
「医師の目」を拡張する画像解析技術。
X線、CT、MRI、病理画像。CNN(畳み込みニューラルネットワーク)やVision Transformerを駆使し、医療画像から病変や特徴を検出・分類する技術を深掘りします。
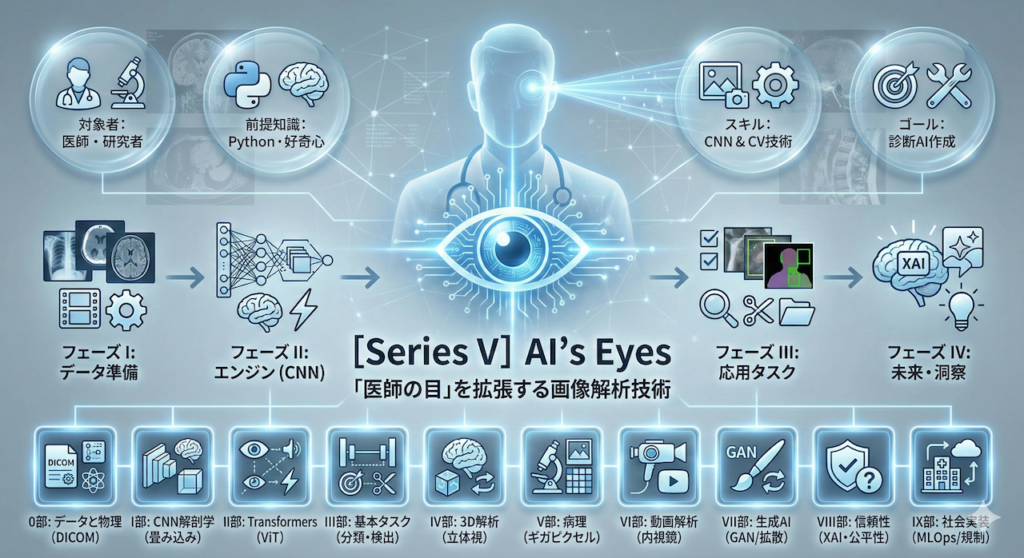
[Series V] AI’s Eyes:コースの全体像
第0部:データと物理 — 画像の向こう側にある「実体」
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V00 | 第00回:序論:医療AIの「目」が変えるもの | CAD (Computer Aided Diagnosis) の歴史, AIの役割, 放射線科医との協業, 倫理的課題 |
| V01 | 第01回:X線・CTの物理と特性 | X線の減衰, HU (Hounsfield Unit), ウィンドウイング, アーティファクト (金属, 骨) |
| V02 | 第02回:MRIの物理とシーケンス | T1/T2強調, FLAIR, 拡散強調画像 (DWI), k空間, 3次元ボクセルデータ |
| V03 | 第03回:超音波・病理・内視鏡の特性 | スペックルノイズ, 染色 (H&E), WSI (Whole Slide Image), 光学特性, 色空間 |
| V04 | 第04回:医用画像の共通言語「DICOM」 | タグ情報, ピクセルデータ, メタデータ, 匿名化処理, Pydicomライブラリ |
| V05 | 第05回:デジタル画像の基礎構造 | ピクセルとボクセル, ビット深度, 空間分解能, チャンネル数, テンソル表現 |
| V06 | 第06回:ヒストグラムとコントラスト調整 | ヒストグラム平坦化, CLAHE, ガンマ補正, 輝度正規化, 前処理の基礎 |
| V07 | 第07回:空間フィルタリングとノイズ除去 | ガウシアンフィルタ, メディアンフィルタ, エッジ検出 (Sobel/Canny), モルフォロジー演算 |
| V08 | 第08回:アノテーションの戦略とツール | バウンディングボックス, ポリゴン, キーポイント, マスク作成, ITK-SNAP, 3D Slicer |
| V09 | 第09回:データ拡張 (Augmentation) の極意 | 幾何学的変換, 弾性変形, Mixup, CutMix, 医療画像における「やってはいけない変換」 |
第0部:データと物理 — 画像の向こう側にある「実体」
- 第00回:V00:序論:医療AIの「目」が変えるもの
└ CAD (Computer Aided Diagnosis) の歴史, AIの役割, 放射線科医との協業, 倫理的課題 - 第01回:V01:X線・CTの物理と特性
└ X線の減衰, HU (Hounsfield Unit), ウィンドウイング, アーティファクト (金属, 骨) - 第02回:V02:MRIの物理とシーケンス
└ T1/T2強調, FLAIR, 拡散強調画像 (DWI), k空間, 3次元ボクセルデータ - 第03回:V03:超音波・病理・内視鏡の特性
└ スペックルノイズ, 染色 (H&E), WSI (Whole Slide Image), 光学特性, 色空間 - 第04回:V04:医用画像の共通言語「DICOM」
└ タグ情報, ピクセルデータ, メタデータ, 匿名化処理, Pydicomライブラリ - 第05回:V05:デジタル画像の基礎構造
└ ピクセルとボクセル, ビット深度, 空間分解能, チャンネル数, テンソル表現 - 第06回:V06:ヒストグラムとコントラスト調整
└ ヒストグラム平坦化, CLAHE, ガンマ補正, 輝度正規化, 前処理の基礎 - 第07回:V07:空間フィルタリングとノイズ除去
└ ガウシアンフィルタ, メディアンフィルタ, エッジ検出 (Sobel/Canny), モルフォロジー演算 - 第08回:V08:アノテーションの戦略とツール
└ バウンディングボックス, ポリゴン, キーポイント, マスク作成, ITK-SNAP, 3D Slicer - 第09回:V09:データ拡張 (Augmentation) の極意
└ 幾何学的変換, 弾性変形, Mixup, CutMix, 医療画像における「やってはいけない変換」
第I部:CNNの解剖学 — 視覚野の数理モデル
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V10 | 第10回:畳み込みニューラルネットワーク (CNN) 原論 | 畳み込み演算, カーネル (フィルタ), 特徴マップ, 局所結合性, 重み共有 |
| V11 | 第11回:受容野とプーリングの役割 | Max Pooling, Average Pooling, ストライド, 受容野の計算, 平行移動不変性 |
| V12 | 第12回:CNNにおける学習のメカニズム | バックプロパゲーション, 勾配消失問題, 活性化関数 (ReLU, Leaky ReLU), バッチ正規化 |
| V13 | 第13回:PyTorchによるCNN実装の基礎 | nn.Module, nn.Conv2d, forwardメソッド, モデルの構築, パラメータ数計算 |
| V14 | 第14回:深層化の歴史 (1):AlexNet & VGG | 3×3フィルタの重要性, 深さと表現力, GPU学習の夜明け, アーキテクチャの標準化 |
| V15 | 第15回:深層化の歴史 (2):ResNetの革命 | Skip Connection, 残差学習, 100層を超えるネットワーク, 勾配消失の解決 |
| V16 | 第16回:結合の工夫:DenseNet & Inception | 密な結合, 特徴の再利用, 1×1畳み込み, マルチスケール処理, 計算効率 |
| V17 | 第17回:効率化の追求:EfficientNet & MobileNet | 複合スケーリング則, Depthwise Separable Conv, 軽量モデル, エッジAI向け設計 |
| V18 | 第18回:転移学習:巨人の肩に乗る | ImageNet事前学習, ファインチューニング, 凍結 (Freezing), MedicalNet, ドメイン適応 |
| V19 | 第19回:損失関数と最適化手法の選択 | Cross Entropy, Adam vs SGD, 学習率スケジューリング, 過学習対策 (Dropout) |
第I部:CNNの解剖学 — 視覚野の数理モデル
- 第10回:V10:畳み込みニューラルネットワーク (CNN) 原論
└ 畳み込み演算, カーネル (フィルタ), 特徴マップ, 局所結合性, 重み共有 - 第11回:V11:受容野とプーリングの役割
└ Max Pooling, Average Pooling, ストライド, 受容野の計算, 平行移動不変性 - 第12回:V12:CNNにおける学習のメカニズム
└ バックプロパゲーション, 勾配消失問題, 活性化関数 (ReLU, Leaky ReLU), バッチ正規化 - 第13回:V13:PyTorchによるCNN実装の基礎
└ nn.Module, nn.Conv2d, forwardメソッド, モデルの構築, パラメータ数計算 - 第14回:V14:深層化の歴史 (1):AlexNet & VGG
└ 3×3フィルタの重要性, 深さと表現力, GPU学習の夜明け, アーキテクチャの標準化 - 第15回:V15:深層化の歴史 (2):ResNetの革命
└ Skip Connection, 残差学習, 100層を超えるネットワーク, 勾配消失の解決 - 第16回:V16:結合の工夫:DenseNet & Inception
└ 密な結合, 特徴の再利用, 1×1畳み込み, マルチスケール処理, 計算効率 - 第17回:V17:効率化の追求:EfficientNet & MobileNet
└ 複合スケーリング則, Depthwise Separable Conv, 軽量モデル, エッジAI向け設計 - 第18回:V18:転移学習:巨人の肩に乗る
└ ImageNet事前学習, ファインチューニング, 凍結 (Freezing), MedicalNet, ドメイン適応 - 第19回:V19:損失関数と最適化手法の選択
└ Cross Entropy, Adam vs SGD, 学習率スケジューリング, 過学習対策 (Dropout)
第II部:Transformers — 画像を「言葉」のように読む
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V20 | 第20回:Vision Transformer (ViT) の衝撃 | CNNの限界, 大域的特徴の捕捉, Inductive Biasの排除, データ量と精度の関係 |
| V21 | 第21回:Self-Attentionのメカニズム | Query/Key/Value, 注意重み行列, スケーリング, マルチヘッドアテンション |
| V22 | 第22回:画像をパッチに:ViTの構造 | パッチ埋め込み, 位置エンコーディング, クラストークン, MLPヘッド |
| V23 | 第23回:Swin Transformer:階層的アプローチ | ウィンドウアテンション, シフトウィンドウ, 階層的特徴抽出, 医療画像への適合性 |
| V24 | 第24回:CNNとViTのハイブリッド戦略 | 局所特徴と大域特徴の融合, TransUNet, コンボリューションの導入, 学習安定化 |
| V25 | 第25回:ConvNeXt:CNNの逆襲 | ViTの知見を取り入れたCNN, マクロ設計, 深層分離畳み込み, 現代的なCNNの最適解 |
| V26 | 第26回:自己教師あり学習 (SSL) 入門 | ラベルなしデータの活用, 表現学習, SimCLR, MoCo, 医療データ不足の解消 |
| V27 | 第27回:Masked Image Modeling (MAE) | マスク画像復元, BERTのような事前学習, 医療画像における有効性, 高い転移性能 |
| V28 | 第28回:医療特化型基盤モデル (Foundation Models) | 大規模事前学習, マルチモーダル対応, 汎用特徴抽出器, ゼロショット学習 |
| V29 | 第29回:Transformerの実装とチューニング | Hugging Face library, timm (PyTorch Image Models), メモリ消費対策, 勾配累積 |
- 第20回:V20:Vision Transformer (ViT) の衝撃
└ CNNの限界, 大域的特徴の捕捉, Inductive Biasの排除, データ量と精度の関係 - 第21回:V21:Self-Attentionのメカニズム
└ Query/Key/Value, 注意重み行列, スケーリング, マルチヘッドアテンション - 第22回:V22:画像をパッチに:ViTの構造
└ パッチ埋め込み, 位置エンコーディング, クラストークン, MLPヘッド - 第23回:V23:Swin Transformer:階層的アプローチ
└ ウィンドウアテンション, シフトウィンドウ, 階層的特徴抽出, 医療画像への適合性 - 第24回:V24:CNNとViTのハイブリッド戦略
└ 局所特徴と大域特徴の融合, TransUNet, コンボリューションの導入, 学習安定化 - 第25回:V25:ConvNeXt:CNNの逆襲
└ ViTの知見を取り入れたCNN, マクロ設計, 深層分離畳み込み, 現代的なCNNの最適解 - 第26回:V26:自己教師あり学習 (SSL) 入門
└ ラベルなしデータの活用, 表現学習, SimCLR, MoCo, 医療データ不足の解消 - 第27回:V27:Masked Image Modeling (MAE)
└ マスク画像復元, BERTのような事前学習, 医療画像における有効性, 高い転移性能 - 第28回:V28:医療特化型基盤モデル (Foundation Models)
└ 大規模事前学習, マルチモーダル対応, 汎用特徴抽出器, ゼロショット学習 - 第29回:V29:Transformerの実装とチューニング
└ Hugging Face library, timm (PyTorch Image Models), メモリ消費対策, 勾配累積
第III部:基本タスク — 分類・検出・セグメンテーション
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V30 | 第30回:画像分類 (Classification) の実践 | 疾患有無判定, 重症度分類, 混同行列, 感度・特異度, ROC曲線/AUC |
| V31 | 第31回:不均衡データへの挑戦 | 稀な疾患への対処, 重み付き損失, Focal Loss, オーバーサンプリング/アンダーサンプリング |
| V32 | 第32回:セマンティックセグメンテーション入門 | 画素単位の分類, Encoder-Decoder構造, 完全畳み込みネットワーク (FCN) |
| V33 | 第33回:形を捉える名手:U-Netの構造美 | スキップ接続の役割, 局所情報の復元, 医療画像分割のデファクトスタンダード |
| V34 | 第34回:U-Netの進化系:U-Net++ & Attention U-Net | ネストされたスキップ接続, アテンションゲート, 深層監督, 精度向上のテクニック |
| V35 | 第35回:物体検出 (Object Detection) の基礎 | バウンディングボックス回帰, IoU (Intersection over Union), NMS (Non-Maximum Suppression) |
| V36 | 第36回:高速検出:YOLOシリーズ | One-stage検出器, アンカーボックス, リアルタイム性, 最新YOLOの進化 |
| V37 | 第37回:高精度検出:Faster R-CNN | Two-stage検出器, RPN (Region Proposal Network), 肺結節検出等の応用 |
| V38 | 第38回:インスタンス & パノプティック分割 | Mask R-CNN, 個体識別と領域分割の同時実行, 背景と物体の統一的理解 |
| V39 | 第39回:セグメンテーションの評価指標 | Dice係数, Jaccard指数 (IoU), Hausdorff距離, 臨床的な評価との乖離 |
第III部:基本タスク — 分類・検出・セグメンテーション
- 第30回:V30:画像分類 (Classification) の実践
└ 疾患有無判定, 重症度分類, 混同行列, 感度・特異度, ROC曲線/AUC - 第31回:V31:不均衡データへの挑戦
└ 稀な疾患への対処, 重み付き損失, Focal Loss, オーバーサンプリング/アンダーサンプリング - 第32回:V32:セマンティックセグメンテーション入門
└ 画素単位の分類, Encoder-Decoder構造, 完全畳み込みネットワーク (FCN) - 第33回:V33:形を捉える名手:U-Netの構造美
└ スキップ接続の役割, 局所情報の復元, 医療画像分割のデファクトスタンダード - 第34回:V34:U-Netの進化系:U-Net++ & Attention U-Net
└ ネストされたスキップ接続, アテンションゲート, 深層監督, 精度向上のテクニック - 第35回:V35:物体検出 (Object Detection) の基礎
└ バウンディングボックス回帰, IoU (Intersection over Union), NMS (Non-Maximum Suppression) - 第36回:V36:高速検出:YOLOシリーズ
└ One-stage検出器, アンカーボックス, リアルタイム性, 最新YOLOの進化 - 第37回:V37:高精度検出:Faster R-CNN
└ Two-stage検出器, RPN (Region Proposal Network), 肺結節検出等の応用 - 第38回:V38:インスタンス & パノプティック分割
└ Mask R-CNN, 個体識別と領域分割の同時実行, 背景と物体の統一的理解 - 第39回:V39:セグメンテーションの評価指標
└ Dice係数, Jaccard指数 (IoU), Hausdorff距離, 臨床的な評価との乖離
第IV部:3D解析 — 立体としての臓器を理解する
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V40 | 第40回:3D画像データのハンドリング | NIfTIフォーマット, アフィン変換行列, 座標系 (RAS/LPS), ボクセルスペーシング |
| V41 | 第41回:3D CNNとV-Net | 3次元畳み込み, 3D U-Net, 体積データの直接学習, 計算コストの壁 |
| V42 | 第42回:効率的な3D学習戦略 | パッチベース学習, スライディングウィンドウ推論, 2.5Dアプローチ, ハイブリッド手法 |
| V43 | 第43回:医療画像の位置合わせ (Registration) 基礎 | 剛体変換 vs 非剛体変換, 類似度指標 (相互情報量), 最適化アプローチ |
| V44 | 第44回:深層学習によるRegistration | VoxelMorph, 教師なし学習による変形場推定, 解剖学的整合性の維持 |
| V45 | 第45回:アトラスベースのセグメンテーション | 標準脳アトラス, マルチアトラス手法, ラベル融合, 統計的形状モデル |
| V46 | 第46回:3Dデータの可視化とレンダリング | ボリュームレンダリング, 等値面抽出 (Marching Cubes), VTKライブラリ |
| V47 | 第47回:心臓MRIの4D解析 (3D+時間) | 心拍動のトラッキング, 左室駆出率 (LVEF) 自動計測, 壁運動評価 |
| V48 | 第48回:3Dパッチサンプリングの工夫 | 重み付きサンプリング, 境界領域の処理, GPUメモリ管理, バッチサイズの最適化 |
| V49 | 第49回:マルチモーダル3D解析 | PET/CT融合, MRIマルチシーケンス統合, 早期融合 vs 後期融合 |
第IV部:3D解析 — 立体としての臓器を理解する
- 第40回:V40:3D画像データのハンドリング
└ NIfTIフォーマット, アフィン変換行列, 座標系 (RAS/LPS), ボクセルスペーシング - 第41回:V41:3D CNNとV-Net
└ 3次元畳み込み, 3D U-Net, 体積データの直接学習, 計算コストの壁 - 第42回:V42:効率的な3D学習戦略
└ パッチベース学習, スライディングウィンドウ推論, 2.5Dアプローチ, ハイブリッド手法 - 第43回:V43:医療画像の位置合わせ (Registration) 基礎
└ 剛体変換 vs 非剛体変換, 類似度指標 (相互情報量), 最適化アプローチ - 第44回:V44:深層学習によるRegistration
└ VoxelMorph, 教師なし学習による変形場推定, 解剖学的整合性の維持 - 第45回:V45:アトラスベースのセグメンテーション
└ 標準脳アトラス, マルチアトラス手法, ラベル融合, 統計的形状モデル - 第46回:V46:3Dデータの可視化とレンダリング
└ ボリュームレンダリング, 等値面抽出 (Marching Cubes), VTKライブラリ - 第47回:V47:心臓MRIの4D解析 (3D+時間)
└ 心拍動のトラッキング, 左室駆出率 (LVEF) 自動計測, 壁運動評価 - 第48回:V48:3Dパッチサンプリングの工夫
└ 重み付きサンプリング, 境界領域の処理, GPUメモリ管理, バッチサイズの最適化 - 第49回:V49:マルチモーダル3D解析
└ PET/CT融合, MRIマルチシーケンス統合, 早期融合 vs 後期融合
第V部:病理と巨大画像 — ギガピクセルへの挑戦
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V50 | 第50回:デジタルパソロジーの世界 | バーチャルスライド, ギガピクセル画像, OpenSlide, ズームレベルとピラミッド構造 |
| V51 | 第51回:パッチング戦略と前処理 | 組織領域抽出 (Tissue Masking), タイリング処理, パッチ抽出の効率化 |
| V52 | 第52回:染色正規化 (Stain Normalization) | 施設間差の解消, Macenko法, Vahadane法, GANを用いた染色変換 |
| V53 | 第53回:弱教師あり学習:MILの基礎 | Multiple Instance Learning, バッグとインスタンス, ラベルなし領域の扱い |
| V54 | 第54回:Attention-based MIL | 注意機構による重要領域の特定, 重み付き集約, 説明可能な病理診断 |
| V55 | 第55回:クラスタリングを用いたMIL (CLAM) | データ効率の向上, 擬似ラベル, 最先端のWSI分類モデル |
| V56 | 第56回:細胞核の検出とセグメンテーション | StarDist, HoVer-Net, 重なり合う細胞の分離, Ki-67指標の自動算出 |
| V57 | 第57回:グリーソン・グレーディング自動化 | 前立腺がんの悪性度評価, パターン認識, 予後予測への応用 |
| V58 | 第58回:空間トランスクリプトミクスとの融合 | 遺伝子発現情報と画像のマッピング, マルチオミクス解析, 次世代病理学 |
| V59 | 第59回:病理AIの実装と高速化 | 大規模データローダー, GPU並列処理, 推論パイプラインの最適化 |
第V部:病理と巨大画像 — ギガピクセルへの挑戦
- 第50回:V50:デジタルパソロジーの世界
└ バーチャルスライド, ギガピクセル画像, OpenSlide, ズームレベルとピラミッド構造 - 第51回:V51:パッチング戦略と前処理
└ 組織領域抽出 (Tissue Masking), タイリング処理, パッチ抽出の効率化 - 第52回:V52:染色正規化 (Stain Normalization)
└ 施設間差の解消, Macenko法, Vahadane法, GANを用いた染色変換 - 第53回:V53:弱教師あり学習:MILの基礎
└ Multiple Instance Learning, バッグとインスタンス, ラベルなし領域の扱い - 第54回:V54:Attention-based MIL
└ 注意機構による重要領域の特定, 重み付き集約, 説明可能な病理診断 - 第55回:V55:クラスタリングを用いたMIL (CLAM)
└ データ効率の向上, 擬似ラベル, 最先端のWSI分類モデル - 第56回:V56:細胞核の検出とセグメンテーション
└ StarDist, HoVer-Net, 重なり合う細胞の分離, Ki-67指標の自動算出 - 第57回:V57:グリーソン・グレーディング自動化
└ 前立腺がんの悪性度評価, パターン認識, 予後予測への応用 - 第58回:V58:空間トランスクリプトミクスとの融合
└ 遺伝子発現情報と画像のマッピング, マルチオミクス解析, 次世代病理学 - 第59回:V59:病理AIの実装と高速化
└ 大規模データローダー, GPU並列処理, 推論パイプラインの最適化
第VI部:動画と時間 — 動的な生体情報の解析
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V60 | 第60回:医療動画データの特殊性 | 内視鏡, 超音波, 透視画像, フレームレート, ブラー, 鏡面反射 |
| V61 | 第61回:動画解析の基本アーキテクチャ | 3D-CNN (C3D, I3D), CNN+RNN (LSTM/GRU), 時間的特徴の抽出 |
| V62 | 第62回:Video Transformers | TimeSformer, ViViT, 時空間アテンション, 長期依存性の学習 |
| V63 | 第63回:手術工程認識 (Phase Recognition) | 手術フェーズの分類, TeCNO, MS-TCN, ワークフロー解析 |
| V64 | 第64回:手術器具の検出と追跡 | リアルタイム物体検出, Multi-Object Tracking (MOT), DeepSORT |
| V65 | 第65回:内視鏡ナビゲーションとSLAM | 自己位置推定, 3D再構成, 深度推定, 没入型手術支援 |
| V66 | 第66回:超音波 (エコー) 動画解析 | 断面の自動認識, 計測の自動化, ノイズ (スペックル) への対応, リアルタイム性 |
| V67 | 第67回:時間的動作検出 (Action Localization) | 手技の開始・終了判定, インシデント検知, 教育・評価システムへの応用 |
| V68 | 第68回:オプティカルフローと動き解析 | 臓器の動き推定, 呼吸性移動の補正, 変形追跡 |
| V69 | 第69回:リアルタイム処理の最適化 | TensorRT, 軽量モデル, レイテンシの削減, ストリーミング推論 |
第VI部:動画と時間 — 動的な生体情報の解析
- 第60回:V60:医療動画データの特殊性
└ 内視鏡, 超音波, 透視画像, フレームレート, ブラー, 鏡面反射 - 第61回:V61:動画解析の基本アーキテクチャ
└ 3D-CNN (C3D, I3D), CNN+RNN (LSTM/GRU), 時間的特徴の抽出 - 第62回:V62:Video Transformers
└ TimeSformer, ViViT, 時空間アテンション, 長期依存性の学習 - 第63回:V63:手術工程認識 (Phase Recognition)
└ 手術フェーズの分類, TeCNO, MS-TCN, ワークフロー解析 - 第64回:V64:手術器具の検出と追跡
└ リアルタイム物体検出, Multi-Object Tracking (MOT), DeepSORT - 第65回:V65:内視鏡ナビゲーションとSLAM
└ 自己位置推定, 3D再構成, 深度推定, 没入型手術支援 - 第66回:V66:超音波 (エコー) 動画解析
└ 断面の自動認識, 計測の自動化, ノイズ (スペックル) への対応, リアルタイム性 - 第67回:V67:時間的動作検出 (Action Localization)
└ 手技の開始・終了判定, インシデント検知, 教育・評価システムへの応用 - 第68回:V68:オプティカルフローと動き解析
└ 臓器の動き推定, 呼吸性移動の補正, 変形追跡 - 第69回:V69:リアルタイム処理の最適化
└ TensorRT, 軽量モデル, レイテンシの削減, ストリーミング推論
第VII部:生成AI — 創造による問題解決
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V70 | 第70回:医療における生成モデル (Generative AI) | データ拡張, 匿名化, モダリティ変換, 異常検知, 創薬・分子生成 |
| V71 | 第71回:GANs (敵対的生成NW) の基礎 | GeneratorとDiscriminator, Min-Maxゲーム, DCGAN, 学習の不安定性 |
| V72 | 第72回:CycleGANによるモダリティ変換 | MRIからCTへ, ペアなし画像変換, 合成CTの作成, ドメイン適応 |
| V73 | 第73回:超解像 (Super-Resolution) | 低線量CTの高画質化, MRIの撮像時間短縮, SRGAN, 臨床的妥当性の検証 |
| V74 | 第74回:変分オートエンコーダ (VAE) | 潜在空間の学習, 確率的生成, もつれ解除 (Disentanglement), 異常検知への応用 |
| V75 | 第75回:Diffusion Models (拡散モデル) 入門 | ノイズ付加と除去, DDPM, スコアベース生成, 高品質な画像生成の原理 |
| V76 | 第76回:Latent Diffusionと条件付き生成 | Stable Diffusionの仕組み, テキスト/マスクによる制御, 医療画像のインペインティング |
| V77 | 第77回:正常学習による異常検知 (Anomaly Detection) | 再構成誤差, AnoGAN, Diffusion-based AD, 未知の病変を見つける |
| V78 | 第78回:希少疾患・症例画像の合成 | データ不均衡の解消, プライバシーフリーなデータセット共有, 倫理的配慮 |
| V79 | 第79回:生成AIの評価と品質保証 | FID, SSIM, PSNR, 放射線科医によるチューリングテスト, 幻覚 (ハルシネーション) のリスク |
第VII部:生成AI — 創造による問題解決
- 第70回:V70:医療における生成モデル (Generative AI)
└ データ拡張, 匿名化, モダリティ変換, 異常検知, 創薬・分子生成 - 第71回:V71:GANs (敵対的生成NW) の基礎
└ GeneratorとDiscriminator, Min-Maxゲーム, DCGAN, 学習の不安定性 - 第72回:V72:CycleGANによるモダリティ変換
└ MRIからCTへ, ペアなし画像変換, 合成CTの作成, ドメイン適応 - 第73回:V73:超解像 (Super-Resolution)
└ 低線量CTの高画質化, MRIの撮像時間短縮, SRGAN, 臨床的妥当性の検証 - 第74回:V74:変分オートエンコーダ (VAE)
└ 潜在空間の学習, 確率的生成, もつれ解除 (Disentanglement), 異常検知への応用 - 第75回:V75:Diffusion Models (拡散モデル) 入門
└ ノイズ付加と除去, DDPM, スコアベース生成, 高品質な画像生成の原理 - 第76回:V76:Latent Diffusionと条件付き生成
└ Stable Diffusionの仕組み, テキスト/マスクによる制御, 医療画像のインペインティング - 第77回:V77:正常学習による異常検知 (Anomaly Detection)
└ 再構成誤差, AnoGAN, Diffusion-based AD, 未知の病変を見つける - 第78回:V78:希少疾患・症例画像の合成
└ データ不均衡の解消, プライバシーフリーなデータセット共有, 倫理的配慮 - 第79回:V79:生成AIの評価と品質保証
└ FID, SSIM, PSNR, 放射線科医によるチューリングテスト, 幻覚 (ハルシネーション) のリスク
第VIII部:信頼性 — ブラックボックスを開く
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V80 | 第80回:説明可能AI (XAI) の必要性 | ブラックボックス問題, 信頼の構築, デバッグとバイアス発見, 法的・倫理的要請 |
| V81 | 第81回:判断根拠の可視化:CAMファミリー | CAM, Grad-CAM, Grad-CAM++, ヒートマップの解釈と限界 |
| V82 | 第82回:摂動ベースと勾配ベースの説明手法 | Integrated Gradients, SHAP, LIME, 特徴量の重要度分析 |
| V83 | 第83回:Attention Mapの可視化 | ViTにおけるAttention Rollout, AIが「どこを見ていたか」の直感的理解 |
| V84 | 第84回:AIの「自信」を知る:不確実性推定 | 予測の確信度, Aleatoric (データ) 不確実性, Epistemic (モデル) 不確実性 |
| V85 | 第85回:Bayesian Neural Networks & Dropout | MC Dropout, アンサンブル学習, 信頼区間の算出, 安全な臨床判断支援 |
| V86 | 第86回:分布外 (OOD) 検知 | 想定外のデータ (未知の疾患・アーティファクト) の拒絶, 安全装置としてのAI |
| V87 | 第87回:敵対的攻撃 (Adversarial Attacks) と防御 | ノイズによる誤認識, FGSM, PGD, 医療AIのセキュリティ, ロバストなモデル構築 |
| V88 | 第88回:公平性とバイアスの評価 | 人種・性別・機種によるバイアス, 公平性指標, 倫理的なデータセット構築 |
| V89 | 第89回:モデルの校正 (Calibration) | 確率予測の正しさ, Reliability Diagram, Temperature Scaling, 臨床リスクスコアとの統合 |
第VIII部:信頼性 — ブラックボックスを開く
- 第80回:V80:説明可能AI (XAI) の必要性
└ ブラックボックス問題, 信頼の構築, デバッグとバイアス発見, 法的・倫理的要請 - 第81回:V81:判断根拠の可視化:CAMファミリー
└ CAM, Grad-CAM, Grad-CAM++, ヒートマップの解釈と限界 - 第82回:V82:摂動ベースと勾配ベースの説明手法
└ Integrated Gradients, SHAP, LIME, 特徴量の重要度分析 - 第83回:V83:Attention Mapの可視化
└ ViTにおけるAttention Rollout, AIが「どこを見ていたか」の直感的理解 - 第84回:V84:AIの「自信」を知る:不確実性推定
└ 予測の確信度, Aleatoric (データ) 不確実性, Epistemic (モデル) 不確実性 - 第85回:V85:Bayesian Neural Networks & Dropout
└ MC Dropout, アンサンブル学習, 信頼区間の算出, 安全な臨床判断支援 - 第86回:V86:分布外 (OOD) 検知
└ 想定外のデータ (未知の疾患・アーティファクト) の拒絶, 安全装置としてのAI - 第87回:V87:敵対的攻撃 (Adversarial Attacks) と防御
└ ノイズによる誤認識, FGSM, PGD, 医療AIのセキュリティ, ロバストなモデル構築 - 第88回:V88:公平性とバイアスの評価
└ 人種・性別・機種によるバイアス, 公平性指標, 倫理的なデータセット構築 - 第89回:V89:モデルの校正 (Calibration)
└ 確率予測の正しさ, Reliability Diagram, Temperature Scaling, 臨床リスクスコアとの統合
第IX部:社会実装 — 研究室から臨床現場へ
| ID | タイトル | 概要・キーワード |
|---|---|---|
| V90 | 第90回:画像AIのためのMLOps | 実験管理 (MLflow/WandB), モデルバージョニング, 再現性の確保, CI/CDパイプライン |
| V91 | 第91回:アノテーションプラットフォームの構築 | ラベル管理, 品質管理 (QA), 能動学習 (Active Learning) による効率化 |
| V92 | 第92回:連合学習 (Federated Learning) 入門 | データを持ち出さない学習, プライバシー保護, 分散学習, FedAvgアルゴリズム |
| V93 | 第93回:連合学習の課題と応用 | データの不均質性 (Non-IID), 通信コスト, 差分プライバシー, 多施設共同研究 |
| V94 | 第94回:エッジデバイスへの実装 | ONNX, TensorRT, OpenVINO, モデルの軽量化・量子化・枝刈り (Pruning) |
| V95 | 第95回:Web・モバイルベースの推論 | TensorFlow.js, WebAssembly, クライアントサイド推論, 遠隔医療への応用 |
| V96 | 第96回:薬事規制とSaMD (医療機器プログラム) | FDA/PMDAのガイドライン, AI医療機器の承認プロセス, 変更計画 (PCCP) |
| V97 | 第97回:AIの臨床評価と試験デザイン | 遡及的検証 vs 前方視的検証, ランダム化比較試験 (RCT), 臨床的有用性の証明 |
| V98 | 第98回:マルチモーダル統合診断 (VQA/Captioning) | 画像とテキスト (カルテ) の統合, Visual Question Answering, レポート自動生成 |
| V99 | 第99回:未来展望:医師とAIの共進化 | Human-in-the-loop, 汎用医療AI, 次世代の画像診断ワークフロー, 最終講義 |
第IX部:社会実装 — 研究室から臨床現場へ
- 第90回:V90:画像AIのためのMLOps
└ 実験管理 (MLflow/WandB), モデルバージョニング, 再現性の確保, CI/CDパイプライン - 第91回:V91:アノテーションプラットフォームの構築
└ ラベル管理, 品質管理 (QA), 能動学習 (Active Learning) による効率化 - 第92回:V92:連合学習 (Federated Learning) 入門
└ データを持ち出さない学習, プライバシー保護, 分散学習, FedAvgアルゴリズム - 第93回:V93:連合学習の課題と応用
└ データの不均質性 (Non-IID), 通信コスト, 差分プライバシー, 多施設共同研究 - 第94回:V94:エッジデバイスへの実装
└ ONNX, TensorRT, OpenVINO, モデルの軽量化・量子化・枝刈り (Pruning) - 第95回:V95:Web・モバイルベースの推論
└ TensorFlow.js, WebAssembly, クライアントサイド推論, 遠隔医療への応用 - 第96回:V96:薬事規制とSaMD (医療機器プログラム)
└ FDA/PMDAのガイドライン, AI医療機器の承認プロセス, 変更計画 (PCCP) - 第97回:V97:AIの臨床評価と試験デザイン
└ 遡及的検証 vs 前方視的検証, ランダム化比較試験 (RCT), 臨床的有用性の証明 - 第98回:V98:マルチモーダル統合診断 (VQA/Captioning)
└ 画像とテキスト (カルテ) の統合, Visual Question Answering, レポート自動生成 - 第99回:V99:未来展望:医師とAIの共進化
└ Human-in-the-loop, 汎用医療AI, 次世代の画像診断ワークフロー, 最終講義
ご利用規約(免責事項)
当サイト(以下「本サイト」といいます)をご利用になる前に、本ご利用規約(以下「本規約」といいます)をよくお読みください。本サイトを利用された時点で、利用者は本規約の全ての条項に同意したものとみなします。
第1条(目的と情報の性質)
- 本サイトは、医療分野におけるAI技術に関する一般的な情報提供および技術的な学習機会の提供を唯一の目的とします。
- 本サイトで提供されるすべてのコンテンツ(文章、図表、コード、データセットの紹介等を含みますが、これらに限定されません)は、一般的な学習参考用であり、いかなる場合も医学的な助言、診断、治療、またはこれらに準ずる行為(以下「医行為等」といいます)を提供するものではありません。
- 本サイトのコンテンツは、特定の製品、技術、または治療法の有効性、安全性を保証、推奨、または広告・販売促進するものではありません。紹介する技術には研究開発段階のものが含まれており、その臨床応用には、さらなる研究と国内外の規制当局による正式な承認が別途必要です。
- 本サイトは、情報提供を目的としたものであり、特定の治療法を推奨するものではありません。健康に関するご懸念やご相談は、必ず専門の医療機関にご相談ください。
第2条(法令等の遵守)
利用者は、本サイトの利用にあたり、医師法、医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(薬機法)、個人情報の保護に関する法律、医療法、医療広告ガイドライン、その他関連する国内外の全ての法令、条例、規則、および各省庁・学会等が定める最新のガイドライン等を、自らの責任において遵守するものとします。これらの適用判断についても、利用者が自ら関係各所に確認するものとし、本サイトは一切の責任を負いません。
第3条(医療行為における責任)
- 本サイトで紹介するAI技術・手法は、あくまで研究段階の技術的解説であり、実際の臨床現場での診断・治療を代替、補助、または推奨するものでは一切ありません。
- 医行為等に関する最終的な判断、決定、およびそれに伴う一切の責任は、必ず法律上その資格を認められた医療専門家(医師、歯科医師等)が負うものとします。AIによる出力を、資格を有する専門家による独立した検証および判断を経ずに利用することを固く禁じます。
- 本サイトの情報に基づくいかなる行為によって利用者または第三者に損害が生じた場合も、本サイト運営者は一切の責任を負いません。実際の臨床判断に際しては、必ず担当の医療専門家にご相談ください。本サイトの利用によって、利用者と本サイト運営者の間に、医師と患者の関係、またはその他いかなる専門的な関係も成立するものではありません。
第4条(情報の正確性・完全性・有用性)
- 本サイトは、掲載する情報(数値、事例、ソースコード、ライブラリのバージョン等)の正確性、完全性、網羅性、有用性、特定目的への適合性、その他一切の事項について、何ら保証するものではありません。
- 掲載情報は執筆時点のものであり、予告なく変更または削除されることがあります。また、技術の進展、ライブラリの更新等により、情報は古くなる可能性があります。利用者は、必ず自身で公式ドキュメント等の最新情報を確認し、自らの責任で情報を利用するものとします。
第5条(AI生成コンテンツに関する注意事項)
本サイトのコンテンツには、AIによる提案を基に作成された部分が含まれる場合がありますが、公開にあたっては人間による監修・編集を経ています。利用者が生成AI等を用いる際は、ハルシネーション(事実に基づかない情報の生成)やバイアスのリスクが内在することを十分に理解し、その出力を鵜呑みにすることなく、必ず専門家による検証を行うものとします。
第6条(知的財産権)
- 本サイトを構成するすべてのコンテンツに関する著作権、商標権、その他一切の知的財産権は、本サイト運営者または正当な権利を有する第三者に帰属します。
- 本サイトのコンテンツを引用、転載、複製、改変、その他の二次利用を行う場合は、著作権法その他関連法規を遵守し、必ず出典を明記するとともに、権利者の許諾を得るなど、適切な手続きを自らの責任で行うものとします。
第7条(プライバシー・倫理)
本サイトで紹介または言及されるデータセット等を利用する場合、利用者は当該データセットに付随するライセンス条件および研究倫理指針を厳格に遵守し、個人情報の匿名化や同意取得の確認など、適用される法規制に基づき必要とされるすべての措置を、自らの責任において講じるものとします。
第8条(利用環境)
本サイトで紹介するソースコードやライブラリは、執筆時点で特定のバージョンおよび実行環境(OS、ハードウェア、依存パッケージ等)を前提としています。利用者の環境における動作を保証するものではなく、互換性の問題等に起因するいかなる不利益・損害についても、本サイト運営者は責任を負いません。
第9条(免責事項)
- 本サイト運営者は、利用者が本サイトを利用したこと、または利用できなかったことによって生じる一切の損害(直接損害、間接損害、付随的損害、特別損害、懲罰的損害、逸失利益、データの消失、プログラムの毀損等を含みますが、これらに限定されません)について、その原因の如何を問わず、一切の法的責任を負わないものとします。
- 本サイトの利用は、学習および研究目的に限定されるものとし、それ以外の目的での利用はご遠慮ください。
- 本サイトの利用に関連して、利用者と第三者との間で紛争が生じた場合、利用者は自らの費用と責任においてこれを解決するものとし、本サイト運営者に一切の迷惑または損害を与えないものとします。
- 本サイト運営者は、いつでも予告なく本サイトの運営を中断、中止、または内容を変更できるものとし、これによって利用者に生じたいかなる損害についても責任を負いません。
第10条(規約の変更)
本サイト運営者は、必要と判断した場合、利用者の承諾を得ることなく、いつでも本規約を変更することができます。変更後の規約は、本サイト上に掲載された時点で効力を生じるものとし、利用者は変更後の規約に拘束されるものとします。
第11条(準拠法および合意管轄)
本規約の解釈にあたっては、日本法を準拠法とします。本サイトの利用および本規約に関連して生じる一切の紛争については、東京地方裁判所を第一審の専属的合意管轄裁判所とします。
For J³, may joy follow you.