

カルテの言葉を、医学的知見へ。
膨大な診療記録(テキストデータ)は宝の山です。自然言語処理(NLP)技術を用いて、非構造化データから価値ある情報を抽出し、活用するための技術を学びます。
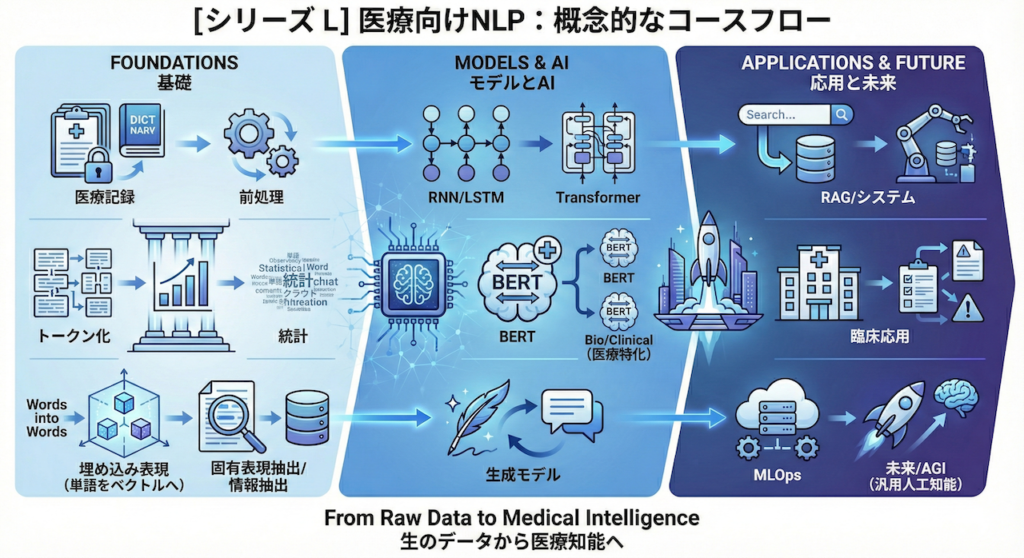
[Series L] NLP for Health: コースの全体像

第0部:データ基盤と前処理 — 医療テキストの特殊性と実務的解決
| ID | タイトル | 概要・キーワード |
|---|---|---|
| L00 | 第00回:医療NLPの射程:非構造化データから価値を抽出する | 医療テキストの特性(EHR/論文/自由記述)、情報抽出(IE)の臨床的意義、最新NLPパイプラインの俯瞰 |
| L01 | 第01回:データソースの理解:サマリ・記録・レポートの構造 | 入院サマリ、経過記録(SOAP)、放射線・病理レポート、PubMedドキュメントの書式とデータモデル |
| L02 | 第02回:医療安全とプライバシー:PHIの匿名化(De-id)技術 | 個人健康情報(PHI)の定義、k-匿名化、差分プライバシー、匿名化ツールの実装と評価 |
| L03 | 第03回:実践的正規表現:臨床テキストのパターン抽出術 | バイタルサイン、検査値、ID、日付の高度なマッチング、臨床コンテキストに特化したRegExエンジニアリング |
| L04 | 第04回:テキストクレンジング:表記ゆれとノイズの除去戦略 | Unicode正規化、全角半角、ストップワード、不要な記号の高度な処理、臨床略語の正規化基礎 |
| L05 | 第05回:医学知識の体系:ICD/ATCマスタのシステム統合 | 国際疾病分類(ICD-10)、薬効分類(ATC)、MEDISマスタのDB設計とAPI連携、階層構造の活用 |
| L06 | 第06回:臨床コンセプトの紐付け:SNOMED-CTとオントロジー | SNOMED-CTの構造、MeSH活用、異種コード間のマッピング技術(UMLS)、知識グラフの基礎 |
| L07 | 第07回:アノテーション戦略:高品質な医療教師データの創出 | ガイドライン設計、一致率(Kappa係数)、Doccano/Label Studio活用、能動学習によるコスト削減の端緒 |
| L08 | 第08回:日本語医療テキストの言語学的特性と形態素解析 | MeCab/Sudachi活用、医学用語ユーザー辞書の構築、未知語処理、漢字・カナ・英数字混在の正規化 |
| L09 | 第09回:データ基盤の構築:収集から前処理パイプラインの自動化 | ETLプロセス、データドリフト、スケーラブルなNLPパイプライン設計、次章への統合 |
第I部:言語モデルの進化とTransformer
| ID | タイトル | 概要・キーワード |
|---|---|---|
| L10 | 第10回:統計的NLPの極意:TF-IDFと特徴語抽出の臨床応用 | Bag-of-Words、TF-IDFによる重要語特定、医学論文や診療録のキーワード自動抽出、次元の呪いへの対処 |
| L11 | 第11回:トピックモデル:潜在的意味解析(LDA)による症例群の層別化 | ディリクレ分布、潜在トピックの推定、類似症例の自動グルーピング、探索的データ解析(EDA)の実装 |
| L12 | 第12回:分散表現の夜明け:Word2VecとFastTextの医療活用 | 分布仮説、Skip-gram/CBOW、類義語のベクトル演算、サブワード(n-gram)による未知語への対応 |
| L13 | 第13回:RNNからAttentionへ:時系列モデルの限界と革新 | LSTM/GRUによる長期依存性の保持、勾配消失問題、初期Attention機構(Luong/Bahdanau)の仕組み |
| L14 | 第14回:Transformer徹底解剖(1):Self-Attentionと並列処理 | Scaled Dot-Product Attention、Multi-Head Attentionの数学的理解、文脈情報の動的抽出 |
| L15 | 第15回:Transformer徹底解剖(2):Encoder-DecoderとPositional Encoding | 位置情報の付与、Feed-Forward Network、Residual Connection、Layer Normalization |
| L16 | 第16回:BERTの衝撃:マスク化言語モデル(MLM)による双方向理解 | 事前学習(Pre-training)と転移学習、NSP(次文予測)、Hugging Faceを通じたBERTモデルのロード |
| L17 | 第17回:医療ドメイン特化モデル:BioBERTとClinicalBERTの真価 | PubMed・MIMICデータによる継続学習、一般ドメインモデルとの精度比較、特化型モデルの選択基準 |
| L18 | 第18回:日本語医療BERT:J-ManifoldからUT-BERTまで | 日本語特有の形態素解析との統合、国内公開モデルのベンチマーク、電子カルテデータへの適用 |
| L19 | 第19回:ファインチューニング実践:分類・抽出タスクの垂直立ち上げ | 学習率の調整、混同行列による評価、オーバーフィッティング対策、次章(生成モデル)への橋渡し |
第II部:LLMとプロンプト工学
| ID | タイトル | 概要・キーワード |
|---|---|---|
| L20 | 第20回:Decoder-onlyモデルの台頭:GPTシリーズと自己回帰学習 | 次単語予測、Causal Self-Attention、スケーリング則、Encoder系モデルとの本質的違い |
| L21 | 第21回:プロンプト工学基礎:指示(Prompt)がモデルの挙動を変える | Zero-shot/Few-shot Learning、役割付与、制約条件の明示、医療タスクでの基本テンプレート |
| L22 | 第22回:思考の連鎖(CoT):推論ステップを明示して精度を上げる | Chain-of-Thought、Self-Consistency、複雑な鑑別診断や計算タスクへの応用、ハルシネーション抑制 |
| L23 | 第23回:高度なプロンプト技術:ReActとツール利用(Function Calling) | Reason + Act、外部ツール連携の基礎、医学データベース検索や計算機との統合、API設計の基本 |
| L24 | 第24回:オープンソースLLM:Llama, Gemma, Mistralの実装 | ローカルLLMのセットアップ、量子化(GGUF/EXL2)、メモリ節約術、プライバシー重視の院内環境構築 |
| L25 | 第25回:日本語LLMの現状:国内発モデルの評価と選定 | 日本語能力ベンチマーク、医療用語への対応状況、Elyza/CyberAgent等モデルの比較と商用利用権 |
| L26 | 第26回:LLMの医学的知識評価:ベンチマーク(USMLE等)と人間による評価 | MedQA、PubMedQA、臨床シミュレーションデータを用いた検証、LLM-as-a-Judgeによる自動評価の信頼性 |
| L27 | 第27回:パラメータ効率の良い微調整(PEFT):LoRAの数学と実装 | Low-Rank Adaptation、アダプタ学習、低リソース環境でのファインチューニング戦略、医療ドメイン適応 |
| L28 | 第28回:ハルシネーションへの挑戦:検出アルゴリズムと検証手法 | 事実性確認(Fact-checking)、自己矛盾検知、NLI(自然言語推論)による根拠検証の自動化 |
| L29 | 第29回:LLMの安全性と毒性管理:医療倫理ガードレールの構築 | 有害出力フィルタリング、機密情報(PHI)の流出防止、医療AIガイドラインへの準拠、次章(RAG)への接続 |
第III部:RAGと知識駆動システム
| ID | タイトル | 概要・キーワード |
|---|---|---|
| L30 | 第30回:RAG(検索拡張生成)入門:LLMに外部知識を授ける | RAGの基本原理、最新情報の反映、ハルシネーション抑制、ドキュメントローダーの実装 |
| L31 | 第31回:ベクトルデータベースの選択と構築:FAISSからPineconeまで | 近傍探索(ANN)、インデックスアルゴリズム(HNSW)、メタデータフィルタリングの実装戦略 |
| L32 | 第32回:医療文書のチャンキング戦略:意味的整合性を保つ分割手法 | 再帰的文字分割、セマンティックチャンキング、オーバーラップ設定、コンテキスト喪失への対策 |
| L33 | 第33回:リトリーバの高度化:ハイブリッド検索とリランキング(Re-rank) | キーワード(BM25) + ベクトル検索、Cross-Encoderによる再ランキング、Cohere Rerank活用 |
| L34 | 第34回:GraphRAGの挑戦:知識グラフとLLMの融合による構造的推論 | Neo4j等のグラフDB活用、エンティティ間の関係性抽出、大域的(Global)な質問への回答精度向上 |
| L35 | 第35回:クエリ変容:Query Translationによる検索漏れの防止 | Multi-query、Step-back Prompting、HyDE(Hypothetical Document Embeddings)の実装と評価 |
| L36 | 第36回:引用元提示の自動化:Attributed QAの実装と信頼性向上 | Citation抽出、根拠箇所のハイライト、引用元URL・PDFページへの自動リンク生成技術 |
| L37 | 第37回:RAG評価フレームワーク:Ragasによる「4つの評価指標」の実装 | Faithfulness、Answer Relevance、Context Precision、Context Recallの自動計測と改善ループ |
| L38 | 第38回:エージェント型RAG:自律的判断を伴う知識探索 | Self-RAG、Corrective RAG (CRAG)、検索の必要性をモデル自身が判断する自律型ループの設計 |
| L39 | 第39回:臨床ガイドラインQAの構築:RAGシステムの垂直統合演習 | 複数ガイドラインの統合、ドメイン適応、UX設計、現場導入に向けた精度評価の総仕上げ |
第IV部:高度なアーキテクチャと調整
| ID | タイトル | 概要・キーワード |
|---|---|---|
| L40 | 第40回:MoE(Mixture of Experts)の衝撃:巨大化と効率化の両立 | Sparse MoEの構造、Routerメカニズム、Mixtralの実装例、推論コスト削減の数学的背景 |
| L41 | 第41回:状態空間モデル(SSM)とMamba:Transformerを超える新潮流 | 線形時間計算量、Selective SSM、長文コンテキスト処理の革新、医療ビッグデータ解析への親和性 |
| L42 | 第42回:RLHF入門:強化学習によるモデルの意図アライメント | 人間によるフィードバック、報酬モデル(Reward Model)の構築、PPOアルゴリズムの基礎 |
| L43 | 第43回:DPO(Direct Preference Optimization):強化学習を不要にする最適化 | 選好データの直接学習、学習の安定性と実装の容易さ、医療ガイドライン適合への適用例 |
| L44 | 第44回:コンテキスト長の極限へ:RopeからFlashAttentionまで | Rotary Positional Embedding、FlashAttention-2による高速化、長大なカルテ履歴の一括処理 |
| L45 | 第45回:Speculative Decoding:推論速度を2〜3倍に加速する技術 | ドラフトモデルによる先読み推論、検証プロセスの並列化、リアルタイム診断支援への応用 |
| L46 | 第46回:ニューロ・シンボリックAI:LLMと論理推論エンジンの統合 | 論理的厳密性の確保、知識ベースとのハードコンストレイント、医療における意思決定の透明性 |
| L47 | 第47回:医療専門エージェントの強化学習:臨床判断プロセスの最適化 | マルチエージェント強化学習、エピソード記憶の活用、臨床シナリオに基づく自己改善ループ |
| L48 | 第48回:分散型モデルマージ:複数の専門モデルを一つに統合する | Model Merging(MergeKit)、SLERP、FrankenMoE、多様な臨床知識の低コスト統合 |
| L49 | 第49回:次世代アーキテクチャ展望:ブロックチェーンとの融合と安全性 | 改竄不可能な学習ログ、証明可能な医療AI、Web3とNLPの交差点、次章への総括 |
第V部:臨床実装ケーススタディ
| ID | タイトル | 概要・キーワード |
|---|---|---|
| L50 | 第50回:自動構造化の極致:退院サマリからのDPC・レジストリ自動生成 | 自由記述からの標準コード変換、情報の欠落検知、ヒューマン・イン・ザ・ループによる精度管理 |
| L51 | 第51回:臨床試験(治験)マッチング:包含・除外基準の自動判定システム | ClinicalTrials.gov解析、カルテとのクロスバリデーション、スクリーニング工数の大幅削減戦略 |
| L52 | 第52回:安全な投薬支援:経過記録からの副作用(ADE)シグナル検知 | 時系列テキストの変化抽出、因果関係推論の補助、ファーマコビジランスの自動化 |
| L53 | 第53回:患者中心の医療AI:難解な医療文書の「患者向け平易化」翻訳 | 専門用語の言い換え(Paraphrasing)、トーン制御、ヘルスリテラシーへの配慮と評価 |
| L54 | 第54回:マルチモーダル臨床支援:画像所見と読影レポートの不一致検出 | Vision-Languageモデルの応用、レポートの自動整合性チェック、重要見落としの防止システム |
| L55 | 第55回:精神科領域のNLP:発話・記述データからのバイオマーカー抽出 | 感情分析、認知的歪みの特定、自殺リスク予測、非侵襲的なスクリーニングツールの構築 |
| L56 | 第56回:看護業務のDX:看護記録からの転倒・褥瘡リスクの予兆検知 | 自由記述に含まれるリスク因子の構造化、リアルタイムアラートの実装、業務負荷軽減の検証 |
| L57 | 第57回:救急・災害医療のNLP:トリアージ支援と状況把握の迅速化 | 搬送記録の自動要約、重要情報の抽出、リソース最適化のためのデータ駆動型トリアージ |
| L58 | 第58回:医学教育・シミュレーション:生成AIによる症例提示と対話型学習 | 模擬患者ボットの設計、フィードバック自動生成、知識の定着度評価アルゴリズム |
| L59 | 第59回:臨床実装の総括:技術選定からシステムインテグレーションまで | コスト対効果の算出、現場への導入プロトコル、次なる拡張枠(L60〜)への展望 |
将来の技術(L60-L99)
| ID | タイトル | 概要・キーワード |
|---|---|---|
| L60-69 | 【第VI部】自律型医療エージェント:意思決定とアクションの自動化 | 将来の技術拡張枠。AIエージェントによる外部ツール操作、診察補助プロトコル、自律的タスク遂行など。 |
| L70-79 | 【第VII部】次世代アーキテクチャ:SSM、Mamba、そして未踏のモデルへ | 将来の技術拡張枠。Transformerを超える新たなアルゴリズム、超長文処理、推論効率の極限追求など。 |
| L80-89 | 【第VIII部】専門領域特化実装:垂直統合型ケーススタディ・アドバンスド | 将来の技術拡張枠。特定の診療科や希少疾患に特化したディープなNLP応用、実社会での大規模実証。 |
| L90-99 | 【第IX部】AGIと医療の未来:連合学習、SaMD、そして生命の言語化 | 将来の技術拡張枠。汎用人工知能への展望、多施設間プライバシー保護学習、規制環境の最終解。 |
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.