを誤った方向へ導くこともあります。
次回、SEASON 2の後半では、この強力な技術を正しく使いこなすために不可欠な「倫理(バイアスの正体)」や、AIをシステムとして動かすための「仕組み(パイプライン)」について深掘りしていきます。
AIという優秀な航海士を正しく導くキャプテンになるために、もう少しだけ、その羅針盤の裏側の仕組みを学んでいきましょう。
※本記事は情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
参考文献
- Chen, R.J. et al. (2021) ‘Synthetic data in machine learning for medicine and healthcare’, Nature Biomedical Engineering, 5(6), pp. 493–497.
- Goodfellow, I. et al. (2014) ‘Generative Adversarial Nets’, Advances in Neural Information Processing Systems, 27.
- Kingma, D.P. and Welling, M. (2013) ‘Auto-Encoding Variational Bayes’, International Conference on Learning Representations.
- Moor, M. et al. (2023) ‘Foundation models for generalist medical AI’, Nature, 616(7956), pp. 259–265.
- Thirunavukarasu, A.J. et al. (2023) ‘Large language models in medicine’, Nature Medicine, 29, pp. 1930–1940.
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




