
🟦 Introduction: Understanding a Sentence Requires More Than Just Word Meanings
In the previous session, we explored how AI attempts to understand words like “apple” or “hospital” by converting them into meaningful bundles of numbers—so-called vectors.
These vector representations allow AI to treat words like “apple” and “banana” as semantically similar, while placing “apple” and “hospital” far apart in its internal “map of meaning,” because they belong to different contexts.
This mechanism forms the foundation of modern generative AI, especially large language models (LLMs).
However, understanding the meaning of individual words is not enough to truly comprehend a sentence.
Let’s take an example from a clinical document:
“The patient reported fever and coughing and was diagnosed with pneumonia.”
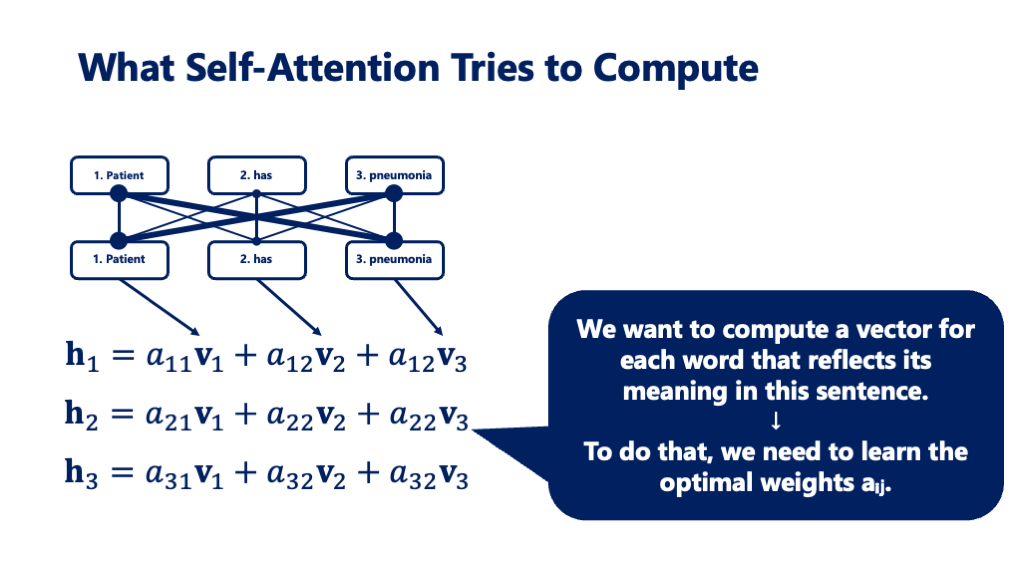
When we read this sentence, we naturally understand the connections within it:
- The symptoms: “fever” and “cough”
- The diagnosis: “pneumonia”
- The clinical action: “was diagnosed”
What’s important here isn’t just the meanings of individual words.
We must also consider questions like:
- Who was diagnosed with what?
- How are the symptoms and diagnosis related?
In other words, the relationships between words and context are key.
How Does AI Understand “Context” in Language?
As humans, we naturally grasp the flow and connection between words based on experience.
But AI doesn’t have emotions, intuition, or common sense.
Even so, there is a method that allows AI to identify and link important words within a sentence.
That method is the focus of this lesson: Attention.
Based on this concept of Attention, AI can now be applied to tasks like summarizing medical records, answering clinical questions, and even assisting in diagnosis.
In this session, we’ll explore:
- What is Attention?
- What is Self-Attention, the mechanism behind it?
- And how does the Transformer architecture work?
We’ll walk through these ideas step by step and intuitively, using real-world examples from medical practice to bring the concepts to life.
🟦 Chapter 1: What Is “Context”?
Even though AI has learned to handle the meaning of words to some extent, that understanding still largely stays at the individual word level.
However, real language is always used within the flow and connection of a full sentence or passage.
The key to decoding this “connection” is what we call context.
🔹 Context Means “Meaning Depends on Surroundings”
Let’s look at the following English sentence:
The patient was diagnosed with pneumonia.
To correctly understand the meaning of the word “diagnosed”, looking at the word alone is not enough.
We must consider its surroundings:
- Who was diagnosed?
→ The patient - With what were they diagnosed?
→ pneumonia
Only by reading the relationships between these surrounding words can one fully grasp the intended meaning.
🔹 In Clinical Settings, Context Is Everything Around the Statement
When reading electronic medical records, we naturally follow the surrounding context.
For example:
- If a note says “fever has persisted,” and is followed by “administered antibiotics” or “CT findings,” we automatically interpret the relationship between them.
- If we see a note like “Medical history: diabetes,” we might infer “This patient may be more susceptible to infection.”
This ability to read the meaningful connections between words is what it means to understand context.
🔹 Not Just the Word Meaning—How It’s Used Is Key
Even the same word can mean different things depending on its usage.
For example:
- “positive”
→ In test results, it means “positive” (as in a positive test for disease),
but emotionally, it could mean “optimistic” or “upbeat.” - “discharge”
→ Medically, it might mean “bodily fluid” or “discharge from the hospital,”
but its interpretation varies depending on context.
So, a word’s true meaning doesn’t come from the dictionary alone—
It comes from its behavior within a sentence.
🔹 The Next Challenge for AI: How to Read Context?
Even if AI can understand individual words as vectors, that alone isn’t enough to grasp the meaning of an entire sentence.
It also needs the ability to recognize:
“Which words are related to which, and how?”
This is where a powerful mechanism called Attention comes in — the focus of the next chapter.
Attention allows AI to decide:
“To understand this word, I should pay attention to that one.”
With this mechanism, AI can begin to capture the flow and coherence of meaning within a sentence.
In the next chapter, we’ll break down this “paying attention” system — known as Attention — in a way that’s intuitive and easy to understand.
🟦 Chapter 2: What Is Attention? — An Intuitive Explanation
In the previous chapter, we learned that the meaning of a word is shaped by its relationship to the words around it—in other words, context.
But how does AI actually read the connections within a sentence?
The key mechanism is a technique called Attention.
In AI, this term doesn’t just mean “paying attention” in the human sense—it refers to a system that determines how much focus to give each word in a sentence when processing language.
Let’s break this concept down using intuitive explanations and examples.
🔹 What Does “Paying Attention” Mean for AI?
When humans read a sentence, we instinctively focus on important words.
For instance, when we see the word “diagnosed”, we naturally ask:
- Who was diagnosed?
- With what were they diagnosed?
That is, humans unconsciously select important words in context.
The Attention mechanism allows AI to do something similar.
It numerically determines which words in a sentence to focus on when trying to understand a particular word.
🔹 Visualizing How Attention Works
Let’s consider the sentence:
The patient was diagnosed with pneumonia.
Suppose we want AI to understand the meaning of the word “diagnosed.”
The AI calculates how much attention it should pay to each other word in the sentence, such as:
- Focus on patient: 0.30
- Focus on pneumonia: 0.45
- Low attention on function words like the or was: maybe 0.05
Each word receives a score, representing how relevant it is to understanding “diagnosed.”
This scoring process is what we call Attention.

🔹 Attention Is a “Weighted Average”
But AI doesn’t just select which words to focus on.
It also gathers information from them in proportion to their scores.
In other words, it creates a weighted average of the meanings of all words in the sentence—weighted by how important each word is.
- Words with higher importance (e.g., pneumonia) contribute more to the final meaning.
- Words with lower importance (e.g., the) contribute less.
This allows AI to gradually form a context-aware understanding of a sentence.
🔹 Medical Applications of Attention
This mechanism is especially powerful in healthcare settings.
When AI reads a clinical record, it can:
- Focus more on diagnoses,
- While still considering the symptoms and test results that came before,
- Assigning each piece of information the proper weight.
This enables AI to automatically determine which information is more important in medical documents like progress notes or intake forms.
🟦 Chapter 3: What Is Self-Attention?
In the previous chapter, we learned how AI calculates how much attention to give each word when trying to understand a sentence—this is the essence of the Attention mechanism.
But how does AI apply this Attention to the entire sentence?
This is where the concept of Self-Attention comes in.
🔹 Every Word Attends to Every Other Word
Self-Attention is a mechanism where every word in a sentence pays attention to every other word—including itself.
At first, this might sound strange, but it allows AI to grasp how all the words in a sentence relate to one another at the same time.
Let’s take a clinical sentence as an example:
The patient reported a cough and fever and was diagnosed with pneumonia.
When processing this sentence, the AI might:
- Focus on the relationship between “pneumonia” and the symptoms “cough” and “fever.”
- Connect “diagnosed” with both the “patient” and “pneumonia” to understand who was diagnosed and with what.
- Link “patient” to many other words, as it’s the grammatical subject of the sentence.
In this way, Self-Attention allows the model to calculate how strongly every word is connected to every other word—all at once.
🔹Why Is It Called “Self”-Attention?
Traditional Attention typically involves two different sequences—for example, a question and a set of answer choices.
In contrast, Self-Attention works within a single sentence.
Each word “looks at” all other words in the same sentence and decides how much to focus on each one.
Because this process happens entirely within itself, it’s called Self-Attention.
🔹 Seeing the Whole Sentence at Once
The greatest strength of Self-Attention is that it allows AI to see the entire sentence from beginning to end at once.
For example, a symptom mentioned at the start of a sentence might relate to a diagnosis at the end.
Older AI models struggled to maintain this long-range connection.
But Self-Attention enables the AI to flexibly and simultaneously analyze relationships throughout the sentence—no matter how long it is.
This capability makes it possible for AI to read and understand long, complex clinical documents like medical records or reports without losing track of the overall flow.
🔹 Applications in Healthcare
This technology holds great promise for a wide range of applications—
from automatically summarizing electronic health records,
to predicting possible diagnoses,
to generating patient-friendly explanations.
Thanks to the mechanism of Self-Attention, AI is evolving from merely “reading words”
to deeply understanding context.
In the next chapter, we’ll explore how the degree of attention is calculated within Self-Attention.
To do that, we’ll take a closer look at the three essential vectors involved: Query, Key, and Value.
🟦 [Advanced] Chapter 4: The Three Roles Inside Attention — What Are Query, Key, and Value?
So far, we’ve seen that AI determines how much attention to give each word when processing a sentence.
But how exactly does it compute those attention scores numerically?
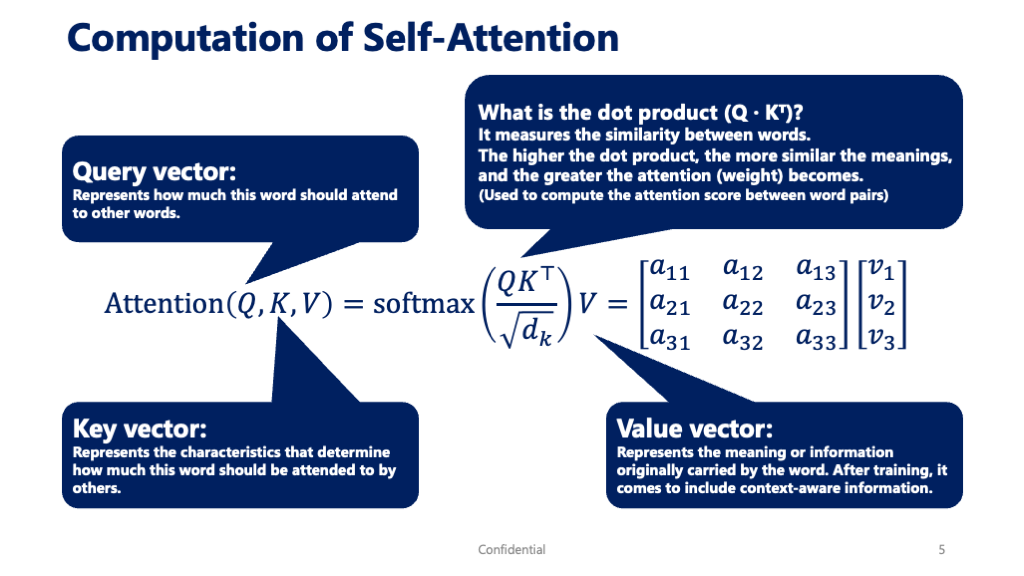
This is where three important vectors come into play:
Query, Key, and Value.
These may sound unfamiliar at first, but they are essential components that let AI calculate attention.
🔹 The Roles of Each: An Intuitive Breakdown
Let’s break them down one by one with simple analogies:
- Query (Q)
→ The “perspective” of the word trying to understand something.
Example: “To understand this word, where should I look?” - Key (K)
→ The “features” or “identity” of each word in the sentence.
Example: “What characteristics does this word have that make it worth focusing on?” - Value (V)
→ The actual “meaning” or content that will be used if the word is selected.
Example: “What information do I take in once I’ve focused on this word?”
You can think of it like this:
- Query = the one who is trying to focus
- Key = the one being evaluated for how relevant it is
- Value = the actual content contributed if selected
🔹 Understanding the Mechanism of Attention Through Illustrations
Let’s walk through this with an illustration.
📘 Image 1: Calculating Relatedness with Query

- The character on the left represents the Query—the word currently trying to understand its context.
- The three characters on the right represent other words in the sentence, each with a Key and a Value.
- The Query compares itself to each Key and calculates a similarity score (e.g., 0.4, 0.2, 0.1).
These scores represent how much attention should be paid to each word.
📘 Image 2: Creating a Weighted Meaning

- Using those scores, the AI then blends together the corresponding Values.
- A highly relevant word (e.g., score = 0.4) contributes more.
- A less relevant word (e.g., score = 0.1) contributes less.
- This process creates a new, context-aware meaning for the Query word.

🔹 A Medical Example
Let’s take a clinical sentence:
The patient complained of a 39°C fever and a severe cough.
Suppose AI is trying to understand the verb “complained.”
- “complained” is the Query — the focus of attention.
- “fever” and “cough” are the Keys — candidates for attention.
- Their corresponding Values contain information about those symptoms.
AI calculates how well “complained” matches with each Key, then gathers the Values accordingly to construct a context-aware understanding.
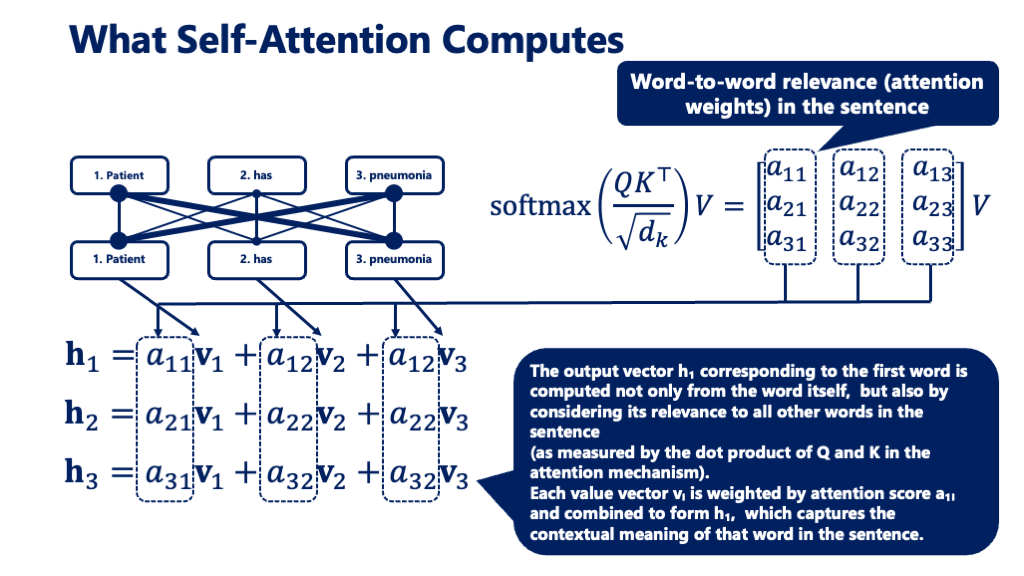
🔹 [Advanced] How the Calculation Works
The Attention process involves the following steps:
- Compute the dot product between each Query and Key
→ A measure of how related the two words are (higher = more relevant) - Apply scaling and a Softmax function
→ Converts raw scores into attention weights that sum to 1 - Use the weights to blend the Values
→ Creates a new vector that represents the Query word’s meaning in context
In this way, AI computes how much to draw from each other word’s information to form its understanding.
🔹 Clinical Implications
In medical documents, information such as symptoms, test findings, diagnoses, and treatments are often intricately intertwined.
The Attention mechanism allows AI to automatically extract contextually important information from such complex text and identify meaningful relationships.
For example, it can be applied in the following ways:
- Automatically identifying symptoms related to a diagnosis within clinical notes
- Understanding the relationship between test results and prescribed medications
- Highlighting parts of a patient’s complaint that a doctor should pay close attention to
All of these are made possible through the mechanism of Query, Key, and Value—the core components of Attention.
In the next chapter, we’ll explore how this Attention mechanism is scaled up into a powerful structure known as the Transformer.
This architecture forms the foundation of modern large language models (LLMs), including ChatGPT.
🟦 [Advanced] Chapter 5: What Is a Transformer?
So far, we’ve learned how AI uses mechanisms like Attention and Self-Attention to understand the relationships and context within a sentence.
Building on these ideas, the architecture that gave AI the power to deeply understand language is called the Transformer.
This model lies at the heart of today’s generative AI systems—including large language models (LLMs) like ChatGPT.
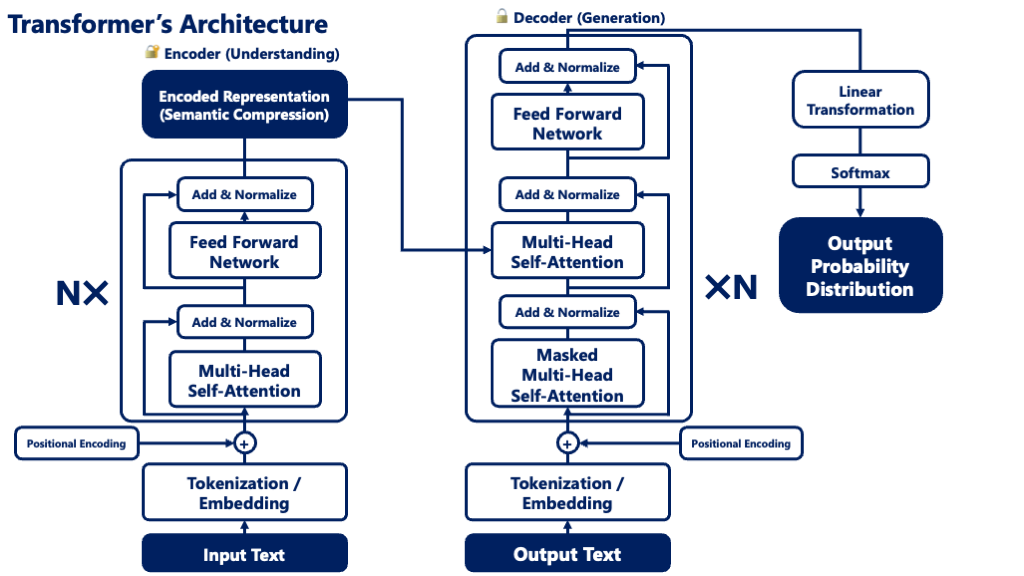
🔹 The Transformer Is a “Stack of Attention Mechanisms”
At its core, a Transformer is made up of multiple layers of Self-Attention.
- First, one layer of Self-Attention analyzes the relationships between all the words in a sentence.
- Then, the result is passed through additional layers, each building a deeper and more abstract understanding of the sentence.
This stacked architecture is the defining feature of Transformers.
🔹 How a Transformer Processes a Sentence
When a sentence enters a Transformer, it goes through the following steps:
- Convert words into vectors (Embedding)
→ Translates text into meaningful bundles of numbers. - Add position information (Positional Encoding)
→ Provides clues about the order of the words, since Self-Attention alone doesn’t track sequence. - Analyze relationships with Self-Attention
→ Every word attends to every other word to understand context. - Process the information with Feedforward layers
→ Refines and transforms the data to deepen understanding. - Repeat the above steps over multiple layers
→ Each layer builds on the last, creating a progressively richer understanding.
This multi-layered structure allows the Transformer to interpret sentence structure and flow in a highly sophisticated way.
🔹 Why the Transformer Was Revolutionary
Before the Transformer, older AI models—like RNNs and LSTMs—could only process text one word at a time, in sequence.
This made it hard for them to:
- Handle long sentences,
- Retain important early information,
- And analyze distant word relationships.
Transformers solved all of that by:
- Looking at the entire sentence at once,
- Analyzing all word relationships simultaneously,
- And doing so in a way that’s highly efficient for parallel computation.
This leap is what enabled the incredible performance of modern generative AI.
🔹 Real-World Applications in Healthcare
Transformers are already being applied in many areas of medicine.
For example:
- Extracting chief complaints, symptoms, diagnoses, and treatments from electronic health records
- Automatically generating summaries from patient interview notes
- Summarizing or translating doctor-patient conversations into natural, clear language
The strength of the Transformer lies in its ability to capture subtle relationships between words
while understanding the entire sentence as a whole.
This makes it especially powerful for handling long, complex texts—like medical documentation—with high accuracy.
In the next chapter, we’ll explore how the Transformer evolves further through a mechanism called Multi-Head Attention, which allows AI to “read a sentence from multiple perspectives at once.”
This enables AI to process information like a physician—considering multiple aspects simultaneously.
🟦 [Advanced] Chapter 6: What Is Multi-Head Attention?
In the previous chapter, we learned how the Transformer architecture processes sentences by stacking multiple layers of Self-Attention to understand deeper meaning.
Now, we’ll explore one of the most powerful enhancements inside a Transformer:
Multi-Head Attention.
This mechanism allows AI to read a sentence from multiple perspectives at the same time, making its understanding richer and more nuanced.
🔹 Why Is a Single Perspective Not Enough?
Let’s take this example of a medical sentence:
The patient, with a history of diabetes, visited the clinic complaining of fever and a cough.
This sentence contains multiple important relationships:
- “diabetes” → implies “higher risk of infection”
- “fever and cough” → suggests a “respiratory infection”
- “visited the clinic” → shows a “chief complaint and action”
All of these are relevant, but focusing from just one viewpoint risks missing some of these connections.
That’s where Multi-Head Attention comes in.
🔹 What Is a “Head” in Attention?
A head is one instance of Self-Attention.
In Multi-Head Attention, the Transformer runs several Attention mechanisms in parallel, each with its own perspective.
Each head is trained to focus on different kinds of relationships.
For example:
- Head 1: Focuses on relationships between symptoms and diagnoses
- Head 2: Focuses on grammatical structure (subject-verb connections)
- Head 3: Focuses on temporal or sequential expressions
- Head 4: Focuses on medical terminology clusters
By combining these diverse perspectives, the model achieves a deeper and more balanced understanding of the sentence.
🔹 How Many Heads Are There?
The number of heads depends on the model’s design.
For instance, large models like GPT may use several to over a dozen heads per layer.
Each head processes the sentence independently, then their outputs are merged and integrated.
You can think of it like a panel of doctors:
Each expert reads the same patient chart, but through their own specialty lens—then they combine their insights.
🔹 Advantages in Medical Applications
The Multi-Head Attention mechanism offers distinct advantages in real-world medical applications, such as:
- Simultaneously analyzing a patient’s chief complaint, medical history, test results, and diagnostic reasoning
- Reading both grammatical structure (who did what) and medical meaning (the relationship between symptoms and diagnoses) in parallel
- Interpreting ambiguous medical terms (e.g., whether “positive” means positive test result or optimistic) based on context
In this way, Multi-Head Attention gives AI the ability to capture important information scattered across a sentence and evaluate it comprehensively.
In the next chapter, we’ll reflect on how Attention has driven the evolution and transformation of AI.
We’ll explore why this technology has led to dramatic advances in areas like translation, summarization, and clinical decision support.
🟦 Chapter 7: The Revolution Brought by Attention
So far, we’ve learned how AI uses Attention, Self-Attention, Transformers, and Multi-Head Attention to understand language with increasing depth and nuance.
The introduction of these mechanisms marked a revolution in natural language processing.
It’s no exaggeration to say that Attention fundamentally transformed what AI could do with language.
🔹 Why Was It a Revolution?
Before Attention came along, AI systems—especially in tasks like machine translation and text understanding—relied heavily on sequential processing, using models like RNNs or LSTMs.
These older models processed sentences one word at a time, in order.
As a result, they struggled with:
- Long sentences, where earlier words were easily forgotten
- Complex sentence structures with multiple dependencies
- Capturing distant relationships between words
This was especially problematic in medical documents, where long, information-dense sentences are common and vital relationships must not be overlooked.
The Attention mechanism solved these challenges by allowing AI to:
- See the entire sentence at once
- Flexibly link related words, no matter how far apart
- Use parallel processing, enabling large-scale learning
🔹 Three Breakthroughs Enabled by Attention
- Global Understanding of a Sentence
→ Every word can interact with every other word, forming a web of meaning. - Automatic Focus on Key Information
→ AI can learn to pay more attention to important medical facts—such as diagnoses, test results, or symptoms—on its own. - Dramatic Improvement Across Tasks
→ Tasks like translation, summarization, and question answering saw major leaps in accuracy and usability.
This leap in capability laid the foundation for today’s generative AI.
🔹 Real-World Adoption in Medicine
The Attention-based models are already being used in healthcare, including in:
- Summarizing electronic medical records
→ Extracting key complaints, progress notes, and abnormal findings efficiently. - Supporting diagnoses
→ Suggesting possible conditions based on symptoms and test data. - Generating patient-friendly explanations
→ Turning clinical notes into easy-to-understand language for patients.
These applications are possible because AI now has the ability to identify key information and interpret it within context—just as a human clinician would.
🔹 The Backbone of Modern Language Models
Today’s large language models—such as ChatGPT, Claude, and Gemini—are all built on the foundation of the Transformer architecture and the Attention mechanism.
These models learn how language is used, and how meaning is shaped by context, by reading through trillions of words.
And the way they learn this information is powered by the capabilities of Attention.
In the next chapter, we’ll build on what we’ve learned so far by looking at real-world applications in healthcare.
We’ll deepen our understanding by exploring concrete examples of how Attention is driving progress in medical practice.
🟦 Chapter 8: Real-World Medical Applications — How Is Attention Used in Practice?
Until now, we’ve seen how AI has gained the ability to read not only the meaning of words, but also the context that connects them—thanks to the power of Attention.
So how is this technology actually being used in real-world medical settings?
In this chapter, we’ll explore specific examples of how Attention-powered AI is supporting healthcare professionals.
1. Automatic Summarization of Electronic Health Records (EHRs)
Clinicians often deal with dozens of pages of notes for a single patient.
Manually reviewing these records to find key information can be extremely time-consuming.
Attention-based AI can automatically identify and extract the most important data points.
Examples:
- From “two weeks of outpatient notes,” extract only the chief complaints, treatment changes, and abnormal test results
- From nursing records, highlight changes in vital signs or fall risk indicators
This not only saves time, but also reduces the risk of missing critical information.
2. Diagnosis Support from Symptom Descriptions
AI can read symptom descriptions in intake notes or interview records, then use Attention to identify relevant phrases and suggest possible diagnoses.
Examples:
- “Fever,” “cough,” and “shortness of breath” → Suggest pneumonia, bronchitis, etc.
- “Decreased consciousness” + “history of diabetes” → Suggest diabetic ketoacidosis
While final decisions rest with the clinician, this kind of tool can serve as a safety net or second opinion.
3. Automated Responses and Explanations for Patients
AI tools powered by Attention can also help explain medical information to patients in plain language.
Examples:
- When a patient asks, “Why am I taking this medication?”, the AI reads the chart and replies:
“This medication was prescribed to help control your blood sugar due to diabetes.” - When explaining lab results:
“Your white blood cell count is elevated, which can be a sign of infection.”
This helps reduce inconsistencies in patient communication.
4. Applications Made Possible by Context-Awareness
All of these use cases rely on one core ability:
The AI can understand not just individual words, but how they’re used in context.
That means it’s no longer just “looking up terms,” but truly reading the narrative behind the documentation.
This is the essence of how Attention helps AI understand meaning in real-world settings.
🔮 What’s Coming Next?
Future applications of Attention-based AI in healthcare may include:
- Automated review of nursing records (e.g., detecting fall or pressure ulcer risks)
- Draft generation of discharge summaries
- Summarizing pathology and imaging findings in natural language
- Advanced diagnosis support that integrates patient history and interview data
In all these areas, Attention-based AI can help save time, improve accuracy, and enhance patient safety.
In the next session, we’ll explore how AI doesn’t just read language—it can now generate it.
Building on everything we’ve learned about meaning and context, how does generative AI actually create natural, coherent sentences?
We’ll dive into the core mechanics of language generation in the next lecture!
📚 References
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al.
Attention is all you need.
In: Advances in Neural Information Processing Systems. 2017;30:5998–6008.
Devlin J, Chang MW, Lee K, Toutanova K.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
arXiv [Preprint]. 2018 Oct 11. arXiv:1810.04805. Available from: https://arxiv.org/abs/1810.04805
Radford A, Narasimhan K, Salimans T, Sutskever I.
Improving Language Understanding by Generative Pre-Training.
OpenAI; 2018. Available from: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Liu Y, Ott M, Goyal N, Du J, Joshi M, Chen D, et al.
RoBERTa: A Robustly Optimized BERT Pretraining Approach.
arXiv [Preprint]. 2019 Jul 26. arXiv:1907.11692. Available from: https://arxiv.org/abs/1907.11692
Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, et al.
Language Models are Few-Shot Learners.
In: Advances in Neural Information Processing Systems. 2020;33:1877–1901.
Lee J, Yoon W, Kim S, Kim D, Kim S, So CH, Kang J.
BioBERT: a pre-trained biomedical language representation model for biomedical text mining.
Bioinformatics. 2020;36(4):1234–40. doi:10.1093/bioinformatics/btz682
Rajkomar A, Dean J, Kohane I.
Machine Learning in Medicine.
N Engl J Med. 2019;380(14):1347–58. doi:10.1056/NEJMra1814259
Touvron H, Lavril T, Izacard G, Martinet X, Lachaux MA, Lacroix T, et al.
LLaMA: Open and Efficient Foundation Language Models.
arXiv [Preprint]. 2023 Feb 27. arXiv:2302.13971. Available from: https://arxiv.org/abs/2302.13971
Esteva A, Robicquet A, Ramsundar B, Kuleshov V, DePristo M, Chou K, et al.
A guide to deep learning in healthcare.
Nat Med. 2019;25(1):24–9. doi:10.1038/s41591-018-0316-z
数理の弾丸⚡️京大博士のAI解説. Transformer誕生物語|Attention is All You Need [インターネット]. YouTube; 2024年7月 [引用日: 2025年4月30日]. 利用可能: https://www.youtube.com/watch?v=6tcjwdanedU
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.




